
Once you've described your persistence with Hibernate *.hbm.xml files and the corresponding Java sources, the basic mechanism for creating, updating, finding, and deleting objects is the Session class. This will be discussed in depth in the first part of the chapter.
Hibernate makes an important distinction between transient objects and persistent objects. A transient object is not associated with a particular session. A persistent object is associated with a session. This can be a subtle (and confusing) distinction when working with Hibernate, but it's important to keep in mind that the objects you are working with may not represent the correct state of affairs as represented in the database outside the context of a session.
The notion of persistent and transient objects is intertwined with the notion of object identity. The review of the session interface will be followed by an in-depth look at the various notions of identity. As long as you stick to a single thread per net.sf.hibernate.Session object, Hibernate will largely take care of identity automatically, but it can be confusing if you encounter problems related to identity (in particular, if you make use of composite identifiers).
Finally, the life-cycle methods provided by Hibernate will be reviewed. These methods allow the receipt of events at various points in an object's existence. Sample code for a simple object is shown, and can be used as the base for your own laboratory experiments with object identity.
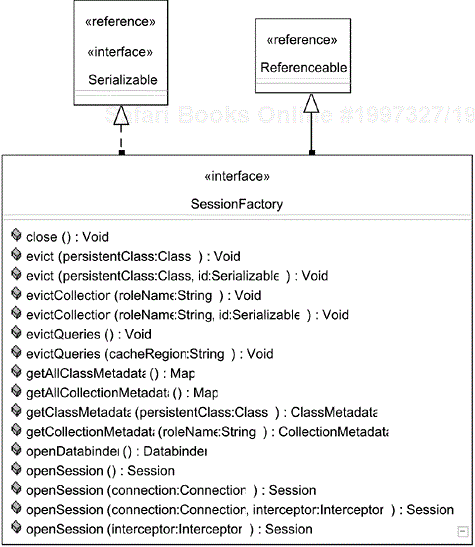
The core of database operations in Hibernate is the lightweight, not-thread-safe net.sf.hibernate.Session object. Session objects are obtained from instances of the heavyweight, thread-safe net.sf.hibernate.Session Factory. A SessionFactory is obtained from a Configuration, in turn a heavy, expensive-to-create, one-time use class. Typically, you will use a singleton pattern to obtain a SessionFactory, and the logic for initializing the SessionFactory will include the use of a Configuration object. For more details on the relationship between Configuration, Session Factory, Session, transactions, and the ordering of statements within a particular session, see Chapter 9.
Session object are lightweight and not-thread-safe, and typically are created and disposed of frequently.
A Configuration object is created once, typically as part of the launching process of your application. The primary task of a Configuration object is to load and process the various *.hbm.xml files, binding them to the relevant persistent code, and returning an appropriately configured SessionFactory.
The list of methods in Table 6.1 is not complete. For a complete list, refer to the Hibernate javadoc (Hibernate_install_dir docapiindex.html). The summary shown in Table 6.1 illustrates the range of options available for storing configuration data.
Table 6.1. Adding Mapping Files
| Uses the class name and package statement to load the |
| Loads all of the |
| Adds a mapping as already loaded by a DOM object. |
| Reads the mapping from a particular file (may have an extension other than |
| Reads the mapping from a supplied |
| Reads the |
| Reads the mapping file from a specified |
| Reads the mapping as passed by an arbitrary String (useful for dynamic mapping generation, perhaps by a Hibernate-enabled tool). |
| Reads the mapping files and properties as specified by a |
| Reads mapping files and properties as specified by a specific file (as per a |
| Reads mapping files and properties as specified by a resource path (as per |
| Reads mapping files and properties as specified by a URL resource (as per |
If you are using a hibernate.cfg.xml (or one of the configure() methods), you will define the connectivity properties in that file. Otherwise, these properties may be set at runtime using a java.util.Properties object via Configuration.addProperties(), Configuration .setProperties(), or individually using Configuration.set Property().
Alternatively, the connectivity may be configured using a hibernate .properties file placed on the class path.
Tables 6.3 through 6.6 describe additional options for the configuration of Hibernate.
Example 6.1. Sample Minimal Properties File
hibernate.connection.driver_class=com.mysql.jdbc.Driver hibernate.connection.url=jdbc:mysql://localhost/hibernate hibernate.connection.username=root hibernate.connection.password= hibernate.dialect=net.sf.hibernate.dialect.MySQLDialect hibernate.show_sql=true
Table 6.3. JNDI Datasource Connectivity Configuration Properties
Property Name | Purpose |
|---|---|
| datasource JNDI name |
| URL of the JNDI provider (optional) |
| class of the JNDI |
| database user (optional) |
| database user password (optional) |
| Pass the property |
Table 6.6. Supported JTA Transaction Managers
Application Server | Transaction Factory |
|---|---|
JBoss |
|
Weblogic |
|
| |
Orion |
|
Resin |
|
JOTM |
|
JOnAS |
|
JRun4 |
|
Borland ES[*] |
|
JNDI[*] |
|
Sun ONE Application Server 7[*] |
|
[*] Available in Hibernate 2.1.5 | |
If you wish to use Hibernate (perhaps in conjunction with a pooling driver, as described in Chapter 10) to manage obtaining and releasing connections, you will want to set the properties as shown in Table 6.2.
