
To work with ZFS, it’s important to understand the basics of the technical side and implementation. I have seen lots of failures that have stemmed from the fact that people were trying to administer or even troubleshoot ZFS file systems without really understanding what they were doing and why. ZFS goes to great lengths to protect your data, but nothing in the world is user proof. If you try really hard, you will break it. That’s why it’s a good idea to get started with the basics.
Note
On most Linux distributions, ZFS is not available by default. For up-to-date information about the implementation of ZFS on Linux, including the current state and roadmap, visit the project’s home page: http://zfsonlinux.org/ . Since Ubuntu Xenial Xerus, the 16.04 LTS Ubuntu release, Canonical has made ZFS a regular, supported file system. While you can’t yet use it during the installation phase, at least not easily, it is readily available for use and is a default file system for LXD (a next-generation system container manager).
In this chapter, we look at what ZFS is and cover some of the key terminology.
What Is ZFS?
ZFS is a copy-on-write (COW ) file system that merges a file system, logical volume manager, and software RAID. Working with a COW file system means that, with each change to the block of data, the data is written to a completely new location on the disk. Either the write occurs entirely, or it is not recorded as done. This helps to keep your file system clean and undamaged in the case of a power failure. Merging the logical volume manager and file system together with software RAID means that you can easily create a storage volume that has your desired settings and contains a ready-to-use file system.
Note
ZFS’s great features are no replacement for backups. Snapshots, clones, mirroring, etc., will only protect your data as long as enough of the storage is available. Even having those nifty abilities at your command, you should still do backups and test them regularly.
COW Principles Explained
The Copy On Write (COW) design warrants a quick explanation, as it is a core concept that enables some essential ZFS features. Figure 1-1 shows a graphical representation of a possible pool; four disks comprise two vdevs (two disks in each vdev). vdev is a virtual device built on top of disks, partitions, files or LUNs. Within the pool, on top of vdevs, is a file system. Data is automatically balanced across all vdevs, across all disks.
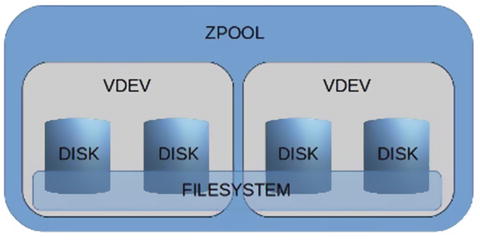
Figure 1-1 Graphical representation of a possible pool
Figure 1-2 presents a single block of freshly written data.

Figure 1-2 Single data block
When the block is later modified, it is not being rewritten. Instead, ZFS writes it anew in a new place on disk, as shown in Figure 1-3. The old block is still on the disk, but ready for reuse, if free space is needed.

Figure 1-3 Rewritten data block
Let’s assume that before the data has been modified, the system operator creates a snapshot. The DATA 1 SNAP block is being marked as belonging to the file system snapshot. When the data is modified and written in new place, the old block location is recorded in a snapshot vnodes table. Whenever a file system needs to be restored to the snapshot time (when rolling back or mounting a snapshot), the data is reconstructed from vnodes in the current file system, unless the data block is also recorded in the snapshot table (DATA 1 SNAP) as shown in Figure 1-4.

Figure 1-4 Snapshotted data block
Deduplication is an entirely separate scenario. The blocks of data are being compared to what’s already present in the file system and if duplicates are found, only a new entry is added to the deduplication table. The actual data is not written to the pool. See Figure 1-5.

Figure 1-5 Deduplicated data block
ZFS Advantages
There are many storage solutions out in the wild for both large enterprises and SoHo environments. It is outside the scope of this guide to cover them in detail, but we can look at the main pros and cons of ZFS.
Simplified Administration
Thanks to merging volume management, RAID, and file system all in one, there are only two commands you need use to create volumes, redundancy levels, file systems, compression, mountpoints, etc. It also simplifies monitoring, since there are two or even three less layers to be looked out for.
