
Chapter 8
Eye Gaze Tracking
Heiko Drewes
LFE Medieninformatik, Ludwig-Maximilians-Universität, München, Germany
8.1 Introduction and Motivation
The amount of our interaction with computer devices increases steadily. Therefore, research in the field of HCI (Human Computer Interaction) looks for interaction methods which are more efficient, more intuitive, and easier. “Efficiency” means that we can do our interaction as quick as possible. We also try to avoid lectures or training for being able to operate computer devices, which means we like to have intuitive interfaces. Finally, we dislike efforts, either physical or mental. We expect that our interaction with a device should be easy.
Traditional interaction devices, such as mouse and keyboard, can cause physical injuries like carpal tunnel syndrome if used extensively. Keyboard and mouse are also not very practical in a mobile context – and finally, we always look for alternatives or even something better. Using our gaze for computer interaction seems to be a promising idea. The eyes are quick and we move them intuitively and with ease, and therefore eye gaze interaction would fulfill all criteria given above.
In addition, eye trackers could be manufactured at low cost if produced in big quantities. A minimal eye tracker consists of a video camera, an LED, a processor and software. In a smart device, such as smart phones, tablets, laptops and even some new TV sets, all these components are already present but, even if produced separately, the costs will be comparable to the costs of manufacturing an optical mouse. Advanced eye trackers use two cameras for a stereoscopic view and sometimes several LEDs, but still, especially if produced for a mass market, the cost is affordable.
A further reason to consider gaze as a future interaction technology is the importance of gaze in human-human interaction.
When comparing human eyes with animal eyes (see Figure 8.1), the white in the human eyes is very distinctive. In animal eyes – eyes of mammals in particular, which work in a similar way to human eyes – no white eyeball is visible. For this reason, it is more difficult to determine the direction of an animal's gaze than of a human's. What role the awareness of the gaze's direction played in the evolution of our species is a field for speculation. What is certain is that we use our eyes for communication. Typically, we address persons or objects with the gaze. If somebody asks somebody else: “Can I take this?” the person knows at which object the asking person is looking and therefore knows what “this” is. If we want human-computer interaction to be similar to human-human interaction, the computer needs gaze awareness.

Figure 8.1 The eyes of a chimpanzee and of a human.
Eye gaze interaction brings along further advantages. It works without physical contact and therefore is a very hygienic way of interaction. Without touch, the device also does not need cleaning. An eye tracker does not have moving parts, meaning it does not need maintenance. If combined with a zoom lens, an eye tracker works over distances longer than our arms and can serve as a remote control.
Additionally, eye trackers can make our computer interaction safer, because they explicitly require our attention. A mobile phone which requires eye contact for an outgoing call will not initiate a call due to accidentally pressed buttons while in a pocket. Finally, eye trackers have the potential for more convenient interaction, as they can detect our activities. For example, when we are reading, the system could postpone non-urgent notifications like the availability of a software update.
This chapter continues with basic knowledge of human eyes and an overview on eye-tracking technologies. The next section explains objections and obstacles for eye gaze interaction, followed by a short summary of eye-tracking research during the last three decades. The next three sections present different approaches to gaze interaction.
The first and most obvious approach is eye pointing, which is similar to pointing with a mouse, albeit with less accuracy. The eye pointing section includes a comparison of mouse and gaze pointing, and discusses the coordination of hand and eyes.
The second approach is the use of gaze gestures. Gaze gestures are not very intuitive, but gestures belong to the standard repertoire of interaction methods. Beside gesture detection and gesture alphabets, this section deals also with the separation of gestures from natural eye movements.
The third approach is eye gaze as context information. Here, the eye movements do not trigger intentional commands, but the system observes and analyzes eye movements with the goal of assisting and supporting the user in a smart way. The section deals with activity recognition in general and, in particular, with reading and attention detection. The chapter closes with an outlook on further development of eye gaze interaction.
8.2 The Eyes
There is an immense knowledge on the eyes in fields such as medicine, biology, neurology and psychology. The knowledge on eyes presented here is simplified and only presents facts necessary for understanding this chapter.
From a technical point of view, we can see the eyes as a pair of motion-stabilized cameras moving synchronously. Each eyeball has three pairs of antagonistic muscles (see Figure 8.2), which can compensate the head's three degrees of freedom – horizontal and vertical movements and rotations around the line of sight.
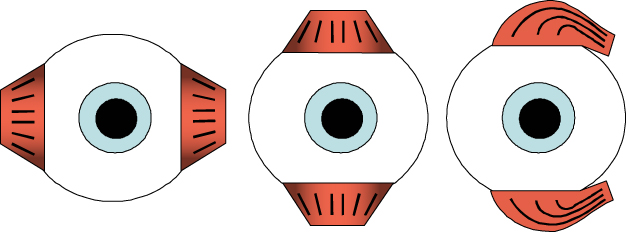
Figure 8.2 Three pairs of muscles can compensate all movements of the head.
Figure 8.3 depicts the simplified schematics of the eye. The eye is similar to a camera – the iris is the aperture, the retina is a photo-sensitive surface, and both camera and eye have a lens. In contrast to a camera, the eye focuses on an object by changing the form of the lens, not by changing its position. The photo-sensitive surfaces of camera and eye differ a lot. The camera has a planar photosensitive surface with equally distributed light receptors, typically for red, green, and blue light. The photo-sensitive surface of the eye is round, and the light receptors are not equally distributed. Beside receptors for the three light colors (cones) the eye has additional receptors which are unspecific for the color of light but more sensitive (rods). The rods give us some ability of night vision. The cones on the retina have a low density, except for a small spot opposite to the pupil, called the fovea. As a consequence, we do not see clearly except in a narrow field of about 1–2 degrees, which is about a thumbnail size in arm length distance. The high-resolution picture of our mental eye is an illusion generated by the brain.
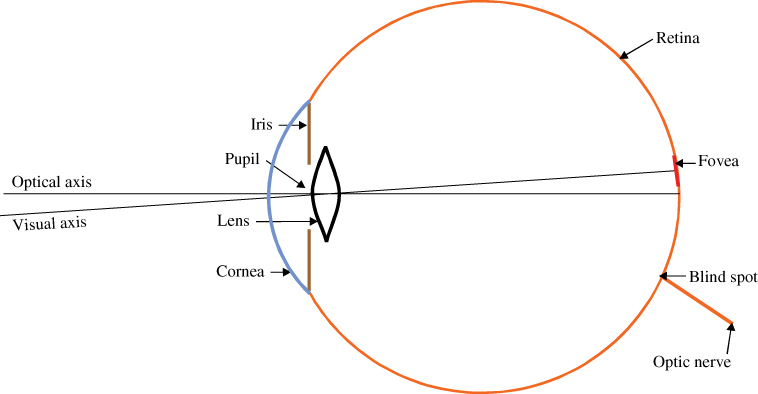
Figure 8.3 Schematics of the eye.
The small field of vision in which we can see with high resolution has consequences. It is the reason why we move our eyes. We always move our eyes to a position that projects whatever we are looking at directly on our fovea. There are two types of movement to achieve this:
- One type of movement is a compensation movement. It occurs when we move our head but keep our gaze on an object. This motion stabilization is necessary, because we need a stable projection on the fovea to see. Such motion stabilization takes place also when we watch a moving object. Movements for keeping an image stable are smooth.
- The other type of eye movements is an abrupt quick movement, which is called a saccade. Typically, the eye moves as quickly as possible to an interesting spot and rests there for a while, which is called a fixation. After this, the eye does another saccade, and so on. Most of the time, our eyes do saccadic movements.
When the eye moves, it does not change its position but it rotates around its center. Therefore the length of a saccade is defined by the angle of the pupil's normal at the beginning and end of the saccade. Figure 8.4 shows saccade times versus angle. It is clear that there is a minimum time for a saccade, depending on the angle. However, for large angles, the time only increases marginally. A saccade for angles above 5° lasts about 100–150 milliseconds.
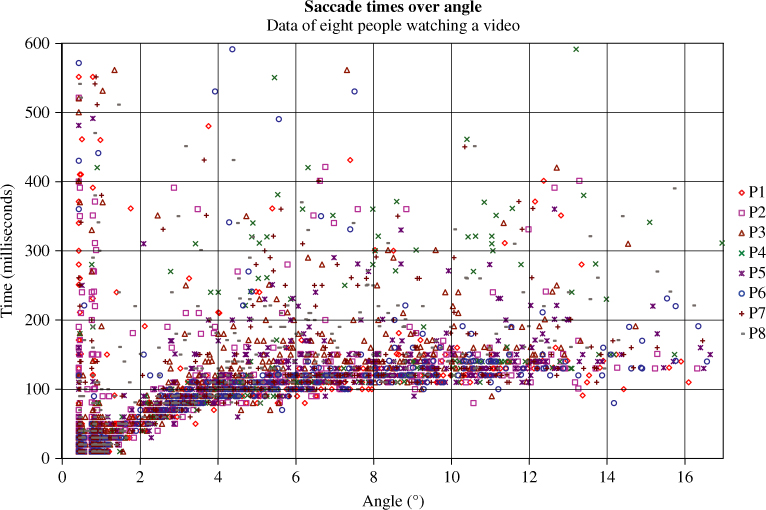
Figure 8.4 Saccade times over their length.
The saccadic movement is so quick – up to 700°/s – that the receptors on the retina do not have time enough to detect a picture and, in consequence, we are blind during the saccade. Therefore, there is no control-feedback loop to steer the eye into the target. Psychology calls the saccadic eye movements ballistic. This means that saccadic eye movements do not obey Fitt's law [1], even if some publications from the HCI community state the opposite [2–5]. In contrast to movements obeying Fitt's law, the time of a ballistic movement does not depend on the target size.
Carpenter measured the rotation amplitude and duration for saccades in 1977 [6]. He used a linear approximation to express the relation between the time ![]() of a saccade and its amplitude
of a saccade and its amplitude ![]() :
:
In 1989, Abrams, Meyer, and Kornblum [7] suggested a model where the muscle force is constantly increasing over time. As the mass and shape of the eye does not change, the acceleration a(t) is proportional to the force and also increasing constantly over time:
Integrating twice over time and solving the equation for the amplitude shows that there is a cubic root relation between time and amplitude:
The constant ![]() depends on constant
depends on constant ![]() and the eye's polar moment of inertia.
and the eye's polar moment of inertia.
Looking at Figure 8.4 shows that a linear approximation, assuming the data are on a straight line, as done by Carpenter, is legitimate in a certain range. The model from [7], however, fits better with experimental data.
Fixation times reported by an eye tracker typically range from 0–1000 milliseconds. Fixations longer than 1000 milliseconds normally do not occur. Short fixations should be taken with care. The eye and the brain need some time for image processing and, therefore, a fixation should last some time. Very short fixations are meaningless or an artifact from the saccade detection algorithm.
