
Chapter 2. The road to HTTP/2
- Examining the performance problems in HTTP/1.1
- Understanding the workarounds for HTTP/1.1 performance issues
- Investigating real-world examples of HTTP/1 problems
- SPDY and how it improved HTTP/1
- How SPDY was standardized into HTTP/2
- How web performance changes under HTTP/2
Why do we need HTTP/2? The web works fine under HTTP/1, doesn’t it? What is HTTP/2 anyway? In this chapter, I answer these questions with real-world examples and show why HTTP/2 is not only necessary, but also well overdue.
HTTP/1.1 is what most of the internet is built upon and has been functioning reasonably well for a 20-year-old technology. During that time, however, web use has exploded, and we’ve moved from simple static websites to fully interactive pages that cover online banking, shopping, booking holidays, watching media, socializing, and nearly every other aspect of our lives.
Internet availability and speed are increasing with technologies such as broadband and fiber for offices and homes, which means that speeds are many times better than the old dial-up speeds that users had to deal with when the internet was launched. Even mobile has seen technologies such as 3G and 4G bring broadband-level speeds on the move at reasonable, consumer-level prices.
Although the increase in download speeds has been impressive, the need for faster speeds has outpaced this increase. Broadband speeds will probably continue to increase for some time, but other limitations can’t be fixed as easily. As you shall see, latency is a key factor in browsing the web, and latency is fundamentally limited by the speed of light—a universal constant that physics says can’t increase.
2.1. HTTP/1.1 and the current World Wide Web
In chapter 1, you learned that HTTP was a request-and-response protocol originally designed for requesting a single item of plain-text content and that ended the connection upon completion. HTTP/1.0 introduced other media types, such as allowing images on a web page, and HTTP/1.1 ensured that the connection wasn’t closed by default (on the assumption that the web page would need more requests).
These improvements were good, but the internet has changed considerably since the last revision of HTTP (HTTP/1.1 in 1997, though the formal spec was clarified a few times and is being clarified again at the time of this writing, as mentioned in chapter 1). The HTTP Archive’s trends site at https://httparchive.org/reports/state-of-the-web allows you to see the growth of websites in the past eight years, as shown in figure 2.1. Ignore the slight dip around May 2017, which was due to measurement issues at HTTP Archive.[1]
Figure 2.1. Average size of websites 2010–2018[4]
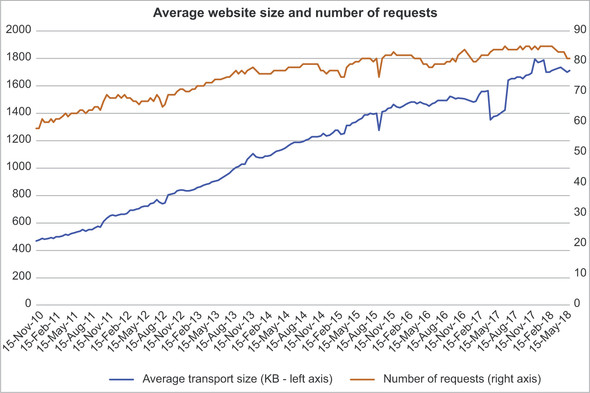
As you can see, the average website requests 80 to 90 resources and downloads nearly 1.8 MB of data—the amount of data transported across the network, including text resources compressed with gzip or similar applications. Uncompressed websites are now more than 3 MB, which causes other issues for constrained devices such as mobile.
There is a wide variation in that average, though. Looking at the Alexa Top 10 websites[2] in the United States, for example, you see the results shown in table 2.1.
Table 2.1. The top 10 websites in the United States ordered by popularity
|
Popularity |
Site |
Number of requests |
Size |
|---|---|---|---|
| 1 | https://www.google.com | 17 | 0.4 MB |
| 2 | https://www.youtube.com | 75 | 1.6 MB |
| 3 | https://www.facebook.com | 172 | 2.2 MB |
| 4 | https://www.reddit.com | 102 | 1.0 MB |
| 5 | https://www.amazon.com | 136 | 4.46 MB |
| 6 | https://www.yahoo.com | 240 | 3.8 MB |
| 7 | https://www.wikipedia.org | 7 | 0.06 MB |
| 8 | https://www.twitter.com | 117 | 4.2 MB |
| 9 | https://www.ebay.com | 160 | 1.5 MB |
| 10 | https://www.netflix.com | 44 | 1.1 MB |
The table shows that some websites (such as Wikipedia and Google) are hugely optimized and require few resources, but others load hundreds of resources and many megabytes of data. Therefore, looking at the average website or even the value of these average stats has been questioned before.[3] Regardless, it’s clear that the trend is for an increasing amount of data across an increasing number of resources. The growth of websites is driven primarily by becoming more media-rich, with images and videos being the norm on most websites. Additionally, websites are becoming more complex, with multiple frameworks and dependencies needed to display their content correctly.
Web pages started out as static pages, but as the web became more interactive, web pages started to be generated dynamically on the server side, such as Common Gateway Interface (CGI) or Java Servlet/Java Server Pages (JSPs). The next stage moved from full pages generated server-side to basic HTML pages supplemented by AJAX (Asynchronous JavaScript and XML) calls made from client-side JavaScript. These AJAX calls make extra requests to the web server to allow the contents of the web page to change without necessitating a full page reload or requiring the base image to be generated dynamically server-side. The simplest way to understand this is to look at the change in web search. In the early days of the web, before the advent of search engines, directories of websites and pages were the primary ways of finding information on the web, and they were static and updated only occasionally. Then the first search engines arrived, allowing users to submit a search form and get the results back from the server (dynamic pages generated server-side). Nowadays, most search sites make suggestions in a drop-down menu as you type before you even click Search. Google went one step further by showing results as users typed (though it reversed that function in the summer of 2017, as more searches moved to mobile, where this functionality made less sense).
All sorts of web pages other than search engines also make heavy use of AJAX requests, from social media sites that load new posts to news websites that update their home pages as news comes in. All these extra media and AJAX requests allow websites to be more interesting web applications. The HTTP protocol wasn’t designed with this huge increase in resources in mind, however, and the protocol has some fundamental performance problems in its simple design.
2.1.1. HTTP/1.1’s fundamental performance problem
Imagine a simple web page with some text and two images. Suppose that a request takes 50 milliseconds (ms) to travel across the internet to the web server and that the website is static, so the web server picks the file up from the file server and sends it back—say, in 10 ms. Similarly, the web browser takes 10 ms to process the image and send the next request. These figures are hypotheticals; if you have a content management system (CMS) that creates pages on the fly (WordPress runs PHP to process a page, for example), the 10 ms server time may not be accurate, depending on what processing is happening on the server and/or database. Additionally, images can be large and take longer to send than an HTML page. We’ll look at real examples later in this chapter, but for this simple example, the flow under HTTP would look like figure 2.2.
Figure 2.2. Request–response flow over HTTP for a basic example website
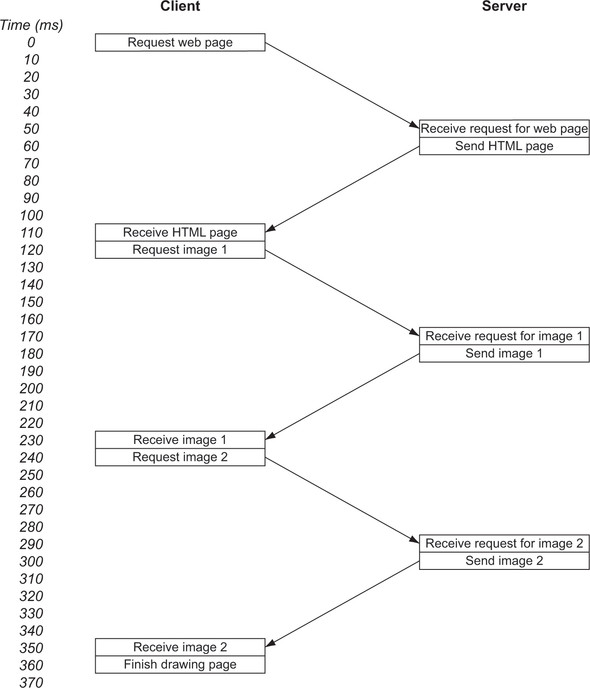
The boxes represent processing at the client or server end, and the arrows represent network traffic. What’s immediately apparent in this hypothetical example is how much time is spent sending messages back and forth. Of the 360 ms needed to draw the complete page, only 60 ms was spent processing the requests at the client or browser side. A total 300 ms, or more than 80% of the time, was spent waiting for messages to travel across the internet. During this time, neither the web browser nor the web server does much in this example; this time is wasted and is a major problem with the HTTP protocol. At the 120 ms mark, after the browser has asked for image 1, it knows that it needs image 2, but waits for the connection to be free before sending the request for it, which doesn’t happen until the 240 ms mark. This process is inefficient, but there are ways around it, as you’ll see later. Most browsers open multiple connections, for example. The point is that the basic HTTP protocol is quite inefficient.
