
18 Reactive and onion architectures

In this chapter
- Learn how to build pipelines from actions using reactive architecture.
- Create a common mutable state primitive.
- Construct the onion architecture to interface your domain with the world.
- See how the onion architecture applies at many levels.
- Learn how the onion architecture compares to the traditional layered architecture.
We’ve learned quite a lot of applications of first-class functions and higher-order functions throughout part 2. Now it’s time to take a step back and cap off those chapters with some talk about design and architecture. In this chapter, we look at two separate, common patterns. Reactive architecture flips the way actions are sequenced. And the onion architecture is a high-level perspective on the structure of functional programs that have to operate in the world. Let’s get to it!
Two separate architectural patterns
In this chapter, we’re going to learn two different patterns, reactive and onion. Each architecture works at a different level. Reactive architecture is used at the level of individual sequences of actions. Onion architecture operates at the level of an entire service. The two patterns complement each other, but neither requires the other.
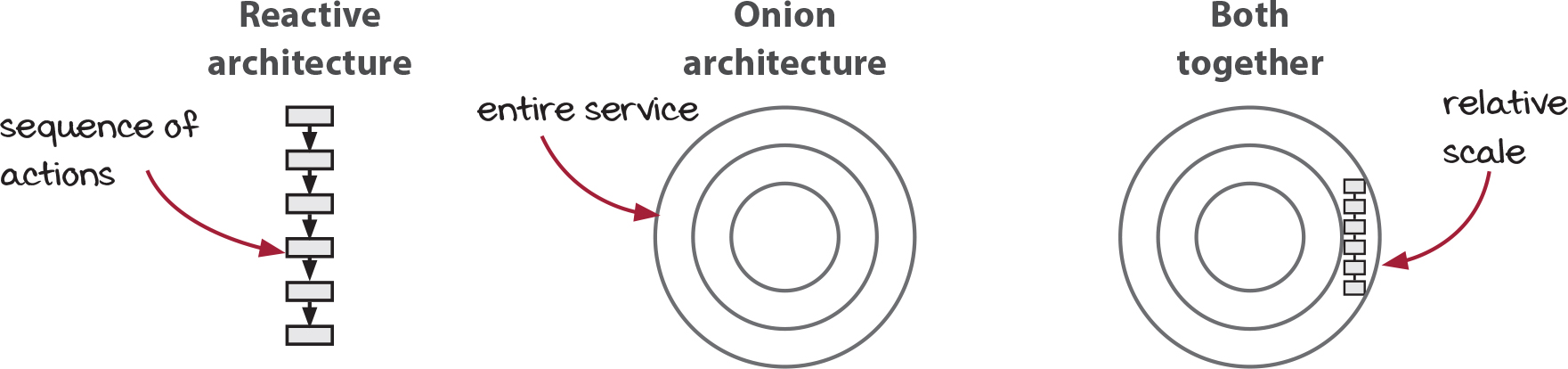
Reactive architecture
The reactive architecture flips the way we express the order of actions in our code. As we’ll see, it helps decouple cause from effect, which can untangle some confusing parts of our code.
Onion architecture
The onion architecture gives a structure to services that must interact with the outside world, be they web services or thermostats. The architecture naturally arises when applying functional thinking.
Coupling of causes and effects of changes

Jenna: Every time I want to add some user interface (UI) element that shows something about the cart, I have to make changes in 10 places. A couple of months ago it was only three places.
Kim: Yeah, I see the problem. It’s a classic n × m problem.
Kim: To add something to one column, you have to modify or duplicate all the things in the other column.
Jenna: Yep! That’s the problem I’m feeling. Any idea how to solve it?
Kim: I think we can use reactive architecture. It decouples actions in the left column from actions in the right. Let’s look at it on the next page.
What is reactive architecture?
Reactive architecture is another useful way of structuring our applications. Its main organizing principle is that you specify what happens in response to events. It is very useful in web services and UIs. In a web service, you specify what happens in response to web requests. In a UI, you specify what happens in response to UI events such as button clicks. These are usually known as event handlers.
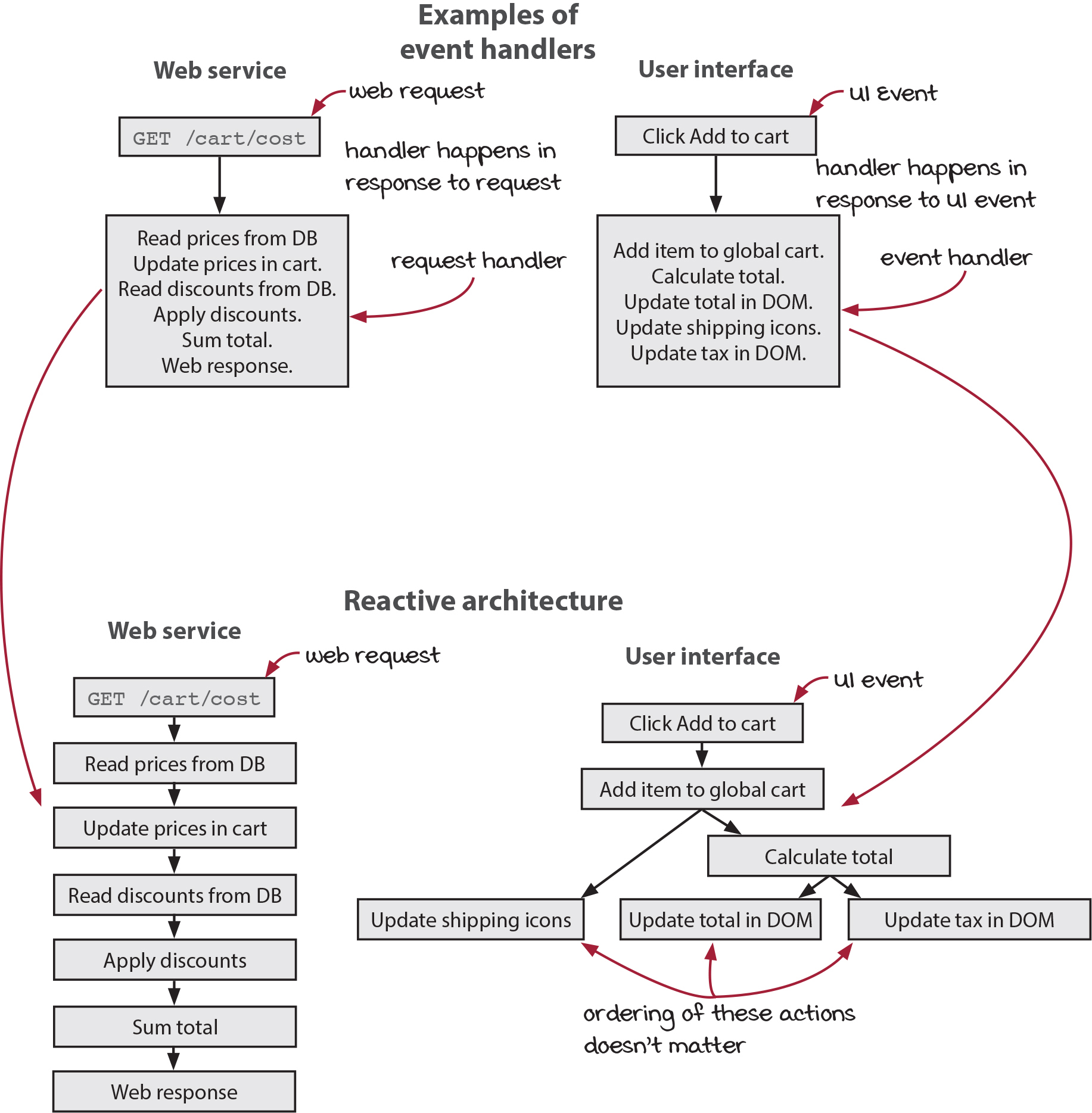
Event handlers let you say, “When X happens, do Y, Z, A, B, and C.” In the reactive architecture, we simply take this as far as we can take it. At the extreme, everything happens in response to something else. “When X happens, do Y. When Y happens, do Z. When Z happens, do A, B, and C.” We break up the typical step-by-step handler function into a series of handlers that respond to the previous one.
Tradeoffs of the reactive architecture
The reactive architecture flips the typical way we express ordering in our code. Instead of “Do X then do Y,” a reactive style says, “Do Y whenever X happens.” Sometimes this makes our code easier to write, read, and maintain. But sometimes it doesn’t! It is not a silver bullet. You have to use your judgment to determine when to use it and how to use it. A deep understanding of what the reactive architecture lets you do will help you. You can then compare the two architectures (typical and reactive) to see if it achieves your goals.
Decouples effects from their causes
Separating the causes from their effects can sometimes make code less readable. However, it can also be very freeing and let you express things much more precisely. We’re going to see examples of both situations.
Treats a series of steps as pipelines
We’ve already seen the power of composing pipelines of data transformation steps. We made good use of them by chaining functional tools together. That was a great way to compose calculations into more sophisticated operations. Reactive architecture lets you do a similar composition with actions and calculations together.
Creates flexibility in your timeline
When you reverse the expression of ordering, you gain flexibility in your timeline. Of course, as we’ve seen, that flexibility could be bad if it leads to unwanted possible orderings. But if used with skill, the same flexibility could shorten timelines.
To examine this, we’re going to develop a very powerful first-class model of state that is common in many web applications and functional programs. State is an important part of applications, functional applications included. Let’s dive into that model on the next page. We’ll use what we develop to explain each of the headings.
Cells are first-class state
The shopping cart is the only piece of global mutable state in our example. We’ve eliminated the rest. What we want to be able to say is, “do Y when the cart changes.”
As it is right now, we don’t know when the cart changes. It is just a normal global variable, and we use the assignment operator to modify it. One option is to make our state first-class. That is, we can turn the variable into an object to control its operations. Here’s a first pass at making a first-class mutable variable.

