
7
Byzantine Fault Tolerance
The fault tolerance approaches we have discussed in previous chapters all adopt a non-malicious fault model. In many cases, tolerating non-malicious faults, such as those caused by power outages and node failures, are sufficient for the dependability required for a system. However, it is reasonable to expect an increasing demand for systems that can tolerate both non-malicious faults as well as malicious faults for two reasons:
- ■ Our dependency on services provided via distributed systems (often referred to as cloud services, Web services, or Internet services) has increased to the extent that such services have become essential necessities of our everyday life.
- ■ Unfortunately, cyber attacks and cyber espionage activities have also been increasing rapidly and they may inject malicious faults into a system which may disrupt the services in a number of ways:
- – Denial of service. Some or all clients are prevented from accessing the service.
- – Compromise the integrity of the service. A client’s request might not be executed as it should be and the response generated might not be correct.
- – The leak of confidential information (either confidential to the client, or confidential to the business owner).
An arbitrary (encompassing both malicious and non-malicious) fault is often referred to as a Byzantine fault. The term Byzantine fault is first coined in [26] by Lamport et al. It highlights the following specific malicious faulty behavior:
- ■ A faulty process might disseminate conflicting information to other processes. For example, a Byzantine faulty client might send different requests to different server replicas, and a faulty primary replica might propose different orders for a request to other replicas.
Because a Byzantine faulty process can choose to behave as a nonmalicious fault such as a crash fault, we can refer an arbitrary fault as a Byzantine fault. In the presence of Byzantine faults, the problem of reaching a consensus by a group of processes is referred to as Byzantine agreement [26].
Byzantine agreement and Byzantine fault tolerance have been studied over the past three decades [26, 25, 5, 6]. Early generations of algorithms for reaching Byzantine agreement and Byzantine fault tolerance are very expensive in that they incur prohibitively high runtime overhead. In 1999, Castro and Liskov published a seminal paper on a practical Byzantine fault tolerance (PBFT) algorithm [5]. PBFT significantly reduced the runtime overhead during normal operation (when the primary is not faulty). Their work revitalized this research area and we have seen (at least) hundreds of papers published subsequently.
7.1 The Byzantine Generals Problem
In [26], Lamport et al. pointed out the need to cope with faulty components that disseminate inconsistent information to different parts of the system. For example, in a distributed system that requires periodic clock synchronization, one of the processes, process k, is faulty in the following ways:
- ■ When process i queries k for the current time at local time 2:40pm, process k reports 2:50pm.
- ■ Concurrently process j queries k at local time 2:30pm, process k reports 2:20pm.
If process i and process j were to adjust their local clocks based on the information provided by the faulty process k, their clocks would diverge even further (e.g., 2:45pm for process i and 2:25pm for process j).
7.1.1 System Model
The distributed consensus problem in the presence of this type of faults is framed as a Byzantine generals problem in which a group of generals of the Byzantine army encircles an enemy city and decides whether to attack the city together or withdraw. One or more generals may be traitors. The only way for the Byzantine army to win the battle and conquer the enemy city is for all the loyal generals and their troops attack the enemy city together. Otherwise, the army would lose.
The generals communicate with each other by using messengers. The messengers are trustworthy in that they will deliver a command issued by a general in a timely manner and without any alteration. In a computer system, each general is modeled as a process, and the processes communicate via plain messages that satisfy the following requirements:
- ■ A message sent is delivered reliably and promptly.
- ■ The message carries the identifier of its sender and the identifier cannot be forged or altered by the network or any other processes.
- ■ A process can detect the missing of a message that is supposed to be sent by another process.
To tolerate f number of traitorous generals, 3f + 1 total generals are needed, one of which is a commander, and the remaining generals are lieutenants. The commander observes the enemy city and makes a decision regarding whether to attack or retreat. To make the problem and its solution more general, we expand the scope of the command issued by the commander process to contain an arbitrary value proposed by the commander (i.e., the value is not restricted to attack or retreat). A solution of the Byzantine generals problem should ensure the following interactive consistency requirements:
- IC1 All non-faulty processes (i.e., loyal generals) agree on the same value (i.e., decision).
- IC2 If the commander process is not faulty, then the value proposed by the commander must be the value that has been agreed upon by non-faulty processes.
Intuitively, a solution to the Byzantine generals problem would contain the following steps:
- ■ The commander issues a command to all its lieutenants.
- ■ The lieutenants exchange the commands they have received with each other.
- ■ Each lieutenant applies a deterministic function, such as the majority function, on the commands it has collected to derive a final decision.
A big concern for the solution is that the set of commands collected by different loyal generals might not be the same for two reasons:
- ■ The commander may send different commands to different lieutenants.
- ■ A traitorous general might lie about the command it has received from the commander.
A solution to the Byzantine generals problem must ensure that the set of commands received by loyal lieutenants be the same. Apparently the total number of generals needed to tolerate f traitorous generals has to be greater than 2f +1 because a lieutenant could not know which decision is the right one if f commands are “Attack” and the other f commands it has collected are “Retreat”. Defaulting to “Retreat” or “Attack” in this case might result in loyal generals making different decisions, as shown in the following example.
As shown in the above example, it is impossible to ensure that loyal generals reach the same decision if there are only 3 generals total and one of them might be traitorous. This observation can be generalized for the case when more than one general is traitorous. Let f be the number of traitorous generals we want to tolerate. By having each general in the 3-general example simulate f generals, it is easy to see that there is no solution if we use only 3f total number of generals. Therefore, the optimal number of generals needed to tolerate f traitorous generals is 3f + 1.
7.1.2 The Oral Message Algorithms
A solution to the Byzantine generals problem is the Oral Message algorithms [26]. The oral message algorithms are defined inductively. The solution starts by running an instance of the Oral Message algorithms OM(f) with n generals, where f is the number of traitors tolerated, and n ≥ 3f + 1. One of the generals is designated as the commander and the remaining generals are lieutenants. Each general is assigned an integer id, with the commander assigned 0, and the lieutenants assigned 1,…,n − 1, respectively.
OM(f) would trigger n − 1 instances of the OM(f − 1) algorithm (one per lieutenant), and each instance of the OM(f − 1) algorithm involves n − 1 generals (i.e., all the lieutenants). Each instance of OM(f − 1) would in turn triggers n − 2 instances of the OM(f − 2) algorithm (each involves n − 2 generals), until the base case OM(0) is reached (each OM(0) instance involves n − f generals).
Because of the recursive nature of the Oral Message algorithms, a lieutenant for OM(f) would serve as the commander for OM(f − 1), and so on. Each lieutenant i uses a scalar variable vi to store the decision value received from the commander, where i is an integer ranges from 1 to n − 1. Furthermore, a lieutenant also uses a variable vj to store the value received from lieutenant j(j ≠ i).
Algorithm OM(0):
- The commander multicasts a message containing a decision (for wider applicability of the solution, the decision could be any value) to all the lieutenants in the current instance of the algorithm.
- For each i, lieutenant i set vi to the value received from the commander. If it does not receive any value from the commander, it defaults to a predefined decision (such as “retreat”).
Algorithm OM(f):
- The commander multicasts a decision to all the lieutenants in the current instance of the algorithm.
- For each i, lieutenant i sets vi to the value received from the commander. If it does not receive any value from the commander, it defaults to a predefined decision. Subsequently, lieutenant i launches an instance of the OM(f − 1) algorithm by acting as the commander for OM(f − 1). The n − 1 generals involved in the instance of the OM(f-1) algorithm consists of all lieutenants in the OM(f,n) instance.
- For each i and j ≠ i,lieutenant i sets vj to the value received from lieutenant j ≠ i in step (2). If it does not receive any value from lieutenant j, it sets vj to the predefined default value. When all instances of the OM(f − 1) algorithm have been completed, lieutenant i chooses the value returned by the majority function on the set [v1, …, vn−1].
Before further discussion on the OM algorithms, we need to define a notation for the messages in the algorithms. Due to the recursive nature of the OM algorithms, a general may receive multiple messages that belong to different recursion levels. To distinguish these messages and to identify the recession level in which a message belongs, we denote a message received at a lieutenant i at recursion level k as ![]() , where k ranges from 0 to f, and s0, …, sk records the hierarchy of the set of OM algorithms from recursion level 0 to the level k, i.e., the commander s0 initiates the OM(f) algorithm, lieutenant s1 then invokes an instance of the OM(f − 1) algorithm upon receiving the message sent by the commander, and at the lowest recursion level lieutenant sk invokes an instance of the OM(f − k) algorithm. We may also denote the receiver id because a traitorous general might send conflicting messages to different lieutenants.
