
Chapter 6. SmartDP Reference Architecture
In terms of architecture, SmartDP should be able to support data management, data science, and data engineering, and enable data engineering teams to effectively collaborate with one another (see Figure 6-1).
Functionally, SmartDP is divided into five layers, as shown in Figure 6-1—the data layer, data access layer, infrastructure layer, data application layer, and operation management layer. Let’s look at each layer in detail.
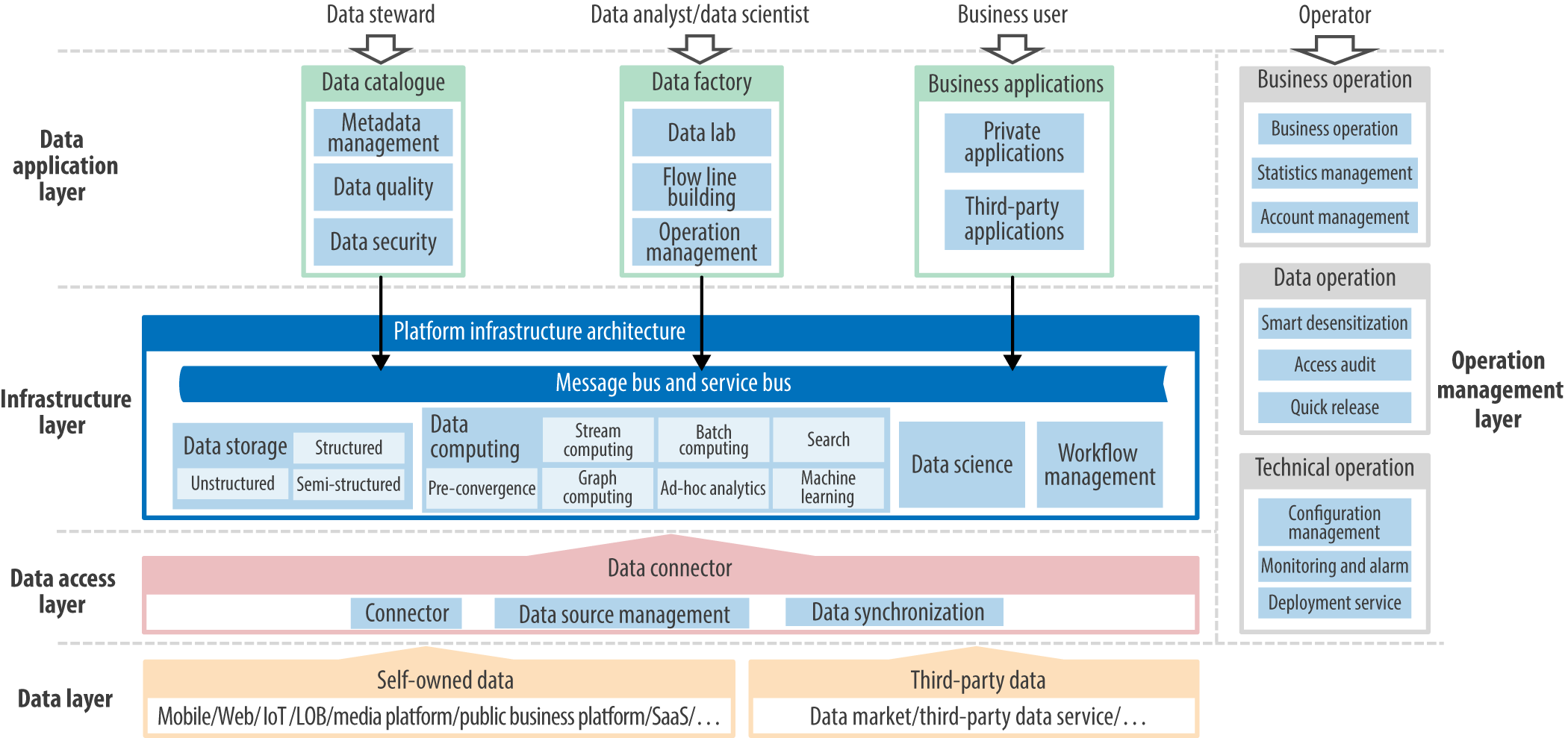
Figure 6-1. SmartDP reference architecture (figure courtesy of Wenfeng Xiao)
Data Layer
The data layer may be divided into self-owned data and third-party data, according to sources.
