


Transparent cloud tiering
In this chapter, we extend the tiering process a step further. We add another tier, which is the cloud.
Good storage management practices are based on the principle that physical space often is configured in logical pools that can be dynamically reconfigured to increase or decrease the storage capacity that is available for use. This reconfiguration should also be transparent to the user.
Storage Cloud on mainframes introduces a new storage tier that can be exploited to provide extended storage capacity at a lower cost while making the data available from different locations.
This chapter includes the following topics:
3.1 Types of storage
Before you start using storage clouds, it is necessary to understand what a gateway is, its function, and how the data is managed between the mainframe and the cloud.
The following types of architectures (see Figure 3-1) can be used for storing data, where each type has its advantages:
•Block and File: This architecture is used on mainframes and other operating systems to store data. It has the advantages of being faster, IOPS-centric, flash-optimized, and allows various approaches.
•Object Storage: This architecture provides larger storage environments, or cool/cold data, which can scale to petabytes of data while being cloud-compatible.

Figure 3-1 Types of storage
Having a storage cloud that uses object storages significantly reduces the complexity of storage systems by simplifying data scaling within a single namespace, and the use of REST protocol for communication between the server and the client. The use of high-density, low-cost commodity hardware turns storage clouds into a scalable, cost-efficient storage.
The transparent cloud tiering function from the DS8880 provides a gateway that is necessary to convert the block to Object Storage to be stored on private or public clouds.
On storage clouds, the data is managed as objects, unlike other architectures that manage data as a block of storage as it is done on mainframes. For that reason, the communication between mainframe systems and storage cloud is done by a gateway that is responsible for converting cloud storage APIs, such as SOAP or REST, to block-based protocols, such as iSCSI or Fibre Channel, when necessary.
Therefore, the storage cloud can be considered an auxiliary storage for mainframe systems to be used by applications, such as DFSMShsm, to migrate and recall data sets, or DFSMSdss to store data that is generated by using the DUMP command.
3.2 Object Storage hierarchy
Data that is written to a cloud by using transparent cloud tiering is stored as objects and organized into a hierarchy. The hierarchy consists of accounts, containers, and objects. An account can feature one or more containers and a container can include zero or more objects.
3.2.1 Storage cloud hierarchy
The storage cloud hierarchy consists of the following entities:
•Account
•Containers
•Objects
Each entity plays a specific role on data store, list, and retrieval by providing a namespace, the space for storage, or the objects. There also are different types of objects, data, and metadata.
A sample cloud hierarchy structure is shown in Figure 3-2.

Figure 3-2 Cloud hierarchy
Each storage cloud component is described next.
Account
An account is the top level of the hierarchy and is created by the service provider, but owned by the consumer. Accounts can also be referred to as projects or tenants and provide a namespace for the containers. An account has an owner that is associated with it and the owner of the account has full access to all the containers and objects within the account.
The following operations can be performed from an account:
•List containers
•Create, update, or delete account metadata
•Show account metadata
Containers
Containers (or buckets) are similar to folders in Windows or UNIX, but one main difference is that containers cannot be nested. That is, no support is available for creating a container within another container. Container names can be 256 bytes and provide an area to organize and store objects, container-to-container synchronization, quotas, and object versioning.
|
Note: A container cannot be nested.
|
Access to objects within a container are protected by using read and write Access Control Lists (ACLs). There is no security mechanism to protect an individual object within a container. After a user is granted access to a container, that user can access all of the objects within that container.
The following operations are supported for containers:
•List objects
•Create container
•Delete container
•Create, update, or delete container metadata
•Show container metadata
Objects
As of this writing, there is a 5 GB limit to the size of an object. Data larger than 5 GB must be broken up and stored by using multiple segment objects. After all of the segment objects are stored, a manifest object is created to piece all of the segments together. When a large object is retrieved, the manifest object is supplied and the Object Storage service concatenates all of the segments and returns them to the requester.
The following operations are supported for objects:
•Read object
•Create or replace object
•Copy object
•Delete object
•Show object metadata
•Create, update, or delete object metadata
The objects can also have a defined, individual expiration date. The expiration dates can be set when an object is stored and modified by updating the object metadata. When the expiration date is reached, the object and its metadata are automatically deleted.