, where k ranges from 0 to f, and s0, …, sk records the hierarchy of the set of OM algorithms from recursion level 0 to the level k, i.e., the commander s0 initiates the OM(f) algorithm, lieutenant s1 then invokes an instance of the OM(f − 1) algorithm upon receiving the message sent by the commander, and at the lowest recursion level lieutenant sk invokes an instance of the OM(f − k) algorithm. We may also denote the receiver id because a traitorous general might send conflicting messages to different lieutenants.
As can be seen in Example 7.2, the algorithm descriptions for the OM algorithms are very clear when applied to the f = 1 case. It is apparent that the step (3) in the OM(f) algorithm is expressed implicitly for f = 1 (for only two levels of recursion). If 3 or more recursion levels are involved (i.e., f ≥ 2), the rules outlined for step (3) have the following two issues:
- A lieutenant i would receive more than one message from each j ≠ i in step (2). In fact, for an integer k between 1 and f inclusive, there will be
 instances of the OM(m − k) algorithm executed. Hence, there will be
instances of the OM(m − k) algorithm executed. Hence, there will be 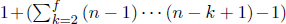 such messages for each j. It is vague as to exactly which value lieutenant i should set for vj.
such messages for each j. It is vague as to exactly which value lieutenant i should set for vj. - For an intermediate instance of the algorithm, OM(f − k), where 1 ≤ k < f, it is unclear what it means by choosing a decision based on the majority function, and especially what the implication is for this operation on the enclosing instance of the OM algorithm.
We can augment the rules for step (3) in the following ways:
- ■ We start by proposing a fix to issue 2. At lieutenant i, in step (3) of the OM(f − k) instance started by lieutenant j ≠ i, vj is set to the value returned by the majority function. This is what means by choosing the decision stated in the original rule.
- ■ Except for OM(1) and OM(0), a lieutenant only sets the v variable corresponding to itself based on the message received from its commander (there is only one such message). For the v variables corresponding to other lieutenants, a lieutenant uses the values set in step (3) of the immediate lower level recursion instance it has started.
To illustrate how the augmented rules for step (3) works, consider the following example with f = 2.
7.1.3 Proof of Correctness for the Oral Message Algorithms
We first prove the following lemma.
Lemma 7.1 For any f and 0 ≤ k ≤ f, Algorithm OM(k) satisfies the interactive consistency IC2 requirement provided that the total number of generals is greater than 3f.
Proof : The interactive consistency IC2 requirement is applicable to the case when the commander is loyal. It is easy to see that when k = 0, Algorithm OM(0) satisfies the IC2 requirement (and therefore Lemma 7.1 is correct for k = f. Because all lieutenants in OM(0) receive the same value from the loyal commander, all loyal lieutenants would use the same value sent by the commander.
Next, we prove that if the lemma is true for k − 1, 1 ≤ k ≤ f, then the lemma must be true for k. In the OM(k) instance, there are n − (f − k) − 1 lieutenants. Because the commander for OM(k) is loyal, it sends the same value v to all these lieutenants in the instance. Each loyal lieutenant then executes an OM(k − 1) instance involving n − (f − k) − 2 lieutenants. Per the induction hypothesis, the commander and all loyal lieutenants in an OM(k − 1) instance agree on the same value sent by the commander, which means that given a loyal lieutenant i in OM(k) that receives a value v, all its lieutenants must also agree on v. That is, at each such lieutenant j, its v variable for i is set to v(vi = v) at the end of OM(k − 1).
Next, we show that the majority of the lieutenants in OM(k) is loyal. Because there are n − (f − k) − 1 lieutenants, n > 3f, and k ≥ 1, we get n −(f − k) −1 > 3f − f + k − 1 ≥ 2f. This means that at each loyal lieutenant, the majority of its v variables have value v. Therefore, the value returned by the majority function on the set of v variables must be v in step (3). Hence, OM(k) satisfies the IC2 requirement. This proves the lemma.
Now, we prove the following theorem using the above lemma.
Theorem 7.1 For any f, Algorithm OM(f) satisfies the interactive consistency requirements IC1 and IC2 provided that the total number of generals is greater than 3f.
Proof : Similar to the proof of the Lemma 7.1, we prove the theorem by induction. If f = 0 (no traitor), it is trivial to see that OM(0) satisfies IC1 and IC2. We assume that the theorem is correct for f −1 and prove that it is correct for f(f ≥ 1). There are only two cases: (1) the commander in OM(f) is loyal, and (2) the commander is a traitor.
For case (1), we can prove that the theorem satisfies IC2 by applying Lemma 7.1 and set k = f. Because the commander is loyal, IC1 is automatically satisfied as well.
For case (2), since the commander is a traitor in OM(f), at most f − 1 lieutenants are traitors. Furthermore, there are at least 3f − 1 lieutenants in OM(f), and each of these lieutenants would invokes an instance of the OM(f −1) participated by all lieutenants. Because 3f − 1 > 3(f − 1), we can safely apply the induction hypothesis for f − 1 and apply the Lemma 7.1. Therefore, for all OM(f − 1) instances launched by loyal lieutenants, they return the same value vloyal in step (3) of OM(f − 1). Because the majority of lieutenants are loyal (3f − 1 − (f − 1) > f − 1), the majority function on the set of v variables would return vloyal as well in step (3) of OM(f). Therefore, Algorithm OM(f) satisfies IC1. Hence, the theorem is correct.
7.2 Practical Byzantine Fault Tolerance
The Oral Message Algorithms solve the Byzantine consensus problem. Unfortunately the solution is not practical for primarily two reasons:
- ■ The Oral Message Algorithms only work in a synchronous environment where there is a predefined bound on message delivery and processing, and the clocks of different processors are synchronized as well. Practical systems often exhibit some degree of asynchrony caused by resource contentions. The use of a synchronous model is especially a concern in the presence of malicious faults because an adversary could break the synchrony assumptions, for example, by launching a denial of service attack on a nonfaulty process to delay message delivery.
- ■ Except for f = 1, the Oral Message Algorithms incur too much runtime overhead for reaching a Byzantine agreement.
More efficient Byzantine fault tolerance protocols, such as SecureRing [16] and Rampart [30], were developed and they were designed to operate in asynchronous distributed systems. However, they rely on the use of timeout-based unreliable fault detectors to remove suspected processes from the membership, as a way to overcome the impossibility result. Because the correctness of such protocol rely on the dynamic formation of membership, which in turn depends on the synchrony of the system. This is particularly dangerous in the presence malicious adversaries, as pointed out in [5].
In 1999, Castro and Liskov published a seminal paper on practical Byzantine fault tolerance (PBFT) [5] with an algorithm that is not only efficient, but does not depend on the synchrony for safety. The design of the PBFT algorithm is rather similar to that of the Paxos algorithm. Hence, the PBFT algorithm is sometimes referred to as Byzantine Paxos [23, 24].
7.2.1 System Model
The PBFT algorithm is designed to operate in an asynchronous distributed system connected by a network. Hence there is no bound on message delivery and processing time, and there is no requirement on clock synchronization. The PBFT algorithm tolerates Byzantine faults with certain restrictions and assumes that the faults happen independently.
To ensure fault independence in the presence of malicious faults, replicas must be made diverse. One way to satisfy this requirement is via the N-version programming where different versions of a program with the same specification are developed [1]. However, the disadvantage for N-version programming is the high cost of software development as well as maintenance. It is also possible to utilize existing software packages that offer similar functionalities to achieve diversified replication, such as file systems and database systems [7, 30]. This approach requires the use of wrappers to encapsulate the differences in the implementations. A more promising approach to achieving diversity is via program transformation [2, 3, 10, 11, 12, 16, 17, 19, 29, 32], for example, by randomizing the location of heap and stack memory [3, 16, 32].
To ensure that a replica can authenticate a message sent by another replica, cryptographic techniques are employed. In the PBFT algorithm description, we assume that each message is protected by a public-key digital signature. Later in this section, we discuss an optimization by replacing the digital signature, which is computationally expensive, with a message authentication code (MAC) [4]. The use of digital signatures or MACs also enables a replica to detect corrupted or altered messages.
The restrictions assumed for an adversary is that it has limited computation power so that it cannot break the cryptography techniques used to spoof a message (i.e., to produce a valid digital signature of a nonfaulty replica). It is also assumed that an adversary cannot delay a message delivery at a nonfaulty replica indefinitely.
7.2.2 Overview of the PBFT Algorithm
The PBFT algorithm is used to implement state machine replication where a client issues a request to the replicated server and blocks waiting for the corresponding reply. To tolerate f faulty replicas, 3f + 1 or more server replicas are needed. The PBFT algorithm has the following two properties:
- ■ Safety. Requests received by the replicated server are executed atomically in a sequential total order. More specifically, all nonfaulty server replicas execute the requests in the same total order.
- ■ Liveness. A client eventually receives the reply to its request provided that the message delivery delay does not grow faster than the time itself indefinitely.
