
CHAPTER 9
Redo and Undo
This chapter describes two of the most important pieces of data in an Oracle database: redo and undo. Redo is the information Oracle records in online (and archived) redo log files in order to "replay" your transaction in the event of a failure. Undo is the information Oracle records in the undo segments in order to reverse, or roll back, your transaction.
In this chapter, we will discuss topics such as how redo and undo (rollback) are generated, and how they fit into transactions, recovery, and so on. We'll start off with a high-level overview of what undo and redo are and how they work together. We'll then drill down into each topic, covering each in more depth and discussing what you, the developer, need to know about them.
The chapter is slanted toward the developer perspective in that we will not cover issues that a DBA should be exclusively in charge of figuring out and tuning. For example, how to find the optimum setting for RECOVERY_PARALLELISM or the FAST_START_MTTR_TARGET parameters are not covered. Nevertheless, redo and undo are topics that bridge the DBA and developer roles. Both need a good, fundamental understanding of the purpose of redo and undo, how they work, and how to avoid potential issues with regard to their use. Knowledge of redo and undo will also help both DBAs and developers better understand how the database operates in general.
In this chapter, I will present the pseudo-code for these mechanisms in Oracle and a conceptual explanation of what actually takes place. Every internal detail of what files get updated with what bytes of data will not be covered. What actually takes place is a little more involved, but having a good understanding of the flow of how it works is valuable and will help you to understand the ramifications of your actions.
What Is Redo?
Redo log files are crucial to the Oracle database. These are the transaction logs for the database. Oracle maintains two types of redo log files: online and archived. They are used for recovery purposes; their purpose in life is to be used in the event of an instance or media failure.
If the power goes off on your database machine, causing an instance failure, Oracle will use the online redo logs to restore the system to exactly the point it was at immediately prior to the power outage. If your disk drive fails (a media failure), Oracle will use archived redo logs as well as online redo logs to recover a backup of the data that was on that drive to the correct point in time. Additionally, if you "accidentally" truncate a table or remove some critical information and commit the operation, you can restore a backup of the affected data and recover it to the point in time immediately prior to the "accident" using online and archived redo log files.
Archived redo log files are simply copies of old, full online redo log files. As the system fills up log files, the ARCH process will make a copy of the online redo log file in another location, and optionally make several other copies into local and remote locations as well. These archived redo log files are used to perform media recovery when a failure is caused by a disk drive going bad or some other physical fault. Oracle can take these archived redo log files and apply them to backups of the data files to catch them up to the rest of the database. They are the transaction history of the database.
Note With the advent of the Oracle 10g, we now have flashback technology. This allows us to perform flashback queries (i.e., query the data as of some point in time in the past), un-drop a database table, put a table back the way it was some time ago, and so on. As a result, the number of occasions where we need to perform a conventional recovery using backups and archived redo logs has decreased. However, performing a recovery is the DBA's most important job. Database recovery is the one thing a DBA is not allowed to get wrong.
Every Oracle database has at least two online redo log groups with at least a single member (redo log file) in each group. These online redo log groups are used in a circular fashion. Oracle will write to the log files in group 1, and when it gets to the end of the files in group 1, it will switch to log file group 2 and begin writing to that one. When it has filled log file group 2, it will switch back to log file group 1 (assuming you have only two redo log file groups; if you have three, Oracle would, of course, proceed to the third group).
Redo logs, or transaction logs, are one of the major features that make a database a database. They are perhaps its most important recovery structure, although without the other pieces such as undo segments, distributed transaction recovery, and so on, nothing works. They are a major component of what sets a database apart from a conventional file system. The online redo logs allow us to effectively recover from a power outage—one that might happen while Oracle is in the middle of a write. The archived redo logs allow us to recover from media failures when, for instance, the hard disk goes bad or human error causes data loss. Without redo logs, the database would not offer any more protection than a file system.
What Is Undo?
Undo is conceptually the opposite of redo. Undo information is generated by the database as you make modifications to data to put it back the way it was before the modifications, in the event the transaction or statement you are executing fails for any reason or if you request it with a ROLLBACK statement. Whereas redo is used to replay a transaction in the event of failure—to recover the transaction—undo is used to reverse the effects of a statement or set of statements. Undo, unlike redo, is stored internally in the database in a special set of segments known as undo segments.
Note "Rollback segment" and "undo segment" are considered synonymous terms. Using manual undo management, the DBA will create "rollback segments." Using automatic undo management, the system will automatically create and destroy "undo segments" as necessary. These terms should be considered the same for all intents and purposes in this discussion.
It is a common misconception that undo is used to restore the database physically to the way it was before the statement or transaction executed, but this is not so. The database is logically restored to the way it was—any changes are logically undone—but the data structures, the database blocks themselves, may well be different after a rollback. The reason for this lies in the fact that, in any multiuser system, there will be tens or hundreds or thousands of concurrent transactions. One of the primary functions of a database is to mediate concurrent access to its data. The blocks that our transaction modifies are, in general, being modified by many other transactions as well. Therefore, we cannot just put a block back exactly the way it was at the start of our transaction—that could undo someone else's work!
For example, suppose our transaction executed an INSERT statement that caused the allocation of a new extent (i.e., it caused the table to grow). Our INSERT would cause us to get a new block, format it for use, and put some data on it. At that point, some other transaction might come along and insert data into this block. If we were to roll back our transaction, obviously we cannot unformat and unallocate this block. Therefore, when Oracle rolls back, it is really doing the logical equivalent of the opposite of what we did in the first place. For every INSERT, Oracle will do a DELETE. For every DELETE, Oracle will do an INSERT. For every UPDATE, Oracle will do an "anti-UPDATE," or an UPDATE that puts the row back the way it was prior to our modification.
Note This undo generation is not true for direct path operations, which have the ability to bypass undo generation on the table. We'll discuss these in more detail shortly.
How can we see this in action? Perhaps the easiest way is to follow these steps:
- Create an empty table.
- Full scan the table and observe the amount of I/O performed to read it.
- Fill the table with many rows (no commit).
- Roll back that work and undo it.
- Full scan the table a second time and observe the amount of I/O performed.
First, we'll create an empty table:
ops$tkyte@ORA10G> create table t
2 as
3 select *
4 from all_objects
5 where 1=0;
Table created.
And then we'll query it, with AUTOTRACE enabled in SQL*Plus to measure the I/O.
Note In this example, we will full scan the tables twice each time. The goal is to only measure the I/O performed the second time in each case. This avoids counting additional I/Os performed by the optimizer during any parsing and optimization that may occur.
The query initially takes three I/Os to full scan the table:
ops$tkyte@ORA10G> select * from t;
no rows selected
ops$tkyte@ORA10G> set autotrace traceonly statistics
ops$tkyte@ORA10G> select * from t;
no rows selected
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
3 consistent gets
...
ops$tkyte@ORA10G> set autotrace off
Next, we'll add lots of data to the table. We'll make it "grow" but then roll it all back:
ops$tkyte@ORA10G> insert into t select * from all_objects;
48350 rows created.
ops$tkyte@ORA10G> rollback;
Rollback complete.
Now, if we query the table again, we'll discover that it takes considerably more I/Os to read the table this time:
ops$tkyte@ORA10G> select * from t;
no rows selected
ops$tkyte@ORA10G> set autotrace traceonly statistics
ops$tkyte@ORA10G> select * from t;
no rows selected
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
689 consistent gets
...
ops$tkyte@ORA10G> set autotrace off
The blocks that our INSERT caused to be added under the table's high-water mark (HWM) are still there—formatted, but empty. Our full scan had to read them to see if they contained any rows. That shows that a rollback is a logical "put the database back the way it was" operation. The database will not be exactly the way it was, just logically the same.
How Redo and Undo Work Together
In this section, we'll take a look at how redo and undo work together in various scenarios. We will discuss, for example, what happens during the processing of an INSERT with regard to redo and undo generation and how Oracle uses this information in the event of failures at various points in time.
An interesting point to note is that undo information, stored in undo tablespaces or undo segments, is protected by redo as well. In other words, undo data is treated just like table data or index data—changes to undo generate some redo, which is logged. Why this is so will become clear in a moment when we discuss what happens when a system crashes. Undo data is added to the undo segment and is cached in the buffer cache just like any other piece of data would be.
Example INSERT-UPDATE-DELETE Scenario
As an example, we will investigate what might happen with a set of statements like this:
insert into t (x,y) values (1,1);
update t set x = x+1 where x = 1;
delete from t where x = 2;
We will follow this transaction down different paths and discover the answers to the following questions:
- What happens if the system fails at various points in the processing of these statements?
- What happens if we
ROLLBACKat any point? - What happens if we succeed and
COMMIT?
The INSERT
The initial INSERT INTO T statement will generate both redo and undo. The undo generated will be enough information to make the INSERT"go away." The redo generated by the INSERT INTO T will be enough information to make the insert "happen again."
After the insert has occurred, we have the scenario illustrated in Figure 9-1.

Figure 9-1. State of the system after an INSERT
There are some cached, modified undo blocks, index blocks, and table data blocks. Each of these blocks is protected by entries in the redo log buffer.
Hypothetical Scenario: The System Crashes Right Now
Everything is OK. The SGA is wiped out, but we don't need anything that was in the SGA. It will be as if this transaction never happened when we restart. None of the blocks with changes got flushed to disk, and none of the redo got flushed to disk. We have no need of any of this undo or redo to recover from an instance failure.
Hypothetical Scenario: The Buffer Cache Fills Up Right Now
The situation is such that DBWR must make room and our modified blocks are to be flushed from the cache. In this case, DBWR will start by asking LGWR to flush the redo entries that protect these database blocks. Before DBWR can write any of the blocks that are changed to disk, LGWR must flush the redo information related to these blocks. This makes sense: if we were to flush the modified blocks for table T without flushing the redo entries associated with the undo blocks, and the system failed, we would have a modified table T block with no undo information associated with it. We need to flush the redo log buffers before writing these blocks out so that we can redo all of the changes necessary to get the SGA back into the state it is in right now, so that a rollback can take place.
This second scenario shows some of the foresight that has gone into all of this. The set of conditions described by "If we flushed table T blocks and did not flush the redo for the undo blocks and the system failed" is starting to get complex. It only gets more complex as we add users, and more objects, and concurrent processing, and so on.
At this point, we have the situation depicted in Figure 9-1. We have generated some modified table and index blocks. These have associated undo segment blocks, and all three types of blocks have generated redo to protect them. If you recall from our discussion of the redo log buffer in Chapter 4, it is flushed every three seconds, when it is one-third full or contains 1MB of buffered data, or whenever a commit takes place. It is very possible that at some point during our processing, the redo log buffer will be flushed. In that case, the picture looks like Figure 9-2.

Figure 9-2. State of the system after a redo log buffer flush
The UPDATE
The UPDATE will cause much of the same work as the INSERT to take place. This time, the amount of undo will be larger; we have some "before" images to save as a result of the update. Now, we have the picture shown in Figure 9-3.
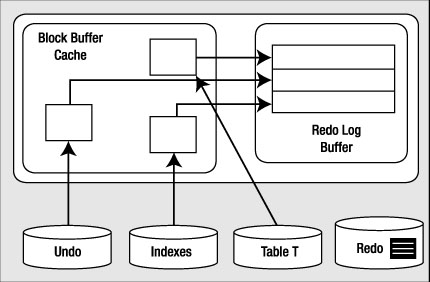
Figure 9-3. State of the system after the UPDATE
We have more new undo segment blocks in the block buffer cache. To undo the update, if necessary, we have modified database table and index blocks in the cache. We have also generated more redo log buffer entries. Let's assume that some of our generated redo log from the insert is on disk and some is in cache.
Hypothetical Scenario: The System Crashes Right Now
Upon startup, Oracle would read the redo logs and find some redo log entries for our transaction. Given the state in which we left the system, with the redo entries for the insert in the redo log files and the redo for the update still in the buffer, Oracle would "roll forward" the insert. We would end up with a picture much like Figure 9-1, with some undo blocks (to undo the insert), modified table blocks (right after the insert), and modified index blocks (right after the insert). Oracle will discover that our transaction never committed and will roll it back since the system is doing crash recovery and, of course, our session is no longer connected. It will take the undo it just rolled forward in the buffer cache and apply it to the data and index blocks, making them look as they did before the insert took place. Now everything is back the way it was. The blocks that are on disk may or may not reflect the INSERT (it depends on whether or not our blocks got flushed before the crash). If they do, then the insert has been, in effect, undone, and when the blocks are flushed from the buffer cache, the data file will reflect that. If they do not reflect the insert, so be it—they will be overwritten later anyway.
This scenario covers the rudimentary details of a crash recovery. The system performs this as a two-step process. First it rolls forward, bringing the system right to the point of failure, and then it proceeds to roll back everything that had not yet committed. This action will resynchronize the data files. It replays the work that was in progress and undoes anything that has not yet completed.
