
Information Management in Qualitative Research
Overview
There is always enormous amount of information in qualitative research due to liberal conversations in the field interviews during ethnographic and phenomenological studies. Hence, management of qualitative information is a major challenge among researchers. A database of qualitative information is usually unorganized and complex. Management of qualitative information essentially needs to be transformed into a system with the basic function of maintaining narrative information for its retrieval on demand to analyze the contents. This chapter discusses the fundamentals of qualitative data management and explains the care to be ensured for maintenance of the data. Analysis of qualitative information has been discussed in five major sections including information acquisition, metaphor analysis techniques, transcription and content management, data coding and content analysis, and computer aided qualitative date analysis. The perspectives on information acquisition have been discussed in reference to instrument development, information acquisition, and retrieval process. Data analysis process has been illustrated explaining how to synchronize the contents analysis categorical questions of the research instrument. In the consecutive discussion, this chapter also converses with the metaphor elicitation technique to analyze the information emerging out of conscious and subconscious mind on effects of imagery. Transcription techniques, data coding, and content analysis process with conventional wisdom and computer-aided qualitative data analysis systems have also been discussed in this chapter.
Principles of Qualitative Data Management
Managing qualitative information is complex as it is intangible. Information statements, phrases, quotes, observations, and storyboards are related to the point of expression timeline. Meanings of the information inputs change when reviewed on another period or if the same information is read repeatedly over time. The validity of information also changes as the time advances, unlike the numbers that reveal a firm view in quantitative research. However, qualitative research provides rich data on a specific phenomenon important to the thesis of the research, and may offer in-depth information for critical analytics to deliver the expected conclusion. Data management in qualitative research encompasses the elements of human cognition, expression, confidentiality, statements leading to evidences, and data ownership. Therefore, data storage, record keeping, and data sharing is a critical process in qualitative research that deserves researchers’ attention. Qualitative research provides a profound representation of a phenomenon that is evidenced in the field research. The information on the phenomenon reveals the richness of a study. Data in qualitative research broadly include field notes, data recording, transcriptions, memos, and cognitive analytics. Data management in qualitative research is defined as a designed structure for systematizing, categorizing, and filing the materials to make them efficiently retrievable and duplicable (Lin 2009).
Management of qualitative data is often difficult due to various cognitive, social, and operational factors emerging during the study. Many times, researchers are not aware of the expected volume of information despite the sample population of subjects being specified. The data emerging out of qualitative inquiries are scattered as they are stored in scattered sources like audio-visual and field notes. Data stored in audiovisual devices need to be transcribed to be documented and stored in electronic files or in categorically arranged paper folders. In either case, transcription of data from audiovisual sources is always risk averse of “content-corruption.” Physical loss of information documented on borrowed devices or theft of digital information from open networks or unprotected cloud-based domain causes major risk in qualitative research. Sometimes, file names create confusion in finding which interview transcript is the most complete one. However, the previous problems can be avoided if the qualitative information is arranged systematically in the coded arrays with a data tracking provision. If the researchers are not using any qualitative information analysis software such as QDA or NVivo, the data can be managed well in using Excel application, where data can be stored using appropriate codes. This arrangement would facilitate categorical data retrieval for making interpretations and drawing inferences. Proper data management allows researchers to accumulate information in various forms or locations by maintaining the security of the data for meta-analysis and data interpretations in the longitudinal studies.
Qualitative information can be organized by drawing a roadmap indicating the area, subjects, taxonomy of questions, observations, and social concerns. By developing a roadmap, organized qualitative data allow researchers to analyze specific research questions. Researchers can use a reflective process of managing the data generated in qualitative research to better systematize their data (Halcomb and Davidson 2006). Qualitative data management includes various concerns, not limited to confidentiality, protection of subjects of sample population covered in the study, and problems of data storage, sharing, and ownership. Confidentiality is one of the major responsibilities of a researcher, and a professional commitment to the participants in the qualitative inquiry process (Pinch 2000). One of the principal commitments of researchers conducting qualitative inquiries is to protect the information of participants in all possible ways. Building cohesive rapport with the participants is also important condition for the researchers because it promotes nonhierarchical relationship between the researcher and the subject. Researchers must show the participants that the researcher will treat their data with respect and maintain privacy. Ethnographic techniques would ensure confidentiality by evaluating the privacy, like anonymity of all interlinked elements of subjects in case of high-risk studies (Woogara 2015).
Reflective diaries maintained by qualitative researchers help in preventing them from committing the same mistakes during the research process. Unless prevented by the subjects of investigation, it is advised to share the research data in many ways to advance knowledge in sociocultural, ethnic, cognitive, and health care fields. Many journals publishing research studies advocate researchers to store the data on cloud-based domains and deliver the details of digital object identifier (DOI). Data ownership needs to be defined, and accountability of investigators should be fixed accordingly. In many instances, data might be owned by the research funders, research institutions, research participants (in some cases), or investigators. In qualitative research, research participants are often highly involved with the data collected, which may make them feel authoritative on the information (Manderson, Kelaher, and Woelz-Stirling 2001).
Community partnerships with qualitative researchers has a sensitive line involved in collaborative, qualitative research projects on social and preventive health such as incidence and control of HIV infection and other communicable diseases. Research on the project generates substantial data with the potential to impact health policy. These data often include highly confidential and sensitive narratives, requiring strict data management practices to protect the data from damages during sharing and information analysis. Often, such high-risk qualitative research projects go beyond the structured instrument during the in-depth and open-ended interviews. Therefore, during the process of information analysis, inclusion of unprotected narratives might deeply affect the personal life and cause grief, hardship, and inconsistency among the subjects. Therefore, researchers must develop a process to communicate the results on selected variables that would protect the anonymity and sensitivity of subjects’ information. This process would require a balance between information acquisition and reporting important findings of the study (Hardy et al. 2016).
Qualitative Information Analysis
Analysis of qualitative information is an art and science. Acquiring information through qualitative instruments, analyzing contents, and drawing inferences is a scientific approach, while blending such inferences with informal observations, field notes, and public views is an art in qualitative research, as it needs a rationale and community sensitive vision. Qualitative data analysis holds the major tasks of classification of data, analysis of information by variable segments, and interpretation of the results. Developing statements about implicit and explicit conclusions by carrying out the structural analysis of meanings embedded in the information provide inadequate support to interpret the qualitative information. In this process interpretations of subjective and social meanings are often complex. Qualitative data analysis should be aimed at discovering and describing issues in the study area, social and family structures, and decision processes among the stakeholders in society, family, and business. Unlike statistical analysis of quantitative data, qualitative data analysis should be divided into two phases: initial and final. In some high-risk studies like technology diffusion, new products development, security risks, health care studies, medicinal trials, and sensitive social topics of research, an intermediate phase is also created to control the analysis and reporting anomalies. The initial phase of information analytics includes of a rough analysis of the material overviews, condensation, summaries. These tasks are followed by the final phase of a detailed analysis concerning elaboration of categories, hermeneutic interpretations, or predetermined identified social structures. Hermeneutics is the theory and methodology of interpretation developed for the interpretation of linguistically complex information such as biblical texts and philosophical texts. Such methodology might not be commonly required to analyze the consumer and business data unless it has some obscure script or linguistic parameters.
