
Route Filtering and Attribute Manipulation
The concept of route filtering is straightforward. A BGP speaker can choose what routes to send and what routes to receive from any of its BGP peers. Route filtering is essential in defining routing policies. An autonomous system can identify the inbound traffic it is willing to accept from other neighbors by specifying the list of routes it advertises to its neighbors. Conversely, an AS can control what routes its outbound traffic uses by specifying the routes it accepts from its neighbors.
Tip
See the section Route Filtering and Attribute Manipulation in Chapter 11.
Filtering is also used on the protocol level to limit routing updates flowing from one protocol to another. Earlier, this chapter discussed the possibility of injecting BGP routes in the IGP as well as injecting the IGP or static routes into BGP. Cisco's terminology for this process is redistributing between protocols. This chapter has also discussed the dangers of mutual redistribution between protocols. Filtering is essential in specifying exactly what goes from BGP into the IGP and vice versa.
Routes permitted through a filter can have their attributes manipulated. Manipulating the attributes affects the BGP decision process used to identify the best routes to a given destination.
Inbound and Outbound Filtering
Both the inbound and outbound filtering concepts can be applied to the peer and protocol levels. Figure 6-24 illustrates this behavior.
Figure 6-24. Inbound/Outbound Filtering Example

From the perspective of routes exchanged between BGP peers, inbound filtering indicates that the BGP speaker is filtering routing updates received from other peers, whereas outbound filtering limits the routing updates advertised from the BGP speaker to other peers. Filtering behavior is the same whether the BGP peers are external (EBGP) or internal (IBGP).
At the protocol level, inbound filtering limits the routing updates being injected into a protocol. Outbound filtering limits the routing updates being injected from this protocol. With respect to BGP, for example, inbound filtering limits the updates being redistributed from other protocols such as the IGP and static routes into BGP. Outbound filtering limits the updates being redistributed from BGP into IGP.
The Route Filtering and Manipulation Process
Filtering and manipulating a route or a set of routes involves three actions:
|
1.
|
Identifying the routes
|
|
2.
|
Permitting or denying the routes
|
|
3.
|
Manipulating attributes
|
Cisco uses access lists, prefix lists, or as-path access lists to accomplish only filtering. Cisco also uses the concept of route maps to achieve both filtering and attribute manipulation. Route maps are discussed in Chapter 11.
Identifying Routes
Identifying routes is the process of setting criteria to differentiate routes from each other. Such criteria could be based on the route's IP prefix, the autonomous system from which a route was originated, a list of ASs that a route has passed through, a specific attribute value inside the route, and so on. A list of criteria instances is contained in the filtering rules, and a route is compared to the first instance in the list. If the route does not match the first instance, it is checked against the next instance in the list. After a route matches an instance, it is considered identified and will not be compared to any further instances.
If the route proceeds to be compared against the entire list of instances and there is still no match, the route is discarded.
Identifying routes based on the Network Layer Reachability Information (NLRI), the AS_PATH, or both is the most common way of identifying routes. Each of these methods is discussed in more detail in the following sections.
Identifying Routes Based on the NLRI
A BGP route could be identified by its NLRI, which is the prefix and the mask, as discussed in Chapter 4. For filtering purposes, a prefix or a range of prefixes is defined. If the route falls within the range, it will be identified.
Tip
See the section Identifying and Filtering Routes Based on the NLRI in Chapter 11.
Figure 6-25 illustrates filtering criteria of 10.1.0.0 0.0.255.255, which represents a range of routes identified by a prefix 10.1.0.0 and an inverse mask 0.0.255.255. The 0s in the mask indicate a match, whereas the 1s indicate a do-not-care-bit. The 10.1.0.0 0.0.255.255 range will identify all routes of the form 10.1.X.X. Presented with the prefixes shown in Figure 6-25, this filter will identify 10.1.1.0/24, 10.1.2.0/24, and 10.1.2.2/30 and will exclude 11.2.0.0/16 and 12.1.1.0/24. Prefix-based filtering will be discussed in detail in later chapters.
Figure 6-25. NLRI Filtering Criteria Example

Prefix lists are currently the preferred mechanism to be used for filter routing information. Introduced to IOS only recently, they provide several benefits in comparison to traditional access lists.
Prefix lists employ a more efficient lookup structure, providing a significant reduction in resources required to process routing updates. At this time, prefix lists cannot be used for functions other than filtering routing protocol information.
One of the key benefits of prefix lists is the capability to perform incremental updates. In other words, you can add, delete, or modify a list without having to completely rebuild it. Also, the syntax used for configured prefix lists is much more intuitive than that used for traditional access lists. Chapter 11 provides configuration guidelines for prefix lists.
Identifying Routes Based on the AS_PATH
Identifying routes based on the AS_PATH information is a bit more involved. As you know by now, the AS_PATH is a list of ASs that a route has traversed before reaching a BGP peer. The list itself is a character string that contains characters from the following set:
-
Numbers 0 through 9
-
Space
-
Left brace {
-
Right brace }
-
Left parenthesis (
-
Right parenthesis )
-
Beginning of the input string
-
End of the input string
-
Comma ,
The AS_PATH list 10 2, for example, is actually a beginning-of-string character followed by character 1 followed by a 0 followed by a space followed by a 2 followed by an end-of-string character.
