
Lotus Connections follows a consistent multitiered architecture across all six of its services. This statement holds true both from a physical deployment topology and in regard to its service-oriented architecture. The former provides a loose coupling between physical layers, enabling the flexibility necessary in large-scale deployments to make independent decisions with regard to platform, hardware, and security zones. The latter enables a compelling presentation while still allowing the creation of ad hoc business mashups to meet the unique needs of each deployment. This chapter will take you through the Lotus Connections architecture and how it fits in a large deployment ecosystem.
A physically tiered deployment topology is usually made up of a front-end web tier, a middle or application server tier, and a back-end or data tier. Lotus Connections will leverage each of these tiers and to varying degrees of complexity based on deployment needs. Within each tier is a set of hardware and software platform choices from various vendors. These choices at each tier allow for a Lotus Connections deployment that can fit into existing infrastructure and match the skills of an IT organization. Figure 3.1 provides an overview of the available software options.

In this section, we’ll discuss several back-end services utilized by Lotus Connections, including your user directory, Tivoli Directory Integrator, relational databases, and the file system. We will cover both deployment and configuration options for each.
At the back end, each deployment requires some form of a user directory. This can be as simple as leveraging an embedded file-based repository to support a pilot deployment and as complex as enabling a mix of multiple corporate LDAP subtrees. Lotus Connections leverages the WebSphere Application Server federated repository functionality to provide this support. The list of directories supported by Lotus Connections includes Sun Java System Directory Server 5.2, SunOne 6, IBM Lotus Domino® Versions 7.0.2 and 8, Microsoft Active Directory 2003 SP2, Microsoft ADAM, IBM Tivoli Directory Server 6.0.0.3 and 6.1, and Novell eDirectory 8.8. Each of these directories does not have an individual listing in the WebSphere federated repository directory type selector but rather should be mapped to the selections detailed in Table 3.1.
Table 3.1. Mapping of Supported Directories to WebSphere Federated Repository Director Selector
LDAP Server | Federated Repository Directory Type |
|---|---|
Sun Java System Directory Server 5.2 | Sun ONE |
SunOne 6 | Sun ONE |
IBM Lotus Domino 7.0.2 | IBM Lotus Domino Version 6.5 |
IBM Lotus Domino 8 | IBM Lotus Domino Version 6.5 |
Microsoft Active Directory 2003 SP2 | Microsoft Windows Server 2003 Active Directory |
Microsoft ADAM | Microsoft Windows Server 2003 Active Directory |
IBM Tivoli Directory Server 6.0.0.3 | IBM Tivoli Directory Server Version 6 |
IBM Tivoli Directory Server 6.1 | IBM Tivoli Directory Server Version 6 |
Novell eDirectory 8.8 | Novell eDirectory 8.8 |
Once configured, the directory information is leveraged for two purposes within Lotus Connections. The first purpose is authentication and authorization. The second is user profile metadata. In all cases, your LDAP server will be used to verify user credentials, but it is not required that all user metadata resides in this same directory server that was selected from Table 3.1. In complex deployment scenarios in large organizations, the realities of a directory topology necessitate the flexibility to be able to retrieve user profile metadata from alternate repositories including secondary directories, CRM systems, and proprietary storage databases. An important service that Lotus Connections brings to a production deployment is the ability to collect and surface this user information seamlessly from all of these sources, open or propriety, through standard and custom TDI production lines. More on these production lines is discussed in the following section.
If your directory information does not live in a single traditional directory, Lotus Connections Profiles will offer the necessary glue to roll out each of the social software services available in Lotus Connections and enable your organization to build additional Web 2.0 applications that require a unified user repository available through modern REST-based access techniques. In addition, Profiles and the other Lotus Connections services can supplement your directory information with critical social network data about your employees to maximize your annual investment in human capital by exposing cross-team collaborations patterns such as related colleagues. This enables your organization to quickly find people by keywords, projects, expertise, location, and many other criteria. Even in the simplest of directory topologies, Profiles can provide a highly scalable single source of user profile data.
In Figure 3.2, you are presented with a flow diagram that illustrates the communication flow between each of the Lotus Connections services and the underlying Lotus Connections directory infrastructure. The complexities of a directory topology are isolated in the center diamond, shown in the diagram as WPI (which stands for Waltz-Profiles Integration).

In the world of dance, the waltz is famous for its smooth, gliding steps, which in their simplest form even novice dancers can pick up, but when advanced steps are used, significant training and experience are required. Lotus Connections named this layer Waltz for that very reason. With Profiles integration, Waltz can ensure seamless handling of user metadata for both entry-level and complex deployments. In its most basic rollout, no additional configuration is required beyond setting up standard WebSphere security settings for user authentication and authorization. Waltz will communicate with this same directory for user metadata by introspecting these settings and leveraging WebSphere Federated Repositories for the data. For more demanding environments, Waltz can leverage Lotus Connections Profiles and its directory extensions. This setting enables the collection of user metadata from various alternate sources. Following is a sample configuration setting that instructs Waltz to communicate with Profiles for user metadata:
<sloc:serviceReference serviceName="directory"
waltz_profiles_integration_href="http://example.com/profiles/dsx/"
waltz_profiles_integration_enabled="true"
...
/>By enabling Waltz to leverage Profiles as its user data repository, Lotus Connections can unify multiple underlying data sources to provide a highly scalable single point of access. This approach offloads the demands of a new breed of Web 2.0 social applications that are thirsty for user data that has previously been served by your traditional directory backbone. In addition to serving user data to Lotus Connections services, the Profiles REST APIs can provide other applications with this same information. This support is provided via a rich set of feeds over HTTP using an Atom 1.0–compliant XML response format. More details on these APIs are described later in this book, and formal documentation can be found on the IBM InfoCenter website for Lotus Connections.
In deployments containing Profiles and the Profiles directory service extensions, Tivoli Directory Integrator will manage the synchronization of user information between the Profiles database and the underlying directory sources. This process can be either one-way (from the directory to the Profiles database) or two-way. Two-way synchronization allows changes on administrative designated attributes to get pushed back into the originating repository. This process is managed by a TDI solution containing assembly lines. An assembly line is nothing more than piecing together smaller executable units to make up a more meaningful work unit that is performed repeatedly on individual items provided by one or more source connectors. In this case, the source connector is the directory and the work items are user records from this directory. The assembly line operates on these individual records, ultimately delivering them to Profiles, the destination output connector. The operations performed on these records are determined by the custom flow controls as stated in your assembly line descriptor (that is, loops, branches, and switches) and via embedded script elements to manipulate the data attributes. This process can collect data from additional sources, join attributes, and compute new ones, with the net output being a work item that conforms to the Profiles required data schema.
The complexity of an assembly line will vary depending on your deployment needs. Out of the box, Profiles will provide assembly lines for both one- and two-way synchronization with one or more LDAP repositories. There are also assembly lines to allow for supplemental information provided from CSV files. The default solution containing each of these assembly lines can be run as a one-off execution, providing the initial population via a population wizard. This wizard provides a simple means to specify connection information to both the database and the LDAP repository, as well as specify custom attribute mappings and JavaScript functions. This process can be executed via the wizard user interface or via manual scripts. For continued synchronization of changes in your directory with the Profiles database, you can again leverage the out-of-the-box assemblies to execute as a scheduled task, either through the TDI interface or via the operating system. Two-way synchronization is performed by keeping track of what has changed in both your source and your destination repository since the last synchronization and replaying these changes. The Profiles’ data repository provides this capability using a look-aside table that is later flushed back to the source directory. Profiles can provide a uniform approach for synchronizing almost any type of source repository. Each scheduled synchronization will create a custom hash of available source records, identify them by a unique key, and group them into page sizes that it is able to process in memory. Each grouping is then processed using a comparison algorithm for relevant attributes, and each record that has changed since the last synchronization is updated. This approach enables synchronization with almost any source repository and greatly simplifies the complexities introduced by the varying degrees of support that each vendor’s source repository change logs provide. For more complex deployments that integrate with non LDAP directories, custom assembly lines are necessary. In these cases, it is possible to extend an existing assembly line or build your own custom assembly from scratch. Since TDI assembly lines are fully customizable with regard to workflow, connectors, and data manipulation via custom hooks, the possibilities are endless when it comes to pulling data from your non-LDAP sources. TDI eases such integration by providing prebuilt connectors for many popular enterprise systems. For those systems without existing prebuilt connectors, plumbing for low-level transport protocols is also made available through various programming languages.
