
In the previous chapter, we looked at what the difference is when a field becomes indexed and searchable and at how the analysis process affects the relevant search results. In this chapter, we will dive deep into the concept of the Elasticsearch index. Therefore, we will first go through basic concepts. Then we will examine the inverted index data structure. By the end of this chapter, we will have covered the following topics:
- What is dynamic mapping?
- What is denormalization?
- Is index flexible?
- What is the inverted index?
Let's go through the basic concepts of Elasticsearch indices and their features.
Elasticsearch is document-oriented. Each record in Elasticsearch is a document. Elasticsearch uses JSON (JavaScript Object Notation) as the serialization format for documents. Therefore, each piece of data that is sent to Elasticsearch for indexing is a JSON document.
Tip
JSON is an open standard format that uses human-readable text to transmit data objects consisting of attribute–value pairs. If you want more information, please refer to https://en.wikipedia.org/wiki/JSON.
Elasticsearch indices compared to database management systems may be considered to be databases. How a database is a collection of regular information, Elasticsearch indices are a collection of structured JSON document. In other words, an index is a logical partition for user data.
Documents are stored in the same index of similar characteristics, for example, your member data in the member index, your customer data in the customer index, and so on. In this sense, the index names refer to grouped documents. Like in SQL world, a database name refers to a regular collection of information.
As mentioned in the previous chapter, Elasticsearch uses the Apache Lucene library for writing and reading the data from the index. Apache Lucene stores all data in a data structure called an inverted index. An inverted index is a data structure mapped to documents and terms. We will examine the Inverted Index data structure in detail after discussing the basic concepts.
When it comes to indices, we need to talk about the data distribution mechanism used by Elasticsearch. Elasticsearch uses shards and replicas in order to distribute data around the cluster.
Elasticsearch distributes data to more than one Lucene index as physical by default. These indices are called shards and this distribution process is called sharding. A shard is automatically managed by Elasticsearch. It is a low-level worker unit. Take a look at the following distribution strategy:
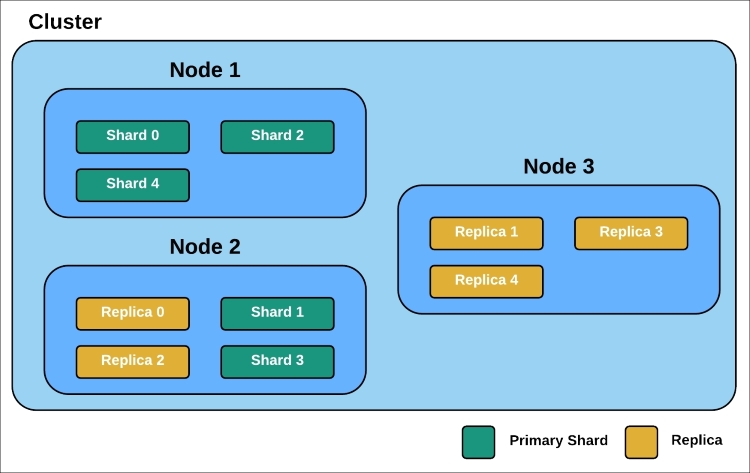
Understanding the distribution strategy of Elasticsearch is important in the context of efficient indexing, and this topic will be dealt with in greater detail in Chapter 5, Anatomy of an Elasticsearch Cluster with shards and replicas.
When trying to understand the nature of Elasticsearch index, we need to look closely at the concept of mapping.
Mapping is the process of defining how a document should be indexed to Elasticsearch. In addition to this, how to analyze the fields of the target query is determined by mapping.
Types are created according to the mapping information. It is important to know that Elasticsearch creates mapping automatically based on the data sent. When data is added, Elasticsearch tries to identify the data structure and makes it searchable. This process is known as dynamic mapping.
Mapping is very important for relevant search results, and from this point it should be understood quite well that how a field is analyzed is determined by mapping.
Elasticsearch indices contain one or more type(s). Types can be considered as tables, again compared to database management systems. Types ensure grouped documents under indices like tables do.
It is important to understand that although documents are grouped with similar characteristics under indices and types, Elasticsearch is not limiting in our search to a particular index or type:
curl -XGET localhost:9200/ purchaser,vendor/_search -d '{
"query": {
"match": {
"country": "Turkey"
}
}
}'In the preceding example, we have searched across all documents in the purchaser and vendor indices without specifying the type:
curl -XGET localhost:9200/publisher/author,reviewer/_search -d '{
"query": {
"match": {
"city": "İstanbul"
}
}
}'This time we have searched across all documents in the author and reviewer types of the publisher index.