8.3 Eye Trackers
The term eye tracking does not have a precise definition. In some contexts, eye tracking means tracking the position of the eyes, while in some other contexts it means detection of the gaze direction. There are also people who track the eye as a whole, including the eyebrows, and try to detect the emotional state – for example, [8, 9]. This kind of eye tracking is a part of facial expression analysis. Within this text, the term “eye tracker” refers to the detection of the gaze's direction and is sometimes, therefore, also called “gaze tracker” or “eye gaze tracker”. Tracking the position of the eyes is a subtask of gaze-tracking systems which allows free head movements in front of a display.
8.3.1 Types of Eye Trackers
There are three different methods to track the motion of the eyes.
The most direct method is the fixation of a sensor to the eye. The fixation of small levers to the eyeball belongs to this category, but is not recommended because of high risk of injuries. A safer way of applying sensors to the eyes is using contact lenses. An integrated mirror in the contact lens allows measuring reflected light [10]. Alternatively, an integrated coil in the contact lens allows detection of the coil's orientation in a magnetic field [11]. The thin wire connecting the coil with the measuring device is not comfortable for the subject. The big advantage of such a method is high accuracy and the nearly unlimited resolution in time. For this reason, medical and psychological research uses this method.
Another method is electrooculography (EOG), where sensors attached to the skin around the eyes measure an electric field. Initially, it was believed that the sensors measure the electric potential of the eye muscles. It turned out that it is the electric field of the eye which is an electric dipole. The method is sensitive to electro-magnetic interferences, but works well as the technology is advanced and has already existed for a long time; therefore there is a lot of knowledge and standards on the topic [12]. The big advantage of the method is its ability to detect eye movements even when the eye is closed, e.g., while sleeping. Modern hardware allows integrating the sensors into glasses to build wearable EOG eye trackers [13].
Both methods explained so far are obtrusive and are not suited well for interaction by gaze. The third and preferred method for eye-gaze interaction is video-based. The central part of this method is a video camera connected to a computer for real-time image processing. The image processing takes the pictures delivered from the camera and detects the pupil to calculate the direction of the gaze. The big advantage of video-based eye tracking is its unobtrusiveness. Consequently, it is the method of choice for building eye-gaze interfaces for human-computer interaction. A detailed description of the video-based corneal reflection method follows in the next section.
There are two general types of video-based eye trackers: stationary systems and mobile systems.
Stationary eye trackers, such as the one shown in Figure 8.5, deliver the gaze's direction relative to the space around the user, typically as screen coordinates. Simple stationary eye trackers need a stable position for the eye and, therefore, require head fixation. Disabled people who cannot move anything except the eyes use such systems. People without disabilities prefer systems which allow free movement in front of the display. Such systems do not only track the gaze direction, but also the position and orientation of the head, typically by a pair of cameras providing a stereoscopic view. Stationary eye trackers can be a stand-alone device which allows tracking the gaze on physical objects. However, as many eye-tracking applications track the gaze in front of a display, there are eye trackers integrated into displays which may not even be noticed by the user.

Figure 8.5 Stationary eye trackers from Tobii, one stand-alone system and one integrated into a display. Source: Reproduced with permission from Tobii.
Mobile eye trackers are attached to the head of the user. This type of eye tracker delivers the gaze's direction relatively to the head's orientation. Typically, mobile eye trackers come with a head-mounted camera which captures what the user sees. With the data from the eye tracker, it is possible to calculate the point the user is looking at and mark this point in the images delivered by the head-mounted camera. With the recent progress in building small cameras, it is possible to build eye trackers integrated into glasses. As an example, Figure 8.6 shows a pair of eye tracking glasses.

Figure 8.6 Eye tracking glasses from SMI. Source: SMI Eye Tracking Glasses. Reproduced by permission of SensoMotoric Instruments.
There is a further class of video-based eye trackers introduced by Vertegaal et al., which are called ECS for eye contact sensors [14]. An ECS does not deliver coordinates for the gaze direction but only signals eye contact. This works up to a distance of ten meters. The eye contact sensor Eyebox2 from xuuk inc. is shown in Figure 8.7.

Figure 8.7 The Eye Contact Sensor Eyebox2 from xuuk inc. Source: xuuk.inc. Reproduced with permission.
8.3.2 Corneal Reflection Method
The general task of a video-based eye tracker is to estimate the direction of gaze from the picture delivered by a video camera.
A possible way is to detect the iris using the high contrast of the white of the eye and the dark iris. This method results in good horizontal, but bad vertical, accuracy as the upper and lower part of the iris is covered by the eyelid. For this reason, most video-based eye trackers detect the pupil instead. Detecting the pupil in the camera image is a task for image recognition, typically edge detection, to estimate the elliptical contour of the pupil [15]. Another algorithm for pupil-detection is the starburst algorithm explained in [16].
There are two methods to detect the pupil – the dark and the bright pupil method. With the dark pupil method, the image processing locates the position of a black pupil in the camera image. This can be problematic for dark brown eyes, where the contrast between the brown iris and the black pupil is very low. The bright pupil method uses additional illumination, with infrared light coming from the same direction as the view of the camera. Therefore, an infrared LED has to be mounted inside or close to the camera, which requires mechanical effort. The retina reflects the infrared light and this makes the pupil appear white in the camera image. The effect is well known as “red eye” when photographing faces with a flash. For differences in the infrared bright pupil response among individuals, see [17].
Most eye trackers use a reflection on the cornea, also called first Purkinje image, to estimate the gaze direction. As the cornea has a perfect spherical shape, the glint stays in the same position, independent of the gaze direction (Figure 8.9).
The eye tracker's image processing software detects the position of the glint and the center of the pupil. The vector from the glint to the center of the pupil is the basis for the calculation of the gaze's direction (Figure 8.8), and finally the position of the gaze on the screen. A direct calculation would not only need the spatial geometry of the eye tracker, the infrared LED and the display and the eye, but also the radius of the eyeball, which is specific to the subject using the eye tracker. For this reason, a calibration procedure estimates the parameters for the mapping of the glint-pupil vector to positions on the screen. A calibration procedure asks the user to look at several calibration points displayed during the calibration. A calibration with four points uses calibration points close to the four corners of the display.
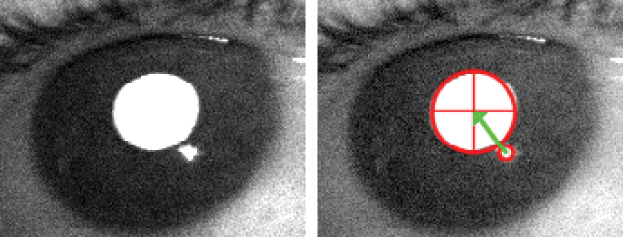
Figure 8.8 The vector from the glint to the pupil's center is the basis to calculate the gaze direction.
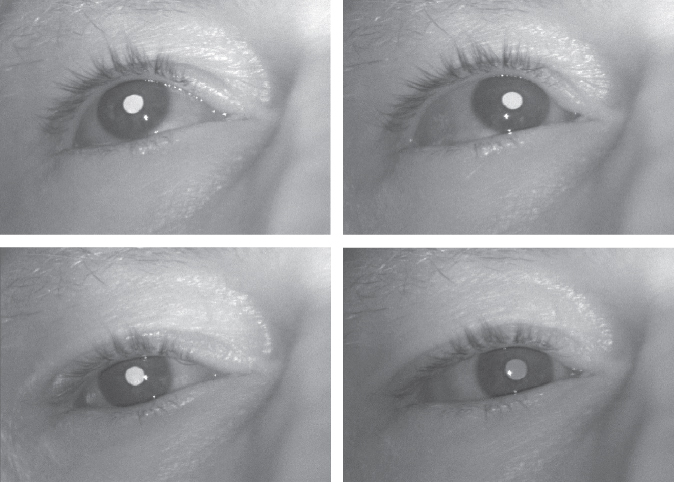
Figure 8.9 Looking to the four corners of the screen – the reflection stays in the same position.
The corneal reflection method does not work for people with eyeball deformations. It can also be problematic when people wear contact lenses. Glasses are less problematic; although the glasses may change the position of the glint, the reflection stays in the same position. The calibration compensates for the optical distortion of the glasses.
The corneal reflection method explained so far requires that the eye stays in a stable position, which means it requires a head fixation. For human-computer interaction, it is desirable to allow free movement in front of the device. Such eye trackers use stereoscopic views, with two cameras. Alternatively, it is possible to use only one camera and multiple light sources for multiple glints. For a description of how such system works see [18–20]. The way how commercial eye-tracking systems work, however, is normally a business secret.
The eye contact sensor presented above uses the corneal reflection method, too. For the illumination, a set of infrared LEDs is mounted on-axis around an infrared camera. When the camera delivers a picture with a glint inside the pupil, it means that the onlooker is looking directly towards the camera. A big advantage of this method is that it does not need calibration.
8.4 Objections and Obstacles
In the introduction, gaze interaction seemed promising. However, not all promises are easy to fulfill, and there are some obstacles on the way to gaze interaction.
8.4.1 Human Aspects
There is some general concern that gaze interfaces will conflict with the primary task of the eye, which is vision. The eye could get an input-output conflict, where vision and interaction require different eye movements. Zhai et al. wrote in 1999: “Second, and perhaps more importantly, the eye, as one of our primary perceptual devices, has not evolved to be a control organ. Sometimes its movements are voluntarily controlled while at other times it is driven by external events.” [21]
Changes in the field of vision can trigger an eye movement. If a gaze-aware interface displays a blinking object, the eyes will most probably move to the blinking object. If this eye movement triggers a new command, the user will invoke this command unintentionally. In general, it is possible to create such input-output conflict in gaze interfaces. However, a developer of gaze interfaces has to construct such conflicts. Typically, such conflicts do not occur, and no scientist reported serious problems of this type.
There are also objections that we are not able to control our eye movements. However, although our eye movements are driven by the task of vision, we are aware of our gaze and we are able to controlling it. Otherwise, we would violate our social protocols.
A further argument against gaze interaction is that the eye could fatigue and problems such as repetitive stress injuries could occur. However, we move our eyes constantly, even while we sleep. If a person does not move the eyes for a minute, we start to worry whether they have lost consciousness. Fatigue seems not to be a problem for the eyes.
Finally, another concern against eye-tracking is acceptance. Video cameras and internet connections in all electronic devices would provide the infrastructure for Orwell's vision of “big brother is watching you”. The fact that an eye tracker has a video camera is something we may get used to, with all the other cameras around us already. However, the users of an eye-tracking system could feel observed, and perhaps will not accept it in private spaces like the bathroom. It seems that an analysis of eye movements can judge our reading skills and therefore tell a lot about our intelligence, or at least our formation. Such conclusions, which are possible from gaze data, could also frighten people, especially employees.
