
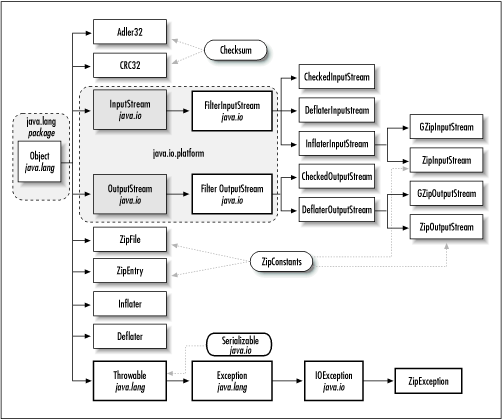
The java.util.zip package, shown in Figure 9.1, contains six stream classes and another half
dozen assorted classes that read and write data in zip, gzip, and
inflate/deflate formats. Java uses these classes to read and write
JAR archives and to display PNG images. You can use the
java.util.zip classes as general utilities for
general-purpose compression and decompression. Among other things,
these classes make it trivial to write a simple file
compression or
decompression program.
The
java.util.zip.Deflater
and
java.util.zip.Inflater
classes provide compression and
decompression services for all other classes. They are Java’s
compression and decompression engines. These classes support several
related compression
formats,
including zlib, deflate, and gzip. These formats are documented in
RFCs 1950, 1951, and 1952. (See ftp://ftp.uu.net/graphics/png/documents/zlib/zdoc-index.html)
They all use the Lempel-Ziv 1977 (LZ77) compression
algorithm (named after the inventors, Jakob Ziv and Abraham Lempel),
though each has a different way of storing metadata that describes an
archive’s contents. Since compression and decompression are
extremely CPU-intensive operations, for the most part these classes
are Java wrappers around native methods written in C. More precisely,
these are wrappers around the zlib compression library written
by Jean-Loup Gailly and Mark Adler. According to Greg Roelofs,
writing on the zlib web page at http://www.cdrom.com/pub/infozip/zlib/,
“zlib is designed to be a free, general-purpose, legally
unencumbered—that is, not covered by any patents—lossless
data-compression library for use on virtually any computer hardware
and operating system.”
Without going into excessive detail, zip, gzip, and zlib all compress data in more or less the same way. Repeated bit sequences in the input data are replaced with pointers back to the first occurrence of that bit sequence. Other tricks are used, but this is basically how these compression schemes work and has certain implications for compression and decompression code. First, you can’t randomly access data in a compressed file. To decompress the nth byte of data, you must first decompress bytes 1 through n-1 of the data. Second, a single twiddled bit doesn’t just change the meaning of the byte it’s part of. It also changes the meaning of bytes that come after it in the data, since subsequent bytes may be stored as copies of the previous bytes. Therefore, compressed files are much more susceptible to corruption than uncompressed files. For more general information about compression and archiving algorithms and formats, the comp.compression FAQ is a good place to start. See http://www.faqs.org/faqs/compression-faq/part1/preamble.html.
The Deflater
class
contains methods to compress blocks of data. You can choose the
compression format, the level of compression, and the compression
strategy. There are nine steps to deflating data with the
Deflater class:
Construct a
Deflaterobject.Choose the strategy (optional).
Set the compression level (optional).
Preset the dictionary (optional).
Set the input.
Deflate the data repeatedly until
needsInput()returnstrue.If more input is available, go back to step 5 to provide additional input data. Otherwise, go to step 8.
Finish the data.
If there are more streams to be deflated, reset the deflater.
More often than not, you don’t use this class directly.
Instead, you use a Deflater object indirectly
through one of the compressing stream classes like
DeflaterInputStream or
DeflaterOutputStream. These classes provide more
convenient programmer interfaces for stream-oriented compression than
the raw Deflater methods.
There are three Deflater() constructors:
public Deflater(int level, boolean useGzip) public Deflater(int level) public Deflater()
The most general constructor allows you to set the level of
compression and the format used. Compression level is specified as an
int between
and 9.
is no compression; 9 is maximum compression. Generally, the higher
the compression level, the smaller the output will be and the longer
the compression will take. Four mnemonic constants are available to
select particular levels of compression. These are:
public static final int NO_COMPRESSION = 0; public static final int BEST_SPEED = 1; public static final int BEST_COMPRESSION = 9; public static final int DEFAULT_COMPRESSION = -1;
If useGzip is true, then gzip
compression format is used. Otherwise, the zlib compression format is
used. (zlib format is the default.) These formats are essentially the
same except that zlib includes some extra header and checksum fields.
