
Chapter 6. Batch Is a Special Case of Streaming
So far in this book, we have been talking about unbounded stream processing—that is, processing data from some time continuously and forever. This condition is depicted in Figure 6-1.
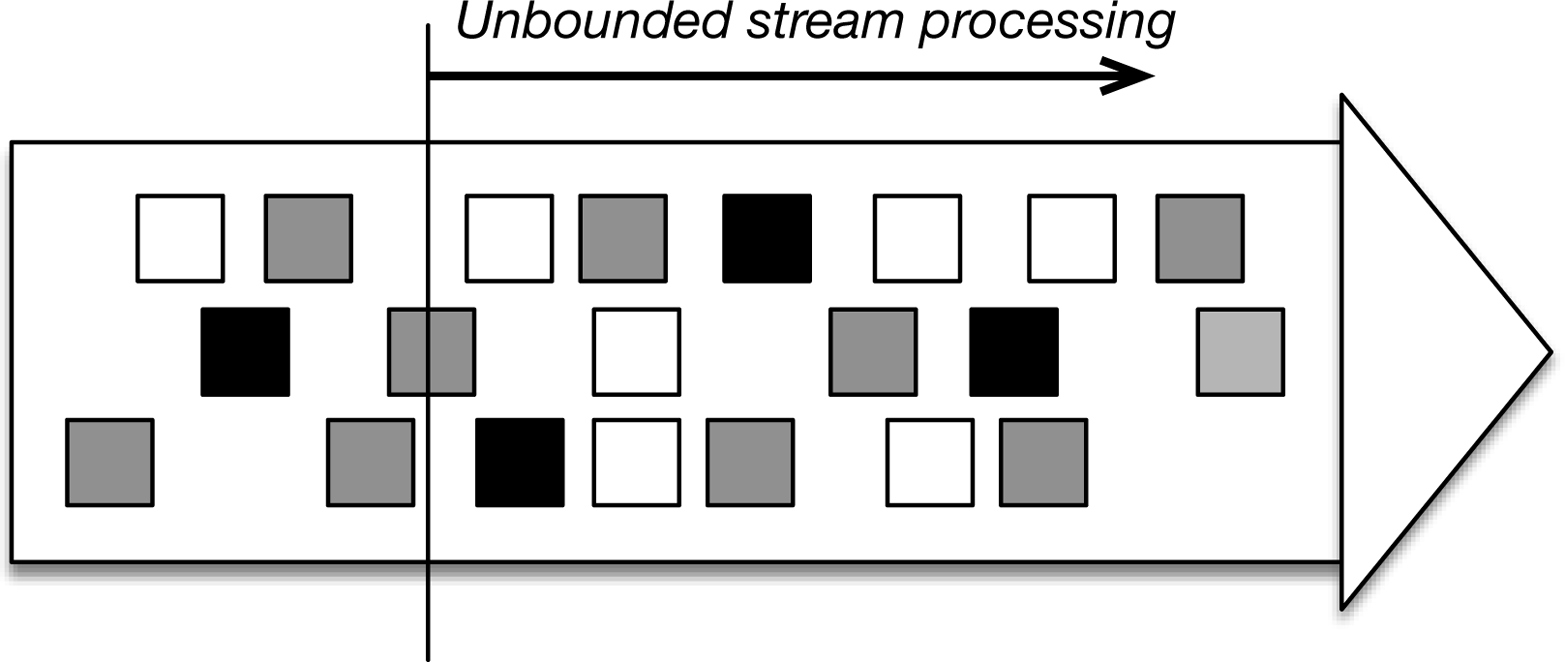
Figure 6-1. Unbounded stream processing: the input does not have an end, and data processing starts from the present or some point in the past and continues indefinitely.
A different style of processing is bounded stream processing, or processing data from some starting time until some end time, as depicted in Figure 6-2. The input data might be naturally bounded (meaning that it is a data set that does not grow over time), or it can be artificially bounded for analysis purposes (meaning that we are only interested in events within some time bounds).
