
Chapter 6. Using Modules to Share Stack Code
One of the principles of good software design is the DRY principle (“Don’t Repeat Yourself”)1. As you write code for different infrastructure stacks, you may find yourself writing very similar code multiple times. Rather than maintaining the same code in multiple places, it is often easier to maintain a single copy of the code.
Most stack management tools support modules, or libraries, for this reason. A Stack Code Module is a piece of infrastructure code that you can use across multiple stack projects. You can version, test, and release the module code independently of the stack that uses it.
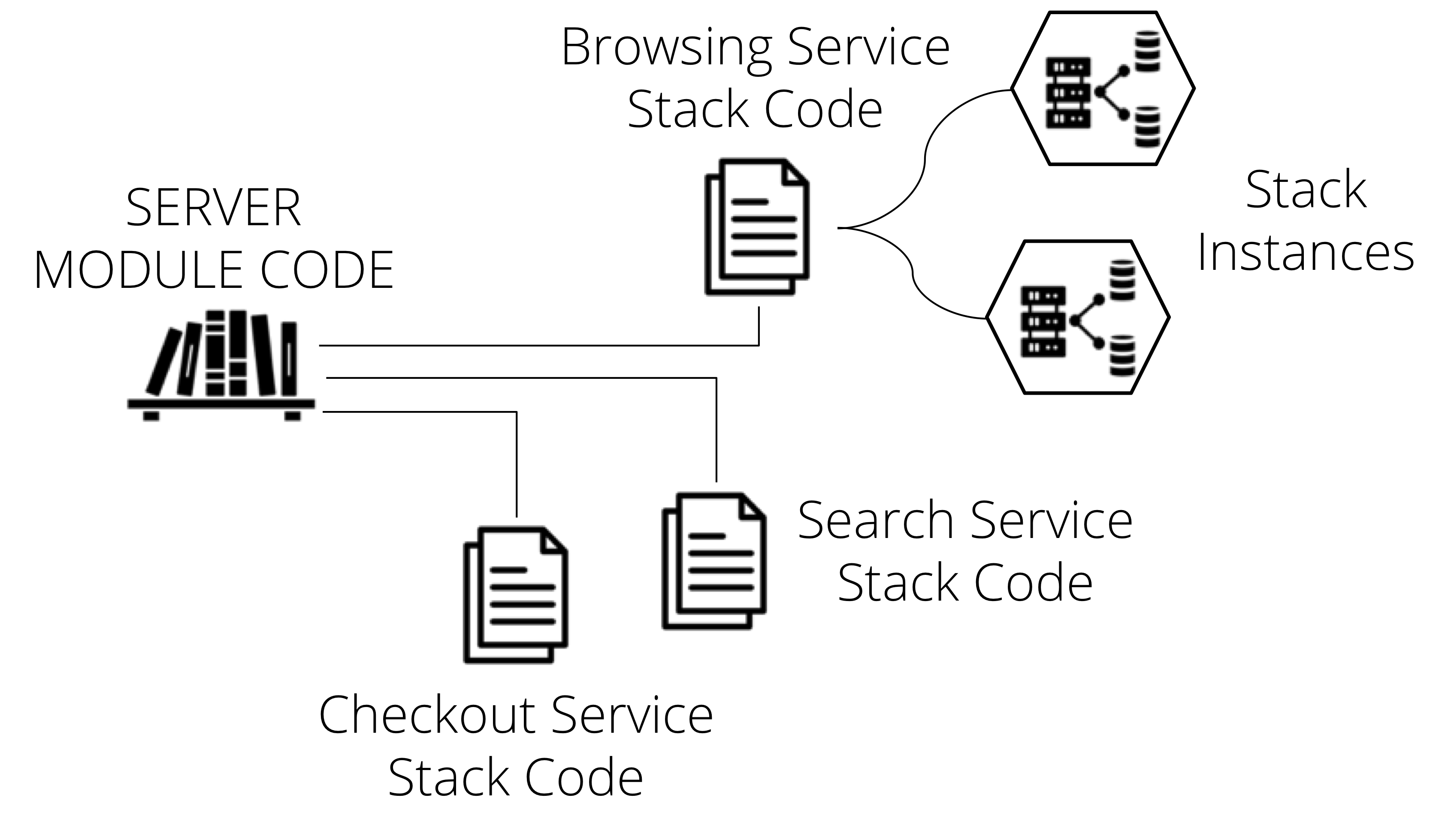
Figure 6-1. A Stack Code Module is a piece of infrastructure code that you can use across multiple stack projects.