Proven Stability
ZFS has been publicly released since 2005 and countless storage solutions have been deployed based on it. I’ve seen hundreds of large ZFS storages in big enterprises and I’m confident the number is hundreds if not thousands more. I’ve also seen small, SoHo ZFS arrays. Both worlds have witnessed great stability and scalability, thanks to ZFS.
Data Integrity
ZFS was designed with data integrity in mind. It comes with data integrity checks, metadata checksumming, data failure detection (and, in the case of redundant setup, possibly fixing it), and automatic replacement of failed devices.
Scalability
ZFS scales well, with the ability to add new devices, control cache, and more.
ZFS Limitations
As with every file system, ZFS also has its share of weaker points that you need to keep in mind to successfully operate the storage.
80% or More Principle
As with most file systems, ZFS suffers terrible performance penalty when filled up to 80% or more of its capacity. It is a common problem with file systems. Remember, when your pool starts filling to 80% of capacity, you need to look at either expanding the pool or migrating to a bigger setup.
You cannot shrink the pool, so you cannot remove drives or vdevs from it once they have been added.
Limited Redundancy Type Changes
Except for turning a single disk pool into a mirrored pool, you cannot change redundancy type. Once you decide on a redundancy type, your only way of changing it is to destroy the pool and create a new one, recovering data from backups or another location.
Key Terminology
Some key terms that you’ll encounter are listed in the following sections.
Storage Pool
The storage pool is a combined capacity of disk drives. A pool can have one or more file systems. File systems created within the pool see all the pool’s capacity and can grow up to the available space for the whole pool. Any one file system can take all the available space, making it impossible for other file systems in the same pool to grow and contain new data. One of the ways to deal with this is to use space reservations and quotas.
vdev
vdev is a virtual device that can consist of one or more physical drives. vdev can be a pool or be a part of a larger pool. vdev can have a redundancy level of mirror, triple mirror, RAIDZ, RAIDZ-2, or RAIDZ-3. Even higher levels of mirror redundancy are possible, but are impractical and costly.
File System
A file system is created in the boundaries of a pool. A ZFS file system can only belong to one pool, but a pool can contain more than one ZFS file system. ZFS file systems can have reservations (minimum guaranteed capacity), quotas, compression, and many other properties. File systems can be nested, meaning you can create one file system in another. Unless you specify otherwise, file systems will be automatically mounted within their parent. The uppermost ZFS file system is named the same as the pool and automatically mounted under the root directory , unless specified otherwise.
Snapshots
Snapshots are point-in-time snaps of the file system’s state. Thanks to COW semantics, they are extremely cheap in terms of disk space. Creating a snapshot means recording file system vnodes and keeping track of them. Once the data on that inode is updated (written to new place—remember, it is COW), the old block of data is retained. You can access the old data view by using said snapshot, and only use as much space as has been changed between the snapshot time and the current time.
Clones
Snapshots are read-only. If you want to mount a snapshot and make changes to it, you’ll need a read-write snapshot, or clone. Clones have many uses, one of greatest being boot environment clones. With an operating system capable of booting off ZFS (illumos distributions, FreeBSD), you can create a clone of your operating system and then run operations in a current file system or in a clone, to perhaps upgrade the system or install a tricky video driver. You can boot back to your original working environment if you need to, and it only takes as much disk space as the changes that were introduced.
Dataset
A dataset is a ZFS pool, file system, snapshot, volume, and clone. It is the layer of ZFS where data can be stored and retrieved.
Volume
A volume is a file system that emulates the block device. It cannot be used as a typical ZFS file system. For all intents and purposes, it behaves like a disk device. One of its uses is to export it through iSCSI or FCoE protocols, to be mounted as LUNs on a remote server and then used as disks.
Note
Personally, volumes are my least favorite use of ZFS. Many of the features I like most about ZFS have limited or no use for volumes. If you use volumes and snapshot them, you cannot easily mount them locally for file retrieval, as you would when using a simple ZFS file system.
