
Chapter 9
Multimodal Input for Perceptual User Interfaces
Joseph J. LaViola Jr., Sarah Buchanan and Corey Pittman
University of Central Florida, Orlando, Florida
9.1 Introduction
Ever since Bolt's seminal paper, “Put that there: Voice and Gesture at the Graphics Interface”, the notion that multiple modes of input could be used to interact with computer applications has been an active area of human computer interaction research [1]. This combination of different forms of input (e.g., speech, gesture, touch, eye gaze) is known as multimodal interaction, and its goal is to support natural user experiences by providing the user with choices in how they can interact with a computer. These choices can help to simplify the interface, to provide more robust input when recognition technology is used, and to support more realistic interaction scenarios, because the interface can be more finely tuned to the human communication system. More formally, multimodal interfaces process two or more input modes in a coordinated manner which aim to recognize natural forms of human language and behavior and, typically, incorporate more than one recognition-based technology [2].
With the advent of more powerful perceptual computing technologies, multimodal interfaces that can passively sense what the user is doing are becoming more prominent. These interfaces, also called perceptual user interfaces [3], provide mechanisms that support unobtrusive interaction where sensors are placed in the physical environment and not on the user. Previous chapters in this book have focused on various input technologies and associated interaction modalities. In this chapter, we will examine how these different technologies and their input modalities – specifically speech, gesture, touch, eye gaze, facial expressions, and brain input – can be combined, and the types of interactions they afford. We will also examine the strategies for combining these input modes together, otherwise known as multimodal integration or fusion. Finally, we will examine some usability issues with multimodal interfaces and methods for handling them. Research in multimodal interfaces spans many fields, including psychology, cognitive science, software engineering, and human computer interaction [4]. Our focus in this chapter will be on the types of interfaces that have been created using multimodal input. More comprehensive surveys can be found in [5] and [6].
9.2 Multimodal Interaction Types
Multimodal interaction can be defined as the combination of multiple input modalities to provide the user with a richer set of interactions, compared to traditional unimodal interfaces. The combination of input modalities can be divided into six basic types: complementarity; redundancy; equivalence; specialization; concurrency; and transfer [7]. In this section, we briefly define each:
- Complementarity. Two or more input modalities complement each other when they combine to issue a single command. For example, to instantiate a virtual object, a user makes a pointing gesture and then speaks. Speech and gesture complement each other, since the gesture provides the information on where to place the object and the speech command provides the information on what type of object to place.
- Redundancy. Two or more input modalities are redundant when they simultaneously send information to the application. By having each modality issue the same command, redundant information can help resolve recognition errors and reinforce what operation the system needs to perform [8]. For example, a user issues a speech command to create a visualization tool, while also making a hand gesture which signifies the creation of that tool. When more than one input stream is provided, the system has a better chance of recognizing the user's intended action.
- Equivalence. Two or more input modalities are equivalent when the user has a choice of which modality to use. For example, the user can create a virtual object by either issuing a voice command or by picking the object from a virtual palette. The two modalities present equivalent interactions, in that the end result is the same. The user can choose which modality to use, based on preference (they simply like speech input over the virtual palette) or on circumvention (the speech recognition is not accurate enough, thus they move to the palette).
- Specialization. A particular modality is specialized when it is always used for a specific task because it is more appropriate and/or natural for that task. For example, a user wants to create and place an object in a virtual environment. For this particular task, it makes sense to have a “pointing” gesture determine the object's location, since the number of possible voice commands for placing the object is too large, and a voice command cannot achieve the specificity of the object placement task.
- Concurrency. Two or more input modalities are concurrent when they issue dissimilar commands that overlap in time. For example, a user is navigating by gesture through a virtual environment and, while doing so, uses voice commands to ask questions about objects in the environment. Concurrency enables the user to issue commands in parallel, reflecting such real-world tasks as talking on the phone while making dinner.
- Transfer. Two input modalities transfer information when one receives information from another and uses this information to complete a given task. One of the best examples of transfer in multimodal interaction is the push-to-talk interface [9]; the speech modality receives information from a hand gesture, telling it that speech should be activated.
9.3 Multimodal Interfaces
In this section, we examine how the different technologies and input modalities discussed in this book have been used as part of multimodal interaction systems. Note that, although speech input is a predominant modality in multimodal interfaces, we do not have a dedicated section for it in this chapter. Rather, uses of speech are found as part of each modality's subsection.
9.3.1 Touch Input
Multi-touch devices have become more prevalent in recent years with the growing popularity of multi-touch phones, tablets, laptops, table-top surfaces and displays. As a result, multitouch gestures are becoming part of users' everyday vocabulary, such as swipe to unlock or pinch to zoom. However, complex tasks, such as 3D modeling or image editing, can be difficult when using multi-touch input alone. Multimodal interaction techniques are being designed to incorporate multi-touch interfaces with other inputs, such as speech, to create more intuitive interactions for complex tasks.
9.3.1.1 3D Modeling and Design
Large multitouch displays and table-top surfaces are marketed as natural interfaces that foster collaboration. However, these products often target commercial customers in public settings, and are more of a novelty item. Thus, the question remains as to whether they provide utility as well as unique experiences. Since the mouse and keyboard are no longer available, speech can provide context to operations where WIMP paradigms were previously used, such as in complex engineering applications (e.g., Auto-CAD). For instance, MozArt [10] combines a tiltable multi-touch table with speech commands to provide an easier interface to create 3D models, as shown in Figure 9.1. A study was conducted, evaluating MozArt versus a multi-touch CAD program with novice users. The majority of users preferred the multimodal interface, although a larger number of users would need to be tested in order to evaluate efficiency and accuracy. Similar interfaces could be improved upon by using speech and touch, as stated in work on a multitouch-only interface for performing 3D CAD operations [11].

Figure 9.1 MozArt Table hardware prototype. Source: Sharma A, Madhvanath S, Shekhawat A and Billinghurst M 2011. Reproduced with permission.
9.3.1.2 Collaboration
Large multi-touch displays and tabletop surfaces are ideal for collaboration, since they have a 360-degree touch interface, a large display surface, and allow many input sources. For instance, Tse et al. (2008) [12] created a multimodal multi-touch system that lets users gesture and speak commands to control a design application called The Designer's Environment. The Designer's Environment is based on the KJ creativity method that industrial designers use for brainstorming. The four steps of the KJ creativity method are:
- create notes;
- group notes;
- label groups; and
- relate groups.
In The Designer's Environment, multiple users can complete these tasks by using a combination of touch, gesture, and speech input, as shown in Figure 9.3. However, there are some obstacles as explored by Tse et al. (2008) [12]: parallel work, mode switching, personal and group territories, and joint multimodal commands. Tse et al. proposed solutions to these issues, such as allowing for parallel work by creating personal work areas on the surface.
Tse et al. (2006) [13] also created the GSI Demo (Gesture and Speech Infrastructure created by Demonstration). This system demonstrates multimodal interaction by creating a multiuser speech and gesture input wrapper around existing mouse/keyboard applications. The GSI Demo can effectively convert a single-user desktop application to a multi-touch table application, such as maps, command and control simulations, simulation and training, and games. Tse et al. (2007) [14] specifically discuss how playing Blizzard's Warcraft III and The Sims can become a collaborative effort on a multi-touch tabletop system. Their proposed interface allows players to use gesture and speech input to create a new and engaging experience that is more similar to the social aspect provided by arcade gaming, shown in Figure 9.2.

Figure 9.2 Two people interacting with Warcraft III (left) and The Sims game (right). Source: Tse E, Greenberg S, Shen C, Forlines C and Kodama R 2008. Reproduced with permission.

Figure 9.3 A two person grouping hand gesture in the Designer's Environment. Source: Tse E, Greenberg S, Shen C and Forlines C 2007. Reproduced with permission.
Another interesting aspect of collaborative environments is how to track who did or said what during a collaborative effort. Collaboration data can then shed light on the learning or collaboration process. This type of data can also act as input to machine learning or data mining algorithms, providing adapted feedback or personalized content.
Collaid (Collaborative Learning Aid) is an environment that captures multimodal data about collaboration in a tabletop learning activity [15]. Data is collected using a microphone array and a depth sensor, integrated with other parts of the learning system, and finally transformed into visualizations showing the collaboration processes that occurred at the table. An example visualization of data collected from a collaborative group versus a less collaborative group is shown in Figure 9.4. Other work on multimodal collaboration using distributed whiteboards can be found in [16].
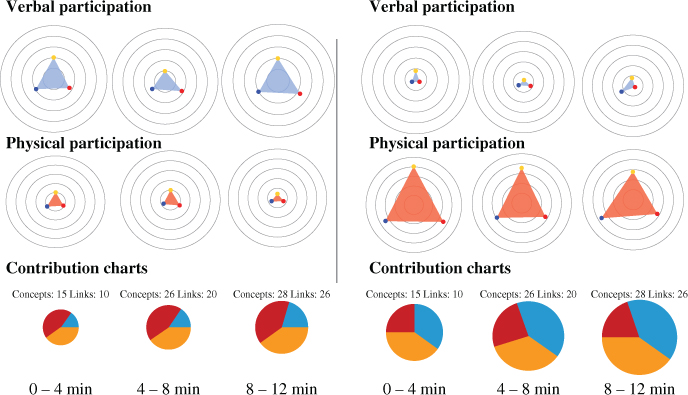
Figure 9.4 A collaborative visualization corresponding to 12 minutes of activity from a communicative group (left) and a less collaborative group (right). Source: Martínez-Maldonado R, Collins A, Kay J and Yacef K 2011. Reproduced with permission.