Most of the qualitative research projects like studying consumer behavior, corporate culture, and stakeholder values on business policies are able to derive specific or fragmented conclusions within consumer categories, clusters, or over temporal and spatial dimensions of the research. Such fragmented conclusions cause narrow scope of qualitative data in reference to its analytical implications. However, longitudinal qualitative studies conducted over temporal and spatial dimensions aim to arrive at generalizable statements by comparing wide-focused responses, cross-sectional information, and analyzing the strategic business or governmental documents. The analysis of qualitative data should encompass the following focuses to deliver the conclusions that can be generalized:
- Describing a phenomenon
- Comparing information across subjects, space, and time
- Explanations to lead and peripheral analysis, and
- Developing an inductive theory
A systematically organized information within the psychosocial and developmental arrays across spatial and temporal dimensions help researchers in describing a phenomenon and comparing the evolution of related factors across subjects and geo-demographic segments. Chronological information offers researchers relevant indicators to explain thematically the qualitative research thesis and lead peripheral analysis. Accordingly, inductive theory concerning the research can be established. In carrying out the analysis of qualitative information, the subjective experiences such as observations of the researcher play a significant contribution. Another factor that intervenes in the analytical process include a social situation, which needs to be explained in reference to its consequences on the family and public life of the subjects. Social practices and routines also offer relevant hints to explain the background of the social analytical procedures using the qualitative information. The theoretical roots of this approach outgrows from ethnomethodology, which is one of the principal approaches to collect qualitative data.
Over the years, the focus of information analysis has turned toward interpreting the phenomena through narratives and ethnographic descriptions. The trend of reporting qualitative studies has turned more systematic and conventional in the context of writing essays, coding, and data arraying with the help of software programs and packages for computer aided data analysis (Banner and Albarran 2009). During the mid-1980s, the qualitative information analysis led to development of static and dynamic social paradigms based on the interactivity of key indicators of a research study. In this context, the evaluation of research and findings became central to methodological discussions. In the following period, the interpretation of narratives and storyboards have replaced paradigm analytics and deductive theories. The pattern of analysis of qualitative information gradually shifted to grand narratives and inductive theories explaining the local, historical situations, and socially felt problems. Accordingly, the data analysis adapted to experimental writing, linking issues of qualitative research to public policies.
Acquiring Information
Qualitative methods include structured verbal interviews and free associations techniques (Danes et al. 2010) that can be used toward assessing consumer perceptions on behavioral branding. These methods improve the data collection process derived from more traditional scale-based approaches (Arora and Stoner 2009).While sharing experience on the structured research instrument, subjects experience cognitive, rational, emotional, social, and cultural attributes while dealing with brands. In the case of consumers, such data collection approaches allow researchers to map perceptions of consumers on product, services, and brands anthropomorphically through personal interactions (Hooper 2011). Therefore, data can be effectively collected using semistructured verbal interviews. However, informal associations with the respondents help in supplementing the data through categorical observations. Acquiring qualitative information depends on the type of questions structured in the research instrument and the method of data collection opted during the study. Collecting information through the in-depth interviews provides ample scope of pooling comprehensive data for conducting multilayered content analysis. For collecting comprehensive and quality information through the in-depth interviews, following points need to be reviewed while preparing questions:
- Design a few general questions to permit participants to share introductory information.
- Construct questions that are neutral and nonjudgmental, but have the potential to explore comprehensive information during the interview process.
- Use nonauthoritative, polite, and ethical language to structure the questions.
- Structure direct questions with all respect to sentiments of the respondents and legal fit of conversation.
- Design and list lead and supporting questions that are thematic to the research and match with the ecosystem of the study, and
- Closed-ended questions are discouraged in the qualitative research instrument as they restrict the expressions of subjects and obstruct the rationale in thinking process.
In qualitative research, research questions differ greatly from the research topic during conversations with respondents. Such a situation emerges when the researcher intercepts the responses and frames new questions instantly. Most inquisitive researchers face such problem, they collect enormous information but are unable to streamline the responses. Consequently, a large data gets redundant, which cannot be used in the analysis. Research topic is a broad area, in which a central phenomenon is woven around the key concept, idea, or process intended to be studied by the researcher through qualitative research (Creswell 2005). Once research questions are drafted, the researcher should examine the questions to validate the response trend and the hidden attributes. Good research questions are researchable, clearly stated, theoretically motivated, and involve applied concepts to drive respondent to reveal their opinion (Bradley 2001). However, evaluating the research questions consumes a considerable amount of time and effort.
Qualitative research requires both lead and supporting questions to comprehensively acquire information while conducting interviews. The lead questions trigger kick-off of the interview process to obtain base information and set the scenario for further data collection. These questions should include direct questions (6W’s) comprising what, when, where, who, why, and which, and encourage response of subjects on the given situation. A researcher should give the respondents enough space to share their perceived experience during the information gathering process. Sometimes respondents are sensitive to direct questions, so the lead questions should be framed indirectly seeking opinion on statements, referred reviews, indirect personal questions, and plans and motives. Researchers pursuing information through qualitative sources should be trained in structuring direct, indirect, and interceptive questions to obtain quality information from the respondents. Interceptive questions are derived from the continuing response with a view to gain in-depth information. Such questions do not have just one correct answer, they might provoke parallel or counter questions to stimulate diverse or supplementary responses. Intercept surveys are conducted in-person, generally in a public place or business. For instance, interviewers might approach the subjects leaving a restaurant and ask to interview them about their experiences. Interviewers ask questions or simply explain the project and give questionnaire to the respondent to fill out. The surveys might be completed on paper or any electronic device. Intercept interviews appear to be a great method for obtaining data for a research project. On-site interviews provide top-of-mind feedback of the respondents. However, it is necessary to develop the lead questions that could be responded with the evidential support. Such interpretive questions generate the most engaging discussions and might emerge with several different correct answers (Rajagopal 2018).
In order to explore comprehensive information from the subjects, the researcher must locate the key and community informants. Key informants are the subjects who have knowledge on the research theme and experience to respond to the questions, possess leadership quality, and have social or family responsibilities. Community informants are the local subjects who also share conversations on variety of questions during the fieldwork at the respective localities. If the researcher succeeds in building good relationships with the subjects, they develop confidence in sharing knowledge on the research topic and may become effective key informants. Key informants are not only useful for soliciting a lot of information on the research topic, but are also essential in locating other informants through their connection with, and knowledge of (sections of), the community. Unless researchers have experience with qualitative methodologies, interviewers should be trained in data collection and data transcription processes. Interviewers should learn role-playing, and watching or listening to the interview tapes scientifically. It is necessary to develop a que-sheet of information stored in tapes, which needs to be analyzed. The que-sheet should contain the core information, arguments, evidences, and creative ideas in reference to the concerned questions.
During the information collection process, skilled researchers show a genuine interest in interviewees and their responses. During the process of conducting in-depth interviews, researchers should be able to manage their social image and personality, and exhibit nonjudgmental attitude. It is common that most subjects use slangs in their responses. Therefore, the recorded interviews should be carefully listened, and appropriate meaning of slangs should to be derived. Researchers also need to develop the ability to observe verbal and nonverbal cues in the information to substantiate the contents of the subjects. The information acquisition process can be controlled by developing the following norms and standards:
- Ability to follow up responses with a view to explore emerging issues while adhering to the research instrument.
- Adopt “bridge and breach” techniques for information acquisition.
- Interrupt to move to next question / theme.
- Make connections / recognize contradictions.
- Use nondirective and noncommanding probes.