Resilvering
Resilvering is the process of rebuilding redundant groups after disk replacement. There are many reasons you may want to replace a disk—perhaps the drive becomes faulted, or you decide to swap the disk for any other reason—once the new drive is added to the pool, ZFS will start to restore data to it. This is a very obvious advantage of ZFS over traditional RAIDs. Only data is being resilvered, not whole disks.
Note
Resilvering is a low-priority operating system process. On a very busy storage system, it will take more time.
Pool Layout Explained
Pool Layout is the way that disks are grouped into vdevs and vdevs are grouped together into the ZFS pool.
Assume that we have a pool consisting of six disks, all of them in RAIDZ-2 configuration (rough equivalent of RAID-6). Four disks contain data and two contain parity data. Resiliency of the pool allows for losing up to two disks. Any number above that will irreversibly destroy the file system and result in the need for backups.
Figure 1-6 presents the pool. While it is technically possible to create a new vdev of fewer or larger number of disks, with different sizes, it will almost surely result in performance issues.
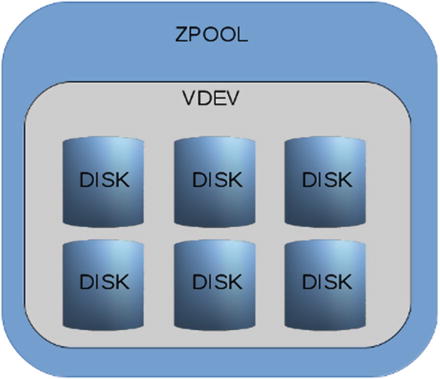
Figure 1-6 Single vdev RAIDZ-2 pool
And remember—you cannot remove disks from a pool once the vdevs are added. If you suddenly add a new vdev, say, four disks RAIDZ, as in Figure 1-7, you compromise pool integrity by introducing a vdev with lower resiliency. You will also introduce performance issues.
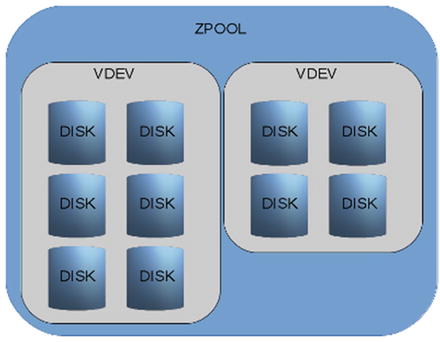
Figure 1-7 Wrongly enhanced pool
The one exception of “cannot change the redundancy level” rule is single disk to mirrored and mirrored to even more mirrored. You can attach a disk to a single disk vdev, and that will result in a mirrored vdev (see Figure 1-8). You can also attach a disk to a two-way mirror, creating a triple-mirror (see Figure 1-9).

Figure 1-8 Single vdev turned into a mirror
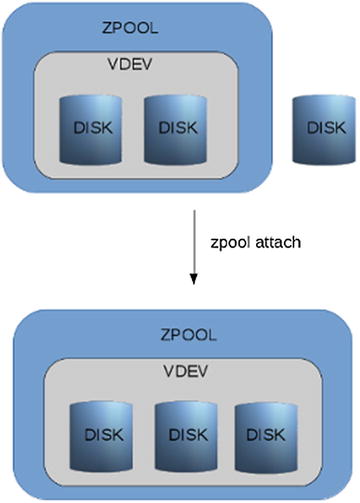
Figure 1-9 Two way mirror into a three-way mirror
Common Tuning Options
A lot of tutorials tell you to set two options (one pool level and one file system level) that are supposed to increase the speed. Unfortunately, most of them don’t explain what they do and why they should work: ashift=12 and atime= off.