Examples of using modules
As an example, the Foodspin team has several servers in their system-container host servers, application servers, and a CD server. The code for each of these is similar:
Example 6-1. Example of stack code with duplication
virtual_machine:name:foodspin-clusterhostsource_image:hardened-linux-basememory:16GBprovision:tool:servermakermaker_server:maker.foodspin.iorole:clusterhostvirtual_machine:name:foodspin-appserversource_image:hardened-linux-basememory:8GBprovision:tool:servermakermaker_server:maker.foodspin.iorole:appservervirtual_machine:name:foodspin-gocd-mastersource_image:hardened-linux-basememory:4GBprovision:tool:servermakermaker_server:maker.foodspin.iorole:appserver
The Foodspin team writes a module to declare a server, with placeholders for parameters:
Example 6-2. Example of a stack module for defining a server
declare module:foodspin-serverparameters:name:STRINGmemory:STRINGserver_role:STRINGvirtual_machine:name:${name}source_image:hardened-linux-basememory:${memory}provision:tool:servermakermaker_server:maker.foodspin.iorole:${server_role}
Each stack that needs a server can then use this module:
Example 6-3. Example of a stack module that defines a server
use module:foodspin-servername:foodspin-clusterhostmemory:16GBserver_role:clusterhostuse module:foodspin-servername:foodspin-appservermemory:8GBserver_role:appserveruse module:foodspin-servername:foodspin-gocd-mastermemory:4GBserver_role:gocd_master
The code for each server is simpler using modules since it only declares the elements that are different rather than duplicating the declarations for the server image and server provisioner. Most usefully, they can make changes to how they provision servers in one location, rather than needing to change code in different codebases.
Patterns and antipatterns for infrastructure modules
Modules can be useful for reusing code. However, they also add complexity. So it’s essential to use modules in a way that creates more value than complexity. A useful module simplifies stack code, improving readability and maintainability. A poor module reduces flexibility and is difficult to understand and maintain.
Here are a few patterns and antipatterns that illustrate what works well and what doesn’t:
-
A Facade Module provides a simplified interface for a resource provided by the stack tool language, or the underlying platform API.
-
An Anemic Module wraps the code for an infrastructure element but does not simplify it or add any particular value.
-
A Domain Entity Module implements a high-level concept by combining multiple low-level infrastructure resources.
-
A Spaghetti Module is configurable to the point where it creates significantly different results depending on the parameters given to it
-
An Obfuscation Layer is composed of multiple modules. It is intended to hide or abstract details of the infrastructure from people writing stack code but instead makes the codebase as a whole harder to understand, maintain, and use.
-
A One-shot Module is only used once in a codebase, rather than being reused.
Pattern: Facade Module
A Facade Module provides a simplified interface for a resource provided by the stack tool language, or the underlying platform API.
The facade module presents a small number of parameters to code that uses it:
Example 6-4. Example code using a facade module
use module:foodspin-servername:burgerbarn-appservermemory:8GB
The module itself includes a larger amount of code, that the calling code doesn’t need to worry about:
Example 6-5. Code for the example facade module
declare module:foodspin-servervirtual_machine:name:${name}source_image:hardened-linux-basememory:${memory}provision:tool:servermakermaker_server:maker.foodspin.iorole:application_servernetwork:vlan:application_zone_vlangateway:application_zone_gatewayfirewall_inbound:port:22from:management_zonefirewall_inbound:port:443from:webserver_zone
Motivation
A facade module simplifies and standardizes a common use case for an infrastructure resource. The stack code the uses a facade module should be simpler and easier to read. Improvements to the quality of the module code are rapidly available to all of the stacks which use it.