Researchers must pay attention to explore contemporary information from the subjects during the interview process. In this process, they may pose many peripheral and intercept questions, but must adhere to the broad perspective of the research instrument. It has been observed that subjects often need some logical support to build their responses due to temporary loss of context or memory per se. Researchers should possess the knowledge and skills to bridge such information gaps, and the skills to moderate the discussions and streamline the information flow, interrupt, or move to the next question breaching the time on the current question. However, researchers must stay nonjudgmental, noncommanding, and nondirective while conducting the interviews. The interviews can be moderated by guiding and explaining critical points of information. The quality of information is affected by the current state of mind of the subjects. Therefore, the active and passive subjects need to be managed by the researchers in reference to psychosocial cognition factors, beliefs, ethnicity, and emotions. Simultaneously, the discussions during the interview process need to be streamlined intermittently to ensure quality of information and eliminate on-field data redundancy. Before moving to the next question in the interview process, or concluding a section of information, researchers must summarize salient discussion points, and seek the endorsement by the subjects on the conclusion. However, while documenting or recording the information, small cues on the points of interest raised by the subjects need to be categorically noted. These cues would help the researchers explore further information on the emerging concerns of the subjects either by organizing additional interviews or through the text-data-mining approach. In the process of interviewing the subjects, unpleasant or irrelevant memories often shadow the principal point of discussion. Such memory inhibition must be filtered to avoid biases in information. Similarly, cognitive inhibition, which emerges due to mind’s ability to surface irrelevance while discussing the uninterested or avoidable concerns, also needs to be controlled.
Information Retrieval and Learning Process
Researchers must develop skills to retrieve the memorized information and the information collected on the various devises. Despite enhanced interest in the mechanics of qualitative information retrieval in recent years, the extended qualitative data storage-retrieval and data reduction-analysis have been applied in some research studies. Common procedures for these tasks are not systematically examined or codified in the qualitative research. The five principles to be followed to ensure safe retrieval of the data include formatting, cross-referral, indexing including thesauri (lexica or vocabulary) design and cross-referencing, abstracting, and pagination (Levine 1985). The field work data is typically recorded in a sequence of the questions in the research instruments. The data related to the social interaction of the investigator and informant are documented in the field diary rather than linearly pointing to the topics under investigation.
The general models of data storage and retrieval for the field-based qualitative investigation are similar to the information management in library science. There are problems associated with qualitative databases, which need careful investigation specific to the nature of information that requires data storage and retrieval. Abstracting, index systems, thesaurus, storing descriptive data in digital file, and semantic textual analysis are some mechanical ways of developing information inventory that could help the researchers. Depending on the plans of the text analysis, new information can be generated by using codes, code definitions, code relationships, code–text relationships, hypertext linkages, and conceptual maps (MacQueen and Milstein 1999).
In the information retrieval process, researchers need to manage texts and phrases in retrieving the information besides the mechanical approaches to store and retrieve the data. Subjects often exhibit physical gestures and expressions to convey their views. Such incidences might happen with the subjects who are children, less educated, at high risk referring to health disorders, under civil protection, or facing terminal disease. Therefore, subjects need to be stimulated appropriately to retrieve memories and convey the right information during the study process. The memory retrieval process can be stimulated using the closed- and open-loop approaches. Closed-loop approach consists of sensory feedback or stimuli to cognitive dynamics and explores memory traces of subjects over space and time. Breaking the closed cognitive loop of subjects helps the researchers carry out perceptual mapping and interpretation. Open-loop approach helps the subjects pull out abstract memory and recall information with peripheral feedback or stimuli. Open-loop stimuli drive emotions and excitement among subjects during the interview process. Thus, researchers might observe rapid and aggressive physical movements, articulation, and novel expressions of subjects during personal interviews. Researchers must understand the cognitive ecosystem of the subjects, and manage the information emerging from conscious mind and stored in the subconscious memories. The coordination between self-congruence and referrals, perceptual mapping (spatial and temporal), connectivity between cognition, thoughts, and expressions must be clearly documented by the researchers during the information acquisition process.
Analyzing Data Through Research Instrument
A comprehensive research instrument used to collect information serves as an asset for carrying out sequential analytics of interconnected variables. Most research instruments are built around the statements such as “effective public policies improve the quality of social life.” The validation of such statements by quantification and purposive interpretations would help in analyzing such qualitative statements. Other types of questions, as discussed in the following, need to be categorically analyzed:
- Descriptive questions
º Limitations
º Contents
º Ethics
- Intercept questions
- Reverse questions
º Respondent generated
º Synthesized questions
- Funnel questions
- Pictorial questions
Descriptive questions form the core of a qualitative research instrument and widely influence the information analysis process. However, due to the comprehensive information embedded in descriptive responses, the limitation of the information in reference to the selected parameters like time, area, cost, economic benefits, social development, and quality of life should be fixed for analysis. Information analysis can be carried out on a case-by-case basis by arranging the responses in a consecutive order. The content analysis of descriptive information needs to be done moving from macro to micro perspectives. Intercept questions in the interview process are asked to comprehend the contextual information on the responses to the principal questions. Analysis of the peripheral information generated through the intercept questions (asked by the researcher and reverse questions (posed by the subject to the investigator) need to be categorically arranged and reviewed in reference to the core information collected during the study. Information generated through these questions provides a base for raising social arguments at the grassroots. Most researchers exhibit their enthusiasm in qualitative research by enchaining subjects into a series of thematic perspectives. However, researchers should take a categorical approach on drawing inferences and structuring arguments to synthesize such funneled information on random perspectives. Information analysis can be carried out in different tiers based on the taxonomy of questions in the research instrument. The systematic approach of information analysis leading to meta-analysis and meta-synthesis is shown in Figure 3.1.
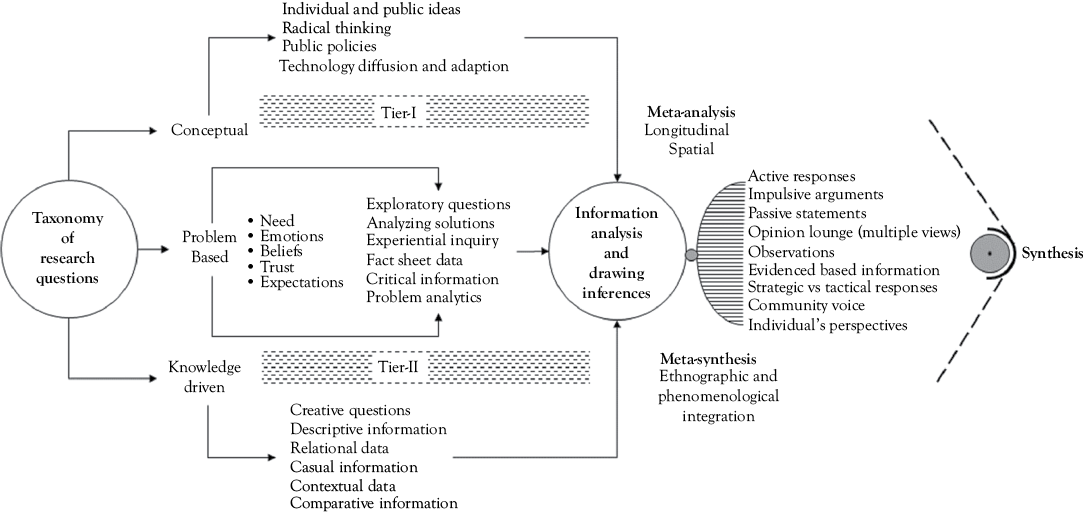
Figure 3.1 Systematic view of qualitative information analysis
Research questions can be broadly classified into three categories: conceptual, problem based, and knowledge-driven perspectives as shown in Figure 3.1. Tier-I analysis in qualitative research is suggested to explore the conceptual values of the subjects toward social and public ideas, surfacing radical thinking, and critically examining the public policies. The information analysis at Tier-II provides filtering of creative ideas, arguments, and descriptive contents on relational and contextual data. Researchers can compare the strengths and weaknesses of the information at this tier of analysis. The problem-based information contains responses based on the experience, facts, and critical understanding of problems. Such information should be analyzed on the background of needs, emotions, beliefs, trust, and expectation of the subjects. Accordingly, researchers can draw inferences on active responses, impulsive arguments and evidence-based information. An opinion lounge can be set on an appropriate software like QDA, NVivo, or Excel, where a research can accommodate opinions of all the subjects and filter them according to their pragmatism and significance. Sometimes, the passive statements posed by the subjects also make a base for raising strong arguments in the qualitative research. Accordingly, the analysis across spatial and temporal dimensions can be planned as meta-analysis on the selected variables of the study. However, ethnographic and phenomenological studies could develop meta-synthesis by linking the vital arguments emerging out of the study.