While the truth is, they may offer a significant performance increase, setting them blindly is a major error. As stated previously, to properly administer your storage server, you need to understand why you use options that are offered.
ashift
The ashift option allows you to set up a physical block layout on disks. As disk capacities kept growing, at some point keeping the original block size of 512 bytes became impractical and disk vendors changed it to 4096 bytes. But for backward compatibility reasons, disks sometimes still advertise 512 block sizes. This can have an adverse effect on pool performance. The ashift option was introduced in ZFS to allow manual change of block sizing done by ZFS. Since it’s specified as a binary shift, the value is a power, thus: 2^12 = 4096. Omitting the ashift option allows ZFS to detect the value (the disk can lie about it); using value of 9 will set the block size to 512. The new disk block size is called Advanced Layout (AL).
The ashift option can only be used during pool setup or when adding a new device to a vdev. Which brings up another issue: if you create a pool by setting up ashift and later add a disk but don’t set it, your performance may go awry due to the mismatched ashift parameters. If you know you used the option or are unsure, always check before adding new devices:
trochej@madchamber:~$ sudo zpool listNAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOTdata 2,72T 133G 2,59T - 3% 4% 1.00x ONLINE -trochej@madchamber:~$ sudo zpool get all dataNAME PROPERTY VALUE SOURCEdata size 2,72T -data capacity 4% -data altroot - defaultdata health ONLINE -data guid 7057182016879104894 defaultdata version - defaultdata bootfs - defaultdata delegation on defaultdata autoreplace off defaultdata cachefile - defaultdata failmode wait defaultdata listsnapshots off defaultdata autoexpand off defaultdata dedupditto 0 defaultdata dedupratio 1.00x -data free 2,59T -data allocated 133G -data readonly off -data ashift 0 defaultdata comment - defaultdata expandsize - -data freeing 0 defaultdata fragmentation 3% -data leaked 0 defaultdata feature@async_destroy enabled localdata feature@empty_bpobj active localdata feature@lz4_compress active localdata feature@spacemap_histogram active localdata feature@enabled_txg active localdata feature@hole_birth active localdata feature@extensible_dataset enabled localdata feature@embedded_data active localdata feature@bookmarks enabled local
As you may have noticed, I let ZFS auto-detect the value.
smartctl
If you are unsure about the AL status for your drives, use the smartctl command:
[trochej@madtower sohozfs]$ sudo smartctl -a /dev/sdasmartctl 6.4 2015-06-04 r4109 [x86_64-linux-4.4.0] (local build)Copyright (C) 2002-15, Bruce Allen, Christian Franke,www.smartmontools.org=== START OF INFORMATION SECTION ===Model Family: Seagate Laptop SSHDDevice Model: ST500LM000-1EJ162Serial Number: W7622ZRQLU WWN Device Id: 5 000c50 07c920424Firmware Version: DEM9User Capacity: 500,107,862,016 bytes [500 GB]Sector Sizes: 512 bytes logical, 4096 bytes physicalRotation Rate: 5400 rpmForm Factor: 2.5 inchesDevice is: In smartctl database [for details use: -P show]ATA Version is: ACS-2, ACS-3 T13/2161-D revision 3bSATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)Local Time is: Fri Feb 12 22:11:18 2016 CETSMART support is: Available - device has SMART capability.SMART support is: Enabled
You will notice that my drive has the line:
Sector Sizes: 512 bytes logical, 4096 bytes physical It tells us that drive has a physical layout of 4096 bytes, but the driver advertises 512 bytes for backward compatibility .
Deduplication
As a rule of thumb, don’t dedupe. Just don’t. If you really need to watch out for disk space, use other ways of increasing capacity. Several of my past customers got into very big trouble using deduplication.
ZFS has an interesting option that spurred quite lot of interest when it was introduced. Turning deduplication on tells ZFS to keep track of data blocks. Whenever data is written to disks, ZFS will compare it with the blocks already in the file system and if finds any block identical, it will not write physical data, but will add some meta-information and thus save lots and lots of disk space.