Hypothetical Scenario: The Application Rolls Back the Transaction
At this point, Oracle will find the undo information for this transaction either in the cached undo segment blocks (most likely) or on disk if they have been flushed (more likely for very large transactions). It will apply the undo information to the data and index blocks in the buffer cache, or if they are no longer in the cache request, they are read from disk into the cache to have the undo applied to them. These blocks will later be flushed to the data files with their original row values restored.
This scenario is much more common than the system crash. It is useful to note that during the rollback process, the redo logs are never involved. The only time redo logs are read is during recovery and archival. This is a key tuning concept: redo logs are written to. Oracle does not read them during normal processing. As long as you have sufficient devices so that when ARCH is reading a file, LGWR is writing to a different device, then there is no contention for redo logs. Many other databases treat the log files as "transaction logs." They do not have this separation of redo and undo. For those systems, the act of rolling back can be disastrous—the rollback process must read the logs their log writer is trying to write to. They introduce contention into the part of the system that can least stand it. Oracle's goal is to make it so that logs are written sequentially, and no one ever reads them while they are being written.
The DELETE
Again, undo is generated as a result of the DELETE, blocks are modified, and redo is sent over to the redo log buffer. This is not very different from before. In fact, it is so similar to the UPDATE that we are going to move right on to the COMMIT.
The COMMIT
We've looked at various failure scenarios and different paths, and now we've finally made it to the COMMIT. Here, Oracle will flush the redo log buffer to disk, and the picture will look like Figure 9-4.

Figure 9-4. State of the system after a COMMIT
The modified blocks are in the buffer cache; maybe some of them have been flushed to disk. All of the redo necessary to replay this transaction is safely on disk and the changes are now permanent. If we were to read the data directly from the data files, we probably would see the blocks as they existed before the transaction took place, as DBWR most likely has not written them yet. That is OK—the redo log files can be used to bring up to date those blocks in the event of a failure. The undo information will hang around until the undo segment wraps around and reuses those blocks. Oracle will use that undo to provide for consistent reads of the affected objects for any session that needs them.
Commit and Rollback Processing
It is important for us to understand how redo log files might impact us as developers. We will look at how the different ways we can write our code affect redo log utilization. We've already seen the mechanics of redo earlier in the chapter, and now we'll look at some specific issues. Many of these scenarios might be detected by you, but would be fixed by the DBA as they affect the database instance as a whole. We'll start with what happens during a COMMIT, and then get into commonly asked questions and issues surrounding the online redo logs.
What Does a COMMIT Do?
As a developer, you should have a good understanding of exactly what goes on during a COMMIT. In this section, we'll investigate what happens during the processing of the COMMIT statement in Oracle. A COMMIT is generally a very fast operation, regardless of the transaction size. You might think that the bigger a transaction (in other words, the more data it affects), the longer a COMMIT will take. This is not true. The response time of a COMMIT is generally "flat," regardless of the transaction size. This is because a COMMIT does not really have too much work to do, but what it does do is vital.
One of the reasons this is an important fact to understand and embrace is that it will lead you down the path of letting your transactions be as big as they should be. As we discussed in the previous chapter, many developers artificially constrain the size of their transactions, committing every so many rows, instead of committing when a logical unit of work has been performed. They do this in the mistaken belief that they are preserving scarce system resources, when in fact they are increasing them. If a COMMIT of one row takes X units of time, and the COMMIT of 1,000 rows takes the same X units of time, then performing work in a manner that does 1,000 one-row COMMITs will take an additional 1,000*X units of time to perform. By committing only when you have to (when the logical unit of work is complete), you will not only increase performance, but also reduce contention for shared resources (log files, various internal latches, and the like). A simple example demonstrates that it necessarily takes longer. We'll use a Java application, although you should expect similar results from most any client—except, in this case, PL/SQL (we'll discuss why that is after the example). To start, here is the sample table we'll be inserting into:
scott@ORA10G> desc test
Name Null? Type
----------------- -------- ------------
ID NUMBER
CODE VARCHAR2(20)
DESCR VARCHAR2(20)
INSERT_USER VARCHAR2(30)
INSERT_DATE DATE
Our Java program will accept two inputs: the number of rows to INSERT (iters) and how many rows between commits (commitCnt). It starts by connecting to the database, setting autocommit off (which should be done in all Java code), and then calling a doInserts() method a total of three times:
- Once just to warm up the routine (make sure all of the classes are loaded)
- A second time, specifying the number of rows to
INSERTalong with how many rows to commit at a time (i.e., commit every N rows) - A final time with the number of rows and number of rows to commit set to the same value (i.e., commit after all rows have been inserted)
It then closes the connection and exits. The main method is as follows:
import java.sql.*;
import oracle.jdbc.OracleDriver;
import java.util.Date;
public class perftest
{
public static void main (String arr[]) throws Exception
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection con = DriverManager.getConnection
("jdbc:oracle:thin:@localhost.localdomain:1521:ora10g",
"scott", "tiger");
Integer iters = new Integer(arr[0]);
Integer commitCnt = new Integer(arr[1]);
con.setAutoCommit(false);
doInserts( con, 1, 1 );
doInserts( con, iters.intValue(), commitCnt.intValue() );
doInserts( con, iters.intValue(), iters.intValue() );
con.commit();
con.close();
}
Now, the method doInserts() is fairly straightforward. It starts by preparing (parsing) an INSERT statement so we can repeatedly bind/execute it over and over:
static void doInserts(Connection con, int count, int commitCount )
throws Exception
{
PreparedStatement ps =
con.prepareStatement
("insert into test " +
"(id, code, descr, insert_user, insert_date)"
+ " values (?,?,?, user, sysdate)");
It then loops over the number of rows to insert, binding and executing the INSERT over and over. Additionally, it is checking a row counter to see if it needs to COMMIT or not inside the loop. Note also that before and after the loop we are retrieving the time, so we can monitor elapsed times and report them:
int rowcnt = 0;
int committed = 0;
long start = new Date().getTime();
for (int i = 0; i < count; i++ )
{
ps.setInt(1,i);
ps.setString(2,"PS - code" + i);
ps.setString(3,"PS - desc" + i);
ps.executeUpdate();
rowcnt++;
if ( rowcnt == commitCount )
{
con.commit();
rowcnt = 0;
committed++;
}
}
con.commit();
long end = new Date().getTime();
System.out.println
("pstatement " + count + " times in " +
(end - start) + " milli seconds committed = "+committed);
}
}
Now we'll run this code repeatedly with different inputs:
$ java perftest 10000 1
pstatement 1 times in 4 milli seconds committed = 1
pstatement 10000 times in 11510 milli seconds committed = 10000
pstatement 10000 times in 2708 milli seconds committed = 1
$ java perftest 10000 10
pstatement 1 times in 4 milli seconds committed = 1
pstatement 10000 times in 3876 milli seconds committed = 1000
pstatement 10000 times in 2703 milli seconds committed = 1
$ java perftest 10000 100
pstatement 1 times in 4 milli seconds committed = 1
pstatement 10000 times in 3105 milli seconds committed = 100
pstatement 10000 times in 2694 milli seconds committed = 1
As you can see, the more often you commit, the longer it takes (your mileage will vary on this). This is just a single-user scenario—with multiple users doing the same work, all committing too frequently, the numbers will go up rapidly.
We've heard the same story, time and time again, with other similar situations. For example, we've seen how not using bind variables and performing hard parses frequently severely reduces concurrency due to library cache contention and excessive CPU utilization. Even when we switch to using bind variables, soft parsing too frequently, caused by closing cursors even though we are going to reuse them shortly, incurs massive overhead. We must perform operations only when we need to—a COMMIT is just another such operation. It is best to size our transactions based on business need, not based on misguided attempts to lessen resource usage on the database.
There are two contributing factors to the expense of the COMMIT in this example:
- We've obviously increased the round-trips to and from the database. If we commit every record, we are generating that much more traffic back and forth.
- Every time we commit, we must wait for our redo to be written to disk. This will result in a "wait." In this case, the wait is named "log file sync."
We can actually observe the latter easily by slightly modifying the Java application. We'll do two things:
- Add a call to
DBMS_MONITORto enable SQL tracing with wait events. In Oracle9i, we would usealter session set events'10046 trace name context forever, level 12'instead, asDBMS_MONITORis new in Oracle 10g. - Change the
con.commit()call to be a call to a SQL statement to perform the commit. If you use the built-in JDBCcommit()call, this does not emit a SQLCOMMITstatement to the trace file, andTKPROF, the tool used to format a trace file, will not report the time spent doing theCOMMIT.
So, we modify the doInserts() method as follows:
doInserts( con, 1, 1 );
Statement stmt = con.createStatement ();
stmt.execute
( "begin dbms_monitor.session_trace_enable(waits=>TRUE); end;" );
doInserts( con, iters.intValue(), iters.intValue() );
To the main method, we add the following:
PreparedStatement commit =
con.prepareStatement
("begin /* commit size = " + commitCount + " */ commit; end;" );
int rowcnt = 0;
int committed = 0;
...
if ( rowcnt == commitCount )
{
commit.executeUpdate();
rowcnt = 0;
committed++;
Upon running that application with 10,000 rows to insert, committing every row, the TKPROF report would show results similar to the following:
begin /* commit size = 1 */ commit; end;
....
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 10000 0.00 0.01
SQL*Net message from client 10000 0.00 0.04
log file sync 8288 0.06 2.00
If we insert 10,000 rows and only commit when all 10,000 are inserted, we get results similar to the following:
begin /* commit size = 10000 */ commit; end;
....
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
----------------------------------------- Waited ---------- ------------
log file sync 1 0.00 0.00
SQL*Net message to client 1 0.00 0.00
SQL*Net message from client 1 0.00 0.00
When we committed after every INSERT, we waited almost every time—and if you wait a little bit of time but you wait often, then it all adds up. Fully two seconds of our runtime was spent waiting for a COMMIT to complete—in other words, waiting for LGWR to write the redo to disk. In stark contrast, when we committed once, we didn't wait very long (not a measurable amount of time actually). This proves that a COMMIT is a fast operation; we expect the response time to be more or less flat, not a function of the amount of work we've done.
So, why is a COMMIT's response time fairly flat, regardless of the transaction size? Before we even go to COMMIT in the database, we've already done the really hard work. We've already modified the data in the database, so we've already done 99.9 percent of the work. For example, operations such as the following have already taken place:
- Undo blocks have been generated in the SGA.
- Modified data blocks have been generated in the SGA.
- Buffered redo for the preceding two items has been generated in the SGA.
- Depending on the size of the preceding three items, and the amount of time spent, some combination of the previous data may be flushed onto disk already.
- All locks have been acquired.
When we COMMIT, all that is left to happen is the following:
- An SCN is generated for our transaction. In case you are not familiar with it, the SCN is a simple timing mechanism Oracle uses to guarantee the ordering of transactions and to enable recovery from failure. It is also used to guarantee read-consistency and checkpointing in the database. Think of the SCN as a ticker; every time someone
COMMITs, the SCN is incremented by one. LGWRwrites all of our remaining buffered redo log entries to disk and records the SCN in the online redo log files as well. This step is actually theCOMMIT. If this step occurs, we have committed. Our transaction entry is "removed" fromV$TRANSACTION—this shows that we have committed.- All locks recorded in
V$LOCKheld by our session are released, and everyone who was enqueued waiting on locks we held will be woken up and allowed to proceed with their work. - Some of the blocks our transaction modified will be visited and "cleaned out" in a fast mode if they are still in the buffer cache. Block cleanout refers to the lock-related information we store in the database block header. Basically, we are cleaning out our transaction information on the block, so the next person who visits the block won't have to. We are doing this in a way that need not generate redo log information, saving considerable work later (this is discussed more fully in the upcoming "Block Cleanout" section).
As you can see, there is very little to do to process a COMMIT. The lengthiest operation is, and always will be, the activity performed by LGWR, as this is physical disk I/O. The amount of time spent by LGWR here will be greatly reduced by the fact that it has already been flushing the contents of the redo log buffer on a recurring basis. LGWR will not buffer all of the work you do for as long as you do it; rather, it will incrementally flush the contents of the redo log buffer in the background as you are going along. This is to avoid having a COMMIT wait for a very long time in order to flush all of your redo at once.
So, even if we have a long-running transaction, much of the buffered redo log it generates would have been flushed to disk, prior to committing. On the flip side of this is the fact that when we COMMIT, we must wait until all buffered redo that has not been written yet is safely on disk. That is, our call to LGWR is a synchronous one. While LGWR may use asynchronous I/O to write in parallel to our log files, our transaction will wait for LGWR to complete all writes and receive confirmation that the data exists on disk before returning.