Metaphor Elicitation Analysis
Qualitative researchers often face the metaphoric expressions of subjects while responding to the interview questions. A metaphor is an expression of speech that describes an object or action in an unrealistic way, but helps to explain an idea or draw a comparison. Broadly, in qualitative market research, a metaphor involves understanding and experiencing one product or service in terms of another. It elucidates the perception of the consumer on one product or service, as if it was different from its real image. Metaphors are central to understanding the human cognition as they invoke and express nonverbal imagery. Linguistic metaphors widely reflect underlying conceptualizations of experience in long-term memory. The nonverbal communications are considered as major touch points, in which researchers observe the neurophysical dynamics of the subjects.
Zaltman Metaphor Elicitation Technique (ZMET) is a milestone in measuring the cognitive moves of people on personality development perspectives. ZMET explores both conscious and unconscious thoughts, in order to understand people from inside at the deepest level possible. Ethnographers, who are involved in mapping the subconscious thoughts of their subjects, use this technique extensively. Qualitative researchers observe, and interact with, people in their most emotionally relevant environments, and combine metaphor elicitation methodology for deeper, more nuanced understanding of the perceptions of the subjects. In the ZMET analysis, researchers determines how effectively people’s unconscious emotional drivers identify the meaning people co-create on the social or personal development standpoints. In this methodology, subjects collect a handful of images representing their thoughts and feelings about a particular topic, and each participant is interviewed using their images as a jumping-off point for discussion. This method is similar to participatory (rural) appraisals, in which subjects map their resources, identify problems, and suggest solutions.
The ZMET methodology involves the following key elements for cognitive analysis of information:
- Contextual stimuli
- Sensory cognition
- Episodic memory
- Rationale, metaphor, and anthropomorphism
- Emotional consequences
- Physio-psychological response
- Consumer traits and values
- Storytelling and storyboard analysis
- Verbal and nonverbal communication
- Controlled gestures, voice analytics, and neuro-imagery analysis
Contextual stimulus is a situation-based motivation given to the subject during the interview process in qualitative research. The situations are assessed in reference to behavioral status and the expected consequence of the stimulus on the subject. Therefore, opinions of the subjects on pictures vary widely and affect the real-time responses. For instance, a picture of a person who is looking at a food store might stimulate the subject contextually to reveal whether he had passed through such money crunch situation. The consequence of such contextual stimuli may be positive or depressing, which might affect the real-time response of the subject. Hence, researchers should understand the behavior of the subject before introducing any contextual stimuli.
Sensory cognition is a process, which moves from senses to the brain, to carry out cognitive analysis. The upstream sectors of synaptic hierarchy in the brain develop unimodal association with the features of sensation such as color, motion, form, and pitch, and encode them for cognitive analytics. However, complex sensory experiences such as objects, faces, word-forms, spatial locations, and sound sequences are encoded within downstream sectors of unimodal areas. Hence, colors and physical objects do drive the sensory cognition of subjects during the qualitative inquiry process. Inflexible bonds between sensation and action lead to instinctual and automatic behaviors that are often resistant to change, even when faced by negative consequences (Mesulam 1998). Such sensory cognition helps researchers explore the experiences-led responses over space and time.
Episodic memory is defined as the ability to cognitively recall and re-experience specific episodes from the personal past. It is an autobiographical memory mapping process, which is opposite to semantic memory that includes memory for generic, context-free knowledge. In the qualitative research, episodic memories can be documented as storytelling and the researchers can develop a storyboard for each subject. Episodic memories are consciously recollected memories related to personally experienced events, while the episodic remembrance is a dynamic process that draws upon mnemonic and non-mnemonic cognitive abilities. The retrieval of episodic memories is a useful tool to cognitively reconstruct past experiences following appropriate retrieval cues. Therefore, researchers should prompt episodic memories of the subjects and document them in the order of relevance (Wheeler and Ploran 2009).
The rationale of stimuli and appropriateness of metaphor reflect in building anthropomorphism among the subjects, which makes them impersonate an entity. Anthropomorphic expressions raise emotional and physio-psychological responses among the subjects. Such situations need to be handled carefully by the researchers, and should be recorded digitally if possible, which would be helpful to the researchers while analyzing the episodic memories. ZMET is widely used in the consumer research, and the social and developmental research. It helps in exploring the consumer traits and values through storytelling and storyboard analysis. This technique is based on verbal and nonverbal communication. However, active researchers also map the gestures, conduct voice analytics, and perform neuro-imagery analysis of the qualitative research studies.
Other analytical approaches that support ZMET include mind-mapping, semantic perceptions, and analyzing contents of metaphorical conversation. Mind mapping techniques were developed in the late 1960s, but only after the emergence of information and communication technologies, mind maps are being successfully applied in consumer behavior analysis, innovation management, and organizational behavior areas. Mind mapping can be done using software or can be drawn on a paper during the qualitative interview produces. This technique is useful to explore learning experiences that facilitate cognitive reflection, knowledge building, problem solving, inquiry, and critical thinking among the subjects. Using mind maps as an active learning strategy is an innovative technique used to facilitate exploring new ideas, developmental concepts, and experience-based elucidations. In the qualitative research, subjects can illustrate a vision, exhibit their contextual knowledge and creativity, and make associations about a central theme during this activity (Rosciano 2015). Semantics comprising contextual meanings, interrelated logics, and ideas can be documented during the qualitative research process as an outgrowth of mind mapping exercise. The lexical semantics can be plotted around the core idea and interlinked in reference to word meaning and symbiotic rationale.
Transcription and Content Management
The most challenging task in qualitative research is the transcription of information stored in electronic devices. Since the responses of subjects in qualitative research are lengthy and complex, interviews are often recorded in electronic devices and later transcribed to the text form. Transcribing appears to be a straightforward technical task, but in fact involves judgments of the researcher while protecting the contents of original data and its interpretation, omitting nonverbal dimensions of the interaction. The quality of transcribed data is often questionable due to convenience of data interpretation and less rigor in conserving the originality of the information. Often, the slang communication used in the responses cannot be transcribed verbatim, which causes bias in the information. It is also observed in various interviews that the responses of the subjects to various questions stay unclear, making it difficult for the researchers to transcribe under assumptions. For example, respondents might not be clear in responding to some questions about their family and health such as personal relations, family sickness, etc.
