
Chapter Highlights
• Introduction to Machine Learning: What is machine learning?
• Machine Learning and Artificial Intelligence (AI)
• Examples of Some Problems Where Machine Learning Is Applied
• Types of Problems Machine Learning Can Solve
• Supervised Learning: Classification
• Regression
• Unsupervised Learning
• Clustering and Types of Clustering
• Examples of Classification Problems: Examples
• Clustering Problems: Examples
• Programming Languages used in Machine Learning
• R-Statistical Programing Language
• Python Programing Language
• Automating the Machine Learning Problem
• SAS Machine Learning
• Microsoft Auto Machine Learning: Azur
What Is Machine Learning (ML)?
Machine learning is a method of designing systems that can learn, adjust, and improve based on the data fed to them without being explicitly programmed. Machine learning applications are a way of analyzing and creating models from huge amount of data commonly referred to as big data. Machine learning is closely related to artificial intelligence (AI). In fact, it is an application of artificial intelligence (AI).
Machine learning works based on predictive and statistical algorithms that are provided to these machines. The algorithms are designed to learn and improve as more data flows through the system. Fraud detection, e-mail spam, GPS systems are some examples of machine learning applications.
Machine learning applications are based on teaching a computer how to learn. Besides predictive and statistical algorithms, it also uses pattern recognition to draw conclusion from the data.
Machine learning methods are used to develop complex models and algorithms that help to understand and make predictions from the data. The analytical models in machine learning allow the analysts to make predictions by learning from the trends, patterns and relationships in the historical data. Machine learning automates model building. The algorithms in machine learning are designed to learn iteratively from data without being programmed.
According to Arthur Samuel, machine learning gives “computers the ability to learn without being explicitly programmed.”2 Samuel, an American pioneer in the field of computer gaming and artificial intelligence, coined the term “machine learning” in 1959 while at IBM.
Machine learning algorithms are extensively used for data-driven predictions and in decision making. Some applications where machine learning has been used are email filtering, detection of network intruders or detecting a data breach, optical character recognition (OCR), learning to rank, computer vision, and a wide range of engineering and business applications. Machine learning is employed in a range of computing tasks. Often designing and programming explicit algorithms that are reproducible and have repeatability with good performance is difficult or infeasible.
Machine Learning Methods and Tasks
At the fundamental level, Machine learning tasks are typically classified into following broad categories depending on the nature of the learning “signal” or “feedback” available to a learning system. These are20 (1) Supervised learning (2) Unsupervised learning.
In supervised learning, the computer is presented with example inputs and their desired outputs by the analyst, and the goal is to create a model to learn a general rule that maps inputs to outputs. The learning involves creating a model by establishing the relationship between inputs or the features and the desired output or some label. Once this model is established, it can be used to apply labels to new, unknown data to predict future events. The idea is to learn from the past data and apply to new data to make prediction for the future events using the created learning algorithm. The output from the learning algorithm can also compare its output to the known output to find the associated error that helps modify the model. The supervised learning problems can be divided into classification problems and regression problems.
Classification
Classification involves classifying the data into one or the other group. Here the labels are discrete categories where the inputs are divided into two or more classes, and the learner must produce a model that assigns unseen inputs to one or more (multilabel classification) of these classes. This is typically tackled in a supervised way.
Classification is a process of assigning items to pre specified classes or categories. For example, a financial institution may study the potential borrowers to predict whether a group of new borrowers may be classified as having a high degree of risk. Spam filtering is another example of classification, where the inputs are email messages that are classified into classes as “spam” and “no spam.”
Classification uses the algorithms to categorize the new data according to the observations of the training set. Classification is a supervised learning technique where a training set is used to find similarities in classes. This means that the input data are divided into two or more classes or categories and the learner creates a model that assigns inputs to one or more of these classes. This is typically done in a supervised way. The objects are classified, based on the training set of data. A classification problem is when the output variable is a category, such as e-mails can be classified as “spam” or “no spam” or a test can be classified as “negative” and “positive.”
The algorithm that implements classification is known as the classifier. Some of the most commonly used classification algorithms are K-Nearest Neighbor algorithm and decision tree algorithms. These are widely used in data mining. An example of classification would be credit card processing. A credit card company may want to segment customer database based on similar buying patterns.