Most websites aren’t made up of only two images, and the performance issues in figure 2.2 increase with the number of assets that need to be downloaded—particularly for smaller assets with a small amount of processing on either side relative to the network request and response time.
One of the biggest problems of the modern internet is latency rather than bandwidth. Latency measures how long it takes to send a single message to the server, whereas bandwidth measures how much a user can download in those messages. Newer technologies increase bandwidth all the time (which helps address the increase in the size of websites), but latency isn’t improving (which prevents the number of requests from increasing). Latency is restricted by physics (the speed of light). Data being transmitted through fiber-optic cables is traveling pretty close to the speed of light already; there’s only a little to be gained here, no matter how much the technology improves.
Mike Belshe of Google did some experiments[5] that show we’re reaching the point of diminishing returns for increasing bandwidth. We may now be able to stream high-definition television, but our web surfing hasn’t gotten faster at the same rate, and websites often take several seconds to load even on a fast internet connection. The internet can’t continue to increase at the rate it has without a solution for the fundamental performance issues of HTTP/1.1: too much time is wasted in sending and receiving even small HTTP messages.
2.1.2. Pipelining for HTTP/1.1
As stated in chapter 1, HTTP/1.1 tried to introduce pipelining, which allows concurrent requests to be sent before responses are received so that requests can be sent in parallel. The initial HTML still needs to be requested separately, but when the browser sees that it needs two images, it can request them one after the other. As shown in figure 2.3, pipelining shaves off 100 ms, or a third of the time in this simple, hypothetical example.
Figure 2.3. HTTP with pipelining for a basic example website
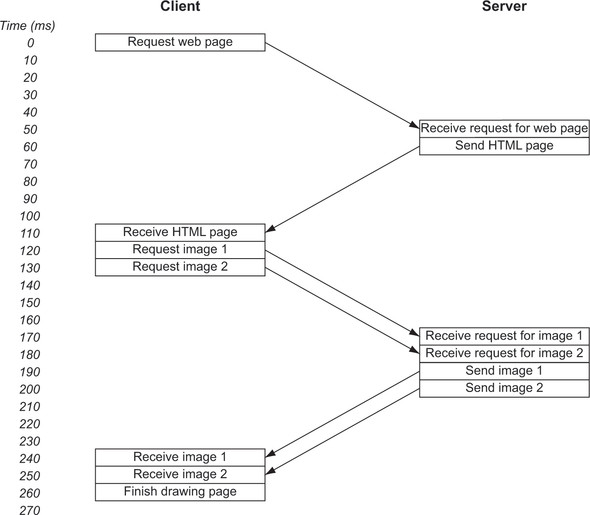
Pipelining should have brought huge improvements to HTTP performance, but for many reasons, it was difficult to implement, easy to break, and not well supported by web browsers or web servers.[6] As a result, it’s rarely used. None of the main web browsers uses pipelining, for example.[7]
Even if pipelining were better supported, it still requires responses to be returned in the order in which they were requested. If Image 2 is available, but Image 1 has to be fetched from another server, the Image 2 response waits, even though it should be possible to send this file immediately. This problem is known as head-of-line (HOL) blocking and is common in other networking protocols as well as HTTP. I discuss the TCP HOL blocking issue in chapter 9.
2.1.3. Waterfall diagrams for web performance measurement
The flows of requests and responses shown in figures 2.2 and 2.3 are often shown as waterfall diagrams, with assets on the left and increasing time on the right. These diagrams are easier to read than the flow diagrams used in figures 2.2 and 2.3 for large numbers of resources. Figure 2.4 shows a waterfall diagram for our hypothetical example site, and figure 2.5 shows the same site when pipelining is used.
Figure 2.4. Waterfall diagram of example website

Figure 2.5. Waterfall diagram of example website with pipelining

In both examples, the first vertical line represents when the initial page can be drawn (known as first paint time or start render), and the second vertical line shows when the page is finished. Browsers often try to draw the page before the images have been downloaded, and the images are filled in later, so images often sit between these two times. These examples are simple, but they can get complex, as I show you in some real-life examples later in this chapter.
Various tools, including WebPagetest[8] and web-browser developer tools (introduced briefly at the end of chapter 1), generate waterfall diagrams, which are important to understand when reviewing web performance. Most of these tools break the total time for each asset into components such as Domain Name Service (DNS) lookup and TCP connection time, as shown in figure 2.6.
Figure 2.6. Waterfall diagram from webpagetest.org
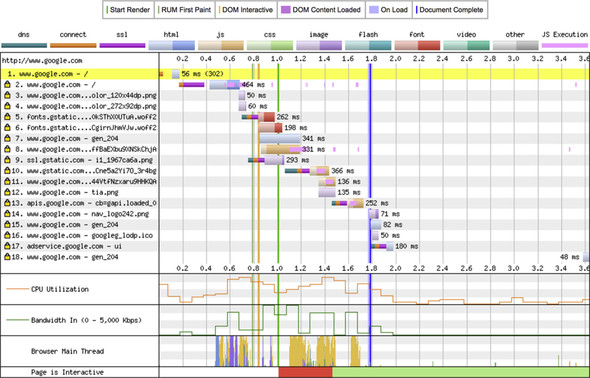
This diagram provides a lot more information than simple waterfall diagrams do. It breaks each request into several parts, including
- The DNS lookup
- The network connection time
- The HTTPS (or SSL) negotiation time
- The resource requested (and also splits the resource load into two pieces, with the lighter color for the request and the darker color for the response download)
- Various vertical lines for the various stages in loading the page
- Other graphs that show CPU use, network bandwidth, and what the browser’s main thread is working on
All this information is useful for analyzing the performance of a website. I make heavy use of waterfall diagrams throughout this book to explain the concepts.
2.2. Workarounds for HTTP/1.1 performance issues
As stated earlier, HTTP/1.1 isn’t an efficient protocol because it blocks on a send and waits for a response. It is, in effect, synchronous; you can’t move on to another HTTP request until the current request is finished. If the network or the server is slow, HTTP performs worse. As HTTP is intended primarily to request resources from a server that’s often far from the client, network slowness is a fact of life for HTTP. For the initial use case of HTTP (a single HTML document), this slowness wasn’t much of a problem. But as web pages grew more and more complex, with more and more resources required to render them properly, slowness became a problem.
Solutions for slow websites led to a whole web performance optimization industry, with many books and tutorials on how to improve web performance being published. Although overcoming the problems of HTTP/1.1 wasn’t the only performance optimization, it was a large part of this industry. Over time, various tips, tricks, and hacks have been created to overcome the performance limitations of HTTP/1.1, which fall into the following two categories:
- Use multiple HTTP connections.
- Make fewer but potentially larger HTTP requests.
Other performance techniques, which have less to do with the HTTP protocol, involve ensuring that the user is requesting the resources in the optimal manner (such as requesting critical CSS first), reducing the amount downloaded (compression and responsive images), and reducing the work on the browser (more efficient CSS or JavaScript). These techniques are mostly beyond the scope of this book, though I return to some of them in chapter 6. The Manning book Web Performance in Action, by Jeremy Wagner,[9] is an excellent resource for learning more about these techniques.