Transcription is necessary for open-ended responses, information of focus groups, observation, and individual interviews. Transcripts strengthen the data audit as researchers can review the text while listening to the interview recording. Qualitative inquiries can also be set up through digital networks. The interviews scheduled via Zoom conference have online transcription option, which allows the researcher to watch the recording and read the transcript simultaneously. All transcriptions should have the subject identifier tags to keep the anonymity of information. Transcription of language-specific conversations should be done contextually instead of verbatim transcription. While transcribing the information, researchers may also be benefitted by field notes, flow charts, and figures drawn during the field study. Researchers should also learn about various transcription approaches as discussed as follows:
- Videos interviews
- Audio recordings
- Transcription and translation
- Partial or selective transcripts
- Sign language transcription
- Inference based transcription- Managing qualitative interviews with children and physically challenging people
Video interviews can be automatically transcribed using some software as discussed in the pretext. However, audio recordings need to be carefully transcribed by the researchers without altering the meaning of narration. Verbatim translations often damage the meaning of narrations. Hence, translations should be done in contextual sense without affecting the contents of narrations. Partial transcription refers to transcribing narrations along with interpretation of nonverbal information like charts, images, and semantic notes. Certified interpreters must carry out sign language transcription, though there are automatic sign language translation software like Sign All. The researcher may also opt for inference-based transcription for managing qualitative interviews with children and physically challenging people.
Visual data are more difficult to process since they take a huge length of time to transcribe, and there are fewer conventions to represent visual elements on a transcript. The meanings of utterances are profoundly shaped in the way something has been said. Transcriptions need to be very detailed to capture features of talk such as emphasis, speed, tone of voice, timing and pauses, as these elements can be crucial for interpreting data. Transcription involves close observation of data through repeated careful listening (and/or watching), and this is an important first step in data analysis. This familiarity with data, and attention to what is actually there rather than what is expected, can facilitate realizations or ideas, which emerge during analysis (Pope 2000).
Transcribing the spoken language and slang expressions emerging out of an interview or a focus group is yet another challenge for the researcher as the text needs modification of transcription rules. The interview transcription generally results in about 20 percent loss in content and needs focus on slangs, regional language, and peripheral information. Usually the content of the language is of main interest, but there are possibilities to enrich the text with additional aspects. A transcription system contains a set of exact rules on how spoken language is transformed into written text. Therefore, researchers must complete the pretranscription tasks as listed as follows:
- Familiarization with the instrument
- Recalling data collection scenario
- Referring to researcher’s journal/ agenda
- Key indicators of data collection
- Analyzing behavior of respondents
- Decide pattern:
- Verbatim transcription
- Selective transcription
- Comprehensive transcription
Before starting the transcription, researchers should reorient themselves with the research instrument, familiarize with the questions, and recall the interview scenario, so that contextual inferences can be developed. Referring to researcher’s journal (diary) would help in supplementing the transcribed contents of narrations. There are different transcription protocols that need to be followed during the qualitative research process:
- Selective protocol: In this process, the researcher selectively transcribes the audio recording of the interview, which is relevant for the research question. Interviews often contain extensive introductory parts, auxiliary discussions, motivational standpoints, and explanation of the research question that constitute the contents and quality of information and compliance of the interviewee. However, selection of contents made by the researchers is sometimes biased, and it adversely influences the transcription process and text interpretation. If the interviews are long and narrative in nature, the selection of narration for transcription is a difficult task. Researcher should make a que-sheet of narration and match it with the required response to questions and research propositions.
- Comprehensive protocol: A researcher may like to transcribe the complete contents of recorded interviews of respondents without selecting the sections in parts if the information is neither ambiguous nor too open to interpretations. However, if a researcher is interested in transcribing only the contents, a comprehensive protocol might be sufficient. The researcher or his transcribing team reads or listens the language, pauses at regular intervals to synchronize narration with the text, and sums up the main contents. Use of an automatic speech recognition program could be useful for the transcription provided the narration is compatible to the software program.
- Verbatim transcription: This is an unusual practice and should be avoided as the etymology and contextual narrations differ by language. A word might have different meaning while transcribing into another language. For example, “Nova” might refer to a brand in Mexico and indicate the verbatim meaning as “doesn’t go.” The verbatim transcription is done word for word for citing the opinions of interviewees or preparing quotes, but all utterances like hmm or aha, and decorating words like, right, you know, and yeah are discarded. The researcher produces a coherent text simple to understand but representing the original wording and grammatical structure during the transcription. Short-cut articulation and dialect are translated into standard language, for example, c’mon indicates “come on.” However, in this process, dialect formulations, fillers, and articulation are maintained as in the narration.
Verbatim transcription of qualitative information has become a common data management strategy in association with the technology applications. It is being actively used in public health and nursing research, and has been proved effective to the analysis and interpretation of verbal data. The benefits of verbal data are becoming more widely popular in social marketing, consumer research, and health care studies, and interviews are being increasingly used to collect information for a wide range of qualitative research studies. In addition to purely qualitative investigations, there has been significant increase in opinion-led research studies. It is important to set-up the contextual rules for transcription. It is necessary to define a system of transcription specific to region and language. Deciding which one of these systems to use depends on the research question, the characteristics of the language, and the theoretical background of the analysis. However, one of the major challenges in transcription of information arises when the narration is supported with nonverbal illustrations like pictures and charts. Successful transcription could be done by following the transcription process as discussed in the following:
- Intermittent listening/viewing
- Developing que-sheet
- Sentence-by-sentence transcription
- Reconfirmation of transcript with original response
- Approvals of respondents
- Cross-references to questions
- Editing transcripts
- Highlighting contents/ indexing /cataloguing
In order to ensure successful transcription of narrations from the audiovisual devises, it is necessary to listen intermittently, develop a que-sheet of significant points, and set the sequencing of transcription. If the narrations are small, sentence-by-sentence transcription can be done. However, all transcriptions need to be revalidated from the original narration or the subjects, if available. Sometimes the subjects repeat the same responses for the contextually relevant questions. Such repetitions might create biases in interpreting the responses. Hence, transcripts also need to be edited rationally by highlighting significant contents and developing an index of keywords. This process would help researchers in eliminating the outliers from the data. Outliers are inconsistent in providing information and do not validate the data throughout the study. Such data must be removed from coding and content analysis.
Transcription in qualitative research constitutes a principal segment of the data analysis process, which should be clearly disclosed in the study design of a project. It is therefore essential for a transcription method to be congruent with the theoretical maxims of a specific investigation should be used. This practice determines the potential to use alternate processes for managing verbal interview data over the conventional verbatim transcription techniques if they are consistent with the underlying philosophy of the study design.
Data Coding and Content Analysis
Data coding in qualitative research is a field-information identification tag, which facilitates researchers to carry out systematic information analysis. A code in qualitative inquiry is most often a set of alphanumeric fields or short phrases that symbolically assign the study area, subject’s identity such as age, gender, social hierarchy occupation and so on. and order of interview, language, data, time, and other significant identification marks. It is a summative, salient, essence-capturing, and/or evocative attribute for a narrative or visual data. Such code can be easily segmented for arraying the interview transcripts, participant observation, field notes, journals, documents, literature, artifacts, photographs, video, websites, and e-mail correspondence. In developing a storyboard of the interviews, the portion of data to be coded during first cycle coding process can range in magnitude from a single word to longer phrase to a stream of moving information. In second cycle coding processes, the coded portions can be the exact same units, longer passages of text, and even a reconfiguration of the codes themselves developed thus far. Such coding exercise can be done for longitudinal qualitative studies, which are spread across the geo-demographic and temporal indicators. For example, coding of narratives in the qualitative research can be used as discussed in Table 3.1.