Tip
See the section Identifying and Filtering Routes Based on the AS_PATH in Chapter 11.
Trying to identify the AS_PATH list consists of comparing the list to what is called a regular expression. A regular expression is just a pattern of characters represented by a formula such as ^200 100$. This is a regular expression representing a list that starts with 200, that is followed by a space, and that ends with 100. The ^ and $ are representations of the beginning-of-string and end-of-string characters, respectively.
Note
A regular expression can be formed by using single-character patterns or multiple-character patterns.
Permitting or Denying Routes
After the route has been identified, actions can be taken on it. The route is permitted or denied, depending on what filtering rules have been established for that juncture. The criteria for permitting or denying routes depend on the policies an AS is setting. If the route is permitted, it is either accepted "as is" or is submitted for modification of attributes. Again, this depends on what attributes are to be modified. If the route is denied, that route is discarded, and no further processing is required.
Manipulating Attributes
If a route is permitted, its attributes can be changed to affect the decision process. In earlier sections, you saw how attributes such as local preference and MED can be added or made larger or smaller to prefer one route to another. As you will see later, attribute manipulation is key to establishing route policies, load balancing, and route symmetry.
Figure 6-26 shows in detail how multiple instances can be applied on a set of routes to find a match.
Figure 6-26. Summary Example of the Route Filtering and Manipulation Process
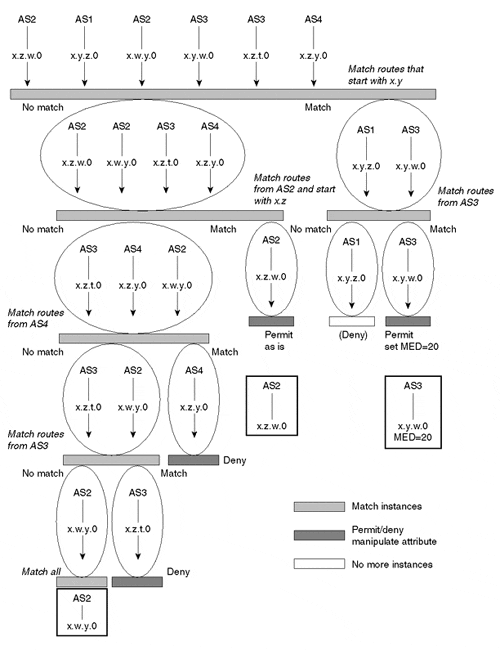
Note that each instance could have one or more criteria. A route could be checked based on its prefix and its AS_PATH information, for example, and it must meet all criteria before a match occurs.
Also note that after a route matches, it is not compared to any more instances. Hence, the order in which the instances are checked is important. For example, if it's put at the beginning of the list, an instance that permits all routes will override all the other instances.
Single-Character Patterns
A single-character pattern tries to match a single character. The single-character regular expression 3 tries to match the character 3 in an input string. You can specify a range of single characters to match against a string. Ranges are included within brackets ([]). The order in which the characters forming the range are listed is not important. The regular expression consisting of the range [efghEFGH], for example, tries to match any of the bracket-enclosed characters in an input string. Given two input strings, "hello" and "there", the regular expression matches both of these lists because they both contain the character e.
Ranges can be listed by typing the end points of a range. For example, ranges [a–z] and [0–9] indicate any lowercase character from a to z and any numeric character between 0 and 9, respectively.
You can also reverse or negate the pattern matching by including a caret (^) at the beginning of the range. The range [^a–dA–D], for example, matches any character except a, b, c, d, A, B, C, or D. Some characters have a special meaning, such as the dollar sign $ and the underscore _ (see Table 6-4).
To list the special characters as part of an input list, precede them with a backslash (). The range [abc$], for example, will match an input string that contains the characters a, b, c, and $. Table 6-4 lists the special characters used in regular expressions.
| Character | Symbol | Special Meaning |
|---|---|---|
| Period | . | Matches any single character, including white space. |
| Asterisk | * | Matches zero or more sequences of the pattern. |
| Plus sign | + | Matches one or more sequences of the pattern. |
| Question mark | ? | Matches zero or one occurrences of the pattern. |
| Caret | ^ | Matches the beginning of the input string. Also used to negate a pattern match if used inside the beginning of a range of characters—for example, [^range]. |
| Dollar sign | $ | Matches the end of the input string. |
| Underscore | _ | Matches a comma (,), left brace ({), right brace (}), left parenthesis, right parenthesis, the beginning of the input string, the end of the input string, or a space. |
| Brackets | [range] | Designates a range of single-character patterns. |
| Hyphen | - | Separates the end points of a range. |
Multiple-Character Patterns
Multiple-character regular expressions are just an ordered sequence of single-character patterns. The pattern is a combination of letters, numbers, any keyboard characters, and special-meaning characters. Here is an example of a multiple-character regular expression: 100 1[0–9]. This regular expression matches any string that contains the exact sequence 100, followed by a space, followed by a 1, followed by any number between 0 and 9. Any of the following input strings will match the regular expression: 123 100 10 11, or 100 19, or 19 100 11 200, and so on.