Table 6.2. JDBC Connectivity Configuration Properties
Property Name | Purpose |
|---|---|
| JDBC driver class |
| JDBC URL |
| Database user account |
| Database user password |
| Maximum number of pooled connections |
If you wish to use Hibernate in the context of an application server, you will probably rely on the application server's built-in JNDI-based datasource mechanism for managing connections. Table 6.3 shows the properties that must be set to allow Hibernate to connect to JNDI datasources.
Hibernate also offers a wide variety of configurable options, as shown in Table 6.4. You can use them to provide additional database connectivity options or to set performance options.
Table 6.4. Miscellaneous Optional Hibernate Configuration Properties
Property Name | Purpose | Value |
|---|---|---|
| The class name of a Hibernate |
|
| Qualify unqualified table names with the given schema/table space in generated SQL. |
|
| Bind this name to the |
|
| Enables outer join fetching. For more information on outer joins, see Chapter 8. |
|
| Set a maximum “depth” for the outer join fetch tree. For more information on outer joins, see Chapter 8. | recommended values between 0 and 3 |
| A nonzero value determines the JDBC fetch size (call | |
| A nonzero value enables use of JDBC2 batch updates by Hibernate. | recommended values between 5 and 30 |
| Enables use of JDBC2 scrollable result sets by Hibernate. This property is only necessary when using user-supplied connections. In all other instances Hibernate uses connection metadata. |
|
| Use streams when writing / reading binary or serializable types to/from JDBC. System-level property. |
|
| Enables use of CGLIB instead of runtime reflection (system-level property, default is to use CGLIB where possible). Defaults to true. Setting this to false can sometimes be useful when troubleshooting. |
|
Set the JDBC transaction isolation level (optional) |
| |
| Pass the JDBC property | |
| Class name of a custom | Fully qualified class name of an implementation of |
| Class name of a custom | Fully qualified class name of an implementation of |
| Optimize second-level cache operation to minimize writes, at the cost of more frequent reads (useful for clustered caches). See Chapter 10 for more information. |
|
| Enable the query cache. |
|
| Prefix to use for second-level cache region names. |
|
Class name of a | Use JDBC Transactions: | |
| JNDI name used by |
|
| Class name of a | A value from Table 6.6 or a custom implementation of |
| Mapping from tokens in Hibernate queries to SQL tokens (tokens might be function or literal names, for example) |
|
| Write all SQL statements to console (a minimal alternative to the use of the logging functionality as described in Chapter 10) |
|
| Automatically export schema DDL. |
|
Typically, Hibernate is able to automatically detect the proper SQL dialect to use based on the JDBC driver. You may wish to manually set the SQL dialect, either to ensure the proper dialect or for schema management (as described in Chapter 11). Table 6.5 shows the possible values for hibernate.dialect.
Table 6.5. Supported SQL Dialects
Database | Dialect |
|---|---|
DB2 |
|
DB2400 |
|
Firebird |
|
FrontBase |
|
Generic |
|
HypersonicSQL |
|
Informix |
|
Ingres |
|
Interbase |
|
Mckoi SQL |
|
Microsoft SQL Server |
|
MySQL |
|
Oracle 9 |
|
Oracle |
|
Pointbase |
|
PostgreSQL |
|
Progress |
|
SAP DB |
|
Sybase Anywhere |
|
Sybase 11.9.2 |
|
Sybase |
|
Similarly, Hibernate offers support for JTA to manage your transactions. Table 6.6 shows the supported JTA transaction managers.
Listing 6.2 shows an example of the use of the Configuration object to obtain a Session.
Example 6.2. Typical Configuration Initialization
Configuration myConfiguration = new Configuration(); myConfiguration.addClass(Exam.class); myConfiguration.addClass(Examresult.class); myConfiguration.addClass(Course.class); myConfiguration.addClass(Student.class); // Sets up the session factory (used in the rest // of the application). sessionFactory = myConfiguration.buildSessionFactory();
Once a SessionFactory has been obtained, you will store this object somewhere (typically in a static variable) and use it throughout the rest of your application.
Most commonly, openSession()is the only method of a SessionFactory that you will use. The no-argument version will use the mechanism as described by the Configuration properties to connect to the database (usually the preferred mechanism).
Once you have obtained a session, you have access to a variety of options for manipulating data, as shown in Figure 6.2.