8.4.2 Outdoor Use
Stationary eye trackers normally work well and reliably, as they are typically located in an indoor environment where the light conditions are relatively stable. In outdoor environments, the light varies in a wide range, which means there can be extreme contrasts. Additionally, the light can change also very quickly, for example by moving shadows, especially if sitting in a car. Such a situation is still a challenge for cameras. Infrared light-based systems, which most commercial systems are, can have problems, as the sun is a bright infrared radiator. This makes it difficult to reliably detect the pupil and the glint within a camera picture. Approaches with differential pictures and infrared illumination synchronized with the frame rate of the video camera or the use of polarized light are promising [22]. Therewith, eye tracking for most light conditions, except the extremes, should be achievable.
8.4.3 Calibration
Eye trackers need calibration to achieve a good accuracy. Methods using the glint of an infrared LED depend on the radius of the eyeball and, therefore, need calibration for the user. Even eye trackers which are able to determine the orientation of the pupil in space without a glint, and therefore do not depend on the eyeball's radius, need a calibration. The reason is that the position of the fovea differs from individual to individual, and the optical axis (the normal on the pupil's center) is not exactly the visual axis (line from the fovea to the pupil's center).
The positive aspect of the calibration procedure is that it is only necessary to do it once. A personal system equipped with an eye tracker requires a calibration only once. For public systems which require reasonable accuracy for the gaze detection, for example ATMs, the calibration procedure is a real obstacle.
One way to avoid the calibration issue is not to use absolute gaze positions, but only relative gaze movements. Detecting only relative movements means using gestures. This is an option, but it is also a severe restriction.
8.4.4 Accuracy
The accuracy issue has two aspects. One is the accuracy of eye tracker; the other is the accuracy of the eye movements.
The accuracy of available eye trackers is still far from physical limits. Eye trackers have a spatial and a temporal resolution. The temporal resolution depends on camera and processor speed and algorithms. For stationary eye trackers the spatial resolution is mainly a question of camera resolution. As camera resolutions and processor speed will continue to increase, we can expect that we can build eye trackers with higher accuracy in near future. For mobile systems, the spatial accuracy also depends on mechanical stability of the head-mounted system.
Eye trackers nowadays typically state an accuracy of ![]() . In arm length distance, which is the typical distance of a display from the eyes, the eye tracker's accuracy is about the size of a thumbnail. This accuracy is not sufficient to use eye gaze as a substitute for a mouse. Typical graphical user interfaces use interaction elements which are smaller than a thumbnail.
. In arm length distance, which is the typical distance of a display from the eyes, the eye tracker's accuracy is about the size of a thumbnail. This accuracy is not sufficient to use eye gaze as a substitute for a mouse. Typical graphical user interfaces use interaction elements which are smaller than a thumbnail.
The accuracy of our eyes is a subtle problem. The question is not only how accurately we can position our gaze, but also how accurately we do. Even if we can fixate quite accurately, the question is how much concentration we need for this. For recognizing something, it is sufficient that the object has a projection inside the fovea and, therefore, we should expect that the eye positions itself with this accuracy. The situation seems to be comparable with spotting an insect at night with a torch – it is enough if the insect is in the circle of light and it is not worth the effort to center it.
Ware and Mikaelian expressed it this way:
“The research literature on normal eye movements tells us that it is possible to fixate as accurately as 10 minutes of visual angle (0.16 deg) but that uncontrolled spontaneous movements cause the eye to periodically jerk off target. It is likely, however, that when an observer is attempting to fixate numerous targets successively, accuracy is considerably reduced and misplacements as large as a degree may become common.” [2]
8.4.5 Midas Touch Problem
Although gaze pointing is very similar to pointing with a finger, there is an important difference: we cannot lift our gaze like a finger. On a touch-sensitive display, we can point on an interaction element and trigger the command by touching the surface. With the gaze, we can also point to an interaction element, but we do not have a touch event. If we trigger the command just by looking at it, we have the problem that even if we only want to see what is there, we will trigger a command. Jacob called this the Midas Touch problem, which he explained with these words:
“At first, it is empowering simply to look at what you want and have it happen. Before long, though, it becomes like the Midas Touch. Everywhere you look, another command is activated; you cannot look anywhere without issuing a command” [23].
When Jacob identified the Midas Touch problem, he had eye pointing in his mind. On a more general level, the Midas Touch problem is the problem of deciding whether an eye activity was made to issue a command, or happened within the task of vision. The problem remains, even if changing the interaction method. Gaze gestures also bear the danger that they can occur within natural eye movements and invoke unintended commands. As gestures do not imply touches, the term Midas Touch problem in this context would be misleading, and it is better to speak about the problem of separation of gestures from natural movements.
8.5 Eye Gaze Interaction Research
The idea of using eye gaze for interaction is already more than 30 years old, and a lot of research has been done since then. Therefore, the following overview only goes a short way through the historic development of this field of research.
Gaze interaction became possible with the invention of the electronic video camera and computers which are powerful enough to do real-time image processing. The first systems were built in the 1970s to assist disabled people. The typical application for these people is eye-typing [24]. For eye-typing, the display shows a standard keyboard. If the gaze hits a key on this virtual keyboard, the corresponding key is highlighted. If the gaze stays on this key longer than a predefined dwell time – typically around 500 milliseconds – it means the key was pressed.
In 1981 Bolt [25] provided a vision of multi-modal gaze interaction for people without disabilities. He described a Media Room with a big display where 15–50 windows display dynamic content simultaneously, which he named “World of Windows”. His idea was to zoom in upon some window the user is looking at. He described an interface method based on dwell time and he also discussed multi-modal interface techniques. One year later, Bolt published the paper “Eyes at the Interface” [26], summing up the importance of gaze for communication, and concludes there is a need of gaze-awareness for the interface. His vision has not yet been realized completely.
In 1987, Ware and Mikaelian did a systematic research on eye pointing [2]. In their paper, “An evaluation of an eye tracker as a device for computer input”, they introduced three different selection methods, which they called “dwell time button”, “screen button”, and “hardware button”, and measured the times the eyes need for selection. For the dwell-time button method, the gaze has to stay for a certain time (the dwell time) on the button to trigger the action associated with the button. The screen button method is a two-target task. The gaze moves to the chosen button and, afterwards, to the screen key to trigger the action. The hardware button method uses a key to press with the finger in the moment when the gaze is on the chosen button. The first two methods are gaze-only, while the hardware button uses an extra modality. Ware and Mikaelian fitted their data against a “modified” Fitts' law to compare their results with the experiments done by Card et al. [27] for mouse devices. However, Fitts' law does not hold for the eye (see also the chapter on the eyes on page 252).
In 1990, Jacob [23] systematically researched the interactions needed to operate a GUI (graphical user interface) with the eyes – object selection, moving objects, scrolling text, invoking menu commands and setting the keyboard focus to a window. One big contribution of this paper is the identification of the Midas Touch problem (explained in section 8.4). The generality of Jacob's paper caused all further research to focus on single or more specialized problems of eye-gaze interaction.
In 1999, Zhai et al. made a suggestion to handle the low accuracy intrinsic to eye pointing (explained in section 8.4) and named it MAGIC (Mouse And Gaze Input Cascaded) pointing [21]. MAGIC pointing uses the gaze for raw positioning and a traditional mouse device for the fine positioning.
In 2005, Vertegaal et al. introduced Media EyePliances, where a single remote control can interact with several media devices [14]. The selection of the device to control happens by looking at it. For this, they augmented the devices with a simple form of an eye tracker, called eye contact sensor ECS. In another paper from the same year [28], Vertegaal et al. used the ECS in combination with mobile devices. It is typical for mobile devices that they do not get full attention all the time, as the user of the mobile device has to pay some attention to her or his surroundings. With two applications, seeTXT and seeTV, they demonstrated how to use the eye gaze to detect attention and how to use this context information to control the device. The seeTV application is a video player, which automatically pauses when the user is not looking at it. seeTXT is a reading application, which advances text only when the user is looking.
In recent years, eye-tracking interaction research has become popular and the number of publications has increased enormously. There has been a special conference for the topic since the year 2000 called ETRA (Eye-Tracking Research and Application). Since 2005, the COGAIN (Communication by Gaze Interaction) initiative, supported by the European Commission, has also organized conferences and offers a bibliography of research papers on the internet.
8.6 Gaze Pointing
The most obvious way to utilize gaze as computer input is gaze pointing. Looking at something is intuitive, and the eyes perform this task quickly and with ease. Pointing is also the basic operation to interact with graphical user interfaces, and performing pointing actions with the eyes would speed up our interaction. In consequence, most of the research done on gaze interaction deals with eye gaze pointing. However, as mentioned already in the chapter on objections and obstacles (section 8.4), there are intrinsic problems in eye pointing, such as the Midas Touch problem and the low accuracy.
8.6.1 Solving the Midas Touch Problem
A gaze-aware interface which issues commands when looking at an interaction object would trigger actions even when we only want to look what is there. The problem is known as Midas Touch problem, and there are several ways solving it. Gaze-only systems, as typically used by disabled people, introduce a dwell time. This means that the user has to look for a certain time, the dwell time, at an interaction object for triggering a command. The dwell time is normally in the range of 500–1000 milliseconds and eats up the time saved by the quick eye movement.
Another method for solving the Midas Touch problem is using a further modality like a gaze key. Pressing the gaze key invokes the command at which the eye is looking at that moment. Using a gaze key allows quick interaction, but also destroys some of the benefits of gaze interfaces. An additional key also means that the interface is not hygienic any more, as there is again something to touch. Additionally, it does not work over distance, as there has to be a key in reach – and finally, it does not work for disabled people as they use a gaze interface, because they are not able to press a key. Thinking more deeply about a gaze key reveals that it only makes sense if the intention is to enter two-dimensional coordinates. Entering a command (e.g., a save operation) by looking at the “save interaction object” and pressing the gaze key provokes the question, “Why not simply press ctrl-s without looking at a special interaction object?”
The frequently mentioned suggestion to blink with the eye for triggering a command does not seem to be an option. The eyes blink from time to time to keep the eyes moist and, therefore, a blink command has to take longer than a natural blink and any speed benefit is lost. It is also a little bit paradoxical to trigger a command at the gaze position in the moment the eye is closed. The main reason, however, for not using blinking is that it does not feel comfortable. The blinking would be a substitute for a mouse click. The number of mouse clicks we perform when operating a graphical user interface is enormous, and easily exceeds thousand clicks per hour. Blinking a thousand times with the eye typically creates a nervous eye.