9.3.1.3 Communication with Disabled or Elderly Patients
Multimodal surface applications have also been shown to support medical communication with hearing impaired patients [17] and is being explored as way to enhance medical communication with the elderly by transcribing speech [18]. The Shared Speech Interface (SSI) is an application for an interactive multitouch tabletop display designed to facilitate medical communication between a deaf patient and a hearing, non-signing physician. The Deaf patient types on a keyboard, and the hearing doctor speaks into a headset microphone. As the two people communicate, their speech is transcribed and appears on the display in the form of movable speech bubbles, shown in Figure 9.5.

Figure 9.5 A doctor (left) and patient (right) communicate using the Shared Speech Interface (SSI). Meanwhile, movable speech bubbles appear on the multi-touch surface. Source: Piper AM 2010. Reproduced with permission from Anne-Marie Piper.
Multimodal surface technology can also benefit other populations with different communication needs. For example, a student learning a foreign language could access text-based representations of speech, along with audio clips of the instructor speaking the phrases.
9.3.1.4 Mobile Search
Mobile users are becoming more tech-savvy with their devices and expect to be able to use them while multitasking or on the go, such as when driving, or for quick access of information. In addition, contemporary mobile devices incorporate a wide range of input technologies, such as a multi-touch interface, microphone, camera, GPS, and accelerometer. Mobile applications need to leverage these alternate input modalities in a way that does not require users to stop what they are doing but, instead, provides fast, on-the-go input and output capabilities.
Mobile devices also face their own challenges, such as slower data transfer, smaller displays, smaller keyboards, and thus they have their own design implications, making desktop paradigms even less appropriate. Some believe that voice input is an easy solution to these problems. However, using voice input alone is not feasible, since voice recognition is error-prone, especially in noisy environments, and does not provide fine-grained control. Many multimodal mobile interfaces are emerging that use voice input combined with other interactions in a clever way. For example, voice input can be used to bring context to the desired operation, while leaving fine-grained manipulation to direct touch manipulation. Or, voice input can be used at the same time as text entry, to ensure that text is entered correctly.
Voice input is ideal for mobile search, since it is quick and convenient. However, since voice input is prone to errors, error correction should be quick and convenient as well. The Search Vox system uses multimodal error correction for mobile search [19]. After a query is spoken, the user is presented with an N-best list of recognition results for a given query. The N-best results comprise a word palette that allows the user to conveniently rearrange and construct new queries based on the results, by using touch input.
Another subset of mobile search, local search, is desirable in mobile contexts, allowing searches to be constrained to the current location. Speak4it is a mobile app that takes voice search a step further by allowing users to sketch with their finger the exact area they wish to search in [20]. Speak4it supports multimodal input by allowing users to speak or type search criteria and sketch the desired area with touch input. An example scenario of Speak4it would be a biker searching the closest repair shop along a trail, by using speech and gesture to get a more refined search. For instance, the query by voice, “bike repair shops in the Stuyvesant Town”, combined with a route drawn on the display, will return the results along the specified route traced on the display (Figure 9.6).
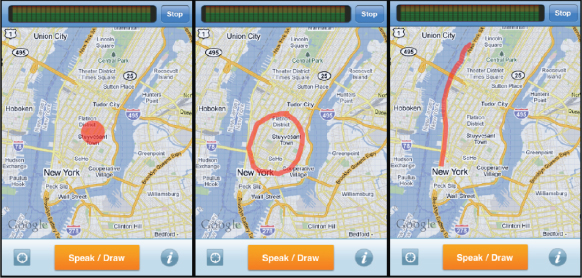
Figure 9.6 Speak4it gesture inputs.
Reproduced by permission of Patrick Ehlen.
Research prototypes with these capabilities have existed for many years, such as QuickSet [21]. However, they have not been available to everyday users until the widespread adoption of mobile devices that come equipped with touchscreen input, speech recognition, and mobile internet access. Other work that has explored multimodal interaction for mobile search is the Tilt and Go system by Ramsay et al. (2010) [22]. A detailed analysis of speech and multimodal interaction in mobile search is presented in Feng et al. (2011) [23].
9.3.1.5 Mobile Text Entry
Typing on a touchscreen display using a soft keyboard remains the most common, but time consuming, text input method for many users. Two resolutions for faster text entry are gesture keyboards and voice input. Gesture keyboards circumvent typing by allowing the user to swipe over the word path quickly on a familiar QWERTY keyboard; however, gestures can be ambiguous for prediction. Voice input offers an attractive alternative that completely eliminates the need for typing. However, voice input relies on automatic speech recognition technology, which has poor performance in noisy environments or for non-native users. Speak-As-You-Swipe (SAYS) [24] is a multimodal interface that integrates a gesture keyboard with speech recognition to improve the efficiency and accuracy of text entry, as shown in Figure 9.7. The swipe gesture and voice inputs provide complementary information for word prediction, allowing the SAYS system to extract useful cues intelligently from the ambient sound to improve the word prediction accuracy. In addition, SAYS builds on previous work [25] by enabling continuous and synchronous input.
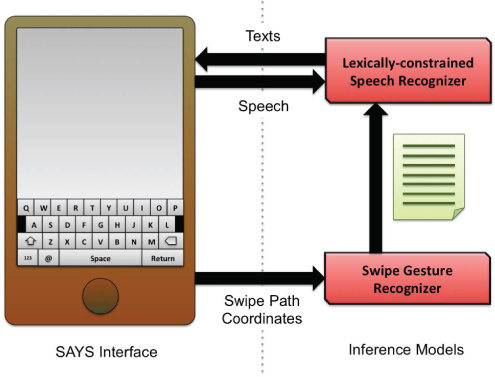
Figure 9.7 Speak As You Swipe (SAYS) interface. Source: Reproduced with permission of Khe Chai Sim.
A similar interface created by Shinoda et al. (2011) [26], allows semi-synchronous speech and pen input for mobile environments, as shown in Figure 9.8. There is an inherent time lag between speech and writing, making it difficult to apply conventional multimodal recognition algorithms. To handle this time-lag, they developed a multimodal recognition algorithm that used a segment-based unification scheme and a method of adapting to the time-lag characteristics of individual users. The interface also supports keyboard input and was tested in a variety of different manners:
- the user writes the initial character of each phrase in a saying;
- the user writes the initial stroke of the initial character as in (1);
- the user inputs a pen touch to cue the beginning of each phrase;
- the user taps the character table to which the first character of each phrase belongs to; and
- the user inputs the initial character of each phrase using a QWERTY keyboard.
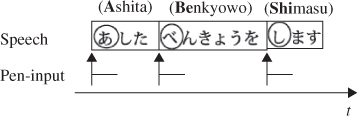
Figure 9.8 Relationship between speech and pen input. Source: Shinoda K, Watanabe Y, Iwata K, Liang Y, Nakagawa R and Furui S 2011. Reproduced with permission.
These five different pen-input interfaces were evaluated using noisy speech data, and the recognition accuracy of the system was higher than that of speech alone in all five interfaces. They also conducted a usability test for each interface, finding a trade-off between usability and improvement in recognition performance.
Other work that compares different multimodal interaction strategies using touch input for mobile text entry can be found in [27].
9.3.1.6 Mobile Image Editing
Another mobile app that incorporates multimodal inputs in novel way is PixelTone [28]. PixelTone is a multimodal photo editing interface that combines speech and direct manipulation to make photo editing easier for novices and when using mobile devices. It uses natural language for expressing desired changes to an image, and direct manipulation to localize these changes to specific regions, as shown in Figure 9.9. PixelTone does more than just provide a convenient interface for editing photos. The interface allows for ambiguous commands that a novice user would make such as “Make it look good”, as well as advanced commands such as “Sharpen the midtones at the top”. Although users performed the same using the multimodal interface versus just a touch interface, they preferred the multimodal interface overall and were able to use it effectively for a realistic workload.

Figure 9.9 PixelTone. Source: Laput GP, Dontcheva M, Wilensky G, Chang W, Agarwala A, Linder J and Adar E 2013. Reproduced with permission.
9.3.1.7 Automobile Control
Although a majority of US states ban text messaging for all drivers, there are still a variety of activities that drivers attempt to complete during their commute. Research is being conducted to help drivers be able to achieve the primary task of driving effectively, while still completing tertiary tasks such as navigating, communicating, adjusting music and controlling climate [29]. The Society of Automotive Engineers recommends that any tertiary task taking more than 15 seconds to carry out while stationary should be prohibited while the vehicle is in motion. Voice controls are exempt from the 15 second rule, since they do not require the user to take their eyes off the road, and they may appear to be an obvious solution.
However, some data suggests that certain kinds of voice interfaces impose high cognitive loads and can negatively affect driving performance. This negative affect is due to the technical limitations of the speech recognition, or to usability flaws such as confusing or inconsistent command sets and unnecessarily deep and complex dialog structures. Multimodal interfaces may be a way to address these problems, by combining the best modes of input depending on the driving situation.
