
3
The Go Memory Model
The Go memory model specifies when memory write operations become visible to other goroutines and, more importantly, when these visibility guarantees do not exist. As developers, we can skip over the details of the memory model by following a few guidelines when developing concurrent programs. Regardless, as mentioned before, obvious bugs are caught easily in QA, and bugs that happen in production usually cannot be reproduced in the development environment, and you may be forced to analyze the program behavior by reading code. A good knowledge of the memory model is helpful when this happens.
In this chapter, we will discuss the following:
- Why a memory model is necessary
- The happened-before relationship between memory operations
- Synchronization characteristics of Go concurrency primitives
Why a memory model is necessary
In 1965, Gordon Moore observed that the number of transistors in dense integrated circuits double every year. Later, in 1975, this was adjusted to doubling every 2 years. Because of these advancements, it quickly became possible to squeeze lots of components into a tiny chip, enabling the building of faster processors.
Modern processors use many advanced techniques, such as caching, branch prediction, and pipelining, to utilize the circuitry on a CPU to its maximum potential. However, in the 2000s, hardware engineers started to hit the limit of what could be optimized on a single chip. As a result, they created chips containing multiple cores. Nowadays, most performance considerations are about how fast a single core can execute instructions, as well as how many cores can run those instructions simultaneously.
The compiler technology did not stand still while these improvements were happening. Modern compilers can aggressively optimize programs to such an extent that the compiled code is unrecognizable. In other words, the order and the manner in which a program is executed may be very different from the way its statements are written. These reorganizations do not affect the behavior of a sequential program, but they may have unintended consequences when multiple threads are involved.
As a general rule, optimizations must not change the behavior of valid programs – but how can we define what a valid program is? The answer is a memory model. A memory model defines what a valid program is, what the compiler builders must ensure, and what programmers can expect.
In other words, a memory model is the compiler builder’s answer to the hardware builder. As developers, we have to understand this answer so that we can create valid programs that run the same way on different platforms.
The Go memory model document starts with a rule of thumb for valid programs: programs that modify data being simultaneously accessed by multiple goroutines must serialize such access. It is as simple as that – but why is this so hard? The main reason comes down to figuring out when the effects of program statements can be observed at runtime, and the limits of an individual’s cognitive capability: you simply cannot analyze all the possible orderings of a concurrent program. Familiarity with the memory model helps pinpoint problems in concurrent programs based on its observed behavior.
The Go memory model famously includes this phrase:
If you must read the rest of this document [i.e. the Go memory model] to understand the behavior of your program, you are being too clever.
Don’t be clever.
I read this phrase as do not write programs that rely on the intricacies of the Go memory model. You should read and understand the Go memory model. It tells you what to expect from the runtime, and what not to do. If more people read it, there would be fewer questions related to Go concurrency on StackOverflow.
The happened-before relationship between memory operations
It all comes down to how memory operations are ordered at runtime, and how the runtime guarantees when the effects of those memory operations are observable. To explain the Go memory model, we need to define three relationships that define different orderings of memory operations.
In any goroutine, the ordering of memory operations must correspond to the correct sequential execution of that goroutine as determined by the control flow statements and expression evaluation order. This ordering is the sequenced-before relationship. This, however, does not mean that the compiler has to execute a program in the order it is written. The compiler can rearrange the execution order of statements as long as a memory read operation of a variable reads the last value written to that variable.
Let’s refer to the following program:
1: x=1 2: y=2 3: z=x 4: y++ 5: w=y
The z variable will always be set to 1, and the w variable will always be set to 3. Lines 1 and 2 are memory write operations. Line 3 reads x and writes z. Line 4 reads y and writes y. Line 5 reads y and writes w. That is obvious. One thing that may not be obvious is that the compiler can rearrange this code in such a way that all memory read operations read the latest written value, as follows:
1: x=1 2: z=x 3: y=2 4: y++ 5: w=y
In these programs, every line is sequenced before the line that comes after it. The sequenced-before relationship is about the runtime order of statements and takes into account the control flow of the program. For instance, see the following:
1: y=0
2: for i:=0;i<2;i++ {
3: y++
4: }In this program, if y is 1 at the beginning of the statement at line 3, then the i++ statement that ran when i=0 is sequenced before line 3.
