
Chapter 11
Performing Basic I/O
IN THIS CHAPTER
![]() Understanding the relationship between I/O and functional programming
Understanding the relationship between I/O and functional programming
![]() Managing data
Managing data
![]() Exploring the Jupyter Notebook magic functions
Exploring the Jupyter Notebook magic functions
![]() Performing I/O-related tasks
Performing I/O-related tasks
To be useful, most applications must perform some level of Input/Output (I/O). Interaction with the world outside the application enables the application to receive data (input) and provide the results of any operations performed on that data (output). Without this interaction, the application is self-contained, and although it could conceivably perform work, that work would be useless. Any language that you use to create a useful application must support I/O. However, I/O would seem to be counter to the functional programming paradigm because most languages implement it as a procedure — a process. But functional languages implement I/O differently from other languages; they use it as a pure function. The goal is to implement I/O without side effects, not to keep I/O from occurring. The first part of this chapter discusses how I/O works in the functional programming paradigm.
After you know how the I/O process works, you need some means of managing the data. This chapter begins by looking at the first kind of I/O that most applications perform, data input, and then reviews data output. You discover how the functional programming paradigm makes I/O work without the usual side effects. This first part also discusses some differences in device interactions.
 Jupyter Notebook offers magic functions that make working with I/O easier. This chapter also looks at the features provided by magic functions when you're working Python. Because Jupyter Notebook provides support for a long list of languages, you may eventually be able to use magic functions with Haskell as well.
Jupyter Notebook offers magic functions that make working with I/O easier. This chapter also looks at the features provided by magic functions when you're working Python. Because Jupyter Notebook provides support for a long list of languages, you may eventually be able to use magic functions with Haskell as well.
The final part of this chapter puts together everything you’ve discovered about I/O in the functional programming paradigm. You see how Haskell and Python handle the task in both pure and impure ways. Performing I/O and programming in a functional way aren’t mutually exclusive, and no one is breaking the rules to make it happen. However, each language has a slightly different approach to the issue, so a good understanding of each approach is important.
Understanding the Essentials of I/O
Previous chapters discuss the essentials of the functional programming paradigm. Some of these issues are mechanical, such as the immutability of data. In fact, some would argue that these issues aren’t important — that only the use of pure functions is important. The various coding examples and explanations in those previous chapters tend to argue otherwise, but for now, consider only the need to perform I/O using pure functions that produce no side effects. In some respects, that really isn’t possible. (Some people say it is, but the proof is often lacking.) The following sections discuss I/O from a functional perspective and help you understand the various sides of the argument over whether performing I/O using pure functions is possible.
Understanding I/O side effects
An essential argument that many people make regarding I/O side effects is actually quite straightforward. When you create a function in a functional language and apply specific inputs, you receive the same answer every time, as long as those inputs remain the same. For example, if you calculate the square root of 4 and then make the same call 99 more times, you receive the answer 2 every time. In fact, a language optimizer would do well to simply cache the result, rather than perform the calculation, to save time.
However, if you make a call to query the user for input, you receive a certain result. Making the same call, with the same query, 99 more times may not always produce the same result. For example, if you pose the question “What is your name?” the response will differ according to user. In fact, the same user could answer differently by providing a full name one time and only a first name another. The fact that the function call potentially produces a different result with each call is a side effect. Even though the developer meant for the side effect to occur, from the definitions of the functional programming paradigm in past chapters, I/O produces a side effect in this case.
The situation becomes worse when you consider output. For example, when a function makes a query to the user by outputting text to the console, it has changed the state of the system. The state is permanently changed because returning the system to its previous state is not possible. Even removing the characters would mean making a subsequent change.
Unfortunately, because I/O is a real-world event, you can’t depend on the occurrence of the activity that you specify. When you calculate the square root of 4, you always receive 2 because you can perform the task as a pure function. However, when you ask the user for a name, you can’t be sure that the user will supply a name; the user might simply press Enter and present you with nothing. Because I/O is a real-world event with real-world consequences, even functional languages must supply some means of dealing with the unexpected, which may mean exceptions — yet another side effect.