The minimal number of replicas, n = 3f + 1, to tolerate f faulty replicas are optimal for any asynchronous system that ensures the safety and liveness properties. Because up to f replicas may be faulty and not respond, a replica must proceed to the next step once it has collected n − f messages from different replicas. Among the n − f messages, up to f of them might actually be sent by faulty replicas. To have any hope of reaching an agreement among the nonfaulty replicas, the number of messages from nonfaulty replicas must be greater than f (i.e., among the n − f messages collected, the number of messages from nonfaulty replicas must be the majority). Hence, n − 2f > f, which means the optimal number of replicas n = 3f + 1.
In the presence of faulty clients, the PBFT algorithm can only ensure the consistency of the state of nonfaulty replicas. Furthermore, the algorithm itself does not prevent the leaking of confidential information from the replicated server to an adversary.
We assume that the optimal number of replicas n = 3f + 1 are used, and each replica is referred to by an index number ranges from 0, 1, …, up to 3f. One of the replicas is designated as the primary, and the remaining ones are backups. The primary is responsible to assign a sequence number to each request received and initiates a new round of protocol to establish the total ordering of the request at all nonfaulty replicas. The sequence number binds a request to its total order relative to all other requests. Initially, the replica 0 assumes the primary role. When replica 0 is suspected as failed, replica 1 will be elected as the new primary. Each primary change is referred to as a view change and each view is identified by a view number v (from 0 to 1, and so on). Hence, for a view v, replica p = vmodn would serve as the primary for that view.
The PBFT algorithm works in the following steps:
- ■ A client multicasts a request to all server replicas. A request has the form
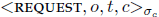 , where o is the operation c to be executed at the server replica, t is a timestamp, c is the identifier of the client, and σc is the client’s digital signature for the request. The client must ensure that a later request bears a larger timestamp. The timestamp t is used by the replicas to detect duplicates. If a duplicate request is detected, the replica would return the logged reply to the client instead of reordering them.
, where o is the operation c to be executed at the server replica, t is a timestamp, c is the identifier of the client, and σc is the client’s digital signature for the request. The client must ensure that a later request bears a larger timestamp. The timestamp t is used by the replicas to detect duplicates. If a duplicate request is detected, the replica would return the logged reply to the client instead of reordering them. - ■ The server replicas exchange control messages to establish and agree on the total order for the request. The complexity of the PBFT algorithm lies in this step.
- ■ The server replicas execute the request according to the total order established and send the corresponding reply to the client. A replica may have to delay the execution of the request until all requests that are ordered ahead of the request have been executed.
- ■ The client would not accept a reply until it has collected consistent replies to its request from f + 1 server replicas. This is to ensure that at least one of them comes from a nonfaulty replica. A reply has the form
 , where v is the current view number, t is the timestamp of the corresponding request, i is the replica identifier, and r is the application response as the result of the execution of the operation o. The client verifies consistency by comparing the r component in the reply message.
, where v is the current view number, t is the timestamp of the corresponding request, i is the replica identifier, and r is the application response as the result of the execution of the operation o. The client verifies consistency by comparing the r component in the reply message.
7.2.3 Normal Operation of PBFT
During normal operation, i.e., when the primary is not faulty, the server replicas can establish and agree on the total order of each request in three phases (referred to as pre-prepare, prepare, and commit phases), as shown in Figure 7.4. PBFT also requires each replica to log both application messages (requests received and reply generated), and control messages that sent during the three phases to achieve Byzantine agreement on the total order of messages.

Figure 7.4 Normal operation of the PBFT algorithm.
During the first phase, i.e., the pre-prepare phase, when the primary receives a new request m, it assigns the next available sequence number s to the request and multicasts a pre-prepare message to the backups. The pre-prepare message has the form ![]() , where d is the digest for the request m. p
, where d is the digest for the request m. p
A backup verifies a pre-prepare message in the following way before it accepts the message:
- ■ The pre-prepare message has a valid digital signature.
- ■ The backup is in view v and it has not accepted a preprepare message with sequence number s.
- ■ Furthermore, the sequence number is within the expected range bounded by a low water mark h and a high water mark H. This is to prevent a faulty primary to exhaust the address space of the sequence number (to avoid the sequence number wrap-around problem).
The backup would need to search its message log for the request associated with the pre-prepare message based on the received message digest. If no request is found, the backup should ask the primary to retransmit that request. On accepting a pre-prepare message, the backup logs the pre-prepare message, creates a prepare message, saves a copy of the prepare message in its message log, and starts the second phase (i.e., the prepare phase) by multicasting the prepare message to all other replicas. The prepare message has the form ![]() , where i is the identifier of the sending backup.
, where i is the identifier of the sending backup.
A replica (the primary or a backup) accepts a prepare message and logs it if the message can pass the following checks:
- ■ The prepare message has a valid digital signature.
- ■ The replica is in the same view v as that in the prepare message.
- ■ The sequence number is within the expected range.
A replica (the primary or the backup) enters the third (i.e., commit) phase by sending a commit message when the following condition is met:
- ■ The replica has collected 2f prepare messages from different replicas (including the one the replica has sent) and the matching pre-prepare message.
When this condition is met at replica i, it is said that prepared(m, v, s, i) is true. The commit message has the form ![]() .
.
A replica verifies a commit message in the same way as for a prepare message. The replica accepts the commit message if the verification is successful and logs the message. When a replica i has sent a commit message and has collected 2f + 1 commit messages (including the one it has sent) that match the pre-prepare message from different replicas, it is said that committed-local(m, v, s, i) is true. If prepared(m, v, s, i) is true for all replicas i in some set of f +1 nonfaulty replicas, it is said that the predicate committed(m, v, s) is true. A replica i proceeds to execute the request m when commitlocal(m, v, s, i) becomes true and if it has already executed all message ordered before m (i.e., requests that are assigned a smaller sequence number than s).
The PBFT algorithm ensures the following two invariance.
- If the predicate prepared(m, v, s, i) is true for a nonfaulty replica i, and the predicate prepared(m′, v, s, j) is true for another nonfaulty replica j, then m = m′.
- If committed-local(m, v, s, i) is true for a non-faulty replica i, then the predicate committed(m, v, s) is true.
The first invariance shows that the first two phases (i.e., preprepare and prepare) of the PBFT algorithm ensures that all nonfaulty replicas that can complete the two phases in the same view agree on the total order of the messages. The proof of this invariance is straightforward. Given any two nonfaulty replicas i and j, if prepared(m, v, s, i) and prepared(m′, v, s, j) are true, then a set of 2f + 1 replicas R1 must have voted for m (in the pre-prepare and prepare messages), and similarly, a set of 2f + 1 replicas R2 must have voted m′. Because there are 3f + 1 replicas, R1 and R2 must intersect in at least f + 1 replicas, and one of these f + 1 replicas is nonfaulty. This nonfaulty replica would have voted for two different messages for the same sequence number s, which is impossible.
It is easy to see why the second invariance is true. When committed-local(m, v, s, i) is true for replica i, the replica i must have received the commit messages from 2f other replicas. This implies that the predicate prepared(m, v, s, i) must be true for replica i, and prepared(m, v, s, j) is true if all the 2f other replicas j. Because there are at most f faulty replicas, there must be at least f + 1 nonfaulty replicas among these 2f + 1 replica, which means the predicate committed(m, v, s) is true.
The second invariance together with the view change protocol guarantee that all nonfaulty replicas agree on the same total order for messages, even if they reach the committed-local state for the messages in different views.
7.2.4 Garbage Collection
Because PBFT requires that all messages are logged at each replica, the message log would grow indefinitely. This obviously is not practical. To limit the size of the message log, each replica periodically takes a checkpoint of its state (the application state as well as the fault tolerance infrastructure state) and informs other replicas about the checkpoint. If a replica learns that 2f + 1 replicas (including itself) have taken a checkpoint and the checkpoints are consistent, the checkpoint becomes stable and all previously logged messages can be garbage collected. This mechanism ensures that the majority of nonfaulty replicas have advanced to the same state, and they can bring some other nonfaulty replica up to date if needed.
To ensure that all nonfaulty replicas take checkpoints at the same synchronization points, the best way is to predefine the checkpoint period in terms of a constant c, and each replica takes a checkpoint whenever it has executed a request with a sequence number that is multiple of c. A replica i multicasts a checkpoint message once it has taken a checkpoint. The checkpoint message has the form ![]() , where s must be multiple of c, and d is the digest of the checkpoint. When a replica receives 2f +1 valid checkpoint messages for the same s with the same digest d, the set of 2f + 1 messages become the proof that this checkpoint has become stable. The proof is logged together with the checkpoint, before the replica garbage-collects all logged messages that bear a sequence number less than or equal to s.