In Java 1.1 and 2 the Deflater class only supports
a single compression method, deflation. This one method is used by
zip, gzip, and zlib. This is represented by the mnemonic constant
Deflater.DEFLATED:
public static final int DEFLATED = 8;
Other methods exist and may be added in the future, such as LZ78
dictionary-based compression, arithmetic compression, wavelet
compression, fractal compression, and many more. The design of the
java.util.zip package does not allow you to
install third-party compression engines easily. Therefore, classes to
support these new methods must come from Sun.[7] In the next chapter,
you’ll see the Java Cryptography Extension (JCE), which is
designed along similar lines. However, because outdated laws prevent
Sun from including strong cryptography in the core API, the JCE
allows you to plug in third-party engines that support a wide variety
of encryption methods.
The first step is to choose the strategy. Java 1.1 supports three
strategies: filtered, Huffman, and default. These are represented by
the mnemonic constants Deflater.FILTERED,
Deflater.HUFFMAN_ONLY, and
Deflater.DEFAULT_STRATEGY, respectively. The
setStrategy() method chooses one of these
strategies.
public static final int DEFAULT_STRATEGY = 0; public static final int FILTERED = 1; public static final int HUFFMAN_ONLY = 2; public synchronized void setStrategy(int strategy)
This method throws an IllegalArgumentException if
an unrecognized strategy is passed as an argument. If no strategy is
chosen explicitly, then the default strategy is used. The default
strategy works well for most data you’re likely to encounter.
It concentrates primarily on emitting pointers to previously seen
data, so it works well in data where runs of bytes tend to repeat
themselves. In certain kinds of files where long runs of bytes are
uncommon, but where the distribution of bytes is uneven, you may be
better off with pure Huffman coding. Huffman coding simply uses fewer
bits for more common characters like “e” and more bits
for less common characters like “q.” A third situation,
common in some binary files, is where all bytes are more or less
equally likely. When dealing with these sorts of files, the filtered
strategy provides a good compromise with some Huffman coding and some
matching of data to previously seen values. Most of the time, the
default strategy will do the best job, and even if it doesn’t,
it will compress within a few percent of the optimal strategy, so
it’s rarely worth agonizing over which is the best solution.
The deflater compresses by trying to match the data it’s
looking at now to data it’s already seen earlier in the stream.
The compression level determines how far
back in the stream the deflater looks for a match. The farther back
it looks, the more likely it is to find a match and the larger the
run of bytes it can replace with a simple pointer. However, the
farther back it looks, the longer it takes as well. Thus, compression
level is a trade-off between speed and file size. The tighter you
compress, the more time it takes. Generally, the compression level is
set in the constructor, but you can change it after the deflater is
constructed by using the setLevel() method:
public synchronized void setLevel(int Level)
As with the Deflater() constructors, the
compression level should be an int between
and 9 (no compression to maximum compression) or perhaps -1,
signifying the default compression level. Any other value will cause
an IllegalArgumentException. It’s good
coding style to use one of the mnemonic constants
Deflater.NO_COMPRESSION (0),
Deflater.BEST_SPEED (1),
Deflater.BEST_COMPRESSION (9), or
Deflater.DEFAULT_COMPRESSION (-1) instead of an explicit
value.
In limited testing with small files, I haven’t found the difference between best speed and best compression to be noticeable, either in file size or the time it takes to compress or decompress. You may occasionally want to set the level to no compression (0) if you’re deflating already compressed files like GIF, JPEG, or PNG images before storing them in an archive. These file formats have built-in compression algorithms specifically designed for the type of data they contain, and the general-purpose deflation algorithm provided here is unlikely to compress them further.[8] It may even increase their size.
You can think of the deflater as building a dictionary of phrases as it reads the text. The first time it sees a phrase, it puts the phrase in the dictionary. The second time it sees the phrase, it replaces the phrase with its position in the dictionary. However, it can’t do this until it’s seen the phrase at least once, so data early in the stream isn’t compressed very well compared to data that occurs later in the stream. On rare occasion, when you have a good idea that certain byte sequences appear in the data very frequently, you can preset the dictionary used for compression. You would fill the dictionary with the frequently repeated data in the text. For instance, if your text is composed completely of ASCII digits and assorted whitespace (tabs, carriage returns, and so forth) you could put those characters in your dictionary. This allows the early part of the stream to compress as well as later parts.
