
2
Understanding Domains, Ubiquitous Language, and Bounded Contexts
In this chapter, we will introduce some of the core concepts of domain-driven design (DDD). For those who have never worked with DDD before, it should cover enough of the details so that you understand the fundamental concepts. For those with more experience, it should serve as a refresher. I hope that after you have completed this book, you will also be able to use this chapter as a reference when applying DDD in the real world.
I have used real-life scenarios wherever possible to make things as clear as possible. This starts with the Setting the scene section, so be sure to read that even if you’re skimming!
By the end of the chapter, you should be able to answer the following questions:
- What is a domain?
- What is a sub-domain?
- What does ubiquitous language mean?
- What is a bounded context?
Technical requirements
In this chapter, we will write a small amount of Golang code. To be able to run it, you will need the following:
- Golang installation: You can find instructions to install it here: https://go.dev/doc/install. The code in this chapter was written with Go 1.19.3 installed, so anything later than this should be fine.
- A text editor or IDE: Some popular options are VS Code (https://code.visualstudio.com/download) and GoLand (https://www.jetbrains.com/help/go/installation-guide.html).
- GitHub repository: https://github.com/PacktPublishing/Domain-Driven-Design-with-GoLang/tree/main/chapter2.
Setting the scene
You have recently been promoted to be the team lead for a brand-new engineering team in your company, the payments and subscriptions team. As this is a new area for you, you diligently organize time with experts in the department to discuss the basics of the domain and how it works. Here is their response:
“When a lead uses our app for the first time, they must pick one of three subscription plans. These are basic, premium, and exclusive. Depending on which they pick determines which features they get access to within the app. This may change over time. Once a subscription plan has been created, we consider that the lead has converted to a customer, and we call them a customer until they churn. At this point, we call them a lead again. After 6 months, we call them a lost lead and we might target them with a re-engagement campaign, which could include a discount code. Once a plan is created, we set up a recurring payment to capture funds from the customer by direct debit.”
Excitedly, you run off and define the following interfaces as a starting point for the new application your team will be building:
package chapter2
import (
"context"
)
type UserType = int
type SubscriptionType = int
const (
unknownUserType UserType = iota
lead
customer
churned
lostLead
)
const (
unknownSubscriptionType SubscriptionType = iota
basic
premium
exclusive
)
type UserAddRequest struct {
UserType UserType
Email string
SubType SubscriptionType
PaymentDetails PaymentDetails
}
type UserModifyRequest struct {
ID string
UserType UserType
Email string
SubType SubscriptionType
PaymentDetails PaymentDetails
}
type User struct {
ID string
PaymentDetails PaymentDetails
}
type PaymentDetails struct {
stripeTokenID string
}
type UserManager interface {
AddUser(ctx context.Context, request UserAddRequest) (User, error)
ModifyUser(ctx context.Context, request UserModifyRequest) (User, error)
}We’ll revisit this as we learn more about DDD.
Domains and sub-domains
In the Setting the scene section, we outlined that we are going to be building a payments and subscriptions system. These are our domains. According to Eric Evans, domains are “a sphere of knowledge, influence, or activity.” (Domain-Driven Design, Addison-Wesley Professional).
The domain is the central entity in DDD; it is what we will model our entire language and system around. Another way to think of it is the world of business. Every time you read the phrase domain-driven design, you could read it as business problem-driven design.
Deciding on domains is a challenging problem and not always as obvious as in our example. In our example, we have two distinct domains—payments and subscriptions. Some teams may choose to treat these both as a single domain, which would be fine, too; DDD is not a science.
Bigger companies will often organize their teams around domains. In a mature organization, this will be a discussion that includes stakeholders from all departments to land on an organizational structure that makes sense. As new domains are discovered and teams grow, teams may split into new domain-based teams.
Domains and sub-domains can be used almost interchangeably. We tend to use a sub-domain to signal that the domain we are talking about is a child of a higher-level domain. In our example, we know that our payment and subscription domains are sub-domains of a much larger business domain. Therefore, we may refer to them as sub-domains, depending on the context of our conversation.
Ubiquitous language
Ubiquitous language is the overlap of the language that domain experts and technical experts use. The following Venn diagram highlights this:
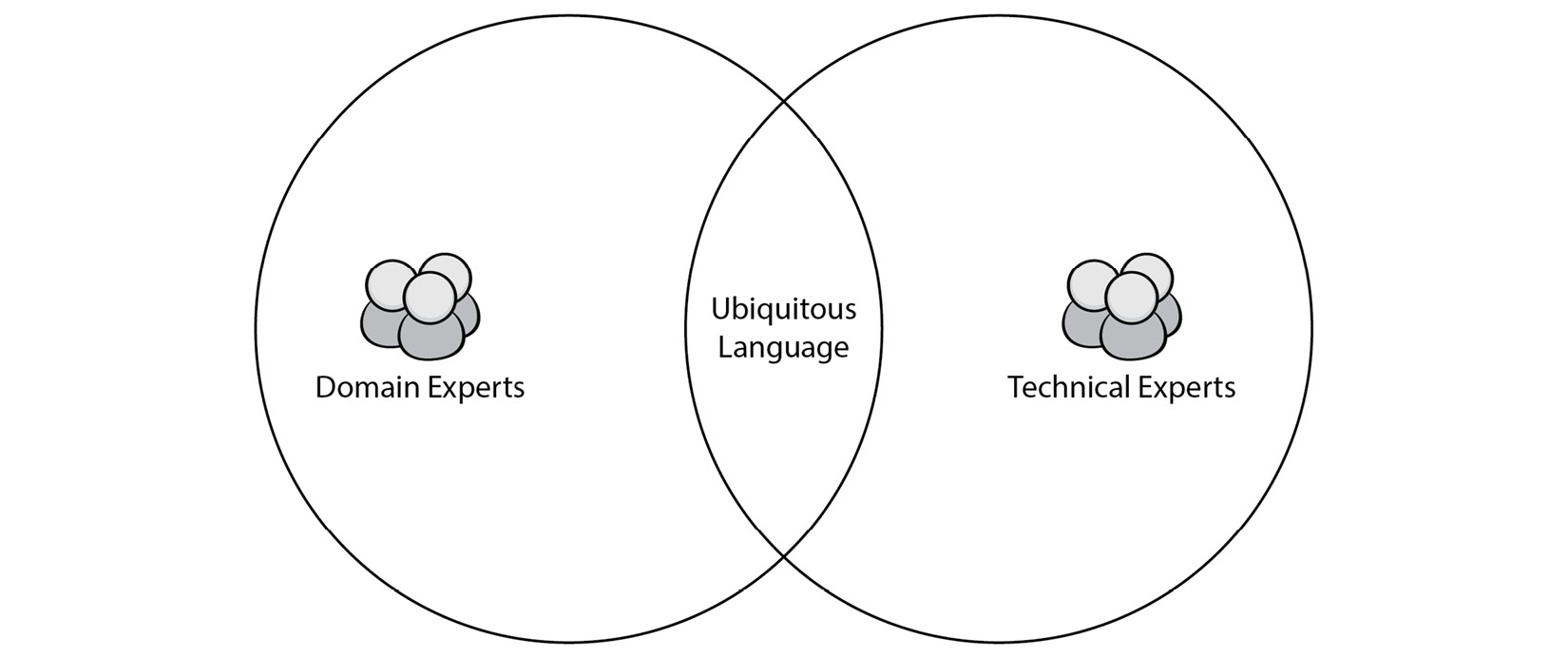
Figure 2.1 – Ubiquitous language
In the Setting the scene section, we highlighted interesting words that the experts used in your conversation. That language has a specific meaning in your team that might not hold for other companies or teams. For example, what is referred to as a customer in your team might mean something slightly different to the marketing team.
