
8
Handling Requests Concurrently
Server programming is a rather large topic. This chapter will mainly focus on some of the concurrency-related aspects of server programming and, in an abstract sense, request handling in general. At the end of the day, almost all programs are written to handle particular requests. For a server application, defining and propagating a request context is very important, so we start the chapter by talking about the context package. Next, we will look at some simple servers to explore how requests can be handled concurrently, and discuss some methods to deal with a few basic problems of server development. The last part of the chapter is on streaming data, where data elements are generated piecemeal, which poses unique challenges to demonstrate some interesting concurrency patterns.
This chapter includes the following sections:
- The context, cancelations, and timeouts
- Backend services
- Streaming data
By the end of this chapter, you should have a good understanding of request contexts, how you can cancel or timeout requests, building blocks of server programming, ways to limit concurrency, and how to deal with data that is generated piecemeal.
Technical Requirements
The source code for this particular chapter is available on GitHub at https://github.com/PacktPublishing/Effective-Concurrency-in-Go/tree/main/chapter8.
The context, cancelations, and timeouts
In Chapter 2, we showed that closing a channel shared between multiple goroutines is a good way to signal cancelation. Cancelations may happen in different ways: a failure in a part of the computation may invalidate the entire result, the computation may last so long that it times out, or the requester notifies the server application that it is no longer interested in the result by closing the network connection. So, it makes sense to pass a channel to the functions that are called to handle a request. But you have to be careful: you can close a channel only once. Closing a closed channel will panic. Here, the term “request” should be taken in an abstract sense: it can be an API request submitted to a server, or it can simply be a function call to handle a particular piece of a larger computation.
It also makes sense to let the functions in the call chain know about certain data related to the request. For example, in a concurrent system with many goroutines, it is important to correlate log messages with requests, so the fulfillment of a request can be traced across different goroutines. A unique request identifier is a common way of achieving this. To accommodate this, all the functions that are called by those services should know about this request identifier.
A context.Context is an object that deals with these two common issues. It includes the Done channel we talked about for cancelations, and it behaves like a generic key-value store. A Context is specifically designed to be used as a request-scoped object. It is a good place to store request identifiers, caller identity and privilege information, a request-specific logger, and so on.
A common mistake for those who are familiar with other languages is to treat context as a thread-local storage. Context is not a replacement for thread-local variables; they are meant to be shared among goroutines handling a request. Context instances cannot cross process boundaries; for example, when you call an HTTP API, the server request handler starts with a brand-new context that has no relation to the client context used to make that call. It should be passed as the first argument for the functions that need it. Following these conventions will make it easier to understand the code for the readers and allow static code analyzers to produce more sensible reports.
Creation and preparation of a context is usually the first order of business when handling a request. Create a new context using the following:
ctx := context.Background()
This will create an empty context with no cancelation or timeout. The Done channel of the context will be nil, thus it is not cancelable.
You work with a context by adding features to it (ever heard of the “decorator pattern”?). When you add a cancelation or timeout feature to a context, you get a new context that wraps the original context you passed in:
ctx1, cancel1 := context.WithCancel(ctx0)
Here, ctx1 is a new context that refers to the original context, ctx0, but with an added cancelation feature. You pass ctx1 to the functions and goroutines that support canceling by checking the ctx1.Done() channel. When you call the cancel1 function, it will close the ctx1.Done() channel, so all goroutines and functions checking for the ctx1.Done() channel will receive that cancelation request. You can call a cancelation function many times; the underlying channel will be closed only the first time you call it. If the original context, ctx0, already had a cancelation feature added to it, it will not be affected by the cancelation of ctx1. However, ctx1 will be canceled if ctx0 is canceled. If other cancelable contexts are created based on ctx1, those contexts will be canceled whenever ctx1 is canceled, but ctx1 will not know about the cancelations of those nested contexts. The proper use of the cancelation feature is as follows:
1: func someFunc(ctx context.Context) error {
2: ctx1, cancel1 := context.WithCancel(ctx)
3: defer cancel1()
4: wg:=sync.WaitGroup{}
5: wg.Add(1)
6: go func() {
7: defer wg.Done()
8: process2(ctx1)
9: }()
10: if err:=process1(ctx1); err!=nil {
11: cancel1()
12: return err
13: }
14: wg.Wait()
15: return nil
16: }This function calls two separate functions, process1 and process2, to perform some computation. The process2 function is called in a separate goroutine. If process1 fails, we want to cancel process2. To do this, we create a cancelable context (line 2) and make sure that this new context is canceled when this function returns (line 3). This is necessary to prevent goroutine leaks because, as you may guess, additional goroutines are necessary to implement such cascading cancelation. The call to cancel a function ensures those goroutines are terminated.
This situation is illustrated in Figure 8.1. ctx0 is the initial context, with a nil Done channel. ctx1 is a cancelable context created from ctx0, thus cancel1 is a closure that closes the done channel for ctx1. There is no need for an additional goroutine as the parent context was not cancelable. ctx2 is another cancelable context created based on ctx1, so it has its own done channel, with a closure to close that done channel. It also has a goroutine that waits for either the parent done channel or the ctx2 done channel to close. If the parent done channel is closed, it cancels ctx2, and all contexts created based on ctx2. If ctx2 is canceled, the goroutine simply terminates. That’s the reason why you must call the cancel function: if the context is never canceled, the goroutine leaks.