Many languages also support performing I/O separately from the main application thread so that the application can remain responsive. The act of creating a thread changes the system state. Again, creating a thread is another sort of side effect that you must consider when performing I/O. You need to deal with issues such as the system’s incapability to support another thread or knowing whether any other problems arose with the thread. The application may need to allow inter-thread communication, as well as communication designed to ascertain thread status, all of which requires changing application state.
 This section could continue detailing potential side effects because myriad side effects are caused by I/O, even successful I/O. Functional languages make a clear distinction between pure functions used to perform calculations and other internal tasks and I/O used to affect the outside world. The use of I/O in any application can potentially cause these problems:
This section could continue detailing potential side effects because myriad side effects are caused by I/O, even successful I/O. Functional languages make a clear distinction between pure functions used to perform calculations and other internal tasks and I/O used to affect the outside world. The use of I/O in any application can potentially cause these problems:
- No actual divide: Any function can perform I/O when needed. So the theoretical divide between pure functions and I/O may not be as solid as you think.
- Monolithic: Because I/O occurs in a sequence (you can’t obtain the next answer from a user before you obtain the current answer), the resulting code is monolithic and tends to break easily. In addition, you can't cache the result of an I/O; the application must perform the call each time, which means that optimizing I/O isn't easy.
- Testing: All sorts of issues affect I/O. For example, an environmental condition (such as lightning) that exists now and causes an I/O to fail may not exist five minutes from now.
- Scaling: Because I/O changes system state and interacts with the real world, the associated code must continue executing in the same environment. If the system load suddenly changes, the code will slow as well because scaling the code to use other resources isn't possible.
The one way you have to overcome these problems in a functional environment is to ensure that all the functions that perform I/O remain separate from those that perform calculations. Yes, the language you use may allow the mixing and matching of I/O and calculations, but the only true way around many of these problems is to enforce policies that ensure that the tasks remain separate.
Using monads for I/O
The “Understanding monoids” section of Chapter 10 discusses monads and their use, including strings. Interestingly enough, the IO class in Haskell, which provides all the I/O functionality, is a kind of monad, as described at https://hackage.haskell.org/package/base-4.11.1.0/docs/System-IO.html. Of course, this sounds rather odd, but it's a fact. Given what you know about monads, you need to wonder what the two objects are and what the operator is. In looking down the list of functions for the IO class, you discover that IO is the operator. The two objects are a handle and the associated data.
A handle is a method for accessing a device. Some handles, such as stderr, stdin, and stdout, are standard for the system, and you don't need to do anything special to use them. For both Python and Haskell, these standard handles point to the keyboard for stdin and the display (console) for stdout and stderr. Other handles are unique to the destination, such as a file on the local drive. You must first acquire the handle (including providing a description of how you plan to use it) and then add it to any call you make.
Interacting with the user
The concept of using a monad for I/O has some ramifications that actually make Haskell I/O easier to understand, despite its being essentially the same as any other I/O you might have used. When performing input using getLine, what you really do is combine the stdin handle with the data the user provides using the IO operator. Yes, it's the same thing you do with the Python input method, but the underlying explanation for the action is different in the two cases; when working with Python, you’re viewing the task as a procedure, not as a function. To see how this works, type :t getLine and press Enter. You see that the type of getLine (a function) is IO String. Likewise, type :t putStrLn and press Enter, and you see that the type of putStrLn is String -> IO (). However, when you use the following code:
putStrLn "What is your name?"
name <- getLine
putStrLn $ "Hello " ++ name
you obtain the same result as you might expect from any programming language. Only the manner in which you review the action differs, not the actual result of the action, as shown in Figure 11-1.

FIGURE 11-1: Interacting with the user implies using monads with an operator of IO.
Notice that you must use the apply operator ($) to the second putStrLn call because you need to apply the result of the monad "Hello " ++ name (with ++ as the operator) to putStrLn. Otherwise, Haskell will complain that it was expecting a [char]. You could also use putStrLn ("Hello " ++ name) in place of the apply operator.
Working with devices
Always remember that humans interact with devices — not code, not applications, and not actually with data. You could probably come up with a lot of different ways to view devices, but the following list provides a quick overview of the essential device types:
- Host: The host device is the system on which the application runs. Most languages support standard inputs and outputs for the host device that don't require any special handling.