The highlighted words are your team’s ubiquitous language. It is a shared language, unique and specific to your team. Whenever your team talks about a customer or a lost lead, there should be no confusion about what this means. It is often helpful to keep a glossary of terms in your team’s wiki or documentation that is reviewed regularly. Although domain experts are fundamental to definitions, engineers must challenge them and think about edge cases to ensure the definitions are robust.
This language should be used when discussing requirements and system design and should even be used in the source code itself. Plus, it should evolve; therefore, you should spend time evaluating and updating it regularly (perhaps during sprint planning if you’re an agile team).
This sounds like a lot of effort, so let’s discuss the benefits of using it.
Benefits of ubiquitous language
One of the major reasons IT projects fail is because a requirement got lost in translation. For example, the business folks asked their team to support multiple accounts per customer. However, due to historical decisions and assumptions made about the business, their system doesn’t have a customer entity. There were strong assumptions made all over the system that there would only ever be one user per account. What could have potentially been a trivial change is now a hugely risky project that could span multiple quarters. Furthermore, notice the use of the term user and not the term customer in the description. This seems a minor distinction, but the fact the engineers were not thinking in terms of the business and using ubiquitous language is likely a reason this important invariant was missed.
We mentioned that our ubiquitous language should be used in the source code itself. Let’s take another look at some of the code we wrote in the Setting the scene section:
type UserType = int type subscriptionType = int const ( unknownUserType UserType = iota lead customer churned lostLead ) const ( unknownSubscriptionType subscriptionType = iota basic premium exclusive )
We have done a good job here of using ubiquitous language in our source code. Whenever the domain experts talk about a subscription, we do not need to do any mental gymnastics to find a system representation of it.
We also created a userType, but the discussion we had with the domain experts did not mention the term user at all. This would be a good opportunity to discuss this specific term and add it to your team’s ubiquitous language glossary to ensure when we use the term user, we are all talking about the same thing.
Some further code we wrote was this:
type UserAddRequest struct {
userType UserType
email string
subType subscriptionType
paymentDetails PaymentDetails
}
type UserModifyRequest struct {
id string
userType UserType
email string
subType subscriptionType
paymentDetails PaymentDetails
}
type User struct {
id string
}
type PaymentDetails struct {
stripeTokenID string
}
type UserManager interface {
AddUser(ctx context.Context, request UserAddRequest) (User, error)
ModifyUser(ctx context.Context, request UserModifyRequest) (User, error)
}At first sight, the rest of the code looks reasonable; I am sure you have seen code such as this before.
Let’s assume we worked with the domain experts and agreed on a definition for the term user as a way to represent any persons using our app (or who have used our app) no matter their status. The possible states are lead, lost lead, customer, and churned, but we may discover more in the future. Given this definition, the AddUser function now doesn’t seem like such a good idea. Our domain doesn’t have the concept of adding users, and using this phrase with domain experts is likely to confuse them. We are going to end up with a mapping between a system representation of the domain and a real-world representation. We are not benefiting from the time we have invested to come up with a robust ubiquitous language.
If we go back to the brief, we see that someone new to the app is called a lead, and once they select a subscription, they convert into a customer. Given this, we can make some amendments to our code, as follows:
type LeadRequest struct {
email string
}
type Lead struct {
id string
}
type LeadCreator interface {
CreateLead(ctx context.Context, request LeadRequest) (Lead, error)
}
type Customer struct {
leadID string
userID string
}
func (c *Customer) UserID() string {
return c.userID
}
func (c *Customer) SetUserID(userID string) {
c.userID = userID
}
type LeadConvertor interface {
Convert(ctx context.Context, subSelection SubscriptionType) (Customer, error)
}
func (l Lead) Convert(ctx context.Context, subSelection SubscriptionType) (Customer, error) {
//TODO implement me
panic("implement me")
}This code is much more reasonable and reflects the real world much better. Now, when we discuss our system with our experts, we can talk in terms of leads, converting leads, customers, and subscriptions—all ubiquitous language to our domain.
How do you ensure you capture all ubiquitous language?
There are no shortcuts to building a robust, ubiquitous language; it takes time. Spending lots of time with domain experts is the best way to ensure you capture all important languages. One way to do this is to ask whether you can join their meetings and perhaps offer to take the minutes. During the meeting, you should write down any terms you did not understand and afterward follow up to get a definition. Ensure you add this to the glossary of terms and share this with the rest of your colleagues.