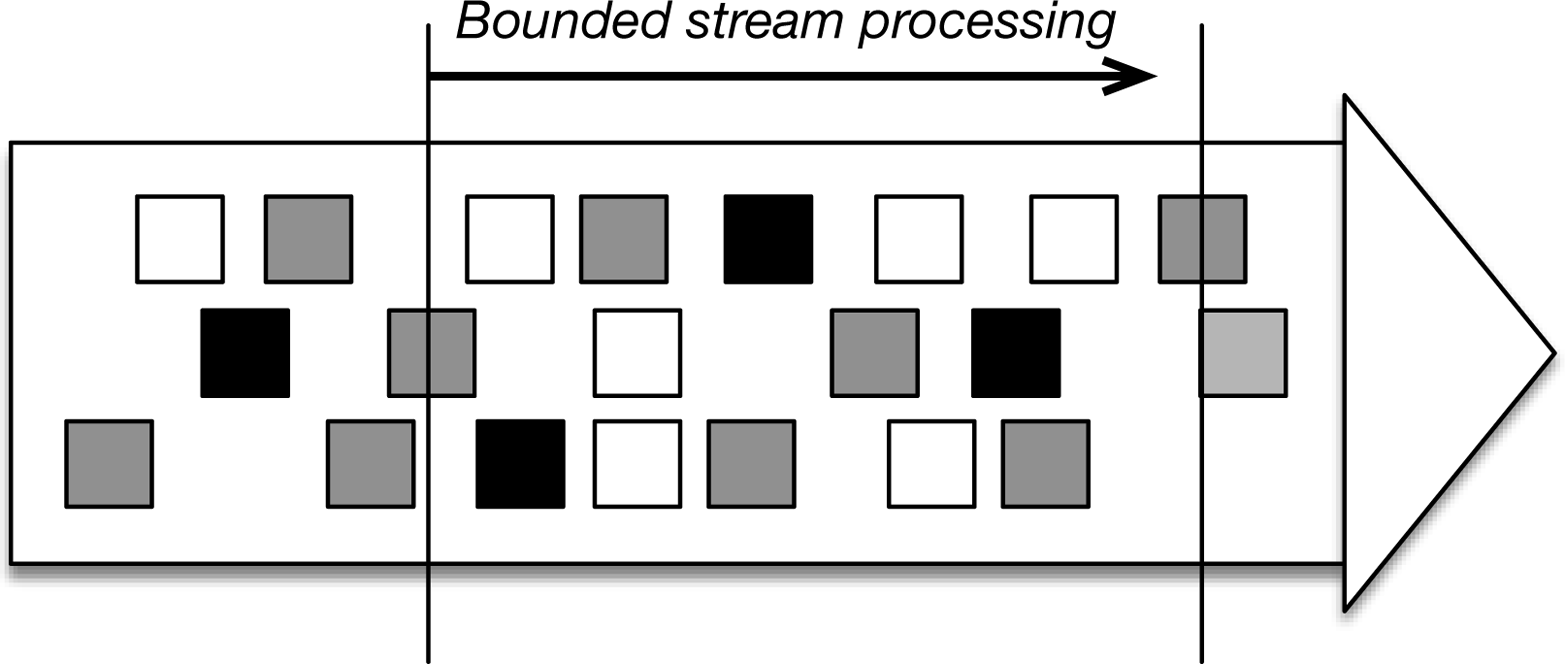
Figure 6-2. Bounded stream processing: the input has a beginning and an end, and data processing stops after some time.
Bounded stream processing is clearly a special case of unbounded stream processing; data processing just happens to stop at some point. In addition, when the results of the computation are not produced continuously during execution, but only once at the end, we have the case called batch processing (data is processed “as a batch”).
Batch processing is a very special case of stream processing; instead of defining a sliding or tumbling window over the data and producing results every time the window slides, we define a global window, with all records belonging to the same window. For example, a simple Flink program that counts visitors in a website every hour, grouped by region continuously, is the following:
val counts = visits
.keyBy("region")
.timeWindow(Time.hours(1))
.sum("visits")
If we know that our input data set was already bounded, we can get the equivalent “batch” program by writing:
val counts = visits
.keyBy("region")
.window(GlobalWindows.create)
.trigger(EndOfTimeTrigger.create)
.sum("visits")
Flink is unusual in that it can process data as a continuous stream or as bounded streams (batch). With Flink, you process bounded data streams also by using Flink’s DataSet API, which is made for exactly that purpose. The above program in Flink’s DataSet API would look like this:
val counts = visits
.groupBy("region")
.sum("visits")
This program will produce the same results when we know that the input is bounded, but it looks friendlier to a programmer accustomed to using batch processors.