8.6.2 Solving the Accuracy Issue
The accuracy of current eye trackers, and also the accuracy of our eye movements, does not allow addressing small objects, or even a single pixel. Much research has been done on solving the accuracy problem. The easiest solution is enlarging the interaction objects. Assuming an accuracy of half inch on a 72 dpi display means that interaction objects should not be smaller than ![]() pixels. Existing graphical user interfaces use buttons of
pixels. Existing graphical user interfaces use buttons of ![]() pixels in size, and the height of a menu item or line of text is around 8–12 pixels. This means that the graphical user interface has to be enlarged by a factor of about three in each dimension, or that we need displays roughly ten times bigger. For most situations, such a waste of display area is not acceptable.
pixels in size, and the height of a menu item or line of text is around 8–12 pixels. This means that the graphical user interface has to be enlarged by a factor of about three in each dimension, or that we need displays roughly ten times bigger. For most situations, such a waste of display area is not acceptable.
There are several suggestions from research how to solve the accuracy problem – raw and fine positioning, adding intelligence, expanding targets, and the use of further input modalities – which are discussed below.
Zhai et al. made a suggestion for handling low accuracy which the called MAGIC (Mouse And Gaze Input Cascaded) pointing [21]. MAGIC pointing uses the gaze for raw positioning and a traditional mouse device for the fine positioning. The basic idea of MAGIC pointing is positioning the mouse cursor at the gaze position on the first mouse move after some time of inactivity. With MAGIC pointing, the gaze positions the mouse pointer close to the target and the mouse is used for fine positioning. In their research, Zhai et al. found out that there is a problem of overshooting the target, because hand and mouse are already in motion at the moment of positioning. They suggested a compensation method calculated from the distance and the initial motion vector.
Drewes et al. suggested an enhancement of this principle and called it MAGIC Touch [29]. They built a mouse with a touch-sensitive sensor and positioned the mouse pointer at the gaze position when touching the mouse key. The improvement lies in the absence of compensation methods, because the mouse does not move when putting the finger on the mouse key. A further advantage is that the user can choose the moment of gaze positioning and does not need a period of mouse inactivity.
When watching people working with big screens or dual monitor setups, it is easy to observe that they sometimes have problems with finding the mouse pointer. In addition, the mouse pointer is very often far away from the target intended to click. In consequence, it is necessary to draw the mouse a long way across the screen. The principle of raw positioning by gaze and fine positioning with the mouse not only solves the accuracy problem, but also avoids the problem with finding the mouse pointer. Additionally, it saves a lot of the distance covered by the mouse and therefore helps to prevent repetitive stress injuries.
In 2000, Salvucci and Anderson presented their intelligent gaze-added interfaces [30]. This starts with a system where the gaze tracker delivers x-y positions to a standard GUI that highlights the interaction object the user is looking at. A gaze key, analogous to a mouse key, offers the user the possibility of triggering the action. To solve the accuracy issue, the system interprets the gaze input in an intelligent way – it maps the gaze points to the items which the user is likely attending. To find these items, the system uses a probabilistic algorithm which determines the items by the location of the gaze (i.e., the items close to the reported gaze point) and the context of the task (e.g., the likelihood of a command after a previous command).
Another approach to solve the accuracy problem is the use of expanding targets. Balakrishnan [31] and Zhai [32] researched the use of expanding targets for manual pointing and showed that this technique facilitates the pointing task. Miniotas, Špakov and MacKenzie applied this technique to eye gaze pointing [33]. In their experiments, the target expansion was not visually presented to the users, but the interface responded to an expanded target area. They called this technique static expansion. In a second publication, Miniotas and Špakov studied dynamically expanding targets [34], i.e., means targets where the expansion is visible to the users. The research was done for menu targets, and the results showed that the error rate for selecting a menu item reduces drastically at the cost of an increased selection time.
In the same year, Ashmore and Duchowski published the idea of using a fisheye lens to support eye pointing [35].
In 2007, Kumar et al. presented an eye-gaze interface called EyePoint [36]. This interface technique uses expansions of the interaction targets, and it also uses a key as additionally needed input modality. When pressing down this key, the screen area that the gaze looks at becomes enlarged. Within this enlarged screen area, the user selects the target with the gaze and the action is triggered in the moment the user releases the key.
The inaccuracy of gaze pointing means that a pointing action has ambiguities on the target if the targets are close to each other. This gave Minotas et al. the idea to specify the target with an additional speech command [37]. They used targets with different colors and asked the users to speak out the color of the target loudly. They showed that this method allows addressing targets subtending 0.85 degrees in size with 0.3-degree gaps between them.
The method does not bring any speed benefit and it is not clear whether the better pointing accuracy is worth the extra effort of speaking, at least in the case of operating a standard GUI. However, the concept is interesting, because it is close to human-human interaction. Normally, we are aware of where other persons look, but with an accuracy much lower than that of an eye tracker. When we say, “Please give me the green book” and look on a table, we get the green book from the table and not the green book from the shelves. We assume that the other person knows where we are looking, and it is only necessary to specify the object within that scope.
8.6.3 Comparison of Mouse and Gaze Pointing
A good way to develop a deeper understanding of gaze pointing is a comparison with other pointing techniques. Besides accuracy and speed, pointing devices differ in space requirements, provision of feedback, support for multiple pointers and the modality to invoke a click. Table 8.1 gives an overview on these properties.
Table 8.1 Properties of pointing devices
| Mouse | Trackball | Track point | Touchpad | Touch screen | Eye gaze | |
| Speed | fast | fast | medium | fast | fast | very fast |
| Accuracy | time | time | time | time | size of finger | size of fovea |
| Space demand | much | little | little | little | none | none |
| Feedback | yes | yes | yes | yes | no | no |
| Method | indirect | indirect | indirect | indirect | direct | direct |
| Multiple pointing | 2 hands | 2 hands | 2 hands | 10 fingers | 10 fingers | 1 pair of eyes |
| Intrinsic click | no | no | no | yes (no) | yes | No |
Fitt's law gives the relation of speed and accuracy for pointing devices; achieving a higher accuracy for a pointing operation demands more time. In the case of a touch screen or eye gaze, anatomic sizes limit the accuracy, and the question of how big the pointing targets should be is answered by the size of the finger or fovea, not by a speed-accuracy trade-off.
A mouse needs some space for its movements on the table. As sufficient space often is not available when sitting in a train or plane, mobile devices typically use a trackball, track point, or touchpad. A touch screen does not need additional space, but the precision of a finger is low because of the size of the fingertip, which hides the visual information. To achieve high precision in pointing on a touch screen, people use a pencil with a thin tip. The situation for gaze pointing regarding space demand and accuracy is similar to pointing with the finger on a touch screen. Eye gaze does not hide the visual information, but increasing the precision with a pencil is not an option.
The provision of feedback by a mouse pointer is mandatory for pointing devices which work indirectly. For direct pointing on a touch screen, feedback is not necessary. Gaze pointing is also a direct method and does not need feedback. The reason a feedback pointer for eye gaze is desirable is to make sure that the coordinates reported by the eye tracker are really at the gaze position. Section 8.6.5 discusses the feedback for gaze pointing and why introducing a gaze pointer can be counter-productive.
The use of multiple pointers is a topic of current research. There are many discussions on two-handed interaction and the use of all fingers for pointing. For the eyes, it is clear that both eyes move synchronously and we are not able to point with both eyes independently. Multiple gaze pointers only make sense for multiple people.
Many GUI operations use pointing in combination with a click on the mouse key, which means that there is a need of an extra modality. This is not the case for the touch screen, where the touch provides a position and a click event. The touchpad does not present the same possibility, as the indirect method does not allow touching a target directly. The touch happens before steering the feedback pointer to the target and, consequently, the touch event is not useful to trigger an action on the target. A touchpad can use increased pressure as a click event, but commercial devices with a touchpad normally provide an extra mouse key. From the traditional pointing devices, the touch screen is most similar to gaze pointing. The big difference is that a finger can be lifted to move to another location, while the gaze cannot do that. Consequently, the eye gaze cannot produce a click event like the finger.
8.6.4 Mouse and Gaze Coordination
Figures 8.10 and 8.11 show typical mouse and gaze movements for a click-the-target task. Interestingly, the gaze moves directly to the target and does not look to the position of the mouse pointer. Motion detection works well in the peripheral vision area, and there is no need to hit the mouse pointer by gaze.
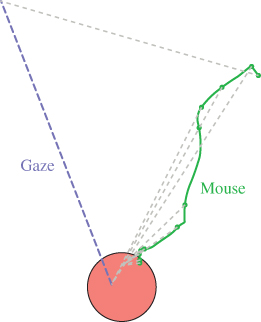
Figure 8.10 Gaze (dashed) and mouse movement (solid) for the classic mouse task without background. The dotted grey lines connect points of same time.
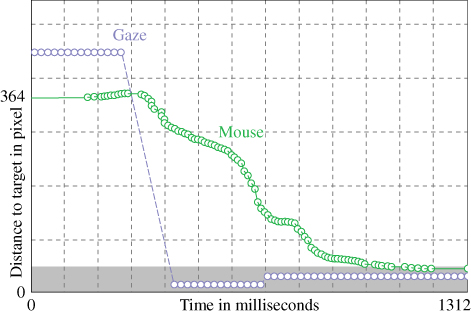
Figure 8.11 Gaze (dashed) and mouse movement (solid) for the classic mouse task without background as a plot of distance to target over time.
Gaze pointing does not put an extra load on the eye muscles and does not cause more stress on the eyes than working with a traditional mouse. The simple reason for that is that we have problems hitting a target without looking at it. Under special conditions, like big targets which we can see with peripheral vision, it is possible to follow the motion of the mouse cursor and steer it to the target only with motion vision, but without the gaze hitting the target.
The fact that the mouse pointer moves directly towards the target means that the user was aware of the mouse pointer position before starting the movements. Conducting the click-the-target task on a complex background destroys the possibility of pre-attentive perception, and the user is not aware of the mouse pointer position. Typically, people start to stir the mouse to detect the mouse pointer by its motion. Figures 8.12 and 8.13 show the situation.
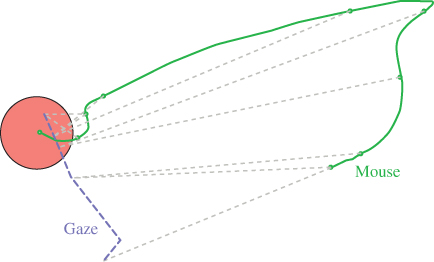
Figure 8.12 Gaze (dashed) and mouse trail (solid) for the classic mouse task with background. In the beginning, the user stirs the mouse to detect its position by movement.
