
In the following section, we'll be talking a lot about indexing and advanced queries; however, it doesn't make sense to run advanced queries on a database that contains just one or two documents! Sometimes, you need to load lots of data into RethinkDB to use as sample data. Such data can include names, numbers, zip codes, locations, and so on.
To simulate a real-world scenario, we're going to import a big dataset into RethinkDB that includes some fake data (name, surname, e-mail, and age) for 30,000 people. This dataset is included in the data.json file that you can find in the code folder that accompanies this book.
RethinkDB includes a bulk loader that can be run from a shell; it is designed to import huge quantities of data into a particular database table on the server.
The import utility can load data from files in these formats:
- CSV: In this file format, also known as comma-separated values, each line within the file represents a document, and each field within one single document is separated by a comma.
- JSON: These files, also known as JavaScript object notation, are much more complex than CSV files as the JSON format allows you to represent full-fledged documents. Unlike other formats, JSON can support documents with variable schemas and different data types.
The RethinkDB import utility is extremely intuitive. For input, it takes a file in one of the two preceding formats, and a few options are used to control where in the database the data will be saved.
Before using the import utility, we must install it.
One of the dependencies required by the importer is the installation of the RethinkDB Python module. There are various ways to install it; we'll be using the pip package manager.
First, we run the following command to install the pip package manager:
sudo apt-get install python-pip
Running this command from a shell will download and install the package manager on your system.
Note
This command assumes you're using a Debian-based operating system, such as Ubuntu Linux. If you're running a different OS., the installation process will be different. Further instructions are available on the project's homepage at https://pip.pypa.io/en/stable/.
Once the pip package manager has been successfully installed, installing RethinkDB's Python module is as simple as running the following:
sudo pip install rethinkdb
This command will download, install, and configure the module on your system.
Now that all the dependencies have been satisfied, we can run the importer. We need to specify two options: the name of the file to import and the database and table where the data needs to be saved.
The following command will import the dataset included in the data.json file into a table called people in the test database:
rethinkdb import -f data.json --table test.people
If the import process succeeds, you will get an output similar to this:
no primary key specified, using default primary key when creating table [========================================] 100% 30000 rows imported in 1 table Done (4 seconds)
As you can see from the previous message, 30000 records have been imported into RethinkDB!
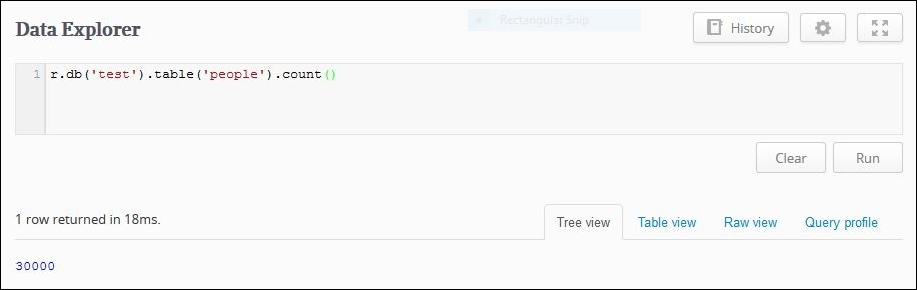
We can confirm this by running a count query from the database web interface:
r.db('test').table('people').count()Unsurprisingly, the result of the query will be 30000:
Now that we've got a table full of sample data, it's time to start running some queries on it. The next section will be all about indexing.