function ValueCell(initialValue) {
var currentValue = initialValue; ❶
return {
val: function() { ❷
return currentValue;
},
update: function(f) { ❸
var oldValue = currentValue;
var newValue = f(oldValue);
currentValue = newValue;
}
};
}
❶ hold one immutable value (can be a collection)
❷ get current value
❸ modify value by applying a function to current value (swapping pattern)
The name ValueCell is inspired by spreadsheets, which also implement a reactive architecture. When you update one spreadsheet cell, formulas are recalculated in response.
ValueCells simply wrap a variable with two simple operations. One reads the current value (val()). The other updates the current value (update()). These two operations implement the pattern we have used when implementing the cart. Here’s how we would use this:
Before
var shopping_cart = {};
function add_item_to_cart(name, price) {
var item = make_cart_item(name, price);
shopping_cart = add_item(shopping_cart, item); ❶
var total = calc_total(shopping_cart);
set_cart_total_dom(total);
update_shipping_icons(shopping_cart);
update_tax_dom(total);
}
❶ read, modify, write (swapping) pattern
After
var shopping_cart = ValueCell({});
function add_item_to_cart(name, price) {
var item = make_cart_item(name, price);
shopping_cart.update(function(cart) { ❶
return add_item(cart, item);
});
var total = calc_total(shopping_cart.val());
set_cart_total_dom(total);
update_shipping_icons(shopping_cart.val());
update_tax_dom(total);
}
❶ replace manual swap with method call
This change makes reading and writing to shopping_cart explicit method calls. Let’s take it a step further on the next page.
We can make ValueCells reactive
On the last page, we defined a new primitive for representing mutable state. We still need to be able to say, “When the state changes, do X.” Let’s add that now. We’ll modify the definition of ValueCell to add a concept of watchers. Watchers are handler functions that get called every time the state changes.
Original
function ValueCell(initialValue) {
var currentValue = initialValue;
return {
val: function() {
return currentValue;
},
update: function(f) {
var oldValue = currentValue;
var newValue = f(oldValue);
currentValue = newValue;
}
};
}
With watchers
function ValueCell(initialValue) {
var currentValue = initialValue;
var watchers = []; ❶
return {
val: function() {
return currentValue;
},
update: function(f) {
var oldValue = currentValue;
var newValue = f(oldValue);
if(oldValue !== newValue) {
currentValue = newValue;
forEach(watchers, function(watcher) { ❷
watcher(newValue);
});
}
},
addWatcher: function(f) { ❸
watchers.push(f);
}
};
}
❶ keep a list of watchers
❷ call watchers when value changes
❸ add a new watcher
Watchers let us say what happens when the cart changes. Now we can say, “When the cart changes, update the shipping icons.”
![]() Vocab time
Vocab time
There’s more than one name for the watcher concept. No name is more correct than the others. You may have heard these other names:
- Watchers
- Listeners
- Callbacks
- Observers
- Event handlers
They’re all correct and represent similar ideas.
Now that we’ve got a way to watch a cell, let’s see what it looks like in our add-to-cart handler on the next page.
We can update shipping icons when the cell changes
On the last page, we added a method to ValueCell for adding watchers. We also made watchers run whenever the current value changed. We can now add update_shipping_icons() as a watcher to the shopping_cart ValueCell. That will update the icons whenever the cart changes, for whatever reason.
Before
var shopping_cart = ValueCell({});
function add_item_to_cart(name, price) {
var item = make_cart_item(name, price);
shopping_cart.update(function(cart) {
return add_item(cart, item);
});
var total = calc_total(shopping_cart.val());
set_cart_total_dom(total);
update_shipping_icons(shopping_cart.val()); ❶
update_tax_dom(total);
}
❶ make the event handler simpler by removing downstream actions
After
var shopping_cart = ValueCell({});
function add_item_to_cart(name, price) {
var item = make_cart_item(name, price);
shopping_cart.update(function(cart) {
return add_item(cart, item);
});
var total = calc_total(shopping_cart.val());
set_cart_total_dom(total);
update_tax_dom(total);
}
shopping_cart.addWatcher(update_shipping_icons); ❶
❶ we only have to write this code once and it runs after all cart updates
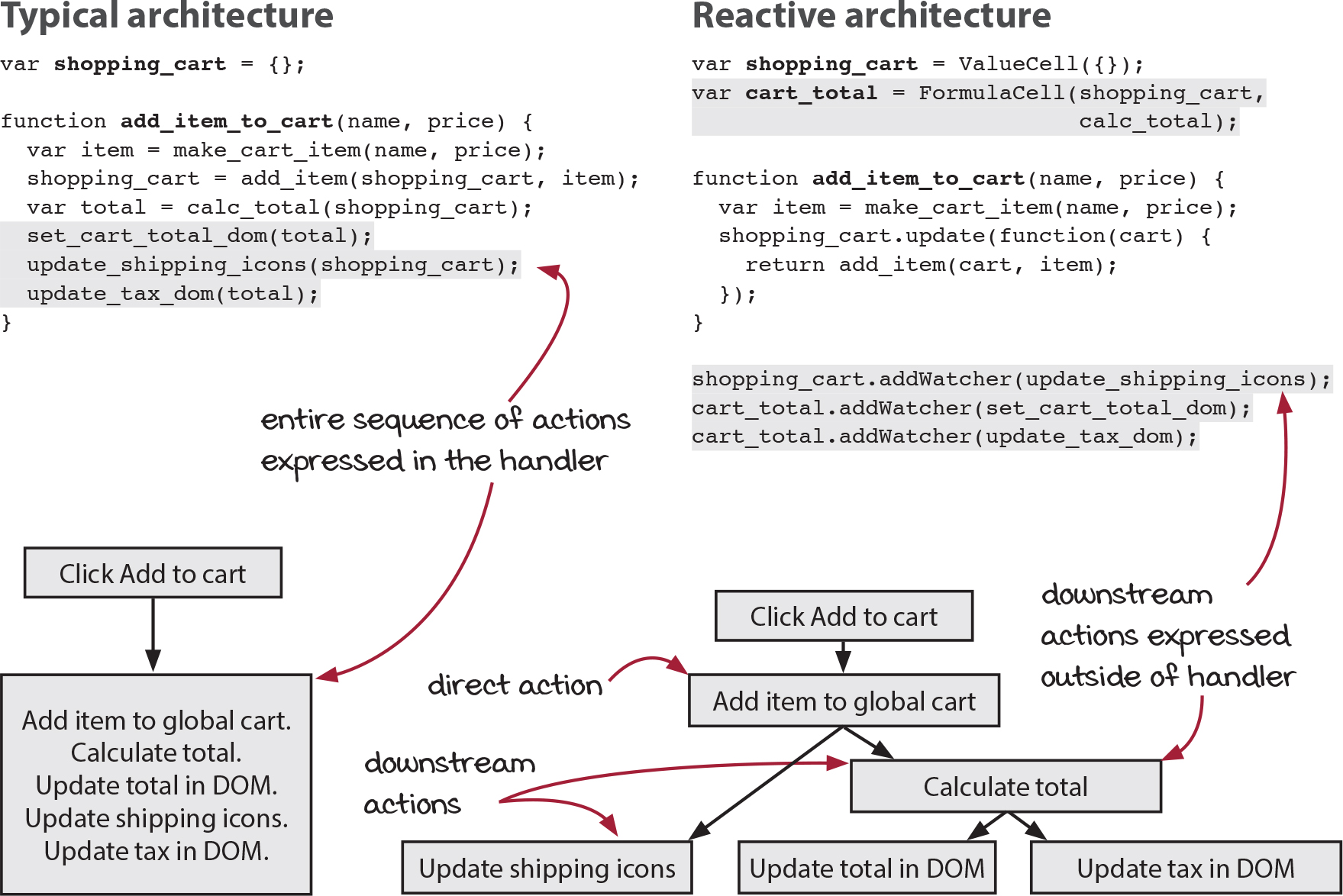
There are two important things to notice here. First, our handler function got smaller. It does less. It no longer has to manually update the icons. That responsibility has moved into the watcher infrastructure. Second, we can remove the call to update_shipping_icons() from all handlers. It will run for any change to the cart, be it adding an item, removing an item, updating a quantity, or what have you. This is exactly what we want: The icons are always up-to-date with the state of the cart.
We’ve removed one DOM update from the handler. The other two only depend indirectly on the cart. More directly, they depend on the total, which is a value derived from the cart. On the next page, we implement another primitive that can maintain a derived value. Let’s check it out.
FormulaCells calculate derived values
On the last page, we made ValueCells reactive by adding watchers. Sometimes you want to derive a value from an existing cell and keep it up-to-date as that cell changes. That’s what FormulaCells do. They watch another cell and recalculate their value when the upstream cell changes.
function FormulaCell(upstreamCell, f) {
var myCell = ValueCell(f(upstreamCell.val())); ❶
upstreamCell.addWatcher(function(newUpstreamValue) { ❷
myCell.update(function(currentValue) {
return f(newUpstreamValue);
});
});
return {
val: myCell.val, ❸
addWatcher: myCell.addWatcher ❸ ❹
};
}
❶ reuse the machinery of ValueCell
❷ add a watcher to recompute the current value of this cell
❸ val() and addWatcher() delegate to myCell
❹ FormulaCell has no way to change value directly
Notice that there is no method to directly update the value of a FormulaCell. The only way to change it is to change the upstream cell that it watches. FormulaCells say “When the upstream cell changes, recalculate my value based on the upstream cell’s new value.” FormulaCells can be watched as well.
Because they can be watched, we can add some actions that happen in response to changes to the total:
Before
var shopping_cart = ValueCell({});
function add_item_to_cart(name, price) {
var item = make_cart_item(name, price);
shopping_cart.update(function(cart) {
return add_item(cart, item);
});
var total = calc_total(shopping_cart.val());
set_cart_total_dom(total);
update_tax_dom(total);
}
shopping_cart.addWatcher(update_shipping_icons);
After
var shopping_cart = ValueCell({}); ❶
var cart_total = FormulaCell(shopping_cart,
calc_total);
function add_item_to_cart(name, price) {
var item = make_cart_item(name, price);
shopping_cart.update(function(cart) {
return add_item(cart, item); ❷
});
}
shopping_cart.addWatcher(update_shipping_icons);
cart_total.addWatcher(set_cart_total_dom);
cart_total.addWatcher(update_tax_dom); ❸
❶ cart_total will change whenever shopping_cart changes
❷ click handler is now very simple
❸ DOM will update in response to cart_total changing
Now we have three parts of the DOM updating whenever the cart changes. What’s more, our handler more directly states what it does.
Mutable state in functional programming
You may have heard functional programmers say they don’t use mutable state and to avoid it at all costs. This is quite likely an overstatement since most software overuses mutable state.
Maintaining mutable state is an important part of all software, including software written using functional programming. All software must take in information from a changing world and remember part of it. Whether it’s in an external database or in memory, something has to learn about new users and the users’ actions in the software, to say the least. What’s important is the relative safety of the state we use. Even though they are mutable, cells are very safe compared to regular global variables if you use them to store immutable values.