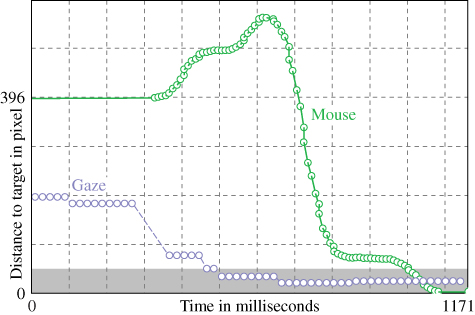
Figure 8.13 Gaze (dashed) and mouse trail (solid) for the classic mouse task on a complex background as a plot of distance to target over time.
Figures 8.11 and 8.13 show that eye and hand have about the same reaction time, but the gaze arrives at the target much earlier. Therefore, gaze pointing is definitely faster than mouse pointing. With mouse pointing, it can happen that we are not aware of where the mouse pointer is and have to find it first, something that never happens for the gaze. Pointing with the eye and pressing a gaze key is the fastest pointing interaction known, and typically needs about 600 milliseconds, 300 milliseconds reaction time, 100 milliseconds to move the gaze to the target and 200 millisecond to press down the key.
8.6.5 Gaze Pointing Feedback
An interesting question connected with gaze pointing is the provision of feedback. Of course, the user knows where she or he is looking, but not with one-pixel accuracy and, additionally, there may be calibration errors, causing the gaze position to differ from the position reported by the eye tracker. Providing a gaze feedback cursor could result in chasing the cursor across the screen – or, as Jacobs expressed it:
“If there is any systematic calibration error, the cursor will be slightly offset from where the user is actually looking, causing the user's eye to be drawn to the cursor, which will further displace the cursor, creating a positive feedback loop.” [23]
However, such chasing of a gaze feedback cursor typically does not occur. It seems that the eyes do not care whether the cursor is exactly in the center of the area of clear vision and, therefore, the eyes are not drawn to the cursor. A further reason for the absence of the phenomenon lies in the eye tracker's filter algorithms. Raw gaze data are normally very noisy and, therefore, the gaze data delivered to the application are smoothed. In many cases, there is a saccade (and fixation) detection done on the raw data, and the gaze aware application only gets notified about saccades. In these situations, a small change in the gaze direction does not change the reported coordinates and the feedback cursor does not move; the feedback cursor will move if the gaze position changes more than a threshold value.
Providing a feedback cursor on the basis of raw data produces a twitchy cursor, because the raw data typically contain noise created by the gaze detection. A feedback cursor with smoothed data is still twitchy and shows delay. Introducing a threshold for changes in the gaze position, which is a simple form of saccade detection, creates a stable but jumpy feedback cursor because the cursor moves at least the threshold distance. All cases are more disturbing than helpful, and therefore there should be no gaze cursor. This does not mean that no feedback is necessary. Typically, systems which use gaze pointing highlight the object where the gaze is focused. If the system uses the dwell time method, it is a good idea to provide feedback on the time elapsed. The question of whether, or what kind of, feedback a gaze-aware application should provide depends on the application, and has no general answer.
8.7 Gaze Gestures
8.7.1 The Concept of Gaze Gestures
Gestures are a possible way for computer interaction. With the introduction of smartphones which are controllable by gestures performed with the fingers on a touch-sensitive display, this interaction concept has suddenly become very popular. 3D scanners allow the detection of hand or body gestures and provide another form of gesture interaction, mostly used in the gaming domain.
Of course, the idea of gestures performed with the eyes is close to being achieved. We certainly use eye gestures in human-human interaction (e.g., we wink or roll the eyes). Such eye gestures include movements of the eyelid and the eyebrows, and are a part of facial expressions. The gestures presented here are restricted to the movement of the eyeball or gaze direction, respectively. This kind of gestures is detectable in the data delivered by an eye tracker.
In 2000, Isokoski suggested the use of off-screen targets for text input [38]. The eye gaze has to visit off-screen targets in a certain order to enter characters. Although Isokoski did not use the term “gesture”, the resulting eye movements are gaze gestures. However, off-screen targets force the gesture to be performed in a fixed location and in a fixed size. Such gestures still need a calibrated eye tracker.
Milekic used the term “gaze gesture” in 2003 [39]. Milekic outlined a conceptual framework for the development of a gaze-based interface for use in a museum context but, being from a Department of Art Education and Art Therapy, his approach is not strictly scientific – there is no algorithm given, and no user study was done.
In contrast to the gaze gestures of Isokoski, the gaze gestures presented by Wobbrock et al. [40] and Drewes and Schmidt [41] are scalable and can be performed in any location. The big advantage of such gestures is that they work even without eye tracker calibration.
8.7.2 Gesture Detection Algorithm
The popular mouse gesture plug-in for web browsers provided the inspiration for gaze gestures. This gesture plug-in traces the mouse movements and translates the movements into a string of characters or tokens representing strokes in eight directions. The eight directions are U, R, D, and L for up, right, down and left respectively, and 1, 3, 7, and 9 for the diagonal directions, according to the standard layout of the number pad on the keyboard. The mouse gesture detection algorithm receives ![]() and
and ![]() coordinates. Whenever one or both coordinates exceed a threshold distance (or grid size) from the start position, the algorithm outputs a character for the direction of the movement, but only when it is a character different from the last character. The current coordinates become the new start position, and the detection of a new stroke starts. The result is a translation of a stream of coordinates into a stream of characters (see Figure 8.14). A string of characters describes a gesture, and the algorithm signals the occurrence of a gesture when it finds the gesture string in the stream of characters.
coordinates. Whenever one or both coordinates exceed a threshold distance (or grid size) from the start position, the algorithm outputs a character for the direction of the movement, but only when it is a character different from the last character. The current coordinates become the new start position, and the detection of a new stroke starts. The result is a translation of a stream of coordinates into a stream of characters (see Figure 8.14). A string of characters describes a gesture, and the algorithm signals the occurrence of a gesture when it finds the gesture string in the stream of characters.
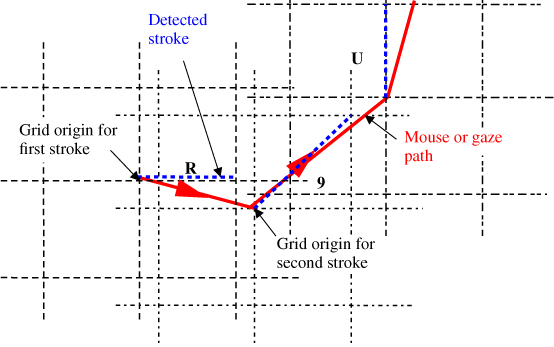
Figure 8.14 The figure shows how a mouse or gaze path translates into the string R9U. The end of a detected stroke is the origin for the grid to detect the next stroke.
The mouse gesture algorithm also works for gaze gestures. Interestingly, the gesture detection is better suited for gaze than to mouse movements. First, the natural motor space for hand movements is curved, while the saccadic movements of the eyes are straight lines. Second, the mouse trail is a continuous series of coordinates, and it is very unlikely that both coordinates cross the threshold in the same moment, which means diagonal strokes are difficult to detect. For detection of diagonal movements, it is good to have only the start- and end-points of a movement. Saccade detection on gaze movements delivers exactly this.
8.7.3 Human Ability to Perform Gaze Gestures
The most important question for gaze gestures as an active interaction method is whether people are able to perform them. Gaze gestures are definitely not very intuitive. Not all persons who try to perform a gaze gesture are successful immediately. Telling someone to move their gaze along a line confuses most subjects, while asking them to visit points with their gaze in a certain order brings better results. Therefore, it is a good idea to provide some supporting points (and not lines) for the users. The four corners of a display are good points for the gaze to perform a gaze gesture. Alternatively, the corners of a dialog window also work well.
The time to perform a gesture consists of the time for the strokes and the time for the stops, which are called fixation. Figure 8.4 shows saccade times over angle, which can be converted to the time for a stroke of certain length. From Figure 8.4, we learn that long saccades last around 100–150 milliseconds, and that there is only a little dependency on the length of a saccade. Therefore, the time to perform a gaze gesture does not depend very much on the size of the gesture, unless the gesture is very small in size. If ![]() is the number of strokes,
is the number of strokes, ![]() the time for a saccade, and
the time for a saccade, and ![]() the time for a fixation, the total time for a gesture
the time for a fixation, the total time for a gesture ![]() is:
is:
Theoretically, the fixation time could be zero and the minimum time to perform a gesture could be 120 milliseconds times the number of strokes in the gesture. Practically, untrained users in particular need some hundred milliseconds for the fixation.
8.7.4 Gaze Gesture Alphabets
The four corners of the display match perfectly with squared gestures, also called EdgeWrite gestures [42]. The EdgeWrite gestures use the order in which four points – the corners of a square – are reached (see Figure 8.15).

Figure 8.15 The four corners and the six connecting lines used for the EdgeWrite gestures and examples for EdgeWrite gestures (digits 0, 1, 2 and 3).
It is easy to describe all possible squared gestures with the notation introduced for gesture detection. The token string LD9DL, for example, represents the zero gesture in Figure 8.15. The token string URUR, on the other hand, is not a squared gesture and, therefore, the squared gestures are only a subset of the mouse gestures. Nevertheless, the squared gestures have the capability to define a large alphabet as shown by Wobbrock et al. [42], who assigned at least one gesture to each of the letters and digits in the Latin alphabet. The squared gestures seem to provide a suitable alphabet to start with. Figure 8.16 shows three examples of squared closed gaze gestures with four and six strokes.
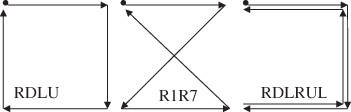
Figure 8.16 Three examples of squared closed gaze gestures with four and six strokes.
The EdgeWrite alphabet uses gestures which resemble Latin characters and digits. This makes it relatively easy to memorize the gestures, but also suggests using the gestures for text entry. The choice of the alphabet depends on the application of gestures. As discussed later, text entry seems not to be the best application for gaze gestures. A general problem of the EdgeWrite alphabet for gaze gestures is detecting when a gesture starts and when it is finished. The EdgeWrite alphabet was invented for gesture entry with a stylus, and a gesture ends with lifting the stylus. In the case of gaze gestures, the Midas Touch problem occurs.
One possible application of gaze gestures could be remote control for a TV set. For such an application, there should be gaze gestures to switch channels up and down or to increase and decrease the volume. It is very likely that repetitions of the same gesture occur in this interaction (e.g., switching the channel up three times). In this situation, it is comfortable to use closed gestures where the end position of the gesture is also the starting point of the gesture. Otherwise, the gaze has to move from the end point of the gesture to the start point for the repetition, which means the entry of an extra stroke, which also creates the danger that the gesture detection recognizes another gesture.