- Input: Anything external to the host can provide input. In this case, external to the host means anything outside the localized processing environment, including hard drives housed within the same physical structure as the motherboard that supports the host. However, inputs can come from anywhere, including devices such as external cameras from a security system.
- Output: An output device can be anything, including a hard drive within the same physical case as the host. However, outputs also include physical devices outside the host case. For example, sending a specific value to a robot may create a thousand widgets. The I/O has a distinct effect on the outside world outside the realm of the host device.
- Cloud: A cloud device is one that doesn’t necessarily have physicality. The device could be anywhere. Even if the device must have a physical presence (such as a hard drive owned by a host organization), you may not know where the device is located and likely don’t even care. People are using more and more cloud devices for everything from data storage to website hosting, so you're almost certain to deal with some sort of cloud environment.
All the I/O that you perform with a programming language implies access to a device, even when working with a host device. For example, when working with Haskell, the hPutStrLn and putStrLn lines of code that follow are identical in effect (note that you must import System.IO before you can perform this task):
import System.IO as IO
hPutStrLn stdout "Hello there!"
putStrLn "Hello there!"
The inclusion of stdout in the first call to hPutStrLn simply repeats what putStrLn does without an explicit handle. However, in both cases, you do need a handle to a device, which is the host in this case. Because the handle is standard, you don't need to obtain one.
Getting a handle for a local device is relatively easy. The following code shows a three-step process for writing to a file:
import System.IO as IO
handle <- openFile "MyData.txt" WriteMode
hPutStrLn handle "This is some test data."
hClose handle
When calling openFile, you again use the IO operator. This time, the two objects are the file path and the I/O mode. The output, when accessing a file successfully, is the I/O handle. Haskell doesn't use the term file handle as other languages do because the handle need not necessarily point to a file. As always, you can use :t openFile to see the definition for this function. When you don’t supply a destination directory, GHCi resorts to using whatever directory you have assigned for loading files. Here is the code used to read the content from the file:
import System.IO as IO
handle <- openFile "MyData.txt" ReadMode
myData <- hGetLine handle
hClose handle
putStrLn myData
 This chapter doesn’t fully explore everything you can do with various I/O methodologies in Haskell. For example, you can avoid getting a handle to read and write files by using the
This chapter doesn’t fully explore everything you can do with various I/O methodologies in Haskell. For example, you can avoid getting a handle to read and write files by using the readFile, writeFile, and appendFile functions. These three functions actually reduce the three-step process into a single step, but the same steps occur in the background. Haskell does support the full range of device-oriented functions for I/O found in other languages.
Manipulating I/O Data
This chapter doesn't discuss all the ins and outs of data manipulation for I/O purposes, but it does give you a quick overview of some issues. One of the more important issues is that both Haskell and Python tend to deal with string or character output, not other data types. Consequently, you must convert all data you want to output to a string or a character. Likewise, when you read the data from the source, you must convert it back to its original form. A call, such as appendFile "MyData.txt" 2, simply won't work. The need to work with a specific data type contrasts to other operations you can perform with functional languages, which often assume acceptance of any data type. When creating functions to output data, you need to be aware of the conversion requirement because sometimes the error messages provided by the various functional languages are less than clear as to the cause of the problem.
Another issue is the actual method used to communicate with the outside world. For example, when working with files, you need to consider character encoding (the physical representation of the characters within the file, such as the number of bits used for each character). Both Haskell and Python support a broad range of encoding types, including the various Unicode Transformation Format (UTF) standards described at https://www.w3.org/People/danield/unic/unitra.htm. When working with text, you also need to consider issues such as the method used to indicate the end of the line. Some systems use both a carriage return and line feed; others don’t.
Devices may also require the use of special commands or headers to alert the device to the need to communicate and establish the communication methods. Neither Haskell nor Python has these sorts of needs built into the language, so you must either create your own solution or rely on a third-party library. Likewise, when working with the cloud, you often must provide the data in a specific format and include headers to describe how to communicate and with which service to communicate (among other things).
The reason for considering all these issues before you try to communicate is that a large number of online help messages deal with these sorts of issues. The language works as intended in producing output or attempting to receive input, but the communication doesn’t work because of the lack of communication protocol (a set of mutually acceptable rules). Unfortunately, the rules are so diverse and some so arcane as to defy any sort of explanation in a single book. Make sure to keep in mind that communication is often a lot more than simply sending or receiving data, even in a functional language in which some things seem to happen magically.
