
Ascending the Five Ethical Levels
Imagine you move into a Covid-friendly office building. It’s circular, and the offices are along the edge of the circle. The inside-facing wall of your office is glass and faces an opaque structure at the middle of the circle, one that runs from the ground floor to the very top of the building. Inside that structure there is at least one supervisor, observing people’s behavior through their glass wall. Given the design of the building, you can’t see who is watching you or even whether someone is watching you, though they can see you.
The supervisor(s) have three responsibilities and one broad goal.
Responsibility one is to learn various things about you by observation. When you have your lunch, what you eat, who you interact with, and so on.
Responsibility two is to extrapolate from that information certain other facts about you, for example, whether you might quit soon, how likely you are to become pregnant in the next year, whether you might be interested in the new cafeteria offerings, and so on.
And responsibility three is to use that information to create new tools that will allow them to collect even more information about you that will in turn fuel new predictions and inventions, and so on, ad infinitum.
Finally, their broad goal is to use all of this information and these tools so they can make various decisions and recommendations related to you: whether you get a raise, promotion, or bonus, what they offer you at the cafeteria, how many reminder emails they’ll send you about trying the new office gym, whether you were overly aggressive in a conversation with colleagues, whether you might need the services of a mental health expert, and so on.
You’re probably not particularly comfortable with any of this. You probably think it’s a violation of your privacy, that the supervisors don’t have your best interests at heart (perhaps all their recommendations center around what they think will make you more productive so they can extract the maximum value from you, independently of what that does to your health or well-being), and that all of this impinges on your autonomy—your ability to live your life freely, without the undue influence of others.
As you have already discerned, these kinds of concerns are exactly the ones raised in the context of talking about privacy and machine learning.
At the core of ML is data, and the more of it, the better for those training their models. This means that companies that want to profit from you are highly incentivized to collect as much data as possible about you and the way you behave. In fact, companies will collect people’s data without even knowing exactly what they’ll use it for, or even if they ever will. They collect it just in case they can wring some value from it down the line. The value doesn’t even have to come directly from how they use it; it can come from selling the data to someone else who thinks they have a use for it.
The fact that you don’t know what data is collected about you and who has access to it is already troublesome. In some cases, it will constitute a violation of privacy, as when your location, financial, or medical history is revealed to parties you never wanted to see those details (your ex-spouse, for instance).
All of that data is then used to train ML models that make predictions about you that in turn influences how those organizations treat you. Perhaps your social media data is used to train models that determine whether you get a mortgage. They determine what news articles bubble up to the top of your search inquiries, what YouTube video is recommended next, what job, housing, and restaurant ads you see, and so on. Insofar as your life consists in choosing options from a menu, and most of that menu is found online, you’ll be choosing among options they—the aggregate of all those companies collecting and selling all your data while also using it to train their AI to make increasingly accurate predictions about what will get you to click, share, and buy—have chosen for you.
Sometimes using ML and other tools to predict how to get you to stay on a site and click is referred to as the “attention economy.” The more they can control how much attention they get from you, the better they do. And sometimes the data gathering involved in developing AI is referred to as the “surveillance economy.” The more they know about you, the better they can influence you. In truth, both economies are part of the same market. Companies surveil, in part, so they can figure out how to get your attention, so they can direct you to do things that will drive their bottom line.
Finally, all that data and ML is used to create particular products that threaten to invade people’s privacy. The one on the top of most everyone’s list is facial-recognition software, which can potentially pick your face out of a crowd and identify you. Notoriously, the startup Clearview AI collected over 3 billion images of people from Facebook, YouTube, Venmo, and millions of other websites. Those with access to its software can take a picture of someone in public, upload it to the app, and it will return all of the publicly available photos of that person online along with links to where those photos can be found, including sites that might also include your name, address, and other personal information.
These kinds of privacy issues have received a tremendous amount of attention in recent years. Citizens, consumers, employees, and governments are taking note. Newspaper articles and social media posts abound detailing the various ways corporations trample privacy interests and rights. Various regulations have been passed to protect people’s data—most notably, the General Data Protection Regulation (GDPR) in the EU and the California Consumer Privacy Act (CCPA)—and other regulations are in the pipeline, such as recent recommendations to EU member states on AI or ML regulations.