8.7.5 Gesture Separation from Natural Eye Movement
The mouse gesture algorithm needs a gesture key, typically the right mouse key, to make the system detect gestures, otherwise the mouse movements for normal operations would conflict with gesture detection. Of course, it would be possible to use the same mechanism for gaze gestures, but it would make gaze gestures nearly useless. If a key has to be pressed while performing a gaze gesture invoking a command, a key could be pressed to trigger the action without the effort of a gaze gesture. Perhaps in very special situations (e.g., a mobile context with only a single key available), a gesture key makes sense but, in general, a gesture key destroys the benefits of gaze interaction. Therefore it is necessary to separate gaze gestures from natural eye movements. However, this seems not to be an easy task.
One possibility is to detect gestures only in a certain context. For example, if there is a gaze gesture to close a dialog box, gesture detection starts when the dialog appears and ends when the dialog closes. This means that gesture detection only takes place in the context of the open dialog, and typically only for a short period of time. The probability of an unintended gaze gesture from natural eye movements is small if the gesture detection is only active for a short time.
Another possibility to achieve a separation of intentional gaze gestures from natural eye movements lies in the selection of suitable gestures. The more strokes a gesture has, the less likely it is that it will occur in natural eye movements by chance. However, with an increasing number of strokes, the gesture takes more time to perform and is harder to memorize. An analysis of natural eye movements reveals that some gestures appear more frequently than other gestures. The eye movements of people sitting in front of a computer monitor contain many RLRLRL gestures which are generated by reading. The occurrence frequency of a gesture depends on the activity; many people generate many DUDUDU gestures when typing because they look down to the keyboard and back to the display.
Drewes et al. introduced a ninth token, the colon, to indicate a timeout condition. The idea behind a timeout is that a gesture should be performed within a short time. The detection algorithm does not report any token if the gaze stays within a grid cell. In this case, the modified algorithm produces a colon to separate the subsequent token from the previous. Drewes [43] tested gaze gesture recognition with gaze data of people surfing the internet and watching a video, varying the parameters for grid size and timeout. The solution of how to separate gaze gestures from natural eye movements turned out to be surprisingly simple. When using a big grid size close to the display's dimensions, nearly no gestures with four or more strokes occur. Long saccades across the screen seldom occur in natural eye movements, and four or more subsequent long saccades nearly never occur.
The timeout parameter is not critical in the value but crucial. With a big grid size, the gaze typically lingers for a long time inside a cell before moving into another cell. Without colons, it is possible that the algorithm detects a gesture performed over a long time, which is was not intended by the user. As long as the timeout interval is a bit smaller than the average stay of the gaze in a cell, the separation works. Further decreasing of the timeout does not improve the separation. Table 8.2 shows recorded eye movements translated into gesture strings using different values for the parameters.
Table 8.2 Translating the same eye movements (surfing the internet) into a gesture string using different values for the grid size ![]() and timeout
and timeout ![]()
| Parameters | Resulting Gesture String |
| s = 80 t = 1000 |
:3LUD::7R1L9:73LR:73LR:7379RL:U:D:U3:LU::RL::R13U::LR:R:73:73D:73:LRLRLR7373DU7LD:RUL13L:R:RL:RL:LRL:R7L3L9R1UR3DR::7:URLRLRLRDLR7U:R3RL:LR |
| s = 80 t = 700 |
:3LU:D::7R:1L9:7:3LR::73L:R::737:9:RL:U:D:U3:LU::RL::R13U::LR:R:73:73D:73:LR:LRLR7373DU7LD:RUL1:3L:R:RL:RL:LRL::R:7L:3:L9R:1UR3DR::7:URLRL:RLRDLR7U |
| s = 250 t = 1000 |
:3L:::7R:1U:U3::7RL:UDU:L::::::::RD:R::::73::73::::L::L:::R::L:R:L:::R7:R:RL:DR:L:::::U:R:R::LR:L:RL:UD:R:::L::LR:L:3:L:::::::D:RL:RLRL::DRL::RLRLRLRLR:LRLRL:RLR:7::: |
| s = 250 t = 700 |
:3L::::7R:1:U:U:3:::7RL:::UDU::L::::::::RD::R::::::73::73:::::L:::L:::::R::L:R::L::::R7::R::R:L:D:R:L::::::::U:R:R:::LR:::L::RL::UD:R:::::L::LR:L::3::L:::::::::D::RL::RL:RL:::D:RL::RL:RL |
| s = 400 t = 1000 |
:3:::L:D::U3:::::U::L:::::::RD:::::73::73::::::L::::RL::::::U::RL:R:::::::7:R::::::L:R:7:R::L::LR:::::L::R:::::RL::::::::::::::::::::::::::::::::::::::::R::L:RL::::::RL:R::L:::RL:RL:RL::RL:RL:R::L:::RL: |
8.7.6 Applications for Gaze Gestures
Text entry by gaze gestures is possible, but it is questionable whether it makes sense. The time to enter a character by a gaze gesture takes one to two seconds per character for an inexperienced user. Even a well-trained user may have problems to beat the standard eye-typing with dwell time, which typically needs 5000 milliseconds per character. Additionally, performing gaze gestures is less intuitive than looking at a key, so there is no reason to assume that users will prefer the gaze gesture input method.
One of the big advantages of gaze gestures is that they work without calibration. Therefore, an obvious idea is the use a gaze gesture to invoke the calibration procedure on systems for the disabled.
Gaze gestures provide an interface for instant use by different people, because of the absence of a calibration procedure. Additionally, gaze gestures work without touching anything and therefore could be used in highly hygienic environments, such as surgery rooms or labs. Gaze gestures provide more complex control than eye contact sensors or other touch-free techniques, such as capacity sensors or photoelectric barriers.
The question of whether gaze gestures could serve as a remote control for the TV set and become an input technology for the masses, and not only for special purposes, is interesting and still open. The big advantage of remote control by gaze gestures is the absence of a control device – nothing to mislay and no batteries to recharge. However, some TV manufacturers now sell TV sets which can be controlled by gestures performed with the hands. Hand gestures are more intuitive and bring the same benefit for the user.
Another field of applications for gaze gestures is mobile computing. In the mobile context, it is desirable to have the hands free for other tasks. Gaze interfaces can facilitate this. Gaze pointing requires objects to look at on the display and, therefore, portions of an augmented reality display would be needed for this purpose. However, such interaction objects obscure parts of the vision. Gaze gestures do not need any interaction objects and save space on the display. In the context of an augmented reality display with a graphical user interface, it is imaginable to close a dialog window by looking clockwise at the corners of this window. A RDLU gesture would close the dialog in the same way as clicking the OK button with the mouse. Looking at the corners counterclockwise could close the dialog with a NO and, if needed, a crosswise gesture like 3U1U could have the meaning of a cancel operation.
Bulling et al. showed that gaze gestures work for mobile applications [13]. They used eye tracking by electro-occulography for their research, and this shows that the concept of gaze gestures does not depend on the eye-tracking technology used.
8.8 Gaze as Context
Instead of using the gaze as an active input from the user who intentionally invokes commands, it is also possible to treat gaze data as context information or to utilize the user's eye gaze for implicit human computer interaction. The computer uses the information from the eye tracker to analyze the situation and activity of the user, and adapts its behavior according to the user's current state. The idea to take the situation of the user into account dates back to 1997 [44]. Since that time, consideration of the user's environment and situation has been a topic of HCI research called “context awareness”.
8.8.1 Activity Recognition
A very important context for computer interaction is the current activity of the user. Therefore, it is an interesting question whether it is possible to estimate the user's activity, based on her or his eye movements.
Tables 8.3 and 8.4 show gaze statistics from people watching a video and surfing the internet, such as the average number of saccades performed per second, the average saccade time and length and the average fixation time.
Table 8.3 Mean values of gaze activity parameters for all participants (watching video)
| Video | Sac./sec | Pixel/Sac. | Av. Sac. Time | Av. Fix. Time | Total Time |
| unit | 1/sec | pixels | ms | ms | sec |
| P1 | 3.68 | 101.9 | 67.8 | 204.0 | 216.9 |
| P2 | 3.43 | 87.2 | 69.3 | 221.9 | 219.2 |
| P3 | 3.45 | 94.1 | 71.7 | 213.9 | 231.3 |
| P4 | 2.74 | 107.5 | 76.3 | 282.0 | 228.3 |
| P5 | 3.24 | 131.2 | 73.5 | 225.6 | 216.6 |
| P6 | 2.79 | 134.1 | 99.1 | 259.3 | 225.1 |
| P7 | 3.49 | 102.0 | 73.9 | 212.5 | 217.4 |
| P8 | 2.76 | 111.3 | 91.1 | 270.6 | 219.9 |
| Mean | 3.20 | 108.7 | 77.8 | 236.2 | 221.8 |
| Std. dev. | 0.38 | 16.6 | 11.2 | 29.8 | |
| Std. dev./ mean | 11.8% | 15.3% | 14.4% | 12.6% |
Table 8.4 Mean values of gaze activity parameters for all participants (surfing the internet)
| Internet | Sac./sec | Pixel/Sac. | Av. Sac. Time | Av. Fix. Time | Total Time |
| unit | 1/sec | Pixel | ms | ms | sec |
| P1 | 5.36 | 73.0 | 44.9 | 141.5 | 234.0 |
| P2 | 5.10 | 73.2 | 43.9 | 137.2 | 229.4 |
| P3 | 4.54 | 109.4 | 70.3 | 150.0 | 228.9 |
| P4 | 5.51 | 69.0 | 41.5 | 140.0 | 229.8 |
| P5 | 4.58 | 105.9 | 70.2 | 145.6 | 291.1 |
| P6 | 4.59 | 106.7 | 54.7 | 156.0 | 264.0 |
| P7 | 4.78 | 108.0 | 66.0 | 143.3 | 238.2 |
| P8 | 3.17 | 123.3 | 104.5 | 177.1 | 374.7 |
| Mean | 4.70 | 96.1 | 62.0 | 148.8 | 261.3 |
| Std. dev. | 0.72 | 20.9 | 20.9 | 12.9 | |
| Std. dev./ mean | 15.4% | 21.8% | 33.7% | 8.6% |
It is in the nature of statistics that measured values differ and, therefore, we have to answer the question whether different mean values in both tables are by chance or differ significantly. A standard method to answer this question is a t-test. The t-test offers the probability that the difference in the mean value are by chance. Table 8.5 shows the values for a paired student's t-test comparing both tasks. The values that differ significantly are the saccades per second and the average fixation time.
Table 8.5 t-test for “watching video” versus “surfing the internet”
| Sac./sec | Pixel/Sac. | Av. Sac. Time | Av. Fix. Time | |
| t-test | 0.00040 | 0.13136 | 0.05318 | 0.00003 |
The results of the statistics are good news for attempts to use eye-gaze activity for context awareness. The strong significance proves that a gaze-aware system can guess the user's activity quite well. The low individual differences in the gaze activity parameters justify the hope that such activity recognition will work with universal threshold values and does not need an adaptation for individual users.
