
Elasticsearch provides a helper to build complex span queries that depend on simple preconfigured settings. This helper is called match query.
You need an up-and-running Elasticsearch installation as we described in the Downloading and installing Elasticsearch recipe in Chapter 2, Downloading and Setup.
To execute curl via the command line, you need to install curl for your operative system.
To correctly execute the following commands, you need an index populated with the chapter_05/populate_query.sh script available in the online code.
For executing match queries, we will perform the following steps:
- The standard usage of a match query simply requires the field name and the query text. Consider the following example:
curl -XPOST 'http://127.0.0.1:9200/test-index/test- type/_search?pretty=true' -d '{ "query": { "match" : { "parsedtext" : { "query": "nice guy", "operator": "and" } } } }' - If you need to execute the same query as a phrase query, the type from match changes in
match_phrase:curl -XPOST 'http://127.0.0.1:9200/test-index/test- type/_search?pretty=true' -d '{ "query": { "match_phrase" : { "parsedtext" : "nice guy" } } }' - An extension of the previous query used in text completion or
search as you typefunctionality ismatch_phrase_prefix:curl -XPOST 'http://127.0.0.1:9200/test-index/test- type/_search?pretty=true' -d '{ "query": { "match_phrase_prefix" : { "parsedtext" : "nice gu" } } }' - A common requirement is the possibility to search for several fields with the same query. The
multi_matchparameter provides this capability:curl -XPOST 'http://127.0.0.1:9200/test-index/test- type/_search?pretty=true' -d '{ "query": { "multi_match" : { "fields":["parsedtext", "name"], "query": "Bill", "operator": "and" } } }'
The match query aggregates several frequent-used query types that cover standard query scenarios.
The standard match query creates a boolean query that can be controlled by these parameters:
operator: This defines how to store and process the terms. If it's set toOR, all the terms are converted in a boolean query with all the terms in should clauses. If it's set toAND, the terms build a list of must clauses (defaultOR).analyzer: This allows overriding the default analyzer of the field (default based on mapping or set in searcher).fuzziness: This allows defining fuzzy term. Related to this parameter,prefix_lengthandmax_expansionare available.zero_terms_query (none/all): This allows you to define a tokenizer filter that removes all terms from the query, the default behavior is to return nothing or all the documents. This is the case when you build an English query searching fortheorathat means it could match all the documents (defaultnone).cutoff_frequency: This allows handling dynamic stopwords (very common terms in text) at runtime. During query execution, terms over thecutoff_frequencyare considered stopwords. This approach is very useful as it allows converting a general query to a domain-specific query, because terms to skip depend on text statistics. The correct value must be defined empirically.
The boolean query created from the match query is very handy, but it suffers from some common problems related to Boolean query such as term position. If the term position matters, you need to use another family of match queries, the phrase one.
The match_phrase type in match query builds long span queries from the query text.
The parameters that can be used to improve the quality of phrase query are the analyzer for text processing and the slop, which controls the distance between terms (refer to the Using span queries recipe).