, where s must be multiple of c, and d is the digest of the checkpoint. When a replica receives 2f +1 valid checkpoint messages for the same s with the same digest d, the set of 2f + 1 messages become the proof that this checkpoint has become stable. The proof is logged together with the checkpoint, before the replica garbage-collects all logged messages that bear a sequence number less than or equal to s.
Previously we mentioned that each replica maintains a low and a high water marks to define the range of sequence numbers that may be accepted. The low watermark h is set to the sequence number of the most recent stable checkpoint. The range of acceptable sequence numbers is specified in a constant k so that the high watermark H = h + k. As suggested in [5], k is often set to be 2c (twice the checkpoint period).
A direct consequence of truncating the log after a stable checkpoint is that when a replica requests a retransmission for a request or a control message (such as pre-prepare), the message might have been garbage-collected. In this case, the most recent stable checkpoint is transferred to the replica that needs the missing message.
7.2.5 View Change
Because PBFT relies on the primary to initiate the 3-phase Byzantine agreement protocol on the total order of each request, a faulty primary could prevent any progress being made by simply not responding, or by sending conflicting control messages to backups. Hence, a faulty primary should be removed of the primary role and another replica would be elected as the new primary to ensure liveness of the system.
Because in an asynchronous system, a replica cannot tell a slow replica from a crashed one. It has to depend on a heuristic viewchange timeout parameter to suspect the primary. A backup does this by starting a view-change timer whenever it receives a request. If the view-change timer expires before committed-local is true for a replica i in view v, the replica suspects the primary and initiates a view change by doing the following:
- ■ The replica multicasts a view-change message to all replicas (including the suspected primary so that the primary can learn that it has been suspected).
- ■ The replica stops participating operations in view v, i.e., it would ignore all messages sent in view v except the checkpoint, view-change, and new-view messages.
The view-change message has the form ![]() , where s is the sequence number for the most recent stable checkpoint known to replica i, C is the proof for the stable checkpoint (i.e., the 2f + 1 checkpoint messages for the checkpoint with sequence number s), P is a set of prepared certificates, one for each sequence number ss > s for which the predicate prepared(m, v′, ss, i) is true. Each prepared certificate contains a valid pre-prepare message for request m that is assigned a sequence number ss in view v′ ≤ v, and 2f matching valid prepare messages from different backups.
, where s is the sequence number for the most recent stable checkpoint known to replica i, C is the proof for the stable checkpoint (i.e., the 2f + 1 checkpoint messages for the checkpoint with sequence number s), P is a set of prepared certificates, one for each sequence number ss > s for which the predicate prepared(m, v′, ss, i) is true. Each prepared certificate contains a valid pre-prepare message for request m that is assigned a sequence number ss in view v′ ≤ v, and 2f matching valid prepare messages from different backups.

Figure 7.5 PBFT view change protocol.
As shown in Figure 7.5, when the primary for view v + 1 receives 2f matching view-change messages for view v + 1 from other replicas, it is ready to install the new view and multicasts a newview message to all other replicas (including the primary that has been suspected in v to minimize the chance of two or more replicas believe that they are the primary). The new-view message has the form ![]() , where V is proof for the new view consisting of 2f + 1 matching view-change messages (2f from other replicas and the view-change sent or would have sent by the primary in view v + 1), and O is a set of pre-prepare messages to be handled in view v + 1, which is determined as follows:
, where V is proof for the new view consisting of 2f + 1 matching view-change messages (2f from other replicas and the view-change sent or would have sent by the primary in view v + 1), and O is a set of pre-prepare messages to be handled in view v + 1, which is determined as follows:
- ■ First, the primary in the new view v + 1 computes the range of sequence numbers for which the 3-phase Byzantine agreement protocol was launched in the previous view v. The lower bound min − s is set to be the smallest sequence number s (for stable checkpoint) included in a view-change message included in V. The higher bound max − s is set to be the largest sequence number contained in a prepared certificate included in V.
- ■ For each sequence number s between min − s and max − s (inclusive), the primary in view v + 1 creates a pre-prepare message. Similar to the Paxos algorithm, the primary (acting as the role of the proposer) must determine which message m should be assigned to the sequence number s (analogous to the proposal number in Paxos) based on the collected history information in the previous view v.
- ■ If there exists a set of prepared certificates in V containing the sequence number s, the message m contained in the certificate with the highest view number is selected for the pre-prepare message in view v + 1.
- ■ If no prepared certificate is found for a sequence number within the range, the primary creates a pre-prepare message with a null request. The execution of the null request is a no-op, similar to the strategy employed in Paxos.
Upon receiving the new-view message, in addition to checking on the signature of the message, a backup verifies the O component of the message by going through the same steps outlined above. The backup accepts a pre-prepare message contained in O if the validation is successful, and subsequently multicasts the corresponding prepare message. Thereafter, backup resumes normal operation in view v + 1.
Because the primary in view v + 1 reorders all requests since the last stable checkpoint, the predicate commit-local might be already true for some of the messages reordered. The replica would nevertheless participate in the ordering phases by multicasting prepare and commit messages. It is also possible that a replica has already executed a request, in which case, the request is not re-executed.
Another detail is that min − s might be greater than the sequence number of the latest stable checkpoint at the primary for view v + 1. In this case, the primary labels the checkpoint for min − s as stable if it has taken such a checkpoint, and logs the proof for this stable checkpoint (included in the view-change message received at the primary). If the primary lags so far behind and has not taken a checkpoint with sequence number min − s, it would need to request a copy of the stable checkpoint from some other replica.
Finally, to facilitate faster view change, a nonfaulty replica joins a view change as soon as it receives f +1 valid view-change messages from other replicas before its view-change timer expires. Figure 7.5 shows this case for Replica 3.
7.2.6 Proof of Correctness
Theorem 7.2 Safety property. All nonfaulty replicas execute the requests they receive in the same total order.
Proof : We have already proved in Section 7.2.3 that if two nonfaulty replicas commit locally for a sequence number s in the same view v, then both must bind s to the same request m. What is remaining to prove is that if two nonfaulty replicas commit locally for a sequence number s in different views, then both must bind s to the same request m. More specifically, if the predicate commitlocal(m, v, s, i) is true for replica i, and commit-local(m′, v′, s, j) is true for replica j, we show that m = m′.
Assume that m ≠ m′ and without loss of generality v′ > v. Because commit-local(m, v, s, i) is true for replica i, the predicate prepared(m, v, s, i) must be true for a set R1 of at least 2f + 1 replicas. For the replica j to install view v′, it must have received the proof for the new view, which consists of a set R2 of 2f + 1 view-change messages from different replicas. Because there are 3f + 1 replicas in the system, R1 and R2 must intersect in at least f + 1 replicas, which means at least one of them is not faulty. This nonfaulty replica must have included a prepared certificate containing the binding of s to m in its view-change message. According to the view change protocol, the new primary in view v′ must have selected m in the pre-prepare message with sequence number s. This ensures that m = m′.
It is possible that by the time the view change takes place, replica i has taken a stable checkpoint for sequence number equal or greater than s, in which case, no nonfaulty replica would accept a pre-prepare message with sequence number s.
Theorem 7.3 Liveness property. A client eventually receives the reply to its request provided that the message delivery delay does not grow faster than the time itself indefinitely.
Proof : It is easy to see that if the primary is Byzantine faulty, it may temporarily delay progress. However, it cannot prevent the system from making progress indefinitely because every nonfaulty replica maintains a view-change timer. A replica starts the timer when it receives a request if the timer is not running yet. If it fails to execute the request before the timer expires, the replica suspects the primary and multicasts to other replicas a VIEW-CHANGE message. When f + 1 replicas suspect the primary, all nonfaulty replicas join the view change, even if their timers have not expired yet. This would lead to a view change.
Next, we show that as long as the message delivery delay does not grow faster than the time itself indefinitely, a new view will be installed at nonfaulty replicas. This is guaranteed by the adaption of the timeout value for unsuccessful view changes. If the view-change timer expires before a replica receives a valid NEW-VIEW message for the expected new view, it doubles the timeout value and restart the view-change timer.
There is also a legitimate concern that a Byzantine faulty replica may attempt to stall the system by forcing frequent view changes. This concern is addressed by the mechanism that only when a nonfaulty replica receives at least f +1 VIEW-CHANGE messages does it join the view change. Because there are at most f faulty replicas, they cannot force a view change if all nonfaulty replicas are making progress.
7.2.7 Optimizations
Reducing the cost of cryptographic operations. The most significant optimization in PBFT is to replace digital signatures by message authentication code for all control messages except the checkpoint, view-change and new-view messages. According to [4], message authentication code (MAC) based authentication can be more than two orders of magnitude faster than that using digital signatures with similar strength of security.