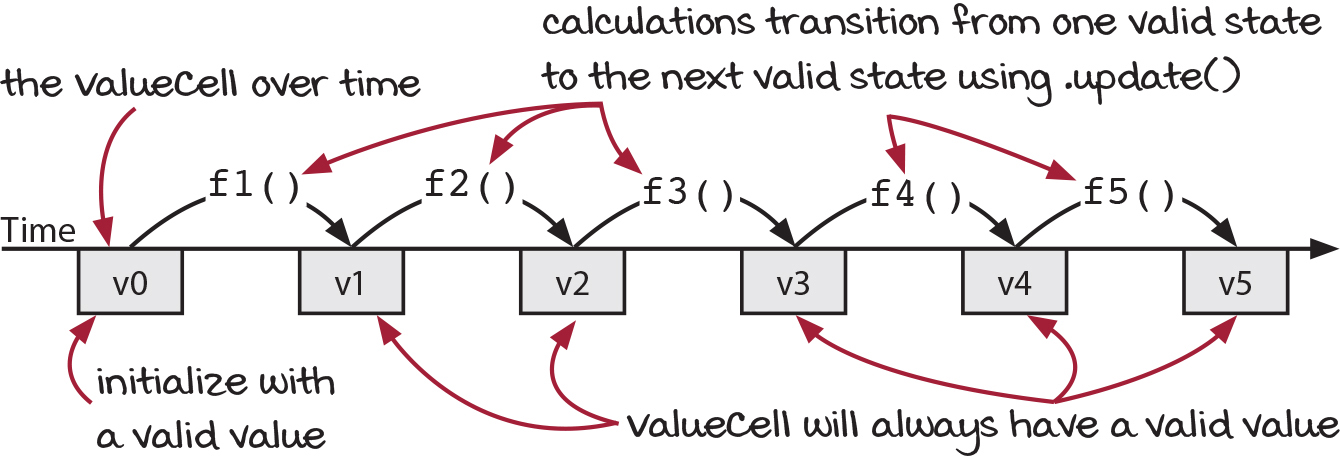
The update() method for ValueCells makes it easy to keep the current value valid. Why? You call update() with a calculation. That calculation takes the current value and returns the new value. If your current value is valid for your domain and the calculation always returns valid values if given a valid value, the new value will always be valid. ValueCells can’t guarantee the order of updates or reads from different timelines, but they can guarantee that any value stored in them is valid. In a lot of situations, that is more than good enough.
ValueCell.update(f) ❶
❶ always pass a calculation to update
ValueCell consistency guidelines
- Initialize with a valid value.
- Pass a calculation to update() (never an action).
- That calculation should return a valid value if passed a valid value.
![]() Vocab time
Vocab time
The equivalent to ValueCells are found in many functional languages and frameworks:
- In Clojure: Atoms
- In React: Redux store and Recoil atoms
- In Elixir: Agents
- In Haskell: TVars
How reactive architecture reconfigures systems
We have just reconfigured our code into an extreme version of the reactive architecture. We made everything a handler to something else changing:
We should explore the consequences of this fundamental reorganization of the architecture. As we’ve seen before, reactive architecture has three major effects on our code:
- Decouples effects from their causes
- Treats series of steps as pipelines
- Creates flexibility in your timeline
Let’s address these in turn on the next few pages.
![]() It’s your turn
It’s your turn
Are ValueCell and FormulaCell actions, calculations, or data?
Answer: Actions, since they’re mutable state. Calling .val() or .update() depends on when or how many times it is called.
Decouples effects from their causes
Sometimes you have a rule you want to implement in your code. For instance, a rule that we’ve implemented in this book has been “The free shipping icons should show whether adding an item to the current cart would qualify for free shipping.” That’s a complex thing that we’ve implemented. However, it has that concept of current cart. It implies that whenever the cart changes, the icons may need to be updated.
Reactive architecture
- Decouples cause and effect.**
** you are here
- Treats steps as pipelines.
- Creates timeline flexibility.
The cart can change for different reasons. We’ve been focusing on clicking the add to cart button. But what about clicking the remove from cart button? What about clicking the empty cart button? Any operation we do to the cart will need us to run essentially the same code.
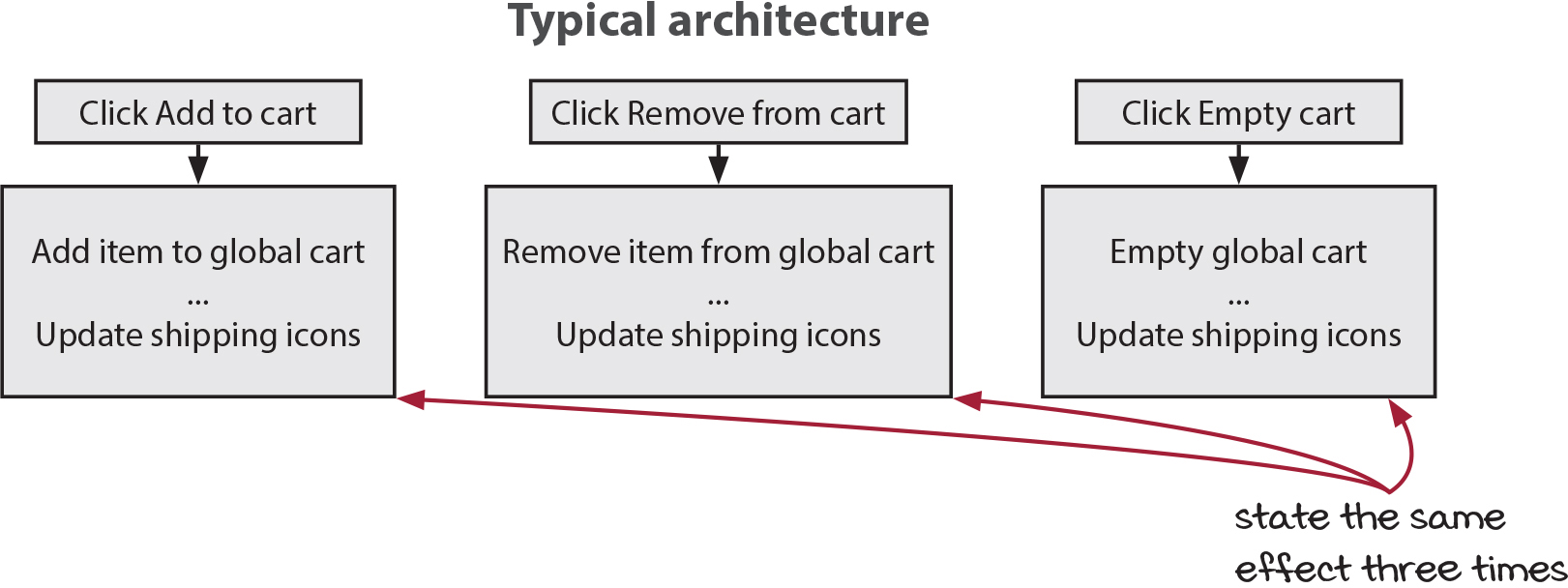
In a typical architecture, we would need to write the same code in every UI event handler. When the user clicks the add to cart button, update the icons. When they click the remove from cart button, update the icons. When they click the empty cart button, update the icons. We have coupled the cause (the button click) with the effect (updating the icons). A reactive architecture lets us decouple the cause and the effect. Instead, we say, “Any time the cart changes, regardless of the cause, update the icons.”
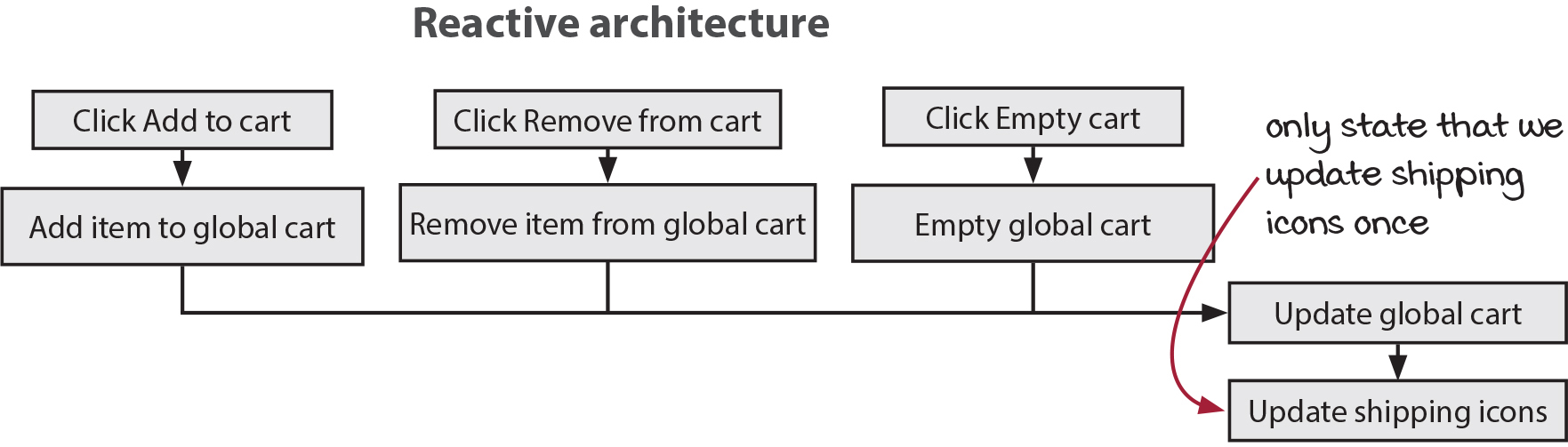
We only have to state once that we need to update the shipping icons. And we can state our rule more precisely: Whenever the global cart changes, for any reason, update the shipping icons. On the next page, let’s look at what problem this architecture solves.
Decoupling manages a center of cause and effect
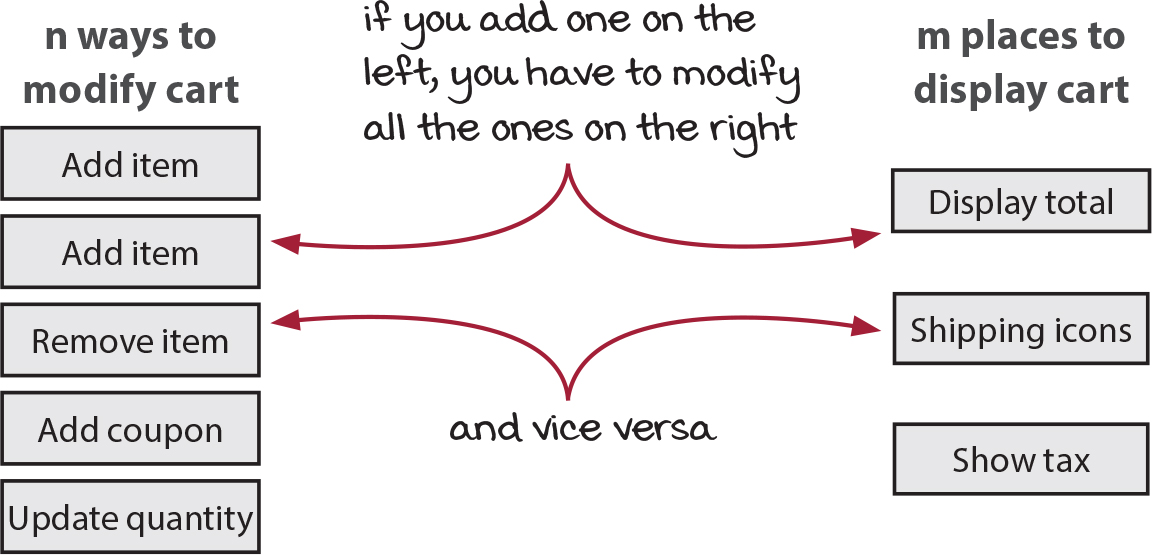
We just saw how the reactive architecture lets us decouple a cause from its effects. This technique is a powerful way to solve a really thorny problem. In our case, the problem manifested as many ways to change the cart and many things to do when the cart changes.
Ways to change the cart
- Add item.
- Remove item.
- Clear cart.
- Update quantity.
- Apply discount code.
Actions to do when cart changes
- Update shipping icons.
- Show tax.
- Show total.
- Update number of items in cart.
There are many more ways to change the cart and many more actions to do. And these change over time. Imagine that we have to add one more thing to do when the cart changes. How many places will we have to add it? Five, one for each of the ways to change the cart. Likewise, if we add one way to change the cart, we will need to add all of the actions into its handler. As we add more things on either side, the problem gets worse.