Incorporating speech, touch, gesture, and haptic touchpad input have been explored separately as input to a driving interface. However, none of these inputs alone create an ideal solution. A multimodal interface created by Pfleging et al. (2012) [30], combines speech with gestures on the steering wheel to minimize driver distraction, shown in Figure 9.10. Pfleging et al. point out that speech input alone does not have fine-grained control, while touch input alone requires too much visual interaction, and gesture input alone does not scale well [31]. They propose a multimodal interaction style that combines speech and gesture, where voice commands select visible objects or functions (mirror, window, etc.) and simple touch gestures are used to control these functions. With this approach, recalling voice commands is simpler, as the users see what they need to say. By the use of a simple touch gesture, the interaction style lowers the visual demand and provides, at the same time, immediate feedback and easy means for undoing actions. Other work that looks at multimodal input for automobile control can be found in Gruenstein et al. (2009) [32].

Figure 9.10 Multimodal automobile interface combining speech with gestures on the steering wheel. Source: Pfleging B, Kienast M, Schmidt A and Doring T 2011. Reproduced with permission.
9.3.2 3D Gesture
Devices like Microsoft's Kinect and depth cameras driven by Intel's Perceptual Computing SDK, such as Creative's Senz3D camera, have steadily become more widespread and have provided for new interaction techniques based on 3D gestures. Using a combination of depth cameras and standard RGB cameras, these devices allow for accurate skeletal tracking and gesture detection. Such 3D gestures can be used to accomplish a number of tasks in a more natural way than WIMP interfaces. In order to enrich the user's experiences, the gestures can be combined with different modalities, such as speech and face tracking. Interestingly enough, the Kinect and Senz3D camera have built in microphones, making them ideal for designing multimodal interfaces.
Another common technique for gesture detection is to use stereo cameras to detect gestures, while using machine learning and filtering to properly classify them. Prior to the development of these technologies, the use of 3D gesture in multimodal interfaces was limited to detecting deictic gestures for selection or similar tasks using simple cameras. Speech is one of the more common modalities to be combined with gesture, as modern 3D gestures tend to involve a large portion of the body and limit what other modalities could realistically be used simultaneously [5].
Numerous applications of the Kinect sensor have been realized, with a number of games developed that have used both speech and gesture developed by Microsoft's first party developers. Outside of the game industry, sensors like the Kinect have been used for simulation and as a means to interface with technology using more natural movements. Some work has been done in the fields of human-robot interaction (HRI) and medicine for the utility of hands-free, gesture-controlled applications.
9.3.2.1 Games and Simulation
Interacting with a simulation using body gestures is commonly used in virtual environments when combined with speech to allow for simultaneous inputs. Williamson et al. (2011) [33] developed a system combining the Kinect, speech commands, and a Sony Playstation Move controller to make a full-body training simulation for soldiers (Figure 9.11). The RealEdge prototype allows users to march through an environment using a marching gesture, and to make small movements of their virtual avatar by leaning. The user can also look around the environment using the Move controller, which is attached to a weapon-like apparatus. The user may also use voice commands to give orders to virtual characters.

Figure 9.11 RealEdge prototype with Kinect and PS Move Controller. Source: Reproduced by permission of Brian Williamson.
One shortcoming of the depth camera-based gesture recognition devices currently available is that they generally require the user to be facing them to accurately track the skeleton of the user. The RealEdge Fusion System, an extension of the RealEdge prototype, allows for accurate 360 degree turning by adding multiple Kinects around the user and fusing retrieved skeletal information at the data level to allow for robust tracking of the user within the range of the sensors regardless of the users orientation [34]. The skeletal tracking information is passed from a Kinect depth sensor through a client laptop to a server, where the data is then fused. The system only requires the addition of more Kinect sensors, laptops, and a head mounted display to give the user the proper view of their environment.
A large amount of research has been done emphasizing the addition of speech to 3D interfaces for segmentation and selection. Budhiraja et al. specify that a problem with deictic gesture alone is that large numbers of densely packed or occluded objects make selection difficult [35]. In order to solve this problem, the authors add speech as a modality to help specify defining attributes of the desired object, such as spatial location, location relative to other objects, or physical properties of the object. This allows for specific descriptions, such as “the blue one to the left”, to be used to clarify what object the user aims to select. Physical attributes and locations must be clearly defined for proper identification.
There are instances where 3D gesture is not the primary method of control in an interface. The SpeeG input system is a gesture-based keyboard replacement that uses speech augmented with a 3D gesture interface [36]. The interface is based on the Dasher interface [37] with the addition of speech and hand gestures, which replace the mouse. The system uses intermediate speech recognition to allow the user to guide the software to the correct phrase using their hand.
Figure 9.12 shows an example of the virtual environment and the pointing gesture. Though the prototype did not allow for real-time input, due to problems with speech recognition latency, users found that SpeeG was “the most efficient interface” when compared to an onscreen keyboard controlled with a Microsoft Xbox 360 controller, speech control only, and Microsoft Kinect keyboard only.

Figure 9.12 SpeeG interface and example environment. Source: Reproduced by permission of Lode Hoste.
3D gestures are not limited to full body movements. Bohus and Horvitz (2009) [38] developed a system to detect head pose, facial gestures, and a limited amount of natural language in a conversational environment. Head position tracking and gaze estimation were done using a basic wide-angle camera and commercially available software. A linear microphone was used to determine the sources of user voices. These modalities were fused and analyzed, and a suitable response was given to the users.
This multiparty system was used for observational studies of dialogues, in which the system asks quiz questions and waits for responses from the users. Upon receiving a response from the user, the system will vocally ask for confirmation from the users. Depending on their responses, the system will respond appropriately and either continue on, or ask for another answer. The system's behavior is based on a turn-taking conversational model, for which the system has four behaviors: Hold, Release, Take, and Null. An example of this system functioning can be seen in Figure 9.13.

Figure 9.13 Example of system for turn-taking model for multiparty dialogues. Source: Reproduced with permission from Microsoft Corporation.
Hrúz et al. (2011) [39] designed a system for multimodal gesture and speech recognition for communication between two disabled users – one hearing impaired and one vision impaired. The system recognizes signed language from one of the users, using a pre-trained sign recognizer. The recognizer uses a single camera for capture of the hand signs, so the user must wear dark clothes to create contrast between the hands and the background and to allow for more accurate detection of the signs The signs are converted to text and then played for the other user using a language-specific text-to-speech system. The other user speaks to the system, which uses automatic speech recognition to translate the spoken words to text, and this is then displayed for the other user. Each one of the users represents a separate input modality for the system architecture, which is illustrated in Figure 9.14. The system allows for communication between two users who otherwise would be unable to find a medium to speak to one another.
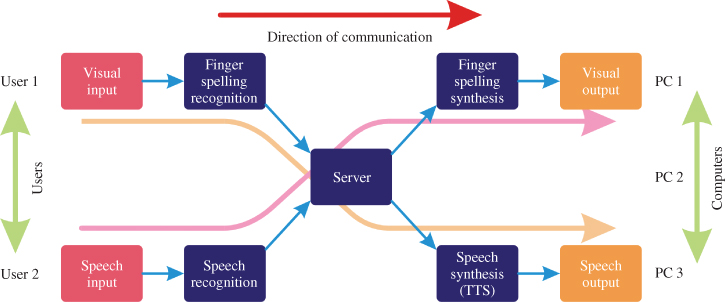
Figure 9.14 Flow of system for communication between two disabled users. Source: Reproduced with permission from Marek Hruz.
9.3.2.2 Medical Applications
Gallo et al. (2011) [40] developed a system for navigating medical imaging data using a Kinect. The user is able to traverse the data as though it were a virtual environment, using hand gestures for operations like zooming, translating, rotating, and pointing. The user is also able to select and extract regions of interest from the environment. The system supports a number of commonly used imaging techniques, including CT, MRI, and PET images.
The benefit of having a 3D gesture interface in medicine is that there is no contact with any devices, maintaining a sterile environment. This interface can therefore be used in surgical environments to reference images without having to repeat a sterilization process. The sterile environment problem arises often in computerized mechanical systems. Typically, there is an assistant in the operating room who controls the terminals that contain information about the surgical procedure and images of the patient. These assistants typically do not have the same level of training as the surgeon in charge, and may misinterpret information the surgeon could have correctly deciphered.
9.3.2.3 Human-Robot Interaction
Perzanowski et al. (2001) [41] designed a method of communicating with robots in a way that was already natural for humans – using natural language and gestures. A stereo camera attached to the robot watched the hands of the user and determined whether the gestures were meaningful. Combining these gestures with the voice input from the user, the robot would carry out the desired commands from the user. The speech commands could be as simple as “Go over there” or “Go this far”.
Along with the information the gesture gives, which could be something like a position in the environment from a pointing gesture or a distance from holding hands spread apart, the robot is able to make intelligent decisions on how far to move. The robot was also capable of being controlled using a PDA that mapped out the environment. The user could combine the PDA commands with speech commands or gesture commands or be used in place of speech and/or gesture. The tasks given to robots could be interrupted and the robot would eventually return to its original task to complete it. Similar interfaces that combine 3D gestures and speech for controlling robots include those described in [42] and [43].