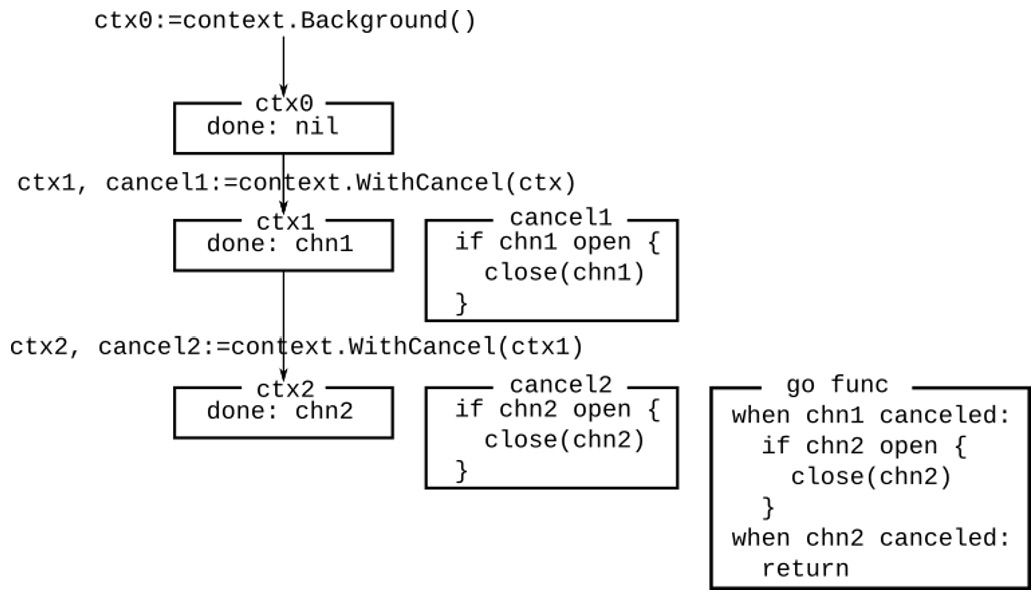
Figure 8.1 – Nested contexts and cancelation
As a side note, Figure 8.1 gives a conceptual overview of the cancelation feature. But how can you check whether a channel is open? The actual cancel function in the standard library has quite an elaborate implementation that also includes functionality to cancel child contexts. A simple cancel function that can be called multiple times can be implemented as follows:
func GetCancelFunc() (cancel func(), done chan struct{}) {
var once sync.Once
done = make(chan struct{})
cancel = func() {
once.Do(func() { close(done) })
}
return
}Context timeouts and deadlines work the same way. The only difference with a cancelable context is that a context with a deadline or timeout has a timer that will call the cancel function once the deadline passes. A timeout works with a duration:
ctx2, cancel := context.WithTimeout(ctx,2*time.Second) defer cancel()
A deadline works with a time:
d := time.Now().Add(2*time.Second) ctx2, cancel := context.WithDeadline(ctx, d) defer cancel()
When a context is canceled, the Err() method will be set to a context.Canceled error. When a context times out, the Err() method will return a context.DeadlineExceeded error.
Contexts also offer a mechanism to store request-specific values. However, you should not treat this mechanism as a generic map[any]any storage. As I mentioned before, contexts are implemented using a decorator pattern. Every new addition to a context creates a new context with that addition while leaving the old one intact. This is also true for the values stored in a context. If you add a value to a context, you will get a new context that has that value. When you query a context for a value (ctx.Value(key)) and the key does not match what ctx has, it will call its parent to search for that value, and the call will continue recursively until the key is found. This means two things: first, you can override an existing value in a new context. The users of the new context will see the new value, whereas the users of the old context will see the unmodified value. Second, if you add hundreds of values to a context, you’ll get a chain of hundreds of contexts. So, be mindful about what and how much you put into a context. If you need to add a lot of values, add a single structure with many values.
In a simple program, there is nothing wrong with using strings as keys for context values. However, this is open to misuse and can cause very hard-to-diagnose subtle bugs if multiple packages use the same name to add values that mean different things. Because of this, the idiomatic way to deal with values in a context is by using the Go type system to prevent unintentional key collisions – that is, use a different type for each key. The following example illustrates adding a request identifier to the context:
1: type requestIDKeyType int
2: var requestIDKey requestIDKeyType
3:
4: func WithRequestID(ctx context.Context) context.Context {
5: return context.WithValue(ctx, requestIDKey,
uuid.New())
6: }
7:
8: func GetRequestID(ctx context.Context) uuid.UUID {
9: id, _ := ctx.Value(requestIDKey).(uuid.UUID)
10: return id
11: }Line 1 defines an unexported data type, and line 2 defines a context key using this data type. This type of declaration ensures that nobody can create the same key unintentionally in a different package. Line 4 defines the WithRequestID function that returns a new context with added request identifier. Line 8 defines the GetRequestID function that extracts the request identifier from the context. If the context does not have a request identifier, it will return the zero value for UUID (which is a byte array of zeros). Based on this, can you guess what the following program will print?
ctx := context.Background() ctx1 := WithRequestID(ctx) ctx2 := WithRequestID(ctx1) fmt.Println(GetRequestID(ctx), GetRequestID(ctx1), GetRequestID(ctx2))
It will actually print a different output every time you run it. However, the first output will always be 00000000-0000-0000-0000-000000000000 (the zero value for UUID), the second value will be the request identifier in ctx1, and the third value will be the request identifier in ctx2. Note that adding another request identifier to the context does not overwrite the request identifier for ctx1.