In setting up Lotus Connections with your directory infrastructure, one important aspect to consider is your choice in an appropriate globally unique user identifying key from your directory. This key is used by the Lotus Connection services to uniquely identify each user in the system. This key is consumed by the running TDI assembly line and fed into Profiles, which later serves up this same key through Waltz and into each of the other Connections service databases. After the key is stored in the Lotus Connections repository, it ensures that user data is always associated with a single user regardless of changes over time to other identifying attributes, such as an email address or a login name. This identifier must meet three key characteristics to fill this role:
Each LDAP repository provides a single LDAP attribute that is guaranteed to meet the first two criteria, and, if the directory entries are properly maintained, it can also meet the third criteria. The first release of Lotus Connections utilized this default attribute provided by each directory for maintaining the association of user data to an individual. This approach safely guaranteed the desired characteristics in most deployments, but in some cases the nonmutable characteristic of this ID was not maintained in practice. In organizations that use a custom LDAP attribute as a globally unique identifier, they might choose to freely insert and remove directory records for an individual user without worrying about the maintenance of the directory’s default ID. These actions will break the nonmutable characteristic that is required of a GUID and is the reason they maintain an alternate custom attribute. With this in mind, Lotus Connections in release 2.0 added additional support to allow the selection of custom LDAP attributes as the globally unique identifier for users. If your organization does not maintain an alternate identifier, you should continue to use the default GUID for your LDAP. Table 3.2 lists the default identifiers provided by each supported LDAP repository.
Table 3.2. Default Global Identifiers for Each Supported LDAP Repository
Directory | Default GUID |
|---|---|
IBM Tivoli Directory Server |
|
Microsoft Active Directory |
|
Microsoft Active Directory Application Mode (ADAM) |
|
IBM Domino Enterprise Server |
|
Sun Java System Directory Server |
|
eNovell Directory Server |
|
When you’re choosing to use a default identifier as listed in Table 3.2, it is important to ensure that each user’s directory records will be properly maintained so that new IDs are not inadvertently generated for an existing user. Changes to this identifier will result in a break in the linkage between a user’s identity and his or her associated data throughout Lotus Connections. If this happens, it can get resolved via administrative commands, but in general it is important that each deployment chooses a GUID that doesn’t violate this constraint often. When it is violated, end users will experience a time-window during which they cannot access the Lotus Connections services until the GUID is resynchronized using the administrative facilities. If your organizational policies for LDAP administration result in behaviors that don’t respect the default GUID in your LDAP (such as removing and reinserting directory objects for an individual), we recommend the selection of an alternate GUID that maps to what your organization is able to maintain as a truly permanent and globally unique identifier.
Selecting a unique identifier first requires a change to your Federated Repositories configuration. Using a text editor and the Federated Repositories wimconfig.xml found in the deployments cell-scoped configuration directory under the folders /wim/config, you can look for the line containing the <config:repositories> element and add to the <config:attributeConfiguration> block your custom GUID. The snippet would look as follows:
<config:externalIdAttributes name="<custom_attribute>"
syntax="<attribute_syntax>"/>The syntax attribute on the externalIdAttributes tag is necessary only if the chosen attribute name contains values other than a string, such as an octetString. If this value is changed, it is important to keep in mind that this will also require updates to the Profiles service field mappings for TDI synchronization, and when setting up and configuring Waltz in your LotusConnections-Config.xml. If existing data resides in your Lotus Connections servers, you will also need to invoke the administrative commands to resync all existing user GUIDs with the updating settings.
In choosing any identifier (custom or default), the populating functions for the Profiles TDI scripts need to match the appropriate LDAP syntax. Table 3.3 provides the syntax used for each directory’s default id and the corresponding TDI script function for processing that format.
Table 3.3. Default LDAP GUID Syntax and Corresponding TDI Script Functions
Directory | LDAP Syntax | TDI Script Functions |
|---|---|---|
IBM Tivoli Directory Server | Canonical | n/a |
Microsoft Active Directory | Octet |
|
Microsoft Active Directory Application Mode (ADAM) | Octet |
|
IBM Domino Enterprise Server | Byte |
|
Sun Java System Directory Server | Canonical | n/a |
eNovell Directory Server | Octet |
|
Waltz does not require any specific configuration settings when a default LDAP attribute is used for the system GUID since it can derive this value from the chosen directory configuration, but it will require knowledge of any custom user and group attributes. When using a custom user or group attribute, you must update the LotusConnections-Config.xml directory service references, found in the LotusConnections-Config.xml with the chosen attribute names:
<sloc:serviceReference serviceName="directory" ...... custom_user_id_attribute="customUserID" custom_group_id_attribute="customGroupID" />
With this flexibility to choose a default or custom attribute as a unique GUID, Lotus Connections can seamlessly identify individual users regardless of changes to other secondary user identifying attributes. Starting in 2.0.1, the Lotus Connections API can also support mashups with other applications that identify users by this GUID.
Another important aspect to the data tier of a Lotus Connections deployment is the underlying persistence model. Lotus Connections requires the use of a relational database as its primary storage medium but also relies on file system storage where appropriate. The deployment topology of the Lotus Connections relational database tables can be as small as a single physical machine and database instance but is expandable to as many as six physical database servers and corresponding instances, along with matching passive servers for HA redundancy. The Lotus Connections database tables are horizontally divided so that each service has its own set of tables associated with it via a unique schema. Since each of the six services has its own schema and database tables, you can utilize planned and actual utilization rates at the service level to split out workload across new machines where necessary. You can also selectively scale individual machines with additional hardware resources based on the usage characteristics for each service.
The recommended physical split of database tables across machines will vary depending on many characteristics, including the type of hardware available and the amount of expected user traffic. A machine with only two cores should not host all six services’ database tables in a high-throughput environment, but a machine with additional cores might adequately handle such a configuration, assuming that best practices for RAID disk IO and memory configurations are followed. High-level sizing guidelines are made available by IBM to help pick an initial deployment topology to meet your needs, but ultimately many factors prevent this choice from being an exact science. For example, a well-tuned disk infrastructure with an allocation of separate RAID disk clusters for the tablespaces, indexes, and logs will experience higher throughput than a deployment constrained by shared read/write heads.
Another service-level configuration is the JNDI resource pools. Since each Lotus Connections service can maintain isolated non-XA transactions, the installer will create six JNDI resource pools. This approach allows for improved performance by the reuse of shared connections at the service level and independent tuning of pool sizes for each of the services while keeping the possibility of separating database tables across multiple physical database instances. Tuning each connection pool is an important aspect to ensure optimal response times because an improperly tuned environment might mean unnecessary time spent waiting for a free connection. Setting the pool sizes large enough will eliminate this risk, but it is also important to respect the overall system resources on the application server by not setting this value higher than necessary for the expected peak workloads. Increasing the default value of 10 connections to 50 is a safe assumption for any size of deployment and should not have a negative impact on overall system resources. Tuning to higher values, such as between 75 and 150 connections, might be needed to support maximum load for some of the components in a large deployment, but as you tune these values higher, keep an eye on overall memory consumption to ensure that your system is able to provide the necessary memory allocations without excessive paging. Increasing the default prepared statement cache size from 10 to a value closer to 100 is also recommended. If an individual WebSphere node cannot handle the required increased allocations, additional server nodes can be added to a cluster for supporting this user traffic. More details on adding WebSphere nodes are covered in the Tier 2 section of this chapter.