Applicability
Facade modules work best for simple use cases, usually involving a low-level infrastructure resource.
Consequences
A facade module limits how you can use the underlying infrastructure resource. Doing this can be useful, simplifying options and standardizing around good quality implementations. However, it can also reduce flexibility.
A module is an extra layer of code between the stack code and the code that directly specifies the infrastructure resources. This extra layer adds at least some overhead to maintaining, debugging, and improving code. It can also make it harder to understand the stack code.
Implementation
Implementing a facade module generally involves specifying an infrastructure resource with a number of hard-coded values, and a small number of values that are passed through from the code that uses the module.
Related patterns
An anemic module (“Antipattern: Anemic Module”) is a facade module that doesn’t hide much, so adds complexity without adding much value. A domain entity module (“Pattern: Domain Entity Module”) is similar to a facade, in that it presents a simplified interface to the code that uses it. But a domain entity combines multiple lower-level elements to present a single higher-level entity to the calling code. In contrast, a facade module is a more direct mapping of a single element.
Antipattern: Anemic Module
An Anemic Module wraps the code for an infrastructure element but does not simplify it or add any particular value. It may be a facade module (“Pattern: Facade Module”) gone wrong, or it may be part of an obfuscation layer (“Antipattern: Obfuscation Layer”).
Example 6-6. Example code using an anemic module
use module:any_serverserver_name:burgerbarn-appserverram:8GBsource_image:base_linux_imageprovisioning_tool:servermakerserver_role:application_servervlan:application_zone_vlangateway:application_zone_gatewayfirewall_rules:firewall_inbound:port:22from:management_zonefirewall_inbound:port:443from:webserver_zone
The module itself passes the parameters directly to the stack management tool’s code:
Example 6-7. Code for the example anemic module
declare module:any_servervirtual_machine:name:${server_name}source_image:${origin_server_image}memory:${ram}provision:tool:${provisioning_tool}role:${server_role}network:vlan:${server_vlan}gateway:${server_gateway}firewall_inbound:${firewall_rules}
Also Known As
Value-Free Wrapper, Pass-Through Module, Obfuscator Module.
Motivation
Sometimes people write this kind of module aiming to follow the DRY (Don’t Repeat Yourself) principle. They see that code that defines a common infrastructure element, such as a virtual server, load balancer, or security group, is used in multiple places in the codebase. So they create a module that declares that element type once and use that everywhere. But because the elements are being used differently in different parts of the code, they need to expose a large number of parameters in their module. The result is that the code that uses the module is no simpler than directly using the stack tool’s code. The codebase still has repeated code, only now it’s repeated use of the module.
Applicability
Nobody intentionally writes an anemic module. You may debate whether a given module is anemic or is a facade, but the debate itself is useful. You should consider whether a module adds real value and, if not, then refactor it into code that uses the stack language directly.
Consequences
Writing, using, and maintaining module code rather than directly using the constructs provided by your stack tool adds overhead. It makes your stack code more difficult to understand, especially for people who know the stack tool but are new to your codebase. It adds more code to maintain, usually with separate versioning and release. You can end up with different versions of a module being used by different stacks, causing people to waste time and energy managing releases, upgrades, and testing.
Implementation
If a module does more than pass parameters, but still presents too many parameters to code that uses it, you might consider splitting it into multiple modules. Doing this makes sense when there are a few common but different use cases for the infrastructure element the module defines. For example, rather than a single module for defining firewall rules, you may want one module to define a firewall rule for public HTTPS traffic, another for internal HTTPS traffic, and a third for SSH traffic. Each of these may need fewer parameters than a single module that handles multiple protocols and scenarios.
Related patterns
Some anemic modules are “Pattern: Facade Module” that grew out of control. Others are part of an “Antipattern: Obfuscation Layer”. It may also be a “Pattern: Domain Entity Module” that maps a bit too directly to a single underlying infrastructure element, rather than to a useful combination of elements.