2.2.1. Use multiple HTTP connections
One of the easiest ways to get around the blocking issue of HTTP/1.1 is to open more connections, allowing parallelization to have multiple HTTP requests on the go. Additionally, unlike with pipelining, no HOL blocking occurs, as each HTTP connection works independently of the others. Most browsers open six connections per domain for this reason.
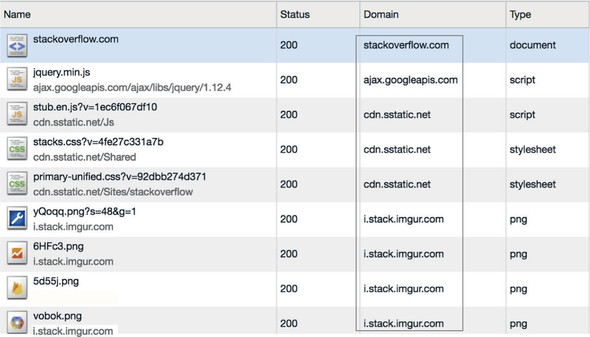
To increase this limit of six further, many websites serve static assets such as images, CSS, and JavaScript from subdomains (such as static.example.com), allowing web browsers to open a further six connections for each new domain. This technique is known as domain sharding (not to be confused with database sharding by those readers who come from a nonweb background, though the performance reasons are similar). Domain sharding can also be handy for reasons other than increasing parallelization, such as reducing HTTP headers such as cookies (see section 2.3). Often, these shared domains are hosted on the same server. Sharing the same resources but using different domain names fools the browser into thinking that the server is separate. Figure 2.7 shows that stackoverflow.com uses multiple domains: loading JQuery from a Google domain, scripts and stylesheets from cdn.static.net, and images from i.stack.imgur.com.
Figure 2.7. Multiple domains for stackoverflow.com
Although using multiple HTTP connections sounds like a simple fix to improve performance, it isn’t without downsides. There are additional overheads for both the client and server when multiple HTTP connections are used: starting a TCP connection takes time, and maintaining the connection requires extra memory and processing.
The main issue with multiple HTTP connections, however, is significant inefficiencies with the underlying TCP protocol. TCP is a guaranteed protocol that sends packets with a unique sequence number and rerequests any packets that got lost on the way by checking for missing sequence numbers. TCP requires a three-way handshake to set up, as shown in figure 2.8.
Figure 2.8. TCP three-way handshake
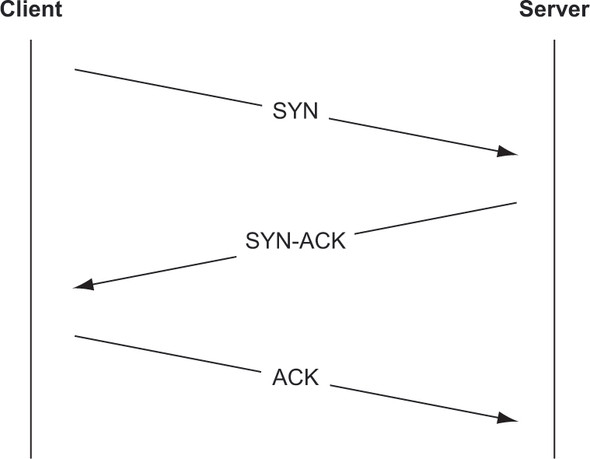
I’ll explain these steps in detail:
- The client sends a synchronization (SYN) message that tells the server the sequence number it should expect all future TCP packets from this request to be based on.
- The server acknowledges the sequence numbers from the client and sends its own synchronization request, telling the client what sequence numbers it will use for its messages. Both messages are combined into a single SYN-ACK message.
- Finally, the client acknowledges the server sequence numbers with an ACK message.
This process adds 3 network trips (or 1.5 round trips) before you send a single HTTP request!
In addition, TCP starts cautiously, with a small number of packets sent before acknowledgement. The congestion window (CWND) gradually increases over time as the connection is shown to be able to handle larger sizes without losing packets. The size of the TCP congestion window is controlled by the TCP slow-start algorithm. As TCP is a guaranteed protocol that doesn’t want to overload the network, TCP packets in the CWND must be acknowledged before more packets can be sent, using increments of the sequence numbers set up in the three-way handshake. Therefore, with a small CWND, it may take several TCP acknowledgements to send the full HTTP request messages. HTTP responses, which are often much larger than HTTP requests, also suffer from the same congestion window constraints. As the TCP connection is used more, it increases the CWND and gets more efficient, but it always starts artificially throttled, even on the fastest, highest-bandwidth networks. I return to TCP in chapter 9, but for now, even this quick introduction should show that multiple TCP connections have a cost.
Finally, even without any issues with TCP setup and slow start, using multiple independent connections can result in bandwidth issues. If all the bandwidth is used, for example, the result can be TCP timeouts and retransmissions on other connections. There’s no concept of prioritization between the traffic on those independent connections to use the available bandwidth in the most efficient manner.
When the TCP connection has been made, secure websites require the setup of HTTPS. This setup can be minimized on subsequent connections by reusing many of the parameters used in the main connection rather than starting from scratch, but the process still takes further network trips, and, therefore, time. I won’t discuss the HTTPS handshake in detail now, but we’ll examine it in more detail in chapter 4.
Therefore, it’s inefficient, at a TCP and HTTPS level, to open multiple connections, even if doing so is a good optimization at an HTTP level. The solution for the latency problems of HTTP/1.1 requires multiple extra requests and responses; therefore, the solution is prone to the very latency problems it’s supposed to resolve!
Additionally, by the time these additional TCP connections have reached optimal TCP efficiency, it’s likely that the bulk of the web page will have loaded and the additional connections are no longer required. Even browsing to subsequent pages may not require many resources if the common elements are cached. Patrick McManus of Mozilla states that in Mozilla’s monitoring for HTTP/1, “74 percent of our active connections carry just a single transaction.” I present some real-life examples later in this chapter.
Multiple TCP connections, therefore, aren’t a great solution to the problems of HTTP/1, though they can improve performance when no better solution is available. Incidentally, this explains why browsers limit the number of connections to six per domain. Although it’s possible to increase this number (as some browsers allow you to), there are diminishing returns, given the overhead required for each connection.
2.2.2. Make fewer requests
The other common optimization technique is to make fewer requests, which involves reducing unnecessary requests (such as by caching assets in the browser) or requesting the same amount of data over fewer HTTP requests. The former method involves using HTTP caching headers, discussed briefly in chapter 1 and revisited in more detail in chapter 6. The latter method involves bundling assets into combined files.
For images, this bundling technique is known as spriting. If you have a lot of social media icons on your website, for example, you could use one file for each icon. But this method would lead to a lot of inefficient HTTP queuing, as the images will be small, so a relatively large proportion of the time needed to fetch them will be spent on the overheads of downloading them. Instead, you can bundle them into one large image file and then use CSS to pull out sections of the image to effectively re-create the individual images. Figure 2.9 shows one such sprite image used by TinyPNG, which has common icons in one file.
Figure 2.9. Sprite image for TinyPNG
For CSS and JavaScript, many websites concatenate multiple files so that fewer files are produced, though with the same amount of code in the combined files. This concatenation is often done while minimizing the CSS or JavaScript to remove whitespace, comments, and other unnecessary elements. Both of these methods produce performance benefits but require effort to set up.
Other techniques involve inlining the resources into other files. Critical CSS is often included directly in the HTML with <style> tags, for example. Or images can be included in CSS as inline Scalable Vector Graphic (SVG) instructions or base 64-encoded binary files, which saves additional HTTP requests.
The main downside to this solution is the complexity it introduces. Creating image sprites takes effort; it’s easier to serve images as separate files. Not all websites use a build step in which optimizations such as concatenating CSS files can be automated. If you use a Content Management System (CMS) for your website, it may not automatically concatenate JavaScript, or sprite images.