Self-Owned Data
Self-owned data refers to data that is owned by an enterprise and that can be completely controlled and managed by the enterprise, which is stored in the enterprise or any external platform of a third party.
The self-owned data stored in an enterprise generally includes:
-
Data from mobile smart devices, including user interaction data of native smart phone applications (including Android, iOS, WinPhone) and of vertical application frameworks (including Cocos2D, Unity3D, APICloud, Cordova).
-
Data from web pages, including user click events of PC or mobile web pages (such as JavaScript) and web page information crawled from web pages
-
Data from IoT devices, including beacon devices (such as iBeacon and Eddystone) and user visit data captured by WiFi probes
-
Data from the existing systems of the enterprise, including CRM systems, ERP systems, and data warehouses
The self-owned data stored outside an enterprise includes:
-
Data on public media platforms, including the WeChat public platform, Microblog platform, Twitter, and Facebook
-
Data on public business platforms, including the goods trading data of Tmall, media data from advertising alliances, and coupon consumption data of the O2O platform
-
Data stored on public SaaS platforms, including data from advertising monitoring platforms, user analysis data from mobile phone app analysis platforms, and customer data from customer management systems
For the harvest of first-party data, enterprises should have standard data harvest techniques so as to stay compatible with data harvest methods in mainstream environments and platforms. The techniques include but are not limited to:
-
Mainstream smart phone platform support, including Android, iOS, and WinPhone
-
Third-party platform support, including Cocos2D, Unity3D, APICloud, and Cordova
-
Web page support, including JavaScript and web page crawlers
-
Support from offline beacon devices (including iBeacon and Eddystone) and WiFi probes.
-
Context-awareness data support from smart devices, including human gestures (such as walking, running, driving, riding, handholding)
Third-Party Data
Third-party data is the data not owned by an enterprise and provided by a third-party data provider.
Normally, the third-party data includes:
-
Data purchased by an enterprise in the data market, such as mobile phone label data of a third-party DMP
-
Data services provided by a third-party data provider, such as traffic data ingested via government data open interface
Data Access Layer
The data access layer ingests the data harvested into the system for subsequent operation. Thus, in order to gain access to more data sources, the data access layer should support as many data connection types as possible, which include but are not limited to the following aspects:
-
Connection support for frontend event harvest sources, such as WiFi probe data, mobile phone interaction events, and web page click events
-
Connection support for various public media platforms, public business platforms, and public SaaS platforms
-
Connection support for RDBMSs
-
Connection support for data warehouses and OLAP (MDX)
-
Connection support for local filesystems
-
Connection support for common big data systems (including Hadoop/HBase)
-
Connection support for NoSQL databases (such as Cassandra and MongoDB)
-
Connection support for traditional analysis platforms, such as SAP/Siebel
-
Connection support from buffer services (such as Redis)
Infrastructure Layer
The infrastructure layer provides the basic technical capacity for data applications at upper layers, including data storage, data computing, data science, workflow management, the message bus, and the service bus.
Data Storage
Data storage capacity supports long-term data storage.
Data storage can be divided into the following types according to the type of data stored:
- Structured
-
It is required that a predefined strict data model (schema) or a predefined organization mode be established for storage. Normally, the structured storage includes row-oriented storage (including traditional RDBMSs, and MySQL), column-oriented storage (including column-oriented databases, such as HBase, and Vertica) and graph storage (including graph databases, such as GraphSQL).
- Semi-structured
-
This has no strict definition of a data model but a certain format, which is freely scalable, such as JSON and XML.
- Unstructured
-
There is no strict definition of a data model. And there is no way to pre-organize the storage type. Unstructured storage includes scalable or freely organized files, including server blogs, emails, compressed files and videos.
Data storage can be divided into the following types in terms of the form of stored content:
-
Filesystem, such as HDFS and Alluxio, applicable to the storage of large-scale datasets
-
Graph storage, such as Neo4J, applicable to data structures with multilevel interaction
-
Column-oriented storage, such as HBase and Parquet, applicable to batch data processing and real-time query
-
Row-oriented storage, such as MySQL, applicable to random query
-
KV storage, such as Redis and Aerospike, applicable to business data with fewer data relations
-
File storage, such as MongoDB, applicable to the storage and query of document formats
Data Computing
Data computing capacity supports all operations of data organization and analytics.