Some companies have handled the issue … poorly. Facebook’s reputation suffered not only from the Cambridge Analytica saga—which would be an existential threat for most any company other than a financial behemoth like Facebook—but from subsequent events that continually tarnish its reputation. Other companies have fared better. Apple, for instance, has turned its stance on privacy into a major element of its brand.
In my experience, most companies handle the issue poorly by virtue of misunderstanding what privacy is all about.
Disambiguating “Privacy”
One of the problems with talking about “privacy” with engineers, data scientists, and senior leaders is that they don’t hear the word in the way most citizens hear it. That’s because the term is multiply ambiguous, or put slightly differently, privacy has three sides.
One way to think about privacy is in terms of compliance with regulations and the law, for example, compliance with GDPR and CCPA. By complying, someone with this mindset thinks, you have achieved respecting people’s privacy. A second way is to think about it in terms of cybersecurity: what practices one has for keeping data safe from those who should not have access to it (e.g., various employees, hackers, governments, etc.). By preventing unwanted and unwarranted access, someone with this mindset thinks, you have sufficiently respected people’s privacy. And the third way to think about privacy is from an ethical risk perspective.
While there are overlapping areas in the Venn diagram of these three aspects of privacy, they are clearly distinct. For our purposes, it’s important to explore this third version and see what ethical risks arise that are distinct from compliance and cybersecurity.
First, ethical risks remain even with regulations like GDPR and CCPA, because those only have effect in certain jurisdictions: EU member states and California, respectively. Even if it were the case that the set of ethical risks is identical to the set of regulatory violation risks of either of these, there remains the simple fact that much of the United States is unaffected by them. This means that a company can operate in ways incompatible with CCPA in all states except California, and thus those ethical risks remain a threat.
Second, even beyond jurisdiction, it’s not the case that ethical risks with regard to privacy are identical to the regulatory risks. For instance, various bans on facial-recognition software are recommended by the EU precisely because those recommendations are not contained in GDPR. Nonetheless, various companies have been criticized in the news and social media for their use of that technology.
Third, ethical risks remain because unwarranted access risks aren’t the only cybersecurity risks relating to data and AI. Again, facial-recognition software potentially constitutes a threat to privacy independently of concerns about sloppy data controls or the threat of a data leak or hack. Perhaps more worrying than facial-recognition software is lip-reading AI, which can discern what people are saying without being within ear- or, one might say, microphone-shot.1 And things get even worse if the way people move their mouths, jaws, tongues, and so on acts as a kind of fingerprint, in which case a camera enhanced with this software can identify who is saying what. These are privacy risks that are neither regulated against nor relevant to cyber risks.
None of this implies that compliance and security are not important. Defying regulations is expensive. It costs resources to accommodate investigations and pay fines, and headlines announcing those investigations and fines tarnishes brands. Cybersecurity has similar consequences. A system in which user, patient, consumer, or citizen data is leaked or hacked is an expensive problem. And both are ethically problematic. Neither set of risks, however, is identical to the set of ethical risks we reference when we talk about privacy in the context of data and AI ethics.
Privacy Is Not Just about Anonymity
In some cases, engineers, data scientists, and other technologists will talk about anonymity as the key to respecting privacy, including in the context of a discussion on AI ethics, which in turn invites technical conversations about how to anonymize the data with the smallest probability of being de-anonymized.
We’ve seen this before. In talking about bias, technologists think a mathematical tool will identify and mitigate bias. It isn’t true. In talking about explainability, technologists think a mathematical tool will turn the black box transparent. It isn’t true. So, when technologists reduce the ethical risk of privacy to an issue of anonymity and then search for mathematical tools to anonymize data—for example, differential privacy, k-anonymity, I-diversity, and cryptographic hashings—we should be suspicious.
The main assumption technologists make is that, If I don’t know whose data this is, then I can’t be violating anyone’s privacy.
The assumption is not entirely unreasonable. When an organization or individual knows you by name, or any other personally identifiable information (PII), that makes it easier to track you across websites (for instance) and to build a profile of you with increasing quantities of information. That said, in the context of data and AI ethics, the assumption is false. We can see how by thinking about Facebook’s Cambridge Analytica scandal.