9.3.2.4 Consumer Electronics
Multimodal input technologies have matured to the point where they are becoming interfaces to consumer electronics devices, particularly large screen displays and televisions. One commercial example is Samsung's Smart TV series, which includes 3D gestures, speech input, and facial recognition. In the research community, Lee et al. (2013) [44] combined 3D hand gestures and face recognition to interact with Smart TVs. Facial recognition was used as a viewer authentication system and the 3D hand gestures are used to control volume and change channels. Takahashi et al. (2013) [45] also explored 3D hand gestures coupled with face tracking using a ToF depth camera to assist users in TV viewing.
Krahnstoever et al. (2002) [46] constructed a similar system for large screen displays that combined 3D hand gestures, head tracking, speech input, and facial recognition. This system was deployed in a shopping mall to assist shoppers in finding appropriate stores. As the technology continues to improve and becomes smaller and less expensive, these types of multimodal interfaces will be integrated into more consumer electronic devices, such as PCs and laptops, as their main user interface.
9.3.3 Eye Tracking and Gaze
The ability to track a user's eyes in order to know their gaze location has been an important area of research over the last several years [47], as there are a variety of commercial eye tracking and gaze determination devices used in many different applications, from video games to advertising analysis. One of the more common uses of eye gaze in a multimodal input system has been for object selection by either coupling eye gaze with keyboard button presses [48, 49] or using eye gaze as a coarse selection technique, coupled with a mouse for finer pointing [50, 51].
Eye gaze in multimodal interfaces include integration with hand gestures for multi-display environments with large area screens [52]. Coupling eye gaze with a variety of different modalities including a mouse scroll wheel, tilting a handheld device, and touch input on a smart phone have also be used for pan and zoom operations for large information spaces [53]. Text entry has been explored using eye gaze by combining it with speech input [54]. In this interface, users would focus on a character of interest and issue a voice command to type the character in a document, although in usability testing, a traditional keyboard was found to be faster and more accurate. Multimodal interfaces making use of eye gaze have also be developed in the entertainment domain. For example, Heo et al. (2010) [55] developed a video game (see Figure 9.15) that combined eye gaze, hand gestures, and bio-signal analysis and showed the multimodal interface was more compelling than traditional keyboard and mouse controls.

Figure 9.15 A video game that combines eye gaze, hand gestures, and bio-feedback.
Reproduced by permission of Hwan Heo.
Finally, eye gaze has recently been explored in combination with brain-computer input (BCI) to support disabled users [56, 57]. In this interface, eye gaze was used to point to objects with the BCI component used to simulate dwell time for selection. Integrating eye gaze with BCI for multimodal interaction makes intuitive sense, given that movement is often limited when using BCI (see Section 9.3.5).
9.3.4 Facial Expressions
Recognizing facial expressions is a challenging and still open research problem that can be an important component of perceptual computing applications. There has been a significant amount of research on facial expression recognition in the computer vision community [58]. In terms of multimodal interaction, facial expressions are commonly used in two ways.
In the first way, other modalities are integrated with facial expression recognizers to better improve facial expression recognition accuracy, which ultimately supports human emotion recognition. For example, De Silva et al. (1997) [59] combined both video and audio information to determine what emotions are better detected with one type of information or another. They found that anger, happiness, surprise and dislike were better recognized by humans with visual information, while sadness and fear tended to be easier to recognize using audio.
Busso et al. (2004) [60] found similar results by integrating speech and facial expressions together in a emotion recognition detection system. Kessous et al. (2010) [61] used facial expressions and speech, as well as body gestures, to detect human emotions in a multimodal-based recognizer. Another example of an emotion detection system that couples facial expressions and speech input can be found in [62].
The second way that facial expression recognition has been used in the context of multimodal interfaces is to build affective computing systems which determine emotional state or mood in an attempt to adapt an application's interface, level of difficulty, and other parameters to improve user experience. For example, Lisetti and Nasoz (2002) [63] developed the MAUI system, a multimodal affective user interface that perceives a user's emotional state combining facial images, speech and biometric feedback.
In another example, Caridakis et al. (2010) [64] developed an affective state recognizer using both audio and visual cues using a recurrent neural network. They were able to achieve recognition rates as high as 98%, which shows promise for multimodal perceptual computing systems that can observe and understand the user not only when they are actively issuing commands, but when they are being passively monitored as well.
9.3.5 Brain-computer Input
Modern brain-computer interfaces (BCI) are capable of monitoring our mental state using nothing more than an electroencephalograph (EEG) connected to a computer. In order for signals to be tracked using today's technologies, a number of electrodes must be connected to the user's head in specific locations. These connections limit the possibilities for the addition of certain modalities to systems that the user can interact with. If the user moves while wearing a BCI, there is typically some noise in the signal, decreasing the accuracy of the signal. This is often not a large issue, as BCIs have typically been used to facilitate communication and movement from disabled individuals.
A number of companies, including Emotiv (Figure 9.16) and Neurosky, have begun developing low-cost BCIs for previously unconventional applications, one of which is video games. With the decrease in the cost of consumer BCIs, a number of multimodal applications using them have been proposed. Currently, the most commonly used modalities with BCIs are speech and eye gaze, as these do not require significant movement of the body. Gürkök and Nijholt (2012) [65] cite numerous examples of BCIs being used to improve user experience and task performance by using a brain-control interface as a modality within multimodal interfaces.

Figure 9.16 Emotiv EEG neuroheadset. Source: Corey Pittman.
Electroencephalography (EEG) is often combined with additional neuroimaging methods, such as electromyography (EMG), which measures muscle activity. Leeb et al. (2010) [66] showed significant improvement in recognition performance when EEG is used in conjunction with EMG when compared to either EEG or EMG alone. Bayesian fusion of the two signals was used to generate the combined signal. EEG, combined with NIRS (Near-infrared spectroscopy), has also been shown to significantly improve classification accuracy of signals [67]. NIRS creates a problem for real-time BCIs because of its significant latency.
Gürkök et al. (2011) [68] studied the effects of redundant modalities on a user's performance in a video game of their own design. The game, titled “Mind the Sheep!”, required the player to move a group of dogs around to herd sheep into a pen. The system setup is shown in Figure 9.17. The game used a mouse in conjunction with one or two other modalities. The participant controlled which dog was selected using either speech or a BCI. To select a dog with speech, participants needed only to say the name of the dog. To control the dog with the BCI, the participant was required to focus on the desired dog's location, and then release the mouse button on the location where the dog was to move. Participants were asked to play the game under multiple conditions: with automatic speech recognition (ASR); with BCI; and lastly with both in a multimodal configuration. The study found that being given the opportunity to select the current modality did not give a significant performance increase when compared to either of the single modality modes, with some participants not even changing modalities once.

Figure 9.17 “Mind the Sheep!” system interface. Source: Reproduced with permission from Hayrettin Gürkök.
One further application for BCIs is modeling interfaces. Sree et al. (2013) [69] designed a framework for using BCI as an additional modality to assist in 3D modeling. EEG and EMG are again combined, this time in conjunction with a keyboard and mouse to control the modeling operations, with the Emotiv EEG neuroheadset as the primary device. The software accompanying the Emotiv is used to set some parameters for the device's signals and to calibrate the device for each particular user. Facial movements are detected using the EMG component, with gestures like looking left, controlling drawing an arc or blinking to left click on the mouse. Mouse movement is controlled using the EEG component, which detects the intent of the user.
The Emotiv API allows for interpretation of twelve movements – six directional movements and six rotational movements – which can all be used in the CAD environment. Participant fatigue was a common problem with the system, along with some problems with EEG signal strength. Additional input modalities, such as speech, could be added to this system to allow for improved usability.
Zander et al. (2010b) [70] allowed users the freedom to control a BCI using either imagined movement, visual focus, or a combination of both. The authors proposed that since BCI does not always work for all users when there is only one method of control, providing alternatives or hybrid techniques allows for significant improvement in accuracy. Maye et al. (2011) [71] present a method for increasing the number of distinct stimuli (different tactile and visual stimuli) when using a BCI increases the number of the dimensions the user can control, while maintaining similar mental effort. Brain activity can be more easily classified by asking the user to shift focus between different stimuli. Zander et al. (2010b) [70] separate BCIs that are used in HCI into three categories: active, reactive, and passive.
9.4 Multimodal Integration Strategies
One of the most critical parts of a multimodal interface is the integration component, often called the fusion engine, that combines the various input modalities together to create a cohesive interface that supports meaningful commands [72]. There are many technical challenges with building a multimodal integration engine seems extraneous.
- First, the different input modalities may have very different characteristics, including data formats, frequencies, and semantic meaning, making it difficult to combine them together.
- Second, timing plays a significant role in integration since different modalities may come at different times during an interaction sequence, requiring the integration engine to be flexible in its ability to process the input streams.
- Third, and related to timing, resolving ambiguities is a significant challenge when the integration engine is under-constrained (the engine does not have enough information to make a fusion decision) or over-constrained (the engine has conflicting information and has more than one possible fusion decision to make).