The main reason that MAC-based authentication is much faster than that digital signature based authentication is that MACs use symmetric cryptography while digital signatures are based on public-key cryptography. To use MAC, two communication parties would need to establish a shared secret session key (or a pair of keys, one for each communication direction). A MAC is computed by applying a secure hash function on the message to be sent and the shared secret key. Then the computed MAC is appended to the message. The receiver would then authenticate the message by recompute the MAC based on the received message and its secret key and compare with the received MAC. The message is authenticated if the recomputed MAC is identical to the received MAC.
For a message to be physically multicast (using UDP or IP multicast) to several receivers, a vector of MACs is attached to the message. The vector of MACs is referred to as an authenticator. In an authenticator, there is one MAC for each intended receiver.
The purpose of using digital signatures in pre-prepare, prepare, and commit messages is to prevent spoofing. Using MACs instead of digital signatures could achieve the same objective. To see why, consider the following example. Replica i is faulty, and Replicas j and k are not faulty. We show that replica i cannot forge a message sent to replica j preventing that replica j sent it. Even though replica i has a shared secret key with replica j, it does not know the shared secret key between replica j and replica k. Therefore, if replica i were to forge a message from replica j to replica k, the MAC cannot be possibly correct and replica k would deem the message invalid. Therefore, during normal operation, the preprepare, prepare, and commit messages can be protected by MACs instead of digital signatures without any other changes to the PBFT algorithm.
For the checkpoint message, even though it is possible to use MACs instead of digital signatures during normal operation, when the proof for a stable checkpoint is needed, a new control message, called check-sign message, which is protected by a digital signature, must be exchange among the replicas to assemble the proof. Considering that checkpoints are taken periodically (say one for every 100 requests executed), it is more beneficial to use digital signatures in the first place for simplicity of the algorithm and faster recovery (because the proof is needed during view changes and when to recover a slow replica).
The use of MACs in pre-prepare and prepare messages does have some impact on the view change protocol because a faulty replica could in fact forge the proof that it has collected a pre-prepare message with 2f matching prepare messages. Hence, during a view change, a replica that has prepared a message m with sequence number s must build the proof by going through a round message exchange with other replicas.
For each request m that has prepared with a sequence number s at replica i, the replica digitally signs any pre-prepare and prepare messages it has sent and multicasts a prepare-sign message in the form ![]() to other replicas, where d is the digest of m. Upon receiving a valid prepare-sign message, a non faulty replica j responds with its own prepare-sign message for the same m and s, if it has not produced a stable checkpoint with a sequence number equal or greater than s. Replica i waits to collect f + 1 valid prepare-sign messages (including the one it has sent) to build the proof. The reason why replica i has to stop waiting when it receives f + 1 prepare-sign messages is because in the worst case, up to f faulty replicas that responded during normal operation may choose not to respond at all or respond with a valid prepare-sign message.
to other replicas, where d is the digest of m. Upon receiving a valid prepare-sign message, a non faulty replica j responds with its own prepare-sign message for the same m and s, if it has not produced a stable checkpoint with a sequence number equal or greater than s. Replica i waits to collect f + 1 valid prepare-sign messages (including the one it has sent) to build the proof. The reason why replica i has to stop waiting when it receives f + 1 prepare-sign messages is because in the worst case, up to f faulty replicas that responded during normal operation may choose not to respond at all or respond with a valid prepare-sign message.
Theoretically, it is possible for the primary in the new view to receive valid view-change messages that conflict with each other because there are only f +1 signed prepared certificates in the proof for a prepared message. For example, replica i’s proof contains f + 1 prepared certificates for a message m with sequence number s, whereas replica j’s proof contains f + 1 prepared certificates for a message m′ with the same sequence number. If this happens, the primary for the new view might not know which message to choose for sequence number s.
It turns out that the proofs from nonfaulty replicas for the same prepared message will never conflict due to the invariance that if a message m is prepared with a sequence number s at a nonfaulty replica, all nonfaulty replicas that prepared message m would agree with the same sequence number s.
Therefore, if the primary for the new view always waits until it has collected 2f + 1 view-change messages with no conflict before it issues the new-view message. One consequence for doing this is that in the worst case, the primary for the new view must wait until all nonfaulty replicas have advanced to the same stage if the f faulty replicas initially participated in the 3-phase Byzantine agreement protocol but refused to help build the proof for prepared requests.
Tentative execution. To reduce the end-to-end latency, a replica tentatively executes a request as soon as it is prepared and all requests that are ordered before it have been committed locally and executed. With tentative execution enabled, the client must collect 2f + 1 matching replies from different replicas instead of f + 1. If 2f + 1 have prepared and tentatively executed a message, it is guaranteed that the message will eventually committed locally, possibly after one or more view changes. To see why this is the case, let R1 be the set of 2f +1 replicas that have prepared and tentatively executed a message m. If a view change has occurred subsequently, the primary for the new view must collect valid view-change messages from a set R2 of 2f + 1 replicas. Because there are 3f + 1 replicas in the system, R1 and R2 must intersect in f +1 replicas, which means at least one of the replicas is not faulty. This nonfaulty replica must have included the prepared certificate for m in its view-change message, which ensures that the primary in the new view would assign the same sequence number in the prepared certificate for m.
If the primary fails before 2f +1 replicas have prepared a message m, the primary for the new view might not be able to find a prepared certificate for m in the 2f + 1 view-change messages it would collect, hence, there is no guarantee that the primary in the new view would assign m the same sequence number as that for the tentative execution.
To avoid the potential inconsistency in requests ordering highlighted in the above example, replicas rollback to the most recent checkpoint if a view change happens and there exists at least one request that has been tentatively executed. To facilitate this mechanism, each of the prepared certificates in the view-change messages must indicate whether or not a request has been tentatively executed. Because all nonfaulty replicas would receive the view-change messages that enabled the new view, they all should be able to determine whether or not a request has been tentatively executed and decides whether or not to rollback its state.
Read-only requests. If operations that do not modify the system state are predefined, it is desirable to avoid totally ordering readonly requests so that the client can receive a reply faster. Since a read-only request does not change the system state, a replica can immediately execute a read-only request as soon as it receives one without risking the divergence of the state at different replicas provided that all tentative executions have been committed. However, the downside for immediate execution of read-only requests is that different replicas may return different states to the client if there are concurrent modifications to the state accessed by the read-only request.
Without tentative execution, a client waits for f + 1 matching replies from different replicas to ensure that at least one of them is from a nonfaulty replica. If tentative execution is enabled, the client must wait until it has collected 2f +1 matching replies. It is possible that the client is unable to collect f + 1 or 2f + 1 matching replies, in which case, the client has to resubmit the request as a regular request.
7.3 Fast Byzantine Agreement
Similar to Fast Paxos [22], faster Byzantine agreement can be achieved by using more replicas. By using a quorum size of 4f + 1 (total number of acceptors needed is 5f + 1), a Byzantine agreement can be achieved in two communication steps instead of three in normal operation where there is a unique proposer [28]. Figure 7.7 shows the normal operation in a state-machine Byzantine fault tolerance system. The view change algorithm for PBFT can be used for new leader election in case of the primary failures. Similarly, the optimizations introduced in PBFT [7] such as read-only operations and speculative execution can be applied to Fast Byzantine fault tolerance system as well.
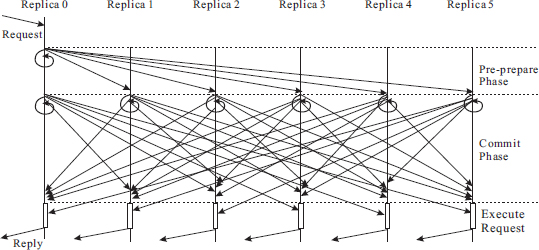
Figure 7.7 Normal operation of Fast Byzantine fault tolerance.
7.4 Speculative Byzantine Fault Tolerance
Because faults are rare, it is reasonable to expect that the performance of a Byzantine fault tolerance system can be improved by speculative execution. If a speculative execution is wrong due to the presence of faulty replicas, the speculative execution must be rolled back. Speculative execution in the context of state-machine Byzantine faulty tolerance is first introduced in PBFT [5] where replicas can tentatively execute a request as soon as it is prepared and all requests that are ordered before it have been delivered and executed. Server-side speculative execution is pushed to the limit in Zyzzyva [20] where replicas can speculatively execute a request as soon as a request is assigned a sequence number (by the primary). In [31], client-side speculative execution is introduced to primarily reduce the end-to-end latency of a remote method invocation, where the client speculatively accepts the first reply received and carries on with its operation.
Client-side speculative execution is relatively straightforward. To avoid cascading rollbacks in case of wrong speculation, a client must not externalize its speculative state. A client that has speculatively accepted a reply keeps tracks of additional replies received. When a client has received sufficient number of matching replies, the speculative execution related to the request and reply will be labeled as stable.