Using the Jupyter Notebook Magic Functions
Python can make your I/O experience easier when you work with specific tools, which is the point of this section. Notebook and its counterpart, IPython, provide you with some special functionality in the form of magic functions. It’s kind of amazing to think that these applications offer you magic, but that’s precisely what you get with the magic functions. The magic is in the output. For example, instead of displaying graphic output in a separate window, you can choose to display it within the cell, as if by magic (because the cells appear to hold only text). Or you can use magic to check the performance of your application, and do so without all the usual added code that such performance checks require.
A magic function begins with either a percent sign (%) or double percent sign (%%). Those with a % sign work within the environment, and those with a %% sign work at the cell level. For example, if you want to obtain a list of magic functions, type %lsmagic and then press Enter in IPython (or run the command in Notebook) to see them, as shown in Figure 11-2. (Note that IPython uses the same input, In, and output, Out, prompts that Notebook uses.)
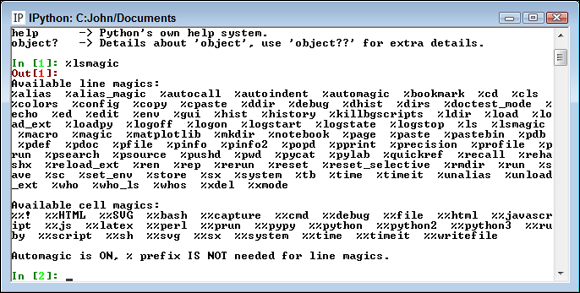
FIGURE 11-2: The %lsmagic function displays a list of magic functions for you.
Not every magic function works with IPython. For example, the %autosave function has no purpose in IPython because IPython doesn't automatically save anything.
Table 11-1 lists a few of the most common magic functions and their purpose. To obtain a full listing, type %quickref and press Enter in Notebook (or the IPython console) or check out the full listing at https://damontallen.github.io/IPython-quick-ref-sheets/.
TABLE 11-1 Common Notebook and IPython Magic Functions
|
Magic Function |
Type Alone Provides Status? |
Description |
|
|
Yes |
Assigns or displays an alias for a system command. |
|
|
Yes |
Enables you to call functions without including the parentheses. The settings are Off, Smart (default), and Full. The Smart setting applies the parentheses only if you include an argument with the call. |
|
|
Yes |
Enables you to call the line magic functions without including the percent (%) sign. The settings are False (default) and True. |
|
|
Yes |
Displays or modifies the intervals between automatic Notebook saves. The default setting is every 120 seconds. |
|
|
Yes |
Changes directory to a new storage location. You can also use this command to move through the directory history or to change directories to a bookmark. |
|
|
No |
Clears the screen. |
|
|
No |
Specifies the colors used to display text associated with prompts, the information system, and exception handlers. You can choose between NoColor (black and white), Linux (default), and LightBG. |
|
|
Yes |
Enables you to configure IPython. |
|
|
Yes |
Displays a list of directories visited during the current session. |
|
|
No |
Outputs the name of the file that contains the source code for the object. |
|
|
Yes |
Displays a list of magic function commands issued during the current session. |
|
|
No |
Installs the specified extension. |
|
|
No |
Loads application code from another source, such as an online example. |
|
|
No |
Loads a Python extension using its module name. |
|
|
Yes |
Displays a list of the currently available magic functions. |
|
|
Yes |
Displays a help screen showing information about the magic functions. |
|
|
Yes |
Sets the back-end processor used for plots. Using the inline value displays the plot within the cell for an IPython Notebook file. The possible values are: 'gtk', ‘gtk3’, ‘inline’, ‘nbagg’, ‘osx’, ‘qt’, ‘qt4’, ‘qt5’, ‘tk’, and ‘wx’. |
|
|
No |
Pastes the content of the Clipboard into the IPython environment. |
|
|
No |
Shows how to call the object (assuming that the object is callable). |
|
|
No |
Displays the |
|
|
No |
Displays detailed information about the object (often more than provided by help alone). |
|
|
No |
Displays extra detailed information about the object (when available). |
|
|
No |
Reloads a previously installed extension. |
|
|
No |
Displays the source code for the object (assuming that the source is available). |
|
|
No |
Calculates the best performance time for an instruction. |
|
|
No |
Calculates the best performance time for all the instructions in a cell, apart from the one placed on the same cell line as the cell magic (which could therefore be an initialization instruction). |
|
|
No |
Removes a previously created alias from the list. |
|
|
No |
Unloads the specified extension. |
|
|
No |
Writes the contents of a cell to the specified file. |
Receiving and Sending I/O with Haskell
Now that you have a better idea of how I/O in the functional realm works, you can find out a few additional tricks to use to make I/O easier. The following sections deal specifically with Haskell because the I/O provided with Python follows the more traditional procedural approach (except in the use of things like lambda functions, which already appear in previous chapters).