Cambridge Analytica collected the data of over 87 million Facebook users, 70.6 million of whom were in the United States. Cambridge Analytica used that data to create psychological profiles, which were in turn used to predict what kind of political ad would influence which kinds of people in a given location, for example, what kinds of ads would incline them to vote for Donald Trump. That Facebook designed its product in a way that would allow Cambridge Analytica to collect that information with the app it uploaded to the platform was widely seen as a privacy violation; Facebook should not have shared that information with Cambridge Analytica. Note that Facebook wasn’t hacked in the cybersecurity sense of that term. It simply didn’t take privacy into account or, at least, not in the right way or to the right extent, when designing its systems.
Is this massive breach of privacy about anonymity? I don’t see how. Cambridge Analytica doesn’t need to have anyone in the organization know the names of any of the users. In fact, it could have, for the sake of maintaining profile anonymity, intentionally encrypted or hashed the username and other PII. To Cambridge Analytica, all it has is “User fe79n583025nk will, with a probability of 74.3 percent, find ad #23 persuasive.” If that were the case, would Facebook users, citizens, and government officials find no issue with Cambridge Analytica, which mined the data, or Facebook, which designed its software in such a way that Cambridge Analytica had the level of access it did? Somehow, I doubt it.
The moral of the story is not that anonymity doesn’t matter. It’s that it can’t be all that matters. That’s because anonymity is not sufficient to stop companies, governments, and other organizations from collecting data about you, training its ML with your data, making predictions about you, and making various decisions on how to treat you. More specifically, what’s at issue is the increasing degree of power or control companies have by virtue of the data they collect and the AI they create: control over who gets an interview or housing, what content people consume, what ads they see, who people vote for, what those people believe about the legitimacy of elections, and so on.
If you knew what data companies are collecting and what they’re doing with it, and you had the control to stop them from either collecting it in the first place or using it in ways to which you object, you could, at least in part, protect yourself from undue manipulation and being treated in a way to which you object. Further, if you knew how economically valuable your data was to those organizations, you might require compensation for the collection and use of your data. If your data is an asset, you probably don’t want to give it away for free (just as you’d be opposed to this with regard to any other asset). At the end of the day, privacy talk in AI ethics is not about what companies know about citizens. It’s about control. More specifically, it’s about the right to control who can collect what data about you and what they can use it for.
Privacy Is a Capacity
When you pull down your shades in your bedroom, you are exercising your right to privacy, and you are similarly exercising that right when you retract the shades. Relatedly, when you invite someone into your bedroom (presumably with the shades down), that person is not violating your privacy. That’s because privacy is a right (or perhaps an interest) that you can act on.
This conception of privacy is codified in the law, which articulates a distinction between informational privacy and constitutional privacy.
Informational privacy concerns a right to control information about yourself: who has it, for how long, and under what conditions. Such control is deemed important so that people can protect themselves from, for instance, unwarranted searches and surveillance. Constitutional privacy is not about control over information about oneself but rather about control over oneself. Insofar as we have such a right, it is a right to exhibit a certain level of independence in how our lives unfold, with whom we associate, what kind of lifestyle we prefer. Such a right has been used to defend, for instance, being gay, whether to have children and, if so, how many, and whether to practice a religion.
If your company has respecting privacy as one of its goals, then that means, at a bare minimum, not deploying AI in such a way that this capacity to control (information about) oneself is either undermined or cannot be exercised without great effort on the part of the user, consumer, or citizen. At a maximum, it means deploying AI that positively promotes or enables the exercise of that capacity.
Let’s suppose you work for an organization that claims to respect people and their privacy. You don’t want to undermine people’s capacity to exercise their right to privacy. You might want to maximally empower their capacity to exercise that right. Or you may want something in between. How do we measure such things, though, and how do we infuse it into the development and deployment of AI?
The Five Ethical Levels of Privacy
We start by thinking about the elements that create the conditions under which your users, consumers, or citizens can exercise their capacity to control their (digital) lives.
Transparency
If users, consumers, or citizens don’t know what information is being collected about them, what’s being done with it, what decisions they contribute to, who it’s being shared with or sold to, then they cannot possibly exercise any control. If, as a business, you haven’t told customers or, worse, you don’t know either, that’s a problem.