Coupling and Cohesion with infrastructure modules
When organizing code of any kind into different components, you need to consider dependencies. A stack project that uses a module depends on that module2. The level of coupling describes how much a change to one part of the codebase affects other parts. If a stack is tightly coupled to a module, then changes to the module will probably require changing the stack code as well. This is a problem when multiple stacks are tightly coupled to a module, or when there is tight coupling across multiple modules and stacks. Tight coupling creates friction and risk for making changes to code.
You should aim to make your code loosely coupled. You can draw on lessons from software architecture to find ways to identify and avoid tight coupling3.
The level of cohesion of a component describes how well-focused it is. A module that does too much, like a spaghetti module (“Antipattern: Spaghetti Module”), has low cohesion. A module has high cohesion when it has a clear focus. A facade module (“Pattern: Facade Module”) can be highly cohesive around a low-level infrastructure resource, while a domain entity module (“Pattern: Domain Entity Module”) can be highly cohesive around a clear, logical entity.
Pattern: Domain Entity Module
A Domain Entity Module implements a high-level concept by combining multiple low-level infrastructure resources. An example of a higher level concept is the infrastructure needed to run a specific Java application. This example shows how a module that implements a Java application infrastructure instance might be used from stack project code:
Example 6-8. Example of using a domain entity module
use module:java-application-infrastructurename:"shopping_app_cluster"application:"shopping_app"application_version:"4.20"network_access:"public"
The module creates a complete set of infrastructure elements, including a cluster of virtual servers with load balancer, database instance, and firewall rules.
Motivation
Infrastructure stack languages provide language constructs that map directly to resources and services provided by infrastructure platforms (the things I described in Chapter 3). Teams combine these low-level constructs into higher-level constructs to serve a particular purpose, such as hosting a Java application or running a data pipeline.
It can take a fair bit of low-level infrastructure code to define all of the pieces needed to meet that high-level purpose. As I described above, to create the infrastructure to run a Java application, you may need to write code for a cluster of virtual servers, for a load balancer, for a database instance, and for firewall rules. That’s a lot of code. Although you may write modules so you can share code for each low-level resource, if you need multiple different applications with similar infrastructure, it would be useful to share code at this higher level as well.
Applicability
A domain entity module is useful for things that are fairly complex to implement, and that are used in pretty much the same way in multiple places in your system. Don’t create a domain entity module that you only use once. And don’t create one of these modules for multiple instances of the same thing, when each instance is significantly different. The first case is a one-shot module (“Antipattern: One-shot Module”), the second risks becoming a spaghetti module (“Antipattern: Spaghetti Module”).
For example, you may run multiple application servers that use the same stack-operating system, application language, and application deployment method. This is a candidate for a domain entity module.
As a counter-example, you may have multiple application servers, but some run Windows, some run Linux. One runs a stateless PHP application, another runs a Java application on Tomcat with a MySQL database, while a third hosts a .Net application that uses message queues to integrate with other applications. Although all three of these are application servers, their implementation is quite different. Any module that can create a suitable infrastructure stack for all of these is unlikely to have a clean design and implementation.
Implementation
On a concrete level, implementing a domain entity model is a matter of writing the code for a related grouping of infrastructure in a single module. But the best way to create a high-quality codebase that is easy for people to learn and maintain is to take a design-led approach.
I recommend drawing from lessons learned in software architecture and design. The domain entity module pattern derives from Domain Driven Design (DDD)5, which creates a conceptual model for the business domain of a software system, and uses that to drive the design of the system itself. Infrastructure, especially one designed and built as software, can be seen as a domain in its own right. The domain is building, delivering, and running software.
A particularly powerful approach is for an organization to use DDD to design the architecture for the business software, and then extend the domain to include the systems and services used for building and running that software.
The code to implement a Java application server might look like Example 6-9. This example creates and assembles three different resources: a DNS entry, which points to a load balancer, which routes traffic to a server cluster.