In this section, we focus on the server-side speculative execution as described in Zyzzyva [20]. Zyzzyva employs the following main mechanisms:
- ■ A replica speculatively executes a request as soon as it receives a valid pre-prepare message from the primary.
- ■ The commitment of a request is moved to the client. A request is said to have completed (instead of committed) at the issuing client if the corresponding reply can be safely delivered to the client application according to Zyzzyva. Zyzzyva ensures that if a request completes at a client, then the request will eventually be committed at the server replicas.
- ■ The all-to-all prepare and commit phases are reduced to a single phase. As a trade-off, an additional phase is introduced in view change.
- ■ A history hash is used to help the client determine if its request has been ordered appropriately. A server replica maintains a history hash for each request ordered and appends the history hash hs = H(hs−1, ds) to the reply for the request that is assigned a sequence number s, where H() is the secure hash function, and ds is the digest for the request that is assigned the sequence number s. hsi is a prefix of hsj if sj > si and there exist a set of requests with sequence numbers si + 1, si + 2, …, sj − 1 with digests dsi+1, dsi+2, …, dsj−1 such that hsi+1 = H(hsi, dsi+1), hsi+2 = H(hsi+1, dsi+2), …, hsj = H(hsj−1,dsj).
The system model used in Zyzzyva is identical to that in PBFT. Similar to PBFT, Zyzzyva employs three protocols: the agreement protocol for normal operation, the view change protocol for new primary election, and the checkpointing protocol for garbage collection.
Zyzzyva ensure the following safety and liveness properties:
- Safety: Given any two requests that have completed, they must have been assigned two different sequence numbers. Furthermore, if the two sequence numbers are i and j and i < j, the history hash hi must be a prefix of hj.
- Liveness: If a nonfaulty client issues a request, the request eventually completes.
7.4.1 The Agreement Protocol
A client maintains a complete timer after issuing each request. A request may complete at the issuing client in one of the following ways:
- Case 1: The client receives 3f + 1 matching replies from different replicas before the complete timer expires. This means that all replicas have executed the request in exactly the same total order.
- Case 2: The client receives at least 2f + 1 matching replies when the complete timer expires. In this case, the client would initiate another round of message exchanges with the server replicas before the request is declared as complete.
The main steps for case 1 and case 2 are shown in Figure 7.8 and Figure 7.9, respectively. The client initially sends its request to the primary and starts the complete timer for the request. The request has the form ![]() , where o is the operation to be c executed at the server replica, t is a timestamp, c is the identifier of the client, and σc is the client’s digital signature or authenticator for the request.
, where o is the operation to be c executed at the server replica, t is a timestamp, c is the identifier of the client, and σc is the client’s digital signature or authenticator for the request.
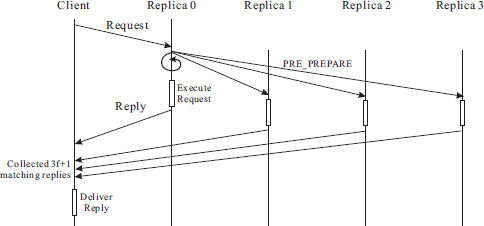
Figure 7.8 Zyzzyva agreement protocol (case 1).
Upon receiving a valid request m from a client, the primary assigns the request a sequence number and multicasts a ORDER-REQ message and the request m to all backup replicas. The ORDER-REQ is similar to the pre-prepare request in PBFT and has the form ![]() , where v is the current view p number, s is the sequence number assigned to request m, hs is the history hash for the request, d is the digest of m, and ND is a set of values chosen by the primary for nondeterministic variables involved in the operation o.
, where v is the current view p number, s is the sequence number assigned to request m, hs is the history hash for the request, d is the digest of m, and ND is a set of values chosen by the primary for nondeterministic variables involved in the operation o.
When a replica receives an ORDER-REQ message from the primary, it verifies the message in the following way:
- ■ The digest d is the correct digest for the request m.
- ■ The sequence number s in ORDER-REQ is the next expected sequence number based on the replica’s knowledge (i.e., the replica maintains a max sequence number maxs, and in this case, maxs = s − 1), and the history hash received in the ORDER-REQ message, hs = H(hs−1, d), where hs−1 is the history hash at the replica prior to receiving the ORDER-REQ message.
- ■ The ORDER-REQ is properly signed by the primary.
If the ORDER-REQ message is valid, the replica accepts it and updates its history hash. Then it executes the request speculatively and sends a SPEC-RESPONSE message to the client. The SPEC-RESPONSE message includes the following components:
- ■ A component signed by the replica:
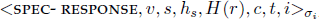 , where H(r) is the digest i of the reply r, c and t are the client id and the timestamp included in the request m, and i is the sending replica id. (In [20], i is outside the signed component. We believe it is more robust to include i in the signed component so that the client can be assured the identity of the sending replica, i.e., a faulty replica cannot spoof a SPEC-RESPONSE message as one or more nonfaulty replicas.)
, where H(r) is the digest i of the reply r, c and t are the client id and the timestamp included in the request m, and i is the sending replica id. (In [20], i is outside the signed component. We believe it is more robust to include i in the signed component so that the client can be assured the identity of the sending replica, i.e., a faulty replica cannot spoof a SPEC-RESPONSE message as one or more nonfaulty replicas.) - ■ The reply r.
- ■ The original ORDER-REQ message received from the primary, i.e.,
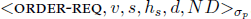 .
.
If the client receives matching SPEC-RESPONSE from all replicas (i.e., 3f + 1) before the complete timer expires, as described in case 1 and shown in Figure 7.8, the request completes and the client deliver the reply to the application layer for processing. Two SPEC-RESPONSE messages match provided that they have identical
- ■ view number v,
- ■ sequence number s,
- ■ history hash hs,
- ■ client id c,
- ■ timestamp t,
- ■ reply r,
- ■ digest of the reply H(r).
When the complete timer expires, if the client manages to receive at least 2f + 1 matching replies, but not from all replicas, as described in case 2 and shown in Figure 7.9, the client assembles a commit certificate CC using the 2f + 1 or more matching replies, broadcasts to the replicas a ![]() message, and starts another timer for retransmission. A commit certificate contains the following components:
message, and starts another timer for retransmission. A commit certificate contains the following components:
- ■ A list of 2f + 1 replica ids,
- ■ The signed component of the SPEC-RESPONSE from each of the 2f + 1 replicas.

Figure 7.9 Zyzzyva agreement protocol (case 2).
Upon receiving a COMMIT message, a replica responds with a LOCAL-COMMIT message to the client. If the client could receive 2f + 1 or more valid LOCAL-COMMIT messages before the retransmission timer expires, it knows that the request has completed and it is safe to deliver the reply.
When a replica receives a COMMIT message with a valid commit certificate, it further verifies that its local history hash is consistent with the certified history hash:
- ■ If the replica has received a ORDER-REQ message for the request to be committed, the history hash for the request must be identical to that included in the commit certificate.
- ■ If the replica has not received a ORDER-REQ message for the request to be committed, then the request must carry the next expected sequence number i.e., maxs + 1.
If the verification on the history hash is successful, the replica performs the following operations:
- ■ If the commit certificate’s sequence number is higher than the stored maximum sequence number, it increments its local maximum sequence number maxCC.
- ■ The replica sends the client a message

When the client receives 2f +1 consistent LOCAL-COMMIT messages, it completes the request and delivers the corresponding reply.
If the client receives fewer than 2f + 1 matching replies before the complete timer expires, or the additional of round of message exchanges in case 2 is not successful, it retries the request by broadcasting the request to all replicas.
7.4.2 The View Change Protocol
Because the primary is designated to assign sequence numbers to the requests and drive the agreement protocol, a faulty primary can easily stall the progress of the system. To ensure liveness, the current primary must be removed from the role if it is suspected of being faulty and another replica will be elected to serve as the primary. This is referred to as a view change. In Zyzzyva, a view change can be triggered in one of two ways:
- Sufficient number of backups time out the current primary. This is identical to that in PBFT. On receiving a request from a client, a backup replica starts a view change timer and it expects that the request would be committed before the timer expires if the primary is not faulty.
- In Zyzzyva, a client might receive two or more SPEC-RESPONSE messages for the same request in the same view, but different sequence numbers or history hash values, in which case, the client broadcasts a POM message to all replicas. The POM message contains the current view number and the set of conflicting ORDER-REQ messages that it has received. A replica initiates a view change when it receives a valid POM message. In addition, the replica also multicasts the POM message it has received to other replicas to speed up the view change.
The Zyzzyva view change protocol differs from the PBFT view change protocol in the following ways:
- ■ In Zyzzyva, only one of the prepare and commit phases is effectively used (when the client receives at least 2f + 1 but less than 3f + 1 matching SPEC-RESPONSE messages, or none of them (when the client receives 3f + 1 matching SPEC-RESPONSE messages). As a tradeoff, an additional “I hate the primary” phase is introduced in the beginning of the view change protocol.