Building Complex Regular Expressions
The special characters listed in Table 6-4 can be used to build complex but very practical regular expressions. The caret (^) and dollar sign ($) are used to match the regular expression pattern against the beginning and end of the input string. Other characters, such as the asterisk (*), the plus sign (+), and the question mark (?), let you repeat the patterns inside the regular expression.
The following example matches any number of occurrences of the letter a, including none:
a* is equivalent to any of the following: (nothing), a, aa, aaa, aaaa, and so on.
The following example requires that at least one letter a be present in the string to be matched:
a+ is equivalent to a, aa, aaa, aaaa, and so on.
The following is an example of a list that may or may not contain the letter a:
ba?b is equivalent to bb or bab.
To repeat instances of multiple-character patterns, the pattern is enclosed in parentheses. For example, the expression (ab)+ is equivalent to ab or abab.
The underscore character (_) matches the beginning of a string (^), the end of a string ($), parentheses, space, braces, comma, or underscore. The dot character (.) matches a single character, including a white space. Figure 6-27, Table 6-5, and Table 6-6 illustrate how characters can be strung together to create a useful regular expression.
Consider the network topology illustrated in Figure 6-27. AS400, AS300, AS200, AS100, and AS50 are originating the routes NetA, NetB, NetC, NetD, and NetE, respectively. RTA in AS50 is receiving updates about all these networks from its neighbors AS100 and AS300. After running its BGP decision process, RTA has picked the best path to reach these networks according to Table 6-5.
Figure 6-27. Sample Network Topology for Complex Regular Expression
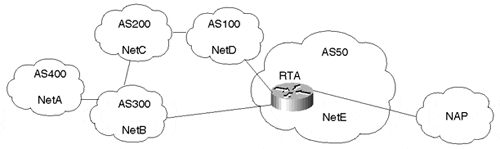
| Network | AS_PATH |
|---|---|
| NetA | 300 400 |
| NetB | 300 |
| NetC | 100 200 |
| NetD | 100 |
| NetE | Empty |
Table 6-6 reflects the regular expressions that would be used to create possible route filtering arrangements that RTA could apply when propagating routes to the NAP.
Filtering based on AS_PATH information is quite effective because it filters all the routing updates that belong to the AS_PATH at the same time. Without this type of filtering, thousands of routes would have to be listed individually or perhaps be members of an already identified BGP community.
Peer Groups
A BGP peer group is a group of BGP neighbors that share the same update policies. Instead of defining the same policies for each individual neighbor, you define a peer group name and assign policies to the peer group itself. For example, an administrator setting policies toward its BGP peers will probably set the same policies toward the majority of its peers and therefore will define them as a peer group.
Not only do peer groups save the operator from repetitive configuration of each BGP peer, they save the BGP router itself from the effort of parsing the policies sequentially for each neighbor. With peer groups, the router formulates the update once, based on the policies of the peer group, and then floods the same update to all the neighbors that fall within the group.
In Figure 6-28, RTA has three internal peers with which it has the same internal policies. RTA also has three external peers with which it has the same policies. RTA's configuration includes two sets of peer groups—one for inside the AS and one for outside the AS. Each peer group contains the set of policies that RTA has toward its peers. These policies could be a set of IP prefix filters or AS_PATH filters and possibly other attribute manipulations. After the peer groups have been defined, these policies are applied to the neighbors that make up the peer group.
Figure 6-28. Peer Group Implementation
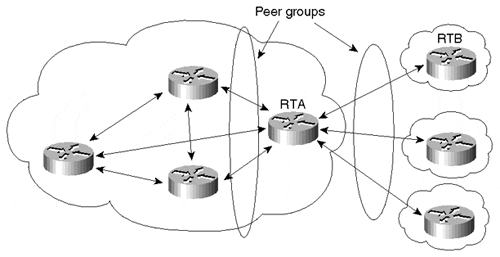
At one time, Cisco IOS imposed some restrictions on EBGP neighbors residing in the same peer group. Enhancements have since removed these restrictions. Therefore, we won't consume additional time discussing those restrictions. However, note that if you're using older versions of IOS, some of these restrictions might still be present. Consult Cisco documentation associated with your specific version of IOS for additional information.
Peer Group Exceptions
Exceptions occur when some neighbors inside a peer group have slightly different policies from other neighbors. Additional policies can be added to the neighbor to complement the set of policies that fall within the peer group. Assume in the scenario presented in Figure 6-28 that RTA requires an additional set of filters to be set toward its peer RTB. RTA can apply the extra filters toward RTB while still keeping RTB within the external peer group.
Tip
See the section Peer Groups in Chapter 11.