Batch Processing Technology
In principle, batch processing is a special case of stream processing: when the input is bounded and we want only the final result at the end, it suffices to define a global window over the complete data set and perform the computation on that window. But how efficient is it?
Traditionally, dedicated batch processors are used to process bounded data streams, and there are cases where this approach is more efficient than using the stream processor naively as described above. However, it is possible to integrate most optimizations necessary for efficient large-scale batch processing in a stream processor. This approach is what Flink does, and it works very efficiently (as shown in Figure 6-3).
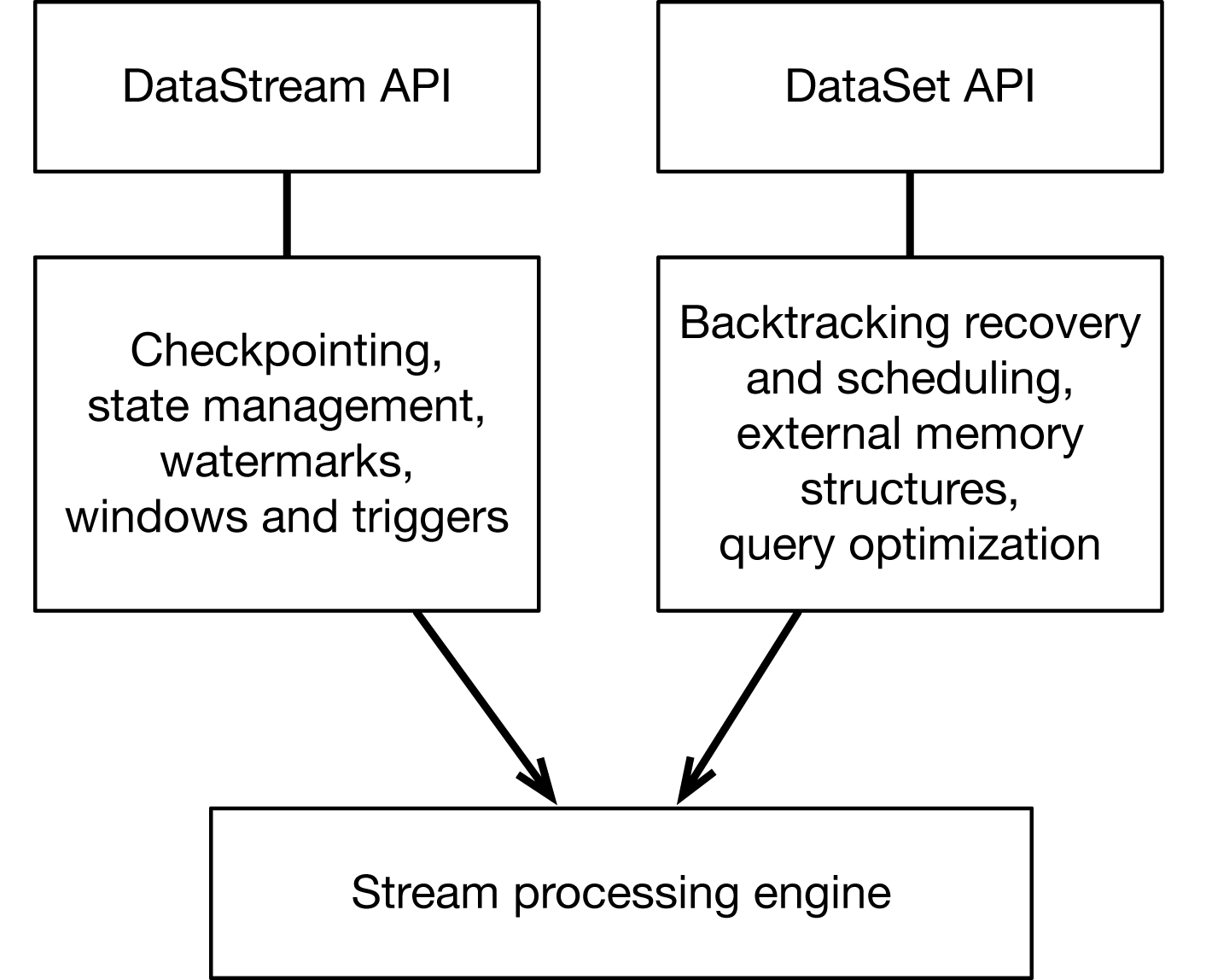
Figure 6-3. Flink’s architecture supports both stream and batch processing styles, with one underlying engine.