However, the expiration does not update information about the z/OS host; therefore, DFSMShsm and DFSMSdss do not use this feature. Instead, DFSMShsm handles the expiration of objects.
User-created backups (backups that are created outside of DFSMShsm to the cloud must be managed by the user. Therefore, a user must go out to a cloud and manually delete backups that are no longer valid. At present, this process is not recommended.
3.2.2 Metadata
In addition to the objects, metadata is recorded for account, container, and object information. Metadata consists of data that contains information about the stored data. Some metadata information might include data creation and expiration date, size, owner, last access, and other pertinent information.
The difference between data and metadata is shown in Figure 3-3.

Figure 3-3 Data and metadata differences
z/OS accesses the metadata and the data by using a gateway. The gateway is software-based and is the enabler for transparent cloud tiering.
3.3 Storage cloud communication
The communication between the mainframe and the cloud should be done by using a Representational State Transfer (REST)ful interface. REST is a lightweight, scalable protocol that uses the HTTP standard. A toolkit was shipped by using an APAR and is available on z/OS V2R1 and above. It supports secure, HTTPS communication between endpoints by using the Secure Sockets Layer (SSL) protocol or the Transport Layer Security (TLS) protocol.
The z/OS Web Enablement Toolkit provides the following sets of APIs that are necessary to establish communication:
•HTTP/HTTPS protocol enabler
•Java Script Object Notation (JSON) parser
|
Note: JSON is an open standard for exchanging data between two endpoints. It supports only a few simple data types and organizes the data in a set of {name,value} pairs.
|
The JSON parser is a set of APIs that allow applications on z/OS to search for specific names and get the corresponding values from the output that is returned by a server.
The HTTP/HTTPS protocol enabler allows applications on z/OS to connect to a server, build an HTTP request, submit the request, receive a response, and disconnect from a server. Multiple requests can be sent while a connection to a server is active.
The responses from a web server can be returned in different formats. It is the application that is issuing the requests that specify the return responses in a particular format.
An HTTP response can be returned as plain text, which is considered an unstructured string of bytes. It also can be returned in a more structured format that is called JSON. The toolkit supplies a set of APIs to handle the structured data that is returned as a response to an HTTP request. This set is called the JSON parser.
DFSMS then uses the z/OS Web Enablement Toolkit to communicate directly with an Object Storage server to perform the following tasks:
•Create containers: An application can create containers in an account by using the PUT method.
•Delete containers: An application can delete containers from an account by using the DELETE method.
•List objects in a container: An application can list objects within a particular container by using the GET method.
•Store objects: An application can store data as an object in an object store by using the PUT method.
•Retrieve objects: An application can retrieve an object from an object store by using the GET method.
•Delete objects: An application can delete objects from a container using the DELETE method.
The Web Enablement Toolkit is used to create, list, and delete containers and store and retrieve metadata. The transparent cloud tiering is responsible for storing and retrieving data from the cloud.
Figure 3-4 shows the relationship between the DFSMS, Web Enablement Toolkit, transparent cloud tiering, and the cloud.
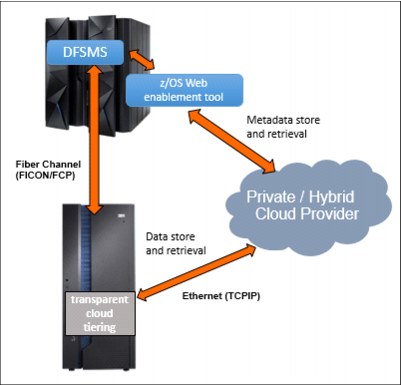
Figure 3-4 Cloud communication paths
The security in communication between the mainframe and the cloud is provided by using a user ID and password combination. Although the password is not included in DFSMS Cloud constructs, it is used by DFSMShsm and DFSMSdss to perform store and recovery tasks from the cloud.