- ■ In the best case for Zyzzyva where the client receives 3f + 1 matching SPEC-RESPONSE messages, the replicas would not possess a commit certificate. As such, the condition for including a request in the NEW-VIEW message is weakened so that such requests will be present in the history.
In [20], the authors made an interesting observation regarding the dependencies between the agreement protocol and the view change protocol, and why in PBFT both the prepare and the commit phases are needed to ensure proper view changes. The latter is illustrated with the following counter example.
Assume that the primary and f − 1 other replicas are Byzantine faulty. The primary forces f nonfaulty replicas to suspect itself and not the remaining replicas. Recall that in PBFT, once a replica suspects the primary (i.e., commits to a view change), it stops accepting messages in the current view except checkpoint and view change messages (and hence would not participate in the ordering and execution of requests in the current view). The remaining f + 1 nonfaulty replicas could still make progress with the help of the f faulty replicas. However, if one or more requests have been prepared since the f nonfaulty have suspected the primary, there is no guarantee that the corresponding prepared certificates would be seen at the primary for the new view if the commit phase is omitted.
Recall in PBFT, if a replica has committed locally a request, it is guaranteed that the replica would have secured a prepared certificate with 2f matching prepare messages and the corresponding pre-prepare message from the primary. If the commit phase is omitted and a replica “commits” a request as soon as it has prepared the request, the above guarantee would no longer hold. Assume that f nonfaulty replicas have “committed” a request this way. The 2f + 1 view-change messages collected by the primary for the new view could have come from the remaining 2f +1 replicas, therefore, the primary for the new view would not know that a request has been committed at some replicas to a particular sequence number and hence, might order the request differently, thereby, violating the safety property. That is why the commit phase is necessary in PBFT. With the commit phase, if any replica has committed locally a request, then at least 2f + 1 replica would have prepared the request, and therefore, the primary for the new view is assured to receive the prepared certificate for the request from at least one nonfaulty replica and the safety property would be preserved.
If the PBFT view change protocol is directly applied in Zyzzyva, the liveness will be lost (instead of safety violation) in similar cases. Again, consider a Byzantine faulty primary that forces exactly f nonfaulty replicas to suspect it, thereby these f nonfaulty replicas would stop accepting new requests and the corresponding ORDER-REQ messages. If the f faulty replicas would not execute new requests either, the client would only receive the SPEC-RESPONSE messages from the f + 1 nonfaulty replicas that have not suspected the primary. As a result, the client cannot complete the request. In the meantime, no view change could take place because only f nonfaulty replicas suspect the primary.
For Zyzzyva, the problem is caused by the fact that a nonfaulty replica may commit to a view change without any assurance that a view change will take place according to the PBFT view change protocol. The solution, therefore, is to ensure that a nonfaulty replica does not abandon the current view unless all other nonfaulty replicas would agree to move to a new view too. This is achieved by introducing an additional phase on top of the PBFT view change protocol in Zyzzyva.
In Zyzzyva, when a replica suspects the primary, it broadcasts a no-confidence vote to all replicas in the form ![]() . Only when a replica receives f + 1 no-confidence i votes in the same view, does it commit to a view change and broadcasts a VIEW-CHANGE message containing the f + 1 no-confidence votes it has collected as the proof. Because of this additional phase, a nonfaulty replica joins the view change even if it receives a single valid VIEW-CHANGE message.
. Only when a replica receives f + 1 no-confidence i votes in the same view, does it commit to a view change and broadcasts a VIEW-CHANGE message containing the f + 1 no-confidence votes it has collected as the proof. Because of this additional phase, a nonfaulty replica joins the view change even if it receives a single valid VIEW-CHANGE message.
Another significant difference between the PBFT view change protocol and the Zyzzyva view change protocol is the information included in the VIEW-CHANGE messages. In PBFT, a replica includes its prepared certificates, which is equivalent to the commit certificates in Zyzzyva. However, in Zyzzyva, a replica receives a commit certificate for a request only if the client receives between 2f + 1 and 3f matching SPEC-RESPONSE messages. If the client could receive 3f + 1 matching SPEC-RESPONSE messages for its request, no replica would receive a commit certificate. To deal with this case, the Zyzzyva view change protocol makes the following changes:
- ■ Instead of prepare (or commit) certificates, a replica includes all ORDER-REQ messages it has received since the latest stable checkpoint or the most recent commit certificate.
- ■ The primary for the new view compute the request-sequence number binding for the new view in the following way:
- – The primary for the new view adopts the request-sequence number binding if there are at least f + 1 matching ORDER-REQ messages.
The above changes ensure that if a request has completed at a client, the total order (reflected by the sequence number) for the request is respected in the new view. However, the primary for the new view may find more than one set of f + 1 matching ORDER-REQ messages for different requests but with the same sequence number. This corner case turns out will not damage the safety property of the system because such requests could not have completed at any clients. The primary for the new view can choose to use either request-sequence number binding in the new view. Note that when a backup for the new view verifies the NEW-VIEW message, it may find a conflict in the request-sequence number binding for such requests. Being aware of this corner case, it should take the binding chosen by the primary. More details are discussed in the following example.
7.4.3 The Checkpointing Protocol
The checkpointing protocol in Zyzzyva in virtually identical to that in PBFT, except the BFT infrastructure state is slightly different. A core piece of state maintained by each replica is the ordered history of requests that it has executed. The replica also keeps track of the maximum commit certificate, which is the commit certificate with the largest sequence number (maxCC) that it has received (if any). In the history of the requests, those that carry a sequence number smaller or equal to maxCC are part of the committed history, and those with a sequence number larger than maxCC are part of the speculative history. The history is truncated using the checkpointing protocol. Similar to PBFT, each replica also maintains a response log.
7.4.4 Proof of Correctness
Theorem 7.4 Safety property. Given any two requests that have completed, they must have been assigned two different sequence numbers. Furthermore, if the two sequence numbers are i and j and i < j, the history hash hi must be a prefix of hj.
Proof : We first prove that the safety property holds if the two requests complete in the same view. It is easy to see why two requests cannot be completed with the same sequence number because a request completes only when (1) a client receives 3f + 1 matching SPEC-RESPONSE messages, or (2) 2f + 1 matching LOCAL-COMMIT messages. Because a nonfaulty replica accepts one ORDER-REQ message or sends one LOCAL-COMMIT for the same sequence number, if one request completes in case (1), no other request could have completed with the same sequence number, and if one request completes in case (2), any other request could at most amass 2f matching ORDER-SEQ or LOCAL-COMMIT messages and hence, cannot complete with the same sequence number.
Next, assume that Req1 completes with sequence number i, and Req2 completes with sequence number j. Without loss of generality, let i < j. For a request to complete, at least 2f + 1 replicas have accepted the i for Req1 and at least 2f + 1 replicas have accepted j for Req2. Because there are 3f + 1 replicas, the two sets of replicas must intersect in at least f + 1 replicas and at least one of which is not faulty. This nonfaulty replica ordered both Req1 and Req2. This would ensure that hi is a prefix of hj.
If on the other hand, Req1 completes in view v1 with sequence number i and Req2 completes in view v2 with sequence number j. Without loss of generality, let v1 < v2. If Req1 completes when the client receives 3f + 1 matching order-req messages, then in the VIEW-CHANGE message, every nonfaulty replica must have included the corresponding ORDER-REQ message, which ensure that the primary for view v2 learns the sequence number i and history hash hi for Req1. Therefore, the primary in view v2 cannot assign the same sequence to Req2, and hi must be prefix for hj. If Req1 completes when the client receives 2f + 1 matching LOCAL-COMMIT messages, then at least f + 1 nonfaulty replicas must have included the corresponding commit certificate for i in the VIEW-CHANGE messages, and at least one of them must be included in the set of 2f + 1 VIEW-CHANGE messages received by the primary in view v2. This nonfaulty replica would ensure the proper passing of history information from view v1 to view v2.
Theorem 7.5 Liveness property. If a nonfaulty client issues a request, the request eventually completes.
Proof : We prove this property in two steps. First, we prove that if a nonfaulty client issues a request and the primary is not faulty, then the request will complete. Second, we prove that if a request does not complete, then a view change will occur.
If both the client and the primary are not faulty, then the agreement protocol guarantees that all nonfaulty replicas would accept the same ORDER-REQ message, execute the request, and send matching SPEC-RESPONSE to the client. Because there are at least 2f + 1 nonfaulty replicas, the client would be able to receive at least 2f + 1 matching SPEC-RESPONSE messages and subsequently 2f + 1 matching LOCAL-COMMIT messages in the worst case, or 3f + 1 matching SPEC-RESPONSE messages in the best case. In both cases, the request will complete at the client.
