
| Tip 13 | Control Time (and Timelines) |
 | [White Belt] Good version control is central to a good daily workflow. It’s an essential organizational tool, and even better, it lets you answer the age-old question, “Where the heck did this code come from?” |
The purpose of a version control system is simple: it tracks some content (generally files) over time, allowing you to commit new versions of content and roll back to previous versions. A competent system will also track multiple timelines and assist with merging content between them. With a basic understanding of how this works, it’s a tremendously useful tool—one that you’ll wonder how you ever lived without.
Moving Through Time
There are a couple reasons you need to move back in time with your source code—and any content, for that matter. First, you may screw up and need to revert to a previous version. It’s a fact of life; sometimes you’ll work yourself into a mess, and the easiest path is simply to throw away your last day of work and start over. A version control system allows you to do this easily.
Second, when you release code, you need the ability go back and look at what you released. It’s entirely normal for problems to crop up in the field that you need to fix but without changing anything else. Thus, you need to stash your current work, check out the released code, and make a fix on that copy. Then you’ll want to merge that fix to your in-progress code.
To move through time, you need to tell the version control system when to take a snapshot of your work. This is known as a commit. Usually you’ll have a batch of changes, and they’ll all get committed together as one version. If needed, you can revert your changes or simply pull another copy of the source code at any prior version.
When a version represents a milestone you want to refer to later, for example a product release, you assign a tag to that version. This is simply a convenient name that you can refer to later. When you check out the released version of code, you can specify the tag name instead of the version number.
Coordinating with Others
Programming is a group effort, and the version control system is your hub for coordinating efforts on a shared code base. When others have committed code, you’ll update your version to incorporate their changes. This is called a merge operation, where two variants of a file are used to create a new version incorporating all changes. Most of the time the version control system will merge your co-workers’ changes with yours automatically.
Sometimes two programmers will be working on the same code, and their work will overlap. One lucky programmer will need to manually merge the overlapping changes. The version control system will mark overlapping changes in the file, one section for the upstream changes and another for your changes, and you edit the file to make it right.
Multiple Timelines
The final basic practice of version control is managing multiple timelines. The classic case goes like this: you release version 1.0 of your product and start working on features for 2.0. Customers report bugs, and you need to create a bug-fix release to 1.0 without introducing the 2.0 changes. Therefore, you create two parallel timelines in the version control system: one for 1.0 bug fixes and another for 2.0 features.
Traditionally, the feature development timeline is called the trunk, and the others are called branches. This is because the trunk always continues on, whereas branches tend to have a limited life span. If you plotted the relationships over time, they’d have a treelike appearance with the trunk running through the center.
There are two traditional uses for branches: first, as we mentioned, is to control changes that go into a released version of code. This is, unsurprisingly, called a release branch. The second use is for more speculative feature development that is considered too risky to do on the trunk. These feature branches are developed to a point of good-enough stability and then merged back to the trunk.
Centralized vs. Distributed
Version control systems have split into two competing philosophies about who’s in charge of your content. Traditionally, systems have been client/server, and the server has the definitive copy of all content and its history. Clients can check out copies and commit new versions, but it’s the server that’s in charge of these transactions. Popular version control systems following this centralized model include Subversion and Perforce.
Another approach asserts that no one copy of the content is the master; instead, all clients contain the full version history so nobody (or everybody) is a definitive source. Popular systems following this decentralized model include Git and Mercurial.
I couldn’t possibly address all the pros and cons of each approach here—that would require its own book—but I will say that the centralized approach is what you most often see in industry right now, and I expect this will be true for some time. Many programmers simply aren’t comfortable with branching and merging on a frequent basis. (Distributed version control implies, to a degree, that every programmer has their own private branch.) However, these systems have much to offer for the team that learns to use them well.
Whichever type of system your company uses, master that first, including branch, merge, and tag operations. Then try your hand with a system from the other camp. As you learn, pay special attention to the motivation that drove the design of each type of system; they’re not trying to solve exactly the same problem.
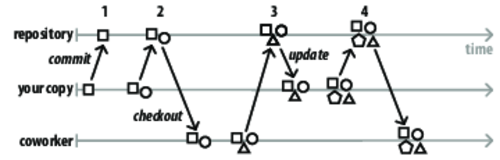
Figure 4. Version control: day-to-day collaboration
Actions
Learning version control isn’t hard, but you do need to try concepts on a simple project before tackling big problems in the wild. Start with the system your company already uses. If you’re on your own, pick any free VCS with good documentation—Pragmatic Version Control Using Subversion [Mas06] or Pragmatic Version Control Using Git [Swi08] would be a great starting point!
Fire up a terminal window and work through the following exercises with a simple code base:
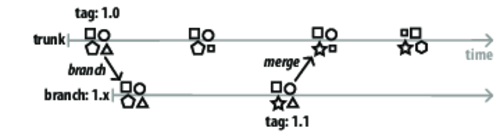
Figure 5. Version control: branch and merge
- Create Repository
-
First, create a repository and add some files to it. This will be your master repository, and you’re working on the trunk or default branch. Your first commit looks like the left side of Figure 4, Version control: day-to-day collaboration.
- Work on Trunk
-
Make some changes and commit them. Now do a couple more commits. Get a log to show your history; it should include change-set (or revision) numbers and summaries of your changes. Update to a prior version—exercise your control over time.
- Interact with a Co-worker
-
Either borrow a co-worker or play along using two working trees. Make changes from both places and commit; if using a distributed system, pull changes from each other. Now we’re at the right side of Figure 4, Version control: day-to-day collaboration.
Change different files and watch the VCS automatically merge. See what happens when both you and your co-worker make a change to the same parts of a file and commit—you’ll get a merge conflict you need to resolve.
- Create a Branch
-
Let’s say it’s time to create a release to customers. Create a version 1.0 tag and a release branch, as in Figure 5, Version control: branch and merge. You can choose to have two working copies of your project on disk, one for each branch, or just one copy that you can flip between the branch and the trunk.
- Merge Branch to Trunk
-
Now change a file on the branch. Say this is release 1.1 and tag it. Merge the change back to the trunk using the version control system—you shouldn’t have to do any copying and pasting.