It is always important to keep in mind that the settings discussed in this chapter are only a few of the many variables that will require adjusting to provide optimal performance. By the nature of a relational database, administration and maintenance are very important for the continued operation of your applications. Utilizing a database platform that matches the skill set of your database administrators will greatly ease this process. For this reason, we fully support three database vendor platforms:
IBM DB2 9.1 fp 4 Enterprise Edition
Oracle 10G Release 2 (10.2.0.3)
Microsoft SQL 2005 Enterprise (SP2)
Each platform, although functionally equivalent to the others, will require different procedures with regard to index maintenance, backup and restore, and data integrity. The Lotus Connections installation package provides a set of utilities to automate the creation of database tables, users, indexes, and maintenance schedules for all three platforms based on recommended configuration settings determined by the system verification and performance analysis teams at IBM. The installer also provides utilities to enable migration of existing data sets across database vendors, allowing the migration of pilot evaluations into full-fledged production deployments without loss of user data.
The database wizard provided with the Lotus Connections installer will create a separate database per component when using DB2. This is recommended to allow for tuning of each service even if all the databases are deployed on the same physical box running in a single database instance. Multiple instances are also recommended when running on 32-bit operating systems to ensure full utilization of available system resources. During installation and setup of DB2, you will create a db2admin account that requires a corresponding operating system account. Although db2admin will work, the installation scripts for Lotus Connections will encourage the use of an LCUSER account for connecting the application servers to each database. This will ensure that the minimal set of necessary permissions are assigned to this user and reduce security exposures that could result from malicious end-user attacks. After installation, you will find six distinct databases, each with a corresponding schema. Table 3.4 lists the details of each of these databases.
To help maintain optimal performance, basic maintenance scripts are shipped with the Lotus Connections installer. When these scripts are run, they will optimize index statistics on each of these component databases and periodically restructure the database to avoid disk defragmentation. It is critical that the provided runstats.sql script for each of the component databases is run on a regular basis, and it is highly recommended that you set up a system task to run it on a schedule. It is not necessary to stop any services while performing runstats. Without proper index statistics, DB2 will likely choose inefficient query plans, resulting in unnecessary CPU and memory consumption, severely limiting system performance. When upgrading from Lotus Connections 1.0 to Lotus Connections 2.0, be sure to upgrade your system tasks to run the latest runstats.sql files that shipped with the Lotus Connections 2.0 installer.
The default setup for Oracle is a single database with a schema created for each component. In Oracle, the schema is equivalent to the concept of a username. If desired, it is possible to separate the schemas and corresponding tables across multiple database instances by configuring each of the separate application server data sources to connect to the appropriate database server. When using the database creation wizard for Lotus Connections, you will be asked for a database instance name; provide it with the name of an existing database instance and select which feature databases you would like to install to this instance. You can rerun the wizard to install additional feature databases to a different database instance. An operating system account is not required by oracle for each schema; instead, the oracle user account doubles as the schema. Table 3.5 provides a list of the resulting schemas for each of the Connections services.
Oracle, much like DB2, requires regular maintenance of its index statistics, but such facilities have been integrated into the Oracle job scheduler. One such job, GATHER_STATS_JOB, is created by Oracle when your database instance is created. Also during the database creation steps, the database wizard will create a second job required by Dogear for optimal query performance against its TAG and LINK tables. This job will be found in the same “Scheduler Jobs” section of the Oracle admin console and will be called DOGEAR_HISTO_STATS_JOB. This job will get assigned to the SYS.MAINTENANCE_WINDOW_GROUP. It is important to ensure that both jobs are enabled and running with regular maintenance windows that make sense for your deployment. These jobs will ensure proper index statistics for optimal query-plan generation. The impact of improper query plans due to out-of-date statistics on overall system performance is severe and will hamper a deployment if not managed properly. The good news is that these automated tasks should take care of keeping your statistics up-to-date.
Much like DB2, the default setup for SQL Server is a single server instance with a database created per component. As with the other platforms, it is also safe to relocate databases across multiple server instances where desired. As shown in Table 3.6, the component database names and schemas are the same as in DB2, but since SQL Server does not require system accounts for users, each component has a specific database user that is created for use with only that database.
SQL Server also requires index statistic maintenance and provides an automatic statistics facility to perform this task. Depending on how your server is configured, you might need to run UPDATE STATISTICS manually or adjust the sampling rate to improve overall accuracy of the system statistics.
File System storage is used by all the services in Lotus Connections for purposes for which storage in a relational database is not appropriate. In many cases, this is secondary storage, such as an optimized search index on data already persistent in the relational database. Such an index can get rebuilt at any point so no backup policy is necessary. In some cases, the file system is used as primary storage for large files. The use of the file system for large files provides deployments with the flexibility to leverage existing low-cost, high-bandwidth file storage architectures and was determined to be the best choice to maximize overall system performance and minimize resource contention in these specific scenarios.
The file system is frequently used across the Lotus Connections services to provide optimal performance characteristics for queries that don’t work well in a relational storage model. For each service except Activities, you will find that the file system is used for a full-text search index. This inverted index is generated based on a crawl of the underlying data repositories, and the information is reformatted to optimize for high throughput of free text queries. Each of the system components will provide a means to regenerate these indexes if corrupt or lost; therefore, regular backup is not necessary to ensure data integrity but periodic backup is recommended to minimize regeneration time.
Some services also leverage the local file system to cache fast data retrieval of objects that appear frequently on the page. For example, the Dogear’s favicon service allows for an efficient rendering of site-specific icons next to each bookmark. This service ensures that page rendering does not rely on a high-bandwidth connection back to each of the original host servers for each displayed icon. This storage is designed to be self-healing if the icons are removed or become outdated.
Activities, Blogs, and Community Discussion Forums each leverage the file system as a primary storage medium for file attachments and extended descriptions. This approach does not require the files to be co-located with the physical box but does insist on them being available locally via a remote mount or network file share. Unlike the secondary storage approach, these files are stored only on the file system, and therefore it is important that they are accounted for in your overall system backup strategy. Lotus Connections does not ship with any tools for backup of your local file systems because it is expected that each organization will already have practices in place that range from a simple tool for incremental file transfer such as rsync to a more comprehensive solution such as Tivoli Storage Manager.
The application and service tier for Lotus Connections is built on IBM’s WebSphere Application Server technology. Utilizing the WAS J2EE container enables Lotus Connections to leverage a proven and highly scalable middleware backbone as a means to support the necessary complex deployment topologies, system availability, and serviceability requirements that are expected of an enterprise-class product offering.
A simple deployment includes a standalone server that runs in a single JVM. This server is self-managed and offers a means to get a deployment off the ground quickly. Such a deployment is possible with our Pilot installer. This installer sets up Lotus Connections, the application server, and all system prerequisites in a standalone environment for a quick and easy evaluation of our functional characteristics.
When you’re planning a production, staging, or advanced pilot deployment, numerous choices are available to ensure that your setup can sustain expected peak load scenarios and grow with your user base. Lotus Connections’ use of IBM’s WebSphere platform will provide a means to federate multiple server instances into a shared array of computing resources that is centrally managed from a single administration endpoint.
The Lotus Connections architecture provides for six well-defined functional units. Each of these units is capable of running as a standalone product, but, more important, they can seamlessly join together to provide the cross-functional synergies that are necessary for a complete social software platform. This flexibility in our component infrastructure allows for staged deployment strategies onto WebSphere that can minimize overall time to value, ease user adoption, and allow for highly flexible deployment topologies that can federate multiple clusters of nodes on shared or dedicated hardware.