Some of the commonly uses classification algorithms are:
• Decision trees and random forest
• Support vector machines (SVM) for classification problems
• Bayes classification
Regression
Regression is a supervised problem where the outputs are continuous rather than discrete. Regression problems are used to predict continuous labels. There are several regression models used in machine learning. These are linear and nonlinear regression, logistic regression, and others. Besides these the commonly used algorithms are support vector machines (SVM). These are the most widely used regression algorithms:
• Ordinary least squares regression (OLSR)
• Linear regression
• Logistic regression
• Stepwise regression
• Multivariate adaptive regression splines (MARS)
• Locally estimated scatterplot smoothing (LOESS)
Unsupervised Learning
As the name suggests, in unsupervised learning, no labels are given to the program. Unsupervised learning is where we have only have input data (X) and no corresponding output variables. The learning algorithm is expected to find the structure in its input. The goals of unsupervised learning may be finding hidden pattern in the large data. Thus, unsupervised learning process are not based on general rule of training the algorithms. The commonly used models in unsupervised learning include Clustering and Dimensionality reduction.
Clustering
In clustering, data is assigned to some number of discrete groups. In this type of problem, a set of inputs is to be divided into groups. Unlike in classification, the groups are not known beforehand, making this typically an unsupervised task.
Clustering technique is used to find natural groupings or clusters in a set of data without prespecifying a set of categories. It is unlike classification where the objects are classified based on pre specified classes or categories. Thus, clustering is an unsupervised learning technique where a training set is not used. It uses statistical tools and concepts to create clusters with similar features within the data. Some examples of clustering are as follows:
• Cluster of houses in a town into neighborhoods based on similar features like houses with overall value of over million dollars.
• Marketing analyst may define distinct groups in their customer bases to develop targeted marketing programs.
• City planning may be interested in identifying groups of houses according to their house value, type, and location.
• In cellular manufacturing, the clustering algorithms are used to form the clusters of similar machines and processes to form machine-component cells.
• Scientists and geologists may study the earthquake epicenters to identify clusters of fault lines with high probability of possible earthquake occurrences.
Cluster analysis is the assignment of a set of observations into subsets (called clusters) so that observations within the same cluster are similar according to some prespecified criterion or criteria, while observations drawn from different clusters are dissimilar. Clustering techniques differ in application and make different assumptions on the structure of the data. In clustering, the clusters are commonly defined by some similarity metric or similarity coefficient and may be evaluated by internal compactness (similarity between members of the same cluster) and separation between different clusters. Other clustering methods are based on estimated density and graph connectivity. It is important to note that clustering is unsupervised learning, and commonly used method in statistical data analysis. The well-known and used clustering algorithms are K-means clustering, spectral clustering, and Gaussian mixture models.
The goal of Clustering algorithms is to identify distinct groups of data.
Dimensionality Reduction
In machine learning problems involving classification, there are often too many factors or variables originally that need to be considered for classification These variables are commonly referred to as features. A large numbers of features makes it hard to visualize the training set and then work on it. These features may also be correlated that make them redundant. In such cases, dimensionality reduction algorithms are used to reduce the number of variables under consideration. These reduction algorithms help to obtain a set of key variables. Dimensionality reduction consists of feature selection and feature extraction.
Some examples where dimensionality reduction algorithms have been used are credit card fraud detection and spam filtering. These may involve many features that may overlap or are correlated. In such cases, reducing the number of features is very helpful in visualizing the problem. For example, a 3-D classification problem can be reduced to a 2-D problem that can make the visualization easier.
Difference Between Clustering and Classification
Clustering is an unsupervised learning technique used to find groups or clusters of similar instances based on features. The purpose of clustering is a process of grouping similar objects to determine whether there is any relationship between them. Classification is a supervised learning technique used to find similarities in classification based on a training set. It uses algorithms to categorize the new data according to the observations in the training set. Table 13.1 outlines the differences between classification and clustering.