These are all ordinary memory operations. There are also synchronizing memory operations, which are defined as follows:
- Synchronizing read operations: Mutex lock, channel receive, atomic read, and atomic compare-and-swap operations
- Synchronizing write operations: Mutex unlock, channel send and channel close, atomic write, and atomic compare-and-swap operations
Note that atomic compare-and-swap is both a synchronizing read and a synchronizing write.
Ordinary memory operations are used to define the sequenced-before relationship within a single goroutine. Synchronizing memory operations can be used to define the synchronized-before relationship when multiple goroutines are involved. That is: if a synchronizing memory read operation of a variable observes the last synchronized write operation to that variable, then that synchronized write operation is synchronized before the synchronized read operation.
The happened-before relationship is a combination of a synchronized-before and sequenced-before relationships as follows:
- If a memory write operation, w, is synchronized before a memory read operation, r, then w happened before r
- If a memory write operation, x, is sequenced before w, and a memory read operation, y, is sequenced after r, then x happened before y
This is illustrated in Figure 3.1 for the following program:
go func() {
x = 1
ch <- 1
}()
go func() {
<-ch
fmt.Println(x)
}()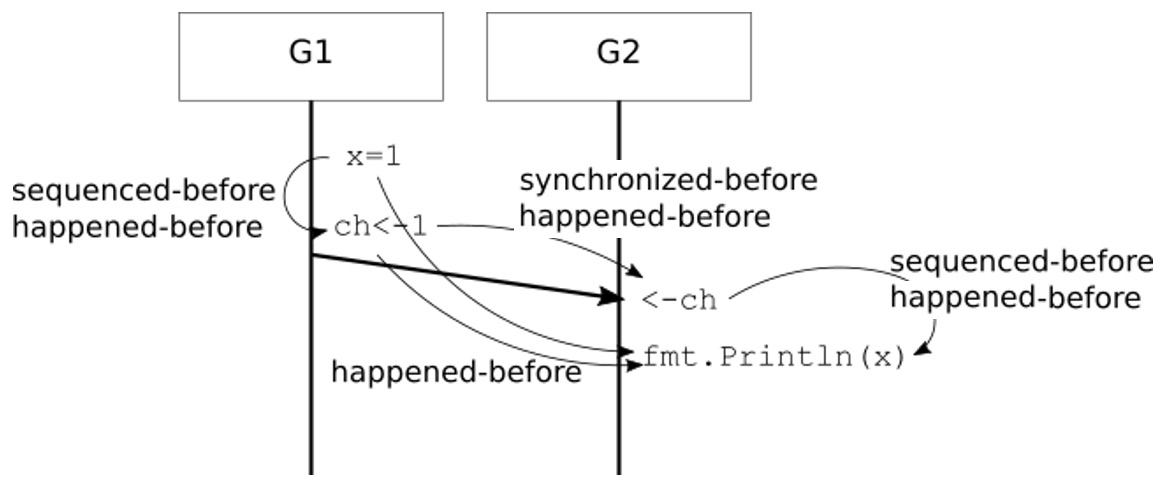
Figure 3.1 – Sequenced-before, synchronized-before, happened-before
The following modification, however, has a data race. After the first goroutine sends 1 to the channel and the second one receives it, x++ and fmt.Println(x) are concurrent:
go func() {
for {
x ++
ch <- 1
}
}()
go func() {
for range ch {
fmt.Println(x)
}
}()The happened-before relationship is important because a memory-read operation is guaranteed to see the effects of memory-write operations that happened before it. If you suspect that a race condition exists, establishing which operations happened before others can help pinpoint any problems.
The rule of thumb is that if a memory-write operation happens before a memory-read operation, it cannot be concurrent, and thus, it cannot cause a data race. If you cannot establish a happened-before relationship between a write operation and a read operation, they are concurrent.
Synchronization characteristics of Go concurrency primitives
Having defined a happened-before relationship, it is easy to lay the ground rules for the Go memory model.
Package initialization
If package A imports another package, B, then the completion of all init() functions in package B happens before the init() functions in package A begin.
The following program always prints B initializing before A initializing:
package B
import "fmt"
func init() {
fmt.Println("B initializing")
}
---
package A
import (
"fmt"
"B"
)
func init() {
fmt.Println("A initializing")
}This extends to the main package as well: all packages directly or indirectly imported by the main package of a program complete their init() functions before main() starts. If an init() function creates a goroutine, there is no guarantee that the goroutine will finish before main() starts running. Those goroutines run concurrently.