Another downside is the waste in these files. Some pages may be downloading large sprite image files and using only one or two of those images. It’s complicated to track how much of your sprite file is still used and when to trim it. You also have to rewrite all your CSS to load the images correctly from the right locations in the new sprite file. Similarly, JavaScript can become bloated and much larger than it needs to be if you concatenate too much and download a huge file even when you need only to use a small amount of it. This technique is inefficient in terms of both the network layer (particularly at the beginning, due to TCP slow start) and processing (as the web browser needs to process data it won’t use).
The final issue is caching. If you cache your sprite image for a long time (so that site visitors don’t download it too often) but then need to add an image, you have to make the browsers download the whole file again, even though the visitor may not need this image. You can use various techniques such as adding a version number to the filename or using a query parameter,[10] but these techniques are still wasteful. Similarly, on the CSS or JavaScript side, a single code change requires the whole concatenated file to be redownloaded.
2.2.3. HTTP/1 performance optimizations summary
Ultimately, HTTP/1 performance optimizations are hacks to get around a fundamental flaw in the HTTP protocol. It would be much better to fix this flaw at the protocol level to save everyone time and effort here, and that’s exactly what HTTP/2 aims to do.
2.3. Other issues with HTTP/1.1
HTTP/1.1 is a simple text-based protocol. This simplicity introduces problems. Although the bodies of HTTP messages can contain binary data (such as images in whatever format the client and server can agree on), the requests and the headers themselves must still be in text. Text format is great for humans but isn’t optimal for machines. Processing HTTP text messages can be complex and error-prone, which introduces security issues. Several attacks on HTTP have been based on injecting newline characters into HTTP headers, for example.[11]
The other issue with HTTP being a text format is that HTTP messages are larger than they need to be, due to not encoding data efficiently (such as representing the Date header as a number versus full human-readable text) and repeating headers. Again, for the initial use case of the web with single requests, this situation wasn’t much of a problem, but the increasing number of requests makes this situation quite inefficient. The use of HTTP headers has grown, which leads to a lot of repetition. Cookies, for example, are sent with every HTTP request to the domain, even if only the main page request requires cookies. Usually, static resources such as images, CSS, and JavaScript don’t need cookies. Domain sharding, as described earlier in this chapter, was brought in to allow extra connections, but it was also used to create so-called cookieless domains that wouldn’t need cookies sent to them for performance and security reasons. HTTP responses are also growing, and with security HTTP headers such as Content-Security-Policy producing extremely large HTTP headers, the deficiencies of the text-based protocol are becoming more apparent. With many websites being made up of 100 resources or more, large HTTP headers can add tens or hundreds of kilobytes of data transferred.
Performance limitations are only one aspect of HTTP/1.1 that could be improved. Other issues include the security and privacy issues of a plain-text protocol (addressed pretty successfully by wrapping HTTPS around it) and the lack of state (addressed less successfully by the addition of cookies). In chapter 10, I explore these issues more. To many, however, the performance issues are problems that aren’t easy to address without implementing workarounds that introduce their own issues.
2.4. Real-world examples
I’ve shown that HTTP/1.1 is inefficient for multiple requests, but how bad is that situation? Is it noticeable? Let’s look at a couple of real-world examples.
When I originally wrote this chapter, both of the example websites I used didn’t support HTTP/2. Both sites have since enabled it, but the lessons shown here are still relevant as examples of complex websites that suffer under HTTP/1.1, and many of the details discussed here are likely similar to those of other websites. HTTP/2 is gaining in popularity, and any site chosen as an example may be upgraded at some point. I prefer to use real, well-known sites to demonstrate the issues that HTTP/2 looks to solve rather than using artificial example websites created purely to prove a point, so I’ve kept the two example websites despite the fact that they’re now on HTTP/2. The sites are less important than the concepts they show.
To repeat these tests at webpagetest.org, you can disable HTTP/2 by specifying --disable-http2 (Advanced Settings > Chrome > Command-Line Options). There are similar options if you’re using Firefox as your browser.[a] These are also helpful ways to test your own HTTP/2 performance changes after you go live with HTTP/2.
2.4.1. Example website 1: amazon.com
I’ve talked theoretically up until now, but now I look at real-world examples. If you take www.amazon.com and run it through www.webpagetest.org, you get the waterfall diagram shown in figure 2.10. This figure demonstrates many of the problems with HTTP/1.1:
- The first request is for the home page, which I’ve repeated in a larger format in figure 2.11.
It requires time to do a DNS lookup, time to connect, and time to do the SSL/TLS HTTPS negotiation before a single request
is sent. The time is small (slightly more than 0.1 second in figure 2.11), but it adds up. Not much can be done about that for this first request. This result is part and parcel of the way the web
works, as discussed in chapter 1, and although improvements to HTTPS ciphers and protocols might reduce the SSL time, the first request is going to be subject to these delays. The best you can do is ensure that your servers are responsive, and, ideally, close to
the users to keep round-trip times as low as possible. In chapter 3, I discuss content delivery networks (CDNs), which can help with this problem.
Figure 2.10. Part of the results for www.amazon.com
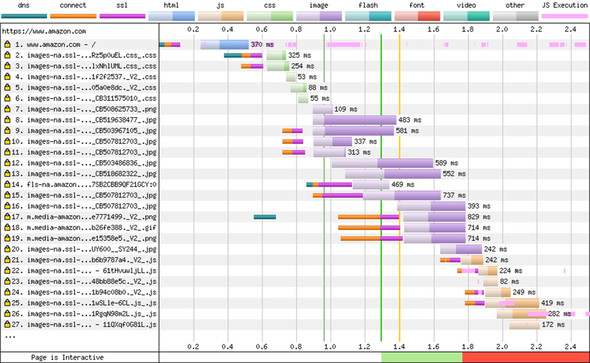
Figure 2.11. The first request for the home page
After this initial setup, a slight pause occurs. I can’t explain this pause, which could be due to slightly inaccurate timings or an issue in the Chrome browser. I didn’t see the same gap when repeating the test with Firefox. Then the first HTTP request is made (light color), and the HTML is downloaded (slightly darker color), parsed, and processed by the web browser.
- The HTML makes references to several CSS files, which are also downloaded, as shown in figure 2.12.
Figure 2.12. The five requests for the CSS files

- These CSS files are hosted on another domain (images-na.ssl-images-amazon.com), which has been sharded from the main domain for performance reasons, as discussed earlier. As this domain is separate, you need to start over from the beginning for the second request and do another DNS lookup, another network connection, and another HTTPS negotiation before using this domain to download the CSS. Although the setup time for request 1 is somewhat unavoidable, this second setup time is wasted; the domain name sharding is done to work around HTTP/1.1 performance issues. Note also that this CSS file appears early in the processing of the HTML page in request 1, causing request 2 to start slightly before the 0.4-second mark despite the fact that the HTML page doesn’t finish downloading until slightly after 0.5 of a second. The browser didn’t wait for the full HTML page to be downloaded and processed; instead, it requested the extra HTTP connection as soon as it saw the domain referenced (even if the resource itself doesn’t start to be downloaded until after the HTML has been fully received in this example due to the connection setup delays).
- The third request is for another CSS file on the same sharded domain. As HTTP/1.1 allows only a single request in flight at the same time, the browser creates another connection. You don’t need the DNS lookup this time (because you know the IP address for that domain from request 2), but you do need the costly TCP/IP connection setup and HTTPS negotiating time before you can request this CSS. Again, the only reason for this extra connection is to work around HTTP/1.1 performance issues.
- Next the browser requests three more CSS files, which are loaded over the two connections already established. Not shown in the diagram is why the browser didn’t request these other CSS files immediately, which would have necessitated creating even more connections and the costs associated with them. I looked at the Amazon source code, and there’s a <script> tag before these CSS files request that blocks the later requests until the script is processed, which explains why requests 4, 5, and 6 aren’t requested at the same time as requests 2 and 3. This point is an important one that I return to later: although HTTP/1.1 inefficiencies are a problem for the web and could be solved by improvements to HTTP (like those in HTTP/2), they’re far from being the only reasons for slow performance on the web.
- After the CSS has been dealt with in requests 2 to 6, the browser decides that the images are next, so it starts downloading
them, as shown in figure 2.13.