Before diving too deeply into the detailed deployment topologies for Lotus Connections, we need to cover some basics on how WebSphere supports different configurations. First and foremost, when we discuss the deployment of individual Lotus Connections services to server instances, it has nothing to do with the physical server or hardware, but rather the WebSphere server runtime. A single physical box can run multiple WebSphere server instances concurrently, and the number of server instances you should deploy to any given box might vary based on the physical system resources, expected user load, desired redundancy characteristics, and many other factors. All of these decisions are point-in-time statements that might change as your deployment grows.
Each server instances can run one or multiple Lotus Connections services. A typical deployment would put one connection service on each server instance, so installing all six services would create six server instances. Again, this might all still run on one physical box or span out to six physical boxes, depending on your hardware environment.
A compact deployment allows one to install all six Lotus Connections services on a single server instance and hence a single physical box. The compact model reduces overall memory consumption on this box (because only one server instance will start up) but reduces your flexibility to cluster and scale out individual Lotus Connections services across an array of machines.
In addition to a standard and a compact installation, you have the option to utilize a custom deployment topology that will allow you to split the six Lotus Connections services across any number of server instances (for example, three server instances, each with two services). Such a deployment topology might make sense if you are looking to scale out all six services at the same rate and want to conserve available system resources. The choice of how many services per server instance and which services coexist should be based on your expected usage patterns and available hardware.
Now that we have determined what a set of individual server instances might look like in your deployment (compact, typical, or custom), we can begin to think about how this choice fits into a production rollout. A production environment will likely raise many additional requirements, including a single point of administration, server redundancy, and supporting the demands of a larger user population. IBM WebSphere Application Server Network Deployment can provide the infrastructure necessary to meet these requirements.
When WebSphere Application Server ND is used, each of your deployed server instances can be added into a single cell with centralized management. As part of this cell, you get a deployment manager. This manager provides a single administrative console for maintaining configuration settings across all the server instances that have been federated. A second new concept in ND is that of a cluster. Think of a cluster as a virtual container. This container can have any number of server instances associated with it, but they all must be identical. That means if you have two server instances each running the same Lotus Connections services, you can federate them into a single cluster. This is a virtual association of a node to a cluster and does not require any changes in your physical topology. Initially your cluster will have one server instance, until you clone the server instance with a duplicate set of services deployed on it. After a cluster is set up to manage multiple identical nodes, WebSphere can seamlessly monitor the status of each of these nodes and utilize your defined policies for load balancing. As traffic arrives for a specific service, let’s say Profiles in this case, it will get served to any one of the available servers in the cluster that is currently hosting Profiles and is available for traffic. WebSphere will utilize your policy settings to determine which server can best handle this request and route the traffic accordingly. If a server goes down, all traffic will get routed to the other server instances in the cluster. Such a topology allows for seamless addition and removal of servers from a cluster without impacting your up time. Splitting the servers in a cluster across physical boxes provides additional redundancy that is necessary to ensure system availability.
Now going back to when we chose which deployment topology (compact, typical, or custom) earlier in this section, we were determining how many functional services should run on a single server instance, and this could span from one per instance to all six on the same instance. With the introduction of clusters, we can begin to see the impact of this decision. As new hardware is brought into the environment, if all six services are running on a single server instance, clustering this server instance will require all six services to run on each new machine. If you add four boxes, you now have all six services running on all four boxes. This is likely not ideal versus having a deployment in which each service is running on two of the four boxes with each box needing to handle only three of the services.
Now that we understand the basic approaches to scaling out an application built on IBM’s WebSphere platform, and the different directory, database, and file system topologies supported by Lotus Connections, we can discuss some recommended deployment topologies to meet varying organizational goals.
A pilot deployment is ideal for an evaluation of the Lotus Connections features. This is a self-contained single server environment that requires no preexisting software beyond the operating system. Installed for the pilot in addition to Lotus Connections 2.0 is all the necessary prerequisite software. This includes IBM WebSphere Application Server 6.1.0.13 and IBM DB2 Express Edition. No external LDAP integration is provided in a pilot configuration but you can import a set of registered users. The pilot installation provides a quick and easy way to get a deployment off the ground, allowing an evaluation of the Lotus Connections feature set. For use after a pilot evaluation is complete, the migration wizard that is shipped with the Lotus Connections installation package eases the conversion of a pilot installation to a product environment. A migration is possible only if the users defined in the pilot also exist in the production directory with a shared secondary key, such as the user’s email address. Starting in release 2.0.1, we will also utilize the login name attribute as an additional shared secondary key. In a pilot, this key maps to the uid, but in your production directory, it can map to any number of possible attributes. Assuming that your pilot user base clearly has a 1-to-1 mapping to actual users in your production LDAP, moving to a production installation should succeed with little issue. The migration procedures can be broken down into three important high-level steps that are all performed when the production deployment is being set up:
Create the production databases. As described earlier in this chapter, choosing an appropriate database platform to match the skills of your organization is important in a production deployment. Our database migration wizard provides the necessary tools to migrate data from the pilot installation to any supported database platform. Using the database wizard, you can prepare the production database on the desired platform and then run the database migration wizard to move pilot data across.
Install the same version of Lotus Connections to a production environment. Chose a production deployment topology that maps to the needs of your organization, set up and install a WebSphere cell, configure Federated Repositories to use your production corporate directory, and enable WebSphere security (not Java 2 security). Finally, use the Lotus Connections Installation Wizard or Cluster Installation Wizard to install Lotus Connections into your production topology. Ensure that you map this new installation to the newly created production database that contains your pilot data.
Perform directory synchronization. Although the users are the same as those in the pilot installation, the enterprise directory keys and other user metadata will be different or out-of-date. The administrative commands in each of the Lotus Connections services will key off the users’ email address or login name to synchronize the pilot user data to match the production directory. The most important aspect of this step is correcting the GUID for each user with the actual GUID in your production LDAP. Without this synchronization, the users will not have access to their pilot data and likely will be unable to log in to the new system.
A more detailed breakdown of the steps required to install a production environment and migrate pilot data to the production deployment is available in the IBM InfoCenter site for Lotus Connections.
A simple deployment aligns with the intents of a pilot deployment with regard to scale but now lets you utilize any of the production operating systems and will integrate with the directory and database platform of your choosing. This environment is well suited for small organizations that don’t need the redundancy of highly available deployments or can be used as a staging environment for a larger deployment. When installing a nonpilot environment, Lotus Connections requires an existing WebSphere cell and profile installed with proper security and directory settings preconfigured but will automate the generation of server instances and associated resources.
A simple deployment topology usually breaks out Lotus Connections into a two-server configuration. The first server is hosting your chosen database platform (and optimally TDI for Profiles), and the second server is hosting your Application and HTTP servers. Figure 3.3 depicts the communication between these two servers and your supporting directory infrastructure.
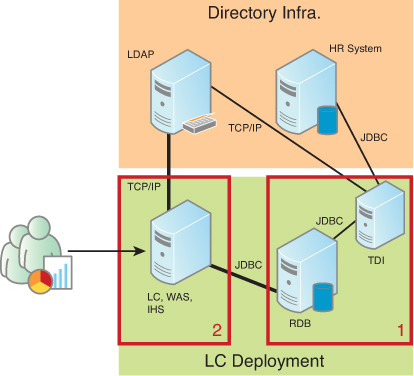
As shown in the figure, TDI resides on server 1 along with your relational database and uses its assembly lines and connectors to communicate with both an LDAP directory and a secondary HR repository. The WebSphere Application server and HTTP server are both installed on the second server; this machine will communicate directly with the LDAP for authentication and authorization and the relational database for user data. The top rectangle depicts your existing directory for authentication and user data. In planning for a larger-scale deployment in the future, it might be logical to span the Lotus Connections services across multiple WebSphere server instances even though they will still reside on a single physical machine.