The same backend (the stream processing engine) is used for both bounded and unbounded data processing. On top of the stream processing engine, Flink overlays the following mechanisms:
A checkpointing mechanism and state mechanism to ensure fault-tolerant, stateful processing
The watermark mechanism to ensure event-time clock
Available windows and triggers to bound the computation and define when to make results available
A different code path in Flink overlays different mechanisms on top of the same stream processing engine to ensure efficient batch processing. Although reviewing these in detail are beyond the scope of this book, the most important mechanisms are:
Backtracking for scheduling and recovery: the mechanism introduced by Microsoft Dryad and now used by almost every batch processor
Special memory data structures for hashing and sorting that can partially spill data from memory to disk when needed
An optimizer that tries to transform the user program to an equivalent one that minimizes the time to result
At the time of writing, these two code paths result in two different APIs (the DataStream API and the DataSet API), and one cannot create a Flink job that mixes the two and takes advantage of all of Flink’s capabilities. However, this need not be the case; in fact, the Flink community is discussing a unified API that includes the capabilities of both APIs. And the Apache Beam (incubating) community has created exactly that: an API for both batch and stream processing that generates Flink programs for execution.
Case Study: Flink as a Batch Processor
At the Flink Forward 2015 conference, Dongwon Kim (then a postdoctoral researcher at POSTECH in South Korea) presented a benchmarking study that he conducted comparing MapReduce, Tez, Spark, and Flink at pure batch processing tasks: TeraSort and a distributed hash join.1
The first task, TeraSort, comes from the annual terabyte sort competition, which measures the elapsed time to sort 1 terabyte of data. In the context of these systems, TeraSort is essentially a distributed sort problem, consisting of the following phases, depicted in Figure 6-4:
A read phase reads the data partitions from files on HDFS
A local sort partially sorts these partitions
A shuffle phase redistributes the data by key to the processing nodes
A final sort phase produces the sorted output
A write phase writes out the sorted partitions to files on HDFS
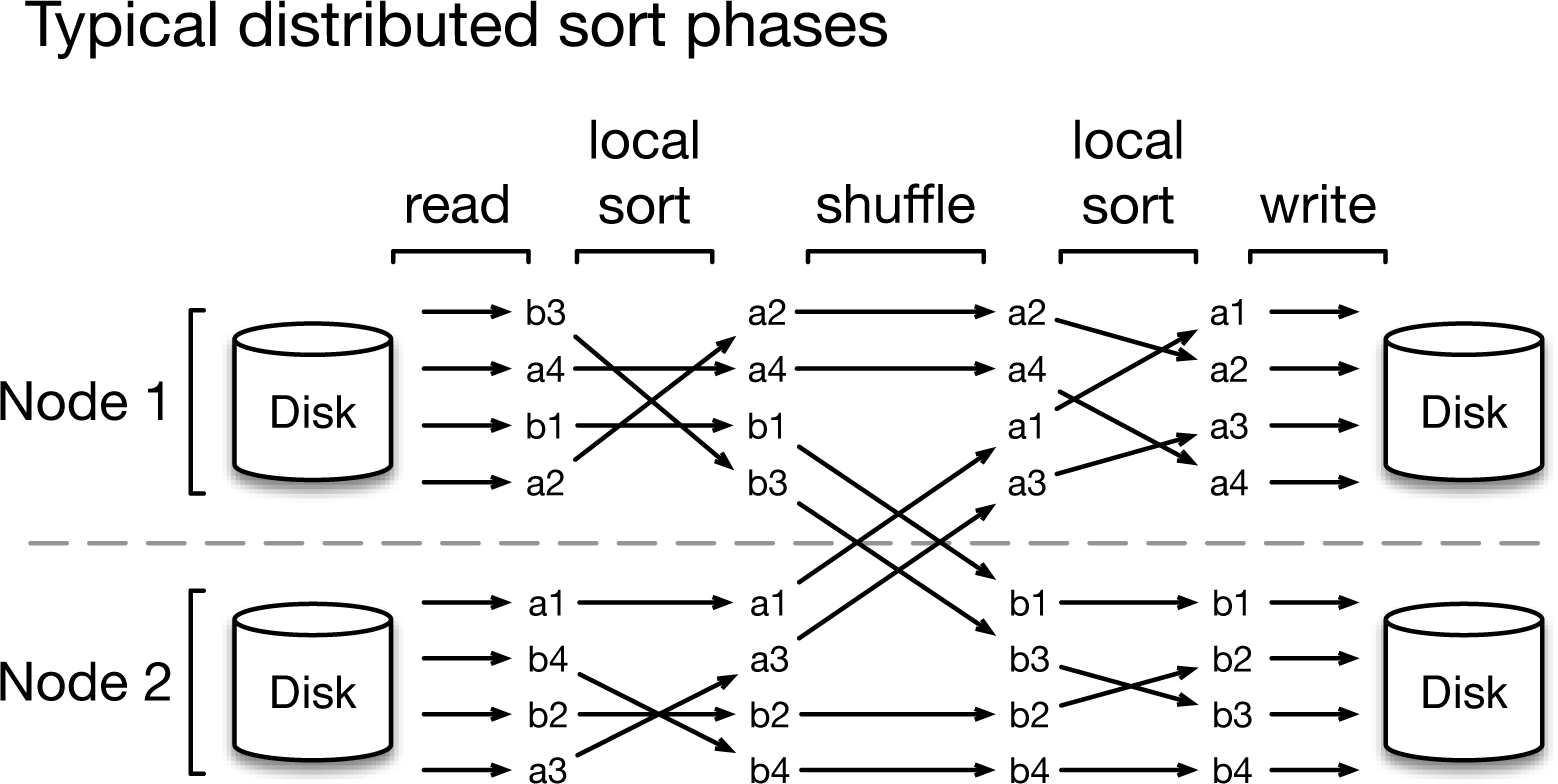
Figure 6-4. Processing phases for distributed sort.
A TeraSort implementation is included with the Apache Hadoop distribution, and you can use the same implementation unchanged with Apache Tez, given that Tez can execute programs written in the MapReduce API. The Spark and Flink implementations were provided by the author of that presentation and are available at https://github.com/eastcirclek/terasort. The cluster that was used for the measurements consisted of 42 machines with 12 cores, 24 GB of memory, and 6 hard disk drives each.
The results of the benchmark, depicted in Figure 6-5, show that Flink performs the sorting task in less time than all other systems. MapReduce took 2,157 seconds, Tez took 1,887 seconds, Spark took 2,171 seconds, and Flink took 1,480 seconds.
