
What Is Statelessness?
When I speak of maintaining state, I am only speaking of client identification, which is accomplished by associating multiple HTTP requests.
Maintaining session, on the other hand, requires two related tasks:
Identifying the client (state management)
Retaining information about the client
Although the nature of HTTP messages has been explained in detail, you have yet to fully explore the stateless characteristic of the Web. It is fairly common knowledge among Web developers that HTTP (the Web) is stateless, and many believe this to be a shortcoming of HTTP. On the contrary, this is a characteristic that has been essential in the Web’s success, regardless of the challenges it has presented developers through the years.
Identifying the client requires some effort on the part of the Web server in terms of storage space, processing, memory, and so on. Because the original model for the Web did not include the idea of Web applications, maintaining state was unnecessary, so integrating this extra effort into the protocol would have made little sense. Without the overhead of state management, things scale fairly linearly, meaning that the resources required to support Web transactions increase proportionally with the amount of traffic received.
With the widespread use of the Web and the subsequent creativity that has been applied to the business possibilities, Web applications are now the focal point of most Web development. This is especially true for the majority of Web developers who develop as their profession. As a result, many solutions have been created to address the need for state management.
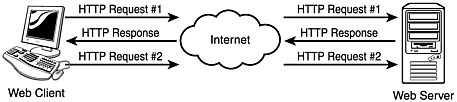
When I refer to the identification of the client, I do not mean the identification of the user. Rather, I am referring to identifying the client as the same client who sent a previous request. Figure 11.2 shows an example of two subsequent HTTP requests sent from the same Web client. In this case, identification is equivalent to recognizing that a client that sends a request is the same one that sent a previous request or that the client is a new visitor. With cookies, this type of association is possible.
Figure 11.2. A Web browser sends two subsequent HTTP requests.
User identification requires more. Once you establish a method (such as cookies) that can be used to identify the client, user identification only requires that you authenticate the user and then recognize which client the user is associated with. For example, if a user visits your Web site for the first time and receives the identifier id=12345 in the form of a cookie, you have a way of identifying the client as long as that cookie is returned in subsequent requests. If the user logs in as chris from the client identified by id=12345, you now can identify the user simply by identifying the client (the client identified by id=12345 is currently being used by the user identified as chris). The username in this example is an example of client data, and the maintenance of this data is the subject of Chapter 13, “Maintaining Client Data.”