While the feature seems great in theory, in practice it turns out to be rather tricky to use smartly. First of all, deduplication comes at a cost and it’s a cost in RAM and CPU power. For each data block that is being deduplicated, your system will add an entry to DDT (deduplication tables) that exist in your RAM. Ironically, for ideally deduplicating data, the result of DDT in RAM was that the system ground to a halt by lack of memory and CPU power for operating system functions.
It is not to say deduplication is without uses. Before you set it though, you should research how well your data would deduplicate. I can envision storage for backups that would conserve space by use of deduplication. In such a case though the size of DDT, free RAM amount and CPU utilization must be observed to avoid problems.
The catch is, DDT are persistent. You can, at any moment, disable deduplication, but once deduplicated data stays deduplicated and if you run into system stability issues due to it, disabling and rebooting won’t help. On the next pool import (mount), DDT will be loaded into RAM again. There are two ways to get rid of this data: destroy the pool, create it anew, and restore the data or disable deduplication, or move data on the pool so it gets undeduplicated on the next writes. Both options take time, depending on the size of your data. While deduplication may save disk space, research it carefully.
The deduplication ratio is by default displayed using the zpool list command. A ratio of 1.00 means no deduplication happened:
trochej@madchamber:~$ sudo zpool listNAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOTdata 2,72T 133G 2,59T - 3% 4% 1.00x ONLINE -
You can check the deduplication setting by querying your file system’s deduplication property:
trochej@madchamber:~$ sudo zfs get dedup data/datafsNAME PROPERTY VALUE SOURCEdata/datafs dedup off default
Deduplication is a setting set per file system .
Compression
An option that saves disk space and adds speed is compression. There are several compression algorithms available for use by ZFS. Basically, you can tell the file system to compress any block of data it will write to disk. With modern CPUs, you can usually add some speed by writing smaller physical data. Your processors should be able to cope with packing and unpacking data on the fly. The exception can be data that compress badly, such as MP3s, JPGs, or video file. Textual data (application logs, etc.) usually plays well with this option. For personal use, I always turn it on. The default compression algorithm for ZFS is lzjb.
The compression can be set by on a file system basis:
trochej@madchamber:~$ sudo zfs get compression data/datafsNAME PROPERTY VALUE SOURCEdata/datafs compression on localtrochej@madchamber:~$ sudo zfs set compression=on data/datafs
The compression ratio can be determined by querying a property:
trochej@madchamber:~$ sudo zfs get compressratio data/datafsNAME PROPERTY VALUE SOURCEdata/datafs compressratio 1.26x
Several compression algorithms are available. Until recently, if you simply turned compression on, the lzjb algorithm was used. It is considered a good compromise between performance and compression. Other compression algorithms available are listed on the zfs man page. A new algorithm added recently is lz4. It has better performance and a higher compression ratio than lzjb. It can only be enabled for pools that have the feature@lz4_compress feature flag property :
trochej@madchamber:~$ sudo zpool get feature@lz4_compress dataNAME PROPERTY VALUE SOURCEdata feature@lz4_compress active local
If the feature is enabled, you can set compression=lz4 for any given dataset. You can enable it by invoking this command:
trochej@madchamber:~$ sudo zpool set feature@lz4_compress=enabled datalz4 has been the default compression algorithm for some time now.
ZFS Pool State
If you look again at the listing of my pool:
trochej@madchamber:~$ sudo zpool listNAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOTdata 2,72T 133G 2,59T - 3% 4% 1.00x ONLINE -
You will notice a column called HEALTH. This is a status of the ZFS pool. There are several other indicators that you can see here:
ONLINE: The pool is healthy (there are no errors detected) and it is imported (mounted in traditional file systems jargon) and ready to use. It doesn’t mean it’s perfectly okay. ZFS will keep a pool marked online even if some small number of I/O errors or correctable data errors occur. You should monitor other indicators as well such as disk health (hdparm, smartctl, and lsiutil for LSI SAS controllers).