Data control
Users, consumers, or citizens may or may not have the ability to correct, edit, or delete information about themselves and may or may not be able to opt out of being treated in a certain way (e.g., opting out of targeted ads). Having the capacity to perform these actions is at least part of what is involved in exercising control over one’s information. Giving the capacity is increasingly important for companies, for at least three reasons. First, that ability is required by some regulations, for example, GDPR. Second, it communicates to users (or consumers or citizens, hereafter I’ll say “users” to represent all three) that you respect their privacy. And third, it gives users an opportunity to fix inaccurate information you have about them, which will enable you to serve them better and create more accurate AI models.
Opt in or out by default
Most companies collect a great deal of data by default. It might happen during a registration process. It may happen as a user is active on your site, where your organization collects data about where they go on the site, for how long, what they click on, and so on. This happens without any choice by the user; they are automatically “opted in” for such data collection. The alternative is for companies to automatically “opt out” their users from data collection and requiring users to opt in to such data collection. The former approach puts the burden on the user to investigate how to obtain the data the organization has about them, to review that list, and to opt out of the organization’s collection of some set of data or using it for some set of purposes. The latter approach puts the burden on your organization to demonstrate to the user that they will sufficiently benefit from sharing that data and using it in the proposed ways such that it is a good decision for them to opt in to sharing their data. Opting out by default is motivated, in part, by the thought that, first, do no harm, and you can do that by not assuming you have the user’s consent to collect and use their data.
Full services
Your organization may increase or decrease the services it provides depending on what data a person provides. Some organizations will not provide any services if you do not consent to their privacy (intrusive) policies. Some will vary the degree of services provided depending on how much data the user shares. Some will provide full services independently of how much data the user shares. One concern here has to do with how essential the services are. If autonomy consists in, at least in part, your ability to live your life freely, without the undue influence of others, and an organization provides an essential service on the condition that you provide them with a level of access to your data that you’re not comfortable with, then the organization is exhibiting an undue influence on you; your autonomy is being impinged upon.
With these elements of privacy articulated, we can see what I call The Five Ethical Levels of Privacy, captured in table 4-1.
Table 4-1
The five ethical levels of privacy
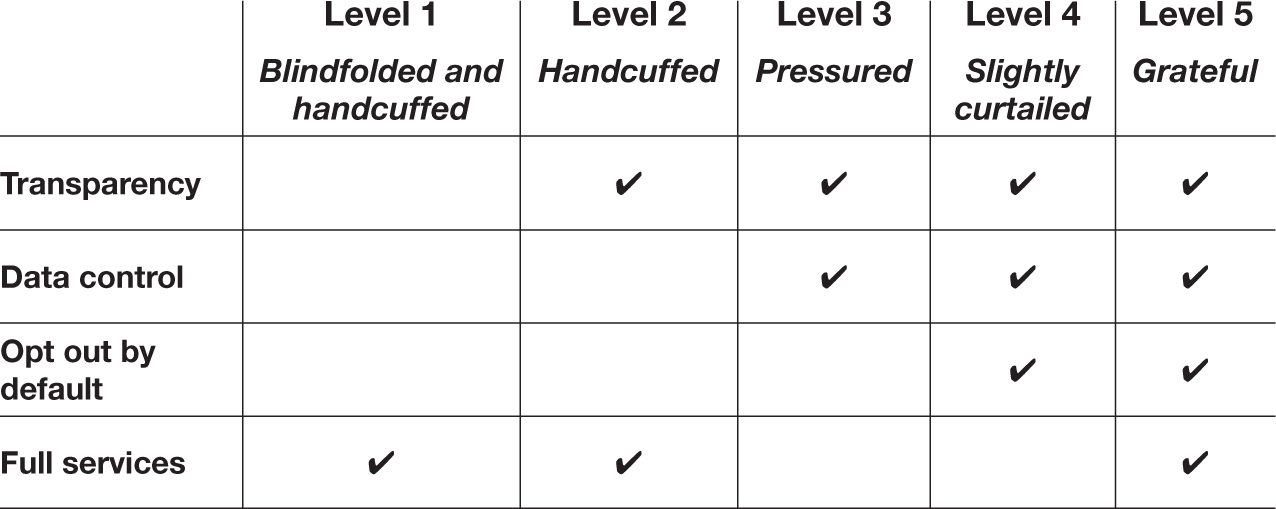
Level One: Blindfolded and handcuffed consumer. People are in the dark and passive with regard to their data and the predictions made about them. This is the standard state of affairs. The vast majority of consumers scarcely know what data is, let alone what “metadata” or “artificial intelligence” or “machine learning” or “predictive algorithms” are. And even if they were educated on such matters, the average person is not familiar with the privacy policies of the dozens if not hundreds of sites and apps they interact with regularly. What’s more, data can be collected about people and predictions made about them despite their not choosing to be on a website or purchase anything. Corporate surveillance of employees (as caricatured at the start of this chapter) is performed in a way that is not transparent, so employees lack control and they are opted in by default. Citizens surveilled by a police force—which we’ll discuss in more detail in chapter 7—are in the same boat.