- Finally, the input modalities used in multimodal interfaces often stem form natural communication channels (e.g., 3D gesture, speech, facial expressions) where recognition technologies are required to segment and classify the incoming data. Thus, levels of probabilistic uncertainty will exist with these modalities, making the integration engine's job more complex.
There are two basic approaches to performing multimodal integration in the fusion engine. The first is early integration and the second is late integration and, within these two approaches, there are several different integration strategies [73]. The premise behind early integration is that the data is first integrated before any major processing is done (aside for any low-level processing). In contrast to early integration, late integration processes the data from each mode separately and interprets it as if it is unimodal before integration occurs. The advantage of late integration is that, since the input modalities can be analyzed individually, time synchronization is not an issue and software development tends to be simpler.
However, late integration suffers from a potential loss of information, in that it can miss potential cross-modal interaction. For example, in early integration, the results from a gesture recognizer could be improved, based on the results from a speech recognizer or vice versa. However, with late integration, each individual recognizer must make a decision about its modality independently. The choice of whether to use early or late integration is still an open research question, and depends on the types of modalities used, as well as the multimodal interaction styles supported by an application. Note that, in some cases, a compromise between early and late integration can be used to perform the multimodal integration. For example, taking an early integration of 3D gestures and eye gaze with late integration with speech.
Within the context of early and late integration, there are three different integration levels for any incoming data stream [74]. Data-level and feature-level integration both fit into the early integration approach. Data-level integration focuses on low-level processing and is often used when the input modalities are similar, such as lip and facial expressions. This type of processing is also used when there is minimal integration required. Since it is closest to the raw data source, it can provide the highest level of detail, but is susceptible to noise.
Feature-level integration is used when the modalities are closely coupled or time-synchronized. Example modalities would be speech recognition from voice and lip movements, and example strategies include neural networks and hidden Markov models. Feature-level integration is also less sensitive to noise, but does not provide as much detail as low-level integration.
Decision-level integration (i.e., dialog level fusion [72]) is a late integration approach and is the most common type of multimodal integration. Its main strength is its ability to handle loosely coupled modalities (e.g., touch input and speech) but it relies on the accuracy of the processing already done on each individual modality.
Frame-based, unification-based, procedural, and symbolic/statistical integration are the most common integration strategies under decision-level integration.
9.4.1 Frame-based Integration
Frame-based integration focuses on data structures that support attribute-value pairs. Such frames collect these pairs from the various modalities to make an overall interpretation. For example, for speech input, an attribute-value pair could be “operation”, with possible values of “delete”, “add entry”, “modify entry”, etc. Each frame supports an individual input modality, and the integration occurs as the union of the sets of values in the individual frames. Scores are assigned to each attribute, and the overall score from the integration determines the best course of action to take. Koons et al. (1993) [75] were one of the first groups to explore feature-based integration that combined 3D gestures, eye gaze, and speech. More recently, Dumas et al. (2008) [76] developed the HephaisTK multimodal interface toolkit, which includes the frame-based approach to multimodal integration. Other multimodal interfaces that make use of frame-based integration using a variety of different input modalities include [77–79].
9.4.2 Unification-based Integration
The main idea behind unification-based integration is the use of the unification operator. Taken from natural language processing [80], it determines the consistency of two pieces of partial information, and if consistent, combines them into a single result [81]. For example, Cohen et al. (1997b) [82] was the first to use unification coupled with typed feature structures to integrate pen gesture and speech input in the QuickSet system. More recently, Taylor et al. (2012) [83] chose a unification integration scheme for combining speech and 3D pointing gestures and speech with touch gestures to support interaction with an unmanned robotic vehicle, while Sun et al. (2006) [84] also used unification, coupled with a multimodal grammar syntax in a traffic management tool that used 3D gestures and speech. Unification tends to work well when fusing only two modalities at any one time, and most unification-based integration research tends to focus on input pairs. Other examples of multimodal integration based on unification can be found in [85, 86].
9.4.3 Procedural Integration
Procedural integration techniques explicitly represent the multimodal state space through algorithmic management [72]. Common example representations using procedural integration include augmented transition networks and finite state machines. For example, both Neal et al. (1989) [87] and Latoschik (2002) [88] made use of augmented transition networks, and Johnston and Bangalore (2005) [89] and Bourguet (2002) [90] used finite state automata for procedural integration. Other approaches to procedural integration include Petri nets [91] as well as guided propagation networks [7]. In these systems, speech input was combined with either the mouse, keyboard, pen input, touch input, or 3D gestures.
9.4.4 Symbolic/Statistical Integration
Symbolic/statistical integration takes more traditional unification-based approaches and combines them with statistical processing to form hybrid multimodal integration strategies [92]. These strategies also bring in concepts from machine learning. Although machine learning has been primarily used with feature level integration, it also have been explored at the decision level [4]. As an example, Pan et al. (1999) [93] used Bayesian inference to derive a formula for estimating joint probabilities of multisensory signals that uses appropriate mapping functions to reflect signal dependencies. Mapping selection is guided by maximum mutual information.
Another early example of a symbolic/statistical integration technique is the Member Team Committee (MTC) architecture [94] used in the QuickSet application. In this approach, modalities are integrated on the basis of their posterior probabilities. Recognizers from individual modes become members of an MTC statistical integrator, and multiple teams are then trained to coordinate and weight the output from the different modes. Each team establishes a posterior estimate for a multimodal command, given the current input received. The committee of the MTC integrator analyzes the empirical distribution of the posteriors and then establishes an n-best ranking for each possible command. Flippo et al. (2003) [95] used a similar approach to MTC as part of a multimodal interaction framework, where they used parallel agents to estimate a posterior probability for each modal recognition result and then weighed them to come to an overall decision on the appropriate multimodal command.
More recently, Dumas et al. (2012) [96] developed a statistical multimodal integration scheme that uses hidden Markov models to select relevant modalities at the semantic level via temporal relationship properties. More information on using machine learning in multimodal integration can be found in [97, 98]. Although these methods can be very powerful at modeling the uncertainty in multimodal integration, their main drawback is the need for an adequate amount of training data.
9.5 Usability Issues with Multimodal Interaction
Given the very nature of multimodal interaction in the context of perceptual computing, usability becomes a critical part of multimodal interface design because of the attempt to couple different input modalities tightly together in a way that provides an intuitive and powerful user experience [99]. To discuss some of the usability issues with multimodal input, we use Oviatt's ten myths of multimodal interaction as starting points for discussion [100]. Although written several years ago, they are still applicable today.
If you build a multimodal system, users will interact multimodally. Just because an application supports multiple modes of input does not mean that users will make use of them for all commands. Thus, flexibility in the command structure is critical to support natural forms of communication between the human and the computer. In other words, multimodal interfaces should be designed with flexibility for the user in mind, so that they can issue commands in different ways. For example, a user should be able to use both speech and 3D gesture simultaneously to issue a command, and support should also be provided for using speech and eye gaze, or using 3D gesture and eye gaze, or using speech in isolation. This design choice makes the overall multimodal user interface more complex in terms of how the input modes are integrated, but provides the most generality.
Speech and pointing is the dominant multimodal integration pattern. From a usability perspective, speech and pointing make for an intuitive multimodal input combination, especially when the user wants to select some virtual object and then perform some operation on it (e.g., paint [this] cylinder blue). However, as we have seen in this chapter, there are a variety of different multimodal input combinations that are possible. The key question from a usability perspective is, does a particular input combination make sense for a particular task?
As a general guideline, it is important to provide multimodal input combinations that will support a simple and natural interaction metaphor for any given task. For example, speech and pointing may not be the best input combination in mobile settings, where touch input or 3D gestures may be more appropriate.
Multimodal input involves simultaneous signals. Not all multimodal input strategies require users to perform the individual inputs at the same time. Certain modalities extraneous afford such temporal integration but, in many cases, individual input modes are used consecutively (e.g., saying something, then performing a 3D gesture, and vise versa) but they still act as complementary modes of input. In fact, multimodal input strategies can also use one mode for certain tasks and a second or third mode for other tasks. Thus, from a usability perspective, it is important to recognize that there are a number of different ways that individual inputs can be combined, and not all of them need to support simultaneous input.
Speech is the primary input mode in any multimodal system that includes it. While speech is a dominant input channel that humans use to communicate, in many cases it does not need to be the primary modality in a multimodal interface. Unfortunately, speech recognition can be compromised in noisy environments, making it a less robust input mechanism. In addition, it may be the case that users do not want to use voice input due to privacy concerns. In other cases, speech may simply be a backup modality, or other modalities may be better suited to combine for a given task. Thus, when designing multimodal interaction scenarios, it is not a requirement to make speech the primary input mode, and it should only be used when it makes the most sense.
Multimodal language does not differ linguistically from unimodal language. One of the benefits of multimodal interaction is that it tends to simplify input patterns. As an example, consider a user who wants to move an object from one location to another. Using speech in isolation would require the user not only to describe the object of interest, but also to describe the location where the objects needs to be placed. However, with a combination of speech and gesture, the user can simplify the description of the object, because they are also using a second modality (in this case, pointing) both to identify the object and to place it in a different location. This input combination implies that one can use simpler input commands for each individual mode of input when performing concurrent multimodal interaction. In terms of usability, it is important to understand that unimodal language can be more complex than multimodal language, and that multimodal input can take away this complexity, making for an easier-to-use interface.