There are two
setDictionary()
methods. The first uses the entire
byte array passed as an argument as the dictionary. The second uses
the subarray of data starting at offset and
continuing for length bytes.
public void setDictionary(byte[] data) public native synchronized void setDictionary(byte[] data, int offset, int length)
Note
Presetting a dictionary is never necessary and requires detailed understanding of both the compression format used and the data to be compressed. Putting the wrong data in your dictionary can actually increase the file size. Unless you’re a compression expert and you really need every last byte of space you can save, I recommend letting the deflater build the dictionary adaptively as the data is compressed.
I started with a highly compressible 44,392-byte text file (the
output of running FileDumper2.java on itself in
decimal mode). Without presetting the dictionary, it deflated to
3,859 bytes. My first attempt to preset the dictionary to the ASCII
digits, space, and
actually increased that
size to 3,863 bytes. After carefully examining the data and
custom-designing a dictionary to fit it, I was able to deflate the
data to 3,852 bytes, saving a whopping 7 extra bytes or 0.18%. Of
course, the dictionary itself occupied 112 bytes, so it’s truly
arguable whether I really saved anything.
Exact details are likely to vary from file to file. The only real possible gain is for very short, very predictable files where zlib may not have enough data to build a good dictionary before the end of stream is reached. However, zlib uses a pretty good algorithm for building an adaptive dictionary, and you’re unlikely to do significantly better by hand. I recommend you not worry about setting a dictionary, and simply let the deflater build one for you.
If Inflater.inflate() decompresses the data later,
the Inflater.getAdler() method will return the
Adler-32 checksum of the dictionary needed for decompression.
However, you’ll need some other means to pass the dictionary
itself between the deflater and the inflater. It is not stored with
the deflated file.
Next you must set the input data to be deflated with one of the
setInput()
methods:
public void setInput(byte[] input) public synchronized void setInput(byte[] input, int offset, int length)
The first method prepares the entire array to be deflated. The second
method prepares the specified subarray of data starting at
offset and continuing for
length bytes.
Finally, you’re ready to deflate the data. Once
setInput() has filled the input buffer with data,
it is deflated through one of two deflate()
methods:
public int deflate(byte[] output) public native synchronized int deflate(byte[] output, int offset, int length)
The first method fills the specified output array
with the bytes of compressed data. The second fills the specified
subarray of output beginning at
offset and continuing for
length bytes with the compressed data. Both
methods return the actual number of compressed bytes written into the
array. You do not know in advance how many compressed bytes will
actually be written into output, because you do
not know how well the data will compress. You always have to check
the return value. If deflate() returns 0, you
should check needsInput() to see if you need to
call setInput() again to provide more uncompressed
input data:
public boolean needsInput()
When more data is needed, the
needsInput()
method returns
true. At this point you should invoke
setInput() again to feed in more uncompressed
input data, call deflate(), and repeat the process
until deflate() returns
and there is no more input data to be
compressed.
Finally, when the input data is exhausted, invoke
finish()
to
indicate that no more data is forthcoming and the deflater should
finish with the data it already has in its buffer:
public synchronized void finish()
The finished() method returns
true when the end of the compressed output has
been reached; that is, when all data stored in the input buffer has
been deflated:
public synchronized boolean finished()
After calling finish(), you invoke
deflate() repeatedly until
finished() returns true. This
flushes out any data that remains in the input buffer.
This completes the sequence of method invocations required to
compress data. If you’d like to use the same strategy,
compression level, and other settings to compress more data with the
same Deflater, call its reset()
method:
public native synchronized void reset()
Otherwise, call end() to throw away any
unprocessed input and free the resources used by the native code:
public native synchronized void end()
The finalize() method calls
end() before the deflater is garbage-collected, if
you forget:
protected void finalize()
Example 9.1 is a simple program that deflates files
named on the command line. First a Deflater
object, def, is created with the default strategy,
method, and compression level. A file input stream named
fin is opened to each file. At the same time, a
file output stream named fout is opened to an
output file with the same name plus the three-letter extension
.dfl. The program then enters a loop in which it
tries to read 1024 -byte chunks of data from fin,
though care is taken not to assume that 1024 bytes are actually read.