A common question is: what values should be put in a Context? The guiding principle is whether or not the value is request-specific rather than the nature of the value itself. If you have a database connection that is shared among all request handers, that does not belong in the context. However, if you have a system that may connect to a different database based on the caller’s credentials, then it may make sense to put that database connection into the context. An application configuration structure does not belong in the context. If you load a configuration item from a database based on the request, it may make sense to put that into the context.
A context object is meant to be passed into multiple goroutines, which means you have to be careful about race conditions involving context values. Consider the following context:
newCtx:=context.WithValue(ctx,mapKey,map[string]interface{"key":"value"})If newCtx is passed to multiple goroutines, the map in that context becomes a shared variable. Multiple goroutines adding/removing values to/from that map will cause race conditions and probably corrupt memory. A correct way of dealing with this problem is using a structure:
type StructWithMap struct {
sync.Mutex
M map[string]interface{}
}
...
newCtx:=context.WithValue(ctx,mapKey,&StructWithMap{
M:make(map[string]interface{}),
}In this example, a pointer to a structure with a mutex and map is put into the context. Goroutines will have to lock the mutex to access the map. Also, note that a mutex must not be copied, so the address of the structure is put into the context.
Backend services
If you are using Go, it is likely that you have written or will write a backend service of some sort. Service development comes with a unique set of challenges. First, the concurrency aspect of request handling is usually hidden under a service framework, which causes unintentional memory sharing and data races. Second, not all clients of the service have good intentions (attacks) or are free of bugs. In this section, we will look at some basic constructs using HTTP and web socket services. But before those, knowing a bit about TCP networking helps because many higher-level protocols like HTTP and web sockets are based on TCP. Next, we will construct a simple TCP server that handles requests concurrently and shuts down gracefully. For this, we need a listener, a request handler, and a wait group:
type TCPServer struct {
Listener net.Listener
HandlerFunc func(context.Context,net.Conn)
wg sync.WaitGroup
}The server provides a Listen method that waits for connections. It starts by creating a cancelable context. This context will be canceled when the Listen method returns, notifying all active connection handlers about the cancelation. When a connection is established, the method creates a new goroutine to handle the connection and continues listening:
func (srv *TCPServer) Listen() error {
baseContext, cancel :=
context.WithCancel(context.Background())
defer cancel()
for {
conn, err := srv.Listener.Accept()
if err != nil {
if errors.Is(err, net.ErrClosed) {
return nil
}
fmt.Println(err)
}
srv.wg.Add(1)
go func() {
defer srv.wg.Done()
srv.HandlerFunc(baseContext, conn)
}()
}
}As you may notice, the Listen method will not return until the Accept call fails. Once started, the server can be stopped from another goroutine by closing the listener:
func (srv *TCPServer) StopListener() error {
return srv.Listener.Close()
}Closing the listener will cause the Accept call to fail, and the Listen method will stop listening, cancel the context, and return. Canceling the context will notify all active connections that the server is shutting down, but it is unreasonable to expect them to stop processing immediately. We have to give some time to these handlers to finish, using a WaitForConnections method with a timeout:
func (srv *TCPServer) WaitForConnections(timeout time.Duration) {
toCh := time.After(timeout)
doneCh := make(chan struct{})
go func() {
srv.wg.Wait()
close(doneCh)
}()
select {
case <-toCh:
case <-doneCh:
}
}This is where WaitGroup is useful. If there are no active connections, srv.wg.Wait() will immediately return, closing doneCh, which will cause the WaitForConnections method to return. If there are active connections, we will wait for them in a separate goroutine, and if they all complete before the timeout, doneCh will be closed and the method will return. However, if there are connections that do not comply with the stop request within the given timeout, the method will still return, leaving those connections active. An option to deal with this is to close those active connections, but that may result in unexpected behavior. So, it will be up to you to decide the best course of action in this situation.
Containerized backend services can handle termination signals for a graceful shutdown. This has to be done before any of the servers start listening. The following code snippet will set up a signal handle to listen to termination signals, and will give the server 5 seconds to shutdown:
sig := make(chan os.Signal, 1)
signal.Notify(sig, syscall.SIGTERM, syscall.SIGINT)
go func() {
<-sig
srv.StopListener()
srv.WaitForConnections(5 * time.Second)
}()The following is a simple echo server using these utilities:
srv.Listener, err = net.Listen("tcp", "")
if err != nil {
panic(err)
}
srv.HandlerFunc = func(ctx context.Context, conn net.Conn) {
defer conn.Close()
// Echo server
io.Copy(conn, conn)
}
srv.Listen()
srv.WaitForConnections(5 * time.Second)Now let’s look at a simple HTTP service using the standard library. HTTP is a text-based protocol built on top of TCP, so the HTTP code very much looks like the TCP server. An HTTP request contains a header that tells the HTTP verb (GET, POST, etc.), the path (part of the URL after the host and the port), and HTTP headers. Usually, an HTTP server uses different handlers for different request types, and which handler to call is determined based on the request header information (HTTP verb, path, and headers). This is called request multiplexing. The Go standard library includes a basic multiplexer; there are many frameworks out there that offer different capabilities with varying performance characteristics. But when it comes to the application level where the requests are handled, there are a few key assumptions you have to keep in mind:
- Request handlers will be called concurrently.
- Requests may be received out of order. That is, the client calling the APIs in a certain order does not mean that the server will receive those calls in the same order.
- You cannot trust the caller. You must authenticate the caller for APIs that provide access to privileged resources, limit the size of data the caller can send or receive, and validate the data your API receives.