Now, earlier I mentioned that we were using a Java program and not PL/SQL for a reason—and that reason is a PL/SQL commit-time optimization. I said that our call to LGWR is a synchronous one, and that we wait for it to complete its write. That is true in Oracle 10g Release 1 and before for every programmatic language except PL/SQL. The PL/SQL engine, realizing that the client does not know whether or not a COMMIT has happened in the PL/SQL routine until the PL/SQL routine is completed, does an asynchronous commit. It does not wait for LGWR to complete; rather, it returns from the COMMIT call immediately. However, when the PL/SQL routine is completed, when we return from the database to the client, the PL/SQL routine will wait for LGWR to complete any of the outstanding COMMITs. So, if you commit 100 times in PL/SQL and then return to the client, you will likely find you waited for LGWR once—not 100 times—due to this optimization. Does this imply that committing frequently in PL/SQL is a good or OK idea? No, not at all—just that it is not as bad an idea as it is in other languages. The guiding rule is to commit when your logical unit of work is complete—not before.
Note This commit-time optimization in PL/SQL may be suspended when you are performing distributed transactions or Data Guard in maximum availability mode. Since there are two participants, PL/SQL must wait for the commit to actually be complete before continuing on.
To demonstrate that a COMMIT is a "flat response time" operation, we'll generate varying amounts of redo and time the INSERTs and COMMITs. To do this, we'll again use AUTOTRACE in SQL*Plus. We'll start with a big table of test data we'll insert into another table and an empty table:
ops$tkyte@ORA10G> @big_table 100000
ops$tkyte@ORA10G> create table t as select * from big_table where 1=0;
Table created.
And then in SQL*Plus we'll run the following:
ops$tkyte@ORA10G> set timing on
ops$tkyte@ORA10G> set autotrace on statistics;
ops$tkyte@ORA10G> insert into t select * from big_table where rownum <= 10;
ops$tkyte@ORA10G> commit;
We monitor the redo size statistic presented by AUTOTRACE and the timing information presented by set timing on. I performed this test and varied the number of rows inserted from 10 to 100,000 in multiples of 10. Table 9-1 shows my observations.
Table 9-1. Time to COMMIT by Transaction Size*
| Rows Inserted | Time to Insert (Seconds) | Redo Size (Bytes) | Commit Time (Seconds) |
| * This test was performed on a single-user machine with an 8MB log buffer and two 512MB online redo log files. | |||
| 10 | 0.05 | 116 | 0.06 |
| 100 | 0.08 | 3,594 | 0.04 |
| 1,000 | 0.07 | 372,924 | 0.06 |
| 10,000 | 0.25 | 3,744,620 | 0.06 |
| 100,000 | 1.94 | 37,843,108 | 0.07 |
As you can see, as we generate varying amount of redo, from 116 bytes to 37MB, the difference in time to COMMIT is not measurable using a timer with a one hundredth of a second resolution. As we were processing and generating the redo log, LGWR was constantly flushing our buffered redo information to disk in the background. So, when we generated 37MB of redo log information, LGWR was busy flushing every 1MB or so. When it came to the COMMIT, there wasn't much left to do—not much more than when we created ten rows of data. You should expect to see similar (but not exactly the same) results, regardless of the amount of redo generated.
What Does a ROLLBACK Do?
By changing the COMMIT to ROLLBACK, we can expect a totally different result. The time to roll back will definitely be a function of the amount of data modified. I changed the script developed in the previous section to perform a ROLLBACK instead (simply change the COMMIT to ROLLBACK) and the timings are very different (see Table 9-2).
Table 9-2. Time to ROLLBACK by Transaction Size
| Rows Inserted | Rollback Time (Seconds) | Commit Time (Seconds) |
| 10 | 0.04 | 0.06 |
| 100 | 0.05 | 0.04 |
| 1,000 | 0.06 | 0.06 |
| 10,000 | 0.22 | 0.06 |
| 100,000 | 1.46 | 0.07 |
This is to be expected, as a ROLLBACK has to physically undo the work we've done. Similar to a COMMIT, a series of operations must be performed. Before we even get to the ROLLBACK, the database has already done a lot of work. To recap, the following would have happened:
- Undo segment records have been generated in the SGA.
- Modified data blocks have been generated in the SGA.
- A buffered redo log for the preceding two items has been generated in the SGA.
- Depending on the size of the preceding three items, and the amount of time spent, some combination of the previous data may be flushed onto disk already.
- All locks have been acquired.
When we ROLLBACK,
- We undo all of the changes made. This is accomplished by reading the data back from the undo segment, and in effect, reversing our operation and then marking the undo entry as applied. If we inserted a row, a
ROLLBACKwill delete it. If we updated a row, a rollback will reverse the update. If we deleted a row, a rollback will re-insert it again. - All locks held by our session are released, and everyone who was enqueued waiting on locks we held will be released.
A COMMIT, on the other hand, just flushes any remaining data in the redo log buffers. It does very little work compared to a ROLLBACK. The point here is that you don't want to roll back unless you have to. It is expensive since you spend a lot of time doing the work, and you'll also spend a lot of time undoing the work. Don't do work unless you're sure you are going to want to COMMIT it. This sounds like common sense—of course I wouldn't do all of the work unless I wanted to COMMIT it. Many times, however, I've seen a situation where a developer will use a "real" table as a temporary table, fill it up with data, report on it, and then roll back to get rid of the temporary data. In the next section, we'll talk about true temporary tables and how to avoid this issue.
Investigating Redo
As a developer, it's often important to be able to measure how much redo your operations generate. The more redo you generate, the longer your operations will take, and the slower the entire system will be. You are not just affecting your session, but every session. Redo manage-ment is a point of serialization within the database. There is just one LGWR in any Oracle instance, and eventually all transactions end up at LGWR, asking it to manage their redo and COMMIT their transaction. The more it has to do, the slower the system will be. By seeing how much redo an operation tends to generate, and testing more than one approach to a problem, you can find the best way to do things.
Measuring Redo
It is pretty straightforward to see how much redo is being generated, as shown earlier in the chapter. I used the AUTOTRACE built-in feature of SQL*Plus. But AUTOTRACE works only with simple DML—it cannot, for example, be used to view what a stored procedure call did. For that, we'll need access to two dynamic performance views:
V$MYSTAT, which has just our session's statistics in itV$STATNAME, which tells us what each row inV$MYSTATrepresents (the name of the statistic we are looking at)
I do these sorts of measurements so often that I use two scripts I call mystat and mystat2. The mystat.sql script saves the beginning value of the statistic I'm interested in, such as redo size, in a SQL*Plus variable:
set verify off
column value new_val V
define S="&1"
set autotrace off
select a.name, b.value
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
and lower(a.name) like '%' || lower('&S')||'%'
/
The mystat2.sql script simply prints out the difference between the beginning value and the end value of that statistic:
set verify off
select a.name, b.value V, to_char(b.value-&V,'999,999,999,999') diff
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
and lower(a.name) like '%' || lower('&S')||'%'
/
Now we're ready to measure how much redo a given transaction would generate. All we need to do is this:
@mystat "redo size"
...process...
@mystat2
for example:
ops$tkyte@ORA10G> @mystat "redo size"
NAME VALUE
------------------------------ ----------
redo size 496
ops$tkyte@ORA10G> insert into t select * from big_table;
100000 rows created.
ops$tkyte@ORA10G> @mystat2
NAME V DIFF
------------------------------ ---------- ----------------
redo size 37678732 37,678,236
As just shown, we generated about 37MB of redo for that INSERT. Perhaps you would like to compare that to the redo generated by a direct path INSERT, as follows:
Note The example in this section was performed on a NOARCHIVELOG mode database. If you are in ARCHIVELOG mode, the table would have to be NOLOGGING to observe this dramatic change. We will investigate the NOLOGGING attribute in more detail shortly in the section "Setting NOLOGGING in SQL." But please make sure to coordinate all nonlogged operations with your DBA on a "real" system.
ops$tkyte@ORA10G> @mystat "redo size"
NAME VALUE
------------------------------ ----------
redo size 37678732
ops$tkyte@ORA10G> insert /*+ APPEND */ into t select * from big_table;
100000 rows created.
ops$tkyte@ORA10G> @mystat2
ops$tkyte@ORA10G> set echo off
NAME V DIFF
------------------------------ ---------- ----------------
redo size 37714328 35,596
The method I outline using the V$MYSTAT view is useful in general for seeing the side effects of various options. The mystat.sql script is useful for small tests, with one or two operations, but what if we want to perform a big series of tests? This is where a little test harness can come in handy, and in the next section we'll set up and use this test harness alongside a table to log our results, to investigate the redo generated by BEFORE triggers.
Redo Generation and BEFORE/AFTER Triggers
I'm often asked the following question: "Other than the fact that you can modify the values of a row in a BEFORE trigger, are there any other differences between BEFORE and AFTER triggers?" Well, as it turns out, yes there are. A BEFORE trigger tends to add additional redo information, even if it does not modify any of the values in the row. In fact, this is an interesting case study, and using the techniques described in the previous section, we'll discover that
- A
BEFOREorAFTERtrigger does not affect the redo generated byDELETEs. - In Oracle9i Release 2 and before, an
INSERTgenerates extra redo in the same amount for either aBEFOREor anAFTERtrigger. In Oracle 10g, it generates no additional redo. - In all releases up to (and including) Oracle9i Release 2, the redo generated by an
UPDATEis affected only by the existence of aBEFOREtrigger. AnAFTERtrigger adds no additional redo. However, in Oracle 10g, the behavior is once again different. Specifically,- Overall, the amount of redo generated during an update on a table without a trigger is less than in Oracle9i and before. This seems to be the crux of what Oracle wanted to achieve: to decrease the amount of redo generated by an update on a table without any triggers.
- The amount of redo generated during an update on a table with a
BEFOREtrigger is higher in Oracle 10g than in 9i. - The amount of redo generated with the
AFTERtrigger is the same as in 9i.
To perform this test, we'll use a table T defined as follows:
create table t ( x int, y char(N), z date );
but we'll create it with varying sizes for N. In this example, we'll use N = 30, 100, 500, 1,000, and 2,000 to achieve rows of varying widths. After we run our test for various sizes of the Y column, we'll analyze the results. I used a simple log table to capture the results of my many runs:
create table log ( what varchar2(15), -- will be no trigger, after or before
op varchar2(10), -- will be insert/update or delete
rowsize int, -- will be the size of Y
redo_size int, -- will be the redo generated
rowcnt int ) -- will be the count of rows affected
I used the following DO_WORK stored procedure to generate my transactions and record the redo generated. The subprocedure REPORT is a local procedure (only visible in the DO_WORK procedure), and it simply reports what happened on the screen and captures the findings into our LOG table:
ops$tkyte@ORA10G> create or replace procedure do_work( p_what in varchar2 )
2 as
3 l_redo_size number;
4 l_cnt number := 200;
5
6 procedure report( l_op in varchar2 )
7 is
8 begin
9 select v$mystat.value-l_redo_size
10 into l_redo_size
11 from v$mystat, v$statname
12 where v$mystat.statistic# = v$statname.statistic#
13 and v$statname.name = 'redo size';
14
15 dbms_output.put_line(l_op || ' redo size = ' || l_redo_size ||
16 ' rows = ' || l_cnt || ' ' ||
17 to_char(l_redo_size/l_cnt,'99,999.9') ||
18 ' bytes/row' );
19 insert into log
20 select p_what, l_op, data_length, l_redo_size, l_cnt
21 from user_tab_columns
22 where table_name = 'T'
23 and column_name = 'Y';
24 end;
The local procedure SET_REDO_SIZE queries V$MYSTAT and V$STATNAME to retrieve the current amount of redo our session has generated thus far. It sets the variable L_REDO_SIZE in the procedure to that value:
25 procedure set_redo_size
26 as
27 begin
28 select v$mystat.value
29 into l_redo_size
30 from v$mystat, v$statname
31 where v$mystat.statistic# = v$statname.statistic#
32 and v$statname.name = 'redo size';
33 end;
And then there is the main routine. It collects the current redo size, runs an INSERT/UPDATE/DELETE, and then saves the redo generated by that operation to the LOG table:
34 begin
35 set_redo_size;
36 insert into t
37 select object_id, object_name, created
38 from all_objects
39 where rownum <= l_cnt;
40 l_cnt := sql%rowcount;
41 commit;
42 report('insert'),
43
44 set_redo_size;
45 update t set y=lower(y);
46 l_cnt := sql%rowcount;
47 commit;
48 report('update'),
49
50 set_redo_size;
51 delete from t;
52 l_cnt := sql%rowcount;
53 commit;
54 report('delete'),
55 end;
56 /
Now, once we have this in place, we set the width of column Y to 2,000. We then run the following script to test the three scenarios, namely no trigger, BEFORE trigger, and AFTER trigger:
ops$tkyte@ORA10G> exec do_work('no trigger'),
insert redo size = 505960 rows = 200 2,529.8 bytes/row
update redo size = 837744 rows = 200 4,188.7 bytes/row
delete redo size = 474164 rows = 200 2,370.8 bytes/row
PL/SQL procedure successfully completed.
ops$tkyte@ORA10G> create or replace trigger before_insert_update_delete
2 before insert or update or delete on T for each row
3 begin
4 null;
5 end;
6 /
Trigger created.
ops$tkyte@ORA10G> truncate table t;
Table truncated.
ops$tkyte@ORA10G> exec do_work('before trigger'),
insert redo size = 506096 rows = 200 2,530.5 bytes/row
update redo size = 897768 rows = 200 4,488.8 bytes/row
delete redo size = 474216 rows = 200 2,371.1 bytes/row
PL/SQL procedure successfully completed.
ops$tkyte@ORA10G> drop trigger before_insert_update_delete;
Trigger dropped.
ops$tkyte@ORA10G> create or replace trigger after_insert_update_delete
2 after insert or update or delete on T
3 for each row
4 begin
5 null;
6 end;
7 /
Trigger created.
ops$tkyte@ORA10G> truncate table t;
Table truncated.
ops$tkyte@ORA10G> exec do_work( 'after trigger' );
insert redo size = 505972 rows = 200 2,529.9 bytes/row
update redo size = 856636 rows = 200 4,283.2 bytes/row
delete redo size = 474176 rows = 200 2,370.9 bytes/row
PL/SQL procedure successfully completed.