If a request did not complete at the client, then the client must not have received 3f + 1 matching SPEC-RESPONSE messages and must not have received 2f + 1 matching LOCAL-COMMIT messages. There can be only two types of scenarios:
- The client did not receive conflicting SPEC-RESPONSE and LOCAL-COMMIT messages, if any, and the number of SPEC-RESPONSE messages received is fewer than 3f + 1 and the number of LOCAL-COMMIT messages are fewer than 2f + 1. In this case, the client retransmit the request to all replicas (possibly repeatedly until the request complete). This would ensure all nonfaulty replicas receive this request. If the primary refuses to send a ORDER-REQ message to all or some nonfaulty replicas, these replicas would suspect the primary. Since we assume that fewer than 2f + 1 LOCAL-COMMIT messages have been received by the client, at least f + 1 nonfaulty replicas would suspect the primary, which would lead to a view change.
- The client received conflicting SPEC-RESPONSE or LOCAL-COMMIT messages, in which case, the client would multicast a POM message to all replicas. This would lead to a view change.
REFERENCES
1. A. Avizienis and L. Chen. On the implementation of n-version programming for software fault tolerance during execution. In Proceedings of the IEEE International Computer Software and Applications Conference, pages 149–155, 1977.
2. E. D. Berger and B. G. Zorn. Diehard: probabilistic memory safety for unsafe languages. In Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation, pages 158–168, 2006.
3. S. Bhatkar, D. C. DuVarney, and R. Sekar. Address obfuscation: an efficient approach to combat a board range of memory error exploits. In Proceedings of the 12th conference on USENIX Security Symposium - Volume 12, SSYM’03, pages 8–8, Berkeley, CA, USA, 2003. USENIX Association.
4. M. Castro and B. Liskov. Authenticated byzantine fault tolerance without public-key cryptography. Technical Report Technical Memo MIT/LCS/TM-589, MIT Laboratory for Computer Science, 1999.
5. M. Castro and B. Liskov. Practical byzantine fault tolerance. In Proceedings of the third symposium on Operating systems design and implementation, OSDI ’99, pages 173–186, Berkeley, CA, USA, 1999. USENIX Association.
6. M. Castro and B. Liskov. Practical byzantine fault tolerance and proactive recovery. ACM Transactions on Computer Systems, 20(4):398–461, 2002.
7. M. Castro, R. Rodrigues, and B. Liskov. Base: Using abstraction to improve fault tolerance. ACM Transactions on Computer Systems, 21(3):236–269, 2003.
8. H. Chai, H. Zhang, W. Zhao, P. M. Melliar-Smith, and L. E. Moser. Toward trustworthy coordination for web service business activities. IEEE Transactions on Services Computing, 6(2):276–288, 2013.
9. H. Chai and W. Zhao. Interaction patterns for byzantine fault tolerance computing. In T.-h. Kim, S. Mohammed, C. Ramos, J. Abawajy, B.-H. Kang, and D. Slezak, editors, Computer Applications for Web, Human Computer Interaction, Signal and Image Processing, and Pattern Recognition, volume 342 of Communications in Computer and Information Science, pages 180–188. Springer Berlin Heidelberg, 2012.
10. B.-G. Chun, P. Maniatis, and S. Shenker. Diverse replication for single-machine byzantine-fault tolerance. In USENIX 2008 Annual Technical Conference on Annual Technical Conference, ATC’08, pages 287–292, Berkeley, CA, USA, 2008. USENIX Association.
11. F. Cohen. Operating system protection through program evolution. Computers and Security, 12(6):565–584, October 1993.
12. B. Cox, D. Evans, A. Filipi, J. Rowanhill, W. Hu, J. Davidson, J. Knight, A. Nguyen-Tuong, and J. Hiser. N-variant systems: A secretless framework for security through diversity. In 15th USENIX Security Symposium, pages 105–120, 2006.
13. T. Distler and R. Kapitza. Increasing performance in byzantine fault-tolerant systems with on-demand replica consistency. In Proceedings of the sixth Eurosys conference, 2011.
14. H. Erven, H. Hicker, C. Huemer, and M. Zapletal. The Web Services-BusinessActivity-Initiator (WS-BA-I) protocol: An extension to the Web Services-BusinessActivity specification. In Proceedings of the IEEE International Conference on Web Services, pages 216–224, 2007.
15. M. Feingold and R. Jeyaraman. Web services coordination, version 1.1, OASIS standard, July 2007.
16. S. Forrest, A. Somayaji, and D. Ackley. Building diverse computer systems. In Proceedings of the Sixth Workshop on Hot Topics in Operating Systems, pages 67–72, Cape Cod, MA, 1997.
17. M. Franz. Understanding and countering insider threats in software development. In Proceedings of the International MCETECH Conference on e-Technologies, pages 81–90, January 2008.
18. T. Freund and M. Little. Web services business activity version 1.1, OASIS standard. http://docs.oasis-open.org/ws-tx/wstx-wsba-1.1-spec-os/wstx-wsba-1.1-spec-os.html, April 2007.
19. Z. M. Kedem, K. V. Palem, M. O. Rabin, and A. Raghunathan. Efficient program transformations for resilient parallel computation via randomization. In Proceedings of the 24th Annual ACM Symposium on Theory of Computing, pages 306–317, Victoria, British Columbia, Canada, 1992.
20. R. Kotla, L. Alvisi, M. Dahlin, A. Clement, and E. Wong. Zyzzyva: Speculative byzantine fault tolerance. In Proceedings of 21st ACM Symposium on Operating Systems Principles, 2007.
21. R. Kotla and M. Dahlin. High throughput byzantine fault tolerance. In Proceedings of International Conference on Dependable Systems and Networks, 2004.
22. L. Lamport. Fast paxos. Distributed Computing, 19(2):79–193, 2006.
23. L. Lamport. Brief announcement: leaderless byzantine paxos. In Proceedings of the 25th international conference on Distributed computing, DISC’11, pages 141–142, Berlin, Heidelberg, 2011. Springer-Verlag.
24. L. Lamport. Byzantizing paxos by refinement. In Proceedings of the 25th international conference on Distributed computing, DISC’11, pages 211–224, Berlin, Heidelberg, 2011. Springer-Verlag.
25. L. Lamport and P. M. Melliar-Smith. Byzantine clock synchronization. In Proceedings of the third annual ACM symposium on Principles of distributed computing, PODC ’84, pages 68–74, New York, NY, USA, 1984. ACM.
26. L. Lamport, R. Shostak, and M. Pease. The byzantine generals problem. ACM Transactions on Programming Languages and Systems, 4:382–401, 1982.
27. M. Little and A. Wilkinson. Web services atomic transactions version 1.1, OASIS standard. http://docs.oasis-open.org/ws-tx/wstx-wsat-1.1-spec-os/wstx-wsat-1.1-spec-os.html, April 2007.
28. J. Martin and L. Alvisi. Fast byzantine consensus. IEEE Transactions on Dependable and Secure Computing, 3(3):202–215, 2006.
29. C. Pu, A. Black, C. Cowan, and J.Walpole. A specialization toolkit to increase the diversity of operating systems. In Proceedings of the ICMAS Workshop on Immunity-Based Systems, Nara, Japan, 1996.
30. B. Vandiver, H. Balakrishnan, B. Liskov, and S. Madden. Tolerating byzantine faults in database systems using commit barrier scheduling. In Proceedings of the 21st ACM Symposium on Operating Systems Principles, Stevenson, WA, 2007.
31. B. Wester, J. Cowling, E. B. Nightingale, P. M. Chen, J. Flinn, and B. Liskov. Tolerating latency in replicated state machines. In Proceedings of the Sixth Symposium on Networked Systems Design and Implementation (NSDI), Boston, Massachusetts, Apr. 2009.
32. J. Xu, Z. Kalbarczyk, and R. Iyer. Transparent runtime randomization for security. In Proceedings of the 22nd International Symposium on Reliable Distributed Systems, pages 260–269, 2003.
33. H. Zhang, H. Chai, W. Zhao, P. M. Melliar-Smith, and L. E. Moser. Trustworthy coordination for web service atomic transactions. IEEE Transactions on Parallel and Distributed Systems, 23(8):1551–1565, 2012.
34. H. Zhang, W. Zhao, P. M. Melliar-Smith, and L. E. Moser. Design and implementation of a byzantine fault tolerance framework for non-deterministic applications. IET Software, 5:342–356, 2011.
35. W. Zhao, L. Moser, and P. M. Melliar-Smith. Deterministic scheduling for multithreaded replicas. In Proceedings of the IEEE International Workshop on Object-oriented Real-time Dependable Systems, pages 74–81, Sedona, AZ, 2005.