A warning on the application of ubiquitous language
It can be tempting to try to apply a ubiquitous language across multiple projects, teams, and even across an entire company. However, if you do this, you are setting yourself up for failure. Evans advises that ubiquitous language should only apply to a single bounded context (we talk about the bounded context in the next section, but for now, you can think of bounded context as our project team and the system we proposed in the Setting the scene section). The reason for this is that ubiquitous language works best when it is rigorous. If you try to make a specific word (especially, loaded terms such as customer or user) apply to all different areas of your business, the term will lose that rigor, and confusion will reign.
Bounded contexts
We have the beginnings of an outline for our subscription system. We have even described some ubiquitous language to describe the system. What if someone from a different area of a business came to discuss customers with us? The first thing we should do is define what a customer means to them as it may mean something different within their bounded context.
Bounded contexts are all about dividing large models into smaller, easier-to-understand chunks and being explicit about how they relate to each other.
Another way to think of them is a boundary—when we define a term in one context, it does not need to mean the same in another (although there are likely similarities). For example, if we were to draw a diagram for our subscription system, it might look like this:
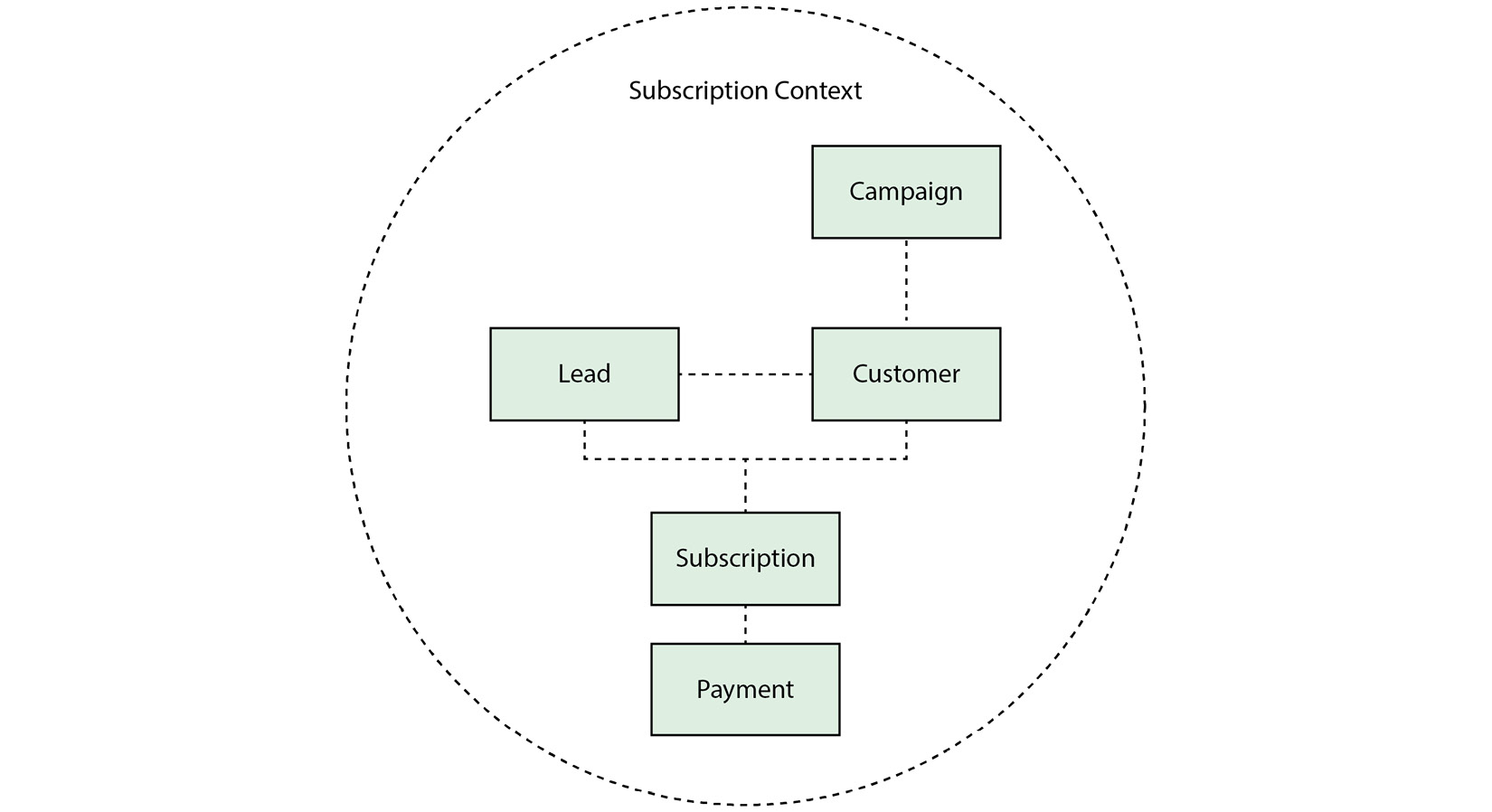
Figure 2.2 – A domain map of our subscription context and how different objects are related