DEGRADED: Probably only applicable to redundant sets, where disks in mirror or RAIDZ or RAIDZ-2 pools have been lost. The pool may have become non-redundant. Losing more disks may render it corrupt. Bear in mind that in triple-mirror or RAIDZ-2, losing one disk doesn’t render a pool non-redundant.
FAULTED: A disk or a vdev is inaccessible. It means that ZFS cannot read or write to it. In redundant configurations, a disk may be FAULTED but its vdev may be DEGRADED and still accessible. This may happen if in the mirrored set, one disk is lost. If you lose a top-level vdev, i.e., both disks in a mirror, your whole pool will be inaccessible and will become corrupt. Since there is no way to restore a file system, your options at this stage are to recreate the pool with healthy disks and restore it from backups or seek ZFS data recovery experts. The latter is usually a costly option.
OFFLINE: A device has been disabled (taken offline) by the administrator. Reasons may vary, but it need not mean the disk is faulty.
UNAVAIL: The disk or vdev cannot be opened. Effectively ZFS cannot read or write to it. You may notice it sounds very similar to FAULTED state. The difference is mainly that in the FAULTED state, the device has displayed number of errors before being marked as FAULTED by ZFS. With UNAVAIL, the system cannot talk to the device; possibly it went totally dead or the power supply is too weak to power all of your disks. The last scenario is something to keep in mind, especially on commodity hardware. I’ve run into dissapearing disks more than once, just to figure out that the PSU was too weak.
REMOVED: If your hardware supports it, when a disk is physically removed without first removing it from the pool using the zpool command, it will be marked as REMOVED.
You can check pool health explicitly using the zpool status and zpool status -x commands:
trochej@madchamber:~$ sudo zpool status -xall pools are healthytrochej@madchamber:~$ sudo zpool statuspool: datastate: ONLINEscan: none requestedconfig:NAME STATE READ WRITE CKSUMdata ONLINE 0 0 0sdb ONLINE 0 0 0errors: No known data errors
zpool status will print detailed health and configuration of all the pool devices. When the pool consists of hundreds of disks, it may be troublesome to fish out a faulty device. To that end, you can use zpool status -x, which will print only the status of the pools that experienced issues.
trochej@madchamber:~$ sudo zpool status -xpool: datastate: DEGRADEDstatus: One or more devices has been taken offline by the administrator.Sufficient replicas exist for the pool to continue functioning in a degraded state.action: Online the device using 'zpool online' or replace the device with 'zpool replace'.scrub: resilver completed after 0h0m with 0 errors on Wed Feb 10 15:15:09 2016config:NAME STATE READ WRITE CKSUMdata ONLINE 0 0 0mirror-0 DEGRADED 0 0 0sdb ONLINE 0 0 0sdc OFFLINE 0 0 0 48K resilverederrors: No known data errors
ZFS Version
ZFS was designed to incrementally introduce new features. As part of that mechanism, the ZFS versions have been introduced by a single number. Tracking that number, the system operator can determine if their pool uses the latest ZFS version, including new features and bug fixes. Upgrades are done in-place and do not require any downtime.
That philosophy was functioning quite well when ZFS was developed solely by Sun Microsystems. With the advent of the OpenZFS community—gathering developers from illumos, Linux, OSX, and FreeBSD worlds—it soon became obvious that it would be difficult if not impossible to agree with every on-disk format change across the whole community. Thus, the version number stayed at the latest that was ever released as open source from Oracle Corp: 28. From that point, pluggable architecture of “features flags” was introduced. ZFS implementations are compatible if they implement the same set of feature flags.