The standard library provides an http.ServeMux type that can be used as a simple request multiplexer. You can register request handlers to an instance of http.ServeMux using Handler and HandlerFunc methods. The standard library also declares a default ServeMux instance, so the http.Handler and http.HandlerFunc functions can be used to register request handlers to that particular instance. So, you can do the following:
mux := http.NewServeMux()
svc := NewDashboardService()
mux.HandleFunc("/dashboard/", svc.DashboardHandler)
http.ListenAndServe("localhost:10001", mux)What’s happening here is that we create a multiplexer, create an instance of our backend service implementation (which is a hypothetical dashboard service), register the handler for the /dashboard/ path, and start the server. The rest of the request handling happened in the DashboardHandler method. The Go type system allows passing a method for function variables, so in this case, the request handler is a method that has access to the DashBoardService implementation, so this can contain all the configuration information, database connections, clients for remote services, and so on. An important point to note here is that the request handler methods will be called concurrently, and all of them will be using the svc instance declared previously. Thus, if you need to modify anything in svc, you have to protect it with a mutex.
A common pattern supported by many multiplexers is the building of a call chain using middleware functions. A middleware in this context is a function that performs some operation on the request such as authentication or context preparation and passes it on to the next handler in the chain. The next handler can be the actual request handler or another middleware. For example, the following middleware replaces the request body with a limited reader to protect the service from large requests:
func Limit(maxSize int64, next http.HandlerFunc) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter,
req *http.Request) {
req.Body = http.MaxBytesReader(w, req.Body,
maxSize)
next(w, req)
})
}And the following middleware authenticates the caller using a given authenticator function and adds the user identifier to the context. Note that if authentication fails, the next handler is not even called:
func Authenticate(authenticator func(*http.Request) (string, error), next http.HandlerFunc) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter,
req *http.Request) {
userId, err := authenticate(req)
if err != nil {
http.Error(w, err.Error(),
http.StatusUnauthorized)
return
}
next(w, req.WithContext(WithUserID(req.Context(),
userId)))
})
}The handler registration now becomes this:
mux.HandleFunc("/dashboard/", Authenticate(authFunc,
Limit(10240, svc.DashboardHandler)))After this setup, DashboardHandler is guaranteed to receive authenticated requests that do not exceed 10 Kb in size.
Next, let’s look at the handler itself. This handler responds to a GET request by computing and returning some dashboard data, which is composed of summary information from multiple backend services. The POST request is used to set dashboard parameters for a user. So, the handler looks like this:
func (svc *DashboardService) DashboardHandler(w http.ResponseWriter, req *http.Request) {
switch req.Method {
case http.MethodGet:
dashboard := svc.GetDashboardData(req.Context(),
GetUserID(req.Context())
json.NewEncoder(w).Encode(dashboard)
case http.MethodPost:
var params DashboardParams
if err := json.NewDecoder(req.Body)
.Decode(¶ms); err != nil {
http.Error(w, err.Error(),
http.StatusBadRequest)
}
svc.SetDashboardConfig(req.Context(),
GetUserID(req.Context()), params)
default:
http.Error(w, "Unhandled request type",
http.StatusMethodNotAllowed)
}
}As you can see, this code relies on middleware for authentication and limiting request size. Let’s look at the GetDashboardData method.
Distributing work and collecting results
Our hypothetical server talks to two backend services to collect statistics. The first service returns information about the current user, and the second returns information about the account, which may include multiple users. In this example, we modeled these as some opaque backend services, but in reality, these can be other web services, microservices called via gRPC, or database calls:
type DashboardService struct {
Users UserSvc
Accounts AccountSvc
}
type DashboardData struct {
UserData UserStats
AccountData AccountStats
LastTransactions[]Transaction
}The actual handler illustrates several methods of distributing work to multiple goroutines and collecting results from them:
func (svc *DashboardService) GetDashboardData(ctx context.Context, userID string) DashboardData {
result := DashboardData{}
wg := sync.WaitGroup{}- The first goroutine calls the Users service to collect statistics for the given user identifier. It uses a wait group to notify the completion of the work and directly modifies the result structure. This is safe as long as no other goroutine touches the result.UserData field. If the context is canceled, it will be up to the Users.GetStats method to return as soon as possible:
wg.Add(1)
go func() {defer wg.Done()
var err error
// Setting result.UserData is safe here, because
// this is the only gouroutine accessing
// that field
result.UserData, err = svc.Users.GetStats(ctx,
userID)
if err != nil {log.Println(err)
}
}()
- The second goroutine gets the account level statistics via a channel, but with a timeout of 100 milliseconds. That means the Accounts.GetStats() method creates a goroutine to compute the statistics and returns it asynchronously. When this result is read, it is sent to the acctCh channel in the select statement. The select statement also detects context cancelation. If the context is canceled while the Accounts.GetStats method is running, it may continue running after the handler returned, but it should eventually realize the context is canceled and return. If the context is canceled because of a timeout, the zero value for the account data will be returned:
acctCh := make(chan AccountStats)
go func() {// Make sure acctCh is closed when goroutine
// returns, so we don't indefinitely block
// waiting for a result from it
defer close(acctCh)
newCtx, cancel := context.WithTimeout(ctx,
100*time.Millisecond)
defer cancel()
resultCh := svc.Accounts.GetStats(newCtx, userID)
select {case data := <-resultCh:
acctCh <- data
case <-newCtx.Done():
}
}()
- The third part creates two goroutines (one for users and the other for accounts) that collect transaction information. These goroutines write the transaction information asynchronously to a common channel, which is listened to by another goroutine that fills the LastTransactions slice. There is a separate wait group that is waited in a new goroutine that closes the transaction channel once all data elements are received:
transactionWg := sync.WaitGroup{}transactionWg.Add(2)
transactionCh := make(chan Transaction)
go func() {defer transactionWg.Done()
for t := range svc.Users.GetTransactions(ctx,
userID) {transactionCh <- t
}
}()
go func() {defer transactionWg.Done()
for t := range svc.Accounts.GetTransactions(ctx,
userID) {transactionCh <- t
}
}()
go func() {transactionWg.Wait()
close(transactionCh)
}()
- The next goroutine collects transactions from transactionCh. Note that this is a fan-in operation:
wg.Add(1)
go func() {defer wg.Done()
for record := range transactionCh {// Updating result.LastTransactions is
// safe here because this is the
// only goroutine that sets it
result.LastTransactions =
append(result.LastTransactions, record)
}
}()
- As a final step, we wait for all the goroutines to complete, read the account data from its channel, and return. The receive from acctCh will not block indefinitely because it either returns a value or it is closed, in which case, we return the zero value for AccountData:
wg.Wait()result.AccountData = <-acctCh
return result
}
This example demonstrates several methods for distributing work and collecting results: one using shared memory safely, and the others using channels. If you are using shared memory, take extra care to protect variables accessed by multiple goroutines. If you are using channel communications, make sure all goroutines terminate correctly.