For those users or consumers whose data is collected because of their use of a website or app, it is no argument for the claim that level one has been surpassed because there are “terms and conditions” and privacy policies that people “accept” when they click on a banner asking for their acceptance. While this may or may not protect companies legally, it does not protect them from ethical or reputational risk. Had Facebook’s terms and conditions indicated the possibility of a Cambridge Analytica–type incident, it would have done little to ebb the flood of criticism that came its way. Indeed, had it announced, “Well, we told you it was possible in our thirty-page terms and conditions written in legalese,” that would have only drawn more ire. As we saw in the previous chapter, in order to be effective and convey respect, explanations need to be intelligible and digestible to their audiences.
When companies operate at level one, they are engaging in the kind of activity that tends to enrage people on social media and excite journalists. It inspires books like Surveillance Capitalism and the New York Times’s “Privacy Project,” in which articles are continuously written on the ways in which corporations breach citizen and consumer trust. It’s what allows Apple to ridicule Facebook.
Level two: Handcuffed consumer. At least the blindfold is off. People are, in principle, knowledgeable about their data and predictions made about them, but they are still passive with regards to what is collected and what is done with their data. Information about their data and relevant predictions are accessible to them, should they put in a little effort. The company collecting their data has gone to some trouble in articulating for the user what data it has about them and what it’s using it for. That said, at this level, while people know what’s being done with their data, they can’t do anything about it. This is roughly the condition you’re in with the Department of Motor Vehicles. It has a lot of data about you—name, home address, height, hair and eye color, number of times you’ve been charged with the misdemeanor of reckless driving. You can’t do much about this, though.
Level three: Pressured consumer. People know what’s being done and they have some degree of control over what data is collected and how it’s used. More specifically, after their investigation of such matters, they have the capacity to opt out of the organization collecting data and using it in ways to which they object. That said, since they need to opt out, this means some set of data has already been collected and put to various uses before the person engages in their investigation and opts out.
Level four: Slightly curtailed consumer. People have knowledge, and their data isn’t collected or used without their consent being obtained.
Notice that, in levels one and two—where people have no control over what data is collected or what’s done with it, except to not use the services or goods of the company at all—full services are provided. And this is where most companies are. The rationale is “so long as we’re providing value to the customer, we’re justified in using their data when they use our services.” The judgment, in this case, as to whether the services provided are worth the sharing of data, is made by the company itself, which has a financial incentive to make that judgment.
At levels three and four—where people can opt in or out—the judgment is, more or less, made by the consumers whose data is being collected. They gain control. But companies can incentivize (or pressure, depending on the urgency with which people need to use the service) people to make that trade by curtailing services in response to curtailed sharing of data. This is a little like seducing someone you know is married; yes, it’s their decision, but you’ve actively played a role in getting them to make a decision that results in breaking a promise to their spouse.
Level five: Free and grateful consumer. The organization provides full services independently of what data the person opts in to provide and consents to be used for various purposes (except for data required to deliver the services for which the person has requested or paid for). This is compatible, of course, with curtailing services because the person has not provided payment for those services.
These five levels are a heuristic. Reality is much more complex. In some cases, organizations are (rightfully) committed to different levels for different products. And they may be transparent in this respect but not in another one (e.g., transparent about what data is collected but opaque about what predictions they’re making). Still, they give us a grip on what privacy in AI ethics is really about. What’s more, the different levels highlight the need for organizations to determine what level the organization strives for (or, more importantly, what level they never want to fall below), both at the organizational level and on a per-product basis. This brings us to a Structure from Content Lesson.