Figure 2.13. Image downloads
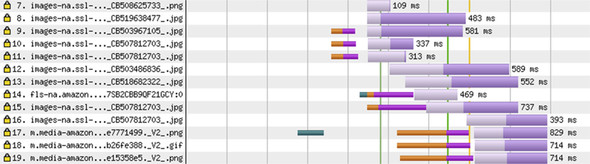
- The first .png file is in request 7, which is a sprite file of multiple images (not shown in figure 2.13), and another performance tweak that Amazon implemented. Next, some .jpg files are downloaded from request 8 onward.
- When two of these image requests are in flight, the browser needs to make more costly connections to allow other files to load in parallel in requests 9, 10, 11, and 15 and then again for new domains in requests 14, 17, 18, and 19.
- In some cases (requests 9, 10, and 11), the browser guessed that more connections are likely to be needed and set up the connections in advance, which is why the connect and SSL parts happen earlier and why it can request the images at the same time as requests 7 and 8.
- Amazon added a performance optimization to do a DNS prefetch[12] for m.media-amazon.com well before it needs it, though oddly not for fls-na.amazon.com. This is why the DNS lookup for request 17 happens at the 0.6 second mark, well before it’s needed. I return to this topic
in chapter 6.
The loading continues past these requests, but even looking at only these first few requests identifies problems with HTTP/1.1, so I won’t belabor the point by continuing through the whole site load.
Many connections are needed to prevent any queuing, and often, the time taken to make this connection doubles the time needed to download the asset. Web Page Test has a handy connection view[13] (shown in figure 2.14 for this same example).
Figure 2.14. Connection view of loading amazon.com

You can see that loading amazon.com requires 20 connections for the main site, ignoring the advertising resources, which add another 28 connections (not shown in figure 2.14). Although the first six images-na.ssl-images-amazon.com connections are fairly well used (connections 3–8), the other four connections for this domain (connections 9–12) are less well used; like many other connections (such as 15, 16, 17, 18, 19, and 20), they’re used to load only one or two resources, making the time needed to create that connection wasteful.
The reason why these four extra connections are opened for images-na.ssl-images-amazon.com (and why Chrome appears to break its limit of six connections per domain) is interesting and took a bit of investigation. Requests can be sent with credentials (which usually means cookies), but requests can also be sent without them and handled by Chrome over separate connections. For security reasons, due to how cross-origin requests are handled in the browser,[14] Amazon uses setAttribute ("crossorigin","anonymous") in some of these requests for JavaScript files, without credentials, which means that the existing connections aren’t used. Instead, more connections are created. The same isn’t necessary for direct JavaScript requests with the <script> tag in HTML. The workaround also isn’t needed for resources hosted on the main domain being loaded, which again shows that sharding can be inefficient at an HTTP level.
The Amazon example shows that even when a site is well optimized with the workarounds necessary to boost performance under HTTP/1.1, there is a still a performance penalty to using these performance workarounds. These performance workarounds are also complicated to set up. Not every site wants to manage multiple domains or sprite images or merge all their JavaScript (or CSS) into one file, and not every site has the resources of Amazon to create these optimizations or is even aware of them. Smaller sites are often much less optimized and therefore suffer the limitations of HTTP/1 even more.
2.4.2. Example website 2: imgur.com
What happens if you don’t make these optimizations? As an example, look at imgur.com. Because it’s an image sharing site, imgur.com loads a huge number of images on the home page, but doesn’t sprite them into single files. A subsection of the WebPagetest waterfall diagram is shown in figure 2.15.
Figure 2.15. Waterfall view of imgur.com
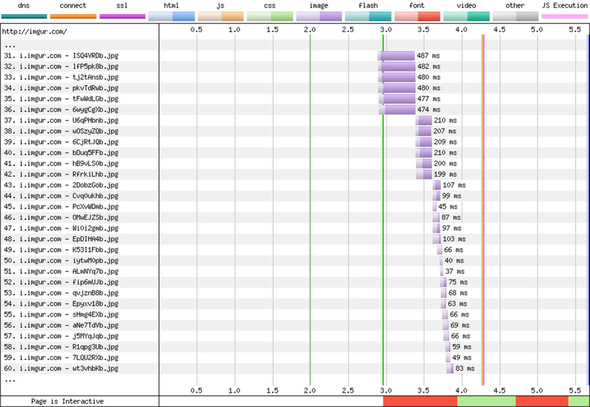
I skipped the first part of the page load (before request 31), which repeats a lot of the amazon.com example. What you see here is that the maximum six connections are used to load requests 31–36; the rest are queued. As each of those six requests finishes, another six can be fired off, followed by another six, which leads to the telltale waterfall shape that gives these charts their name. Note that the six resources are unrelated and could finish at different times (as they do farther down the waterfall chart), but if they’re similar size resources, it’s not unusual for them to finish at around the same time. This fact gives the illusion that the resources are related, but on the HTTP level, they’re not (though they share network bandwidth and go to the same server).
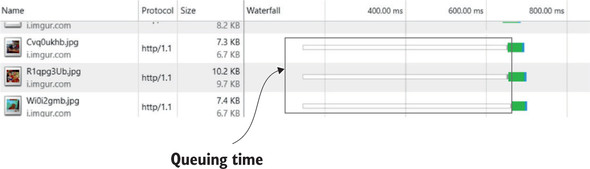
The waterfall diagram for Chrome, shown in figure 2.16, makes the problem more apparent, as it also measures the delay from when the resource could have been requested. As you can see, for later requests, a long delay occurs before the image is requested (highlighted by the rectangle), followed by a relatively short download time.
Figure 2.16. Chrome developer tools waterfall view of imgur.com
2.4.3. How much of a problem is this really?
Although this chapter identifies inefficiencies in HTTP, workarounds are available. These workarounds, however, take time, money, and understanding to implement and to maintain going forward, and they add their own performance problems. Developers aren’t cheap, and having them spend time working around an inefficient protocol is necessary but costly (not to mention the many sites that don’t realize the impact of poor performance on their traffic). Multiple studies show that slower websites lead to abandonment and to loss of visitors and sales.[15],[16]
You must also consider how serious this problem is in relation to other performance problems. There are any number of reasons why a website is slow, from the quality of the internet connection to the size of the website to the ridiculous amounts of JavaScript that some websites use, to the proliferation of poorly performing ads and tracking networks. Although being able to download resources quickly and efficiently is certainly one part of the problem, many websites would still be slow. Clearly, many websites are worried about this aspect of performance, which is why they implement the HTTP/1.1 workarounds, but many other sites don’t because of the complexity and understanding that these workarounds require.
The other problem is the limitations of these workarounds. These workarounds generate their own inefficiencies, but as websites continue to grow in both size and complexity, at some point even the workarounds will no longer work. Although browsers open six connections per domain and could increase this number, the overhead of doing so versus the gains is reaching the point of diminishing returns, which is why browsers limited the number of connections to six in the first place, even though site owners have tried to work around this limit with domain sharding.
Ultimately, each website is different, and each website owner or web developer needs to spend time analyzing the site’s own resource bottlenecks, using tools such as waterfall diagrams, to see whether the site is being badly affected by HTTP/1.1 performance problems.
2.5. Moving from HTTP/1.1 to HTTP/2
HTTP hadn’t really changed since 1999, when HTTP/1.1 came on the scene. The specification was clarified in the new Request for Comments (RFCs) published in 2014, but this specification was more a documentation exercise than any real change in the protocol. Work had started on an updated version (HTTP-NG), which would have been a complete redesign of how HTTP worked, but it was abandoned in 1999. The general feeling is that the change was overly complex, with no path to introduce it in the real world.
2.5.1. SPDY
In 2009, Mike Belshe and Robert Peon at Google announced that they were working on a new protocol called SPDY (pronounced “speedy” and not an acronym). They had been experimenting on this protocol in laboratory conditions and saw excellent results, with up to 64% improvement in page load times. The experiments were run on copies of the top 25 websites, not hypothetical websites that may not represent the real world.