Semaphores – limiting concurrency
What happens if you want to limit concurrency? The dashboard handler can be quite expensive, and you might want to limit the number of concurrent calls to it. A semaphore can be used for this purpose. Semaphores are versatile concurrency primitives. A semaphore keeps a counter representing the number of resources available. The term “resource” should be taken in an abstract sense: it can refer to an actual computing resource, or it can simply mean permission to enter a critical section. A thread consumes resources by decrementing the value of the counter and relinquishes them by incrementing the counter. If the counter is zero, consuming the resource is not allowed, and the thread blocks until the counter is non-zero again. So, a semaphore is like a mutex with a counter. Or, to put it in another way, a mutex is a binary semaphore. You can use a channel of capacity N as a semaphore to control access to N instances of a resource:
semaphore := make(chan struct{},N)You can acquire a resource with a send operation. This operation will block if the semaphore buffer is full:
semaphore <- struct{}{}You can relinquish the resource with a receive operation. This will wake up other goroutines waiting to acquire the resource:
<- semaphore
We are using a channel of the struct{} type here (whose size is 0), so the channel buffer does not actually use any memory.
This is a good way of limiting concurrency in a program where a potentially unbounded number of goroutines can be created. The following example shows a middleware that limits concurrent calls to the dashboard handler:
func ConcurrencyLimiter(sem chan struct{}, next http.HandlerFunc) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter,
req *http.Request) {
sem <- struct{}{}
defer func() { <-sem }()
next(w, req)
})
}And a concurrency-limited handler can be defined using the following:
mux.HandleFunc("/dashboard/", ConcurrencyLimiter(make(chan struct{}, limit), svc.DashboardHandler))Streaming data
A typical software engineer’s life revolves around moving and transforming data. Sometimes the data being moved or transformed does not have a predefined size limit, or it is produced in a piecemeal fashion, so it is not reasonable to load it all and process it. That’s when you may need to stream data.
When I say streaming, what I mean is the processing of data generated continuously. This includes dealing with an actual stream of bytes, such as transferring a large file, as well as dealing with a list of structured objects such as records retrieved from the database, or time-series data generated by sensors. So, you usually need a “generator” function that will collect data based on a specification and pass it on to the subsequent layers.
In what follows, we will build a (hypothetical) application that deals with time series data stored in a database. The application will use a query to select a subset of the data in the database, compute a running average, and return the instances when the running average goes above a certain threshold.
First, the generator: the following declares a Store data type that contains the database information in it. An instance of Store will be initialized at program startup with a connection to the database:
type Store struct {
DB *sql.DB // The database connection
}The Entry structure contains a measurement performed at a certain time:
type Entry struct {
At time.Time
Value float64
Error error
}Why is there an Error in the Entry structure? Error reporting and handling is one of the important considerations of streaming results because errors can happen at every stage of streaming: during preparation (when you run the query, for instance), during the actual streaming (retrieval of some of the entries can fail), and after all the elements are processed (did the stream stop because everything is sent, or because something unexpected happened?). Unlike synchronous processing scenarios that result in either data or an error, a stream can include multiple errors as well as data elements. So, it is best to pass these errors along with each entry so that the processing logic downstream can decide how to deal with errors.