Adding high availability or redundancy to a deployment topology means providing a means for one server instance to go down without losing the service provided by that instance. Adding HA support to the application server tier of Lotus Connections is accomplished by deploying each of the functional units to a multinode cluster across multiple physical boxes. These boxes can reside in a separate building or on independent power grids for greater availability. The additional HA nodes can be set up either as active servers for handling greater throughput or as standby servers that are partially utilized for other purposes. Virtualization is another technique to reduce the cost of ownership in an HA deployment. Although using an application server cluster will provide the necessary availability at this tier, it is important to keep in mind that an overall deployment is still most vulnerable at its weakest point, so a true HA deployment will also require redundancy at each of the other tiers, including the file system, relational database, directory, HTTP servers, and any SSO or caching proxies fronting the deployment. Each product vendor will provide the necessary solutions to ensure high availability at each level. How these products are rolled out for HA will vary by vendor. For example, at the persistence tier, DB2, Oracle, and SQL Server provide similar but different approaches for HA support. These are the three solutions:
DB2 High Availability and Disaster Recovery (HADR)
Oracle Real Application Clusters (RAC) and Oracle Maximum Availability Architecture (MAA)
Microsoft SQL Server Failover Clustering
You can find more details on each of these solutions through your chosen vendor’s documentation and support sites. The capability of Lotus Connections to use a wide arrange of vendors at each tier allows for reuse of existing skills and infrastructure within your organization.
Large-scale deployments are designed to maximize throughput, usually provide high availability, and are effective for serving a global organization. Earlier in this chapter, we discussed the database tier and how you can start with a single database server and spread to six active database servers. In a large-scale deployment, you likely will spread the database instances across multiple physical machines, with the number of machines depending on the type of hardware utilized. High-end hardware with large numbers of core and memory will require less scale-out. At the application server level, it is usually expected that each service will have its own cluster with at least two server instances on multiple physical machines for HA. With the size of this deployment, it is strongly recommended that WebSphere ND is utilized and all administration is done with a single deployment manager. With large-scale deployments often being global, they typically should include the use of regional proxy caches to minimize network latency and maximize server throughput across the weakest points in your network bandwidth. Details on the benefits of a reverse proxy cache and a complete depiction of a large-scale deployment for Lotus Connections are discussed in the Tier 1 section that follows. After a discussion of this final tier, Figure 3.4 provides a picture detailing a large-scale deployment.

In this section, we examine the components of the front-end web tier. These consist of proxies and single sign-on (SSO) solutions.
A proxy can be used to front a deployment for many reasons, including security, load balancing, and caching. Usually a proxy server is hosted in a web-accessible zone while the underlying tier 2 and tier 3 infrastructure will get deployed in protected zones. This is to prevent unwanted access to user data by constraining direct interaction with the deployment via the secured proxy. Only traffic between the proxy and the HTTP server will be allowed to tunnel between these security zones. Proxies are also commonly used in large-scale deployments to offload back-end services from hosting static content and publicly cacheable dynamic content. With proper deployment topologies a proxy can also reduce network latency for the delivery of cached content to a geographically dispersed client. Significant portions of content served by Lotus Connections are publicly cacheable, and the deployment of a proxy can provide a low-cost means to increase the overall scalability of your server environment.
Performance tests of the Dogear, Blogs, and Profiles services have shown significant gains on overall scalability and response time by the introduction of a reverse proxy cache. More moderate gains were observed in the other services but they were still significant enough to warrant its use. In the performance lab, Blogs showed as much as four times improvement in overall TPS and Dogear exhibited three times improvement in TPS. These gains were achieved by leveraging the proxy cache to offload dynamic content generation where data has not changed. Additional benefits are also possible by minimizing HTTP connections for static content and moving such requests closer to the edge of your infrastructure and ultimately the client.
In a standard deployment topology in which all six services share the same host name, such as connections.example.com, or the same parent domain name, such as activities.example.com and dogear.example.com, no external SSO solution is required to allow for WebSphere to provide a single authentication token that is utilized across all of Lotus Connections. Each request made by a browser will send along a set of browser cookies. In these browser cookies will be a cookie called “LTPAToken.” This is basically a ticket for the end user that was generated at login and is valid for a time period configured by the deployment. When multiple servers are set up to share this ticket with all other servers in the same parent domain, the ticket is passed by the browser on each such request. Each server in the environment can then validate that the ticket was generated by a trusted authority and accept it as a valid authorization token. When multiple servers are in the same cell, this will work out of the box. With minimal configuration, servers in multiple cells can also participate in this trust association without requiring an external solution.
The single sign-on solution that is provided out of the box not only allows all Lotus Connections servers to trust the tickets generated by other servers in the same deployment but also can interoperate with other non–Lotus Connections environments that support LTPA. This includes WebSphere Portal, Lotus Quickr™, and even Lotus Domino servers. As a deployment complexity expands beyond a single parent domain or a single authentication technology for cross-vendor compatibility, Lotus Connections provides support for integration with an external single sign-on solution. The supported platforms include Tivoli Access Manager and SiteMinder. These two solutions can provide a complete SSO strategy across your organization and the inclusion of additional auditing capabilities, policy-based authorization, and many other advanced security solutions.
We have now seen the many layers of a three-tiered deployment topology and the flexibility Lotus Connections can bring to each of these tiers to allow for vendor freedom, high availability, improved scalability, hardware virtualization, and integration into your existing back-end services. Figure 3.4 pulls this all together to demonstrate a complete large-scale deployment that leverages each of these choices to their fullest extent.
The Lotus Connections offering was built from the ground up with SOA in mind. A primary goal of social software, and specifically Lotus Connections, is to enable the ability to capture and expose the social fabric of an organization. Enabling API clients to extract information produced by an individual or a group of users will surface new interaction patterns previously left unturned. To help meet these goals, this means providing not only a first-class user experience but also a first-class service tier to enable modern mashups of data across your organization. A traditional web application is built with a three-tier model (presentation, business, and data). Lotus Connections follows this model internally but also puts a great emphasis on exposing the business tier via REST-based services that are as powerful as what can be done with the presentation tier.
The basic architecture of Lotus Connections maintains a clearly defined set of individually deployable three-tiered services that when installed together provide a set of cross-service enhancements that produce a unified social software platform. This approach enables incremental installation of the Lotus Connections services to ease user adoption while allowing for the later rollout of additional capabilities that enhance those already in use. To accomplish this flexibility, Lotus Connections has focused on three main principles:
Build all services on a set of key core service enablers.
Use a consistent REST-based SOA architecture to expose all functionality.
Provide cross-service integration using semantic microformats and mashups.
This section goes into detail on how these three principles have been utilized to provide the flexibility, consistency, and extensibility required of a rich social software platform. Let’s start with an example. An organization looking to roll out Lotus Connections might need to coordinate across IT organizations to fully integrate a disparate set of directory data needed to deploy Profiles. In the meantime, Dogear is installed in a standalone deployment and users are immediately creating bookmarks and building a corporate folksonomy of tags and associated bookmarks. The return on investment is almost immediate. At some point in the future, Profiles goes live and Dogear users now begin to notice that Dogear is surfacing additional information about those who created bookmarks. They can now take advantage of contextual business cards from within Dogear to view user pictures and contact information, and even initiate an instant messaging conversation directly from within Dogear. This became possible when Profiles was installed. Next users will begin to pivot from someone’s bookmarks into their full profile, where they realize they can also see all the social content this person has contributed in addition to his or her bookmarks. This is a key point of discovery that enables the viral adoption necessary for a flourishing social community.
