
Chapter 4
Understanding Key Coding Concepts
In This Chapter
![]() Discovering the four major parts of any website or app
Discovering the four major parts of any website or app
![]() Knowing the difference between SQL and NoSQL
Knowing the difference between SQL and NoSQL
![]() Seeing a version control system at work
Seeing a version control system at work
![]() Uncovering how search engines rank websites
Uncovering how search engines rank websites
Thoughts without content are empty, intuitions without concepts are blind.
—Immanuel Kant
As you continue learning about coding careers, whether researching on the Internet or having conversations with other programmers, you’ll hear some words and phrases repeatedly. You might hear a developer say, “I started on the back end, but front end work is more visual and definitely my style.” Or “Merging my branch with master, deployed to production, seeing your work live is what makes this so much fun.”
A few key coding concepts crop up in almost every conversation on coding. After you understand these concepts, you’ll be better equipped to participate in the conversation. Much like following a baseball game, you might not know what the infield fly rule is, but knowing the basics of strikes, outs, walks, and runs makes it easier to understand the more obscure rules.
In this chapter, you discover key coding concepts such as developing for the front end and back end, storing data in databases, version control, and big data basics.
Developing for the Front End and Back End
When browsing a website or using an application, the experience is seamless and cohesive as you move from one screen to another, reading and entering information as needed. The code for websites and programs can be divided into four categories, as shown in Figure 4-1, according to the code’s function:
- Appearance: The visible part of the website, including content layout and any applied styling, such as font size, font typeface, and image size. This category is called the front end and is created using languages such as HTML, CSS, and JavaScript.
- Logic: Determines the content to show and when to show it. For example, a New Yorker accessing a news website should see New York weather, whereas Chicagoans accessing the same site should see Chicago weather. This category is part of the group called the back end and is created using languages such as Ruby on Rails, Python, and PHP. These back-end languages can modify the HTML, CSS, and JavaScript displayed to the user.
- Storage: Saves any data generated by the site and its users. User-generated content, preferences, and profile data must be stored for retrieval later. This category is part of the back end and is stored in databases such as MongoDB and MySQL.
- Infrastructure: Delivers the website from the server to you, the client machine. When the infrastructure is properly configured, no one notices it. But it can become noticeable when a website becomes unavailable due to high traffic from events such as presidential elections, the Super Bowl, or natural disasters. Web servers such as Apache and Nginx receive requests from clients and respond by sending copies of website code. Without the proper configuration a surge of traffic will generate requests faster than the web server can respond, resulting in error messages.
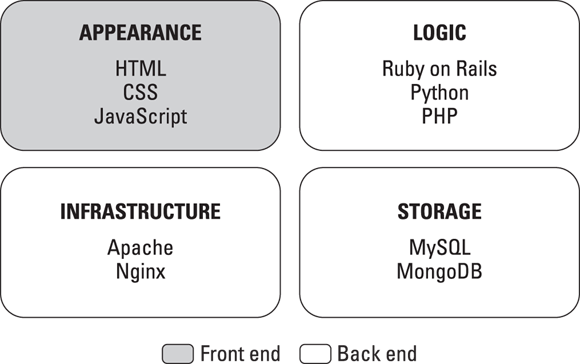
Figure 4-1: Every website is made up of four parts.
Usually, website developers specialize in one or at most two of these categories. For example, a developer might understand the front end and logic languages, or specialize in only databases. Website developers have strengths and specializations, and their expertise outside these areas is limited, much in the same way that Kanye West, a terrific rapper, would likely make a terrible harp player in a symphony orchestra.
 The rare website developer proficient in all four of these categories is referred to as a full stack developer. Usually, smaller companies hire full stack developers, whereas larger companies require the expertise that comes with specialization.
The rare website developer proficient in all four of these categories is referred to as a full stack developer. Usually, smaller companies hire full stack developers, whereas larger companies require the expertise that comes with specialization.
Each feature you see on a web page requires set up for the front end and back end. For example, let’s say you’re building a social network, and you want to include user profiles. First, on the front end you’ll need to design how each profile screen looks and functions. Next, on the back end, you’ll need to select, install, and set up a database that will allow you to create, retrieve, update, and delete profiles as needed. Finally, you’ll need to make your database accessible to web and mobile applications. Depending on which operating system your server is using, you may need to upgrade the entire operating system or key libraries to resolve compatibility issues before you can install the database.
Back end as a service (BAAS) providers reduce the time and effort you spend on back-end installations and setup by maintaining ready-to-use servers, which you can rent. To install a service, like a database, you click a button; the installation happens automatically on the server and you don’t need to worry about software incompatibilities. Any libraries or dependencies needed by the database are installed by the BAAS provider, which also handles keeping the servers up and running, upgrades, and security patches. Some of the more popular BAAS providers are Heroku, for web apps, and Parse, for mobile apps.