The following illustrates the general structure of such generator methods. It is designed as a method of Store so it has access to database connection information. The method gets a context together with a query structure that describes what results are requested. It returns a channel of the Entry type from which the caller can receive query results and an error that describes an error that happened at the preparation stage (for instance, a query error):
func (svc Store) Stream(ctx context.Context, req Request) (<-chan Entry, error) {
// Normally you should build a query using
// the request
rows, err := svc.DB.Query(`select at,
value from measurements`)
if err != nil {
return nil, err
}
ret := make(chan Entry)
go func() {
// Close the channel to notify the receiver
// that data stream is finished
defer close(ret)
// Close the database result set
defer rows.Close()
for {
var at int64
var entry Entry
// Check for cancelations
select {
case <-ctx.Done():
return
default:
}
if !rows.Next() {
break
}
if err := rows.Scan(&at,
&entry.Value); err != nil {
ret <- Entry{Error: err}
continue
}
entry.At = time.UnixMilli(at)
ret <- entry
}
if err := rows.Err(); err != nil {
ret <- Entry{Error: err}
}
}()
return ret, nil
}The method prepares a database query based on the request and runs it. Any errors at this stage are returned immediately as an error value from the method. If the query runs successfully, the method starts a goroutine that will retrieve results from the database, and it returns a channel from which the caller can read the results one by one. At any point, the caller can cancel the generator method by canceling the context. The goroutine starts by deferring some cleanup tasks, namely, the closing of the database result set and the closing of the results channel. The goroutine will iterate through the result set and send the results via the channel one by one. Any errors captured while iterating the results will be sent in that instance of the Entry structure. When all data items are sent, the goroutine will close the channel, signaling the exhaustion of the results. If the result set fails, an additional Entry instance will be sent with the error.
What is really happening here is that the Stream method creates a closure that sends data through a channel. That means the closure will live after the Stream method returns. Thus, any cleanup that needs to be done is done in the closure, not in the Stream method itself. It is also important to ensure termination of the closure either by consuming all the results or by canceling the context; otherwise, the goroutine (and the database resources associated with it) will leak.
Stream processing is structurally similar to data pipelines. Stream processing components can be chained one after the other to process data in an efficient manner. For example, the following function reads the input stream and filters out entries that are below a certain value while preserving error entries:
func MinFilter(min float64, in chan<- store.Entry) <-chan store.Entry {
outCh := make(chan store.Entry)
go func() {
defer close(outCh)
for entry := range in {
if entry.Err != nil ||
entry.Value >= min {
outCh <- entry
}
}
}()
return outCh
}Sometimes you need to separate the stream into multiple streams based on certain criteria. The following function returns a closure that sends all errors to a separate channel. The returned entry channel now only contains the entries that have no error:
func ErrFilter(in <-chan store.Entry) (<-chan store.Entry, <-chan error) {
outCh := make(chan store.Entry)
errCh := make(chan error)
go func() {
defer close(outCh)
defer close(errCh)
for entry := range in {
if entry.Error != nil {
errCh <- entry.Error
} else {
outCh <- entry
}
}
}()
return outCh, errCh
}After filtering the stream and separating out the errors, we can compute a moving average of the measurements and select the entries when the moving average is above a threshold. For this, we define the following new structure, which contains the entry and the moving average value:
type AboveThresholdEntry struct {
store.Entry
Avg float64
}The following function then reads the entries from the input channel and keeps a moving average of the measurements. A moving average is defined by the average value of the last windowSize elements seen in the stream. When a new measurement is read, the first measurement is removed from the running total, and the new measurement is added to it. This requires a first-in, first-out, or a circular buffer of the given size. A channel can double as such a buffer:
func MovingAvg(threshold float64, windowSize int, in <-chan store.Entry) <-chan AboveThresholdEntry {
// A channel can be used as a circular/FIFO buffer
window := make(chan float64, windowSize)
out := make(chan AboveThresholdEntry)
go func() {
defer close(out)
var runningTotal float64
for input := range in {
if len(window) == windowSize {
avg := runningTotal /
float64(windowSize)
if avg > threshold {
out <- AboveThresholdEntry{
Entry: input,
Avg: avg,
}
}
// Drop the oldest value in window
runningTotal -= <-window
}
// Add value to window
window <- input
runningTotal += input
}
}()
return out
}The following code snippet puts all of it together. It streams the results from the database, filters the results, computes a moving average, and writes the selected entries to the output. If there were any errors during this processing, it writes the first error after all the output is written:
// Stream results
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
entries, err := st.Stream(ctx, store.Request{})
if err != nil {
panic(err)
}
// Remove all entries less than 0.001
filteredEntries := filters.MinFilter(0.001, entries)
// Split errors
entryCh, errCh := filters.ErrFilter(filteredEntries)
// Select all entries when moving average >0.5 with
// window size of 5
resultCh := filters.MovingAvg(0.5, 5, entryCh)
// We will capture the first error, and cancel
var streamErr error
go func() {
for err := range errCh {
// Capture first error
if streamErr == nil {
streamErr = err
cancel()
}
}
}()
for entry := range resultCh {
fmt.Printf("%+v
", entry)
}
if streamErr != nil {
fmt.Println(streamErr)
}There are a few points to be careful about here. First, there is a separate goroutine that is receiving from the error channel. When the first error is captured, it cancels the stream processing completely. If that happens, the Stream method receives that cancelation and will close the entries channel. This will be detected by the next processing step in the pipeline (MinFilter), and it will close its channel. This will continue until resultCh is closed, and when that happens, the for loop that is reading from resultCh will close as well. The next statement reads the streamErr variable, which is written in the error handling goroutine, but this is not a data race. The ErrFilter function closes errCh before it closes entryCh, and entryCh is closed before resultCh (can you see why?), thus the termination of the for loop guarantees that errCh is closed. Second, the results are collected in the main goroutine. The same result can also be achieved using a separate goroutine to collect the results, but then you have to use sync.WaitGroup to wait for both goroutines to finish. You can also choose to read the errors in the main goroutine while collecting the results in a different goroutine. There, you have to use sync.WaitGroup again, because the closing of errCh happens before the closing of resultCh, so you have to wait for resultCh to close.