Data computing can be divided into the following types based on computing type:
-
Stream computing: Storm, Spark
-
Batch computing: Hive, Spark
-
Ad-hoc analytics: Presto
-
Search: Elastic Search
-
Pre-convergence computing: Druid, TalkingData, AtomCube
-
Graph computing: GraphSQL
-
Machine learning platforms: TensorFlow, Petuum, OpenMPI, Spark
Data Science
Data science capacity provides various algorithms and models.
According to the application contexts of algorithms and models, data science can be divided into the following algorithms:
-
Data standardization algorithms: TF-IDF weighted statistics
-
Time-frequency transformation algorithms: fast Fourier transformation
-
Dimension reduction algorithms: principal components analysis
-
Clustering algorithms: hierarchical clustering, power iteration clustering, streaming k-means clustering, Gaussian mixture model, latent Dirichlet allocation, and DB scan
-
Classification algorithms: naive Bayes classification, k-nearest neighbors, support vector machines, batch logistic regression, simple linear regression, random decision trees, Lasso regression, decision trees, and logistic regression
-
Recommendation algorithms: collaborative filtering
-
Interaction analysis algorithms: a priori data mining, FP-Growth and cSPADE
-
Algorithm models owned by other enterprises
Workflow Management
Workflow management is used to manage data-related work and flow processes. It arranges various automatic or manual tasks necessary for data engineering and ensures their completion and implementation. Workflow management relates to task security, error handling, dependency arbitration, and other coordination tasks.
The common tools for workflow management include Azkaban and Oozie.
Message and Service Bus
The message bus aims to decouple message generators and consumers and the service bus aims to decouple service providers and callers. The message and service buses can provide the system with a more flexible architecture and much higher scalability.
The common message buses includes Kafka, and the common service buses include such microservice governance frameworks as Eureka and Dubbo.
Data Application Layer
Data applications are the commercialization of data engineering that satisfies particular demands. They may run normally based on the data convergence of SmartDP and technical capacity of the platform.
SmartDP includes both system applications similar to data catalogs and data factories, as well as business applications of various types.
Data Catalog
Equivalent to a search engine for data, the data catalog can facilitate users to search, understand, and use data by organizing the relevant information of data.
Generally, the data catalog is maintained by the data steward and may be used by all other roles of the data engineering team.
Normally, the data catalog undertakes the tasks as data management and includes the following core functions:
- Metadata management
-
Management of data lineage, data summary, and data format
- Data quality management
-
Management of record rearrangement, unit error correction, and data correlation
- Data security management
-
Management of audit, hiding, and tokenization and access control
Data Factory
A data factory is used to build production flow lines for data engineering and ensure these lines operate normally.
Generally, a data factory is maintained by data engineers and may be used by all other roles of the data engineering team.
Normally, a data factory includes the following core functions:
- Data lab
-
For exploring data engineering, including explorative data analysis, building and verification of new algorithm models, and trying new data processing procedures
- Flow line building
-
For assembly data processing, including visualized task scheduling and interactive exploration
- Operation management
-
For managing all flow lines, including smart task deployment, monitoring and abnormal alarms, and heterogeneous computing
Business Applications
Business applications provide services to business departments.
In general, business applications are used by business users and may be developed either by the enterprise or by a third party.
Common business applications include marketing release, mobile analysis, advertisement monitoring, offline visitor flow analysis, competition analysis, financial risk control, and identity verification.
Operation Management Layer
The operation management layer is able to support the business, data, and technical operations of SmartDP.
Business Operations
Business operations can help operators manage the SmartDP account as well as the measurement and billing of services provided externally.
Data Operations
Data operations can enable operators to manage compliance, anonymization, and access control rules as well as the audit strategies of the data services they provide, and improve the efficiency of data service releases.
Technical Operations
Technical operations may help operators manage server configuration and monitor alarm strategies at the core of SmartDP as well as maintain the deployment of platform resources.