Using monad sequencing
Monad sequencing helps you create better-looking code by enabling you to combine functions into a procedure-like entity. The goal is to create an environment in which you can combine functions in a manner that makes sense, yet doesn't necessarily break the functional programming paradigm rules. Haskell supports two kinds of monad sequencing: without value passing and with value passing. Here is an example of monad sequencing without value passing:
name <- putStr "Enter your name: " >> getLine
putStrLn $ "Hello " ++ name
In this case, the code creates a prompt, displays it onscreen, obtains input from the user, and places that input into name. Notice the monad sequencing operator (>>) between the two functions. The assignment operator works only with output values, so name contains only the result of the call to getLine. The second line demonstrates this fact by showing the content of name.
You can also create monad sequencing that includes value passing. In this case, the direction of travel is from left to right. The following code shows a function that calls getLine and then passes the result of that call to putStrLn.
echo = getLine >>= putStrLn
To use this function, type echo and press Enter. Anything you type as input echoes as output. Figure 11-3 shows the results of these calls.
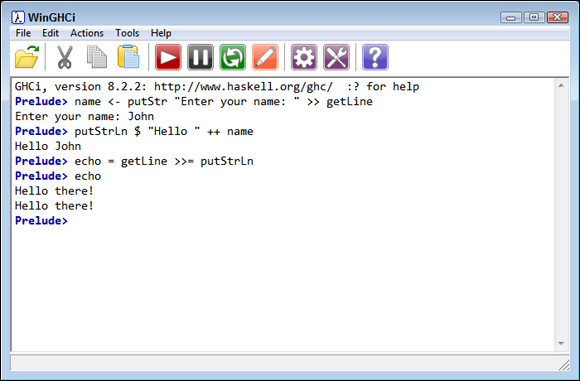
FIGURE 11-3: Monad sequencing makes combining monad functions in specific ways easier.
Employing monad functions
Because Haskell views I/O as a kind of monad, you also gain access to all the monad functions found at http://hackage.haskell.org/package/base-4.11.1.0/docs/Control-Monad.html. Most of these functions don't appear particularly useful until you start using them together. For example, say that you need to replicate a particular string a number of times. You could use the following code to do it:
sequence_ (replicate 10 (putStrLn "Hello"))
The call to sequence_ (with an underscore) causes Haskell to evaluate the sequence of monadic actions from left to right and to discard the result. The replicate function performs a task repetitively a set number of times. Finally, putStrLn outputs a string to stdout. Put it all together and you see the result shown in Figure 11-4.
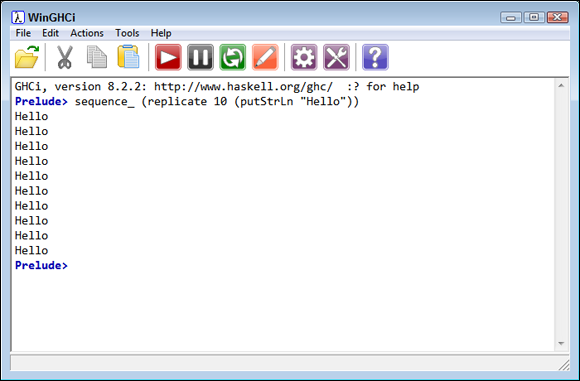
FIGURE 11-4: Use monad functions to achieve specific results using little code.