Although DFSMShsm stores an encrypted version of the password in its control data sets (CDSs) for use when migrating and recalling data, DFSMSdss requires the user ID and password to be included on JCL when DUMP and RESTORE functions are performed manually.
|
Note: Any users with access to the user ID and password to the cloud have full access to the data from z/OS or other systems perspective. Ensure that only authorized and required personnel can access this information.
|
For more information about security and user ID and password administration for DFSMShsm, see Chapter 8, “Operational integration considerations” on page 61.
3.3.1 Missing interrupt considerations
Storing data sets in and retrieving data sets from the cloud poses an interesting question about missing interrupt values because the response time of a network access is much slower than the response time of an IBM FICON® attached DASD or tape.
An I/O response time’s duration might be so long that if the software were to require that control not be returned by the storage subsystem until the store or retrieve is complete, a Missing Interrupt Handler (MIH) value is exceeded; therefore, normal MIH is affected.
The MIH timeout value can be set to a higher value, but the amount of time to transfer a large data set can be many minutes. There are also various external factors, such as heavy network traffic or routing issues, that can influence the response time of the network.
|
Note: The maximum MIH value is 255 seconds. IOSXTIME is a 1-byte field.
|
In this solution, the DS8880 returns Control End and Device End (CE/DE) conditions after accepting the cloud-related command and requesting software must deploy a mechanism to detect that the operation is complete. The following approaches can be used to accomplish this task:
•Implement a polling mechanism in software to periodically check whether the operation is complete.
The advantage of a polling mechanism is that software is guaranteed to receive an acknowledgment (positive or negative) from the storage subsystem whenever it makes a query to determine whether the data set is stored in or retrieved from the cloud.
The disadvantage or challenge is defining an appropriate polling interval. Defining too short of an interval introduces extra overhead because of excessive polling. But, defining too long of an interval causes the responsiveness of software to be affected.
•Queue a request and handle an attention interrupt that is raised by the DS8880 storage subsystem.
The advantage of the attention interrupt approach is that there is no overhead that is incurred as there is with a polling approach.
The disadvantage of an attention interrupt approach is that it might go unnoticed by software. Cases also occur in which an attention interrupt might never be raised by the storage subsystem.
•A hybrid approach that uses a combination of attention interrupts and polling.
If an attention interrupt is not raised after a specific time, software can poll the DS8880 to check the status of a request. The advantage of this hybrid approach is that an attention that might be missed can be discovered by using the polling mechanism. Also, it avoids excessive polling.
In this solution, access to cloud objects by using the IBM DS8000® are asynchronous. Software uses the AOM infrastructure to handle asynchronous operations of the DS8880, which implements the hybrid approach. This infrastructure has been in use for decades and is used for asynchronous operations in the DS8880 and the TS7700.
It is a proven and successful asynchronous processing mechanism for commands that require response only after completion. Although the low-level software interfaces into the DS8000 are asynchronous, higher-level APIs provide options to perform requests synchronously or asynchronously
3.4 Storing and retrieving data by using DFSMS
From a z/OS perspective, the storage cloud is considered an auxiliary storage, but unlike tapes, they do not provide a block level I/O interface. Instead, they provide only a simple get-and-put interface that works at the object level.
When data sets are stored in the cloud, the number of objects that are created varies depending on the data set attributes (multi-volume, data set size, and VSAM), and the metadata that is created. For each volume a data set is on, a new object is created within the container. One or more metadata objects are also created in the same container.
DFSMSdss can be used to store logical dumps and restore data sets from the cloud. It also is used as the data mover by DFSMShsm when data is migrated or recalled from cloud. In each case, the number of objects that is created can vary, based on the following factors:
•The number of volumes the data set is on. For each volume the data set is stored on, a new object is created.
•The size of the data set. As of this writing, an object is limited to 5 GB. Larger data sets are automatically broken up in 5 GB segments and each segment is stored in an object. When retrieving objects larger than 5 GB, the DS8000 automatically combines them without any effect on software.
•VSAM data sets. When VSAM data sets are migrated to cloud, each component has its own object, meaning a key-sequenced data set (KSDS) has at least one object for the data component and another for the Index. The same concept is applied to alternative indexes.
Also, several metadata objects are created to store information about the data set and application. Table 3-1 lists some objects that are created as part of the DFSMSdss dump process.