But after speaking to marketing and understanding their context just a little bit, we might define the following relationships:
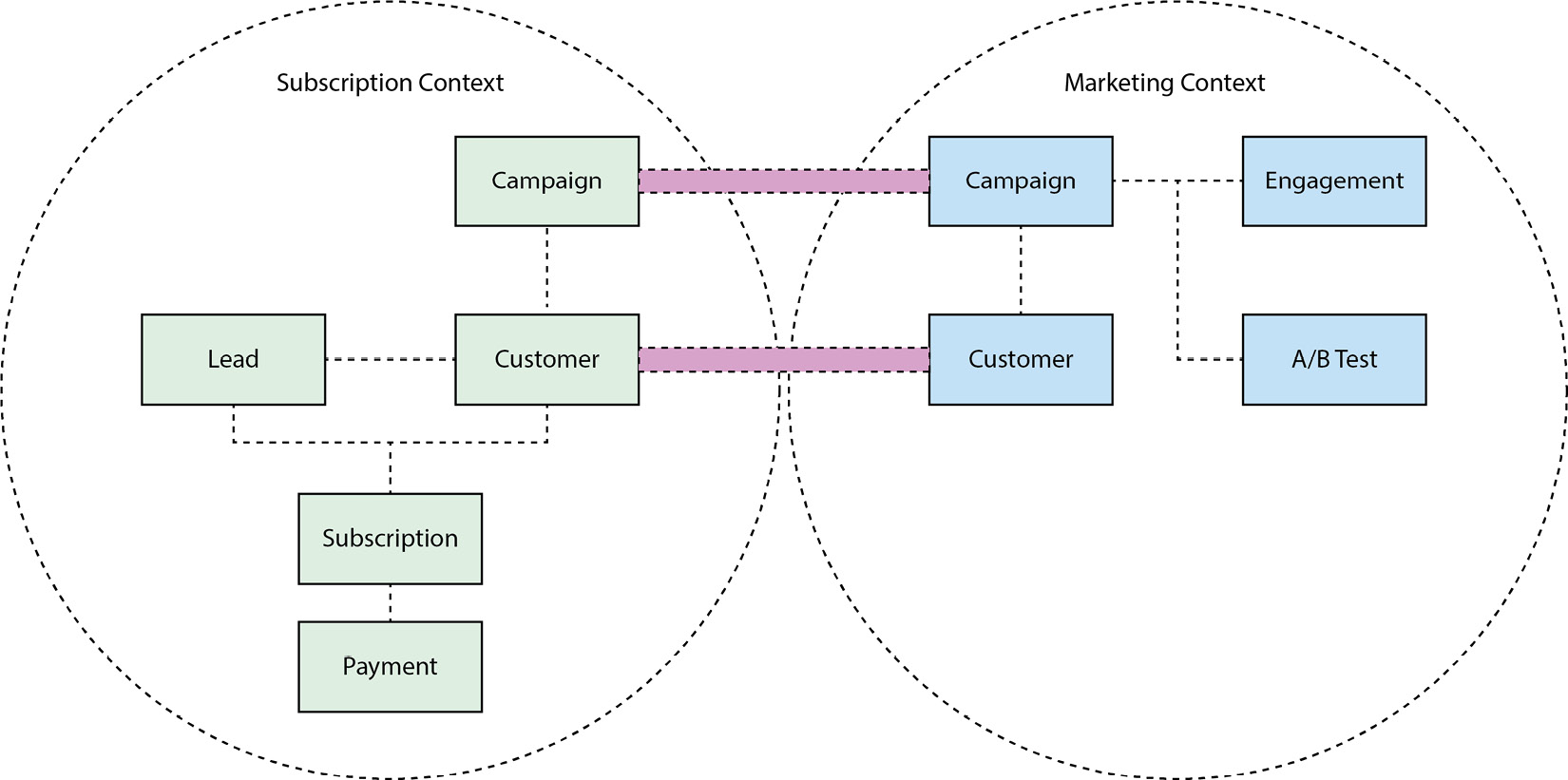
Figure 2.3 – Mapping between marketing and subscription contexts
The lines between campaign and customer in the different bounded contexts represent that, although the same term is used, the model is different, and we can expect to do some mapping between them. This is discussed in detail in the following paragraphs.
We have clarified here that both contexts care about campaigns and customers, but how we model it and talk about it in each context does not need to be the same. This is a simple example, but as systems evolve and gain complexity, defining boundaries makes more and more sense.
Since several bounded contexts often must communicate as shown in Figure 2.3, we often apply patterns to ensure our models can maintain integrity. The three main patterns are as follows:
- Open Host Service
- Published language
- Anti-corruption layer
Let’s explore these patterns in more detail.
Open Host Service
An Open Host Service is a means of giving other systems (or sub-systems) access to ours. Evans leaves it purposefully ambiguous as its implementation depends on your team’s skill sets and other constraints (for example, if you are working with legacy applications, some of the modern Remote Procedure Call (RPC) approaches discussed here might not be viable to you). Typically, an Open Host Service is an RPC. Some choices for RPCs might be to build a RESTful API, implement gRPC, or perhaps even an XML API!
Here is a visual example of what an Open Host Service might look like:
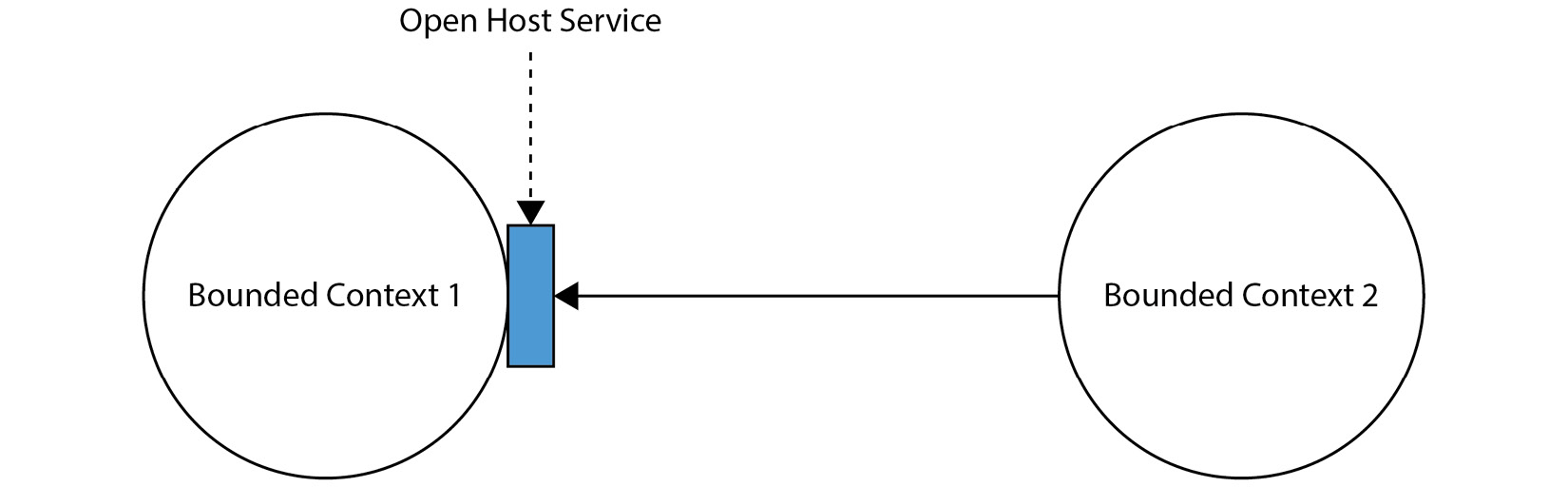
Figure 2.4 – An Open Host Service
In this diagram, the rectangle represents an exposed piece of our bounded context.