Table 3.1 Coding example for narratives in qualitative research
|
Subject Tag |
Narrative |
Content Analysis Code |
|
S1-NY-Brand-M-32-En-Ex-100318-113025 |
…when I use vogue brands, I feel confident, and it allows me to enter high profile social circles... |
Trend-personality Sub Contents Code: Anthropomorphic behavior (AB) |
|
S2-NJ-Brand-F-24-En-St-100318-113025 |
...vogue in the market is created by social interaction and behavioral brands are positioned by word-of- |
Trend-co-creation Sub Contents Code: Innovation and consumer value (ICV) |
It can be seen from the Table 3.1 that subject tag can hold the information like subject identity (S-1), study area (NY), construct classification (Brand), gender (M), age (32), language (En-English), occupation (Ex-executive), and date and time of the interview. The relevant narrative can be cited in the adjacent column, and content analysis code can be generated. Such coding would facilitate researchers to carry out contents analysis systematically. The content analysis code can be further subcoded to indicate the section of analysis in which the information can be used as a subsequent effect. In Table 3.1, the subcontents analysis codes refer to personality leading to anthropomorphic behavior (AB), and co-creation of trends leads to innovation and consumer value (ICV). However, while developing subcodes for contents analysis, researchers should consider the following variants (Hatch 2002) in the information:
- Similarity in information that explains no variation in the contextual meanings.
- Differences in the expressions that indicate predictability in the contextual responses.
- Frequency of information, which indicates biasness unless it refers to a different context.
- Sequential information that explains continuous impact on related variables of the study.
- Correspondence of information that create interconnectivity of events, and
- Causation that explains as one effects appears to cause another.
The coding of information is required to develop an appropriate contents analysis plan, and perceive and interpret what is happening in the data by filtering the redundancy and biasness in the information. In live coding process, researchers keep the data rooted in the participant’s own language, while the ethnographers employ descriptive coding to document and categorize the breadth of opinions stated by multiple participants. However, a social theorist may employ values coding to capture and label subjective perspectives. Coding is a heuristic process of discovering an exploratory problem-solving technique without mathematical formulas to follow. It is the initial step to analyze the qualitative information systematically. Coding is not just labeling, it is a process of linking variables to validate the research constructs. In qualitative inquiries such as case studies, ethnographic and phenomenological research, coding decisions affect the content analysis (Creswell 2007). Coding of information must be done by research proposition, constructs, and content categories to be analyzed. For example, in a social innovation research project, the hierarchical coding pattern can be planned in the following way:
- Community requirement
º Code: Need
º Code: Health
º Code: Infrastructure
- Social innovation
º Code: Accessibility
º Code: Cost
º Code: Type
The coding structure has two levels: domains and taxonomy. Domains are the broad dimensions of the research, whereas the taxonomy of codes represents the factors associated with the domains as discussed earlier in case of social innovation research. Some categories may contain clusters of coded data that merit further refinement into subcategories, which would help researchers to arrange the codes in thematic, conceptual, and theoretical domains for analyzing the contents.
In the coding process, the researcher must familiarize with the data and read the transcribed text to obtain the sense of the whole conversation. Later the narrations can be fragmented into smaller, meaning units. A meaning unit is the smallest unit that contains some of the insights into the researcher needs. These small meaning units can be phrases, or the constellation of sentences or paragraphs containing interrelated aspects of the narrations. In this process, each identified meaning unit is labeled with a code, which should be contextually understood to carry out the contents analysis (Graneheim and Lundman 2004). Coding in qualitative research is a dynamic process. Codes created inductively by the researchers by understanding the responses or drawing inferences, may change as the study progresses, and more data become available. Therefore, interpretations of the meaning units of codes that seem clear at the beginning might turn obscure during the process. Some of the qualitative data analysis software can fix the dynamic coding issue, but since computer programs are not embedded with the artificial intelligence to understand the verbal expressions and emotions, the human creativity is of importance.
Content Analysis
Content analysis in qualitative research is the most important step, which helps researchers draw appropriate inferences from the coded data, develop conclusions, and validate the grounded theory. It is a systematic approach to analyze information form the interviews, focus groups, opinion polls, open-ended survey, and text-data-mining outlets. A variety of strategies to categorize, compare, fragment, and integrate information can be used in content analysis. In addition, researchers can able to interpret several key trends, new social and economic values, and consumer perceptions based on the verbal and nonverbal information collected through research. To begin with the content analysis process, keywords need to be indexed under appropriate categories of the research, required for interpretation. The categorical separation of positive and negative perceptions emerging out the responses of subjects and researcher’s observations facilitates systematic interpretation of the filtered information. The standard procedure of content analysis includes the following sequential stages:
- Coding/indexing
- Categorization
- Abstraction
- Comparison
- Defining dimensions of the data
- Triangulation and data integration
- Iteration
- Refutation (subjecting inferences to scrutiny)
- Interpretation (grasp of meaning, difficult to describe procedurally)
Besides coding/indexing and categorization discussed earlier, one of the challenges with the qualitative researchers is to prepare abstract of information acquired during the interview or field survey. Definition of keywords, and translation and description of the label are essential stages that determine the level of abstraction of data analysis and building of analytical themes. In analyzing the narrative information contents, language must be appropriately used as it impacts the quality of abstraction of theme(s). Recursive abstraction is a simple method based on summarizing the data in steps. It starts by summarizing a larger set of data (e.g., large text abstracted to S1), then summarizing the summarized portion (e.g., the abstracted S1 text to be summarized to S2) and so on, until a very focused and compact summary is reached close to accuracy and distinction. It is highly challenging for researchers to maintain precision in abstracting narrations of the broad-focused and open-ended qualitative inquiries. Upon completing the process of recursive abstraction, researcher can easily compare the text, re-assign codes, and draw inferences. Then researchers can develop broad dimensions of the data for constructing appropriate research propositions and refine the grounded theory of qualitative research (Hershkowitz, Schwarz, and Dreyfus 2001). By defining subsectors of inquiry on a broad theme, research dimensions can be added to stay more focused in carrying out content analysis. For example, in the qualitative inquiry on impact of social development, the sectoral dimensions of the social development can be created as health, education, housing, infrastructure and the like.
Most researchers blend qualitative and quantitative methods to examine different aspects of an overall research question. For example, they might use a randomized controlled trial to assess the effectiveness of a health care intervention through semi-structured interviews with patients and health professionals to consider the way the intervention practically affected the health conditions of the subjects. Data analysis is carried out in an integrated way to combine these findings and define this mixed analytical process as triangulation. In this process, the data sets for both methods are used separately by considering 3C’s: appropriate convergence, complementarity, and consistency of the data. All care is taken to establish integration of findings from each method to ensure that the results offer total agreement (convergence), offer complementary information on the same issue (complementarity), and appear to be nondiscrepant (consistency). The triangulation and data integration methods thus support each other to validate the qualitative inquiries of a large database (Farmer et al. 2006).
Iterative data refers to a systematic, repetitive, and recursive process in qualitative data analysis. This involves a sequence of tasks carried out in the same manner each time to extract the core contents and executed multiple times to refine the information (Mills, Durepos and Wiebe 2010). Iteration of narrations are the vigor of verbal and nonverbal expressions, which need to be coded and analyzed in the original form or by rationally modifying the text. Qualitative researchers also need to carefully examine the embedded meaning emerging out of the conversations, as the same idea embedded in the narration may be extended to contradictory explanations though there are sound arguments for a particular pattern. Such narrations need to be scrutinized to ensure whether they support or refute the analytical results (de Vaus 2009). Qualitative data can be interpreted appropriately after passing through all the stages of data analysis as discussed earlier.