If you look again at the zpool command output for my host:
trochej@madchamber:~$ sudo zpool get all dataNAME PROPERTY VALUE SOURCEdata size 2,72T -data capacity 4% -data altroot - defaultdata health ONLINE -data guid 7057182016879104894 defaultdata version - defaultdata bootfs - defaultdata delegation on defaultdata autoreplace off defaultdata cachefile - defaultdata failmode wait defaultdata listsnapshots off defaultdata autoexpand off defaultdata dedupditto 0 defaultdata dedupratio 1.00x -data free 2,59T -data allocated 133G -data readonly off -data ashift 0 defaultdata comment - defaultdata expandsize - -data freeing 0 defaultdata fragmentation 3% -data leaked 0 defaultdata feature@async_destroy enabled localdata feature@empty_bpobj active localdata feature@lz4_compress active localdata feature@spacemap_histogram active localdata feature@enabled_txg active localdata feature@hole_birth active localdata feature@extensible_dataset enabled localdata feature@embedded_data active localdata feature@bookmarks enabled local
You will notice that last few properties start with the feature@ string. That’s the feature flags you need to look for. The find out the all supported versions and feature flags, run the sudo zfs upgrade -v and sudo zpool upgrade -v commands, as shown in the following examples :
trochej@madchamber:~$ sudo zfs upgrade -vThe following file system versions are supported:VER DESCRIPTION--- --------------------------------------------------------1 Initial ZFS file system version2 Enhanced directory entries3 Case insensitive and file system user identifier (FUID)4 userquota, groupquota properties5 System attributesFor more information on a particular version, including supportedreleases, see the ZFS Administration Guide.trochej@madchamber:~$ sudo zpool upgrade -vThis system supports ZFS pool feature flags.The following features are supported:FEAT DESCRIPTION-------------------------------------------------------------async_destroy (read-only compatible)Destroy file systems asynchronously.empty_bpobj (read-only compatible)Snapshots use less space.lz4_compressLZ4 compression algorithm support.spacemap_histogram (read-only compatible)Spacemaps maintain space histograms.enabled_txg (read-only compatible)Record txg at which a feature is enabledhole_birthRetain hole birth txg for more precise zfs sendextensible_datasetEnhanced dataset functionality, used by other features.embedded_dataBlocks which compress very well use even less space.bookmarks (read-only compatible)"zfs bookmark" commandThe following legacy versions are also supported:VER DESCRIPTION--- --------------------------------------------------------1 Initial ZFS version2 Ditto blocks (replicated metadata)3 Hot spares and double parity RAID-Z4 zpool history5 Compression using the gzip algorithm6 bootfs pool property7 Separate intent log devices8 Delegated administration9 refquota and refreservation properties10 Cache devices11 Improved scrub performance12 Snapshot properties13 snapused property14 passthrough-x aclinherit15 user/group space accounting16 stmf property support17 Triple-parity RAID-Z18 Snapshot user holds19 Log device removal20 Compression using zle (zero-length encoding)21 Deduplication22 Received properties23 Slim ZIL24 System attributes25 Improved scrub stats26 Improved snapshot deletion performance27 Improved snapshot creation performance28 Multiple vdev replacementsFor more information on a particular version, includingsupported releases, see the ZFS Administration Guide.
Both commands print information on a maximum level of ZFS pool and file system versions and list the available feature flags .
You can check the current version of your pool and file systems using the zpool upgrade and zfs upgrade commands:
trochej@madchamber:~$ sudo zpool upgradeThis system supports ZFS pool feature flags.All pools are formatted using feature flags.Every feature flags pool has all supported features enabled.trochej@madchamber:~$ sudo zfs upgradeThis system is currently running ZFS file system version 5.All file systems are formatted with the current version.
Linux is a dominant operating system in the server area. ZFS is a very good file system for storage in most scenarios. Compared to traditional RAID and volume management solutions, it brings several advantages—simplicity of use, data healing capabilities, improved ability to migrate between operating systems, and many more. ZFS deals with virtual devices (vdevs). Virtual device can be either mapped directly to physical disk or to a grouping of other vdevs. A group of vdevs that serve as space for file systems is called a ZFS pool. The file systems within them are called file systems. ZFS file systems can be nested. Administrating the pool is done by the zpool command. Administration of file systems is done by the zfs command.