Multimodal integration involves redundancy of content between modes. One of the key ideas behind multimodal integration is that providing redundant modes of input can help to support a better user experience, because each individual mode can be used to reinforce the others. This is certainly true from a computational point of view, and it does have its place in multimodal integration. However, the complementary nature of multimodal input should not be ignored for its benefits from a usability perspective. Thus, ensuring proper multimodal integration to support complementarity is important from the user's perspective.
Individual error-prone recognition technologies combine multimodally to produce even greater unreliability. One of the interesting challenges with multimodal input, especially with perceptual computing, is that the input modalities used (e.g., speech, 3D gesture, 2D gesture) require recognition technologies designed to understand the input. Unfortunately, recognition is error-prone, based on the accuracy of the individual recognizers. However, combining multiple recognition-based input together actually can help to improve accuracy for the overall command, producing a more reliable interface. Multimodal integration strategies are key to this improvement. In addition, users, if given a choice, will tend to work with modalities that they believe have higher accuracies. Thus, from a usability perspective, this usage pattern is another reason to ensure the multimodal interface is flexible.
All users' multimodal commands are integrated in a uniform way. Users of multimodal interfaces tend to identify an integration pattern for how they will use the interface fairly early on, and they will stick with this pattern. However, as we have seen, there are many different ways that people can use a multimodal interface. Thus, it is important for the multimodal integration scheme to be flexible and to try to identify the dominant integration pattern on a per-user basis. This approach then can support improved recognition rates, because the fusion engine would be aware of how the user is interacting with the different modalities.
Different input modes are capable of transmitting comparable content – but not all input modalities are created equal. In other words, different modalities have strengths and weaknesses, depending on the type of information that the user wants to convey. For example, eye gaze will produce very different types of information than speech. Thus, from a usability perspective, it is important to understand what modalities are available, and what each one is ideal for. Trying to use a given modality as input for tasks that it is not suited for will only make the interface difficult to use.
Enhanced efficiency is the main advantage of multimodal systems. Finally, speed and efficiency are not the only advantages of multimodal interfaces. Reducing errors from individual recognition systems, as well as providing more flexibility to interact with an application in the way that users want to, are also important advantages of multimodal interaction. In addition, a properly designed multimodal interface will provide a level of generality to the user to support a variety of different tasks, applications, and environments.
9.6 Conclusion
In this chapter, we have explored how combining different input modalities can form natural and expressive multimodal interfaces. We have examined the types of multimodal input strategies and presented a variety of different multimodal interfaces that offer different combinations of touch input, speech, 3D gesture, eye gaze and tracking, facial expressions, and brain-computer input. We have also examined multimodal integration or fusion, a critical component of a multimodal architecture that integrates different modalities together to form a cohesive interface by examining the different approaches and levels of integration. Finally, we have presented a number of usability issues as they relate to multimodal input. Clearly, multimodal interfaces have come a long way from Bolt's “put-that-there” system [1].
However, more work is still needed in a variety of areas, including multimodal integration, recognition technology and usability, to fully support perceptual computing applications that provide powerful, efficient, and expressive human computer interaction.
References
- 1. Bolt, R.A. (1980). “Put-that-there”: voice and gesture at the graphics interface. Proceedings of the 7th annual conference on computer graphics and interactive techniques, SIGGRAPH '80, 262–270. ACM, New York, NY, USA.
- 2. Oviatt, S. (2003). Advances in robust multimodal interface design. IEEE Computer Graphics and Applications 23(5), 62–68.
- 3. Turk, M., Robertson, G. (2000). Perceptual user interfaces (introduction). Communications of the ACM 43(3), 32–34.
- 4. Dumas, B., Lalanne, D., Oviatt, S. (2009). Multimodal interfaces: A survey of principles, models and frameworks. In: Lalanne, D., Kohlas, J. (ed.). Human Machine Interaction, 3–26. vol. 5440 of Lecture Notes in Computer Science. Springer Berlin, Heidelberg.
- 5. Jaimes, A., Sebe, N. (2007). Multimodal human-computer interaction: A survey. Computer Vision and Image Understanding 108(12), 116–134. Special Issue on Vision for Human-Computer Interaction.
- 6. Oviatt, S. (2007). Multimodal interfaces. In: Sears, A., Jack, J. (eds.). The Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications, Second Edition, 413–432. CRC Press.
- 7. Martin, J.C. (1998). Tycoon: Theoretical framework and software tools for multimodal interfaces In: Lee, J, (Ed.). Intelligence and Multimodality in Multimedia Interfaces. AAAI Press.
- 8. Oviatt, S., Van gent, R. (1996). Error resolution during multimodal human-computer interaction, 204–207.
- 9. Bowman, D.A., Riff, E., Lavolta, J.J., Papyri, I. (2004). 3D User Interfaces: Theory and Practice. Addison Wesley Longman Publishing Co., Inc., Redwood City, CA, USA.
- 10. Sharma, A., Madhvanath, S., Shekhawat, A., Billinghurst, M. (2011). Mozart: a multimodal interface for conceptual 3D modelling. Proceedings of the 13th international conference on multimodal interfaces, ICMI '11. ACM, New York, NY, USA, 307–310.
- 11. Radhakrishnan, S., Lin, Y., Zeid, I., Kamarthi, S. (2013). Finger-based multitouch interface for performing 3D CAD operations. International Journal of Human-Computer Studies 71(3), 261–275.
- 12. Tse, E., Greenberg, S., Shen, C., Forlines, C., Kodama, R. (2008). Exploring true multi-user multimodal interaction over a digital table. Proceedings of the 7th ACM conference on Designing interactive systems, DIS '08. ACM, New York, NY, USA, 109–118.
- 13. Tse, E., Greenberg, S., Shen, C. (2006). GSI demo: multiuser gesture/speech interaction over digital tables by wrapping single user applications. Proceedings of the 8th international conference on Multimodal interfaces, 76–83.
- 14. Tse, E., Greenberg, S., Shen, C., Forlines, C. (2007). Multimodal multiplayer tabletop gaming. Computers in Entertainment (CIE) 5(2), 12.
- 15. Martínez, R., Collins, A., Kay, J., Yacef, K. (2011). Who did what? Who said that? Collaid: an environment for capturing traces of collaborative learning at the tabletop. Proceedings of the ACM International Conference on Interactive Tabletops and Surfaces, 172–181.
- 16. Barthelmess, P., Kaiser, E., Huang, X., Demirdjian, D. (2005). Distributed pointing for multimodal collaboration over sketched diagrams. Proceedings of the 7th international conference on Multimodal interfaces, ICMI '05. ACM, New York, NY, USA, 10–17
- 17. Piper, A.M., Hollan, J.D. (2008). Supporting medical conversations between deaf and hearing individuals with tabletop displays. Proceedings of the 2008 ACM conference on Computer supported cooperative work, CSCW '08. ACM, New York, NY, USA, 147–156.
- 18 Piper, A.M. (2010). Supporting medical communication with a multimodal surface computer. CHI '10 Extended Abstracts on Human Factors in Computing Systems, CHI EA '10. ACM, New York, NY, USA, 2899–2902.
- 19. Paek, T., Thiesson, B., Ju, Y.C., Lee, B. (2008). Search VOX: Leveraging multimodal refinement and partial knowledge for mobile voice search. Proceedings of the 21st annual ACM symposium on User interface software and technology, 141–150.
- 20. Ehlen, P., Johnston, M. (2011). Multimodal local search in speak4it. Proceedings of the 16th international conference on Intelligent user interfaces, 435–436 ACM.
- 21. Cohen, P.R., Johnston, M., McGee, D., Oviatt, S., Pittman, J., Smith, I., Chen, L., Clow, J. (1997a). Quickset: Multimodal interaction for distributed application. Proceedings of the fifth ACM international conference on Multimedia, 31–40.
- 22. Ramsay, A., McGee-Lennon, M., Wilson, G.A., Gray, S.J., Gray, P., De Turenne, F. (2010). Tilt and go: exploring multimodal mobile maps in the field. Journal on Multimodal User Interfaces 3(3), 167–177.
- 23. Feng, J., Johnston, M., Bangalore, S. (2011). Speech and multimodal interaction in mobile search. IEEE Signal Processing Magazine 28(4), 40–49.
- 24. Sim, K.C. (2012). Speak-as-you-swipe (says): a multimodal interface combining speech and gesture keyboard synchronously for continuous mobile text entry. Proceedings of the 14th ACM international conference on Multimodal interaction, 555–560.
- 25. Kristensson, P.O., Vertanen, K. (2011). Asynchronous multimodal text entry using speech and gesture keyboards. Proceedings of the 12th Annual Conference of the International Speech Communication Association (Interspeech 2011), 581–584.
- 26. Shinoda, K., Watanabe, Y., Iwata, K., Liang, Y., Nakagawa, R., Furui, S. (2011). Semi-synchronous speech and pen input for mobile user interfaces. Speech Communication 53(3), 283–291.
- 27. Dearman, D., Karlson, A., Meyers, B., Bederson, B. (2010). Multi-modal text entry and selection on a mobile device. Proceedings of Graphics Interface 2010, 19–26 Canadian Information Processing Society.