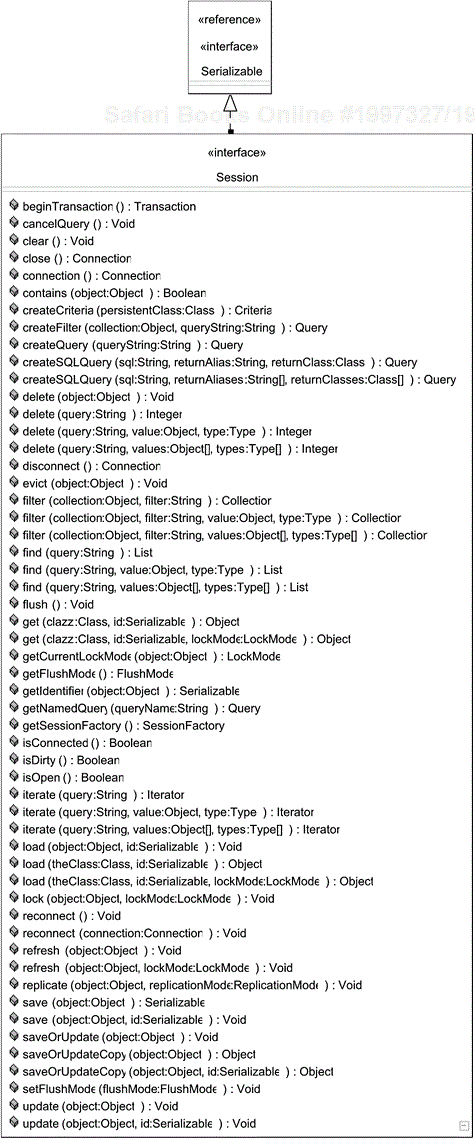
Generally speaking, the methods of a session are concerned with the traditional create, retrieve, update, and delete operations.
TRANSACTIONS
You'll want to wrap calls to the session using method beginTransaction() and then calling Transaction.commit() when finished. Note that Hibernate will sometimes not actually flush SQL statements to the transaction until after the transaction is committed, which can on occasion lead to unwanted reordering of the SQL execution. For more information on flushing statements as part of a transaction, see Chapter 9.
In other words, Hibernate may not execute the SQL in the order in which you issue the commands in the session. To avoid this, use the session.flush() when executing statements to ensure the proper order of execution (see Chapter 9 for more information).
As shown in examples throughout this book, make sure that you are using try/catch/finally blocks to properly commit or roll back transactions as needed and that sessions are closed properly.
Creating objects in Hibernate is straightforward. Simply allocate the persistent objects using new, set the properties, and then use Session.save().
A complication may arise when you are creating objects with collections, however. The important thing to remember is that collection elements added to a parent where the collection is set to inverse="true" are not persisted automatically—you must manually save them and add them to the inverse="false" end of the relationship to persist them.
Unfortunately, Hibernate does not allow both sides of a collection to be set to inverse="false". This means that you must think carefully about your needs in order to decide which side of an association to map as inverse="false". To complicate matters somewhat, this is also true when objects are deleted—it's easy to manually delete the associations, as long as the proper side of the relationship is used. You can work around this when working with the “wrong end” of a bi-directional association by using the outer-join-as-inverse-of-inner technique described in Chapter 8.
Session methods that are useful when you are saving objects are shown in Table 6.7.
Table 6.7. Object Creation
| Saves the object, and sets the id to the generated identifier. |
| Saves the object using the specified identifier. Useful if you use an alternative mechanism for managing identifiers (for example, if you are relying on your EJB container for identifiers). |
| Will save the object if no identifier is present, or update the object if the identifier is valid. |
| Will generate a new object either way, and will make a copy of the object from the current version if one already exists. |
| Will generate a new object with the specified identifier either way, and will make a copy of the object from the current version if one already exists. |
Hibernate offers a wide variety of options for retrieving objects from the database, including HQL, the Criteria API, and using SQL directly (or even mixing different strategies). For more information, see Chapter 8.
The various methods available for retrieving objects via HQL (as described in Chapter 8) are shown in Table 6.8. These methods are routinely expected to return no results (for example, a query for the number of students in a class may legitimately return no students if there are none enrolled). If you wish to view the inability to retrieve an object as an application failure use load(), described under Refreshing Objects below, instead of get().
Table 6.8. Finding Objects via HQL
| Use to retrieve a Query object based on an HQL query. |
| Returns a java.util.List containing the results of the HQL query. |
| Returns a java.util.List, using the values and types provided as bound parameters. |
| Returns a java.util.List, using the value and type provided as a bound parameter. |
| Retrieves a single persistent object, or null if not present. |
| Retrieves a single persistent object with the specified lock mode. Not normally necessary—Hibernate manages lock modes automatically. |
| Gets a query based on a query specified in the *.hbm.xml mapping file. |
| Executes the query, returning the results lazily, loading each object with a new SELECT statement. |
| Executes the query, returning the results lazily, loading each object with a new SELECT statement. Values and types are used to set bound parameters. |
| Executes the query, returning the results lazily, loading each object with a new SELECT statement. Value and type are used to set a bound parameter. |
Some of these methods return a net.sf.hibernate.Query object instead of an immediate set of results. The net.sf.hibernate.Query object can be used to bind parameters and configure other aspects of the query before execution. The advantages of using an intermediate Query object include:
Selecting a portion of the results (using s
etMaxResults()andset-FirstResult())Required to use named query parameters
Retrieve the results as
ScrollableResults
You may notice that there are two seemingly similar methods for retrieving results: find() and iterate(). The find() method executes immediately, whereas iterator() executes on demand. Therefore, find() methods typically perform better than iterator() methods. If you fear you may retrieve too many results with find(), you would probably be better off using create-Query() to configure the returned results.
