
Chapter 2 – How Teradata Utilizes Parallel Processing
“An invasion of Armies can be resisted, but not an idea whose time has come.”
– Victor Hugo
Teradata Stores Data in Tables
Teradata stores data in tables much like an Excel spreadsheet. Each row has many columns. The difference is how Teradata processes the data. The rows are not stored together like an Excel spreadsheet. Each row is physically separated from its neighbor and sent to a particular AMP. The AMPs then store and retrieve the rows they have been assigned when the Parsing Engine orders them to do so. The Parsing Engine puts the data rows together, and the user sees their spreadsheet once again.
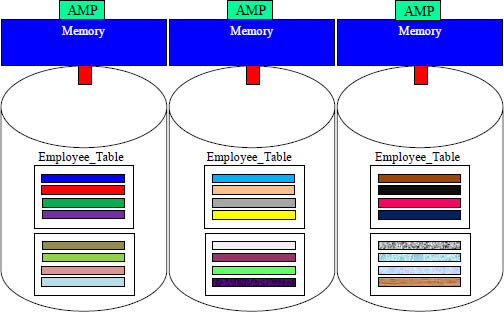
Each AMP is Assigned Specific Rows
“Great ability develops and reveals itself increasingly with every new assignment.”
- Baltasar Gracian
“Great scalability develops as different AMPs are assigned different rows.”
- Guru of the obvious
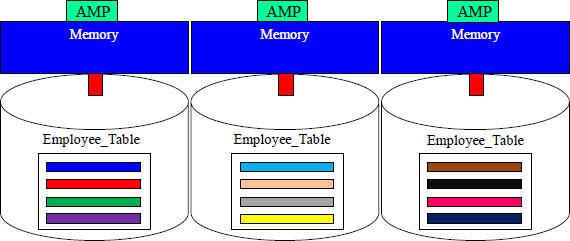
Teradata takes the rows of every table and spreads them among the AMPs. The table above had 12 rows so each AMP was assigned four rows. Every AMP in a Teradata system receives a portion of the rows.
Each AMP Organizes the Rows inside a Data Block
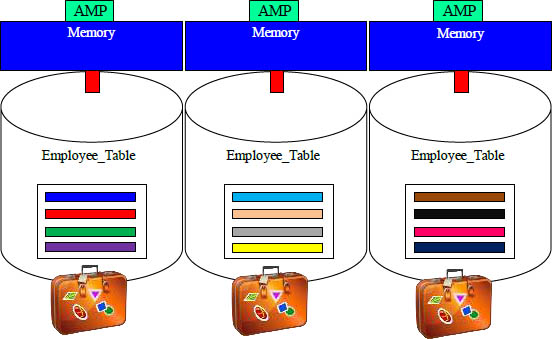
When you go to the airport, you pack your things inside your luggage. Each AMP has a separate luggage bag for each table. This keeps things organized. This luggage is called a data block.
AMPs Always Transfer Their Data Blocks to Memory
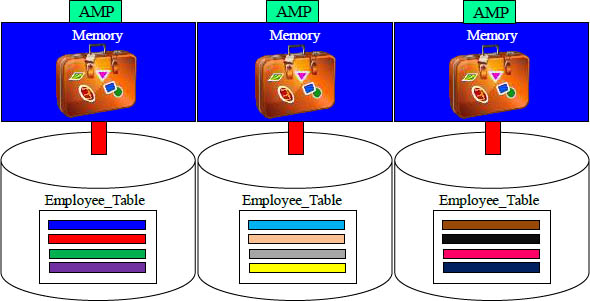
No matter if an AMP needs to read one row or even just one column, it must move the entire block from disk into memory.
When you go to the airport and pack your things inside your luggage, you can’t retrieve these items inside your luggage once you check it in. If you forgot your medicine because it was packed inside your luggage, you would need to retrieve the entire bag to get your medicine. Teradata retrieves the luggage to read one row.
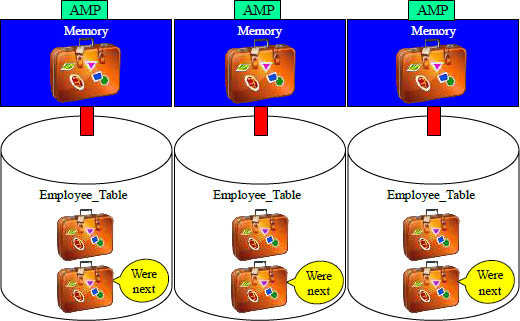
As Tables Get Bigger the AMP uses Multiple Data Blocks
When you go on vacation for two-weeks you might pack a lot of clothes. Most likely you will need to take two suitcases. Teradata has to move data blocks inside memory. When they have a lot of data they pack more suitcases, and as you can see above, each AMP has two data blocks.
AMPs Process A Table One Block at a Time
At the Airport luggage counter each bag needs to be weighed. You put bag one on first, and then after that is processed, you put bag two on. That is how Teradata AMPs process data; one data block at a time.
The Slowest Processing is a Full Table Scan
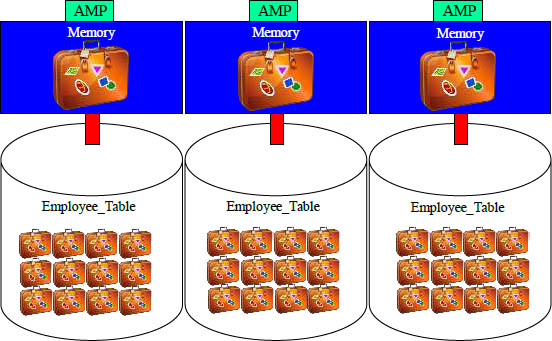
A Full Table Scan (FTS) means every AMP must read every row they own for a particular table. This means the each block must be placed into memory (one block at a time). This is extremely expensive and time-consuming for large tables. Above you can see that the Employee_Table has grown into 12 blocks per AMP.
Teradata Systems Can Grow Forever
“It’s always been and always will be the same in the world: the horse does the work and the coachman is tipped.”
- Anonymous

“Teradata is headquartered in Dayton, Ohio where I live and was born. It’s always been and always will be the same in Dayton: the AMPs do the work and the cows get tipped.”
- Farmer Tera-Tom (out standing in his field)
If you need to double the speed of your Full Table Scans, then just add more hardware and double your AMPs. The data from each table re-spreads and the system is twice as fast. Teradata’s number one weapon for processing massive amounts of data is linear scalability, which means as you add AMPs your system improves performance linearly. Other systems can only get so big before they max out!
Teradata has Five Designs to Prevent the Full Table Scan
1. Have Users use the Table’s Primary Index column in the SQL.
2. Create a table that is Partitioned.
3. Create a table that uses a Columnar Design.
4. Track the most popular tables and keep them in-memory.
5. Use a Secondary Index.
Nobody does a Full Table Scan (FTS) better than Teradata. This is because Teradata breaks up the rows for each table and assigns each AMP to be responsible for reading and writing the rows inside its luggage. That way a Teradata Full Table Scan is faster because a lot of AMPs are doing a portion of the work simultaneously. Companies can continue to buy more hardware and add additional AMPs for more speed. Each time new AMPs are added, the rows of each table are spread again to include the new AMPs. Unless a table is really small, the rows from every table are spread across all AMPs. But why do a Full Table Scan if you don’t have to? Teradata uses the above techniques to eliminate the Full Table Scan for a lot of queries.