SPDY was built on top of HTTP, but doesn’t fundamentally change the protocol, in much the same way that HTTPS wrapped around HTTP without changing its underlying use. The HTTP methods (GET, POST, and so on) and the concept of HTTP headers still exist in SDPY. SPDY worked at a lower level, and to web developers, server owners, and (crucially) users, the use of SPDY was almost transparent. Any HTTP request was simply converted to a SPDY request, sent to the server, and then converted back. This request looked like any other HTTP request to higher-level applications (such as JavaScript applications on the client side and those configuring web servers). Additionally, SPDY was implemented only over secure HTTP (HTTPS), which allowed the structure and format of the message to be hidden from all the internet plumbing that passes messages between client and server. All existing networks, routers, switches, and other infrastructure, therefore, could handle SPDY messages without any changes and without even knowing that they were handling SPDY messages rather than HTTP/1 messages. SPDY was essentially backward-compatible and could be introduced with minimal changes and risk, which is undoubtedly a big reason why it succeeded and HTTP-NG failed.
Whereas HTTP-NG tried to address multiple issues with HTTP/1, the main aim of SPDY was to tackle the performance limitations of HTTP/1.1. It introduced a few important concepts to deal with the limitations of HTTP/1.1:
- Multiplexed streams —Requests and responses used a single TCP connection and were broken into interleaved packets grouped into separate streams.
- Request prioritization —To avoid introducing new performance problems by sending all requests at the same time, the concept of prioritization of the requests was introduced.
- HTTP header compression —HTTP bodies had long been compressed, but now headers could be compressed too.
It wasn’t possible to introduce these features with the text-based request-and-response protocol that HTTP was up until then, so SPDY became a binary protocol. This change allowed the single connection to handle small messages, which together formed the larger HTTP messages, much the way that TCP itself breaks larger HTTP messages into many smaller TCP packets that are transparent to most HTTP implementations. SPDY implemented the concepts of TCP at the HTTP layer so that multiple HTTP messages could be in flight at the same time.
Additional advanced features such as server push allowed the server to tag on extra resources. If you requested the home page, server push could provide the CSS file needed to display it, in response to that request. This process saves the need to suffer the performance delay of the round trip asking for that CSS file and the complication and effort of inlining critical CSS.
Google was in the unique position of being in control of both a major browser (Chrome) and some of the most popular websites (such as www.google.com), so it could do much larger real-life experiments with the new protocol by implementing it at both ends of the connection. SPDY was released to Chrome in September 2010, and by January 2011, all Google services were SPDY-enabled[17]—an incredibly quick rollout by any measure.
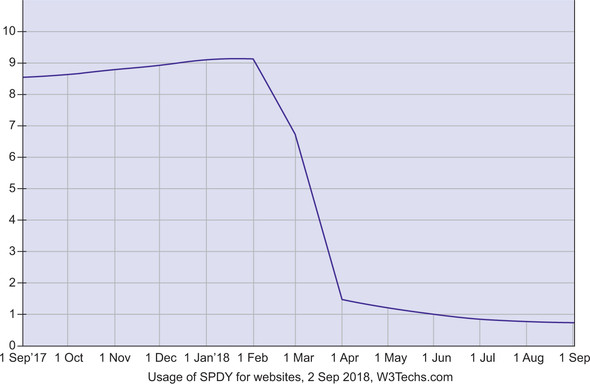
SPDY was an almost-instant success, with other browsers and servers quickly adding support. Firefox and Opera added support in 2012. On the server side, Jetty added support, followed by others, including Apache and nginx. The vast majority of websites that supported SPDY were on the latter two web servers. Websites that introduced SPDY (including Twitter, Facebook, and WordPress) saw the same performance gains as Google, with little downside apart from initial setup. SPDY reached up to 9.1% of all websites, according to w3techs.com,[18] though browsers have started removing support for it now that HTTP/2 is here. Since early 2018, use of SPDY has plummeted, as shown in figure 2.17.
Figure 2.17. SPDY support on websites has dropped since the launch of HTTP/2.
2.5.2. HTTP/2
SPDY proved that HTTP/1.1 could be improved, not in a theoretical manner, but with examples of it working on major sites in the real world. In 2012, the HTTP Working Group of the Internet Engineering Task Force (IETF) noted the success of SPDY and asked for proposals for the next version of HTTP.[19] SPDY was the natural basis for this next version, as it had been proved in the wild, though the working group explicitly avoided saying so, preferring to be open to any proposals (though some people dispute this position, as covered in chapter 10).
After a short period, during which other proposals were considered, SPDY formed the basis of HTTP/2 in the first draft, published in November 2012.[20] This draft was modified slightly over the next two years to improve it (particularly its use of streams and compression). I go into the technical details of the protocol in chapters 4, 5, 7, and 8, so I’m covering this topic lightly here.
By the end of 2014, the HTTP/2 specification was submitted as a proposed standard for the internet, and in May 2015, it was formally approved as RFC 7450.[21] Support followed quickly, especially because the specification was heavily based on SPDY, which many browsers and servers had already implemented. Firefox supported HTTP/2 from February 2015, and Chrome and Opera from March 2015. Internet Explorer 11, Edge, and Safari followed later in the year.
Web servers quickly added support, with many implementing the various versions as they went through standardization. LiteSpeed[22] and H2O[23] were some of the first web servers with support. By the end of 2015, the main three web servers used by the vast majority of internet users (Apache, IIS, and nginx) had implementations, though they were initially marked as experimental and not switched on by default.
As of September 2018, HTTP/2 is available on 30.1% of all websites, according to w3tech.com.[24] This reach is in large part due to content delivery networks and larger sites enabling HTTP/2, but it’s still impressive for a three-year-old technology. As you will see in chapter 3, enabling HTTP/2 on the server side currently requires a fair bit of effort; otherwise, use might be even higher.
The takeaway point is that HTTP/2 is here and is available. It has been proved in real life and has been shown to improve performance significantly precisely because it addresses the problems with HTTP/1.1 raised in this chapter.
2.6. What HTTP/2 means for web performance
You’ve seen the inherent performance problems with HTTP/1 and now have the solution with HTTP/2, but are all web performance problems solved with HTTP/2, and how much faster should owners expect their websites to be if they upgrade to HTTP/2?
2.6.1. Extreme example of the power of HTTP/2
Many examples show the performance improvements of HTTP/2. I have one on my site at https://www.tunetheweb.com/performance-test-360/. This page is available over HTTP 1.1, HTTP 1.1 over HTTPS, and HTTP/2 over HTTPS. As discussed in chapter 3, browsers support HTTP/2 only over HTTPS; hence, there’s no HTTP/2 without the HTTPS test. This test is based on a similar test at https://www.httpvshttps.com/ that excludes the HTTPS-without-HTTP/2 test and loads a web page with 360 images over the three technologies, using a bit of JavaScript to time the loads. The result is shown in figure 2.18.
Figure 2.18. HTTP versus HTTPS versus HTTP/2 performance test
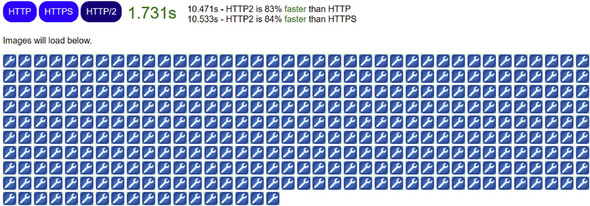
This test shows that the HTTP version took 10.471 seconds to load the page and all the images. The HTTPS version took about the same time at 10.533 seconds, showing that HTTPS doesn’t cause the performance penalty it once did and the difference is barely noticeable from plain-text HTTP. In fact, rerunning this test several times often showed HTTPS being marginally faster than HTTP, which makes no sense (because HTTPS involves extra processing), but this extra processing is within the margin of error for this test site.
The real surprise is HTTP/2, which loaded the site in 1.731 seconds—83% faster than the other two technologies! Looking at the waterfall diagrams shows the reason. Compare the HTTPS and HTTP/2 diagrams in figures 2.19 and 2.20.
Figure 2.19. Waterfall of HTTPS test. Ignore the highlighting of line 18 due to the 302 response.