At first it seems to be a little bit paradoxical that people perform fewer eye movements when watching a video full of action than surfing on static pages in the internet. The reason for that lies in the process of reading, which consists of saccades with short fixations in between. When reading, the eye moves as fast as possible but, when watching a movie, the eye waits for something to happen.
Most activities of humans involve eye movements related to the activity. Land [45] describes eye movements for daily life activities such as reading, typing, looking at pictures, drawing, driving, playing table tennis, and making tea. Retrieving context information means to go the other way round and conclude from eye movements to the activity. Using such an approach, Iqbal and Bailey measured eye-gaze patterns to identify user tasks [46]. Their aim was to develop an attention manager to mitigate disruptive effects in the user's task sequence by identifying the mental workload. The research showed that each task – reading, searching, object manipulation, and mathematical reasoning – has a unique signature of eye movement.
The approach to activity recognition with mean values is simple and more sophisticated math, which is beyond the scope of this text, can retrieve more information from gaze data. Bulling et al. described a recognition methodology that combines minimum redundancy maximum relevance (mRMR) feature selection with a support vector machine (SVM) classifier [47]. They tested their system with six different activities: copying a text, reading a printed paper, taking handwritten notes, watching a video, browsing the web, and no specific activity. They reported a detection precision of around 70%.
The approach of activity recognition is interesting, but the general problem is that the analysis of the eye movements can tell what the user's task was in the past, but not predict what the user is going to do. The period providing the data needed for the analysis causes latency. It is also not clear how reliable the task identification works and, finally, there is no concept for the social intelligence needed to make the right decisions.
8.8.2 Reading Detection
Reading is a very special activity which we do frequently, especially in the context of interacting with computer devices. Eye movements while reading were already a topic of research in the 19th century. Javal (1879) and Lamare (1892) observed the eye movements during reading and introduced the French originated word saccade for the abrupt movements of the eye. Psychologists intensively researched the reading process, which is understood in detail [48].
In many situations, especially when surfing the internet, people tend to read not very carefully and often do not read the text completely. Jakob Nielsen did a big survey with several hundred participants on reading behavior when looking at web pages. He visualized the eye gaze activity with heatmaps and found out that most heatmaps have an F-shape. This means that users tend to read only the first lines. As a consequence, web pages should state important things in the first lines.
Gaze analysis for reading is inspiring when it comes to finding design rules for interaction. However, if done in real-time, it can bring further benefits to the user. For example, if the system knows that the user is reading, it can stop distracting animations on the display and postpone disturbing notifications. There are several suggestions of algorithms for reading detection in the literature [49–51].
Reading detection, in general, is not really difficult. A series of forward saccades and a subsequent backward saccade is a strong indicator for reading activity. The gesture recognition algorithm introduced in the previous chapter outputs RLRLRL gestures when somebody is reading. The problems of reading detection are latency and reliability. The reading detector needs some saccades as input to know the user is reading, and therefore cannot detect that the user has just started reading. Therefore, reading detection has problems with detecting the reading of a short, single line of text. Reading detection can also signal reading activity although the user is doing something else, for example looking at people's heads on a group picture, which has a similar gaze pattern to reading.
Detecting reading as an activity is helpful, but it helps even more if the system also knows what was read. For this, it is worth to have a closer look at the gaze while reading. Figure 8.17 shows the gaze path while reading a text.

Figure 8.17 Gaze path reading a text.
It is easy to see that the gaze moves in saccades with brief fixations. Revisits can occur, especially in difficult texts. An analysis of the data give saccade lengths of around 1° within a line, and backward saccades which are slightly smaller than the length of the line. The angle of the forward saccades is about the same as the angle of the fovea, which makes sense as this means that the coverage of the line is optimal – no gaps and no overlaps. It is interesting to note that, in consequence, the first fixation points in a line are about half a degree behind the beginning of the line and the last fixation is the same distance away from the end of the line. In the vertical direction, the low accuracy causes the problem that it is not possible to detect reliably which line the gaze is reading if the line height is within a normal range. The line height in Figure 8.17 is about 0.5°.
In many professions, it is necessary to read many and long documents. A smart system could track how well documents were read and offer this information to the user. This raises the question of how to convert gaze activity into a number which tells how well a document was read.
One idea presented in [52] is to lay virtual cells over the text which cover the text completely. An algorithm can count the fixations in each cell. The total number of fixations on this document provides useful information, but it does not tell whether the document was read completely or whether one-third of the document was read three times. Therefore, a single number cannot provide a good indicator of how well a document was read. A second value is needed which indicates how the fixations are distributed over the text.
One possible definition for a second value is the variance of fixations in the cells. A low variance indicates that the fixations were equally distributed over the text. Another possibility would be the percentage of text cells hit by the gaze. This would be an easy understandable value which tells whether the document was read completely, but does not provide the information needed to tell whether the document was read several times.
The values for the quality of reading are helpful for queries finding unread documents. The document itself can provide feedback based on the gaze statistics. For example the document can display text which was already read on a different background color.
Reading detection is an example of eye-gaze context information which is not trivial, but also not too vague. When looking at the elaborate models on reading from the field of psychology [48], it becomes clear that there is further potential in reading detection. From the speed of reading, the number of backward saccades and the time needed to read difficult words, it should be possible to get information on the reading skills and formation of the reader. Just by displaying text in different languages or scripts, it is possible to find out which languages the user can read. An online bookshop could use such information for book recommendations in the future. There is definitely much space left for further research.
8.8.3 Attention Detection
The most obvious way to utilize the eye gaze as context information is the interpretation of the eye gaze as an indicator of attention. In most situations, we look at the object that we pay attention to. This may sound trivial, but attention is a very powerful context information which can provide real benefit for a user. A display of an electronic device, like a desktop computer or a mobile phone, provides information for the user. However, there is no need to display the information if the user does not look at it. Nowadays, systems which are normally not aware of the user's attention may display an important message while the user is not present and, when the user returns, the information may be overwritten by the next message. An attention-aware system, realized with an eye tracker, may give the user an overview on what has happened when the user's attention is back at the system.
Logging the user's attention also provides reliable statistics on how much time she or he spent on a particular document. The time the document was displayed is not reliable, as the user can open the document and leave the place to fetch a coffee. The statistics on how much time spent on which document can be very useful. In a working environment, where somebody works on several projects, it is necessary to calculate the costs of each project, which finally means to know how much time was spent on each project. Such statistics can also be useful for electronic learning.
8.8.4 Using Gaze Context
Eye gaze is very important for human communication. If we want good assistance from computers, the computers have to know where we are looking. However, the interpretation of gaze can be difficult, because even humans cannot always read wishes from the eyes of others. The correct interpretation of the way people look requires a kind of social intelligence, and it will not be easy to implement this on a computer.
In many cases, however, simple approaches can bring benefits to the users. A display could switch itself on if somebody is looking at it and switch off when nobody is looking any more. This would not only be convenient for the user, but could also save power, which is a limited resource for a mobile device. Another example is that messages displayed by the computer could disappear without a mouse click if the system recognizes that the message was read.
A further example is the Gazemark introduced by Kern et al. [54]. Gazemark is a substitute for the finger which we put at a location on a map or in a text, when we have to look somewhere else and intend to return our gaze to this location. Gazemark is a visual placeholder, highlighting the last position on the display where we looked at. Gazemark is helpful in situations with multiple monitor setups, or when we have to switch our attention between a display and a physical document. It may be even more helpful for user interfaces in cars, where our interaction with the navigation system can be interrupted by the traffic situation. Because the car moves, the content of the navigation system display may change during the interruption, and this means we need some time for a new orientation when looking at the display again. In this situation, the Gazemark has to move with the map and must not stay fixed on the display. As our attention should mainly focus on steering the car, it is a big advantage if we have a quicker orientation at the interface and shorten the time for interaction.
The examples above make clear that gaze interfaces may not only provide an alternative way of directing computers, but also have a big potential for new types of assistance systems.
8.9 Outlook
As mentioned in the introduction, interaction methods which use the eyes are desirable for many reasons. If we want to have computer devices with which we can interact in a similar way as we do with humans, especially for human-like robots, eye-tracking technology is even mandatory.
Looking at more than 20 years of eye-tracking research, it seems that the way how we expect to utilize the information which lies in our gaze changed over the years. While the early research mostly focused on operating graphical user interfaces with the eyes, the current focus seems to be gaze-aware applications.
Gaze pointing has some difficulties – the Midas Touch problem, the accuracy issue and the need for calibration. We do not need the speed benefit of eye interaction when working with a text processor or spreadsheet application, or operating an ATM. The few situations in which we appreciate speed are in playing shooter games or similar actions in a military context. Eye tracker hardware for the mass market will most probably arrive as an addition for a gaming console.
As soon as there are cheap eye trackers available, we can expect further applications beyond the gaming domain. However, it seems unlikely that we will operate graphical user interfaces mainly with the eye tracker as a full substitute for what we do with a mouse today. It seems more likely that the eye tracker will give us additional functions which make the system smarter. An eye tracker can assist us by positioning the mouse pointer on multi-monitor setups; it can track and record our eye activity and tell us which documents or which part of a document we already read and how intense; animated figures in a digital encyclopedia may pause while we read text.
Interaction with mobile devices has increased drastically in recent years. There are two options for eye-tracking with a mobile device. One option is an eye tracker which resides inside a mobile device. The challenges of such eye trackers are compensation for hand movements and changing light conditions. The other option is a head-mounted eye tracker. A head-mounted eye tracker seems to be easier to realize, but is definitely obtrusive. However, it makes sense in combination with an augmented reality display in the form of glasses.
The fundamental problem of possible conflicts between vision and interface operations is especially severe in the domain of mobile computing. There could also be conflicts with our social protocols, which demand that we direct our gaze to the person's face to whom we are talking. Mobile computing has strong needs for controlling the device without hands. Voice commands are an option, but social protocols do not allow using the voice in many situations. Gaze control does not need the hands and is silent. Perhaps gaze gestures are useful for switching modes of an augmented reality display, such as switching the display on or off.
The step before the introduction of eye trackers as an interface technology for the masses seems to be the introduction of attention sensors. Attention sensors do not report the gaze's direction, but only whether someone is looking. Attention sensors are easier to build and do not need calibration. Some mobile phone manufacturers already have gaze-aware devices in the market which switch off the display for power saving when nobody is looking. Gaze-awareness is already present.
References
- 1. Fitts, P.M. (1954). The Information Capacity of the Human Motor System in Controlling the Amplitude of Movement. Journal of Experimental Psychology 47, 381–391.
- 2. Ware, C., Mikaelian, H.H. (1987). An Evaluation of an Eye Tracker as a Device for Computer Input. Proceedings of the SIGCHI/GI Conference on Human Factors in Computing Systems and Graphics interface CHI '87, 183–188.