Let’s apply what we have learned about Open Host Service to our example.
For our payments and subscription example, we might expose an endpoint to allow the marketing team to get various kinds of information about a user within our context, such as this:
package chapter2
import (
"context"
"encoding/json"
"net/http"
"github.com/gorilla/mux"
)
type UserHandler interface {
IsUserSubscriptionActive(ctx context.Context, userID string) bool
}
type UserActiveResponse struct {
IsActive bool
}
func router(u UserHandler) {
m := mux.NewRouter()
m.HandleFunc("/user/{userID}/subscription/active", func(writer http.ResponseWriter, request *http.Request) {
// check auth, etc
uID := mux.Vars(request)["userID"]
if uID == "" {
writer.WriteHeader(http.StatusBadRequest)
return
}
isActive := u.IsUserSubscriptionActive(request.Context(), uID)
b, err := json.Marshal(UserActiveResponse{IsActive: isActive})
if err != nil {
writer.WriteHeader(http.StatusInternalServerError)
return
}
_, _ = writer.Write(b)
}).Methods(http.MethodGet)
}The preceding code block exposes a simple endpoint over HTTP available at /user/{userID}/subscription/active that could be used by another team to check whether a user has an active subscription or not.
Published language
A ubiquitous language is our team’s internal formally defined language; a published language is the opposite. If our team is going to expose some of our systems to other teams via an Open Host Service, we need to ensure the definition of what we expose to other teams in different bounded contexts is clear.
If we were to extend our HTTP server mentioned earlier to have a GET /{id}/user endpoint, we would need to publish language to help other teams understand the output schema. Two popular ways to present published language are via OpenAPI or gRPC.
OpenAPI
We can use OpenAPI to define the schema. This is a popular approach as you can also generate client and server code to speed up development for your team and for consumer teams too. You can use a tool called Swagger for this. The code might look something like this:
swagger: "2.0" info: description: "Public documentation for payment & subscription System" version: "1.0.0" title: "Payment & Subscription API" contact: email: "[email protected]" host: "api.payments.com" schemes: - "https" paths: /users: get: summary: "Return details about users" operationId: "getUsers" produces: - "application/json" responses: "200": description: "successful operation" schema: $ref: "#/definitions/User" "400": description: "bad request" "404": description: "users not found" definitions: User: type: "object" properties: id: type: "integer" format: "int64" username: type: "string" subscriptionStatus: type: "boolean" subscriptionType: type: "string" email: type: "string" ApiResponse: type: "object" properties: code: type: "integer" format: "int32" type: type: "string" message: type: "string"
This code generates the following easy-to-digest UI, which we can share with other teams as our published language:
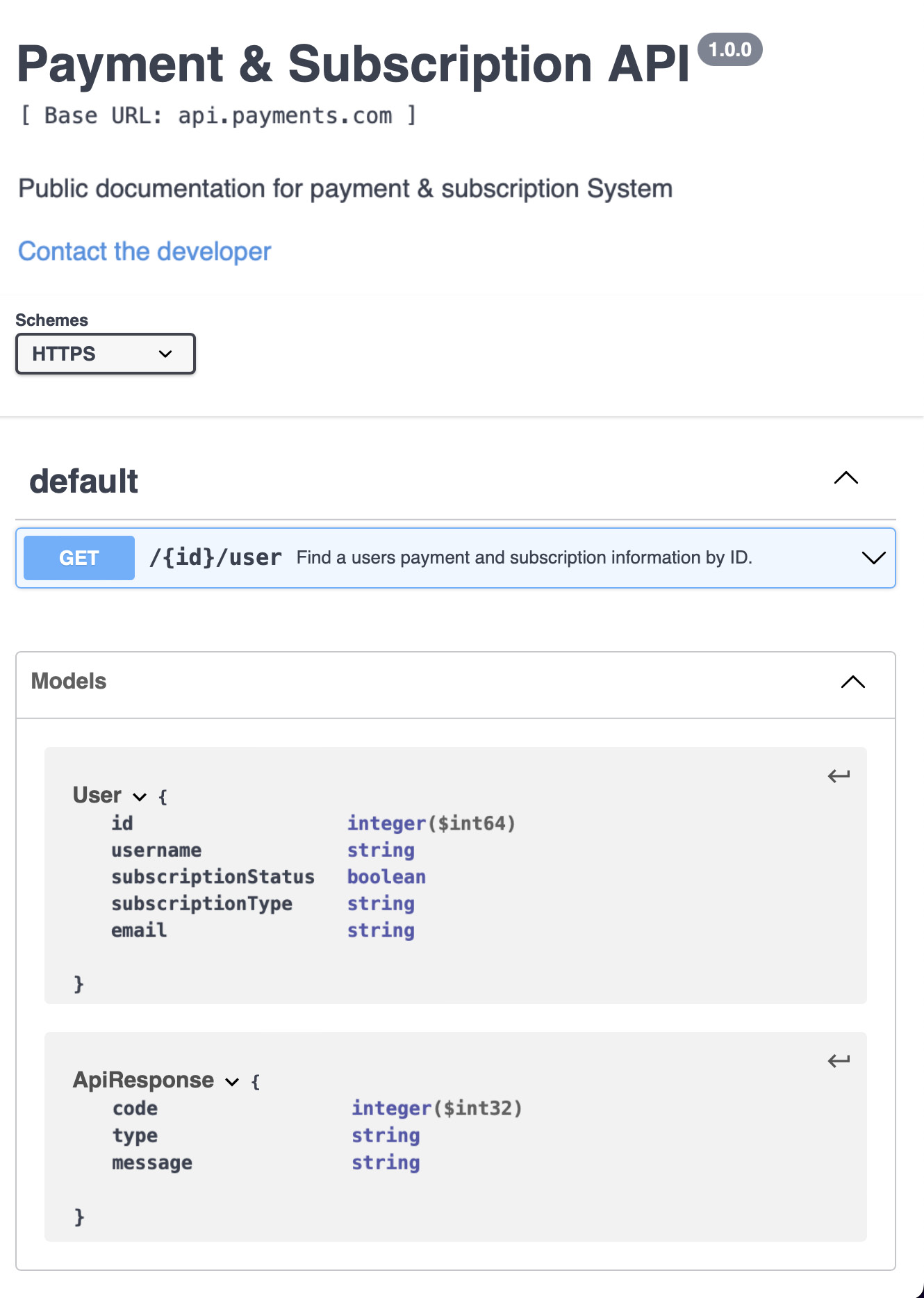
Figure 2.5 – The generated API documentation for the OpenAPI specification
If you want to play around and generate your own OpenAPI code from a specification, you can use the Swagger Editor (https://editor.swagger.io) in your browser.