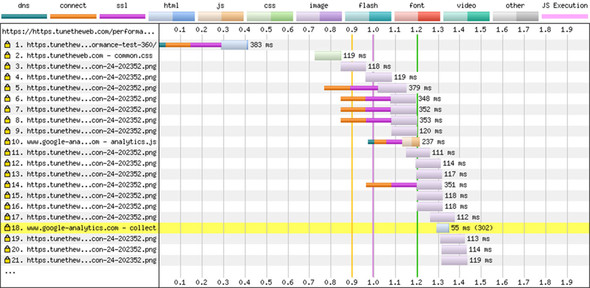
Under HTTPS, you see the familiar delay of setting up multiple connections and then loading the images in batches of six. Under HTTP/2, however, the images are requested together, so there’s no delay. For brevity’s sake, I’ve shown only the first 21 requests rather than all 360 requests, but this figure illustrates the massive performance benefits of HTTP/2 for loading this kind of site. Note also in figure 2.19 that after the maximum number of connections for the page are used, the browser chooses to load Google Analytics in request 10. That request is for a different domain that hasn’t reached its maximum connection limit. Figure 2.20 shows a much higher simultaneous-request limit, so many more of the images are requested at the beginning, and the Google Analytics request isn’t shown in the first 21 requests but farther down this waterfall chart.
Figure 2.20. Waterfall diagram of HTTP/2 test
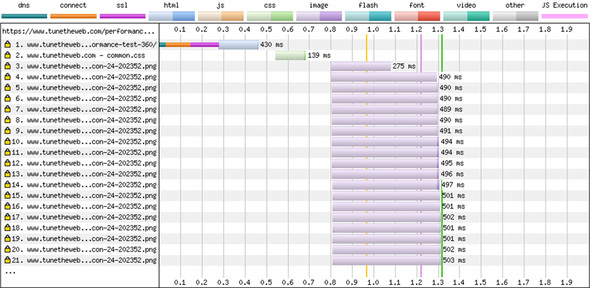
Astute readers may have noticed that the images take longer to download under HTTP/2: around 490 ms compared with around 115 ms under HTTP/1.1 (ignoring the first six, which took longer when you include connection setup time). Assets can appear to take longer to download under HTTP/2 because of the different way of measuring them. Waterfall diagrams typically measure from when the request is sent to when the response is received and may not measure queuing time. Taking request 16 as an example, under HTTP/1, this resource is requested at about the 1.2-second mark and is received 118 ms later, at approximately 1.318 ms. The browser, however, knew it needed the image after it processed the HTML and made the first request at 0.75 second, which is exactly when the HTTP/2 example requested it (not by coincidence!). Therefore, the 0.45-second delay isn’t accurately reflected in HTTP/1 waterfall diagrams, and arguably, the clock should start at the 0.75-second mark. As noted in section 2.4.2, Chrome’s waterfall diagram includes waiting time; so, it shows the true overall download time, which is longer than HTTP/2.
Requests can take longer under HTTP/2, however, due to bandwidth, client, or server limitations. The need to use multiple connections under HTTP/1 creates a natural queuing mechanism of six requests at the same time. HTTP/2 uses a single connection with streams, in theory removing that restriction, though implementations are free to add their own limitations. Apache, which I use to host this page, has a limit of 100 concurrent requests per connection by default, for example. Sending many requests at the same time leads to the requests sharing the available resources and taking longer to download. The images take progressively longer in figure 2.20 (from 282 ms in request line 4 to 301 ms in request line 25). Figure 2.21 shows the same results at lines 88–120. You can see that the image requests take up to 720 ms (six times as long as under HTTP/1). Also, when the 100-request limit is reached, a pause occurs until the first requests are downloaded; then the remaining resources are requested. This effect is identical to the waterfall effect due to HTTP/1 connection limitations but happens less and later due to the much-increased limits. Note also that during this pause, Google Analytics is requested as request 104. A similar thing happened during the pause in HTTP/1.1 in figure 2.19, but it happened much earlier, at request 10.
Figure 2.21. Delays and waterfalls under HTTP/2
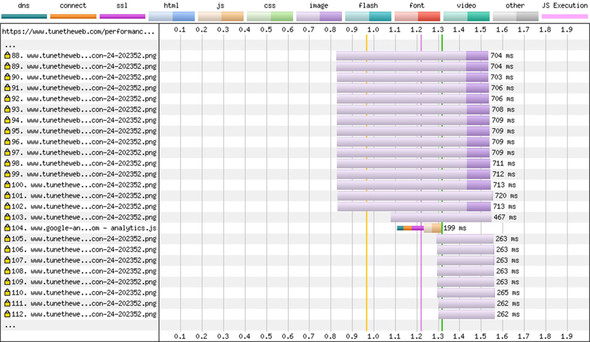
The important point that’s easy to miss when you’re looking at waterfall diagrams under HTTP/2 is that they intrinsically measure different things. Instead, you should look at the overall time, and here, HTTP/2 clearly wins in the overall page load time.
2.6.2. Setting expectations of HTTP/2 performance gains
The example in section 2.6.1 shows the enormous gains that HTTP/2 can give a website; 83% performance improvements are vey impressive. This example isn’t realistic, however, and most websites struggle to see anything near this result. This example illustrates the conditions under which HTTP/2 performs best (another reason why I prefer to use real, well-known websites in the examples in this book). Some websites may not see any performance improvement by switching to HTTP/2 if they have other performance problems, which means that the HTTP/1 deficiencies aren’t much of a problem.
There are two reasons why HTTP/2 may make little difference to some existing websites. The first reason is that the websites may be so tuned, using the workarounds discussed in section 2.2, that they see little slowness due to the problems inherent in HTTP/1. But even well-tuned sites still suffer some performance drawbacks from these techniques, not to mention the significant effort needed to use and maintain these performance techniques. In theory, HTTP/2 allows every website to be even better than a domain-sharded, concatenated website making great use of sprites and inline CSS, JavaScript, and images with zero effort as long as the server supports HTTP/2!
The other reason why HTTP/2 may not improve sites is if other performance problems far eclipse the issues due to HTTP/1. Many websites have massive print-quality images, which take a long time to download. Other websites load far too much JavaScript, which takes time to download (HTTP/2 may be able to help) and process (HTTP/2 won’t help). Websites that are slow even after loading or that suffer from jank (when the browser struggles to keep up with the user’s scrolling around the website) aren’t improved by HTTP/2, which looks only at the networking side of performance. Other, mostly edge cases also make HTTP/2 slower in certain instances of high packet loss, which I discuss in chapter 9.
Having said all that, I strongly believe that HTTP/2 will lead to more-performant websites and reduce the need to use some of the complicated workarounds that website owners have had to use up until now. At the same time, HTTP/2 advocates must set expectations as to what HTTP/2 can solve and what it can’t; otherwise, people will only be disappointed when they move their sites to HTTP/2 and don’t immediately see a huge performance increase. At this writing, we’re probably at the peak of inflated expectations (for those who are familiar with the Gartner hype cycle),[25] and the expectation that a new technology will solve all problems is common before reality sets in. Sites need to understand their own performance problems, and HTTP/1 bottlenecks are only one part of those performance problems. In my experience, however, typical websites will see good improvement from moving to HTTP/2, and it will be extremely rare (though not impossible) for HTTP/2 to be slower than HTTP/1. One example would be a bandwidth-bound website (such as a site with many print-quality images), which may be slower under HTTP/2 if the natural ordering, enforced by the limited number of connections in HTTP/1.1, resulted in critical resources being downloaded faster. One graphic-design company published an interesting example,[26] but even this example can be made faster under HTTP/2 with the right tuning, as discussed in chapter 7.
To return to real-world examples, I took a copy of Amazon’s website, altered all references to make them local references, loaded the copy over HTTP/1 and HTTP/2 (both over HTTPS), and measured the different load times with the typical results shown in table 2.2.