Really, we can say that there are 20 things that need to be maintained. That’s five ways to change (causes) times four actions (effects). As we add more causes or effects, the multiplication gets bigger. We could say that the global shopping cart is a center of cause and effect. We want to manage this center so that the number of things to maintain doesn’t grow as quickly.
This high growth is the problem that decoupling solves. It converts the growth operation from a multiplication to an addition. We need to write five causes and separately write four effects. That’s 5 + 4 places instead of 5 × 4. If we add an effect, we don’t need to change the causes. And if we add a cause, we don’t need to change the effects. That’s what we mean when we say the causes are decoupled from the effects.
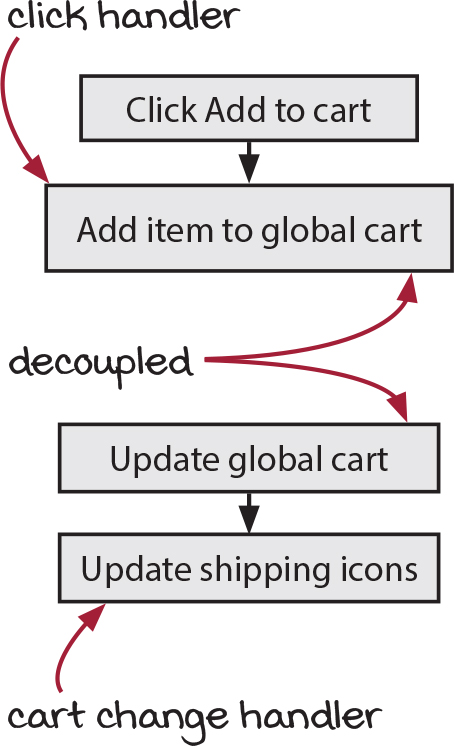
When that’s the problem you have, this solution is very powerful. It lets you think in terms of changes to the cart when you’re programming event handlers. And it lets you think in terms of DOM updates when you are showing things in the DOM.
When that’s not the problem you have, the decoupling won’t help and might make things worse. Sometimes the clearest way to express a sequence of actions is by writing them in sequence, line by line. If there’s no center, there’s no reason to decouple.
Treat series of steps as pipelines
In chapter 13, we saw how we can compose multiple calculations using a chain of functional tools, which let us write very simple functions (easier to write) that could be used to make complex behaviors. In turn, we can get a lot of reuse from those simple functions.
Reactive architecture lets us build complex actions out of simpler actions and calculations. The composed actions take the form of pipelines. Data enters in the top and flows from one step to the next. The pipeline can be considered an action composed of smaller actions and calculations.
If you’ve got a series of steps that need to happen, where the data generated by one step is used as the input to the next step, a pipeline might be exactly what you need. An appropriate primitive can help you implement that in your language.