In addition to HQL, Chapter 8 describes the use of both the Hibernate Criteria API and raw SQL to access data. Table 6.9 shows these methods.
Table 6.9. Finding Objects via Criteria and SQL
| Pass in a persistent class to use as the base of the criteria, and then use additional methods to modify the query, as shown in Chapter 8. |
| Use to execute a query with multiple alias and classes, as shown in Chapter 8. |
| Use to execute a query with a single alias and class, as shown in Chapter 8. |
Sometimes, you know that an object exists, but only have part of the object's information. The most typical example would be a situation in which you know an object's identify reference but don't have the rest of the object information (this is shown in the sample application in Chapter 2). Given an identifier, the load() method can be used to retrieve the rest of the information about an object. The difference between a load() and a get() is that a load() will fail with an exception if the object is not found, whereas a get() will simply return null.
Within the context of a single session, you may expect that the mere act of updating or saving the object will modify the properties. For example, a trigger may modify the data written to a particular column when a record is saved. The refresh() method is used in the context of a single Session to retrieve these changes. In practice, you'll probably use the load() method much more frequently than the refresh() method. The refresh() method can also be used to reassociate objects across transactions with a session (converting a transient object to a persistent object). This is especially important if you wish to take advantage of cascading operations, because Hibernate may not recognize cascading associations if objects are not properly refreshed. For an example of this, see Listing 2.17, Deleting an Author.
Table 6.10. Obtaining the Current Data
| Use to load an object at any time, given only an identifier. |
| As load, with a specific identifier. |
| As load, with a specific identifier and lock mode. |
| Only usable if the object has already been loaded by this session. |
| Only usable if the object has already been loaded by this session |
Deleting an object is largely a simple matter of passing the object to the session.delete(). You can use HQL to identify a range of records for higher-performance bulk deletes.
Table 6.11. shows the methods available for deleting data.
Table 6.11. Deleting Data
| Removes a persistent instance from the database. |
| Deletes all objects returned by the HQL query. |
| Deletes all objects returned by the HQL query. |
| Deletes all objects returned by the HQL query. |
Much like creating an object, updating an object is a matter of simply modifying a persistent object and passing it to Session.update(). Table 6.12 shows the methods available for updating data.
Our applications so far have used several different mechanisms for determining whether two objects are to be considered equal. It's important to understand the different mechanisms for identity, especially concerning the difference between transient and persistent objects as defined by Hibernate.
The first form of identity is expressed in terms of the database key. For example, two records could be considered equal if they have the same primary key value.
The second form of identity is expressed in terms of the Java object reference. We can imagine a situation in which two Java objects contain the same data from the perspective of the developer but are different objects because they are stored in two different places in memory.
Finally, the third form of identity derives from a comparison of all of the data associated with the object. For example, consider an object containing student data. This object might be represented by a primary key (for example, 543), a JVM object reference (for example, 82340), or the values of the associated data (for example, the primary key, 543, the first name, and the last name).
If the student object were to change the value of the last-name property, neither the primary key nor the object reference would be changed, even though the object is clearly no longer equivalent.
Consider the following snippet of code and the different values that may be considered when evaluating equality:
Primary Key | Data | ||
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Obviously, these different notions of equality can lead to radically different answers when one is trying to answer the question “Are these two objects equal?”
Hibernate expresses these two different notions of equality by taking advantage of the two different mechanisms for equality built into the Java language. The Java = and == operators rely on the object reference. All Java objects, on the other hand, descend from the base java.lang.Object class, which defines an equals() method. Therefore, Hibernate uses the equals() method to determine persistent identity, and the == method to determine JVM equality.
Let's look at a standard Hibernate equals() implementation, as shown in Listing 6.3. This is declared in a class called Message (as described in more detail later in this chapter). The first order of comparison in the snippet is by class instance. Then the objects are compared for equality by their primary-key value and nothing else (for more information on the Apache Jakarta Commons Lang project's EqualsBuilder class, see http://jakarta.apache.org/commons/lang/api/org/apache/commons/lang/builder/EqualsBuilder.html). Therefore, this object will rely on the notion of primary-key values for equality.
Example 6.3. Sample Primary-Key Equality Method
public boolean equals(Object other)
{
if (!(other instanceof Message))
return false;
Message castOther = (Message)other;
return new EqualsBuilder()
.append(this.getId(), castOther.getId())
.isEquals();
}
Similarly, Listing 6.4 shows the matching implementation of hashCode().
Example 6.4. Sample Primary-Key Hash Method
public int hashCode()
{
return new
HashCodeBuilder().append(getId()).toHashCode();
}
The documentation for the Apache Jakarta Commons Lang HashCodeBuilder will be found at http://jakarta.apache.org/commons/lang/api/org/apache/commons/lang/builder/HashCodeBuilder.html. The hashCode is principally derived from the primary key id, as in the equals() method.
Hibernate has the very interesting capability of replacing instances that you pass to it with new instances as needed, in order to maintain internal consistency.