Table 3-1 Created objects
|
Object name
|
Description
|
|
Objectprefix/HDR
|
Metadata object that contains ADRTAPB
prefix.
|
|
objectprefix/DTPDSNLnnnnnnn
|
n = list sequence in hexadecimal. Metadata object that contains a list of data set names successfully dumped.
Note: This object differs from dump processing that uses OUTDD where the list consists of possibly dumped data sets. For Cloud processing, this list includes data sets that were successfully dumped.
|
|
objectprefix/dsname/DTPDSHDR
|
Metadata object that contains data set dumped. If necessary, this object also contains DTCDFATT and DTDSAIR.
|
|
objectprefix/dsname/DTPVOLDnn/desc/META
|
Metadata object that contains attributes of the data set dumped:
•desc = descriptor
•NVSM = NONVSAM
•DATA = VSAM Data Component
•INDX = VSAM Index Component
•nn = volume sequence in decimal, 'nn' is determined from DTDNVOL field inDTDSHDR
|
|
objectprefix/dsname/DTPSPHDR
|
Metadata object that contains Sphere information. If necessary, this object also contains DTSAIXS, DTSINFO, and DTSPATHD.
Present if DTDSPER area in DTDSHDR is ON.
|
|
objectprefix/dsname/DTPVOLDnn/desc/EXTENTS
|
Data object. This object contains the data that is found within the extents for the source data set on a per volume basis:
•desc = descriptor
•NVSM = NONVSAM
•DATA = VSAM Data Component
•INDX = VSAM Index Component
|
|
objectprefix/dsname/APPMETA
|
Application metadata object that is provided by application in EIOPTION31 and provided to application in EIOPTION32.
|
After the DSS metadata objects are stored, the data objects are stored by using DS8880 transparent cloud tiering. The data object consists of the extents of the data set that are on the source volume. This process is repeated for every source volume where the data set is stored.
After all volumes for a data set are processed (where DSS successfully stored all the necessary metadata and data objects), DSS stores the application metadata object. DFSMSdss supports one application metadata object for each data set that is backed up.
Because data movement is offloaded to the DS8880, a data set cannot be manipulated as it is dumped or restored. For example, DFSMSdss cannot perform validation processing for indexed VSAM data sets, compress a PDS on RESTORE, nor reblock data sets while it is being dumped.
At the time of this writing, no compression or encryption is performed on DS8000 during data migration. If your data is compressed or encrypted (by zEDC or other technology) when it was allocated on the DS8000, the data is offloaded to cloud as is (compressed or encrypted).
If you attempt to create an object prefix that exists within a container, DFSMSdss fails the DUMP to prevent the data from being overwritten.
|
Note: At the time of this writing, only simplex volumes are eligible to migrate to cloud. Therefore, data sets cannot be recalled or restored to extents that are part of an IBM FlashCopy® or replication relationship.
|
When data sets are retrieved from the storage cloud, the DS8000 automatically combines segments if the original data set was larger than 5 GB. The extent reduction also is performed, when possible.
3.5 Selecting data for storage cloud
When you decide to implement a storage cloud, you also must plan for who can use this cloud and the type of data that you want to store. Defining correct data to be offloaded to cloud gives you more on-premises storage to allocate other critical data.
A described in this chapter, cloud should be considered an auxiliary storage within a z/OS system, meaning that no data that requires online or immediate access should be moved to cloud. Also, only simplex volumes are eligible to have their data sets moved to cloud. Any attempt to move data sets on a duplex volume to cloud fails.
Because no Object Storage data is cataloged or automatically deleted (except for DFSMShsm-owned objects), it is suggested to proceed with caution when deciding which users can dump and restore their data sets from cloud. If any users decide to use the cloud, they must manually housekeep and delete the storage objects and containers that are created by them.
For this reason, one of the main exploiters of storage cloud is DFSMShsm, which maintains DFSMShsm created containers and objects information in its control data sets and can retrieve or expire in its control data sets and can automatically retrieve and expire the objects that are associated with data sets that are migrated to cloud storage.
As of this writing, DFSMShsm does not automatically delete cloud containers when they become empty. Instead, empty containers are deleted by using an external tool.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.