Pipelines are most often implemented using a reactive framework. In JavaScript, promises provide a way to construct pipelines of actions and calculations. A promise works for a single value as it passes through the steps of the pipeline.
If you need a stream of events instead of just one event, the ReactiveX (https://reactivex.io) suite of libraries gives you the tools you need. Streams let you map and filter events. They have implementations for many different languages, including RxJS for JavaScript.
There are also external streaming services, such as Kafka (https://kafka.apache.org) or RabbitMQ (https://www.rabbitmq.com). Those let you implement a reactive architecture at a larger scale in your system between separate services.
If your steps don’t follow the pattern of passing data along, you either want to restructure them so that they do, or consider not using this pattern. If you’re not really passing data through, it’s not really a pipeline. The reactive architecture might not be right.
Reactive architecture
- Decouples cause and effect.
- Treats steps as pipelines.**
** you are here
- Creates timeline flexibility.
![]() Deep dive
Deep dive
The reactive architecture has been gaining popularity as a way to architect microservices. See The Reactive Manifesto for a great explanation of the benefits
Flexibility in your timeline
Reactive architecture can also give you flexibility in your timeline, if that flexibility is desired. Because it flips the way we typically define ordering, it will naturally split the timelines into smaller parts:

As we’ve seen starting in chapter 15, shorter timelines are easier to work with. However, more numerous timelines, in general, are harder to work with. The trick, as we’ve seen, is to split them in such a way as to eliminate shared resources.

Reactive architecture
- Decouples cause and effect.
- Treats steps as pipelines.
- Creates timeline flexibility.**
** you are here
The shopping cart ValueCell calls its watcher functions with the current value of the cart. The watcher functions do not need to read the cart ValueCell themselves, so they don’t use the cart global as a resource. Likewise, the total FormulaCell calls its watcher functions with the current total. The DOM updates don’t use the total FormulaCell, either. Each DOM update modifies a separate part of the DOM. We can safely consider them different resources; hence, none of these timelines have any resources in common.
![]() It’s your turn
It’s your turn
We need to design a user notification system to notify users of changes to their account, when the terms of service change, and when there are special offers. We might have other reasons to notify in the future.
At the same time, we need to notify the user in different ways. We send them an email, put a banner on the website, and put a message in their messages section of our site. And again, we may create more ways to notify them in the future.
A developer on the team suggested the reactive architecture. Would this be a good use of the reactive architecture? Why or why not?


![]() Answer
Answer
Yes, it sounds like a very good application of the reactive architecture. We have multiple causes (reasons to notify the user) and multiple effects (ways to notify the user). The reactive architecture will let us decouple the causes from the effects so that they can vary independently.
![]() It’s your turn
It’s your turn
Our newest document processing system has a very straightforward sequence of steps that needs to be executed to perform a routine task. The document is validated, cryptographically signed, saved to an archive, and recorded in a log. Would this be a good use of the reactive architecture? Why or why not?

![]() Answer
Answer
Probably not. The sequence does not seem to have the center of cause and effect that reactive architecture really helps with. Instead, the steps are always sequential, and none seems to be the cause of the other. A more straightforward sequence of actions might be better.
Two separate architectural patterns
We’ve just seen the reactive architecture. Now we’re going to focus on an entirely different architecture called the onion architecture. The onion architecture occurs at a larger scale than the reactive architecture. The onion architecture is used to construct an entire service so that it can interact with the outside world. When used together, you often see the reactive architecture nested inside an onion architecture, though neither requires the other.

Reactive architecture
The reactive architecture flips the way that we express the order of actions in our code. As we’ll see, it helps decouple cause from effect, which can untangle some confusing parts of our code.
Onion architecture
The onion architecture gives a structure to services that must interact with the outside world, be they web services or thermostats. The architecture naturally arises when applying functional thinking.