If the last term is partially complete and you want to provide your users query while writing functionality, the phrase type can be set to match_phrase_prefix. This type builds a span near query in which the last clause is a span prefix term. This functionality is often used for typehead widgets such as the one shown in the following screenshot:
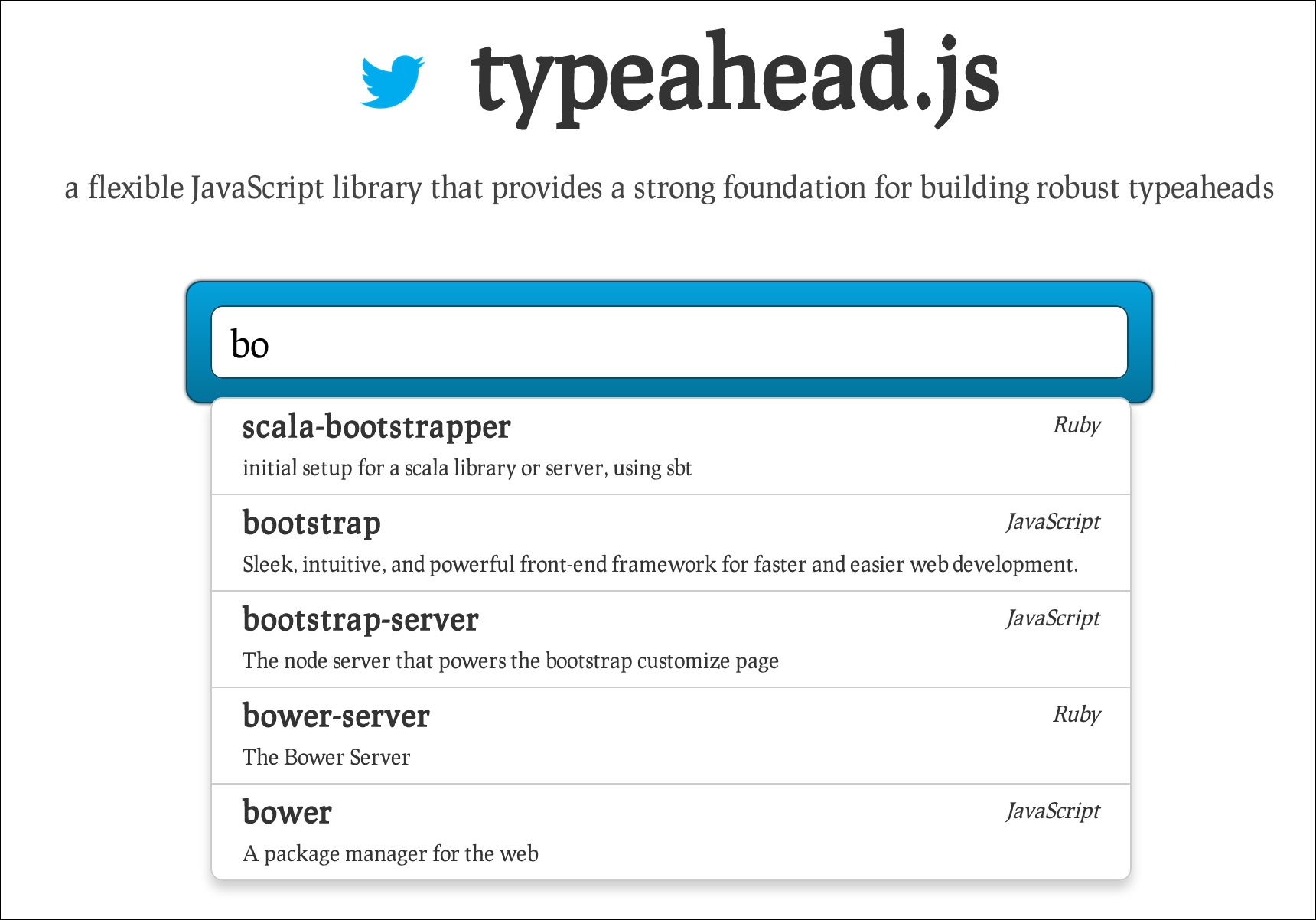
The match query is a very useful query type or, as I previously defined, it is a helper to build several common queries internally.
The multi_match parameter is similar to a match query that allows to define multiple fields to search on. For defining these fields, there are several helpers that can be used such as:
- Wildcards field definition: Using wildcards is a simple way to define multiple fields in one shot. For example, if you have fields for languages such as
name_en,name_es, andname_it, you can define the search field asname_*to automatically search all the name fields. - Boosting some fields: Not all the fields have the same importance. You can boost your fields using the
^operator. For example, you have title and content fields and title is more important than content; you can define the fields in this way:
"fields":["title^3", "content"]