- 28. Laput, G.P., Dontcheva, M., Wilensky, G., Chang, W., Agarwala, A., Linder, J., Adar, E. (2013). Pixeltone: a multimodal interface for image editing. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI '13. ACM, New York, NY, USA, 2185–2194.
- 29. Muller, C., Weinberg, G. (2011). Multimodal input in the car, today and tomorrow. IEEE Multimedia 18(1), 98–103.
- 30. Pfleging, B., Schneegass, S., Schmidt, A. (2012). Multimodal interaction in the car: combining speech and gestures on the steering wheel. Proceedings of the 4th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, AutomotiveUI '12. ACM, New York, NY, USA, 155–162.
- 31. Pfleging, B., Kienast, M., Schmidt, A., Döring, T. (2011). Speet: A multimodal interaction style combining speech and touch interaction in automotive environments. Adjunct Proceedings of the 3rd International Conference on Automotive User Interfaces and Interactive Vehicular Applications, AutomotiveUI, 65–66.
- 32. Gruenstein, A., Orszulak, J., Liu, S., Roberts, S., Zabel, J., Reimer, B., Mehler, B., Seneff, S., Glass, J., Coughlin, J. (2009). City browser: developing a conversational automotive HMI. CHI '09 Extended Abstracts on Human Factors in Computing Systems, CHI EA '09. ACM, New York, NY, USA, 4291–4296.
- 33. Williamson, B.M., Wingrave, C., LaViola, J.J., Roberts, T., Garrity, P. (2011). Natural full body interaction for navigation in dismounted soldier training. The Interservice/Industry Training, Simulation & Education Conference (I/ITSEC), NTSA.
- 34. Williamson, B.M., LaViola, J.J., Roberts, T., Garrity, P. (2012). Multi-kinect tracking for dismounted soldier training. The Interservice/Industry Training, Simulation & Education Conference (I/ITSEC), NTSA.
- 35. Budhiraja, P., Madhvanath, S. (2012). The blue one to the left: enabling expressive user interaction in a multimodal interface for object selection in virtual 3D environments. Proceedings of the 14th ACM international conference on Multimodal interaction, 57–58.
- 36. Hoste, L., Dumas, B., Signer, B. (2012). Speeg: a multimodal speech-and gesture-based text input solution. Proceedings of the International Working Conference on Advanced Visual Interfaces, 156–163.
- 37. Ward, D.J., Blackwell, A.F., MacKay, D.J. (2000). Dashera data entry interface using continuous gestures and language models. Proceedings of the 13th annual ACM symposium on User interface software and technology, 129–137.
- 38. Bohus, D., Horvitz, E. (2009). Dialog in the open world: platform and applications Proceedings of the 2009 international conference on Multimodal interfaces, 31–38, ACM.
- 39. Hrúz, M., Campr, P., Dikici, E., Kındıro
 lu, A.A., Kr
lu, A.A., Kr oul, Z., Ronzhin, A., Sak, H., Schorno, D., Yalçın, H., Akarun, L. et al. (2011). Automatic fingersign-to-speech translation system. Journal on Multimodal User Interfaces 4(2), 61–79.
oul, Z., Ronzhin, A., Sak, H., Schorno, D., Yalçın, H., Akarun, L. et al. (2011). Automatic fingersign-to-speech translation system. Journal on Multimodal User Interfaces 4(2), 61–79. - 40 Gallo, L., Placitelli, A.P., Ciampi, M. (2011). Controller-free exploration of medical image data: Experiencing the Kinect. IEEE International Symposium on Computer-Based Medical Systems (CBMS), 1–6.
- 41. Perzanowski, D., Schultz, A.C., Adams, W., Marsh, E., Bugajska, M. (2001). Building a multimodal human-robot interface. IEEE Intelligent Systems 16(1), 16–21.
- 42. Burger, B., Ferrané, I., Lerasle, F., Infantes, G. (2012). Two-handed gesture recognition and fusion with speech to command a robot. Autonomous Robots 32(2), 129–147.
- 43. Stiefelhagen, R., Fugen, C., Gieselmann, R., Holzapfel, H., Nickel, K., Waibel, A. (2004). Natural human-robot interaction using speech, head pose and gestures. Proceedings of International Conference on Intelligent Robots and Systems, IROS, 3, 2422–2427.
- 44. Lee, S.H., Sohn, M.K., Kim, D.J., Kim, B., Kim, H. (2013). Smart TV interaction system using face and hand gesture recognition. IEEE International Conference on Consumer Electronics (ICCE), 173–174.
- 45. Takahashi, M., Fujii, M., Naemura, M., Satoh, S. (2013). Human gesture recognition system for TV viewing using time-of-flight camera. Multimedia Tools and Applications 62(3), 761–783.
- 46. Krahnstoever, N., Kettebekov, S., Yeasin, M., Sharma, R. (2002). A real-time framework for natural multimodal interaction with large screen displays. Proceedings of the 4th IEEE International Conference on Multimodal Interfaces, 349.
- 47. Duchowski, A.T. (2007). Eye Tracking Methodology: Theory and Practice. Springer-Verlag New York, Inc., Secaucus, NJ, USA.
- 48. Kumar, M., Paepcke, A., Winograd, T. (2007). Eyepoint: practical pointing and selection using gaze and keyboard. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI '07. ACM, New York, NY, USA, 421–430
- 49. Zhang, X., MacKenzie, I. (2007). Evaluating eye tracking with ISO 9241– part 9. In: Jacko, J. (ed.). Human-Computer Interaction. HCI Intelligent Multimodal Interaction Environments. vol. 4552 of Lecture Notes in Computer Science. Springer Berlin, Heidelberg, 779–788.
- 50. Hild, J., Muller, E., Klaus, E., Peinsipp-Byma, E., Beyerer, J. (2013). Evaluating multi-modal eye gaze interaction for moving object selection. The Sixth International Conference on Advances in Computer-Human Interactions, ACHI, 454–459.
- 51. Zhai, S., Morimoto, C., Ihde, S. (1999). Manual and gaze input cascaded (magic) pointing. Proceedings of the SIGCHI conference on Human Factors in Computing Systems, CHI '99. ACM, New York, NY, USA, 246–253.
- 52. Cha, T., Maier, S. (2012). Eye gaze assisted human-computer interaction in a hand gesture controlled multi-display environment. Proceedings of the 4th Workshop on Eye Gaze in Intelligent Human Machine Interaction, Gaze-In '12. ACM, New York, NY, USA, 13, 1–13:3.
- 53. Stellmach, S., Dachselt, R. (2012). Investigating gaze-supported multimodal pan and zoom. Proceedings of the Symposium on Eye Tracking Research and Applications, ETRA '12. ACM, New York, NY, USA, 357–360
- 54. Beelders, T.R., Blignaut, P.J. (2012). Measuring the performance of gaze and speech for text input. Proceedings of the Symposium on Eye Tracking Research and Applications, ETRA '12. ACM, New York, NY, USA, 337–340.
- 55. Heo, H., Lee, E.C., Park, K.R., Kim, C.J., Whang, M. (2010). A realistic game system using multi-modal user interfaces. IEEE Transactions on Consumer Electronics 56(3), 1364–1372.
- 56. Vilimek, R., Zander, T. (2009). Bc(eye): Combining eye-gaze input with brain-computer interaction. In: Stephanidis, C. (ed.). Universal Access in Human-Computer Interaction. Intelligent and Ubiquitous Interaction Environments. Vol. 5615 of Lecture Notes in Computer Science. Springer Berlin, Heidelberg, 593–602.
- 57. Zander, T.O., Gaertner, M., Kothe, C., Vilimek, R. (2010a). Combining eye gaze input with a brain-computer interface for touchless human-computer interaction. Intl. Journal of Human-Computer Interaction 27(1), 38–51.
- 58. Sandbach, G., Zafeiriou, S., Pantic, M., Yin, L. (2012). Static and dynamic 3D facial expression recognition: A comprehensive survey. Image and Vision Computing 30(10), 683–697.
- 59. De Silva, L., Miyasato, T., Nakatsu, R. (1997). Facial emotion recognition using multi-modal information. Proceedings of 1997 International Conference on Information, Communications and Signal Processing (ICICS), 1, 397–401.
- 60. Busso, C., Deng, Z., Yildirim, S., Bulut, M., Lee, C.M., Kazemzadeh, A., Lee, S., Neumann, U., Narayanan, S. (2004). Analysis of emotion recognition using facial expressions, speech and multimodal information. Proceedings of the 6th international conference on Multimodal interfaces, ICMI '04. ACM, New York, NY, USA, 205–211.
- 61. Kessous, L., Castellano, G., Caridakis, G. (2010). Multimodal emotion recognition in speech-based interaction using facial expression, body gesture and acoustic analysis. Journal on Multimodal User Interfaces 3(1–2), 33–48.
- 62 Wöllmer, M., Metallinou, A., Eyben, F., Schuller, B., Narayanan, S.S. (2010). Context-sensitive multimodal emotion recognition from speech and facial expression using bidirectional LSTM modeling. Proceedings of Interspeech, Japan, 2362–2365.