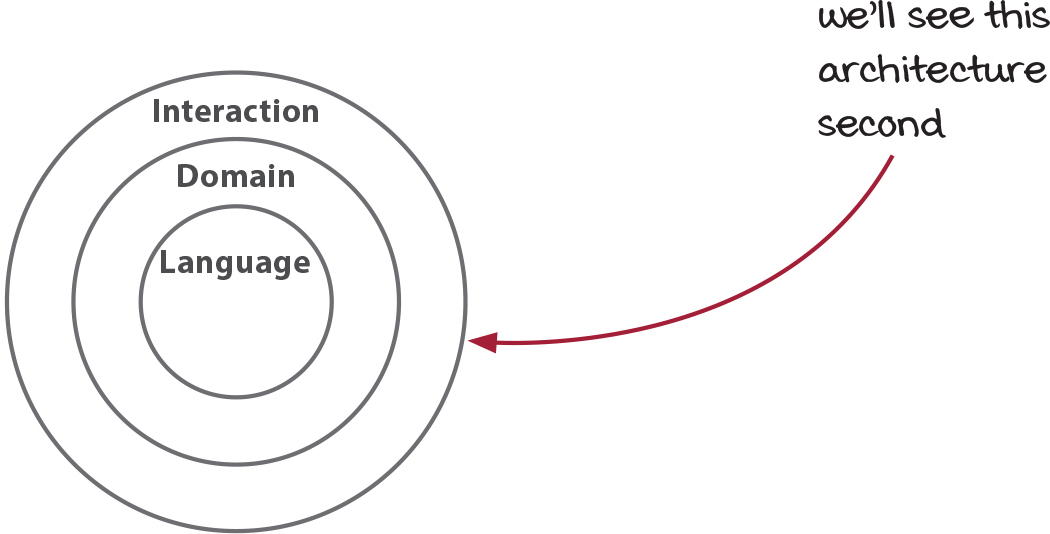
What is the onion architecture?
The onion architecture is a way to structure services and other software that have to interact with the world. As the name suggests, the architecture is drawn as a set of concentric layers, like an onion:

Interaction layer
- Actions that are affected by or affect the outside world
Domain layer
- Calculations that define the rules of your business
Language layer
- Language and utility libraries
The onion architecture is not specific about what layers you have, but they generally follow these three large groupings. Even this simple example shows the main rules that make it work well in functional systems. Here are those rules:
- Interaction with the world is done exclusively in the interaction layer.
- Layers call in toward the center.
- Layers don’t know about layers outside of themselves.
The onion architecture aligns very well with the action/calculation division and stratified design we learned in part 1. We will review those, and then see how we can apply the onion architecture to real-world scenarios.
Review: Actions, calculations, and data
In part 1, we learned about the differences between actions, calculations, and data. We’ll review those here because they will inform a lot of our choices for building the architecture.
Data
We start with data because it is the simplest. Data is facts about events. It’s numbers, strings, collections of those, and so on, anything that is inert and transparent.
Calculations
Calculations are computations from input to output. They always give the same output given the same input. That means calculations don’t depend on when or how many times they are run. Because of that, they don’t appear in timelines since the order they run in doesn’t matter. Much of what we did in part 1 was to move code out of actions and into calculations.
Actions
Actions are executable code that has effects or is affected by the outside world. That means they depend on when or how many times they run. We spent a good portion of part 2 managing the complexity of actions. Since interacting with the database, APIs, and web requests are actions, we’ll be dealing with those a lot in this chapter.
If we follow the recommendations of chapter 4, which guided us to extract calculations from actions, we will naturally arrive at something very much like the onion architecture without meaning to. For this reason, may functional programmers may consider the onion architecture too obvious to even warrant a name. However, the name is used (so it’s important to know it), and it is useful for getting a high-level view of how services might be structured when using functional programming.
Review: Stratified design
Stratified design is the perspective of arranging functions into layers based on what functions they call and what functions call them. It helps clarify what functions are more reusable, changeable, and worth testing.

It also shows us a neat view of the spreading rule: If one of the boxes is an action, every box on the path to the top is also an action:
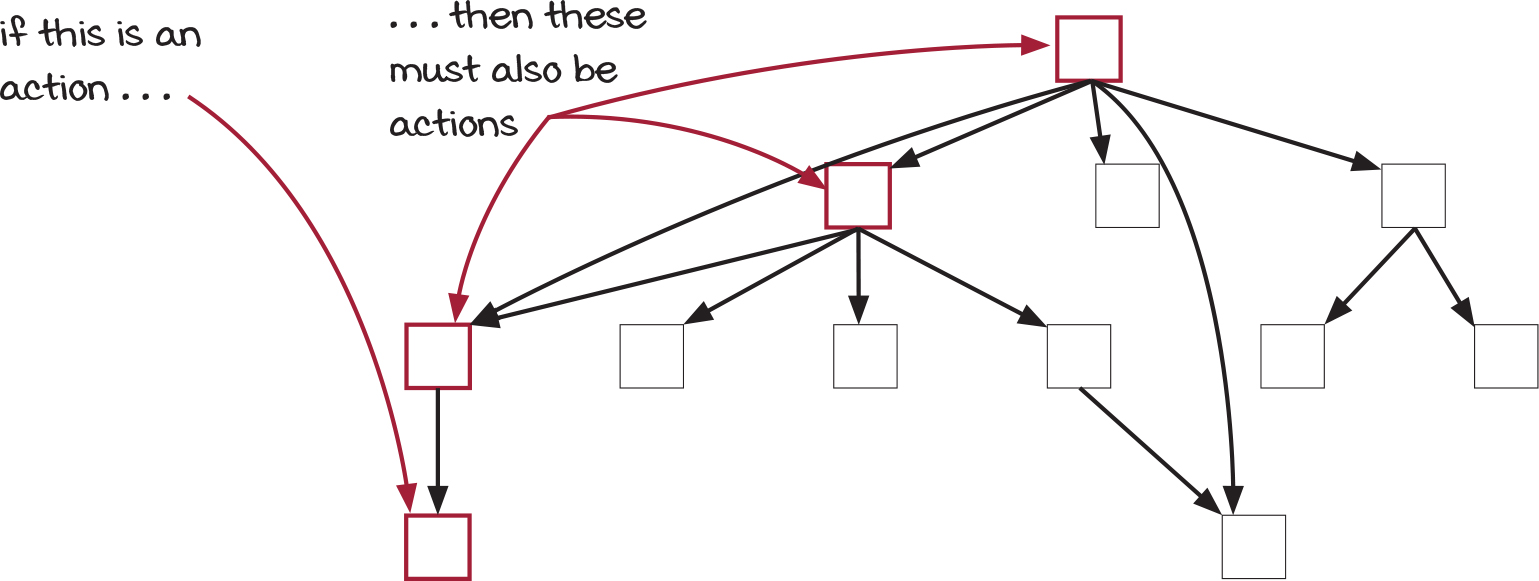
If you have any actions in the graph, the top of the graph will be an action. We spent much of part 1 separating the actions from calculations. Let’s see what that looks like when we draw the graph with actions separated from calculations on the next page.
Traditional layered architecture
A traditional web API is often called layered, just like our layered design. However, the layers are different. Here is a typical layout for a layered web server:

Web Interface layer
- Translate web requests into domain concepts, and domain concepts into web responses
Domain layer
- Application’s custom logic, often translates domain concepts into DB queries and commands
Database layer
- Store information that changes over time
In this architecture, the database (DB) is the foundation at the bottom of everything. The domain layer is built out of, among other things, operations on the DB. The web interface translates web requests into domain operations.
This architecture is quite common. We see it in frameworks like Ruby on Rails, which builds the domain model (the M in MVC) using active record objects, which fetch and save to the database. Of course, we can’t argue with the success of this architecture, but it is not functional.
The reason it is not functional is that putting the database at the bottom means everything in the path to the top above it is an action. In this case, it’s the whole stack! Any use of calculations is incidental. A functional architecture should have a prominent role for both calculations and actions.
Let’s compare this to a functional architecture on the next page.
A functional architecture
Let’s compare the traditional (nonfunctional) architecture to a functional architecture. The main difference is that the database is at the bottom of the traditional layer scheme, while the database is pulled out to the side in a functional architecture. It is mutable, so access to it is an action. We can then draw the line dividing actions from calculations, and another one dividing our code from the language and libraries we use:

The database is mutable. That’s the point of it. But that makes any access to it an action. Everything on the path to the top of the graph will necessarily be an action, including all of the domain operations. As we learned in part 1, functional programmers would rather extract calculations from the actions. They want a clean separation, to the point of building the entire business and domain logic in terms of calculations. The database is separate (though important). The action at the top ties the domain rules to the state in the database.
If we wrap those dotted lines of the functional architecture around to make circles, we get the original diagram of the onion architecture:
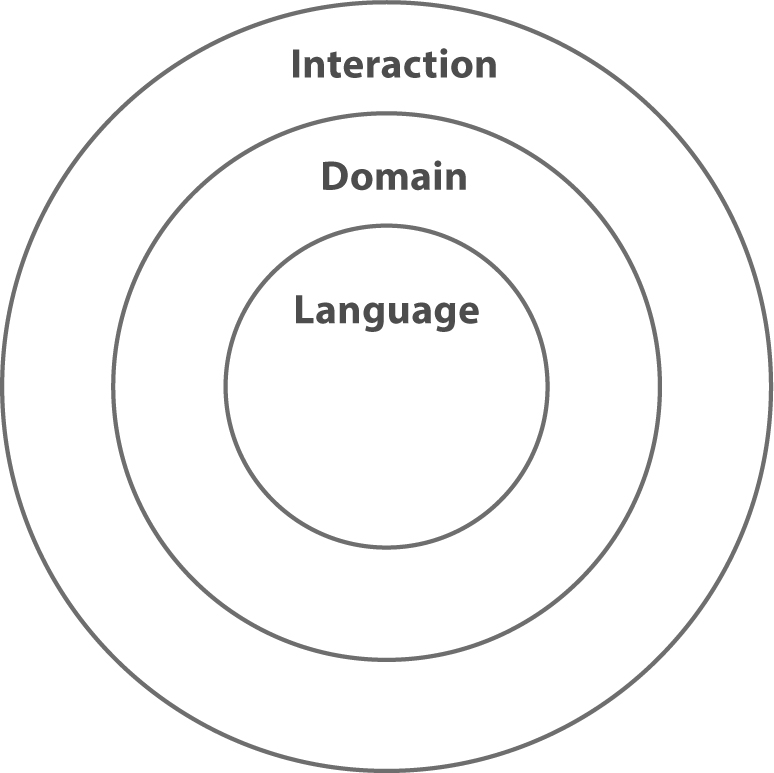
Rules of onion architecture
- Interaction with the world is done exclusively in the interaction layer.
- Layers call in toward the center.
- Layers don’t know about layers outside of themselves.
Facilitating change and reuse
In one sense, software architecture is about facilitating changes. What changes do you want to make easy? If you can answer that question, you’re halfway to choosing an architecture.
We are examining the onion architecture, so we can ask, “What changes does the onion architecture make easy?”
The onion architecture makes it easy to change the interaction layer. It makes it easy to reuse the domain layer.
The onion architecture lets you change the interaction layer easily. The interaction layer is at the top, which we’ve seen is easiest to change. Since the domain layer knows nothing about databases or web requests, we can easily change the database or use a different service protocol. We can also use the calculations in the domain layer with no database or service at all. This is the change that the architecture makes easy:

This is an important point, so we should restate it: External services, such as databases and API calls, are easiest to change in this architecture. They are only referred to by the top-most layer. Everything in the domain layer is easily tested because it makes no reference to external services. The onion architecture emphasizes the value of good domain models over the choice of other infrastructure.
In the typical architecture, domain rules do call out to the database. But in an onion architecture, that’s not possible. In the onion architecture, the same work happens, just with a different call graph arrangement. Let’s look at an example: a web service to calculate the total cost of a shopping cart. A web request is made to /cart/cost/123, where 123 is the cart’s ID number. The ID number can be used to fetch the cart from the database.

Let’s compare the two architectures:

In the typical architecture, the layers are clearly stacked. A web request is routed to a handler. The handler accesses the database. Then it returns the response to the top-most layer, which sends it back to the client.
In this architecture, the domain rule for calculating the total for a cart fetches from the database and sums the total. It is not a calculation, since it fetches from the database.
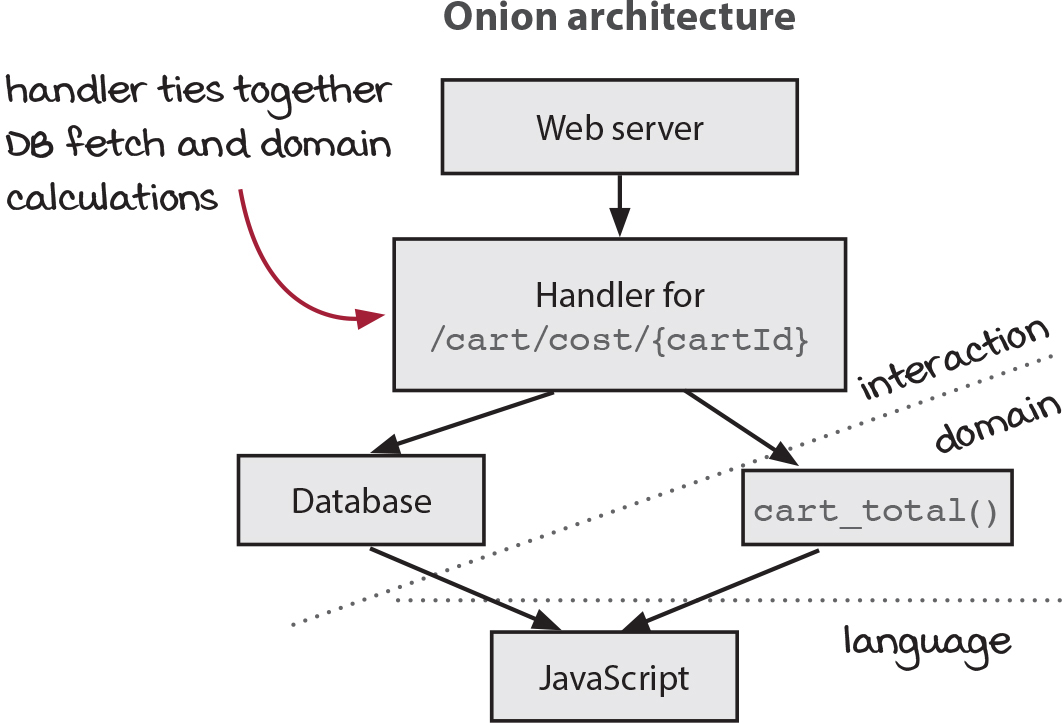
In the onion architecture, we have to turn our heads to see the layers since the dividing line is skewed. The web server, handler, and database all belong in the interaction layer. cart_total() is a calculation that describes how to sum the prices of the cart into a total. It does not know where the cart comes from (from the database or somewhere else). The web handler’s job is to provide the cart by fetching it from the database. Thus, the same work is done, but in different layers. The fetching is done in the interaction layer and the summing in the domain layer.