The preceding output was from a run where the size of Y was 2,000 bytes. After all of the runs were complete, we are able to query the LOG table and see the following:
ops$tkyte@ORA10G> break on op skip 1
ops$tkyte@ORA10G> set numformat 999,999
ops$tkyte@ORA10G> select op, rowsize, no_trig,
before_trig-no_trig, after_trig-no_trig
2 from
3 ( select op, rowsize,
4 sum(decode( what, 'no trigger', redo_size/rowcnt,0 ) ) no_trig,
5 sum(decode( what, 'before trigger', redo_size/rowcnt, 0 ) ) before_trig,
6 sum(decode( what, 'after trigger', redo_size/rowcnt, 0 ) ) after_trig
7 from log
8 group by op, rowsize
9 )
10 order by op, rowsize
11 /
OP ROWSIZE NO_TRIG BEFORE_TRIG-NO_TRIG AFTER_TRIG-NO_TRIG
---------- -------- -------- ------------------- ------------------------
delete 30 291 0 0
100 364 −1 −0
500 785 −0 0
1,000 1,307 −0 −0
2,000 2,371 0 −0
insert 30 296 0 −0
100 367 0 0
500 822 1 1
1,000 1,381 −0 −0
2,000 2,530 0 0
update 30 147 358 152
100 288 363 157
500 1,103 355 150
1,000 2,125 342 137
2,000 4,188 300 94
15 rows selected.
Now, I was curious if the log mode (ARCHIVELOG versus NOARCHIVELOG mode) would affect these results. I discovered that the answer is no, the numbers were identical in both modes. I was curious about why the results were very different from the first edition of Expert One-on-One Oracle, upon which this book you are reading is loosely based. That book was released when Oracle8i version 8.1.7 was current. The Oracle 10g results just shown differed greatly from Oracle8i, but the Oracle9i results shown in this table resembled the Oracle8i results closely:
OP ROWSIZE NO_TRIG BEFORE_TRIG-NO_TRIG AFTER_TRIG-NO_TRIG
---------- -------- -------- ------------------- -----------------
delete 30 279 −0 −0
100 351 −0 −0
500 768 1 0
1,000 1,288 0 0
2,000 2,356 0 −11
insert 30 61 221 221
100 136 217 217
500 599 199 198
1,000 1,160 181 181
2,000 2,311 147 147
update 30 302 197 0
100 438 197 0
500 1,246 195 0
1,000 2,262 185 0
2,000 4,325 195 −1
15 rows selected.
I discovered that the way triggers affect the redo generated by a transaction materially changed between Oracle9i Release 2 and Oracle 10g. The changes are easy to see here:
- A
DELETEwas not and is still not affected by the presence of a trigger at all. - An
INSERTwas affected in Oracle9i Release 2 and before, and at first glance you might say Oracle 10g optimized theINSERTso it would not be affected, but if you look at the total redo generated without a trigger in Oracle 10g, you'll see it is the same amount that was generated in Oracle9i Release 2 and before with a trigger. So, it is not that Oracle 10g reduced the amount of redo generated by anINSERTin the presence of a trigger, but rather that the amount of redo generated is constant—and anINSERTin Oracle 10g will generate more redo than in Oracle9i without a trigger. - An
UPDATEwas affected by aBEFOREtrigger in 9i but not anAFTERtrigger. At first glance it would appear that Oracle 10g changed that so as both triggers affect it. But upon closer inspection, we can see that what actually happened was that the redo generated by anUPDATEwithout a trigger was decreased in Oracle 10g by the amount that theUPDATEgenerates with the trigger. So the opposite of what happened withINSERTs between 9i and 10g happened withUPDATEs—the amount of redo generated without a trigger decreased.
Table 9-3 summarizes the effects of a trigger on the amount of redo generated by a DML operation in both Oracle9i and before and Oracle 10g.
Table 9-3. Effect of Triggers on Redo Generation
| DML Operation | AFTER Trigger Pre-10g |
BEFORE Trigger, Pre-10g |
AFTER Trigger, 10g |
BEFORE Trigger, 10g |
DELETE |
No affect | No affect | No affect | No affect |
INSERT |
Increased redo | Increased redo | Constant redo | Constant redo |
UPDATE |
Increased redo | No affect | Increased redo | Increased redo |
So, now you know how to estimate the amount of redo, which every developer should be able to do. You can
- Estimate your "transaction" size (how much data you modify).
- Add 10 to 20 percent overhead of the amount of data you modify, depending on the number of rows you will be modifying. The more rows, the less overhead.
- Double this value for
UPDATEs.
In most cases, this will be a good estimate. The doubling on the UPDATEs is a guess—it really depends on how you modify the data. The doubling assumes you take a row of X bytes, and UPDATE it to be a row of X bytes. If you take a small row and make it big, you will not double the value (it will behave more like an INSERT). If you take a big row and make it small, you will not double the value (it will behave like a DELETE). The doubling is a "worst-case" number, as there are various options and features that will impact this—for example, the existence of indexes (or lack thereof, as in my case) will contribute to the bottom line. The amount of work that must be done to maintain the index structure may vary from UPDATE to UPDATE, and so on. Side effects from triggers have to be taken into consideration (in addition to the fixed overhead described previously). Implicit operations performed on your behalf, such as an ON DELETE CASCADE setting on a foreign key, must be considered as well. This will allow you to estimate the amount of redo for sizing/performance purposes. Only real-world testing will tell you for sure. Given the preceding script, you can see how to measure this for yourself, for any of your objects and transactions.
Can I Turn Off Redo Log Generation?
This question is often asked. The simple short answer is no, since redo logging is crucial for the database; it is not overhead and it is not a waste. You do need it, regardless of whether you believe you do or not. It is a fact of life, and it is the way the database works. If in fact you "turned off redo," then any temporary failure of disk drives, power, or some software crash would render the entire database unusable and unrecoverable. However, that said, there are some operations that can be done without generating redo log in some cases.
Note As of Oracle9i Release 2, a DBA may place the database into FORCE LOGGING mode. In that case, all operations are logged. The query SELECT FORCE_LOGGING FROM V$DATABASE may be used to see if logging is going to be forced or not. This feature is in support of Data Guard, a disaster recovery feature of Oracle that relies on redo to maintain a standby database copy.
Setting NOLOGGING in SQL
Some SQL statements and operations support the use of a NOLOGGING clause. This does not mean that all operations against the object will be performed without generating a redo log, just that some very specific operations will generate significantly less redo than normal. Note that I said "significantly less redo," not "no redo." All operations will generate some redo—all data dictionary operations will be logged regardless of the logging mode. The amount of redo generated can be significantly less. For this example of the NOLOGGING clause, I ran the following in a database running in ARCHIVELOG mode:
ops$tkyte@ORA10G> select log_mode from v$database;
LOG_MODE
------------
ARCHIVELOG
ops$tkyte@ORA10G> @mystat "redo size"
ops$tkyte@ORA10G> set echo off
NAME VALUE
---------- ----------
redo size 5846068
ops$tkyte@ORA10G> create table t
2 as
3 select * from all_objects;
Table created.
ops$tkyte@ORA10G> @mystat2
ops$tkyte@ORA10G> set echo off
NAME V DIFF
---------- ---------- ----------------
redo size 11454472 5,608,404
That CREATE TABLE generated about 5.5MB of redo information. We'll drop and re-create the table, in NOLOGGING mode this time:
ops$tkyte@ORA10G> drop table t;
Table dropped.
ops$tkyte@ORA10G> @mystat "redo size"
ops$tkyte@ORA10G> set echo off
NAME VALUE
---------- ----------
redo size 11459508
ops$tkyte@ORA10G> create table t
2 NOLOGGING
3 as
4 select * from all_objects;
Table created.
ops$tkyte@ORA10G> @mystat2
ops$tkyte@ORA10G> set echo off
NAME V DIFF
---------- ---------- ----------------
redo size 11540676 81,168
This time, there is only 80KB of redo generated.
As you can see, this makes a tremendous difference—5.5MB of redo versus 80KB. The 5.5MB is the actual table data itself; it was written directly to disk, with no redo log generated for it.
If you test this on a NOARCHIVELOG mode database, you will not see any differences. The CREATE TABLE will not be logged, with the exception of the data dictionary modifications, in a NOARCHIVELOG mode database. If you would like to see the difference on a NOARCHIVELOG mode database, you can replace the DROP TABLE and CREATE TABLE with DROP INDEX and CREATE INDEX on table T. These operations are logged by default, regardless of the mode in which the database is running. This example also points out a valuable tip: test your system in the mode it will be run in production, as the behavior may be different. Your production system will be running in ARCHIVELOG mode; if you perform lots of operations that generate redo in this mode, but not in NOARCHIVELOG mode, you'll want to discover this during testing, not during rollout to the users!
Of course, it is now obvious that you will do everything you can with NOLOGGING, right? In fact, the answer is a resounding no. You must use this mode very carefully, and only after discussing the issues with the person in charge of backup and recovery. Let's say you create this table and it is now part of your application (e.g., you used a CREATE TABLE AS SELECT NOLOGGING as part of an upgrade script). Your users modify this table over the course of the day. That night, the disk that the table is on fails. "No problem," the DBA says. "We are running in ARCHIVELOG mode, and we can perform media recovery." The problem is, however, that the initially created table, since it was not logged, is not recoverable from the archived redo log. This table is unrecoverable and this brings out the most important point about NOLOGGING operations: they must be coordinated with your DBA and the system as a whole. If you use them and others are not aware of that fact, you may compromise the ability of your DBA to recover your database fully after a media failure. They must be used judiciously and carefully.
The important things to note about NOLOGGING operations are as follows:
- Some amount of redo will be generated, as a matter of fact. This redo is to protect the data dictionary. There is no avoiding this at all. It could be of a significantly lesser amount than before, but there will be some.
NOLOGGINGdoes not prevent redo from being generated by all subsequent operations. In the preceding example, I did not create a table that is never logged. Only the single, individual operation of creating the table was not logged. All subsequent "normal" operations such asINSERTs,UPDATEs, andDELETEs will be logged. Other special operations, such as a direct path load using SQL*Loader, or a direct path insert using theINSERT /*+ APPEND */syntax, will not be logged (unless and until youALTERthe table and enable full logging again). In general, however, the operations your application performs against this table will be logged.- After performing
NOLOGGINGoperations in anARCHIVELOGmode database, you must take a new baseline backup of the affected data files as soon as possible, in order to avoid losing subsequent changes to these objects due to media failure. We wouldn't actually lose the subsequent changes, as these are in the redo log; we would lose the data to apply the changes to.
Setting NOLOGGING on an Index
There are two ways to use the NOLOGGING option. You have already seen one method—that of embedding the NOLOGGING keyword in the SQL command. The other method, which involves setting the NOLOGGING attribute on the segment (index or table), allows operations to be performed implicitly in a NOLOGGING mode. For example, I can alter an index or table to be NOLOGGING by default. This means for the index that subsequent rebuilds of this index will not be logged (the index will not generate redo; other indexes and the table itself might, but this index will not):
ops$tkyte@ORA10G> create index t_idx on t(object_name);
Index created.
ops$tkyte@ORA10G> @mystat "redo size"
ops$tkyte@ORA10G> set echo off
NAME VALUE
---------- ----------
redo size 13567908
ops$tkyte@ORA10G> alter index t_idx rebuild;
Index altered.
ops$tkyte@ORA10G> @mystat2
ops$tkyte@ORA10G> set echo off
NAME V DIFF
---------- ---------- ----------------
redo size 15603436 2,035,528
When the index is in LOGGING mode (the default), a rebuild of it generated 2MB of redo log. However, we can alter the index:
ops$tkyte@ORA10G> alter index t_idx nologging;
Index altered.
ops$tkyte@ORA10G> @mystat "redo size"
ops$tkyte@ORA10G> set echo off
NAME VALUE
---------- ----------
redo size 15605792
ops$tkyte@ORA10G> alter index t_idx rebuild;
Index altered.
ops$tkyte@ORA10G> @mystat2
ops$tkyte@ORA10G> set echo off
NAME V DIFF
---------- ---------- ----------------
redo size 15668084 62,292
and now it generates a mere 61KB of redo. But that index is "unprotected" now, if the data files it was located in failed and had to be restored from a backup, we would lose that index data. Understanding that fact is crucial. The index is not recoverable right now—we need a backup to take place. Alternatively, the DBA could just re-create the index as we can re-create the index directly from the table data as well.