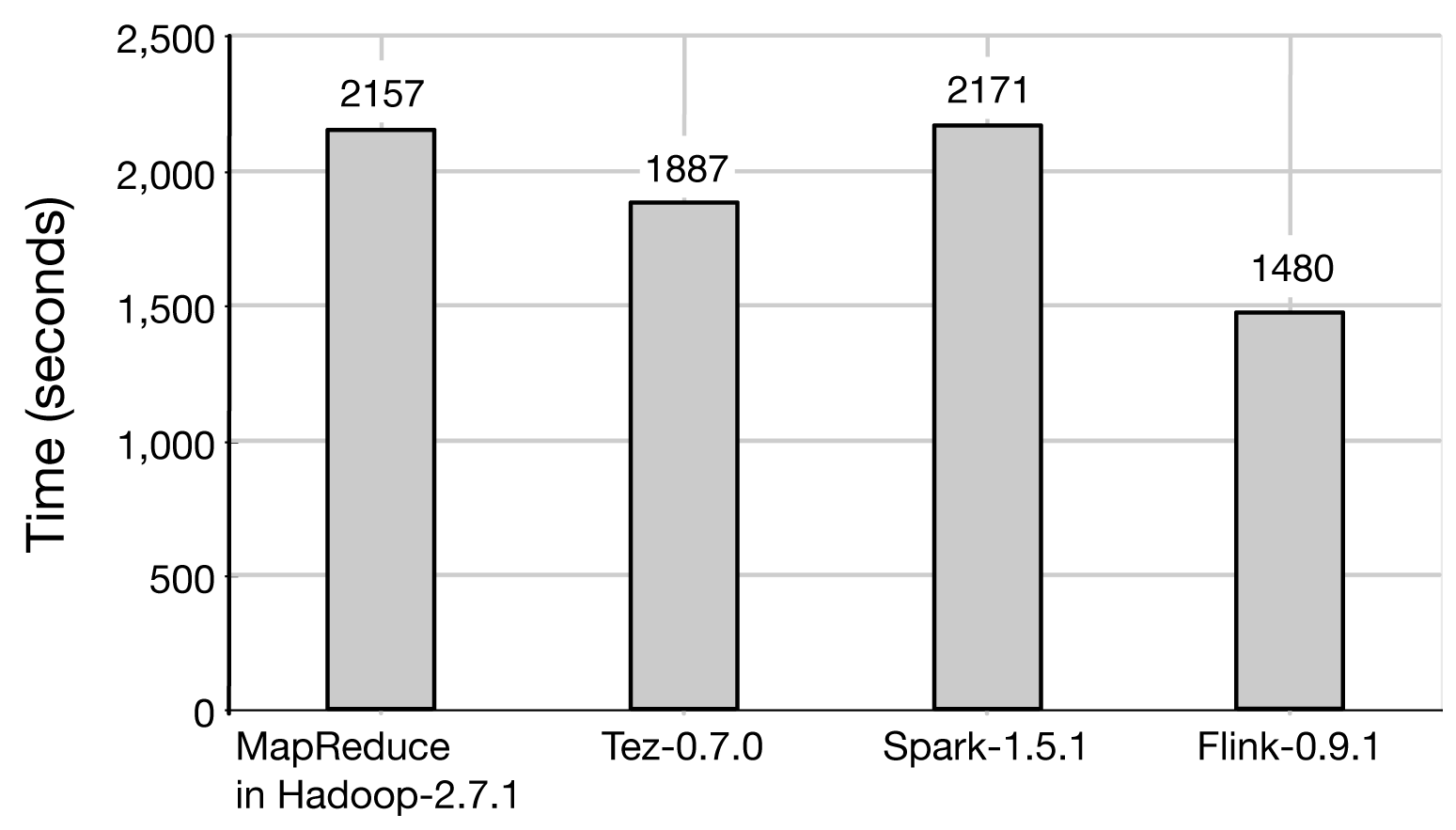
Figure 6-5. TeraSort results for MapReduce, Tez, Spark, and Flink.
The second task was a distributed join between a large (240 GB) and a small (256 MB) data set. There, Flink was also the fastest system, outperforming Tez by 2x and Spark by 4x. These results are shown in Figure 6-6.