Figure 3.5 depicts how the three architectural principles mentioned previously are used as building blocks for this SOA approach. Sample core service enablers run vertically down the left column and represent the architectural glue that spans each of the Lotus Connections services. Across the top of the figure is the Lotus Connections REST API layered with sample client mashups that were built using this public API. Finally, the middle of the figure shows each of the Lotus Connections services that can be incrementally installed into this framework to extend the overall platform functionality.
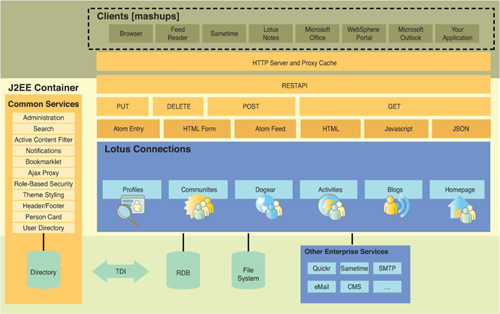
The Lotus Connections user experience can surface in many clients. Out of the box, it includes a native browser experience and a set of REST APIs that enable integration into a large set of client platforms. Available on the Lotus Connections Business Solution Catalog are many of these platform on-ramps, including integration with Lotus Sametime, Lotus Notes, WebSphere Portal, Microsoft Office, and Microsoft Windows. Each of these client renderings build on many of the same public REST APIs available for custom integration into any third-party platform. Browser support for the web experience includes Microsoft Internet Explorer 6.0 and 7.0 and Mozilla Firefox 2.0 on Windows, Linux, and Macintosh. As part of Lotus Connections 2.0, the browser experience is translated into 25 languages, including many bidirectional languages. Lotus Connections 2.0 has also added support for accessibility, including screen readers and high-visibility mode.
Most page views in Lotus Connections contain a feed icon that represent a link to an Atom feed document of the visible page’s resources. This feed document semantically represents the same data shown in the web experience but delivered via an XML document formatted based on the Atom 1.0 specification. In addition to having a view into a service’s data using the standard Atom Syndication Format, each Lotus Connections service also provides a discoverable service document as an entry point into the Atom Publishing Protocol. This protocol allows two-way resource manipulations, over HTTP, again using Atom as the data format. HTTP as a communication protocol allows a deployment to seamlessly leverage existing infrastructure, including proxies, firewalls, and other intermediary layers that work on the HTTP stack. Common tasks such as auditing, workload balancing, and secure tunneling are all supported by one’s existing infrastructure. Atom publishing uses the HTTP verb GET for retrieving a resource that is associated with a given URL, POST for creating a resource into a collection associated with a URL, PUT for updating a resource associated with a URL, and DELETE for removing a resource associated with a URL. Since each interaction is independent with no server state and all context information maintained in the HTTP request, one can easily explore both programmatically and visually to discover additional resources. For example, Dogear follows a basic scheme for filtering a collection of bookmarks. Manipulation of the output format part of the URL can result in a list of bookmarks in the webui (/html), via the public Atom API (/atom), or in alternate JavaScript and json formats (/snippet, /lisnippet, and /json). The use of basic query parameters on each of these URLs will constrain the list of bookmarks for the specified format to a filtered list.
With HTTP clients available in almost any programming language, the Lotus Connections API is also platform agnostic. Having been built on the standards-based Atom XML format and protocols, open-source client libraries exist for higher-level resource manipulation using native object models. One sample client is the Apache Abdera project, which provides a higher-level abstraction for communication in Java with any service that conforms to the Atom Publishing or Syndication specifications. Not only can existing programming libraries consume the Lotus Connections feeds, but some end-user applications such as feed readers, blog authoring tools, and other Atom-compliant applications can interoperate with Lotus Connections out of the box.
Each of the Lotus Connections services is built on a set of common components that enable the business tier to provide a consistent user and administrative experience across the functional units that make up the Lotus Connections product suite. Each of these common components provides a single access point for customization, administration, and feature injection that uniformly surfaces throughout the Lotus Connection portfolio.
The default behavior of Lotus Connections is to enforce an SSL connection when a user is being asked for authentication credentials but to redirect to a non-SSL connection after the user is authenticated. During the authentication process, a time-constrained security token that does not contain the user’s password is generated and set as a cookie so that it will continue to pass on all future page requests. This default behavior provides a reasonable degree of security while still ensuring optimal performance during normal user interactions that don’t include a user’s password. The generated security token is transmitted over HTTP for each browser request after authentication but has a default expiration window of 120 minutes. After this window expires, the user must reauthenticate. A longer window would reduce the frequency with which a user would need to reauthenticate but also increase the available time during which a stolen cookie could be utilized. A shorter window would reduce the usability of a stolen cookie but also require the user to reauthenticate more frequently. For most intranet deployments and many Internet deployments, this time-constrained security-token approach provides adequate security without the added performance burden of encrypting every page request. For those deployments with a need for greater security, Lotus Connections has a configuration setting to force SSL encryption on every page request. If the admin service is used and the forceConfidentialCommunications property is set to true, every page view will be forced over an encrypted channel. The same token exchange policy is utilized for user authentication, but the token is now sent encrypted on every page request. This configuration, although more secure, introduces a performance overhead to manage the encryption and decryption of every page. If it is necessary to reach the same level of scalability, this overhead can be greatly reduced through the use of a hardware accelerator for the encryption and decryption process.
Many of the services in Lotus Connections contain publicly available data that is readable without requiring user authentication. Allowing anonymous access to public resources is the default out-of-the-box configuration for Lotus Connections and is surfaced in Profiles, Dogear, Blogs, and Communities. In external-facing deployments or those intended for a limited audience, simply changing the security role-mapping in each of these services can ensure that user authentication is required for all content throughout Lotus Connections. This setting is found in the WebSphere Administrative console under each enterprise application’s “Security role to user/group mapping” section. Look for the reader role and remap it to “All-Authenticated” from its default mapping of “Everyone.” To further constrain your deployment to a limited user-set in your directory configuration, you can remap both the “reader” and the “person” roles to a constrained user group list and uncheck the All-Authenticated check box. This action will constrain user authentication to only the people found in the specified group.
Full-text search is available both locally within each service and globally across Lotus Connections to enable information discovery. The global search index is enhanced with IBM’s Web 2.0 Unified search capabilities for faceted navigation of results by context-sensitive filters generated dynamically for each search request. The Lotus Connections unified search strategy allows for a single search experience across all the Lotus Connections data. The dynamic facets generated with each result include related tags, people, and content type. The search user experience is surfaced as part of the Lotus Connections Home Page service and has its corresponding back-end index managed by the same underlying functional unit. Installation of the Home Page service is required to surface the unified index either in the web UI or via its API.
Administering a full-text search index differs slightly from the steps to administer a primary content store such as a relational database. A full-text index is a secondary storage mechanism that is generated by crawling a primary data source and processing the information in a means that is optimal for full-text information retrieval and faceted data navigation. Since this data is a secondary structure, regular backups are not necessary because regeneration is possible. Because a full recrawl of a large deployment might take some time, periodic backups are recommended to allow for point-in-time recovery on index corruption or disk failure. This would allow indexing to pick up and reindex from the timestamp of your last backup. Another difference between a full-text index and a relational database is that a full-text index is nontransactional. In normal operation, this has no real impact on you, but when performing a backup, you need to be sure to verify that the indexing process is not active. Since indexing is performed on a scheduled basis, verification of this state is simple to perform before a file system backup of the shared index structure is invoked.