This means that you will always get back the same JVM object reference when you perform operations in the context of a single session. For example, consider the Hibernate pseudo-code shown in Listing 6.5.
Example 6.5. Session Identity
hibernateSession = sessionFactory.openSession();
Student myStudent = hibernateSession.load(Student.class, new Long(23));
...
Student altStudent = hibernateSession.load(Student.class, new Long(23));
if(myStudent == altStudent)
System.out.println("Students are equal!");
The snippet in Listing 6.5 will evaluate myStudent == altStudent to true, because Hibernate maintains the object reference as part of the open session.
Conversely, this state is not shared across sessions, and so if myStudent and altStudent were retrieved from different sessions, they may or may not evaluate to true, depending on the session, cache, thread, and other JVM details. All this means that you don't need to worry about object identity or concurrency as long as you don't share a session across threads (virtually never a good idea).
Later in this chapter, we will show how to use Hibernate object life-cycle methods to examine the issues of identity in more detail.
The terms identity and primary key have different meanings, but they are often used interchangeably when working with Hibernate. Object identity refers to the more general notion of identity—a unique value that can be used to retrieve a unique object.
Generally speaking, when a record is stored in a database, it is given a pri mary key as the main indicator of its identity. As a safeguard against possible changes to the application, this primary key typically has no particular business value or association with other data in the record.
WARNING
It bears repeating: you are strongly encouraged to not use a primary key with a business value. Avoiding the use of business values is sometimes trickier than might be expected. For example, you may think that a social security number (a standard U.S. government identifier) would serve as a reasonable primary key number. Unfortu nately, in this age of identity theft, it's possible for people to change their social security numbers (and thereby the value used for key relationships). Therefore, whenever possible use a synthetic, internal-to-the-application-only value for primary keys.
In certain instances, however, object identity is not managed by a primary key, but by another mechanism. For example, the records in a collection table may be referred to by a composite key (the fusion of the two collected foreign keys), with no primary key required.
There are several built-in strategies available for primary key generation. Hibernate controls the configuration of identity generation for standard primary keys using the generator tag in the *.hbm.xml mapping file (see the generator tag in Chapter 5 for more information). Hibernate allows you to specify a custom Java class that implements the interface net.sf .hibernate.id.IdentifierGenerator for identity generation, but it also includes a large suite of built-in generation classes.
Hibernate includes many built-in implementations of net.sf.hibernate .id.IdentifierGenerator that allow you to easily support a wide variety of possible key generators. You can refer to these built-in generators either by their fully qualified class names or by their “shortcut” names.
If you are working with an existing database, you'll want to select the generator that matches the current key generation strategy.
incrementGenerates in-process (i.e., within this JVM instance only) identifiers of type
long,short,orint. Only guaranteed to be unique when no other process is inserting data into the same table. Do not use in a cluster.identityUse when working with an identity column in DB2, MySQL, MS SQL Server, Sybase, or HypersonicSQL. The returned identifier is of type
long,short,orint.sequence(net.sf.hibernate.id.SequenceGenerator)Use when working with a sequence column in DB2, PostgreSQL, Oracle, SAP DB, McKoi, or a generator in Interbase. The returned identifier is of type
long,short,orint.hilo(net.sf.hibernate.id.TableHiLoGenerator)Uses a particular hi/lo table to keep manage identifier generation. Whereas a simple table generator hits the database every time an identifier is requested, the hi/lo strategy minimizes database access by requesting possible identifiers in blocks. The size of the block of possible identifiers reserved is specified by the required
<param name="max_lo"> 100</param>tag.You can use
<param nam="table">mytable</param>tag to override the default table name (hibernate_unique_key), and<param nam="column">mycolumn</param>to override the default column name (next) if desired.The hi/lo algorithm generates identifiers that are unique only for a particular database. This generator requires a new database transaction to retrieve the identifier, so do not use it with connections managed by JTA or with a user-supplied connection.
seqhilo(net.sf.hibernate.id.SequenceHiLoGenerator)Similar to the hi/lo algorithm, but uses an underlying sequence to generate identifiers of type
long,short,orint, given a named database sequence. In addition to the<param name="max_lo">100 </param>, you will also need to identify the sequence using a<param name="sequence">hi_value</param>tag.uuid.hex(net.sf.hibernate.id.UUIDHexGenerator)Uses a 128-bit UUID algorithm to generate identifiers of type string, unique within a network. The UUID is encoded as a 32-character-long string of hexadecimal digits. The UUIDs are based on IP address, startup time of the JVM (accurate to a quarter-second), system time, and a counter value (unique in the JVM). You can pass in a
<param name= "separator">-</param>tag to configure a separator character. Use this class if you want human-readable UUID values.uuid.string(net.sf.hibernate.id.UUIDStringGenerator)Uses the same UUID algorithm as
uuid.hex, only instead of encoding as a 32-character-long string of hex digits, uses a 16-character string of ASCII characters (including unprintable, non-human-readable characters). Do not use with PostgreSQL or if you want a human to be able to reasonably view or edit the key.native(assigned in net.sf.hibernate.id. Identifier Generator)Automatically chooses either
identity,sequence,orhilodepending upon the capabilities of the target database.assigned(net.sf.hibernate.id.Assigned)Lets the application assign an identifier to the object before
Session .save()is called. This generator is especially important for use in one-to-one relationships (see the one-to-one tag in Chapter 5 for more information). Due to its inherent nature, entities that use this generator cannot be saved via theSession.saveOrUpdate()method. Instead you have to explicitly specify to Hibernate whether the object should be saved or updated by calling eitherSession.save()orSession .update(). If you are using this strategy, be very careful to assign proper identifiers (especially if you also rely on cascading object updates).foreign(net.sf.hibernate.id.ForeignGenerator)Uses the identifier of another associated object. Generally used in conjunction with a one-to-one primary-key association. Requires a
<param name="property">target_key</param>.