Table 13.1 Difference between classification and clustering
Classification |
Clustering |
Classification is supervised learning technique where items are assigned to pre specified classes or categories. For example, a bank may study the potential borrowers to predict whether a group of new borrowers may be classified as having a high degree of risk. |
Clustering is unsupervised technique used to find natural groupings or clusters in a set of data without pre specifying a set of categories. It is unlike classification where the objects are classified based on pre specified classes or categories. |
Classification algorithm requires training data. |
Clustering does not require training data. |
Classification uses predefined instances. |
Clustering does not assign pre-defined label to each and every group. |
In classification, the groups (or classes) are pre-specified with each training data instance that belongs to a particular class. |
In clustering the groups (or clusters) are based on the similarities of data instances to each other. |
Classification algorithms are supposed |
Unlike in classification, the groups are not known beforehand, making this an unsupervised task. |
Example: An insurance company trying to assign customers into high risk and low risk categories. |
Example: Drop box, a movie rental company may recommend a movie to customers because others who had made similar movie choices in the past have favorably rated that movie. |
Other Classes of Machine Learning Problems
There are other classes of machine learning problems that fall in between supervised and unsupervised learning problems. These are semisupervised machine learning algorithms and reinforcement learning.
Semisupervised Machine Learning Algorithms
These algorithms fall in between supervised and unsupervised learning. They are designed with both labeled and unlabeled data for training and may contain typically a small amount of labeled data and a large amount of unlabeled data. These systems may in some cases be more efficient and are able to considerably improve learning accuracy. The semisupervised learning methods are usually used when the labeled data requires skilled resources to train or learn from it. The acquired unlabeled data generally doesn’t require additional resources.
In this type of learning, the designed computer program interacts with a dynamic environment in which it has a specific goal to perform. This differs from standard supervised learning as no input/output pairs are provided which involves finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).6 Examples of reinforced learning are playing a game against an opponent. In this type of learning, the computer program is provided feedback in terms of rewards and punishments as it navigates its problem space.
Other Applications of Machine Learning
Another application of machine learning is in the area of deep learning,25 which is based on artificial neural networks.6 In his application, the learning tasks may contain more than one hidden layer or tasks with a single hidden layer known as shallow learning.
Artificial Neural Networks
An artificial neural network6,7 (ANN) learning algorithm, usually called “neural network” (NN), is a learning algorithm that is inspired by the structure and functional aspects of biological neural networks. Computations are structured in terms of an interconnected group of artificial neurons, processing information using a connectionist approach to computation. Modern neural networks are nonlinear statistical data modeling tools. They are usually used to model complex relationships between inputs and outputs, to find patterns in data, or to capture the statistical structure in an unknown joint probability distribution between observed variables.
Deep learning8
Falling hardware prices and the development of GPUs for personal use in the last few years have contributed to the development of the concept of deep learning, which consists of multiple hidden layers in an artificial neural network. This approach tries to model the way the human brain processes light and sound into vision and hearing. Some successful applications of deep learning are computer vision and speech recognition.
Note: Neural networks use machine learning algorithms whereas machine leaning is an application of artificial intelligence9 that automates analytical model building by using algorithms that iteratively learn from data without being explicitly programmed.
Machine Learning and Data Mining
Machine learning and data mining are similar in some ways and often overlap in applications. Machine learning is used for prediction, based on known properties learned from the training data whereas data mining algorithms are used for discovery of (previously) unknown patterns. Data mining is concerned with knowledge discovery in databases (or KDD).
Data mining uses many machine learning methods. On the other hand, machine learning also employs data mining methods as “unsupervised learning” or as a preprocessing step to improve learner accuracy. The goals are somewhat different. The performance of the machine learning is usually evaluated with respect to the ability to reproduce known knowledge. In data mining, which is knowledge discovery from the data (KDD) the key task is the discovery of previously unknown knowledge. Unlike machine learning which is evaluated with respect to known knowledge, data mining uses uninformed or unsupervised methods that often outperform compared to other supervised methods. In a typical KDD task, supervised methods cannot be used due to the unavailability of training data. Figure 13.1 outlines the predictive and descriptive data mining learning techniques along with supervised and unsupervised leaning techniques. A number of data mining and machine learning methods overlap in applications. As indicated earlier, data mining is concerned with knowledge discovery from the data (KDD) where the key task is the discovery of previously unknown knowledge.