As well as generating documentation, Swagger also enables you to generate client and server code in a variety of different languages and frameworks:

Figure 2.6 – Languages supported by Swagger
For Go specifically, I have had a lot of success using oapi-codegen (https://github.com/deepmap/oapi-codegen). oapi-codegen supports generating Go clients and servers from OpenAPI specifications such as the one we created previously. It contains plenty of configuration options and supports multiple server libraries, such as gorilla and chi. Let’s see how we can use it and step through the generated code. You can find all the code and configuration in the GitHub repository for this book here: https://github.com/PacktPublishing/Domain-Driven-Design-with-GoLang/tree/main/chapter2/oapi.
Firstly, we have created a configuration file. This tells the open-api generator which go package we would like our generated code to be in and which file to store the generated code in. It looks like this:
package: oapi output: ./openapi.gen.go generate: models: true
We now need to install the open-api generator. We can do this with the following command:
go install github.com/deepmap/oapi-codegen/cmd/oapi-codegen@latest
After this is installed, we simply need to run the following command from within the chapter2/oapi folder:
oapi-codegen --config=config.yml ./oapi.yaml
If all goes well, you should see an openapi.gen.go file is created:

Figure 2.7 – openapi.gen.go file
If you see some errors when you open the file, it’s likely because we don’t have all the necessary Go modules synced to our project. If you run the following, the errors should go away:
go mod tidy && go mod vendor
You now have an interface for a server that you can implement. Every time you update your API documentation, you can rerun this command to generate a new server definition.
Generating a Go client is especially easy. All we need to do is add client: true to our config file. So, config.yml now looks like this:
package: oapi output: ./openapi.gen.go generate: models: true client: true
Our generated code now has a new Client definition:
// The interface specification for the client above.
type ClientInterface interface {
// GetUsers request
GetUsers(ctx context.Context, reqEditors ...RequestEditorFn) (*http.Response, error)
}Again, if we updated our OpenAPI specification and wanted to update the client, all we would need to do is run the preceding command again. You could set up a job as part of your continuous integration (CI) pipeline that generates a new client package every time a specification change is made, allowing consumer teams to get the latest version whenever they need it.
As an exercise, see whether you can implement the OpenAPI server and call it with the generated Go client. You may find the examples from oapi-gen useful—you can find them here: https://github.com/deepmap/oapi-codegen/tree/master/examples.
OpenAPI is a great option for your published language if you and your team are already familiar with REST APIs. OpenAPI is documentation-first, which means your external-facing documentation is always kept up to date, which is a huge advantage. The code generation means you can support many different use cases with no extra effort.
The downside to OpenAPI is that there are more performant alternatives out there. Furthermore, OpenAPI does not give any protection for breaking changes natively. For example, if you removed a field from your documentation, but another team depended on it, you would likely break their workflow.
An alternative, modern approach that solves some of these issues and adds some more features is gRPC.
gRPC
gRPC was created at Google to handle remote communication at scale. It supports load balancing, tracing, health checks, bi-directional streaming, and authentication. Usually, these are features you needed to provision other software services or even hardware for in the past.
Furthermore, gRPC uses binary serialization to compress the payload it sends, making it very efficient and fast. In gRPC, a client application can call a method on a remote server as if it were local code. gRPC supports a variety of different languages and frameworks, such as OpenAPI.