NOLOGGING Wrap-Up
The operations that may be performed in a NOLOGGING mode are as follows:
- Index creations and
ALTERs (rebuilds). - Bulk
INSERTs into a table using a "direct path insert" such as that available via the/*+ APPEND */hint or SQL*Loader direct path loads. The table data will not generate redo, but all index modifications will (the indexes on this nonlogged table will generate redo!). LOBoperations (updates to large objects do not have to be logged).- Table creations via
CREATE TABLE AS SELECT. - Various
ALTER TABLEoperations such asMOVEandSPLIT.
Used appropriately on an ARCHIVELOG mode database, NOLOGGING can speed up many operations by dramatically reducing the amount of redo log generated. Suppose you have a table you need to move from one tablespace to another. You can schedule this operation to take place immediately before a backup occurs—you would ALTER the table to be NOLOGGING, move it, rebuild the indexes (without logging as well), and then ALTER the table back to logging mode. Now, an operation that might have taken X hours can happen in X/2 hours perhaps (I'm not promising a 50 percent reduction in runtime!). The appropriate use of this feature includes involvement of the DBA, or whoever is responsible for database backup and recovery or any standby databases. If that person is not aware of the use of this feature, and a media failure occurs, you may lose data, or the integrity of the standby database might be compromised. This is something to seriously consider.
Why Can't I Allocate a New Log?
I get this question all of the time. You are getting warning messages to this effect (this will be found in alert.log on your server):
Thread 1 cannot allocate new log, sequence 1466
Checkpoint not complete
Current log# 3 seq# 1465 mem# 0: /home/ora10g/oradata/ora10g/redo03.log
It might say Archival required instead of Checkpoint not complete, but the effect is pretty much the same. This is really something the DBA should be looking out for. This message will be written to alert.log on the server whenever the database attempts to reuse an online redo log file and finds that it cannot. This will happen when DBWR has not yet finished checkpointing the data protected by the redo log or ARCH has not finished copying the redo log file to the archive destination. At this point in time, the database effectively halts as far as the end user is concerned. It stops cold. DBWR or ARCH will be given priority to flush the blocks to disk. Upon completion of the checkpoint or archival, everything goes back to normal. The reason the database suspends user activity is that there is simply no place to record the changes the users are making. Oracle is attempting to reuse an online redo log file, but because either the file would be needed to recover the database in the event of a failure (Checkpoint not complete), or the archiver has not yet finished copying it (Archival required), Oracle must wait (and the end users will wait) until the redo log file can safely be reused.
If you see that your sessions spend a lot of time waiting on a "log file switch," "log buffer space," or "log file switch checkpoint or archival incomplete," then you are most likely hitting this. You will notice it during prolonged periods of database modifications if your log files are sized incorrectly, or because DBWR and ARCH need to be tuned by the DBA or system administrator. I frequently see this issue with the "starter" database that has not been customized. The "starter" database typically sizes the redo logs far too small for any sizable amount of work (including the initial database build of the data dictionary itself). As soon as you start loading up the database, you will notice that the first 1,000 rows go fast, and then things start going in spurts: 1,000 go fast, then hang, then go fast, then hang, and so on. These are the indications you are hitting this condition.
There are a couple of things you can do to solve this issue:
- Make
DBWRfaster. Have your DBA tuneDBWRby enablingASYNCI/O, usingDBWRI/O slaves, or using multipleDBWRprocesses. Look at the I/O on the system and see if one disk, or a set of disks, is "hot" so you need to therefore spread out the data. The same general advice applies forARCHas well. The pros of this are that you get "something for nothing" here—increased performance without really changing any logic/structures/code. There really are no downsides to this approach. - Add more redo log files. This will postpone the
Checkpoint not completein some cases and, after a while, it will postpone theCheckpoint not completeso long that it perhaps doesn't happen (because you gaveDBWRenough breathing room to checkpoint). The same applies to theArchival requiredmessage. The benefit to this approach is the removal of the "pauses" in your system. The downside is it consumes more disk, but the benefit far outweighs any downside here. - Re-create the log files with a larger size. This will extend the amount of time between the time you fill the online redo log and the time you need to reuse it. The same applies to the
Archival requiredmessage, if the redo log file usage is "bursty." If you have a period of massive log generation (nightly loads, batch processes) followed by periods of relative calm, then having larger online redo logs can buy enough time forARCHto catch up during the calm periods. The pros and cons are identical to the preceding approach of adding more files. Additionally, it may postpone a checkpoint from happening until later, since checkpoints happen at each log switch (at least), and the log switches will now be further apart. - Cause checkpointing to happen more frequently and more continuously. Use a smaller block buffer cache (not entirely desirable) or various parameter settings such as
FAST_START_MTTR_TARGET,LOG_CHECKPOINT_INTERVAL, andLOG_CHECKPOINT_TIMEOUT. This will forceDBWRto flush dirty blocks more frequently. The benefit to this approach is that recovery time from a failure is reduced. There will always be less work in the online redo logs to be applied. The downside is that blocks may be written to disk more frequently if they are modified often. The buffer cache will not be as effective as it could be, and it can defeat the block cleanout mechanism discussed in the next section.
The approach you take will depend on your circumstances. This is something that must be fixed at the database level, taking the entire instance into consideration.
Block Cleanout
In this section, we'll discuss block cleanouts, or the removal of "locking"-related information on the database blocks we've modified. This concept is important to understand when we talk about the infamous ORA-01555: snapshot too old error in a subsequent section.
If you recall in Chapter 6, we talked about data locks and how they are managed. I described how they are actually attributes of the data, stored on the block header. A side effect of this is that the next time that block is accessed, we may have to "clean it out"—in other words, remove the transaction information. This action generates redo and causes the block to become dirty if it wasn't already, meaning that a simple SELECT may generate redo and may cause lots of blocks to be written to disk with the next checkpoint. Under most normal circumstances, however, this will not happen. If you have mostly small- to medium-sized transactions (OLTP), or you have a data warehouse that performs direct path loads or uses DBMS_STATS to analyze tables after load operations, then you'll find the blocks are generally "cleaned" for you. If you recall from the earlier section titled "What Does a COMMIT Do?" one of the steps of COMMIT-time processing is to revisit our blocks if they are still in the SGA, if they are accessible (no one else is modifying them), and then clean them out. This activity is known as a commit cleanout and is the activity that cleans out the transaction information on our modified block. Optimally, our COMMIT can clean out the blocks so that a subsequent SELECT (read) will not have to clean it out. Only an UPDATE of this block would truly clean out our residual transaction information, and since the UPDATE is already generating redo, the cleanout is not noticeable.
We can force a cleanout to not happen, and therefore observe its side effects, by understanding how the commit cleanout works. In a commit list associated with our transaction, Oracle will record lists of blocks we have modified. Each of these lists is 20 blocks long, and Oracle will allocate as many of these lists as it needs—up to a point. If the sum of the blocks we modify exceeds 10 percent of the block buffer cache size, Oracle will stop allocating new lists for us. For example, if our buffer cache is set to cache 3,000 blocks, Oracle will maintain a list of up to 300 blocks (10 percent of 3,000) for us. Upon COMMIT, Oracle will process each of these lists of 20 block pointers, and if the block is still available, it will perform a fast cleanout. So, as long as the number of blocks we modify does not exceed 10 percent of the number of blocks in the cache and our blocks are still in the cache and available to us, Oracle will clean them out upon COMMIT. Otherwise, it just skips them (i.e., does not clean them out).
Given this understanding, we can set up artificial conditions to see how the cleanout works. I set my DB_CACHE_SIZE to a low value of 4MB, which is sufficient to hold 512 8KB blocks (my blocksize is 8KB). Then, I created a table such that a row fits on exactly one block—I'll never have two rows per block. Then, I fill this table up with 500 rows and COMMIT. I'll measure the amount of redo I have generated so far, run a SELECT that will visit each block, and then measure the amount of redo that SELECT generated.
Surprising to many people, the SELECT will have generated redo. Not only that, but it will also have "dirtied" these modified blocks, causing DBWR to write them again. This is due to the block cleanout. Next, I'll run the SELECT once again and see that no redo is generated. This is expected, as the blocks are all "clean" at this point.
ops$tkyte@ORA10G> create table t
2 ( x char(2000),
3 y char(2000),
4 z char(2000)
5 )
6 /
Table created.
ops$tkyte@ORA10G> set autotrace traceonly statistics
ops$tkyte@ORA10G> insert into t
2 select 'x', 'y', 'z'
3 from all_objects
4 where rownum <= 500;
500 rows created.
Statistics
----------------------------------------------------------
...
3297580 redo size
...
500 rows processed
ops$tkyte@ORA10G> commit;
Commit complete.
So, this is my table with one row per block (in my 8KB blocksize database). Now I will measure the amount of redo generated during the read of the data:
ops$tkyte@ORA10G> select *
2 from t;
500 rows selected.
Statistics
----------------------------------------------------------
...
36484 redo size
...
500 rows processed
So, this SELECT generated about 35KB of redo during its processing. This represents the block headers it modified during the full scan of T. DBWR will be writing these modified blocks back out to disk at some point in the future. Now, if I run the query again
ops$tkyte@ORA10G> select *
2 from t;
500 rows selected.
Statistics
----------------------------------------------------------
...
0 redo size
...
500 rows processed
ops$tkyte@ORA10G> set autotrace off
I see that no redo is generated—the blocks are all clean.
If we were to rerun the preceding example with the buffer cache set to hold at least 5,000 blocks, we'll find that we generate little to no redo on any of the SELECTs—we will not have to clean dirty blocks during either of our SELECT statements. This is because the 500 blocks we modified fit comfortably into 10 percent of our buffer cache, and we are the only users. There is no one else mucking around with the data, and no one else is causing our data to be flushed to disk or accessing those blocks. In a live system, it will be normal for at least some of the blocks to not be cleaned out sometimes.
This behavior will most affect you after a large INSERT (as just demonstrated), UPDATE, or DELETE—one that affects many blocks in the database (anything more than 10 percent of the size of the cache will definitely do it). You will notice that the first query to touch the block after this will generate a little redo and dirty the block, possibly causing it to be rewritten if DBWR had already flushed it or the instance had been shut down, clearing out the buffer cache altogether. There is not too much you can do about it. It is normal and to be expected. If Oracle did not do this deferred cleanout of a block, a COMMIT could take as long to process as the transaction itself. The COMMIT would have to revisit each and every block, possibly reading them in from disk again (they could have been flushed).
If you are not aware of block cleanouts and how they work, it will be one of those mysterious things that just seems to happen for no reason. For example, say you UPDATE a lot of data and COMMIT. Now you run a query against that data to verify the results. The query appears to generate tons of write I/O and redo. It seems impossible if you are unaware of block cleanouts; it was to me the first time I saw it. You go and get someone to observe this behavior with you, but it is not reproducible, as the blocks are now "clean" on the second query. You simply write it off as one of those database mysteries.
In an OLTP system, you will probably never see this happening, since those systems are characterized by small, short transactions that affect a few blocks. By design, all or most of the transactions are short and sweet. Modify a couple of blocks and they all get cleaned out. In a warehouse where you make massive UPDATEs to the data after a load, block cleanouts may be a factor in your design. Some operations will create data on "clean" blocks. For example, CREATE TABLE AS SELECT, direct path loaded data, and direct path inserted data will all create "clean" blocks. An UPDATE, normal INSERT, or DELETE may create blocks that need to be cleaned with the first read. This could really affect you if your processing consists of
- Bulk loading lots of new data into the data warehouse
- Running
UPDATEs on all of the data you just loaded (producing blocks that need to be cleaned out) - Letting people query the data
You will have to realize that the first query to touch the data will incur some additional processing if the block needs to be cleaned. Realizing this, you yourself should "touch" the data after the UPDATE. You just loaded or modified a ton of data; you need to analyze it at the very least. Perhaps you need to run some reports yourself to validate the load. This will clean the block out and make it so the next query doesn't have to do this. Better yet, since you just bulk loaded the data, you now need to refresh the statistics anyway. Running the DBMS_STATS utility to gather statistics may well clean out all of the blocks, as it just uses SQL to query the information and would naturally clean out the blocks as it goes along.
Log Contention
This, like the cannot allocate new log message, is something the DBA must fix, typically in conjunction with the system administrator. However, it is something a developer might detect as well if the DBA isn't watching closely enough.