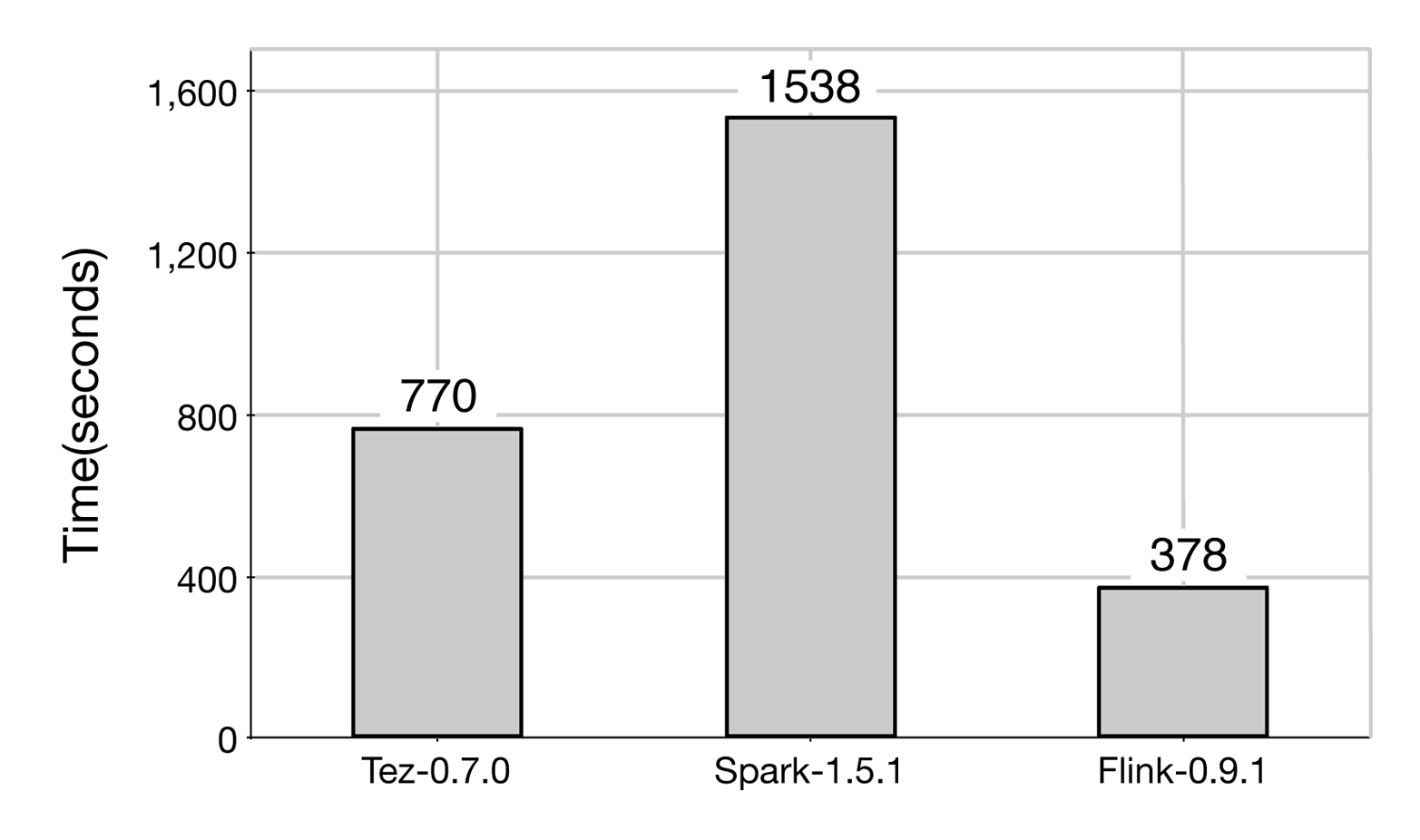
Figure 6-6. HashJoin results for Tez, Spark, and Flink.
The overall reason for these results is that Flink execution is stream-based, which means that the processing stages that we described above overlap more, and shuffling is pipelined, which leads to much fewer disk accesses. In contrast, execution with MapReduce, Tez, and Spark is batch-based, which means that data is written to disk before it’s sent over the network. In the end, this means less idle time and fewer disk accesses when using Flink.
We note that as with all benchmarks, the raw numbers might be quite different in different cluster setups, configurations, and software versions. While the numbers themselves might be different now compared to when that benchmark was conducted (indeed, the software versions used for that benchmark were Hadoop 2.7.1, Tez 0.7.0, Spark 1.5.1, and Flink 0.9.1, which have all been superseded with newer releases), the main point is that with the right optimizations, a stream processor (Flink) can perform equally as well as, or better than, even batch processors (MapReduce, Tez, Spark) in tasks that are on the home turf of batch processors. Consequently, with Flink, it is possible to cover processing of both unbounded data streams and bounded data streams with one data processing framework without sacrificing performance.
1 See the slides and video of the talk at http://2015.flink-forward.org/?session=a-comparative-performance-evaluation-of-flink.