Here is a visual example of how a gRPC client and server may interact:
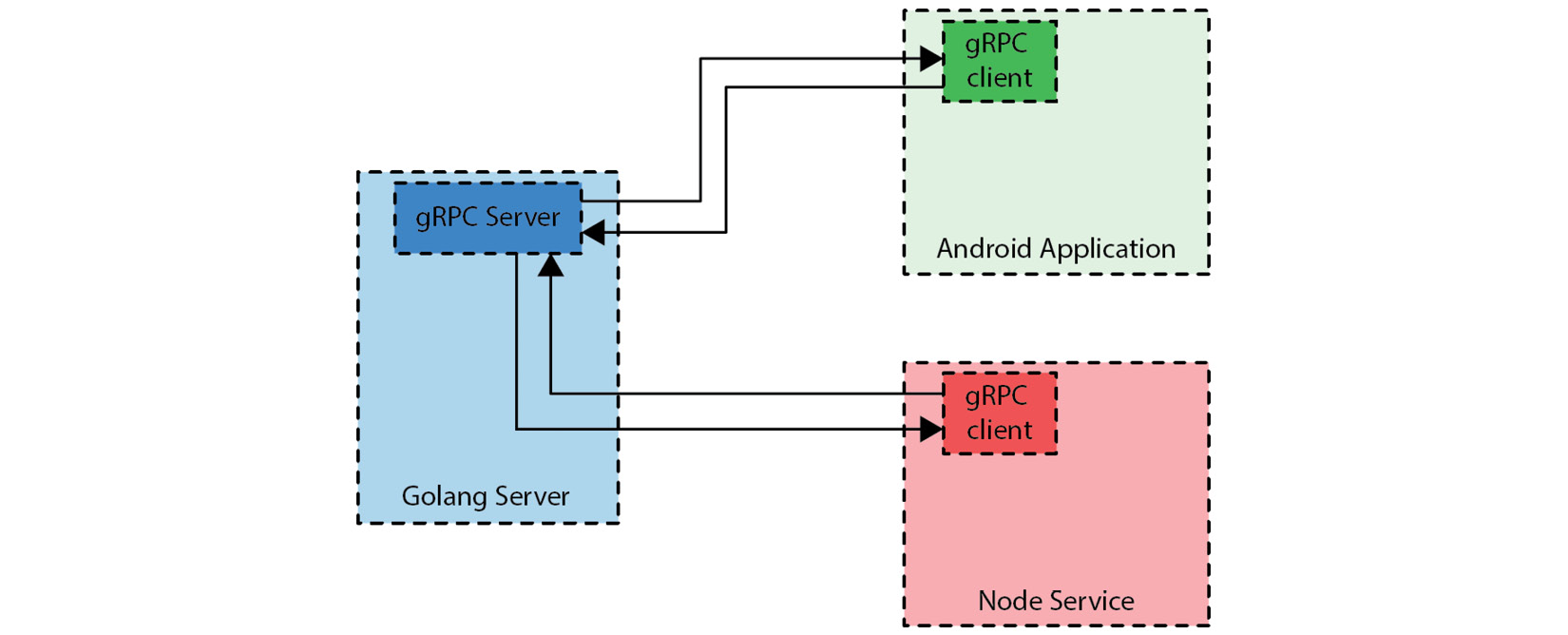
Figure 2.8 – gRPC clients in Node and Kotlin connecting to a gRPC server written in Golang
To call a method on a remote server, firstly, we must define our message protobuf. Protobufs are typically defined in a .proto file, and they are language-agnostic. A basic (incomplete) example might look like this:
message User {
int64 id = 1;
string username = 2;
string email = 3;
}From here, we need to define our service. This is effectively our request and response objects:
// The User service definition.
service UserService {
// Create a User
rpc CreateUser (CreateUserRequest) returns (CreateUserResponse) {}
}
// The request message contains all the things we need to create a user.
message CreateUserRequest {
User user = 1;
}
// The response message contains whether we were successful or not
message CreateUserResponse {
bool success = 1;
}From here, we can generate client and server code, as described earlier.
At the time of writing, gRPC supports the following natively:
- C#
- C++
- Dart
- Golang
- Java
- Kotlin
- Node
- Objective-C
- PHP
- Python
- Ruby
. . . but there are community-built generators for other languages.
gRPC is more complicated to start with than OpenAPI, mostly because developers have generally had more experience with REST-based APIs. Furthermore, some of the tools needed to generate code can be quite complicated to install and get working. Let’s see what that looks like in Go.
gRPC for Go using buf
We are going to use buf (https://buf.build) to generate our Go client and server as I have found it by far the most accessible way to interact with protobuf.
First, let’s install some of the underlying protobuf tools we will need with the following commands:
go install google.golang.org/protobuf/cmd/protoc-gen-go@latest go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest
You also need to update your path with the following command:
export PATH="$PATH:$(go env GOPATH)/bin"
Next, let’s make a file called buf.gen.yml. It looks like this:
version: v1 plugins: - name: go out: gen/proto/go opt: paths=source_relative - name: go-grpc out: gen/proto/go opt: - paths=source_relative - require_unimplemented_servers=false
You can also find the code for this here: https://github.com/PacktPublishing/Domain-Driven-Design-with-GoLang/tree/main/chapter2/grpc. The preceding code simply says we want to generate Go from our protobuf definition. You can add C, Java, and other languages here too.
Let’s now install buf:
brew install bufbuild/buf/buf
To verify everything is running correctly, if you run buf lint from chapter2/grpc, you should see the following output:
user.proto:1:1:Files must have a package defined.
Let’s fix this by adding a package to the top of the file:
syntax = "proto3";
package user.v1;
message User {
int64 id = 1;
string username = 2;
string email = 3;
}
// The User service definition.
service UserService {
// Create a User
rpc CreateUser (CreateUserRequest) returns (CreateUserResponse) {}
}
// The request message contains all the things we need to create a user.
message CreateUserRequest {
User user = 1;
}
// The response message contains whether we were successful or not
message CreateUserResponse {
bool success = 1;
}If you rerun the buf lint command, you should now see no output.
Now, we can run the following command to generate our gRPC client and server:
buf generate
We now experience what will be our final error:
protoc-gen-go: unable to determine Go import path for "user/v1/user.proto" Please specify either: • a "go_package" option in the .proto source file, or • a "M" argument on the command line. See https://developers.google.com/protocol-buffers/docs/reference/go-generated#package for more information. Failure: plugin go: exit status 1
The protobuf tooling comes with lots of opinions and support to ensure best practices. Let’s add a package name for our protobuf file, making the final file look like this:
syntax = "proto3";
package user.v1;
option go_package = "example.com/testing/protos/user";
message User {
int64 id = 1;
string username = 2;
string email = 3;
}
// The User service definition.
service UserService {
// Create a User
rpc CreateUser (CreateUserRequest) returns (CreateUserResponse) {}
}
// The request message contains all the things we need to create a user.
message CreateUserRequest {
User user = 1;
}
// The response message contains whether we were successful or not
message CreateUserResponse {
bool success = 1;
}If we run buf generate one final time, we will see that a gen folder has been created for us with importable Go code:
Figure 2.9 – gen folder
As an exercise, see if you can implement the gRPC client and server. The buf docs give guidance on how you might do that here: https://docs.buf.build/tour/implement-grpc-endpoints.
Which should you choose?
Either! You will have great results with either approach. Due to gRPC’s speed and extra features, it is becoming more popular. However, OpenAPI can be easier to retrofit to already existing APIs and is easier to understand.