Most objects will rely on a built-in generator for key generation. Some objects, however (in particular, those used in collection tables) may rely on composite keys. An example of this is shown in the ownership table in Chapter 3. Listing 6.6 shows the description of the ownership table as given by MySQL. Note that the table has two primary keys. In the discussion that follows, we will assume that the most popular use of composite keys is for collection tables (of course this may not be true for certain applications), and therefore we will discuss them in that context.
Example 6.6. Composite Identity Example
mysql> desc ownership; +-------------+------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------+------------+------+-----+---------+-------+ | owner_id | bigint(20) | | PRI | 0 | | | artifact_id | bigint(20) | | PRI | 0 | | +-------------+------------+------+-----+---------+-------+
On reflection, you will realize that this makes it difficult to work individual records outside the context of the related objects. Although this is largely a non-issue, it makes working with composite identity records more difficult as you develop certain complex relationships. If you are content to allow Hibernate to manage your collections, and do not impose any additional fields beyond those Hibernate requires for the collection (for example, index columns as needed, but no additional data fields), you may never need to deal with composite identity directly.
Putting this in the context of the example application shown in Chapter 3, you will note that there is no class-level declaration of the ownership table. Instead, all references to the ownership table are made via collection-tag bindings. Listing 6.7 shows one side of this binding from the Artifact.hbm.xml file. A similar (but inverted) binding exists in the Owner.hbm.xml file.
Example 6.7. One Side of a Collection
<set name="owners" table="ownership" lazy="false" inverse="true" cascade="none"sort="unsorted"> <key column="artifact_id"/> <many-to-many class="com.cascadetg.ch03.Owner" column="owner_id" outer-join="auto"/> </set>
Thus, even though this application uses a table with composite identity, there is no need to explicitly deal with the composite-identity as such; Hibernate takes care of this for us.
In certain situations, particularly when working with a legacy database schema, you won't have the luxury of a pure collection table. In situations in which you have a collection table with additional data, you are often best off representing the collection table as an independent class (an example of which is shown in Chapter 4). In this case, the table identity may need to be modeled using a composite identity tag, such as composite-element, composite-id, or composite-index. These tags, described in Chapter 5, are used in combination with nested property tags to declare the columns used to manage the composite identifiers.
It's very important to correctly implement the Object.equals() and Object.hashCode() methods to correctly handle composite identity. The default methods, as shown in Listing 6.3 and Listing 6.4, should include all of the property values required to correctly map the composite identity, not just the getId() methods as shown.
Hibernate offers a feature that allows you to perform a save-or-update with a single method call (as shown in Table 6.7). In other words, let's say that you wish to either update an object (if it exists) or create it (if it doesn't). In order to know whether an object has been created (at least from the perspective of the application running in the JVM), Hibernate will inspect certain values to see if they have been set.
The most immediate and obvious example is the primary key (or id) of the object. For example, perhaps you are using a java.lang.Long to track the primary key of an object. If this field is set to null, then Hibernate knows that the object has not been saved in the database. Similarly, if the value is not null, then Hibernate knows that the object has a primary key and therefore must exist in the database (because null is the unsaved value).
This use of a null is an important reason to use the object version of a value (e.g., java.lang.Long) instead of the primitive form (e.g., long). While null values are sometimes simulated with a primitive (e.g., 0 or -1), this is a fragile and non-standard approach. Normally, this is the most significant impact of the notion of unsaved value, but as you develop complex data models or cope with certain legacy data models, you may find other reasons to change the notion of an unsaved value.
Now that we have looked in depth at the various notions of identity, we can take advantage of the life-cycle methods built in to Hibernate to experiment with the various available systems.
There are two main interfaces of life-cycle interest, one for general notifications and one for validation. Let's start by looking at an example of life-cycle application. Figure 6.3 shows a persistent Java object, a simple message. Note the implementation of the net.sf.hibernate.Lifecycle and net.sf .hibernate.Validatable interfaces. These are used to flag that this class is interested both in events relating to the object's life cycle (e.g., creation, saving, updating, destruction) and in events providing an opportunity to validate the state of the object before certain operations (in particular, saving or updating the object).