The notification service leveraged throughout the Lotus Connections product introduces a consistent framework for configuring, administrating, and customizing notifications sent from each service to its registered user base. Sample event notifications include such actions as adding a member to an activity, notifying a user about an interesting bookmark, or adding a colleague to a personal network. Emails sent by the system can be explicitly initiated from an end user or server-generated when in a state that requires a user’s attention. This feature is optional and when it’s disabled, the corresponding end-user actions will not surface in the user experience. When it is enabled, a deployment has two approaches available to integrate with its existing messaging infrastructure. First, when in an environment that maintains valid MX records in its DNS tables to identify available SMTP servers, it is possible to simply configure Lotus Connections to utilize domain namespace lookups to retrieve all registered servers and attempt to send messages to each server until a success is noted. This approach provides a fallback strategy when any of the SMTP servers becomes unavailable. It also provides for both anonymous and authenticated connections to your SMTP server. Where authentication is required, a WebSphere connection alias is used to store the username and password. A second supported approach is also available in environments that do not actively register SMTP servers in DNS tables. In this case, it is possible to configure Lotus Connections to send notifications using a specific SMTP server. This approach is simple to configure but requires monitoring of the SMTP server because it will become a single point of failure for message delivery. When a single SMTP server is configured, a WebSphere Mail Session will get set up in the WebSphere Administrative Console and bound to a JDNI name of mail/notification. Details on how to configure both configurations are available in the Lotus Connections InfoCenter.
The concept of a person as an entity is an important aspect of a social networking offering such as Lotus Connections. The success of a deployment is primarily driven by the creation of user-generated content and the ability of end users to dynamically forge new relationships as a means to discover information. A person’s name is a natural pivot point for this discovery to initiate, and Lotus Connections provides this capability through contextual business cards that surface on every name. This enables users to explore, identify experts, and collaborate across organizational boundaries. This integration technique is built using open standards and a pluggable framework that enables the inclusion of contextual business cards throughout Lotus Connections and even on pages outside of the product. At the heart of all this functionality is the concept of an hCard. An hCard is an industry-standard approach for semantically representing a person in HTML markup. This means that the HTML syntax used for displaying a name on a page is appended with other nonvisual HTML attributes that are programmatically detectable by a JavaScript application. A normal person link without this markup would look like a simple HTML anchor tag:
updated by <a class="lotusPerson" href="#[email protected]">Frank Adams</a>
Usually this anchor tag will contain a class attribute to allow for custom link styling using CSS, a href attribute pointing to an action when the user clicks the link, and a display name as the link’s body. With additional semantic hCard markup added to the standard anchor tag, the page will look no different to an end user but can now allow for services like Lotus Connections to enhance this link with rich dynamic content via simply embedding a JavaScript include on the top of the page. The updated hCard markup looks like this:
updated by <span class="vcard"> <a class="fn person lotusPerson" href="#[email protected]">Frank Adams</a> <span class="email" style="display: none;">[email protected]</span> <span class="x-lconn-userid" style="display: none;">e1234a56- 7b8c-9012-34d5-ef67890g12h3</span> </span>
When looking closely at the preceding markup, you will see that the additional tags have a style attribute that tells the browser that they are nonvisible parts of the page but are still programmatically accessible via an embedded JavaScript framework. By installing the Lotus Connections Profiles Service in addition to the other Lotus Connections services, this markup is used to introduce rich business card enhancements to all names on every page. Figure 3.6 shows a sample business card when a user interacts with a dynamic name.

Figure 3.6 demonstrates how a user not only can have an in-line view of the person’s contact information and picture, but also is able to cross-navigate on a person’s bookmarks, blogs, communities, activities, and profile. Additional features include Sametime awareness, sending of an email, and the ability to invite someone as a colleague or to download the person’s vCard into an address book.
In building largely dynamic applications that federate information and include mashups across both internal and external sources, it is necessary to securely extend the browser capability to communicate across server domains when dynamic feed requests are made. The Lotus Connections Profiles and Home Page services require this ability to enable integration of third-party widgets hosted on external servers. Both Profiles and Communities also utilize this service to allow feed aggregation across a well-defined set of external servers. Since the browser’s single domain restrictions on Ajax requests are in place to avoid the security implications of cross-site scripting, spoofing, and many other forms of web-based security vulnerabilities, Lotus Connections enables controlled cross-domain Ajax requests by implementing a server-side proxy that can selectively allow these actions based on a deployment policy and whitelist. This proxy can be shut off or selectively restrict requests to specific URL patterns, response formats, and HTTP methods. It also has control over what user information (such as cookies) is propagated to each of these sites. This flexibility allows the degree of openness appropriate for each deployment and is configurable on a per component and URL basis. After installation, Profiles, Communities, and Home Page each have default configurations that allow the proxying of requests to any domain. As part of your initial configuration settings, it is highly recommended that a deployment determine what domains are necessary for the set of installed widgets and constrain the proxy configuration for each of these components to only these URL patterns. Since Profiles and Home Page also perform feed requests to each of the other Lotus Connections services, this whitelist should include any of the Lotus Connection server domains in your deployment. Since Communities will perform feed aggregation, it is a deployment choice as to how constrained this setting is to be made.
Ensuring a secure environment for social collaboration is a key attribute for business-ready social software. One important aspect of security is ensuring that users can enter rich text markup for content authoring without allowing malicious injection of unwanted markup such as JavaScript and ActiveX controls. The Lotus Connections active content filter provides this functionality consistently across the product, allowing safe input of user-contributed rich text. From a browser standpoint, this function is needed in places where you see a rich text editor. Under the covers, this editor is generating HTML markup and submitting it to the server via the product APIs. The product API accepts three types of user-contributed content: plain text, HTML, and xHTML. Plain-text content is not treated as markup and stored verbatim. When displayed in the browser, the plain text is fully escaped to ensure that any user text that could represent an active HTML tag is shown to end users “as is” and not interpreted by the browser as representing active content. When HTML and xHTML are submitted, this is intended to be later rendered as rich markup to the other users, so it must be scrutinized and stripped of any malicious attributes before getting persisted. Although this content is usually contributed indirectly via the rich text editors, which are known to generate safe markup, it is possible to contribute arbitrary markup via the API—and this data must all get cleansed before persisting. The scrubbed version of this HTML is stored in the database. This filtering process makes it safe for the server to later return user-contributed rich text markup to other end users for display in the browser.
The ability to persist links to a web address is a key feature of Lotus Connections. The Dogear component allows you to socially manage your own bookmarks while browsing the Web. When reaching a page that is worth sharing with others, a user will click the Lotus Connections browser button for storing a social bookmark. This button is known as a bookmarklet. This button will open a dialog where the user can enter tags, write a detailed description, and save without navigating off the current page. This installed browser button can also detect which Lotus Connections components are available and contextually offer the sharing of a web link to a community, an activity, or even a blog post. The common bookmarklet, available to end users in the footer of any Lotus Connections service, provides a single integrated user experience for adding a bookmark into Lotus Connections.
The Lotus Connections navigational headers, footers, and overall theme are enabled for rebranding to provide a consistent and integrated user experience with existing sites. Lotus Connections also has a common set of style definitions across the services that provide an integrated look and feel for end users and enable simple modifications to integrate the user experience with alternate branding guidelines. To begin customizing, it is easiest to work from a starting point and progressively replace images and styles. To start, you need to copy the header.html file found within any of the deployed services into a web-accessible location. This is usually an HTTP server such as IHS. Next you can override Lotus Connections to use the new header file found on the HTTP server by running an admin command and providing it the new web-accessible URL for the header file:
LCConfigService.updateConfig("style.header.url",
"http://example.com/templates/header.html")This header file is now the default header for all Lotus Connection services and contains fully customizable HTML markup plus a number of supported macros for variable replacement. For example, you will notice that image files start with a macro path of {default images}, which when updated to {images} will instead download image files from a custom-defined web-accessible URL. A similar admin command is used to define the location of the {images} macro to allow for custom images in the header:
LCConfigService.updateConfig("style.images.url",
"http://example.com/images")The links shown horizontally across the Lotus Connections header are also customizable. All of the six enabled services are dynamically inserted as styled <li> entries at the spot denoted by the macro {{application links: li }}. Placing additional <li> tags before or after this macro will allow for custom links:
<ul class="lotusInlinelist lotusLinks">
{{application links: li }}
<li><a href=http://example.com/learning>Learning</a></li>
</ul>The preceding example would add a Learning link to the navigation bar. Figure 3.7 shows what this would look like in the header.