Goroutines
If a program starts a goroutine, the go statement is synchronized before (and thus happens before) the start of the goroutine’s execution. The following program will always print Before goroutine because the assignment to a happens before the goroutine starts running:
a := "Before goroutine"
go func() { fmt.Println(a) }()
select {}The termination of a goroutine is not synchronized with any event in the program. The following program may print 0 or 1. There is a data race:
var x int
go func() { x = 1 }()
fmt.Println(x)
select {}In other words, a goroutine sees all the updates before it starts, and a goroutine cannot say anything about the termination of another goroutine unless there is explicit communication with it.
Channels
A send or close operation on an unbuffered channel is synchronized before (and thus happens before) the completion of a receive from that channel. A receive operation on an unbuffered channel is synchronized before (and thus happens before) the completion of a corresponding send operation on that channel. In other words, if a goroutine sends a value through an unbuffered channel, the receiving goroutine will complete the reception of that value, and then the sending goroutine will finish sending that value. The following program always prints 1:
var x int
ch := make(chan int)
go func() {
<-ch
fmt.Println(x)
}()
x = 1
ch <- 0
select {}In this program, the write to x is sequenced before the channel write, which is synchronized before the channel read. The printing is sequenced after the channel read, so the write to x happens before the printing of x.
The following program also prints 1:
var x int
ch := make(chan int)
go func() {
ch <- 0
fmt.Println(x)
}()
x = 1
<- ch
select {}How can this guarantee be extended to buffered channels? If a channel has a capacity of C, then multiple goroutines can send C items before a single receive operation completes. In fact, the nth channel receive is synchronized before the completion of n + Cth send on that channel.
This is illustrated in Figure 3.2 for a channel with a capacity of 2.
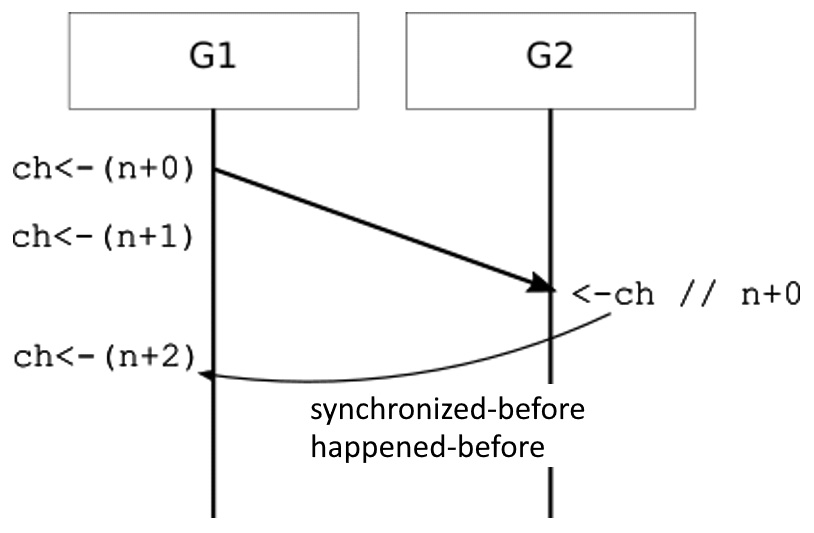
Figure 3.2 – Happened-before guarantees for buffered channels (capacity = 2)
This program creates 10 worker goroutines that share a resource with 5 instances. All 10 workers process jobs from the queue, but, at most, 5 of them can be working with the resource at any given time:
resources := make(chan struct{}, 5)
jobs := make(chan Work)
for worker := 0; worker < 10; worker++ {
go func() {
for work := range <-jobs {
// Do work
// Acquire resource
resources <- struct{}{}
// Work with resource
<-resources
}
}()
}In short, after a channel receive, the receiving goroutine sees all the updates before the corresponding send, and after a channel send, the sending goroutine sees all the operations before the corresponding receive.
Mutexes
Suppose two goroutines, G1 and G2, attempt to enter their critical sections by locking a shared mutex. Also, suppose that G1 locks the mutex (the first call to Lock()), and G2 is blocked. When G1 unlocks the mutex (the first call to Unlock()), G2 locks it (the second call to Lock()). Unlocking G1 is synchronized before (and thus, happens before) G2 is locked. As a result, G2 can see the effects of memory write operations G1 has made during its critical section.