Machine learning, on the other hand, is evaluated with respect to known knowledge. According to Arthur Samuel, machine learning gives “computers the ability to learn without being explicitly programmed.”2
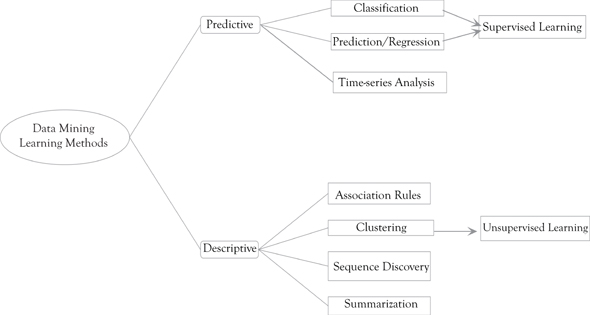
Figure 13.1 Predictive and descriptive data mining
Machine learning methods use complex models and algorithms that are used to make predictions. The machine learning models allow the analysts to make predictions by learning from the trends, patterns, and relationships in the historical data. The algorithms are designed to learn iteratively from data without being programmed. In a way, machine learning automates model building.
Recently, machine learning algorithms are finding extensive applications in data-driven predictions and are a major decision-making tool. Some applications where machine learning has been used are email filtering, cyber security, signal processing, fraud detection, and others. Machine learning is employed in a range of computing tasks. Although machine-learning models are being used in several applications, it has limitations in designing and programming explicit algorithms that are reproducible and have repeatability with good performance. With current research and the use of newer technology, the field of machine learning and artificial intelligence are becoming more promising.
It is important to note that data mining uses unsupervised methods that usually outperform the supervised methods used in machine learning. Data mining is the application of knowledge discovery from the data (KDD) where supervised methods cannot be used due to the unavailability of training data. Machine learning may also employ data mining methods as “unsupervised learning” to improve learner accuracy. The performance of the machine learning algorithms depends on its ability to reproduce known knowledge.
Machine Learning Problems and Tasks: Difference between Supervised and Unsupervised Learning
Machine learning tasks have the following broad categories: supervised learning, unsupervised learning, and reinforced learning. The difference between supervised and unsupervised learning is explained in Table 13.2.
Table 13.2 Supervised and unsupervised learning
Supervised learning |
Unsupervised learning |
Supervised learning uses a set of input variables (x1, x2, …, xn) and an output variable, y(x). An algorithm of the form y = f(x) is used to learn the mapping function relating the input to output. This mapping function or the model relating the input and output variable is used to predict the output variable. The goal is to obtain the mapping function that is so accurate that it can use even the new set of data That is, the model can be used to predict the output variable as the new data becomes available. The name supervised learning means that in this process the algorithm is trained to learn from the training dataset where the learning process is supervised. In supervised learning process, the expected output or the answer is known. The algorithm is designed to make predictions iteratively from the training data and is corrected by the analyst as needed. The learning process stops when the algorithm provides the desired level of performance and accuracy. The most used supervised problems are regression and classification problems. We discussed regression problems earlier. Time series predictions problems, random forest for classification and regression problems, and support vector machines for classification problems also fall in this category. |
Unsupervised learning uses a set of input variable but no output variable. No labels are given to the learning algorithm. The algorithm is expected to find the structure in its input. The goals of unsupervised learning may be finding hidden pattern in the large data or feature learning. Thus, unsupervised learning can be a goal in itself or a means toward an end that are not based on general rule of teaching and training the algorithms. Unlike supervised learning algorithms are designed to devise and find the interesting structure in the data. The most used unsupervised learning problems are clustering and association problems. In clustering, a set of inputs is to be divided into groups. Unlike classification, the groups are not known beforehand, making this typically an unsupervised task. Association: Association problems are used to discover rules that describe association such as people that buy X also tend to buy Y. |
Methods, Various Libraries, and Algorithms Used in Machine Learning
(https://github.com/topics/tensorflow)
Machine learning is the practice of teaching a computer to learn. The concept uses pattern recognition, as well as other forms of predictive algorithms, to make judgments on incoming data. This field is closely related to artificial intelligence and computational statistics.