If you are faced with the log contention, what you might observe is a large wait time on the "log file sync" event and long write times evidenced in the "log file parallel write" event in a Statspack report. If you observe this, you may be experiencing contention on the redo logs; they are not being written fast enough. This can happen for many reasons. One application reason (one the DBA cannot fix, but the developer must fix) is that you are committing too frequently—committing inside of a loop doing INSERTs, for example. As demonstrated in the "What Does a Commit Do?" section, committing too frequently, aside from being a bad programming practice, is a surefire way to introduce lots of log file sync waits. Assuming all of your transactions are correctly sized (you are not committing more frequently than your business rules dictate), the most common causes for log file waits that I've seen are as follows:
- Putting redo on a slow device: The disks are just performing poorly. It is time to buy faster disks.
- Putting redo on the same device as other files that are accessed frequently: Redo is designed to be written with sequential writes and to be on dedicated devices. If other components of your system—even other Oracle components—are attempting to read and write to this device at the same time as
LGWR, you will experience some degree of contention. Here, you want to ensureLGWRhas exclusive access to these devices if at all possible. - Mounting the log devices in a buffered manner: Here, you are using a "cooked" file system (not RAW disks). The operating system is buffering the data, and the database is also buffering the data (redo log buffer). Double buffering slows things down. If possible, mount the devices in a "direct" fashion. How to do this varies by operating system and device, but it is usually possible.
- Putting redo on a slow technology, such as RAID-5: RAID-5 is great for reads, but it is terrible for writes. As we saw earlier regarding what happens during a
COMMIT, we must wait forLGWRto ensure the data is on disk. Using any technology that slows this down is not a good idea.
If at all possible, you really want at least five dedicated devices for logging and optimally six to mirror your archives as well. In these days of 9GB, 20GB, 36GB, 200GB, 300GB, and larger disks, this is getting harder, but if you can set aside four of the smallest, fastest disks you can find and one or two big ones, you can affect LGWR and ARCH in a positive fashion. To lay out the disks, you would break them into three groups (see Figure 9-5):
- Redo log group 1: Disks 1 and 3
- Redo log group 2: Disks 2 and 4
- Archive: Disk 5 and optionally disk 6 (the big disks)
Figure 9-5. Optimal redo log configuration
You would place redo log group 1 with members A and B onto disk 1. You would place redo log group 2 with members C and D onto disk 2. If you have groups 3, 4, and so on, they'll go onto the odd and respectively even groups of disks. The effect of this is that LGWR, when the database is currently using group 1, will write to disks 1 and 3 simultaneously. When this group fills up, LGWR will move to disks 2 and 4. When they fill up, LGWR will go back to disks 1 and 3. Meanwhile, ARCH will be processing the full online redo logs and writing them to disks 5 and 6, the big disks. The net effect is neither ARCH nor LGWR is ever reading a disk being written to, or writing to a disk being read from, so there is no contention (see Figure 9-6).
So, when LGWR is writing group 1, ARCH is reading group 2 and writing to the archive disks. When LGWR is writing group 2, ARCH is reading group 1 and writing to the archive disks. In this fashion, LGWR and ARCH each have their own dedicated devices and will not be contending with anyone, not even each other.
Figure 9-6. Redo log flow
Online redo log files are the one set of Oracle files that benefit the most from the use of RAW disks. If there is one type of file you might consider for RAW, log files would be it. There is much back and forth discussion on the pros and cons of using RAW versus cooked file systems. As this is not a book on DBA/SA tasks, I won't get into them. I'll just mention that if you are going to use RAW devices anywhere, online redo log files would be the best candidates. You never back up online redo log files, so the fact that they are on RAW partitions versus a cooked file system won't impact any backup scripts you might have. ARCH can always turn the RAW logs into cooked file system files (you cannot use a RAW device to archive to), hence the "mystique" of RAW devices is very much minimized in this case.
Temporary Tables and Redo/Undo
Temporary tables are still considered a relatively new feature of Oracle, having been introduced only in Oracle8i version 8.1.5. As such, there is some confusion surrounding them, in particular in the area of logging. In Chapter 10, we will cover how and why you might use temporary tables. In this section, we will explore only the question "How do temporary tables work with respect to logging of changes?"
Temporary tables generate no redo for their blocks. Therefore, an operation on a temporary table is not "recoverable." When you modify a block in a temporary table, no record of this change will be made in the redo log files. However, temporary tables do generate undo, and the undo is logged. Hence, temporary tables will generate some redo. At first glance, it doesn't seem to make total sense: why would they need to generate undo? This is because you can roll back to a SAVEPOINT within a transaction. You might erase the last 50 INSERTs into a temporary table, leaving the first 50. Temporary tables can have constraints and everything else a normal table can have. They might fail a statement on the five-hundredth row of a 500-row INSERT, necessitating a rollback of that statement. Since temporary tables behave in general just like "normal" tables, temporary tables must generate undo. Since undo data must be logged, temporary tables will generate some redo log for the undo they generate.
This is not nearly as ominous as it seems. The primary SQL statements used against temporary tables are INSERTs and SELECTs. Fortunately, INSERTs generate very little undo (you need to restore the block to "nothing," and it doesn't take very much room to store "nothing"), and SELECTs generate no undo. Hence, if you use temporary tables for INSERTs and SELECTs exclusively, this section means nothing to you. It is only if you UPDATE or DELETE that you might be concerned about this.
I set up a small test to demonstrate the amount of redo generated while working with temporary tables, an indication therefore of the amount of undo generated for temporary tables, since only the undo is logged for them. To demonstrate this, I will take identically configured "permanent" and "temporary" tables, and then perform the same operations on each, measuring the amount of redo generated each time. The tables I used were simply as follows:
ops$tkyte@ORA10G> create table perm
2 ( x char(2000),
3 y char(2000),
4 z char(2000) )
5 /
Table created.
ops$tkyte@ORA10G> create global temporary table temp
2 ( x char(2000),
3 y char(2000),
4 z char(2000) )
5 on commit preserve rows
6 /
Table created.
I set up a small stored procedure to allow me to perform arbitrary SQL and report the amount of redo generated by that SQL. I will use this routine to perform INSERTs, UPDATEs, and DELETEs against both the temporary and permanent tables:
ops$tkyte@ORA10G> create or replace procedure do_sql( p_sql in varchar2 )
2 as
3 l_start_redo number;
4 l_redo number;
5 begin
6 select v$mystat.value
7 into l_start_redo
8 from v$mystat, v$statname
9 where v$mystat.statistic# = v$statname.statistic#
10 and v$statname.name = 'redo size';
11
12 execute immediate p_sql;
13 commit;
14
15 select v$mystat.value-l_start_redo
16 into l_redo
17 from v$mystat, v$statname
18 where v$mystat.statistic# = v$statname.statistic#
19 and v$statname.name = 'redo size';
20
21 dbms_output.put_line
22 ( to_char(l_redo,'9,999,999') ||' bytes of redo generated for "' ||
23 substr( replace( p_sql, chr(10), ' '), 1, 25 ) || '"...' );
24 end;
25 /
Procedure created.
Then, I ran equivalent INSERTs, UPDATEs, and DELETEs against the PERM and TEMP tables:
ops$tkyte@ORA10G> set serveroutput on format wrapped
ops$tkyte@ORA10G> begin
2 do_sql( 'insert into perm
3 select 1,1,1
4 from all_objects
5 where rownum <= 500' );
6
7 do_sql( 'insert into temp
8 select 1,1,1
9 from all_objects
10 where rownum <= 500' );
11 dbms_output.new_line;
12
13 do_sql( 'update perm set x = 2' );
14 do_sql( 'update temp set x = 2' );
15 dbms_output.new_line;
16
17 do_sql( 'delete from perm' );
18 do_sql( 'delete from temp' );
19 end;
20 /
3,297,752 bytes of redo generated for "insert into perm "...
66,488 bytes of redo generated for "insert into temp "...
2,182,200 bytes of redo generated for "update perm set x = 2"...
1,100,252 bytes of redo generated for "update temp set x = 2"...
3,218,804 bytes of redo generated for "delete from perm"...
3,212,084 bytes of redo generated for "delete from temp"...
PL/SQL procedure successfully completed.
- The
INSERTinto the "real" table generated a lot of redo. Almost no redo was generated for the temporary table. This makes sense—there is very little undo data generated forINSERTs and only undo data is logged for temporary tables. - The
UPDATEof the real table generated about twice the amount of redo as the temporary table. Again, this makes sense. About half of thatUPDATE, the "before image," had to be saved. The "after image" (redo) for the temporary table did not have to be saved. - The
DELETEs took about the same amount of redo space. This makes sense, as the undo for aDELETEis big, but the redo for the modified blocks is very small. Hence, aDELETEagainst a temporary table takes place very much in the same fashion as aDELETEagainst a permanent table.
Note If you see the temporary table generating more redo than the permanent table with the INSERT statement, you are observing a product issue in the database that is fixed in at least Oracle 9.2.0.6 and 10.1.0.4 patch releases (the current shipping releases as of this writing).
Therefore, the following generalizations may be made regarding DML activity on temporary tables:
- An
INSERTwill generate little to no undo/redo activity. - A
DELETEwill generate the same amount of redo as a normal table. - An
UPDATEof a temporary table will generate about half the redo of anUPDATEof a normal table.
There are notable exceptions to the last statement. For example, if I UPDATE a column that is entirely NULL with 2,000 bytes of data, there will be very little undo data generated. This UPDATE will behave like the INSERT. On the other hand, if I UPDATE a column with 2,000 bytes of data to be NULL, it will behave like the DELETE as far as redo generation is concerned. On average, you can expect an UPDATE against a temporary table to produce about 50 percent of the undo/redo you would experience with a real table.
In general, common sense prevails on the amount of redo created. If the operation you perform causes undo data to be created, then determine how easy or hard it will be to reverse (undo) the effect of your operation. If you INSERT 2,000 bytes, the reverse of this is easy. You simply go back to no bytes. If you DELETE 2,000 bytes, the reverse is INSERTing 2,000 bytes. In this case, the redo is substantial.
Armed with this knowledge, you will avoid deleting from temporary tables. You can use TRUNCATE (bearing in mind, of course, that TRUNCATE is DDL that will commit your transaction and, in Oracle9i and before, invalidate your cursors) or just let the temporary tables empty themselves automatically after a COMMIT or when your session terminated. All of these methods generate no undo and, therefore, no redo. You will try to avoid updating a temporary table unless you really have to for some reason. You will use temporary tables mostly as something to be INSERTed into and SELECTed from. In this fashion, you'll make optimum use of their unique ability to not generate redo.
Investigating Undo
We've already discussed a lot of undo segment topics. We've seen how they are used during recovery, how they interact with the redo logs, and how they are used for consistent, non-blocking reads of data. In this section, we'll look at the most frequently raised issues with undo segments.
The bulk of our time will be spent on the infamous ORA-01555: snapshot too old error, as this single issue causes more confusion than any other topic in the entire set of database topics. Before we do this, however, we'll investigate one other undo-related issue in the next section: the question of what type of DML operation generates the most and least undo (you might already be able to answer that yourself, given the preceding examples with temporary tables).
What Generates the Most and Least Undo?
This is a frequently asked but easily answered question. The presence of indexes (or the fact that a table is an index-organized table) may affect the amount of undo generated dramatically, as indexes are complex data structures and may generate copious amounts of undo information.
That said, an INSERT will, in general, generate the least amount of undo, since all Oracle needs to record for this is a rowid to "delete." An UPDATE is typically second in the race (in most cases). All that needs to be recorded are the changed bytes. It is most common that you UPDATE some small fraction of the entire row's data. Therefore, a small fraction of the row must be remembered in the undo. Many of the previous examples run counter to this rule of thumb, but that is because they update large, fixed-sized rows, and they update the entire row. It is much more common to UPDATE a row and change a small percentage of the total row. A DELETE will, in general, generate the most undo. For a DELETE, Oracle must record the entire row's before image into the undo segment. The previous temporary table example, with regard to redo generation, demonstrated that fact: the DELETE generated the most redo, and since the only logged element of the DML operation on a temporary table is the undo, we in fact observed that the DELETE generated the most undo. The INSERT generated very little undo that needed to be logged. The UPDATE generated an amount equal to the before image of the data that was changed, and the DELETE generated the entire set of data written into the undo segment.
As previously mentioned, you must also take into consideration the work performed on an index. You will find that an update of an unindexed column not only executes much faster, but will tend to generate significantly less undo than an update of an indexed column. For example, we'll create a table with two columns both containing the same information and index one of them:
ops$tkyte@ORA10G> create table t
2 as
3 select object_name unindexed,
4 object_name indexed
5 from all_objects
6 /
Table created.
ops$tkyte@ORA10G> create index t_idx on t(indexed);
Index created.
ops$tkyte@ORA10G> exec dbms_stats.gather_table_stats(user,'T'),
PL/SQL procedure successfully completed.