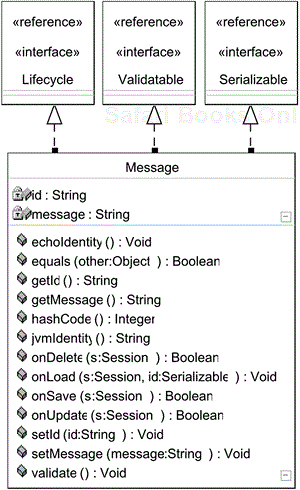
As you review the life-cycle methods shown below, keep in mind that the life-cycle events correspond to the terminology used at the start of this chapter. For example, the update event corresponds to when a transient object is rendered persistent, and not to all instances when a given persistent object is updated. Similarly, the validation methods are called when appropriate from a persistence perspective. Do not use these life-cycle methods to manage your business logic—the terminology and events are only relevant from a persistence model perspective.
The code for the message object, as shown in Listing 6.8 (with white space trimmed) is based on XDoclet (described in Chapter 3). In particular, note the methods implementing the various life-cycle interfaces. This class doesn't do anything very interesting (beyond echoing the fact of notification), but it's easy to envision possible uses.
Example 6.8. Object Life-Cycle Example
package com.cascadetg.ch06;
import java.io.Serializable;
import net.sf.hibernate.CallbackException;
import net.sf.hibernate.Lifecycle;
import net.sf.hibernate.Session;
import net.sf.hibernate.Validatable;
import net.sf.hibernate.ValidationFailure;
import org.apache.commons.lang.builder.HashCodeBuilder;
import org.apache.commons.lang.builder.EqualsBuilder;
/**
* @author Will Iverson
* @hibernate.class
* @since 1.0
*/
public class Message
implements Lifecycle, Validatable, Serializable
{
String message;
/**
* @hibernate.property
* @return Returns the message.
*/
public String getMessage() { return message; }
/**
* @param comments
* The comments to set.
*/
public void setMessage(String message)
{ this.message = message; }
String id;
/**
* @hibernate.id generator-class="uuid.hex"
* Xhibernate.id generator-class="native"
* Xhibernate.id generator-class="increment"
*
* @return Returns the id.
*/
public String getId() { return id; }
/**
* @param id
* The id to set.
*/
public void setId(String id) { this.id = id; }
/* see net.sf.hibernate.Lifecycle#onSave(net.sf.hibernate.Session)
*/
public boolean onSave(Session s) throws CallbackException
{
echoIdentity();
System.out.println("saved.");
return Lifecycle.NO_VETO;
}
/* see net.sf.hibernate.Lifecycle#onUpdate(
net.sf.hibernate.Session)
*/
public boolean onUpdate(Session s) throws CallbackException
{
echoIdentity();
System.out.println("updated.");
return Lifecycle.NO_VETO;
}
/* see net.sf.hibernate.Lifecycle#onDelete(
net.sf.hibernate.Session)
*/
public boolean onDelete(Session s) throws CallbackException
{
echoIdentity();
System.out.println("deleted.");
return Lifecycle.NO_VETO;
}
/* see net.sf.hibernate.Lifecycle#onLoad(
net.sf.hibernate.Session,
java.io.Serializable)
*/
public void onLoad(Session s, Serializable id)
{
echoIdentity();
System.out.println("loaded.");
}
/* see net.sf.hibernate.Validatable#validate()
*/
public void validate() throws ValidationFailure
{
echoIdentity();
System.out.println("validated.");
}
/** Standard Hibernate equality override */
public boolean equals(Object other)
{
if (!(other instanceof Message))
return false;
Message castOther = (Message)other;
return new EqualsBuilder()
.append(this.getId(), castOther.getId())
.isEquals();
}
/** Standard Hibernate hash override. */
public int hashCode()
{ return new
HashCodeBuilder().append(getId()).toHashCode(); }
/** Not certain to work on all JVMs */
public String jvmIdentity() { return super.toString(); }
public void echoIdentity()
{
System.out.print("JVM:" + this.jvmIdentity());
System.out.print(", KEY:" + this.getId());
System.out.print(" HASH:" + this.hashCode() + " ");
}
}
Executing the build file for this class, a *.hbm.xml file is generated by XDoclet, as shown in Listing 6.9 (white space edited).
Example 6.9. Message Mapping
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 2.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-2.0.dtd">
<hibernate-mapping>
<class name="com.cascadetg.ch06.Message"
dynamic-update="false"
dynamic-insert="false" >
<id name="id" column="id" type="java.lang.String" >
<generator class="uuid.hex">
</generator>
</id>
<property name="message" type="java.lang.String"
update="true" insert="true" column="message" />
<!--
To add non XDoclet property mappings, create a
file named hibernate-properties-Message.xml
containing the additional properties and place
it in your merge dir.
-->
</class>
</hibernate-mapping>
Given the Java object and the mapping file, a simple test harness can be used to exercise the object (as shown in Listing 6.10). You'll notice that this class echoes the results of various object identity, validation, and life-cycle features of Hibernate.
Example 6.10. Testing Life Cycles, Validation, and Identity
package com.cascadetg.ch06;
/** Various Hibernate-related imports */
import net.sf.hibernate.*;
import net.sf.hibernate.cfg.*;
import net.sf.hibernate.tool.hbm2ddl.SchemaUpdate;
public class MessageTest
{
public static void main(String[] args)
{
initialization();
createMessage();
loadMessage();
updateMessage();
// deleteMessage();
}
/** We use this session factory to create our sessions */
public static SessionFactory sessionFactory;
/** Loads the Hibernate configuration information,
* sets up the database and the Hibernate session factory.