Content analysis of qualitative information has changed over time from counting frequencies of critical words to a more interpretive approach. One of the principal challenges in analyzing the contents of qualitative inquiries is to differentiate between abstraction level and degree of flexibility in interpretation of contents spread across keywords, critical words, phrases, concepts, observations, and field notes. Analysis of qualitative contents helps to demonstrate inductive and deductive (epistemological) theories. In this process, the level of abstracting information and degree of interpretation are used in constructing categories, descriptive themes, and themes of meaning. However, unless the content analysis validates the grounded theory, its credibility and authenticity are always questionable (Graneheim, Lindgren, and Lundman 2017).
The contents analysis is carried out and interpreted in context to the research background, which may vary as political economic, technological, consumer behavior, market competition, and several other fields are dynamics. The thumb rule of analysis suggests that the qualitative research material should be analyzed systematically, variable-by-variable, question-by-question, or objective by objectives of the study to validate the predetermined research propositions. Following analytics procedure, researcher should divide the complete information into small content analytical units for categorical content analysis. The aspects of text interpretation following the research questions are put into categories, which have been carefully founded and revised within the process of analysis as feedback loops. The researcher should establish criteria of reliability and validity for qualifying the information in categorized variable segments.
Content analysis has three distinct approaches, which include conventional, directed, or summative methodologies. All three approaches are used to interpret meaning from the content of text data and, hence, adhere to the naturalistic paradigm. The major differences among these approaches are coding schemes, origins of codes, and threats to trustworthiness. In conventional content analysis, coding categories are derived directly from the text data. With a directed approach, analysis starts with a theory or relevant research findings as guidance for initial codes. A summative content analysis involves counting and comparisons, usually of keywords or content, followed by the interpretation of the underlying context (Hsieh and Shannon 2005).
Before taking up the content analysis, researchers must ensure that sources of the data are valid and reliable, and the coding categories are appropriately created, representing the data holistically. In addition, it is necessary to explore by observing the qualitative data whether the analysis can be generalized at the macro-, meso-, or micro-level. Accordingly, the contents analysis process can be scheduled by coding data, assessing the data reliability, and analyzing the results based on coding schemes. However, in the process of content analysis, it is important to eliminate perceptional biases and validate the interpretations across responses in the survey. In all types of analysis of qualitative data, regardless of whether it is within a positivist or naturalistic research tradition, the purpose of content analysis is to organize and elicit meaning from the data collected and draw realistic conclusions.
In a more liberal way, the content analysis can be used in both quantitative and qualitative methodologies in an inductive or a deductive way. For example, in a qualitative research study to measure the impact of media communications on social development, qualitative content analysis is predominant in social research, while quantitative content analysis can be conducted to measure the media effect. However, the researcher has to choose whether the analysis is to be a manifest analysis or a latent analysis. In a manifest analysis, the researcher describes verbatim what the informants actually say, stays very close to the text, uses the popular words of subjects, and describes them visible and obvious in the text. On the contrary, latent analysis is extended to an interpretive level where a researcher explores the underlying meaning of the text and draws implicit inferences (Bengtsson 2016).
Computer-Aided Qualitative Research
Computer-based analysis of qualitative information is growing over the manual processing of unorganized data. Researchers managing qualitative data analysis across disciplines increasingly face problems in handling narrations and text-data-mining processing. Consequently, there is a growing literature on computer-assisted qualitative data analysis software (CAQDAS). Various software such as NVivo, Atlas.ti, and MAXQDA emerged as commercial off-the-shelf technologies, evolved over time from pioneering programmable software development industry during the 1980s, and became available for public use within a decade. Other software to assist the qualitative research analysis include QDA Miner, Dedoose, and HyperRESEARCH. These computer-aided qualitative research tools helped the researchers enhance their ability to search, categorize, examine, and develop identifiable content analysis patterns in each specific research in large data sets. Working with the computer-aided software, researchers benefit the following functions to carry out skillfully:
- Organize qualitative data.
- Manage fragmented qualitative data.
- Create memos identifying initial thoughts.
- Organize field notes and observations of researcher.
- Assign codes to qualitative data.
- Combining and assemble codes under multi-layer categories or themes.
- Generate word, phrases frequency searches, and develop semantic map.
- Conducting content analysis.
- Create mind maps to organize perceptions of subjects and researcher’s concepts.
The previously stated software for qualitative data analysis allows researchers to upload text documents to a new project, which can be titled for each observation, and initiate the coding and data analysis process. Some CAQDAS only use text, whereas others can import images, audio and video data, newspaper clippings, and books. The software systems also have the capability to auto-define and organize coding and text information, and analyze relationships across the coded variables and predetermined themes in the data sets. Some of the available software packages with these features include Ethnograph, Atlas Ti, NVivo, and Qualrus. The use of software for qualitative research prompts researchers to analyze simultaneous contents and examine multilayer data set with computer-assisted arraying patterns to conduct systematic analysis. In this manner, the scientific rigor of qualitative research is enhanced, and an audit trail is created about the actions performed by the software. However, the debate on CAQDAS is bidirectional to explain the merits and demerits of computer-aided analysis for qualitative data. While using the software, a trail of analysis needs to be preserved to replicate the research and develop transparency in content analysis (Conrad and Reinharz 1984). Many software systems support retrievals, and searches on data can be repeated in a consistent way, which enables researchers to conduct retrospective checks to ascertain whether the analysis is streamlined (Fielding and Lee 1998). However, it has often argued that an audit trail computer-aided data analytics is not always automatic and still requires systematic and structured record keeping by the researchers (Miles and Huberman 1994).
One of the advantages of CAQDAS is that it enables the researcher to focus on analytical techniques, enhancing intellectual thoughts in developing data interpretation, and drawing appropriate inferences, rather than engaging in manual tasks. However, the major underlying problem with the usage of software for qualitative information analysis is that implicit assumptions of the software architecture interferes with the qualitative research process, and results in corrupting the expressions, meaning and interpretation that the qualitative data bring with manual analysis process (Rodik and Primorac 2015).
Some software such as “Atlas.ti” appears to be a powerful workbench for qualitative data analysis, particularly for large sections of text, visual, and audio data. This software offers support to the researchers to analyze and interpret text using coding and annotating activities during data analysis process. Software that have applications for comprehensive analysis benefit researchers in several ways right from data collection process to reporting stage. Using the software, researchers can search for similarities and differences in narrations, transcript texts, codes and categories, themes, concepts, and manage continuous process of information input and output analysis. Content analysis commences with reading all the data and then dividing the data into smaller more meaningful units. In the qualitative research, data segments are organized into a system that is predominantly derived from the data, which implies that the analysis is inductive. The CAQDAS help researchers to map comparisons to build and refine categories, define conceptual similarities, and to discover new patterns of responses.
Some sociological researchers have used the CAQDAS as a tool for conversation analysis (CA). The application of CA through computer-aided software have been expanded to research in the areas of anthropology, communication, and linguistics. The advancement of research technology in social sciences and computer sciences has proved to provide testament to the robust findings of earlier studies using CA methodology growth for five decades (Kasper and Wagner 2014). Over time, the “applied conversation analysis” is conducted in many areas and types of studies beyond social sciences such as clinical qualitative studies and macro-societal issues (Antaki 2011).
The debate on CAQDAS brought several application issues about the reliability of results to the surface. However, software programmers and many qualitative researchers saw the benefits and potential of using software for analyzing qualitative data, but there remained difference in opinions, as software cannot substitute the human elements in describing the emotions, perceptions, and latent thoughts, which constitute the part of qualitative information.