Structure from Content Lesson #8: Before you start collecting data to train your AI, determine what ethical level of ethical privacy is appropriate for the use case.
Building and Deploying with Five Ethical Levels of Privacy
The Five Ethical Levels of Privacy provide a way of assessing the degree of privacy respected by the product and, indirectly, the organization that created the product, which is good both for external stakeholders and for executives and managers charged with ensuring the organizational commitment to privacy is made real. It is also a tool by which developers can think about privacy as it is developed.
Suppose your product managers have a clear understanding of what your organization’s commitment to privacy looks like, including what kinds of things it will always do and what kinds of things it will never do (an understanding it may arrive at from your AI Ethics Statement, which we’ll discuss in detail in the next chapter). It may even include a commitment to never falling below level two of privacy, or a rabid commitment to level five.
A problem is presented to one of your AI teams, and they get to work brainstorming or—to use a “word” that, when used, should result in the loss of one’s tongue—ideating potential solutions. As they think about those solutions, they also think about what levels of privacy those proposed solutions are compatible with and how the proposed product fits into your organization’s general privacy commitments. Some proposed solutions—like the one that secretly deploys facial-recognition technology so as to identify shoppers in the store so it can send discount codes for toilet paper, good for one hour, to their phones—are rejected because the organization requires transparency with its customers. Other solutions—like the one that texts discount codes for toilet paper to preexisting customers based on when the AI predicts they probably need more—are left on the table because those customers have already opted in to having that data collected for the purposes of receiving targeted discount codes, which reflects the organization’s commitment to level four (since customers are opted out by default but they also won’t get discount codes without opting in).
In some cases, what level a company operates at is largely determined by its business model. In the case of Facebook, it might crumble if it stopped collecting user data unless people opted in while providing full services to everyone. Its revenue is driven through serving ads, and advertisers need user data so they can target them. Other businesses, for example, those that operate on a subscription model, can afford to reach level five.
Not all companies should strive for level five. Privacy, conceived of as the extent to which the people you collect data about and on whom you deploy your AI have knowledge and control over what data your organization collects and what it does with it, is something worth valuing. But it is not the only thing worth valuing, and there are cases in which it is reasonable to decrease the level of privacy you reach for the sake of some other (ethical) good that outweighs it. If, for instance, decreasing the level of privacy you reach is essential to, say, developing a vaccine for a global pandemic, then your choice may well be ethically justified (on the condition that, for instance, you’ve been responsible with the security of the data and the AI infrastructure you’ve built). In fact, Facebook is arguably justified—to some extent—in its privacy practices, given that its business model, which is advertising based, not subscription based, makes it economically feasible to provide its services globally. Citizens of developing countries with extremely low or no wages can use Facebook for personal and work-related reasons without having to shoulder an additional financial burden. Were Facebook to introduce a global subscription model in the name of privacy, it would no doubt come under the criticism, which would not be unreasonable, that it has now excluded the historically and currently marginalized citizens of the global community.
In this respect, Facebook is in a bit of a bind. One of the things it’s forced to do is to weigh two values that are in conflict (and putting the financial calculations to the side): privacy, on the one hand, which can be increased with a subscription model, and providing opportunities to those desperately in need of opportunity, on the other hand, which counsels against a subscription model. How to resolve this tension is not easy, and it’s certainly not in the job description of data scientists and engineers to resolve it. We thus have another Structure from Content Lesson.
Structure from Content Lesson #9: Your organization needs an individual or, ideally, a set of individuals, that can make responsible, expert-informed decisions when ethical values conflict.
Creepy Companies and Respect
We’ve spent this chapter focusing on an essential element for thinking about privacy from an ethical perspective: who controls the data and what it’s used for. But for a lot of people, their concerns about their privacy being violated aren’t formulated in quite this way. Instead, people characterize all the data that your organization and others collect about them as being … creepy. It’s “icky” that companies are “stalking” their consumers. And consumers may reject companies for collecting their data for just that reason.