Storing Data in SQL and NoSQL Databases
Website and applications use databases to permanently store data to be retrieved at a later time. The data to be stored could be user credentials, pictures, product information, status updates, tweets, or just about anything else. The key consideration for any type of database is its scalability, or the capability to handle more data with increasing frequency. Over the last forty years, two types of databases have emerged for storing data — SQL databases and NoSQL databases.
SQL databases
SQL, or Structured Query Language, is the standard language for relational databases. A relational database stores data in tables of columns and rows, with a unique key assigned to each row. This unique key is then used to create relationships between data in related tables. For example, if a university were building a student database, they might create the following:
- Student table with student first and last names, address information, phone number, and emergency contact information. Each student would also have a unique key (student ID).
- Student_Courses table with each student’s unique key, the course’s unique key (course ID), and the student’s final grade.
- Courses table with the course’s unique key, course name, professor’s name, location, and meeting time.
The tables and the predefined relationship between data elements, as shown in Figure 4-2, make a database relational. You might wonder why multiple tables are needed, when instead you could represent all the information in one big table. Two reasons are data consistency and data accuracy. If the name of a course changed and you were using one big table, you would have to find and change all instances of the course name. With one course table, you could change the course name just once. SQL databases work best when data is not repeated and is instead linked using multiple tables.
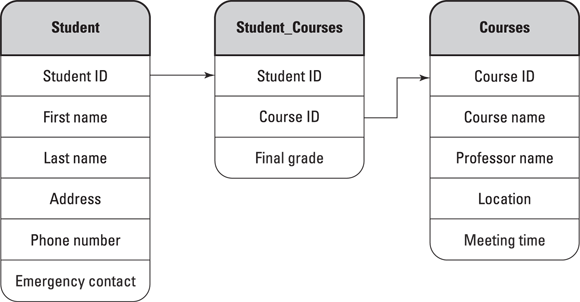
Figure 4-2: A relational student database with student and class information.
The SQL programming language accesses and modifies databases by using SQL queries. A SQL query is inserted into the code of the programming language you’re using (Ruby, Python, or PHP), and the results of the query are then output to your website or data analytics program. If you’re setting up the database yourself, you might want to install a popular database management systems such as MySQL or PostgreSQL. Alternatively, if you’re using a BAAS provider for your application, your database can be installed automatically.
NoSQL databases
NoSQL databases take advantage of advances in hardware to build faster and more efficient databases. Historically, CPUs and storage were expensive, so databases were designed to minimize cost and resources used. If the database grew too large, or the queries started running slowly, the database was moved to a more powerful computer with additional storage.
Today, two things have happened that challenge assumptions used by SQL databases. First, hardware prices of storage and CPUs have dropped, while hard drives have become bigger and CPUs have become more powerful. Second, the amount of data that needs to be stored has increased, and it is not always clear in advance what data will be collected and stored. For example, Google processes 24 petabytes (1000 terabytes) of data daily — the average consumer hard drive is a little over 1 terabyte.
NoSQL databases are distributed, which means they are stored and processed across multiple servers. Popular NoSQL databases include MongoDB, CouchDB, and Redis. A NoSQL database system has the following advantages:
- No schema: Unlike with a SQL database, you do not define the data relationships beforehand. NoSQL databases allow you to change the format or type of data being stored at any time.
- Scalable: If your database becomes too large, you can easily add another relatively cheap server without any downtime. For SQL databases, scaling your database requires buying an expensive server and experiencing downtime to migrate and install the database on a new system.
- Cheap: You can use inexpensive consumer-level hardware for a NoSQL database. For even greater ease, you can use a product such as Amazon Web Services (AWS) to cheaply rent storage space and set up a NoSQL database with just a click, without buying physical servers.
NoSQL databases also spread the processing load across multiple CPUs. In a process called MapReduce, a large data set is divided into smaller data sets, which are each processed independently. The results from these individual data sets are then reduced back into a single data set or result. For example, suppose you want to find the Facebook user with the most friends. Instead of using one computer to search Facebook’s 1.5 billion users, you could split the users into fifteen data sets of 100,000 users each, and then map each data set to one of fifteen computers. Each computer would process its list to find the user with the most friends, after which each result would be reduced into one smaller data set of fifteen names. The final operation would find the user with the most friends from this smaller list of fifteen users.
NoSQL databases have many advantages, but there are some obstacles as well. The database system is relatively new, so there is less technical support and fewer people with expertise to set up, administer, and develop NoSQL databases. Additionally, because running simple queries in NoSQL databases can be difficult, doing analytics and business reporting for NoSQL databases is not as developed and is much harder than doing similar work for SQL databases.