In general, for a mutex, M, the nth call of M.Unlock() is synchronized before (and thus happens before) the (n + i)th M.Lock() returns when i > 0:
func main() {
var m sync.Mutex
var a int
// Lock mutex in main goroutine
m.Lock()
done := make(chan struct{})
// G1
go func() {
// This will block until G2 unlocks mutex
m.Lock()
// a=1 happened-before, so this prints 1
fmt.Println(a)
m.Unlock()
close(done)
}()
// G2
go func() {
a = 1
// G1 will block until this runs
m.Unlock()
}()
<-done
}This program will always print 1, even if the first goroutine runs first.
To summarize: if a mutex lock succeeds, everything happened before the corresponding unlock is visible.
Atomic memory operations
The sync/atomic package provides low-level atomic memory read and memory write operations. If the effect of an atomic write operation is observed by an atomic read operation, then the atomic write operation is synchronized before that atomic read operation.
The following program always prints 1. This is because the print statement in the if block will only run after the atomic store operation completes:
func main() {
var i int
var v atomic.Value
go func() {
// This goroutine will eventually store 1 in v
i = 1
v.Store(1)
}()
go func() {
// busy-waiting
for {
// This will keep checking until v has 1
if val, _ := v.Load().(int); val == 1 {
fmt.Println(i)
return
}
}
}()
select {}
}Map, Once, and WaitGroup
These are higher-level synchronization utilities that can be modeled by the operations explained previously. sync.Map provides a thread-safe map implementation that you can use without an additional mutex. This map implementation can outperform the built-in map coupled with a mutex if elements are written once but read many times, or if multiple goroutines work with disjointed sets of keys. For these use cases, sync.Map offers better concurrent use, but without the type safety of the built-in maps. Caches are good use cases for sync.Map, and an example of a simple cache is illustrated here.
For sync.Map, write operations happen before a read operation that observes the effects of that write.
sync.Once provides a convenient way of initializing something in the presence of multiple goroutines. The initialization is performed by a function passed to sync.Once.Do(). When multiple goroutines call sync.Once.Do(), one of the goroutines performs the initialization while the other goroutines block. After the initialization is complete, sync.Once.Do() no longer calls the initialization function, and it does not incur any significant overhead.
The Go memory model guarantees that if one of the goroutines results in the running of the initialization function, the completion of that function happens before the return of sync.Once() for all other goroutines.
The following is a cache implementation that uses sync.Map as a cache and uses sync.Once to ensure element initialization. Each cached data element contains a sync.Once instance, which is used to block other goroutines attempting to load the element with the same ID until initialization is complete:
type Cache struct {
values sync.Map
}
type cachedValue struct {
sync.Once
value *Data
}
func (c *Cache) Get(id string) *Data {
// Get the cached value, or store an empty value
v, _:=c.values.LoadOrStore(id,&cachedValue{})
cv := v.(*cachedValue)
// If not initialized, initialize here
cv.Do(func() {
cv.value=loadData(id)
})
return cv.value
}For WaitGroup, a call to Done() synchronizes before (and thus happens before) the return of the Wait() call that it unblocks. The following program always prints 1:
func main() {
var i int
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
i = 1
wg.Done()
}()
wg.Wait()
// If we are here, wg.Done is called, so i=1
fmt.Println(i)
}Let’s summarize:
- Read operations of sync.Map return the last written value
- If many goroutines call sync.Once, only one will run the initialization and the other will wait, and once the initialization is complete, its effects will be visible to all waiting goroutines
- For WaitGroup, when Wait returns, all Done calls are completed
Summary
If you always serialize access to variables that are shared between multiple goroutines, you don’t need to know all the details of the Go memory model. However, as you read, write, analyze, and profile concurrent code, the Go memory model can provide the insight that guides you to create safe and efficient programs.
Next, we will start working on some interesting concurrent algorithms.
Further reading
- The Go Memory Model: https://go.dev/ref/mem
- Go’s Memory Model, a presentation by Russ Cox, February 25, 2016: http://nil.csail.mit.edu/6.824/2016/notes/gomem.pdf