Not all data streaming implementations can be chained using Go concurrency primitives like this. If, for instance, you have a microservice architecture that uses HTTP requests, a WebSocket, or a remote procedure call scheme such as gRPC, then you can’t really chain components using channels. Some of these components will be located on different nodes on a network so communication between them will be through a network connection. However, the basic constructs we discussed previously can still be used with the help of simple adapters. So let’s take a look at how such adapters can be implemented to utilize Go concurrency primitives effectively. First, we need to decide what our objects look like when they are exchanged between different components on a network. So we need to serialize (or marshal) these data objects and send them over the wire, where they can be deserialized (or unmarshaled) to reconstruct the original object, or something as close to that as possible. Using an RPC implementation such as gRPC helps greatly in these situations by forcing you to think and model your objects using marshalable/unmarshalable objects only. However, that is not always the case. A common format for data exchange is JSON, so we will use JSON in this example. You can immediately realize the potential problem here: the store.Entry structure can be marshaled easily, but when unmarshaled, the Entry.Error field cannot be reconstructed. If you are sending errors over a network connection, you should implement error structures containing both type and diagnostic information so they can be reconstructed properly on the receiving end. For the sake of simplicity, we will simply represent errors as strings:
type Message struct {
At time.Time `json:"at"`
Value float64 `json:"value"`
Error string `json:"err"`
}Here, the Message structure is a serializable version of the store.Entry type. When sending store.Entry type objects over a network connection, we first translate each entry to a message, encode it as JSON, and write it. Since we are dealing with streaming multiple such store.Entry structures, we have a channel from which we read the stream. A simple generic adapter that does this is as follows:
func EncodeFromChan[T any](input <-chan T, encode func(T) ([]byte, error), out io.Writer) <-chan error {
ret := make(chan error, 1)
go func() {
defer close(ret)
for entry := range input {
data, err := encode(entry)
if err != nil {
ret <- err
return
}
if _, err := out.Write(data); err != nil {
if !errors.Is(err, io.EOF) {
ret <- err
}
return
}
}
}()
return ret
}This function reads entries from the given channel, serializes them using the given encode function, and writes the result to the given io.Writer. Note that it returns an error channel, which has a capacity of 1. The channel passes error information to the caller, and since it has a capacity of 1, the error can be sent to the channel without blocking, even if the caller is not receiving from that channel. The same channel also serves as a signal for completion. An HTTP handler using this is as follows:
http.HandleFunc("/db", func(w http.ResponseWriter,req *http.Request) {
storeRequest := parseRequest(req)
data, err := st.Stream(req.Context(), storeRequest)
if err != nil {
http.Error(w,"Store
error",http.StatusInternalServerError)
return
}
errCh := EncodeFromChan(data, func(entry store.Entry)
([]byte, error) {
msg := Message{
At: entry.At,
Value: entry.Value,
}
if entry.Error != nil {
msg.Error = entry.Error.Error()
}
return json.Marshal(msg)
}, w)
err = <-errCh
if err != nil {
fmt.Println("Encode error", err)
}
}))There are several points to note here. The handler calls the store.Stream function using the request context. Because of this, if the caller of this API stops listening for the stream and closes the connection, the context will be canceled and the handler will stop generating results. Second, the error from the store can be returned as an HTTP error, but not the error from the encoder. This is because by the time an error is detected in the streaming, the HTTP response header will already be written with a 200 Ok HTTP status, so there is no way to change it. The best thing that can be done is to stop processing and log the error. Note that this situation does not include the entries retrieved from the store with an error. Those are transferred successfully. The error only happens if marshaling fails, or if writing to the network connection fails, which can happen if the caller terminates the connection.
Similar to the encoding function, we need a decoder for the receiving end of the connection. The following generic function reads and decodes messages, and sends them over a channel. The actual reading from the connection is to be implemented in the given decode function:
func DecodeToChan[T any](decode func(*T) error) (<-chan T, <-chan error) {
ret := make(chan T)
errch := make(chan error, 1)
go func() {
defer close(ret)
defer close(errch)
var entry T
for {
if err := decode(&entry); err != nil {
if !errors.Is(err, io.EOF) {
errch <- err
}
return
}
ret <- entry
}
}()
return ret, errch
}There are two channels returned this time: one for the actual data stream and one for the error. Again, the error channel has a capacity of 1, so the caller does not need to listen to it. An HTTP client that calls this API and streams data is as follows:
resp, err := http.Get(APIAddr+"/db")
if err != nil {
panic(err)
}
defer resp.Body.Close()
decoder := json.NewDecoder(resp.Body)
entries, rcvErr := DecodeToChan[store.Entry](
func(entry *store.Entry) error {
var msg Message
if err := decoder.Decode(&msg); err != nil {
return err
}
entry.At = msg.At
entry.Value = msg.Value
if msg.Error != "" {
entry.Error = fmt.Errorf(msg.Error)
}
return nil
})As you can see, this is a straightforward HTTP call that uses a JSON decoder to decode a stream of Message objects from the response and sends them to the entries channel. Now, this channel can be fed to the stream processing pipeline. A separate goroutine can be used to listen to errors from the error channel.
This example illustrates how you can translate between readers/writers and channels when dealing with streams. Streaming results like this uses very little memory, starts returning results quickly, and scales well because data will be processed as it arrives. The next example will use WebSockets to illustrate how you can deal with multiple streams concurrently.