Customizing the footer is equally simple. Again using the LCConfigService, update the configuration setting to point to a new web-accessible location where the footer HTML file is copied:
LCConfigService.updateConfig("style.header.url",
"http://example.com/templates/footer.html")Inside this file is a table with four columns, each with rows of links to related information. These links also get generated via the same macros substitution strategy. You can remove, add, or update any of these links and/or columns to ensure that the footer contains information relevant to your deployment. For example, if a deployment has custom tools, a link in the footer will provide end users a means to install these tools.
A significant part of rebranding Lotus Connections is to replace the overall look and feel of the main content area to match your organizational guidelines. This part of customization will take the most time to get an overall site experience that blends cleanly with that of another site. To make this easier, a sample alternate set of style sheets and images, along with a theme editing guide, is provided with Lotus Connections as a resource. This package includes sample CSS styles and images to give Lotus Connections a red look and feel. The theme editing guides provides a complete list of class names, descriptions, and the default values for both the blue and red themes.
Maintaining a solid look and feel that works across many languages, including bidirectional languages, requires care. To best take advantage of the effort made by Lotus Connections and to ensure that the site remains functional in all of these languages; it is recommended that any branding is done by starting with the out-of-box styles and images and making necessary incremental changes from this point forward. When you are updating or replacing images, it is best to stick with consistent dimensions and not alter the overall layout of the page. To maintain consistent font and color throughout the site requires updating multiple styles at a time, and the best approach is to use a search-and-replace strategy that makes the same change to all instances of a single font or color. Also, when picking updated fonts, be sure to keep in mind that not all fonts are universal across browsers and platforms.
This section briefly discusses how Lotus Connections integrates with other systems, including WebSphere Portal, Socialtext and Confluence, and Lotus Quickr.
Organizations with existing investments in WebSphere Portal can extend this investment with features from Lotus Connections using one of three approaches. The first and simplest approach is to utilize a Lotus Connections portlet made available on the IBM Lotus Connections Business Solutions Catalog. This portlet can provide in-context information from each of the Lotus Connections services on any portal page. The portlet was built using the Lotus Connections REST APIs and provides access into each of the Lotus Connections services. Since these APIs are available via HTTP, a second integration approach is to build a custom portlet using these same APIs. This provides the most flexibility when integrating specific features into a custom application on a WebSphere Portal page. Finally, for those looking for seamless navigation across both deployments, the IBM Web Application Integrator for WebSphere Portal is your answer. This solution allows existing web applications, including Lotus Connections, to seamlessly integrate into the WebSphere Portal navigational structure. This solution provides a complete visual integration without requiring the development of any portlets. It works by injecting a live rendering of the portal navigational banner into Lotus Connections. Along with the creation of Lotus Connections page links in the WebSphere Portal navigation header, you are able to navigate between portal and Connections pages seamlessly. Figure 3.8 provides a screenshot of this integration in which a portal navigation header is shown as part of a Lotus Connections page.

The Lotus Connections Communities feature provides groups of users with common interests to create ad hoc spaces for collaboration on shared interests. Out of the box, these spaces include topical feed aggregation, discussion forums, and community bookmarks as means to share content. A community membership can also be utilized for email communications and Sametime broadcast lists. The features available to a community are extensible through the installation of one or multiple available plug-ins. Plug-ins are available to integrate Socialtext or Confluence wiki spaces as part of a community. Both are made available through the Lotus Connections Business Solutions Catalog. When they’re installed, end users creating communities can choose to include a wiki space with either of these technologies. This space will maintain a synchronized membership list, a navigational link to the wiki in the side panel, and a feed of recent wiki changes in the main Community view.
In release 2.0.1, Lotus Connections has expanded its integration points with Lotus Quickr. The first integration point is with Lotus Connections Activities and Quickr Document Libraries. Activities provide a focused space for ad hoc collaboration and development of best practices to manage repeated tasks more effectively. In these collaboration patterns, files are used as a piece of a greater collaboration around a topic. As an activity is brought to completion, the outcome is often a document. Integration with Lotus Quickr allows for the publishing of this file to a team library, making the file available to a broader audience and for long-term storage in an enterprise content management platform. This integration allows for quick publishing of files into ones most frequented Quickr libraries, removing the file from the Activity and replacing it with a link back to the published file now residing in Quickr. Lotus Connections Communities also provides integration with Lotus Quickr, allowing a Quickr wiki to surface as part of a community in the same manner as Socialtext and Confluence. This integration provides the seamless generation of a Quickr wiki when creating a community space along with membership synchronization and an integrated feed of recent changes in the Community page.
As you have seen throughout this chapter, the complexity of a Lotus Connections deployment can vary greatly based on your organizational needs for scale, security, high availability, centralized administration, and overall responsiveness. Next, we detail some of the base requirements to get a deployment off the ground.
A pilot deployment can successfully get off the ground with a single Intel® 64 or IA-32 based server, but in planning for a production deployment, it is recommended to have a minimum of two servers each containing two cores and at least 4GB of memory (preferably per core). In this minimum configuration, we would have the application server on one machine and the database server on a second. This is the simple deployment topology described earlier in this chapter. As a simple deployment expands to support high availability or adds clusters for greater scale, the amount of physical hardware required will increase.
Space requirements will greatly vary by deployment depending on the data characteristics of the user base and the chosen configuration settings. For example, with Activities you can determine the maximum size of a file upload, which will greatly impact your space requirements. Blogs will also allow caps on the upload space per blog. As a rule of thumb, plan on having at least 80GB of free disk space per machine after installing the software. Space requirements by feature fall into two categories: space required per node in the cluster, and shared space made available to all nodes in a cluster via a network file share.
Shared content storage is used by Activities, Communities, and Blogs to persist large content objects. This content is not stored in the relational database and resides only in this shared file system. The amount of space required will be directly proportional to the amount and nature of the content posted by end users. Both Activities and Blogs provide means to cap the size of content an individual can contribute and Communities uses the content storage for only extended descriptions in discussion forums. These caps can effectively help you manage total space required. Activities also provides a means to split the content storage across two drives if the initial allocation is not adequate.
Additional shared storage is necessary for Blogs to replicate its full-text index across nodes in the cluster and for the global search index. A search index can grow as large as 2GB, and the Blogs snapshot storage for index replication should be about three times the size of its actual index. This means that 8-10GB of additional storage should be planned for the full-text search shared storage space—this is in addition to the storage put aside for the file system content store described above.
A local full-text index for free text queries is used by Blogs, Communities, Dogear, and Profiles. Each of these services stores an index that is local to each node in its respective clusters. The space required on each node will vary due to usage patterns and the nature of the content in the index. Communities indexes will be the smallest, whereas the Blogs and Dogear indexes can grow much larger. But you can expect each of the indexes to remain less than 2GB per node for about any size deployment.
Dogear also has a favicon storage. This storage is used to locally cache site-specific icons that visually distinguish a bookmark’s host server. This cache typically is stored on a per node basis and is self healing in that missing icons will automatically redownload on next access or when they become stale. The amount of space used to cache these favicons will grow with the number of bookmarks but not linearly because only one icon is needed per host and many URLs will share a single host. It is reasonable to assume that this cache will remain under 1GB in size, even in very large deployments.
This chapter has outlined a number of topics ranging from the Lotus Connections tiered deployment topology to its SOA architecture and integration points. A unifying theme to the overall Lotus Connections architecture is openness, extensibility, and flexibility. These topics provide an overview of decision points requiring consideration to successfully roll out and maintain Lotus Connections within your organization and extend its reach into your existing applications.