- 63. Lisetti, C.L., Nasoz, F. (2002). Maui: a multimodal affective user interface. Proceedings of the tenth ACM international conference on Multimedia, MULTIMEDIA '02. ACM, New York, NY, USA, 161–170.
- 64. Caridakis, G., Karpouzis, K., Wallace, M., Kessous, L., Amir, N. (2010). Multimodal users affective state analysis in naturalistic interaction. Journal on Multimodal User Interfaces 3(1–2), 49–66.
- 65. Gürkök, H., Nijholt, A. (2012). Brain-computer interfaces for multimodal interaction: a survey and principles. International Journal of Human-Computer Interaction 28(5), 292–307.
- 66. Leeb, R., Sagha, H., Chavarriaga, R., del R Millan, J. (2010). Multimodal fusion of muscle and brain signals for a hybrid-BCI. 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 4343–4346.
- 67. Fazli, S., Mehnert, J., Steinbrink, J., Curio, G., Villringer, A., Müller, K.R., Blankertz, B. (2012). Enhanced performance by a hybrid NIRS-EEG brain computer interface. Neuroimage 59(1), 519–529.
- 68. Gürkök, H., Hakvoort, G., Poel, M. (2011). Modality switching and performance in a thought and speech controlled computer game. Proceedings of the 13th international conference on multimodal interfaces, ICMI '11. ACM, New York, NY, USA, 41–48.
- 69. Sree, S., Verma, A., Rai, R. (2013). Creating by imaging: Use of natural and intuitive BCI in 3D CAD modelling. ASME International Design Engineering Technical Conference ASME/DETC/CIE ASME.
- 70. Zander, T.O., Kothe, C., Jatzev, S., Gaertner, M. (2010b). Enhancing human-computer interaction with input from active and passive brain-computer interfaces. Brain-Computer Interfaces, Springer, 181–199.
- 71. Maye, A., Zhang, D., Wang, Y., Gao, S., Engel, A.K. (2011). Multimodal brain-computer interfaces. Tsinghua Science & Technology 16(2), 133–139.
- 72. Lalanne, D., Nigay, L., Palanque, P., Robinson, P., Vanderdonckt, J., Ladry, J.F. (2009). Fusion engines for multimodal input: a survey. Proceedings of the 2009 international conference on Multimodal interfaces, ICMIMLMI '09. ACM, New York, NY, USA, 153–160.
- 73. Turk, M. (2014). Multimodal interaction: A review. Pattern Recognition Letters 36, 189–195.
- 74. Sharma, R., Pavlovic, V., Huang, T. (1998). Toward multimodal human-computer interface. Proceedings of the IEEE 86(5), 853–869.
- 75. Koons, D.B., Sparrell, C.J., Thorisson, K.R. (1993). Integrating simultaneous input from speech, gaze, and hand gestures. In: Maybury, M.T. (Ed.). Intelligent multimedia interfaces. American Association for Artificial Intelligence, Menlo Park, CA, USA, 257–276.
- 76. Dumas, B., Lalanne, D., Guinard, D., Koenig, R., Ingold, R. (2008). Strengths and weaknesses of software architectures for the rapid creation of tangible and multimodal interfaces. Proceedings of the 2nd international conference on Tangible and embedded interaction, TEI '08. ACM, New York, NY, USA, 47–54.
- 77. Bouchet, J., Nigay, L., Ganille, T. (2004). Icare software components for rapidly developing multimodal interfaces. Proceedings of the 6th international conference on Multimodal interfaces, ICMI '04. ACM, New York, NY, USA, 251–258.
- 78. Nigay, L., Coutaz, J. (1995). A generic platform for addressing the multimodal challenge. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI '95. ACM Press/Addison-Wesley Publishing Co., New York, NY, USA, 98–105.
- 79. Vo, M.T., Wood, C. (1996). Building an application framework for speech and pen input integration in multimodal learning interfaces. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP-96, 6, 3545–3548.
- 80. Calder J. (1987). Typed unification for natural language processing. In: Kahn, G., MacQueen, D., Plotkin, G. (eds.). Categories, Polymorphism, and Unification. Centre for Cognitive Science University of Edinburgh, Edinburgh, Scotland.
- 81. Johnston, M., Cohen, P.R., McGee, D., Oviatt, S.L., Pittman, J.A., Smith, I. (1997). Unification-based multimodal integration. Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and Eighth Conference of the European Chapter of the Association for Computational Linguistics, ACL '98. Association for Computational Linguistics, Stroudsburg, PA, USA, 281–288.
- 82. Cohen, P.R., Johnston, M., McGee, D., Oviatt, S., Pittman, J., Smith, I., Chen, L., Clow, J. (1997b). Quickset: multimodal interaction for distributed applications. Proceedings of the fifth ACM international conference on Multimedia, MULTIMEDIA '97. New York, NY, USA, 31–40.
- 83 Taylor, G., Frederiksen, R., Crossman, J., Quist, M., Theisen, P. (2012). A multi-modal intelligent user interface for supervisory control of unmanned platforms. International Conference on Collaboration Technologies and Systems (CTS), 117–124.
- 84. Sun, Y., Chen, F., Shi, Y.D., Chung, V. (2006). A novel method for multi-sensory data fusion in multimodal human computer interaction. Proceedings of the 18th Australia conference on Computer-Human Interaction: Design: Activities, Artefacts and Environments, OZCHI '06. ACM, New York, NY, USA, 401–404.
- 85. Holzapfel, H., Nickel, K., Stiefelhagen, R. (2004). Implementation and evaluation of a constraint-based multimodal fusion system for speech and 3D pointing gestures. Proceedings of the 6th international conference on Multimodal interfaces, ICMI '04. ACM, New York, NY, USA, 175–182.
- 86. Pfleger, N. (2004). Context-based multimodal fusion. Proceedings of the 6th international conference on Multimodal interfaces, ICMI '04. ACM, New York, NY, USA, 265–272.
- 87. Neal, J.G., Thielman, C.Y., Dobes, Z., Haller, S.M., Shapiro, S.C. (1989). Natural language with integrated deictic and graphic gestures. Proceedings of the workshop on Speech and Natural Language, HLT '89. Association for Computational Linguistics, Stroudsburg, PA, USA, 410–423.
- 88. Latoschik, M. (2002). Designing transition networks for multimodal VR-interactions using a markup language. Proceedings of Fourth IEEE International Conference on Multimodal Interfaces, 411–416.
- 89. Johnston, M., Bangalore, S. (2005). Finite-state multimodal integration and understanding. Natural Language Engineering 11(2), 159–187.
- 90. Bourguet, M. (2002). A toolkit for creating and testing multimodal interface designs. Proceedings of User Interface Software and Technology (UIST 2002) Companion proceedings, 29–30.
- 91. Navarre, D., Palanque, P., Bastide, R., Schyn, A.,Winckler, M., Nedel, L.P., Freitas, C.M.D.S. (2005). A formal description of multimodal interaction techniques for immersive virtual reality applications. Proceedings of the 2005 IFIP TC13 international conference on Human-Computer Interaction, INTERACT'05. Springer-Verlag, Berlin, Heidelberg, 170–183.
- 92. Wu, L., Oviatt, S.L., Cohen, P.R. (1999). Multimodal integration – a statistical view. IEEE Transactions on Multimedia 1, 334–341.
- 93. Pan, H., Liang, Z.P., Huang, T. (1999). Exploiting the dependencies in information fusion. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2, 412.
- 94. Wu, L., Oviatt, S.L., Cohen, P.R. (2002). From members to teams to committee – a robust approach to gestural and multimodal recognition. IEEE Transactions on Neural Networks 13(4), 972–982.
- 95. Flippo, F., Krebs, A., Marsic, I. (2003). A framework for rapid development of multimodal interfaces. Proceedings of the 5th international conference on Multimodal interfaces, ICMI '03. ACM, New York, NY, USA, 109–116.
- 96. Dumas, B., Signer, B., Lalanne, D. (2012). Fusion in multimodal interactive systems: an hmm-based algorithm for user-induced adaptation. Proceedings of the 4th ACM SIGCHI symposium on Engineering interactive computing systems, EICS '12. ACM, New York, NY, USA, 15–24.
- 97. Damousis, I.G., Argyropoulos, S. (2012). Four machine learning algorithms for biometrics fusion: a comparative study. Appl. Comp. Intell. Soft Comput. 242401-1-7.
- 98. Huang, X., Oviatt, S., Lunsford, R. (2006). Combining user modeling and machine learning to predict users multimodal integration patterns. In: Renals, S., Bengio, S., Fiscus, J. (eds.). Machine Learning for Multimodal Interaction, vol. 4299 of Lecture Notes in Computer Science Springer Berlin, Heidelberg, 50–62.
- 99. Reeves, L.M., Lai, J., Larson, J.A., Oviatt, S., Balaji, T.S., Buisine, S., Collings, P., Cohen, P., Kraal, B., Martin, J.C., McTear, M., Raman, T., Stanney, K.M., Su, H., Wang, Q.Y. (2004). Guidelines for multimodal user interface design. Communications of the ACM 47(1), 57–59.
- 100. Oviatt, S. (1999). Ten myths of multimodal interaction. Communications of the ACM 42(11), 74–81.