- 3. Miniotas, D. (2000). Application of Fitt's Law to Eye Gaze Interaction. CHI '00 Extended Abstracts on Human Factors in Computing Systems, 339–340.
- 4. Zhang, X., MacKenzie, I.S. (2007). Evaluating Eye Tracking with ISO 9241 – Part 9. Proceedings of HCI International 2007, 779–788.
- 5. Vertegaal, R.A. (2008). Fitt's Law comparison of eye tracking and manual input in the selection of visual targets. Conference on Multimodal interfaces IMCI '08, 241–248.
- 6. Carpenter, R.H.S. (1977). Movement of the Eyes. Pion, London.
- 7. Abrams, R., Meyer, D.E., Kornblum, S. (1989). Speed and accuracy of saccadic eye movements: characteristics of impulse variability in the occulomotor system. Journal of Experimental Psychology: Human perception and performance 15, 529–543.
- 8. Tian, Y., Kanade, T., Cohn, J.F. (2000). Dual-State Parametric Eye Tracking. Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition, 110–115.
- 9. Ravyse, I., Sahli, H., Reinders MJT, Cornelis J. (2000). Eye Activity Detection and Recognition Using Morphological Scale-Space Decomposition. Proceedings of the international Conference on Pattern Recognition ICPR. IEEE Computer Society, 1, 1080–1083.
- 10. von Romberg, G., Ohm, J. (1944). Ergebnisse der Spiegelnystagmographie. GräfesArch Ophtalm 146, 388–402.
- 11. Robinson, D.A. (1963). A method of measuring eye movement using a scleral search coil in a magnetic field. IEEE Trans Biomed Eng (BME) 10, 137–145.
- 12 Brown, M., Marmor, M., Zrenner, V., Brigell, E., Bach, M. (2006). ISCEV Standard for Clinical Electro-oculography (EOG). Documenta Ophthalmologica 2006 113(3), 205–212.
- 13. Bulling, A., Roggen, D., Tröster, G. (2008). It's in Your Eyes: Towards Context-Awareness and Mobile HCI Using Wearable EOG Goggles. Proceedings of the 10th international Conference on Ubiquitous Computing, UbiComp '08, 344, 84–93.
- 14. Vertegaal, R., Mamuji, A., Sohn, C., Cheng, D. (2005). Media Eyepliances: Using Eye Tracking for Remote Control Focus Selection of Appliances. CHI '05 Extended Abstracts on Human Factors in Computing Systems, 1861–1864.
- 15. Kim, K.-N., Ramakrishna, R.S. (1999). Vision-based Eye-gaze Tracking for Human Computer Interface. Proceedings of IEEE International Conference on Systems, Man and Cybernetics, 2, 324–329.
- 16. Dongheng, L., Winfield, D., Parkhurst, D.J. (2005). Starburst: A hybrid algorithm for video-based eye tracking combining feature-based and model-based approaches. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 3, 79.
- 17. Nguyen, K., Wagner, C., Koons, D., Flickner, M. (2002). Differences in the infrared bright pupil response of human eyes. Proc. Symposium on Eye Tracking Research & Applications (ETRA 2002), 133–138.
- 18. Ohno, T., Mukawa, N., Yoshikawa, A. (2002). FreeGaze: a gaze tracking system for everyday gaze interaction. Proceedings of the symposium on ETRA 2002: eye tracking research & applications symposium, 125–132.
- 19. Ohno, T., Mukawa, N. (2004). A Free-head, Simple Calibration, Gaze Tracking System That Enables Gaze-Based Interaction. Proceedings of the symposium on ETRA 2004: eye tracking research & application symposium, 115–122.
- 20. Hennessey, C., Noureddin, B., Lawrence, P. (2006). A single camera eye-gaze tracking system with free head motion. Proceedings of the 2006 symposium on Eye tracking research & applications, 87–94.
- 21. Zhai, S., Morimoto, C., Ihde, S. (1999). Manual And Gaze Input Cascaded (MAGIC) Pointing. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems CHI '99, 246–253.
- 22. Morimoto, C.H., Koons, D., Amir, A., Flickner, M. (1999). Frame-Rate Pupil Detector and Gaze Tracker. Proceedings of the IEEE ICCV'99 frame-rate workshop.
- 23. Jacob, R.J.K. (1990). What You Look At is What You Get: Eye Movement-Based Interaction Techniques. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems CHI '90, 11–18.
- 24. Majaranta, P., Räihä, K. (2002). Twenty Years of Eye Typing: Systems and Design Issues. Proceedings of the 2002 Symposium on Eye Tracking Research & Applications ETRA '02, 15–22.
- 25. Bolt, R.A. (1981). Gaze-orchestrated Dynamic Windows. Proceedings of the 8th Annual Conference on Computer Graphics and interactive Techniques, SIGGRAPH '81, 109–119.
- 26. Bolt, R.A. (1982). Eyes at the Interface. Proceedings ACM Human Factors in Computer Systems Conference, 360–362.
- 27. Card, S.K., Moran, T.P., Newell, A. (1983). The Psychology of Human-Computer Interaction. Lawrence Erlbaum.
- 28. Dickie, C., Vertegaal, R., Sohn, C., Cheng, D. (2005). eyeLook: using attention to facilitate mobile media consumption. Proceedings of the 2005 ACM Symposium on User Interface Software and Technology 2005, 103–106.
- 29. Drewes, H., Schmidt, A. (2009). The MAGIC Touch: Combining MAGIC-Pointing with a Touch-Sensitive Mouse. Proceedings of Human-Computer Interaction – INTERACT 2009, 415–428.
- 30. Salvucci, D.D., Anderson, J.R. (2000). Intelligent Gaze-Added Interfaces. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems CHI '00, 273–280.
- 31. McGuffin, M., Balakrishnan, R. (2002). Acquisition of Expanding Targets. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems CHI '02, 57–64.
- 32. Zhai, S., Conversy, S., Beaudouin-Lafon, M., Guiard, Y. (2003). Human On-line Response to Target Expansion. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI '03, 177–184.
- 33. Miniotas, D., Špakov, O., MacKenzie, I.S. (2004). Eye Gaze Interaction with Expanding Targets. CHI '04 Extended Abstracts on Human Factors in Computing Systems, 1255–1258.
- 34. Špakov, O., Miniotas, D. (2005). Gaze-Based Selection of Standard-Size Menu Items. Proceedings of the 7th international Conference on Multimodal interfaces, ICMI '05, 124–128.
- 35. Ashmore, M., Duchowski, A.T., Shoemaker, G. (2005). Efficient eye pointing with a fisheye lens. Proceedings of Graphics Interface 2005 (GI '05), 203–210.
- 36. Kumar, M., Paepcke, A., Winograd, T. (2007). EyePoint: Practical Pointing and Selection Using Gaze and Keyboard. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems CHI '07, 421–430.
- 37. Miniotas, D., Špakov, O., Tugoy, I., MackKenzie, I.S. (2005). Extending the limits for gaze pointing through the use of speech. Information Technology and Control 34, 225–230.
- 38 Isokoski, P. (2000). Text Input Methods for Eye Trackers Using Off-Screen Targets. Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, ETRA '00, 15–21.
- 39. Milekic, S. (2003). The More You Look the More You Get: Intention-based Interface using Gaze-tracking. In: Bearman D, Trant J. (eds.). Museums and the Web 2002: Selected Papers from an International Conference. Archives & Museum Informatics, Pittsburgh, PA.
- 40. Wobbrock, J.O., Rubinstein, J., Sawyer, M., Duchowski, A.T. (2007). Not Typing but Writing: Eye-based Text Entry Using Letter-like Gestures. Proceedings of COGAIN, 61–64.
- 41. Drewes, H., Schmidt, A. (2007). Interacting with the Computer using Gaze Gestures. Proceedings of Human-Computer Interaction – INTERACT 2007, 475–488.
- 42. Wobbrock, J.O., Myers, B.A., Kembel, J.A. (2003). EdgeWrite: A Stylus-Based Text Entry Method Designed for High Accuracy and Stability of Motion. Proceedings of the 16th Annual ACM Symposium on User interface Software and Technology, UIST '03, 61–70.
- 43. Drewes, H. (2010). Eye Gaze Tracking for Human Computer Interaction. Dissertation an der Ludwig-Maximilians-Universität München.
- 44. Hull, R., Neaves, P., Bedford-Roberts, J. (1997). Towards Situated Computing. Tech Reports: HPL-97-66, HP Labs Bristol.
- 45. Land, M.F. (2006). Eye movements and the control of actions in everyday life. Prog Retinal & Eye Res 25, 296–324.
- 46. Iqbal, B., Bailey, P. (2004). Using Eye Gaze Patterns to Identify User Tasks. Proceedings of The Grace Hopper Celebration of Women in Computing.
- 47. Bulling, A., Ward, J.A., Gellersen, H., Tröster, G. (2009). Eye movement analysis for activity recognition. Proceedings of the 11th international conference on Ubiquitous computing, 41–50.
- 48. Reichle, E.D., Pollatsek, A., Fisher, D.L., Rayner, K. (1998). Toward a Model of Eye Movement Control in Reading. Psychological Review 105, 125–157.
- 49. Campbell, C.S., Maglio, P.P. (2001). A Robust Algorithm for Reading Detection. Proceedings of the 2001 Workshop on Perceptive User interfaces, PUI '01, 15, 1–7.
- 50. Keat, F.-T., Ranganath, S., Venkatesh, Y.V. (2003). Eye Gaze Based Reading Detection. Conference on Convergent Technologies for Asia-Pacific Region, TENCON '03, 2, 825–828.
- 51. Bulling, A., Ward, J.A., Gellersen, H., Tröster, G. (2008). Robust Recognition of Reading Activity in Transit Using Wearable Electrooculography. Proc. of the 6th International Conference on Pervasive Computing (Pervasive 2008), 19–37.
- 52. Drewes, H., Atterer, R., Schmidt, A. (2007). Detailed Monitoring of User's Gaze and Interaction to Improve Future E-Learning. Proceedings of the 12th International Conference on Human-Computer Interaction HCII '07, 802–811.
- 53. Kern, D., Marshall, P., Schmidt, A. (2010). Gazemarks – Gaze-Based Visual Placeholders to Ease Attention Switching. Proceedings of the 28th ACM Conference on Human Factors in Computing Systems (CHI '10). ACM, Atlanta (GA), USA.
- 54. Wobbrock, J.O., Rubinstein, J., Sawyer, M.W., Duchowski, A.T. (2008). Longitudinal Evaluation of Discrete Consecutive Gaze Gestures for Text Entry. Proceedings of the 2008 Symposium on Eye Tracking Research & Applications, ETRA '08, 11–18.