Python is a dynamically typed programming language designed by Guido van Rossum. Much like the programming language Ruby, Python was designed to be easily read by programmers. Because of its large following and many libraries, Python can be implemented and used to do anything from webpages to scientific research.
TensorFlow is an open source library that was created by Google. It is used to design, build, and train deep learning models.
The Jupyter Notebook is a language-agnostic HTML notebook application for Project Jupyter. Jupyter notebooks are documents that allow for creating and sharing live code, equations, visualizations, and narrative text together. People use them for data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.
Scikit-learn is a widely used Python module for classic machine learning. It is built on top of SciPy. There are several Python libraries which provide solid implementations of a range of machine learning algorithms. One of the best known is Scikit-Learn, a package that provides efficient versions of a large number of common algorithms. Scikit-Learn is characterized by a clean, uniform, and streamlined API, as well as by very useful and complete online documentation. A benefit of this uniformity is that once you understand the basic use and syntax of Scikit-Learn for one type of model, switching to a new model or algorithm is very straightforward.
Pandas is Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data frame objects, statistical functions, and much more.
Matplotlib is a package for visualization in Python. Matplotlib is a multiplatform data visualization library built on NumPy arrays and designed to work with the broader SciPy stack. It was conceived by John Hunter in 2002, originally as a patch to IPython for enabling interactive MATLAB-style plotting via gnu plot from the IPython command line.
NumPy
NumPy (short for Numerical Python) provides an efficient interface to store and operate on dense data buffers. In some ways, NumPy arrays are like Python’s built-in list type, but NumPy arrays provide much more efficient storage and data operations as the arrays grow larger in size. NumPy arrays form the core of nearly the entire ecosystem of data science tools in Python, so time spent learning to use NumPy effectively will be valuable no matter what aspect of data science interests you.
Deep learning is an AI function and subset of machine learning, used for processing large amounts of complex data.
Neural networks: Artificial neural networks (ANN) are computational systems that “learn” to perform tasks by considering examples, generally without being programmed with any task-specific rules.
Summary
Machine learning is a method of designing systems that can learn, adjust, and improve based on the data fed to them without being explicitly programmed. Machine learning is used to create models from huge amount of data commonly referred to as big data. It is closely related to artificial intelligence (AI). In fact, it is an application of artificial intelligence (AI). Machine learning algorithms are based on teaching a computer how to learn from the training data. The algorithms learn and improve as more data flows through the system. Fraud detection, e-mail spam, GPS systems are some examples of machine learning applications.
Machine learning tasks are typically classified into two broad categories: supervised learning and unsupervised learning. In supervised learning, the computer is presented with example inputs and their desired outputs by the analyst, and the goal is to create a model to learn a general rule that maps inputs to outputs. The supervised learning problems are divided into classification and regression problems. A classification problem is when the output variable is a category, such as e-mails can be classified as “spam” or “no spam” or a test can be classified as “negative” and “positive.” Most commonly used classification algorithms are K-Nearest Neighbor and decision-tree algorithms. Regression problems are used to predict continuous labels. There are several regression models used in machine learning. Unlike the supervised learning, no labels are given to the data in unsupervised learning. Unsupervised learning is where there is input data (X) and no corresponding output variables. The commonly used models in unsupervised learning include clustering and dimensionality reduction.
Clustering is an unsupervised learning technique used to find groups or clusters of similar instances based on features. The purpose of clustering is a process of grouping similar objects to determine whether there is any relationship between them. Classification is a supervised learning technique used to find similarities in classification based on a training set. It uses algorithms to categorize the new data according to the observations in the training set.
There are other classes of machine learning problems that fall in between supervised and unsupervised learning problems. These are semisupervised machine learning algorithms and reinforcement learning. Other application of machine learning is deep learning,25 which is based on artificial neural networks.6 Machine learning also has applications in data mining. Machine learning methods use complex models and algorithms that are used to make predictions. The machine learning models allow the analysts to make predictions by learning from the trends, patterns, and relationships in the historical data. The algorithms are designed to learn iteratively from data without being programmed. In a way, machine learning automates model building. To aid in the model building process in Machine Learning several libraries and algorithms are used. Microsoft Azur and SAS machine learning are designed to automate the process.