Now we'll update the table, first updating the unindexed column and then the indexed column. We'll need a new V$ query to measure the amount of undo we've generated in each case. The following query accomplishes this for us. It works by getting our session ID (SID) from V$MYSTAT, using that to find our record in the V$SESSION view, and retrieving the transac-tion address (TADDR). It uses the TADDR to pull up our V$TRANSACTION record (if any) and selects the USED_UBLK column—the number of used undo blocks. Since we currently are not in a transaction, the query is expected to return 0 rows right now:
ops$tkyte@ORA10G> select used_ublk
2 from v$transaction
3 where addr = (select taddr
4 from v$session
5 where sid = (select sid
6 from v$mystat
7 where rownum = 1
8 )
9 )
10 /
no rows selected
This is the query I'll use after each UPDATE, but I won't repeat it in the text—I'll just show the results.
Now we are ready to perform the updates and measure the number of undo blocks used by each:
ops$tkyte@ORA10G> update t set unindexed = lower(unindexed);
48771 rows updated.
ops$tkyte@ORA10G> select used_ublk
...
10 /
USED_UBLK
----------
401
ops$tkyte@ORA10G> commit;
Commit complete.
That UPDATE used 401 blocks to store its undo. The commit would "free" that up, or release it, so if we rerun the query against V$TRANSACTION it would once again show us no rows selected. When we update the same data—only indexed this time—we'll observe the following:
ops$tkyte@ORA10G> update t set indexed = lower(indexed);
48771 rows updated.
ops$tkyte@ORA10G> select used_ublk
...
10 /
USED_UBLK
----------
1938
As you can see, updating that indexed column in this example generated almost five times the undo. This is due to the inherit complexity of the index structure itself and the fact that we updated every single row in the table—moving every single index key value in this structure.
ORA-01555: snapshot too old Error
In the last chapter, we briefly investigated the ORA-01555 error and looked at one cause of it: committing too frequently. Here we are going to take a much more detailed look at the causes and solutions for the ORA-01555 error. ORA-01555 is one of those errors that confound people. It is the foundation for many myths, inaccuracies, and suppositions.
Note ORA-01555 is not related to data corruption or data loss at all. It is a "safe" error in that regard; the only outcome is that the query that received this error is unable to continue processing.
The error is actually straightforward and has only two real causes, but since there is a special case of one of them that happens so frequently, I'll say that there are three:
- The undo segments are too small for the work you perform on your system.
- Your programs fetch across
COMMITs (actually a variation on the preceding point). We covered this in the last chapter. - Block cleanout.
The first two points are directly related to Oracle's read consistency model. As you recall from Chapter 7, the results of your query are pre-ordained, meaning they are well defined before Oracle goes to retrieve even the first row. Oracle provides this consistent point in time "snapshot" of the database by using the undo segments to roll back blocks that have changed since your query began. Every statement you execute, such as the following:
update t set x = 5 where x = 2;
insert into t select * from t where x = 2;
delete from t where x = 2;
select * from t where x = 2;
will see a read-consistent view of T and the set of rows where X=2, regardless of any other concurrent activity in the database.
Note The four statements presented here are just examples of the types of statements that would see a read-consistent view of T. They were not meant to be run as a single transaction in the database, as the first update would cause the following three statements to see no records. They are purely illustrative.
All statements that "read" the table take advantage of this read consistency. In the example just shown, the UPDATE reads the table to find rows where x=2 (and then UPDATEs them). The INSERT reads the table to find where X=2, and then INSERTs them, and so on. It is this dual use of the undo segments, both to roll back failed transactions and to provide for read consistency, that results in the ORA-01555 error.
The third item in the previous list is a more insidious cause of ORA-01555, in that it can happen in a database where there is a single session, and this session is not modifying the tables that are being queried when the ORA-01555 error is raised! This doesn't seem possible—why would we need undo data for a table we can guarantee is not being modified? We'll find out shortly.
Before we take a look at all three cases with illustrations, I'd like to share with you the solutions to the ORA-1555 error, in general:
- Set the parameter
UNDO_RETENTIONproperly (larger than the amount of time it takes to execute your longest running transaction).V$UNDOSTATcan be used to determine the duration of your long-running queries. Also, ensure sufficient space on disk has been set aside so the undo segments are allowed to grow to the size they need to be based on the requestedUNDO_RETENTION. - Increase or add more rollback segments when using manual undo management. This decreases the likelihood of undo data being overwritten during the course of your long-running query. This method goes toward solving all three of the previous points.
- Reduce the runtime of your query (tune it). This is always a good thing if possible, so it might be the first thing you try. This will reduce the need for larger undo segments. This method goes toward solving all three of the previous points.
- Gather statistics on related objects. This will help avoid the third point listed earlier. Since the block cleanout is the result of a very large mass
UPDATEorINSERT, this needs to be done anyway after a massUPDATEor large load.
We'll come back to these solutions, as they are important facts to know. It seemed appropriate to display them prominently before we begin.
Undo Segments Are in Fact Too Small
The scenario is this: you have a system where the transactions are small. As a result of this, you need very little undo segment space allocated. Say, for example, the following is true:
- Each transaction generates 8KB of undo on average.
- You do five of these transactions per second on average (40KB of undo per second, 2,400KB per minute).
- You have a transaction that generates 1MB of undo that occurs once per minute on average. In total, you generate about 3.5MB of undo per minute.
- You have 15MB of undo configured for the system.
That is more than sufficient undo for this database when processing transactions. The undo segments will wrap around and reuse space about every three to four minutes or so, on average. If you were to size undo segments based on your transactions that do modifications, you did all right.
In this same environment, however, you have some reporting needs. Some of these queries take a really long time to run—five minutes, perhaps. Here is where the problem comes in. If these queries take five minutes to execute and they need a view of the data as it existed when the query began, you have a very good probability of the ORA-01555 error occurring. Since your undo segments will wrap during this query execution, you know that some undo information generated since your query began is gone—it has been overwritten. If you hit a block that was modified near the time you started your query, the undo information for this block will be missing, and you will receive the ORA-01555 error.
Here is a small example. Let's say we have a table with blocks 1, 2, 3, ... 1,000,000 in it. Table 9-4 shows a sequence of events that could occur.
Table 9-4. Long-Running Query Timeline
| Time (Minutes:Seconds) | Action |
| 0:00 | Our query begins. |
| 0:01 | Another session UPDATEs block 1,000,000. Undo information for this is recorded into some undo segment. |
| 0:01 | This UPDATE session COMMITs. The undo data it generated is still there, but is now subject to being overwritten if we need the space. |
| 1:00 | Our query is still chugging along. It is at block 200,000. |
| 1:01 | Lots of activity going on. We have generated a little over 14MB of undo by now. |
| 3:00 | Our query is still going strong. We are at block 600,000 or so by now. |
| 4:00 | Our undo segments start to wrap around and reuse the space that was active when our query began at time 0:00. Specifically, we have just reused the undo segment space that the UPDATE to block 1,000,000 used back at time 0:01. |
| 5:00 | Our query finally gets to block 1,000,000. It finds it has been modified since the query began. It goes to the undo segment and attempts to find the undo for that block to get a consistent read on it. At this point, it discovers the information it needs no longer exists. ORA-01555 is raised and the query fails. |
This is all it takes. If your undo segments are sized such that they have a good chance of being reused during the execution of your queries, and your queries access data that will probably be modified, you stand a very good chance of hitting the ORA-01555 error on a recurring basis. It is at this point you must set your UNDO_RETENTION parameter higher and let Oracle take care of figuring out how much undo to retain (that is the suggested approach; it is much easier than trying to figure out the perfect undo size yourself) or resize your undo segments and make them larger (or have more of them). You need enough undo configured to last as long as your long-running queries. The system was sized for the transactions that modify data—and you forgot to size for the other components of the system.
With Oracle9i and above, there are two methods to manage undo in the system:
- Automatic undo management: Here, Oracle is told how long to retain undo for, via the
UNDO_RETENTIONparameter. Oracle will determine how many undo segments to create based on concurrent workload and how big each should be. The database can even reallocate extents between individual undo segments at runtime to meet theUNDO_RETENTIONgoal set by the DBA. This is the recommended approach for undo management. - Manual undo management: Here, the DBA does the work. The DBA determines how many undo segments to manually create, based on the estimated or observed workload. The DBA determines how big the segments should be based on transaction volume (how much undo is generated) and the length of the long-running queries.
Under manual undo management, where a DBA figures out how many undo segments to have and how big each should be, is where one of the points of confusion comes into play. People will say, "Well, we have XMB of undo configured, but they can grow. We have MAXEXTENTS set at 500 and each extent is 1MB, so the undo can get quite large." The problem is that the manually managed undo segments will never grow due to a query; they will grow only due to INSERTs, UPDATEs, and DELETEs. The fact that a long-running query is executing does not cause Oracle to grow a manual rollback segment to retain the data in case it might need it. Only a long-running UPDATE transaction would do this. In the preceding example, even if the manual rollback segments had the potential to grow, they will not. What you need to do for this system is have manual rollback segments that are already big. You need to permanently allocate space to the rollback segments, not give them the opportunity to grow on their own.
The only solutions to this problem are to either make it so that the manual rollback segments are sized so they do not wrap but every six to ten minutes, or make it so your queries never take more than two to three minutes to execute. The first suggestion is based on the fact that you have queries that take five minutes to execute. In this case, the DBA needs to make the amount of permanently allocated undo two to three times larger. The second (perfectly valid) suggestion is equally appropriate. Any time you can make the queries go faster, you should. If the undo generated since the time your query began is never overwritten, you will avoid ORA-01555.
Under automatic undo management, things are much easier from the ORA-01555 perspective. Rather than having to figure out how big the undo space needs to be and pre-allocating it, the DBA tells the database how long the longest-running query is and sets that value in the UNDO_RETENTION parameter. Oracle will attempt to preserve undo for at least that duration of time. If sufficient space to grow has been allocated, Oracle will extend an undo segment and not wrap around—in trying to obey the UNDO_RETENTION period. This is in direct contrast to manually managed undo, which will wrap around and reuse undo space as soon as it can. It is primarily for this reason, the support of the UNDO_RETENTION parameter, that I highly recommend automatic undo management whenever possible. That single parameter reduces the possibility of an ORA-01555 error greatly (when it is set appropriately!).
When using manual undo management, it is also important to remember that the probability of an ORA-01555 error is dictated by the smallest rollback segment in your system, not the largest and not the average. Adding one "big" rollback segment will not make this problem go away. It only takes the smallest rollback segment to wrap around while a query is processing, and this query stands a chance of an ORA-01555 error. This is why I was a big fan of equi-sized rollback segments when using the legacy rollback segments. In this fashion, each rollback segment is both the smallest and the largest. This is also why I avoid using "optimally" sized rollback segments. If you shrink a rollback segment that was forced to grow, you are throwing away a lot of undo that may be needed right after that. It discards the oldest rollback data when it does this, minimizing the risk, but still the risk is there. I prefer to manually shrink rollback segments during off-peak times if at all.
I am getting a little too deep into the DBA role at this point, so we'll be moving on to the next case. It's just important that you understand that the ORA-01555 error in this case is due to the system not being sized correctly for your workload. The only solution is to size correctly for your workload. It is not your fault, but it is your problem since you hit it. It is the same as if you run out of temporary space during a query. You either configure sufficient temporary space for the system, or you rewrite the queries so they use a plan that does not require temporary space.
To demonstrate this effect, we can set up a small, but somewhat artificial test. We'll create a very small undo tablespace with one session that will generate many small transactions, virtually assuring us that it will wrap around and reuse its allocated space many times—regardless of the UNDO_RETENTION setting, since we are not permitting the undo tablespace to grow. The session that uses this undo segment will be modifying a table, T. It will use a full scan of T and read it from "top" to "bottom." In another session, we will execute a query that will read the table T via an index. In this fashion, it will read the table somewhat randomly: it will read row 1, then row 1,000, then row 500, then row 20,001, and so on. In this way, we will tend to visit blocks very randomly and perhaps many times during the processing of our query. The odds of getting an ORA-01555 error in this case are virtually 100 percent. So, in one session we start with the following:
ops$tkyte@ORA10G> create undo tablespace undo_small
2 datafile size 2m
3 autoextend off
4 /
Tablespace created.
ops$tkyte@ORA10G> alter system set undo_tablespace = undo_small;
System altered.
Now, we'll set up the table T used to query and modify. Note that we are ordering the data randomly in this table. The CREATE TABLE AS SELECT tends to put the rows in the blocks in the order it fetches them from the query. We'll just scramble the rows up so they are not artificially sorted in any order, randomizing their distribution:
ops$tkyte@ORA10G> create table t
2 as
3 select *
4 from all_objects
5 order by dbms_random.random;
Table created.
ops$tkyte@ORA10G> alter table t add constraint t_pk primary key(object_id)
2 /
Table altered.
ops$tkyte@ORA10G> exec dbms_stats.gather_table_stats( user, 'T', cascade=> true );
PL/SQL procedure successfully completed.