Example 6-9. Example domain entity module
declare module:java-application-infrastructuredns_entry:id:"${APP_NAME}-hostname"record_type:"A"hostname:"${APP_NAME}.foodspin.io"ip_address:{$load_balancer.ip_address}server_cluster:id:"${APP_NAME}-cluster"min_size:1max_size:3each_server_node:source_image:base_linuxmemory:4GBprovision:tool:servermakerrole:appserverparameters:app_package:"${APP_NAME}-${APP_VERSION}.war"app_repository:"repository.foodspin.io"load_balancer:protocol:httpstarget:type:server_clustertarget_id:"${APP_NAME}-cluster"
Code to provision a stack that runs a search application using this module might look like this:
use module:java-application-infrastructureapp_name:foodspin_search_appapp_version:1.23
Related patterns
If you find that some stack projects have very little code other than importing a single module, you might consider putting the code directly into the stack project. Reusing code in the form of an entire stack, rather than a module, is the reusable stack pattern (“Pattern: Reusable Stack”). In some cases, having the entire stack code in a module is deliberate, as in the wrapper stack pattern (“Pattern: Wrapper Stack”).
A facade module (“Pattern: Facade Module”) is like a domain entity module that only creates a single low-level infrastructure element. A spaghetti module (“Antipattern: Spaghetti Module”) is similar to a domain entity module but has too many different options.
Antipattern: Spaghetti Module
A Spaghetti Module is configurable to the point where it creates significantly different results depending on the parameters given to it. The implementation of the module is messy and difficult to understand, because it has too many moving parts:
Example 6-10. Example of a spaghetti module
declare module:application-server-infrastructurevariable:network_segment = {if ${parameter.network_access} = "public"id:public_subnetelse if ${parameter.network_access} = "customer"id:customer_subnetelseid:internal_subnetend}switch ${parameter.application_type}:"java":virtual_machine:origin_image:base_tomcatnetwork_segment:${variable.network_segment}server_configuration:if ${parameter.database} != "none"database_connection:${database_instance.my_database.connection_string}end..."NET":virtual_machine:origin_image:windows_servernetwork_segment:${variable.network_segment}server_configuration:if ${parameter.database} != "none"database_connection:${database_instance.my_database.connection_string}end..."php":container_group:cluster_id:${parameter.container_cluster}container_image:nginx_php_imagenetwork_segment:${variable.network_segment}server_configuration:if ${parameter.database} != "none"database_connection:${database_instance.my_database.connection_string}end...endswitch ${parameter.database}:"mysql":database_instance:my_databasetype:mysql......
The example code above assigns the server it creates to one of three different network segments, and optionally creates a database cluster and passes a connection string to the server configuration. In some cases, it creates a group of container instances rather than a virtual server. This module is a bit of a beast.
Also Known As
Swiss Army module.
Motivation
As with other antipatterns, people create a spaghetti module by accident, often over time. You may create a facade module (“Pattern: Facade Module”) for a common infrastructure element, such as a server, that grows so that it can create radically different types of servers. Or you may create a domain entity module (“Pattern: Domain Entity Module”) for an application’s infrastructure. But then you find that the module needs to optionally include a variety of elements, such as databases, message queues, load balancers, and public Internet gateways, depending on the application that runs on it.
Consequences
A module that does too many things is less maintainable than one with a tighter scope. The more things a module does, and the more variations there are in the infrastructure that it can create, the harder it is to change it without breaking something. These modules are harder to test. As I explain in a later chapter (Chapter 9), better-designed code is easier to test, so if you’re struggling to write automated tests and build pipelines to test the module in isolation, It’s a sign that you may have a spaghetti module.
Implementation
A spaghetti module’s code often contains conditionals, that apply different specifications in different situations. For example, a database cluster module might take a parameter to choose which database to provision.
When you realize you have a spaghetti module on your hands, you should refactor it. Often, you can split it into different modules, each with a more focused remit. For example, you might decompose your single application infrastructure module into different modules for different parts of the application’s infrastructure. An example of a stack that uses decomposed modules in this way, rather than using the spaghetti module from the earlier example (Example 6-10) might look like this:
Example 6-11. Example of using decomposed modules rather than a single spaghetti module
use module:java-application-serversname:burgerbarn_appserverapplication:"shopping_app"application_version:"4.20"network_segment:customer_subnetserver_configuration:database_connection:${module.mysql-database.outputs.connection_string}use module:mysql-databasecluster_minimum:1cluster_maximum:3allow_connections_from:customer_subnet
Each of the modules is smaller, simpler, and so easier to maintain and tested than the original spaghetti module.