Myself, I’m inclined to think these concerns are somewhat misguided. Being creepy is to appear dangerous or unsafe or threatening. There’s then the further question whether the creepy thing really is a threat. (Some people are creepy but harmless; they make eye contact for too long, for instance, but there’s nothing nefarious behind the stare.) And as I’ve said, the real danger is how organizations use that data, not merely in the fact that they have it. You might think, then, “Well, our organization isn’t doing anything ethically problematic with their data so their concerns about us being creepy or threatening are ill-founded; thus, we can, ethically speaking, ignore their complaints about creepiness.” But in that, you’d be wrong.
Your consumers may or may not have unfounded concerns about what you’ll do with their data. They find it creepy, and you think their feelings of creepiness are unwarranted. But respecting people entails, in part, that you respect their wishes, even if you think their wishes are misguided or ill-informed. To simply wave away their concerns is to substitute your organization’s judgment for theirs, and even if that judgment is more accurate, failing to respect their wishes can be objectionably paternalistic.
A Final Thought: The Oddness of Talking about Privacy
I have to admit that—putting regulatory compliance and cybersecurity to the side—I find talk about privacy in the context of AI a bit odd. The real danger for users, consumers, and citizens is not so much that organizations have certain data about them, but rather that organizations—including yours—may do things with that data to which they object. They might find the things you propose to do with their data, like training your AI models, is or will harm them or society at large by, for instance, manipulating them, having an undue influence on their decisions and actions because they feel they’re being watched, miscategorizing them and so denying them a good or service they are worthy of (e.g., credit, housing, insurance, etc.), causing them emotional distress with how your AI chooses to construct their social media or news feed, and on and on. In short, and at bottom, the expression of a concern about privacy in the context of AI is often the expression of a concern that your organization will engage in ethical misconduct by virtue of deploying ethically unsafe AI. Users want control over their data so you can’t hurt them. In this way, talk of privacy is shorthand for AI ethics more generally.
Getting It Right
By this time, you should have a grip on the basics of AI, the foundations of ethics, and the three big challenges of AI ethics: bias, explainability, and privacy. And as a result of the Structure from Content Lessons, you should start to see a bit of an outline of an AI ethical risk program. Now it’s time to really start throwing that Structure into relief, first by looking at how people usually attempt this and get it wrong. Then, I promise, I’ll show you how to do it the right way.
Recap
- The two Structure from Content Lessons that relate to privacy and can guide approaches to Structure that are gleaned from understanding Content:
– Before you start collecting data to train your AI, determine what ethical level of privacy is appropriate for the use case.
– Your organization needs an individual or, ideally, a set of individuals, that can make responsible, expert-informed decisions when ethical values conflict.
- AI ethics invariably includes data ethics, insofar as machine learning requires the AI-developing or deploying organization to acquire or use troves of data.
– This data, and more specifically, the ML it is used to train, is often built to make predictions about users, consumers, citizens, employees, and so on. These predictions, and the subsequent actions, may or may not have their best interests as their prime target, and people often insist, not unreasonably, that their privacy has been violated by virtue of the data collected and the kinds of predictions that were made.
- Privacy has three aspects:
– Regulatory compliance
– The integrity and security of data (cybersecurity)
– Ethics
- Privacy is often equated with anonymity. While having personally identifiable information properly anonymized is important (and a responsibility from both an ethical and cybersecurity perspective), complaints about privacy violations extend far beyond a lack of anonymity.
- Privacy, in the context of AI ethics, is best understood as the extent to which people have knowledge and control over their data without undue pressure. Put differently, organizations’ respect for privacy is, in large part, respect for the autonomy of the people whose data they collect and deploy their AI on.
- The four elements of the Five Ethical Levels of privacy are:
– Transparency
– Data control
– Opt out by default
– Full services
- The more of these elements that consumers are provided, the higher the level of privacy a company reaches. The Five Ethical Levels of Privacy based on these elements are, in order from least private to most private:
– Level one: blindfolded and handcuffed. Only full services are provided to consumers.
– Level two: handcuffed. Full services and transparency are provided.
– Level three: pressured. Transparency and data control are provided.
– Level four: slightly curtailed. Transparency, data control, and opt-out by default are provided.
– Level five: trusting and grateful. All four elements are provided.
- Not every company in every product should strive for level five. Privacy is one value among many, and tradeoffs between it and other values have to be made in a way that respects an organization’s more general ethical commitments and priorities.