Table 2.2. Improvements HTTP/2 might give Amazon
|
Protocol |
Load time |
First byte |
Start render |
Visually complete |
Speed index |
|---|---|---|---|---|---|
| HTTP/1 | 2.616 | 0.409s | 1.492s | 2.900s | 1692 |
| HTTP/2 | 2.337 | 0.421s | 1.275s | 2.600s | 1317 |
| Difference | 11% | -3% | 15% | 10% | 22% |
This table introduces a few terms that are common in web performance circles:
- Load time is the time it takes for the page to send the onload event—typically, after all CSS and blocking JavaScript are loaded.
- First byte is how long it takes to get the first response from the website. Usually, this response is the first real response, ignoring any redirects.
- Start render is when the page starts painting. This metric is a key performance metric, as users are likely to give up on a website if it doesn’t give a visual update that it’s loading the website.
- Visually complete is when the page stops changing, often long after load time, if asynchronous JavaScript is still changing the page after the initial onload time.
- Speed index is a WebPagetest calculation that indicates the average time for each part of the web page to be loaded, in milliseconds.[27]
Most of these metrics show good improvement with HTTP/2. First-byte time has worsened slightly, but repeating the tests showed the opposite to be true for some tests, so this result looks to be within the margin of error.
I admit, however, that these improvements are somewhat artificial because I haven’t implemented the site exactly as Amazon did. I used only one domain (so no domain sharding occurred) and saved each asset as a static file rather than the dynamically generated content, as Amazon would do, which might be subject to other delays. Nonetheless, these limitations occurred in both the HTTP/1 and HTTP/2 versions of the test, so within these limitations, you can see clear improvements with HTTP/2.
Comparing the waterfall diagrams between the two loads in figures 2.22 and 2.23 shows the expected improvements under HTTP/2: no additional connections and less of a stepped waterfall load at the beginning, when many resources are needed.
Figure 2.22. Loading a copy of Amazon’s home page over HTTP/1
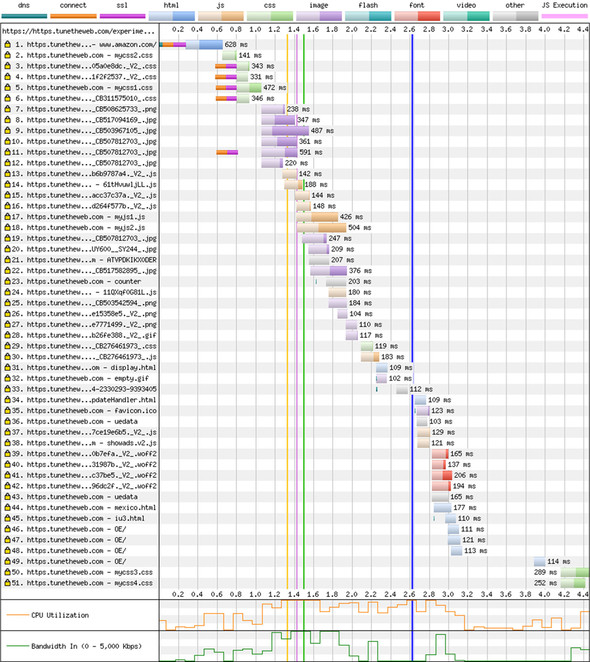
Figure 2.23. Loading a copy of amazon.com’s home page over HTTP/2
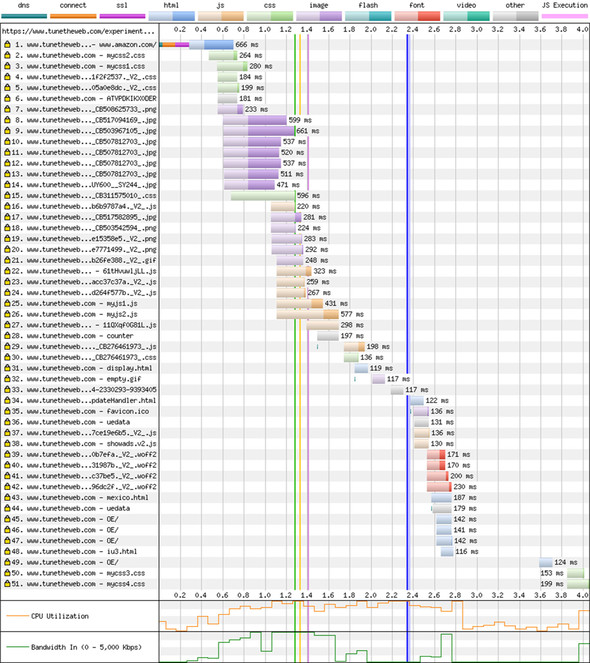
No code has been changed on the website between the two request types; this result is simply the improvement due to HTTP/2. There’s still a waterfall aspect to the loading of the site under HTTP/2 due to the dependent nature of web technologies: web pages load CSS, which loads images, for example. But less time is wasted setting up connections and queues, so the waterfall effect due to HTTP constraints is gone. The numbers may seem to be small, but a 22% improvement is a huge gain, especially considering that this improvement didn’t require any changes beyond the web server itself.
Sites that are truly optimized for HTTP/2 and that use some of the new features available within HTTP/2 (which I cover later in this book) should see much bigger improvements. At the moment, we have 20 years of experience in optimizing sites under HTTP/1 but almost no experience optimizing for HTTP/2.
I’m using Amazon as an example of a well-known website that (when I wrote this chapter) hadn’t yet moved to HTTP/2 and was highly (though not perfectly!) optimized for HTTP/1. To be clear, I’m not saying that Amazon is badly coded or not performant; I’m showing the performance improvements that HTTP/2 can potentially give a website immediately, and, perhaps more importantly, the effort that can be saved by not having to do the HTTP/1.1 workarounds to get great performance.
Since I originally wrote this chapter, Amazon has moved to HTTP/2, which has shown some similar results. The point, however, is to see Amazon as an example of a real-world, complicated website that has already implemented some HTTP/1 performance optimizations but still can improve dramatically with HTTP/2.
2.6.3. Performance workarounds for HTTP/1.1 as potential antipatterns
Because HTTP/2 fixed the performance problems in HTTP/1.1, in theory, there should be no need to deploy the performance workarounds discussed in this chapter anymore. In fact, many people believe that these workarounds are becoming antipatterns in the HTTP/2 world, because they could prevent you from getting the full benefits of HTTP/2. The benefits of a single TCP connection to load a website, for example, are negated if the website owner uses domain sharding and therefore forces several connections (though I discuss connection coalescing, which is designed to address this problem, in chapter 6). HTTP/2 makes it much simpler to create a performant website by default.
The reality is never that simple, though, and as I state in subsequent chapters (particularly chapter 6), it may be too soon to drop these techniques completely until HTTP/2 gets more bedded in. On the client side, some users will still be using HTTP/1.1 despite strong browser support. They may be using older browsers or connecting via a proxy that doesn’t yet support HTTP/2 (including antivirus scanners and corporate proxies).
Additionally, on both the client and server sides, implementations are still changing while people learn how best to use this new protocol. For 20 years after HTTP/1.1 was launched, a thriving web performance optimization industry grew, teaching developers how best to optimize their websites for the HTTP protocol. Although I hope that HTTP/2 won’t require as much web optimization as HTTP/1.1 did, and it should give most of the same performance benefits those optimizations give under HTTP/1.1 without any effort, developers are still getting used to this new protocol, and undoubtedly, some best practices and techniques will require learning.
By now, you’re presumably eager to get HTTP/2 up and running. In chapter 3, I show you how to do this. I return to performance optimization later to show how you can measure improvements and best use HTTP/2 to your advantage. This chapter has given you a taste of what HTTP/2 can bring to the web, and I hope that it makes you eager to understand how you can deploy it on your website.
Summary
- HTTP/1.1 has some fundamental performance problems, particularly with fetching multiple resources.
- Workarounds exist for these performance problems (multiple connections, sharding, spriting, and so on), but they have their own downsides.
- Performance issues are easy to see in waterfall diagrams that can be generated by tools such as WebPagetest.
- SDPY was designed to address these performance issues.
- HTTP/2 is the standardized version of SPDY.
- Not all performance problems can be solved by HTTP/2.