*/
public static void initialization()
{
//System.setErr(System.out);
System.out.println("initialization");
try
{
Configuration myConfiguration = new Configuration();
myConfiguration.addClass(Message.class);
// This is the code that updates the database to
// the current schema.
new SchemaUpdate(myConfiguration).execute(true,
true);
// Sets up the session factory (used in the rest
// of the application).
sessionFactory =
myConfiguration.buildSessionFactory();
} catch (Exception e)
{
e.printStackTrace();
}
}
static String savedMessageID = null;
public static void loadMessage()
{
System.out.println();
System.out.println("loadMessage");
Session hibernateSession = null;
Transaction myTransaction = null;
try
{
hibernateSession = sessionFactory.openSession();
myTransaction = hibernateSession.beginTransaction();
Message newMessage = new Message();
newMessage.echoIdentity();
System.out.println("pre-set");
newMessage.setId(savedMessageID);
newMessage.echoIdentity();
System.out.println("pre-load");
// This object is not "owned" by Hibernate,
// so the onUpdate() method IS called.
hibernateSession.load(
Message.class,
newMessage.getId());
hibernateSession.flush();
myTransaction.commit();
newMessage.echoIdentity();
System.out.println("post-load");
} catch (Exception e)
{
e.printStackTrace();
try
{
myTransaction.rollback();
} catch (Exception e2)
{
// Silent failure of transaction rollback
}
} finally
{
try
{
hibernateSession.close();
} catch (Exception e2)
{
// Silent failure of session close
}
}
}
public static void updateMessage()
{
System.out.println();
System.out.println("updateMessage");
Session hibernateSession = null;
Transaction myTransaction = null;
try
{
hibernateSession = sessionFactory.openSession();
myTransaction = hibernateSession.beginTransaction();
Message newMessage = new Message();
newMessage.setId(savedMessageID);
newMessage.setMessage("updated");
// This object is not "owned" by Hibernate,
// so the onUpdate() method IS called.
hibernateSession.update(newMessage);
hibernateSession.flush();
newMessage.setMessage("indigo");
hibernateSession.save(newMessage);
hibernateSession.flush();
myTransaction.commit();
} catch (Exception e)
{
e.printStackTrace();
try
{
myTransaction.rollback();
} catch (Exception e2)
{
// Silent failure of transaction rollback
}
} finally
{
try
{
hibernateSession.close();
} catch (Exception e2)
{
// Silent failure of session close
}
}
}
public static void deleteMessage()
{
System.out.println();
System.out.println("deleteMessage");
Session hibernateSession = null;
Transaction myTransaction = null;
try
{
hibernateSession = sessionFactory.openSession();
myTransaction = hibernateSession.beginTransaction();
Message newMessage = new Message();
newMessage.setId(savedMessageID);
hibernateSession.delete(newMessage);
hibernateSession.flush();
myTransaction.commit();
} catch (Exception e)
{
e.printStackTrace();
try
{
myTransaction.rollback();
} catch (Exception e2)
{
// Silent failure of transaction rollback
}
} finally
{
try
{
hibernateSession.close();
} catch (Exception e2)
{
// Silent failure of session close
}
}
}
public static void createMessage()
{
System.out.println();
System.out.println("createMessage");
Session hibernateSession = null;
Transaction myTransaction = null;
try
{
hibernateSession = sessionFactory.openSession();
myTransaction = hibernateSession.beginTransaction();
Message myMessage = new Message();
myMessage.setMessage("foo");
hibernateSession.save(myMessage);
hibernateSession.flush();
myTransaction.commit();
System.out.println(
"New message id: " + myMessage.getId());
myTransaction = hibernateSession.beginTransaction();
// This object is already "owned" by Hibernate,
// so the onUpdate() method is NOT called.
myMessage.setMessage("bar");
hibernateSession.update(myMessage);
hibernateSession.flush();
myTransaction.commit();
// Save the message ID for later use.
savedMessageID = myMessage.getId();
} catch (Exception e)
{
e.printStackTrace();
try
{
myTransaction.rollback();
} catch (Exception e2)
{
// Silent failure of transaction rollback
}
} finally
{
try
{
hibernateSession.close();
} catch (Exception e2)
{
// Silent failure of session close
}
}
}
}
When run, the application produces output similar to that shown in Listing 6.11. You may wish to compare the values below to the results of the application as run on your system to verify aspects of identity as described earlier in the chapter. In addition, note the various validation and life-cycle method notifications, and compare the messages echoed to the state of the objects as they correspond to the source shown in Listing 6.9 and Listing 6.10. Finally, you may wish to change the identity and generator values of the Message object to see how different systems implement identity.
Example 6.11. Results of the Identity Test Suite
initialization createMessage JVM:com.cascadetg.ch06.Message@484861a2, KEY:8a8092dcfbf4fd0100fbf4fd05eb0001 HASH