Saving Your Code in a Repository
Version control systems and code repositories allow developers to work together. The code for the front end or back end, along with the queries you write to retrieve data from databases, are initially stored on your own computer. However, if you work on a team — and most coding jobs are team based — you need a version control system so that code on your computer can be shared with other developers without creating conflicts from differing versions.
If you’ve ever had a folder with filenames like Resume_Nov_2014_v1, Resume_Nov_2014_v2, and Resume_Jan_2015_v1,you’ve created a version control system for files. Similarly, the track changes feature in word processors is a version control system for content in a file. Version control systems for code track files and their content, and store code in centralized code repositories that are shared with other programmers. Typically, each developer has a local copy of the code, and everyone uses one centralized code repository.
 Git is one of the most popular version control systems, and GitHub is one of the most popular code repositories. Other version control systems are CVS, SVN, and Mercurial.
Git is one of the most popular version control systems, and GitHub is one of the most popular code repositories. Other version control systems are CVS, SVN, and Mercurial.
The most basic version control system commands are checking in and checking out files. You check in a file when you add it to the code repository, and you check out a file by making a local copy of a file from the code repository. After you check out and change a file, you can either check in the updated file back to the code repository, or discard your copy and leave the original as-is.
Every time you check in a file, add comments to the file so others can easily see at a glance what has changed without reading the entire file.
Sometimes conflicts can occur. For example, suppose you checked out a file with code for a restaurant’s home page, and you changed the image on the front page from a hotdog to a cheeseburger. While you were working on the file, a coworker changed the image on the front page from a hotdog to a milk shake and added an image of an ice cream cone. If your coworker checks in the file before you, and you try to check in your version of the file, you would receive a warning from the version control system alerting you to a conflict. You would either need to overwrite your coworker’s changes with your own, or check out the version of the file with the milk shake and ice cream cone, replace the milk shake image with the cheeseburger image, delete the ice cream cone, and check in the file again.
Advanced version control system commands include branching and merging files. Imagine you had a crazy idea to add a cooking school to the restaurant web page. Instead of changing the existing files, you can make a copy of the master version of the files in the code repository called a branch, as shown in Figure 4-3. You can keep checking in and checking out files from the branch as you add code and content for the cooking school. After you finish and the restaurant owner approves your cooking school addition, you can then merge the changes back into the master version of the files.
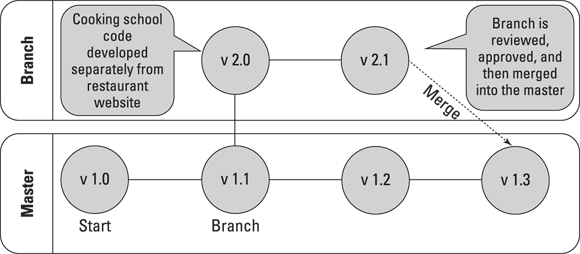
Figure 4-3: Branching code, making changes, and merging it back to the master version.
Before merging your changes, your coworkers may do a code review to check the quality of your code, typically making sure your code is bug-free and well documented.
Optimizing Code for Search Engines
The phrase “If you build it, they will come” was used in the movie Field of Dreams about an Iowa corn farmer who built a baseball field and suddenly players appeared to use the field. Although viral hits do happen, for the most part the saying does not hold true for technology products. Just building a website or an app will result in thousands of visitors, downloads, or substantial other traffic.
The most reliable way to bring in traffic is to rank highly in a search engine for certain keywords. People using search engines such as Google, Bing, or Yahoo! enter keywords and typically click one of the first ten results. The technique of increasing your site’s visibility to be within the top ten search engine results for a particular set of keywords is called search engine optimization (SEO).
Search engines rank results by using two factors: domain authority and page authority. Domain authority describes how high a particular domain ranks in search results, based on the domain’s trustworthiness, and the number of links from other highly ranked domains. Page authority describes how high a specific page will rank in search results. Page authority is based on how many other highly ranked sites link to this specific web page, the keywords used in hyperlinks on other pages, and the keywords on the page itself.
One of the most reliable ways to improve your search ranking is to get more links from other highly ranked pages.
Strategies that follow search engine guidelines and focus on attracting a human audience are called white hat SEO techniques, while strategies that use borderline unethical techniques to trick the programs that crawl websites are called black hat SEO techniques. When search engines discover sites that use black hat SEO techniques, they are penalized in the rankings.
Because web pages are automatically crawled for content, search engines generally recommend creating keyword-rich text content, using the title and headings, and not displaying important information in an image. These tips directly affect how you write the code for a web page because presenting information with complex code may affect the capability of search engines to read your web page. Analytics packages such as Google Analytics track visitors so you can see over time the effect SEO is having on your website.