Dealing with multiple streams
Many times, you have to coordinate between data coming from and going to multiple streams concurrently. A simple example would be a chat room server using WebSockets. Unlike standard HTTP, which is composed of request/response pairs, WebSockets use bidirectional communication over HTTP, so you can both read from and write to the same connection. They are ideal for long-running conversations between systems where both sides send and receive data, such as this chat room example. We will develop a chat room server that accepts WebSocket connections from multiple clients. The server will distribute a message it receives from a client to all the clients connected at that moment. For this purpose, we define the following message structure:
type Message struct {
Timestamp time.Time
Message string
From string
}Let’s start with the client. Each client will connect to the chat server using a WebSocket:
cli, err := websocket.Dial("ws://"+os.Args[1]+"/chat", "", "http://"+os.Args[1])
if err != nil {
panic(err)
}
defer cli.Close()Clients will read text input from the terminal, and send it to the chat server through that WebSocket. At the same time, all clients will be listening to incoming messages as well. So it is clear that we need to have several goroutines to make these things concurrently. We start with setting up the channels to send and receive messages to and from the server. In the following code, rcvCh will be used to receive messages received from the server, and inputCh will be used to send messages to the server:
decoder := json.NewDecoder(cli)
rcvCh, rcvErrCh := chat.DecodeToChan(func(msg *chat.Message) error {
return decoder.Decode(msg)
})
sendCh := make(chan chat.Message)
sendErrCh := chat.EncodeFromChan(sendCh, func(msg chat.Message) ([]byte, error) {
return json.Marshal(msg)
}, cli)Next, using a separate goroutine, we read text from the terminal and send it to the server:
done := make(chan struct{})
go func() {
scanner := bufio.NewScanner(os.Stdin)
for scanner.Scan() {
text := scanner.Text()
select {
case <-done:
return
default:
}
sendCh <- chat.Message{
Message: text,
}
}
}()The final piece of the client code deals with the messages received from the server:
for {
select {
case msg, ok := <-rcvCh:
if !ok {
close(done)
return
}
fmt.Println(msg)
case <-sendErrCh:
return
case <-rcvErrCh:
return
}
}The server is a bit more involved as it has to distribute messages received from the clients to all the connected clients. It also has to keep track of the connected clients and make sure a malicious client cannot disrupt the whole system. The server will have a handler function containing the decoder and encoder goroutines, similar to the ones we have for the client. However, there are some significant differences. First, the server creates a separate goroutine for each connected client. That means if we need to keep track of all active connections, we need a share data structure, and thus a mutex to protect. But there is a way to do this without any shared memory (and thus, without any risk of memory races.) Instead of a shared memory structure, we create a controller goroutine that will keep track of all active connections, and dispatch any received message to them. When a new connection is established, we will use a channel, connectCh, to send the data channel for that connection. When the connection is closed, we will use a different channel, disconnectCh, to send a notification that a disconnect has happened. We will also use a data channel that will receive the messages:
dispatch := make(chan chat.Message)
connectCh := make(chan chan chat.Message)
disconnectCh := make(chan chan chat.Message)
go func() {
clients := make(map[chan chat.Message]struct{})
for {
select {
case c := <-connectCh:
clients[c] = struct{}{}
case c := <-disconnectCh:
delete(clients, c)
case msg := <-dispatch:
for c := range clients {
select {
case c <- msg:
default:
delete(clients, c)
close(c)
}
}
}
}
}()The connection handler deals with the actual encoding and decoding of data:
http.Handle("/chat", websocket.Handler(func(conn *websocket.Conn) {
client := conn.RemoteAddr().String()
inputCh := make(chan chat.Message, 10)
connectCh <- inputCh
defer func() {
disconnectCh <- inputCh
}()
decoder := json.NewDecoder(conn)
data, decodeErrCh := chat.DecodeToChan(func(msg
*chat.Message) error {
err := decoder.Decode(msg)
msg.From = client
msg.Timestamp = time.Now()
return err
})
encodeErrCh := chat.EncodeFromChan(inputCh, func(msg
chat.Message) ([]byte, error) {
return json.Marshal(msg)
}, conn)
for {
select {
case msg, ok := <-data:
if !ok {
return
}
dispatch <- msg
case <-decodeErrCh:
return
case <-encodeErrCh:
return
}
}
}))As you can see, when a new connection starts, an input channel is constructed to accept messages coming from all the clients. This is a buffered channel to prevent a malicious client that stops reading from the WebSocket without closing it. The input channel will buffer the last 10 messages, and if these messages cannot be sent, the controller will terminate the connection for that client by closing the data channel. When the data channel is closed, the encoding goroutine will terminate, eventually terminating the handler for that client.
This simple server illustrates a way to distribute data streams across multiple clients without falling into memory race issues. Many algorithms that look like they need a shared data structure can be converted into a message-passing algorithm that doesn’t need one. This is not always possible, so you should evaluate both ways when developing such programs. If you are writing a cache, then shared memory with mutexes makes more sense. If you are coordinating work between multiple goroutines, a separate goroutine using multiple channels makes more sense. Use your judgment, try writing it, and if you end up with spaghetti code, throw it away and use a different approach.
Summary
This chapter was about the language utilities and concurrency patterns for dealing with requests – mainly, requests that come through the network. In an evolving architecture, it is often the case that some components developed for a non-networked system do not perform as expected when applications move to a more service-oriented architecture. I hope that knowing the basic principles and design rationale behind these utilities and patterns will help you when you are faced with these problems.
Next, we will look at atomics, why you should be careful when you are using them, and how they can be used effectively.