Summary
Several perspectives and challenges in managing qualitative information have been discussed in this chapter. Management of qualitative data is often difficult, as often researchers are not aware of the expected volume of information despite the sample population of subjects being specified. Proper data management is necessary to maintain the security of the data for conducting meta-analysis and data interpretations in the longitudinal studies. Qualitative data management needs confidentiality to protect the information of subjects and professional commitment to the participants in the qualitative inquiry process. Acquiring information through qualitative instruments, analyzing content, and drawing inferences is a scientific approach while blending such inferences with informal observations, filed notes, and public views is an art in qualitative research, as it needs a rationale and community sensitive vision.
Collecting information during qualitative inquiries provides ample scope of acquiring comprehensive data to conduct multilayered content analysis. However, mismanagement of data causes nonretrieval and redundancy problems. Besides the mechanical approaches to store and retrieve the data, researchers also need to manage subjects in retrieving the information. Researchers must understand the cognitive ecosystem of subjects, and manage the information emerging from conscious mind and stored in the subconscious memories. The content analysis of descriptive information needs to be done spanning from macro to micro perspectives. Research questions can be broadly classified into three categories: conceptual, problem-based, and knowledge-driven perspectives.
Qualitative researchers often face metaphoric expressions of subjects while responding to the interview questions. Sensory cognition and episodic memories facilitate the cognitive analysis of information. Transcription is necessary for open-ended responses, information of focus groups, observation, spoken language and slang expressions, and individual interviews.
Data coding, defined as a field information identification tag, is a necessary step in qualitative research, which facilitates researchers to carry out systematic information analysis. A code in qualitative inquiry is most often a set of alphanumeric fields or short phrases. The coding of information is required to develop an appropriate contents analysis plan to perceive and interpret information. It is a systematic approach to analyze information form the interviews, focus groups, opinion polls, open-ended survey, and text-data-mining outlets. A variety of strategies to categorize, compare, fragment, and integrate information can be used in content analysis. Content analysis has three distinct approaches, which include conventional, directed, or summative methodologies.
Though the computer-based analysis of qualitative information is growing over the manual processing of unorganized data, researchers managing qualitative data analysis across disciplines increasingly face problems in handling narrations and text-data-mining processing.
References
Antaki, C. 2011. Applied Conversation Analysis. Basingstoke: Palgrave Macmillan.
Arora, R., and C. Stoner. 2009. “A Mixed Method Approach to Understanding Brand Personality.” Journal of Product & Brand Management 18, no. 4, pp. 272–83.
Banner, D.J., and J.W. Albarran. 2009. “Computer-assisted Qualitative Data Analysis Software: A Review.” Canadian Journal of Cardiovascular Nursing 19, no. 3, pp. 24–27.
Bengtsson, M. 2016. “How to Plan and Perform a Qualitative Study Using Content Analysis. Nursing Plus Open 2, no. 1, pp. 8–14.
Conrad, P., and S. Reinharz. 1984. “CAQDAS Software and Qualitative Data: Editors Introductory Essay.” Qualitative Sociology 7, nos. 1/2, pp. 3–15.
Creswell, J.W. 2005. Educational Research: Planning, Conducting, and Evaluating Quantitative and Qualitative Research. Upper Saddle River, New Jersey: Pearson Education.
Creswell, J.W. 2007. Qualitative Inquiry and Research Design: Choosing Among Five Traditions. Thousand Oaks, CA: Sage.
Danes, J.E., J.S. Hess, J.W. Story, and J.L. York. 2010. “Brand Image Associations for Large Virtual Groups.” Qualitative Market Research: An International Journal 13, no. 3, pp. 309–23.
de Vaus, D. 2009. Research Design in Social Research. Thousand Oaks, CA: Sage.
Farmer, T., K. Robinson, S.J. Elliott, and J. Eyles. 2006. “Developing and Implementing a Triangulation Protocol for Qualitative Health Research.” Qualitative Health Research 16, no. 3, pp. 377–94.
Fielding, N.G., and R.M. Lee. 1998. Computer Analysis and Qualitative Research. London Sage.
Graneheim, U.H., and B. Lundman. 2004. “Qualitative Content Analysis in Nursing Research: Concepts, Procedures and Measure to Achieve Trustworthiness.” Nurse Education Today 24, no. 1, pp. 105–12.
Graneheim, U.H., B.M. Lindgren, and B. Lundman. 2017. “Methodological Challenges in Qualitative Content Analysis: A Discussion Paper.” Nurse Education Today 56, no. 1, pp. 29–34.
Halcomb, E.J., and P.M. Davidson. 2006. “Is Verbatim Transcription of Interview Data Always Necessary?” Applied Nursing Research 19, no. 1, pp. 38–42.
Hardy, L.J., A. Hughes, E. Hulen, and A.L. Schwartz. 2016. “Implementing Qualitative Data Management Plans to Ensure Ethical Standards in Multi-partner Centers.” Journal of Empirical Research on Human Research Ethics 11, no. 2, pp. 191–98.
Hatch, A.J. 2002. Doing Qualitative Research in Education Setting. New York, NY: State University of New York Press.
Hershkowitz, R., B.B. Schwarz, and T. Dreyfus. 2001. “Abstraction in Context: Epistemic Actions.” Journal for Research in Mathematics Education 32, no. 2, pp. 195–222.
Hooper, C.S. 2011. “Qualitative in Context.” Journal of Advertising Research 51, pp. 163–66.
Kasper, G., and J. Wagner. 2014. “Conversation Analysis in Applied Linguistics.” Annual Review of Applied Linguistics 34, no. 1, pp. 171–212.
Levine, H.G. 1985. “Principles of Data Storage and Retrieval for Use in Qualitative Evaluations.” Educational Evaluation and Policy Analysis 7, no. 2, pp. 169–86.
Lin, L.C. 2009. “Data Management and Security in Qualitative Research.” Dimensions of Critical Care Nursing 28, no. 3, pp. 132–37.
MacQueen, K.M., and B. Milstein. 1999. “A Systems Approach to Qualitative Data Management and Analysis.” Field Methods 11, no. 1, pp. 27–39.
Manderson, L., M. Kelaher, and N. Woelz-Stirling. 2001. “Developing Qualitative Databases for Multiple Users.” Qualitative Health Research 11, no. 2, pp. 149–60.
Mesulam, M.M. 1998. “From Sensation to Cognition.” Brain 121, no. 6, pp. 1013–52.
Miles, M.B., and A.M. Huberman. 1994. Qualitative Data Analysis: A Sourcebook of New Methods. Beverly Hills, CA: Sage.
Mills, A.J., G. Durepos, and E. Wiebe. 2010. Encyclopedia of Case Study Research. Thousand Oaks, CA: Sage.
Pinch, W.J.E. 2000. “Confidentiality: Concept Analysis and Clinical Application.” Nursing Forum 35, no. 2, pp. 5–16.
Rodik, P., and J. Primorac. 2015. “To Use or Not to Use: Computer-Assisted Qualitative Data Analysis Software Usage among Early-Career Sociologists in Croatia.” Forum: Qualitative Social Research 16, no. 1, p. Art. 12.
Rosciano, A. 2015. “The Effectiveness of Mind Mapping as an Active Learning Strategy Among Associate Degree Nursing Students.” Teaching and Learning in Nursing 10, no. 2, pp. 93–99.
Wheeler, M.E., and E.J. Ploran. 2009. “Episodic Memory.” In Encyclopedia of Neuroscience, ed. L.R. Squire, 1167–72. Cambridge, MA: Academic Press.
Woogara, J. 2015. “Patients’ Privacy of the Person and Human Rights.” Nursing Ethics 12, no. 3, pp. 273–87.