And now we are ready to do our modifications:
ops$tkyte@ORA10G> begin
2 for x in ( select rowid rid from t )
3 loop
4 update t set object_name = lower(object_name) where rowid = x.rid;
5 commit;
6 end loop;
7 end;
8 /
Now, while that is running, we run a query in another session. This query was reading this table T and processing each record. I spent about 1/100 of a second processing each record before fetching the next (simulated using DBMS_LOCK.SLEEP(0.01)). I used the FIRST_ROWS hint in the query to have it use the index we created to read the rows out of the table via the index sorted by OBJECT_ID. Since the data was randomly inserted into the table, we would tend to query blocks in the table rather randomly. This block ran for only a couple of seconds before failing:
ops$tkyte@ORA10G> declare
2 cursor c is
3 select /*+ first_rows */ object_name
4 from t
5 order by object_id;
6
7 l_object_name t.object_name%type;
8 l_rowcnt number := 0;
9 begin
10 open c;
11 loop
12 fetch c into l_object_name;
13 exit when c%notfound;
14 dbms_lock.sleep( 0.01 );
15 l_rowcnt := l_rowcnt+1;
16 end loop;
17 close c;
18 exception
19 when others then
20 dbms_output.put_line( 'rows fetched = ' || l_rowcnt );
21 raise;
22 end;
23 /
rows fetched = 253
declare
*
ERROR at line 1:
ORA-01555: snapshot too old: rollback segment number 23 with name "_SYSSMU23$"
too small
ORA-06512: at line 21
As you can see, it got to process only 253 records before failing with the ORA-01555: snapshot too old error. To correct this, we want to make sure two things are done:
UNDO_RETENTIONis set in the database to be at least long enough for this read process to complete. That will allow the database to grow the undo tablespace to hold sufficient undo for us to complete.- The undo tablespace is allowed to grow or you manually allocate more disk space to it.
For this example, I have determined my long-running process takes about 600 seconds to complete. My UNDO_RETENTION is set to 900 (this is in seconds, so the undo retention is about 15 minutes). I altered the undo tablespace's data file to permit it to grow by 1MB at a time, up to 2GB in size:
ops$tkyte@ORA10G> column file_name new_val F
ops$tkyte@ORA10G> select file_name
2 from dba_data_files
3 where tablespace_name = 'UNDO_SMALL';
FILE_NAME
------------------------------
/home/ora10g/oradata/ora10g/OR
A10G/datafile/o1_mf_undo_sma_1
729wn1h_.dbf
ops$tkyte@ORA10G> alter database
2 datafile '&F'
3 autoextend on
4 next 1m
5 maxsize 2048m;
old 2: datafile '&F'
new 2: datafile '/home/ora10g/.../o1_mf_undo_sma_1729wn1h_.dbf'
Database altered.
When I ran the processes concurrently again, both ran to completion. The undo tablespace's data file grew this time, because it was allowed to and the undo retention I set up said to:
ops$tkyte@ORA10G> select bytes/1024/1024
2 from dba_data_files
3 where tablespace_name = 'UNDO_SMALL';
BYTES/1024/1024
---------------
11
So, instead of receiving an error, we completed successfully, and the undo grew to be large enough to accommodate our needs. It is true that in this example, getting the error was purely due to the fact that we read the table T via the index and performed random reads all over the table. If we had full scanned the table instead, there is a good chance we would not get the ORA-01555 in this particular case. This is because both the SELECT and UPDATE would have been full scanning T, and the SELECT could most likely race ahead of the UPDATE during its scan (the SELECT just has to read, but the UPDATE must read and update and therefore could go slower). By doing the random reads, we increase the probability that the SELECT will need to read a block, which the UPDATE modified and committed many rows ago. This just demonstrates the somewhat insidious nature of ORA-01555. Its occurrence depends on how concurrent sessions access and manipulate the underlying tables.
Delayed Block Cleanout
This cause of the ORA-01555 error is hard to eliminate entirely, but it is rare anyway, as the circumstances under which it occurs do not happen frequently (at least not in Oracle8i and above anymore). We have already discussed the block cleanout mechanism, but to summarize, it is the process whereby the next session to access a block after it has been modified may have to check to see if the transaction that last modified the block is still active. Once the process determines that the transaction is not active, it cleans out the block so that the next session to access it does not have to go through the same process again. To clean out the block, Oracle determines the undo segment used for the previous transaction (from the blocks header) and then determines if the undo header indicates whether it has been committed or not. This confirmation is accomplished in one of two ways. One way is that Oracle can determine that the transaction committed a long time ago, even though its transaction slot has been overwritten in the undo segment transaction table. The other way is that the COMMIT SCN is still in the transaction table of the undo segment, meaning the transaction committed a short time ago, and its transaction slot hasn't been overwritten.
To receive the ORA-01555 error from a delayed block cleanout, all of the following conditions must be met:
- A modification is made and
COMMITed, and the blocks are not cleaned out automatically (e.g., it modified more blocks than can fit in 10 percent of the SGA block buffer cache). - These blocks are not touched by another session and will not be touched until our unfortunate query (displayed shortly) hits it.
- A long-running query begins. This query will ultimately read some of those blocks from earlier. This query starts at SCN
t1, the read consistent SCN it must roll back data to in order to achieve read consistency. The transaction entry for the modification transaction is still in the undo segment transaction table when we began. - During the query, many commits are made in the system. These transactions do not touch the blocks in question (if they did, then we wouldn't have the impending problem).
- The transaction tables in the undo segments roll around and reuse slots due to the high degree of
COMMITs. Most important, the transaction entry for the original modification transaction is cycled over and reused. In addition, the system has reused undo segment extents, so as to prevent a consistent read on the undo segment header block itself. - Additionally, the lowest SCN recorded in the undo segment now exceeds
t1(it is higher than the read-consistent SCN of the query), due to the large number of commits.
When our query gets to the block that was modified and committed before it began, it is in trouble. Normally, it would go to the undo segment pointed to by the block and find the status of the transaction that modified it (in other words, it would find the COMMIT SCN of that transaction). If the COMMIT SCN is less than t1, our query can use this block. If the COMMIT SCN is greater than t1, our query must roll back that block. The problem is, however, that our query is unable to determine in this particular case if the COMMIT SCN of the block is greater than or less than t1. It is unsure as to whether it can use that block image or not. The ORA-01555 error then results.
To see this, we will create many blocks in a table that need to be cleaned out. We will then open a cursor on that table and allow many small transactions to take place against some other table—not the table we just updated and opened the cursor on. Finally, we will attempt to fetch the data for the cursor. Now, we know that the data required by the cursor will be "OK"—we should be able to see all of it since the modifications to the table would have taken place and been committed before we open the cursor. When we get an ORA-01555 error this time, it will be because of the previously described problem. To set up for this example, we'll use
- The 2MB
UNDO_SMALLundo tablespace (again). - A 4MB buffer cache, which is enough to hold about 500 blocks. This is so we can get some dirty blocks flushed to disk to observe this phenomenon.
Before we start, we'll create the big table we'll be querying:
ops$tkyte@ORA10G> create table big
2 as
3 select a.*, rpad('*',1000,'*') data
4 from all_objects a;
Table created.
ops$tkyte@ORA10G> exec dbms_stats.gather_table_stats( user, 'BIG' );
PL/SQL procedure successfully completed.
That table will have lots of blocks as we get about six or seven rows per block using that big data field. Next, we'll create the small table that the many little transactions will modify:
ops$tkyte@ORA10G> create table small ( x int, y char(500) );
Table created.
ops$tkyte@ORA10G> insert into small select rownum, 'x' from all_users;
38 rows created.
ops$tkyte@ORA10G> commit;
Commit complete.
ops$tkyte@ORA10G> exec dbms_stats.gather_table_stats( user, 'SMALL' );
PL/SQL procedure successfully completed.
Now, we'll dirty up that big table. We have a very small undo tablespace, so we'll want to update as many blocks of this big table as possible, all while generating the least amount of undo possible. We'll be using a fancy UPDATE statement to do that. Basically, the following subquery is finding the "first" rowid of a row on every block. That subquery will return a rowid for each and every database block identifying a single row on it. We'll update that row, setting a VARCHAR2(1) field. This will let us update all of the blocks in the table (some 8,000 plus in the example), flooding the buffer cache with dirty blocks that will have to be written out (we have room for only 500 right now). We'll make sure we are using that small undo tablespace as well. To accomplish this and not exceed the capacity of our undo tablespace, we'll craft an UPDATE statement that will update just the "first row" on each block. The ROW_NUMBER() built-in analytic function is instrumental in this operation; it assigns the number 1 to the "first row" by database block in the table, which would be the single row on the block we would update:
ops$tkyte@ORA10G> alter system set undo_tablespace = undo_small;
System altered.
ops$tkyte@ORA10G> update big
2 set temporary = temporary
3 where rowid in
4 (
5 select r
6 from (
7 select rowid r, row_number() over
(partition by dbms_rowid.rowid_block_number(rowid) order by rowid) rn
8 from big
9 )
10 where rn = 1
11 )
12 /
8045 rows updated.
ops$tkyte@ORA10G> commit;
Commit complete.
OK, so now we know that we have lots of dirty blocks on disk. We definitely wrote some of them out, but we just did not have the room to hold them all. Next, we opened a cursor, but did not yet fetch a single row. Remember, when we open the cursor, the result set is preordained, so even though Oracle did not actually process a row of data, the act of opening that result set fixed the point in time the results must be "as of." Now since we will be fetching the data we just updated and committed, and we know no one else is modifying the data, we should be able to retrieve the rows without needing any undo at all. But that is where the delayed block cleanout rears its head. The transaction that modified these blocks is so new that Oracle will be obliged to verify that it committed before we begin, and if we overwrite that information (also stored in the undo tablespace), the query will fail. So, here is the opening of the cursor:
ops$tkyte@ORA10G> variable x refcursor
ops$tkyte@ORA10G> exec open :x for select * from big;
PL/SQL procedure successfully completed.
ops$tkyte@ORA10G> !./run.sh
run.sh is a shell script. It simply fired off nine SQL*Plus sessions using a command:
$ORACLE_HOME/bin/sqlplus / @test2 1 &
where each SQL*Plus session was passed a different number (that was number 1; there was a 2, 3, and so on). The script test2.sql they each ran is as follows:
begin
for i in 1 .. 1000
loop
update small set y = i where x= &1;
commit;
end loop;
end;
/
exit
So, we had nine sessions inside of a tight loop initiate many transactions. The run.sh script waited for the nine SQL*Plus sessions to complete their work, and then we returned to our session, the one with the open cursor. Upon attempting to print it out, we observe the following:
ops$tkyte@ORA10G> print x
ERROR:
ORA-01555: snapshot too old: rollback segment number 23 with name "_SYSSMU23$"
too small
no rows selected
As I said, the preceding is a rare case. It took a lot of conditions, all of which must exist simultaneously to occur. We needed blocks that were in need of a cleanout to exist, and these blocks are rare in Oracle8i and above. A DBMS_STATS call to collect statistics gets rid of them so the most common causes—large mass updates and bulk loads—should not be a concern, since the tables need to be analyzed after such operations anyway. Most transactions tend to touch less then 10 percent of the block buffer cache; hence, they do not generate blocks that need to be cleaned out. In the event that you believe you've encountered this issue, in which a SELECT against a table that has no other DML applied to it is raising ORA-01555, try the following solutions:
- Ensure you are using "right-sized" transactions in the first place. Make sure you are not committing more frequently than you should.
Use DBMS_STATS to scan therelated objects, cleaning them out after the load. Since the block cleanout is the result of a very large massUPDATEorINSERT, this needs to be done anyway.- Allow the undo tablespace to grow by giving it the room to extend and increasing the undo retention. This decreases the likelihood of an undo segment transaction table slot being overwritten during the course of your long-running query. This is the same as the solution for the other cause of an
ORA-01555error (the two are very much related; you are experiencing undo segment reuse during the processing of your query). In fact, I reran the preceding example with the undo tablespace set to autoextend 1MB at a time, with an undo retention of 900 seconds. The query against the tableBIGcompleted successfully. - Reduce the runtime of your query (tune it). This is always a good thing if possible, so it might be the first thing you try.
Summary
In this chapter, we took a look at redo and undo, and what they mean to the developer. I've mostly presented here things for you to be on the lookout for, since it is actually the DBAs or SAs who must correct these issues. The most important things to take away from this chapter are the significance of redo and undo, and the fact that they are not overhead—they are integral components of the database, and are necessary and mandatory. Once you have a good understanding of how they work and what they do, you'll be able to make better use of them. Understanding that you are not "saving" anything by committing more frequently than you should (you are actually wasting resources, as it takes more CPU, more disk, and more programming) is probably the most important point. Understand what the database needs to do, and then let the database do it.