Related patterns
A spaghetti module is often a domain entity module (“Pattern: Domain Entity Module”) gone wrong.
Antipattern: Obfuscation Layer
Unlike the other patterns and antipatterns in this chapter, an Obfuscation Layer is composed of multiple modules. Intended to hide or abstract details of the infrastructure from people writing stack code, it instead makes the codebase as a whole harder to understand, maintain, and use.
Also Known As
Abstraction layer, portability layer, in-house infrastructure model.
Motivation
An obfuscation layer is usually intended to simplify or standardize implementation. A team might create a library of modules as an in-house model for building infrastructure. Sometimes the intention is for people to write stack code without needing to learn the stack tool itself. In other cases, the layer tries to abstract the specifics of the infrastructure platform so that code can be written once and used across multiple platforms.
Consequences
If your team uses a heavily customized model for infrastructure code, then it becomes a barrier to new people joining your team. Even someone who knows the stack tools you use has a steep learning curve to understand your special language. An in-house obfuscation layer tends to be inflexible, forcing people to either work around its limitations or spend time making changes to the obfuscation layer itself. Either way, people waste time creating and maintaining extra code.
People, especially managers and hands-off architects6, often overestimate the benefit of hiding an underlying platform or tools from people writing infrastructure code. I have yet to see a cloud abstraction layer that adds noticeable value, or that avoids adding cost and complexity. Most fail at both.
Related patterns
Domain entity modules (“Pattern: Domain Entity Module”) may be used to create an obfuscation layer at a higher level, while facade modules (“Pattern: Facade Module”) would be used to obfuscate lower-level resources. If each module in the layer handles multiple platforms, they are probably spaghetti modules (“Antipattern: Spaghetti Module”).
Antipattern: One-shot Module
A one-shot module is only used once in a codebase, rather than being reused.
Motivation
People usually create one-shot modules as a way to organize the code in a project.
Applicability
If a stack project includes enough code that it becomes difficult to navigate, you have a few options. Splitting the stack into modules is one approach. If the stack is conceptually doing too much, it might be better to divide it into multiple stacks, using an appropriate stack structural pattern (see “Patterns and antipatterns for structuring stacks”). Otherwise, merely organizing code into different files and, if necessary, different folders, can make it easier to navigate and understand the codebase without the overhead of the other options.
Consequences
Organizing the code into modules adds the overhead of declaring the module and passing parameters. You add even more complexity if you manage the module code separately, with separate versioning. This overhead is worthwhile when you share code across multiple stack projects. The benefits of code reuse make up for the added time and energy of maintaining a separate module. Paying that cost when you’re not using the benefit is a waste.
Related patterns
A one-shot module may map closely to lower-level infrastructure elements, like a facade module (“Pattern: Facade Module”), or to a higher-level entity, like a domain entity module (“Pattern: Domain Entity Module”).
Conclusion
This chapter has explored the use of modules to share code across stacks. Modules are a popular mechanism to manage the growth of a codebase, but as you can see, it’s easy to create an unmaintainable mess.
The next chapter (Chapter-Building-Environments) is devoted to one of the most common situations that require multiple instances of the same or similar infrastructure. This need leads to some patterns and antipatterns for implementing shared code at the level of the stack.
1 The DRY principle, and others, can be found in The Pragmatic Programmer: From Journeyman to Master by Andrew Hunt and David Thomas
2 In later chapters ([Link to Come]) we’ll see that a stack can depend on another stack, as well.
3 Two resources to get started include Martin Fowler’s paper Reducing Coupling, and Mohamed Sanaulla’s post Cohesion and Coupling: Two OO Design Principles.
4 Later on (“Example of how Foodspin moves to reusable stacks”) we’ll see how the Foodspin team evolves this to use a single reusable stack project
5 See Domain-Driven Design: Tackling Complexity in the Heart of Software, by Eric Evans, 2003 Addison Wesley
6 For a thoughtful view on how architecture, and architects, relates to implementation, I recommend the Architect Elevator, by Gregor Hohpe.