Anti-corruption layer
Sometimes called an adapter layer, an anti-corruption layer can be used to translate models from different systems. It is a complementary pattern that works well with the Open Host Service. For example, the marketing team’s published language may define a campaign as follows:
{
"id":"4cdd4ba9-7c04-4a3d-ac52-71f37ba75d7f",
"metadata":{
"name":"some campaign",
"category":"growth",
"endDate":"2023-04-12"
}
}However, our internal model for a campaign might look like this:
type Campaign struct {
id string
title string
goal string
endDate time.Time
}As you can see, we care about most of the same information, but we name it differently or have a slightly different format. We have two options here:
- We can swap our campaign model to be exactly the same as the marketing model. This would go against the principles of DDD and mean we are strongly coupling the domain model to something outside of our control.
- We can write an anti-corruption layer.
An anti-corruption later would look like this:
package chapter2
import (
"errors"
"time"
)
type Campaign struct {
ID string
Title string
Goal string
EndDate time.Time
}
type MarketingCampaignModel struct {
Id string `json:"id"`
Metadata struct {
Name string `json:"name"`
Category string `json:"category"`
EndDate string `json:"endDate"`
} `json:"metadata"`
}
func (m *MarketingCampaignModel) ToCampaign() (*Campaign, error) {
if m.Id == "" {
return nil, errors.New("campaign ID cannot be empty")
}
formattedDate, err := time.Parse("2006-01-02", m.Metadata.EndDate)
if err != nil {
return nil, errors.New("endDate was not in a parsable format")
}
return &Campaign{
ID: m.Id,
Title: m.Metadata.Name,
Goal: m.Metadata.Category,
EndDate: formattedDate,
}, nil
}In this short snippet, we translated a MarketingCampaignModel into a Campaign in our domain. We included some checks to ensure the format of the data we receive is acceptable and won’t corrupt our data model. It’s worth noting that in more complex systems, anti-corruption layers could be entire services. This can be useful when you intend to migrate from an old system to a new system in multiple stages. However, it adds another point of latency and failure. The following diagram provides an example of an anti-corruption layer:
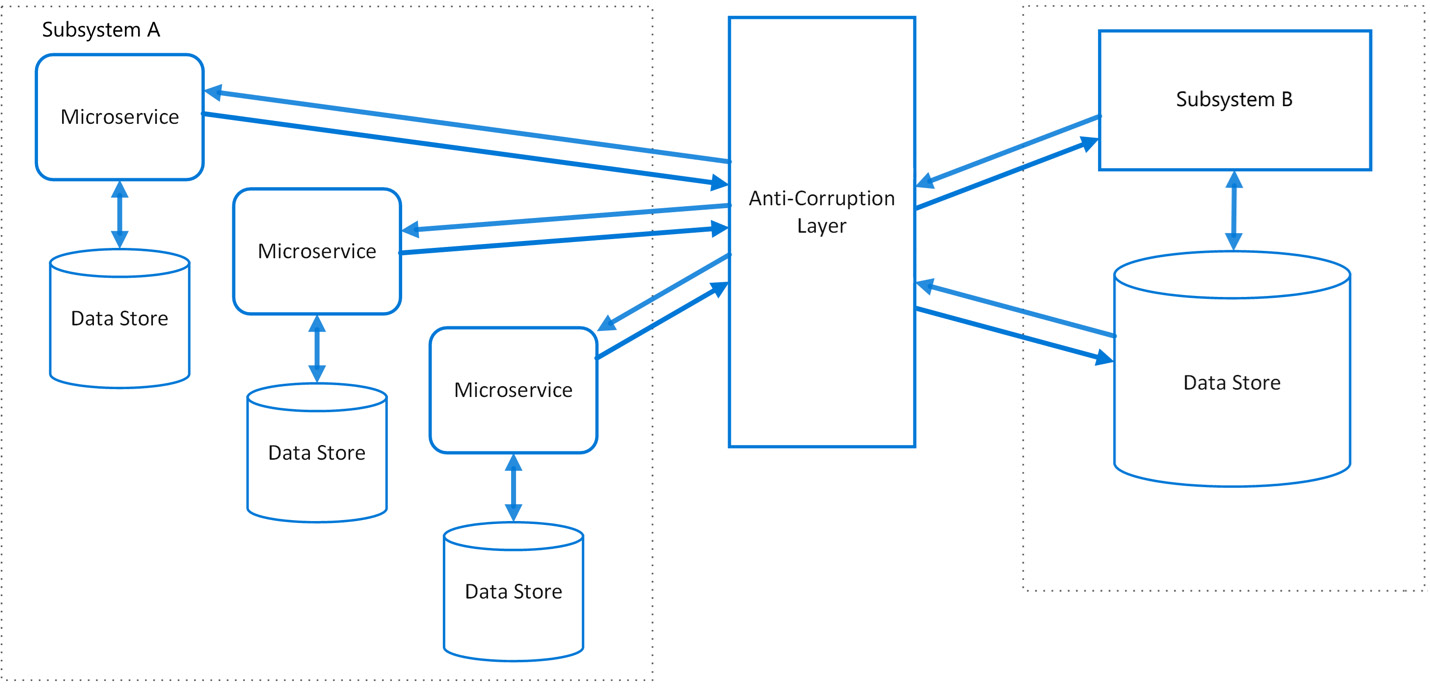
Figure 2.10 – Anti-corruption layer in a distributed system
Of all the DDD patterns, the anti-corruption pattern is the one I use most when working on systems that do not use DDD. It’s simple but very effective for ensuring we keep systems decoupled.
Summary
In this chapter, we have learned about domains, sub-domains, ubiquitous language, and bounded contexts. These are all core components of DDD.
We explored some domain-driven Go code for the first time and saw how even minor changes could improve the readability of our code and make it align more with the domain we are developing software for.
We also learned about some new patterns—Open Host Service, published language, and anti-corruption layers. Finally, we explored some tools (OpenAPI and gRPC) we can use to make publishing language easier.
In the next chapter, Aggregates, Entities, and Value Objects, we will explore more DDD terminology and learn how these concepts can help make our domain-driven code more robust and scalable.
Further reading
- OpenAPI: https://github.com/OAI/OpenAPI-Specification
- Swagger: https://swagger.io
- gRPC: https://grpc.io