That’s a great question. The short answer is that you can always make your domain out of calculations. We spent a lot of time in part 1 showing how to do this. Extract calculations from actions. The calculations and the actions become simpler, to the point where the lower-level actions have very little logic. Then, as we’ve shown in this chapter, the higher-level action ties together the actions and the domain calculations.
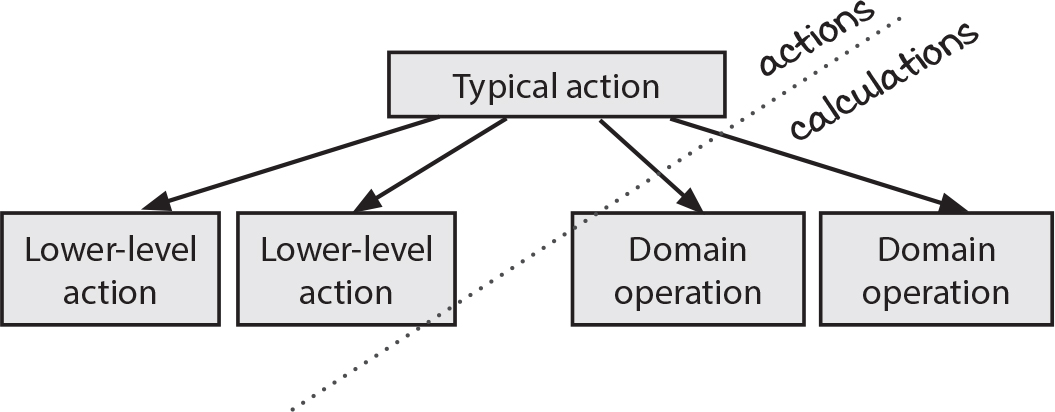
The long answer is more complicated. The truth is, it depends. There are two factors you need to think about to figure out whether a particular domain rule should be a calculation or an action:
- Examine the terms used to place the rule in a layer.
- Analyze readability and awkwardness.
Let’s look at these two factors on the following pages.
Examine the terms used to place the rule in a layer
We often think of all of the important logic of our program as a domain rule (sometimes it’s also called a business rule). However, not all of the logic is about your domain. Usually, the terms your code uses help you decide if it’s a domain rule. For example, you might have code that chooses which database to use. If the new database has an image for the product, use it. Otherwise, try the old database. Note that this code involves two actions (reads from databases):
var image = newImageDB.getImage('123');
if(image === undefined)
image = oldImageDB.getImage('123');
Even though it’s vitally important to your business, this isn’t really a domain rule. It’s not phrased in domain terms. The terms of the domain are product, image, price, discount, and so on. Database doesn’t really describe the domain; new and old database even less so.
Domain rules are phrased in domain terms. Look to the terms in the code to know if it’s a domain rule or if it belongs in the interaction layer.
This code is a technical detail to deal with the reality that some of your product images haven’t been migrated to the new database. We need to be careful that we don’t confuse this logic for a domain rule. This code squarely belongs in the interaction layer. It clearly deals with interacting with a changing world.
Another example of this is the logic for retrying failed web requests. Let’s say you have some code that retries multiple times if a web request fails:
function getWithRetries(url, retriesLeft, success, error) {
if(retriesLeft <= 0)
error('No more retries');
else ajaxGet(url, success, function(e) {
getWithRetries(url, retriesLeft - 1, success, error);
});
}
This also is not a business rule—even though retrying is important to the business. It is not phrased in domain terms. The e-commerce domain is not about AJAX requests. This is just some logic for dealing with the difficulties of unreliable network connections. As such, it belongs in the interaction layer.
Analyze readability and awkwardness
Okay, we’re getting real here. Let’s be really clear: Sometimes the benefits of a particular paradigm are not worth the cost. This includes choosing to implement parts of your domain as calculations. Even though it’s totally possible to implement your domain entirely as calculations, we have to consider that sometimes, in a particular context, an action is more readable than the equivalent calculation.
Readability depends on quite a few factors. Here are some major ones:
- The language you are writing in
- The libraries you are using
- Your existing legacy code and code style
- What your programmers are accustomed to
The image of the onion architecture we’ve seen here is an idealized view of a real system. People can easily tie themselves in knots trying to reach that ideal of 100% purity of the onion architecture vision. However, nothing is perfect. Part of your role as architect is to trade off between conformance to the architecture diagram and real-world concerns.
Code readability
While functional code is usually very readable, occasionally the programming language makes a nonfunctional implementation many times clearer. Be on the lookout for those times. For short-term clarity, it may be best to adopt the nonfunctional way. However, be on the lookout for a clear and readable way to cleanly separate the domain layer calculations from the interaction layer actions, usually by extracting calculations.
Development speed
Sometimes we need features to get out the door faster than we would like for business reasons. Rush jobs are never ideal, and many compromises are made when rushed. Be ready to clean up the code later to conform to the architecture. You can use the standard skills we’ve learned throughout the book: extracting calculations, converting to chains of functional tools, and manipulating timelines.
System performance
We often make compromises for system performance. For instance, mutable data is undoubtedly faster than immutable data. Be sure to isolate these compromises. Better still, consider the optimization to be part of the interaction layer and see how the calculations in the domain layer can be reused in a speedier way. We saw an example of this on page 52 where we optimized email generation by fetching fewer from the database at a time. The domain calculations didn’t change at all.
Applying a new architecture is always difficult. As your team’s skills improve, it will become easier to apply the architecture the first time in a readable way.
This is a good question. It’s a scenario you might run into. Let’s say you need to make a report of all the products that sold last year. You write a function that takes the products and generates the report:
function generateReport(products) {
return reduce(products, "", function(report, product) {
return report + product.name + " " + product.price + " ";
});
}
var productsLastYear = db.fetchProducts('last year');
var reportLastYear = generateReport(productsLastYear);

All is good and functional. But then a new requirement comes in and the report needs to change. You now need to include discounts in the report. Unfortunately, the product record only includes an optional discount identifier, not the whole discount record. That discount record needs to also be fetched from the database:
{
name: "shoes",
price: 3.99,
discountID: '23111' ❶
}
❶ product with discountID
{
name: "watch",
price: 223.43,
discountID: null ❶
}
❶ product without discountID
The easiest thing to do is to fetch the discount given the ID in the callback to reduce. But that would make generateReport() an action. You need to do the actions at the top level—the same level as the code to fetch the products from the DB.
function generateReport(products) {
return reduce(products, "", function(report, product) {
return report + product.name + " " + product.price + " ";
});
}
var productsLastYear = db.fetchProducts('last year');
var productsWithDiscounts = map(productsLastYear, function(product) { ❶
if(!product.discountID)
return product;
return objectSet(product, 'discount', db.fetchDiscount(product.discountID));
});
var reportLastYear = generateReport(productsWithDiscounts);
❶ augment the product at the top level
Remember, it is always possible to build your domain out of calculations and cleanly separate the interaction layer from the domain layer.
![]() It’s your turn
It’s your turn
We are doing some work on public library software that tracks who has checked out what book. Write an I, D, or L next to the following pieces of functionality to indicate whether they go in the interaction layer, domain layer, or language layer.
- A string processing library you’ve imported
- Routines for querying a user record from the database
- Accessing the Library of Congress API
- Routines to determine which shelf a book is on given its topic
- Routines to calculate the library fines due given a list of checked out books
- Routine for storing a new address for a patron
- The Lodash JavaScript library
- Routines for displaying the checkout screen to a library patron
Key
- I Interaction layer
- D Domain layer
- L Language layer
![]() Answer
Answer
1. L, 2. I, 3. I, 4. D, 5. D, 6. I, 7. L, 8. I.
Conclusion
In this chapter, we got a high-level perspective on two architectural patterns: reactive architecture and onion architecture. Reactive architecture is a way to fundamentally reorient the way actions are sequenced so that you specify what actions happen in response to another action. Onion architecture is a pattern that occurs naturally when you apply functional programming practices. It’s a very useful perspective because it shows up at every level of our code.
Summary
- Reactive architecture flips the way we sequence actions. It goes from “Do X, do Y” to “When X, then do Y.”
- Reactive architecture, taken to its extreme, organizes actions and calculations into pipelines. The pipelines are compositions of simple actions that happen in sequence.
- We can create first-class mutable state that lets us control the read and write operations. One example is the ValueCell, which takes inspiration from spreadsheets and lets us implement a reactive pipeline.
- The onion architecture, in broad strokes, divides software into three layers: interaction, domain, and language.
- The outer interaction layer holds the actions of the software. It orchestrates the actions with calls to the domain layer.
- The domain layer contains the domain logic and operations of your software, including business rules. This layer is exclusively comprised of calculations.
- The language layer is the language plus utility libraries that your software is built with.
- The onion architecture is fractal. It can be found at every level of abstraction in your actions.
Up next…
We’ve just finished part 2. In the next chapter, we will conclude the journey with a look at what we’ve learned and where you can go in the future to learn more.