Any data that is successfully read is passed to the deflater’s
setInput() method. The data is repeatedly deflated
and written onto the output stream until the deflater indicates that
it needs more input. Then the process repeats itself until the end of
the input stream is reached. When no more input is available, the
deflater’s finish() method is called. Then
the deflater’s deflate() method is
repeatedly invoked until its finished() method
returns true. At this point, the program breaks
out of the infinite read() loop and moves on to
the next file.
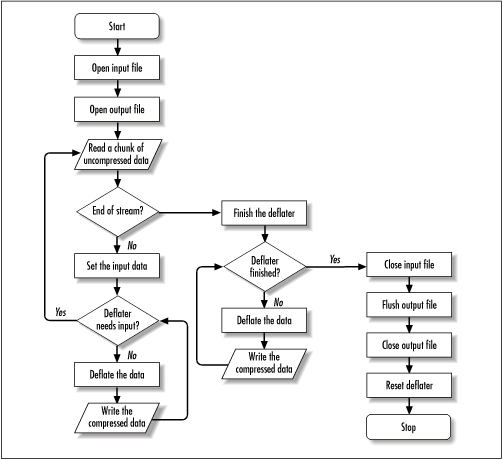
Figure 9.2 is a flow chart demonstrating this
sequence for a single file. One thing may seem a little fishy about
this chart. After the deflater is finished, a repeated check is made
to see if the deflater is in fact finished. The
finish() method tells the deflater that no more
data is forthcoming and it should work with whatever data remains in
its input buffer. However, the finished() method
does not actually return true until the input
buffer has been emptied by calls to deflate().
Example 9-1. The DirectDeflater
import java.io.*;
import java.util.zip.*;
public class DirectDeflater {
public final static String DEFLATE_SUFFIX = ".dfl";
public static void main(String[] args) {
Deflater def = new Deflater();
byte[] input = new byte[1024];
byte[] output = new byte[1024];
for (int i = 0; i < args.length; i++) {
try {
FileInputStream fin = new FileInputStream(args[i]);
FileOutputStream fout = new FileOutputStream(args[i] + DEFLATE_SUFFIX);
while (true) { // read and deflate the data
// Fill the input array.
int numRead = fin.read(input);
if (numRead == -1) { // end of stream
// Deflate any data that remains in the input buffer.
def.finish();
while (!def.finished()) {
int numCompressedBytes = def.deflate(output, 0, output.length);
if (numCompressedBytes > 0) {
fout.write(output, 0, numCompressedBytes);
} // end if
} // end while
break; // Exit while loop.
} // end if
else { // Deflate the input.
def.setInput(input, 0, numRead);
while (!def.needsInput()) {
int numCompressedBytes = def.deflate(output, 0, output.length);
if (numCompressedBytes > 0) {
fout.write(output, 0, numCompressedBytes);
} // end if
} // end while
} // end else
} // end while
fin.close();
fout.flush();
fout.close();
def.reset();
} // end try
catch (IOException e) {System.err.println(e);}
}
}
}This program is more complicated than it needs to be, because it has
to read the file in small chunks. In Example 9.3,
later in this chapter, you’ll see a simpler program that
achieves the same result using the
DeflaterOutputStream class.
The
Deflater class
also provides several methods that return information about the
deflater’s state. The getAdler() method
returns the Adler-32 checksum of the uncompressed data. This is
not a java.util.zip.Checksum
object but the actual int value of the checksum:
public native synchronized int getAdler()
The getTotalIn() method returns the number of
uncompressed bytes passed to the setInput()
method:
public native synchronized int getTotalIn()
The getTotalOut() method returns the total number
of compressed bytes output so far via deflate():
public native synchronized int getTotalOut()
For example, to print a running total of the compression achieved by
the Deflater object def, you
might do something like this:
System.out.println((1.0 - def.getTotalOut()/def.getTotalIn())*100.0 + ˝% saved˝);
The Inflater
class contains methods to decompress blocks of data compressed in the
zip, gzip, or zlib formats. This data may have been produced by
Java’s Deflater class or by some other
program written in another language entirely, such as PKZip or gzip.
Using an inflater is a little simpler than using a deflater, since
there aren’t a lot of settings to pick. Those were established
when the data was compressed. There are seven steps to inflating
data:
Construct an
Inflaterobject.Set the input with the compressed data to be inflated.
Call
needsDictionary()to determine if a preset dictionary is required.If
needsDictionary()returnstrue, callgetAdler()to get the Adler-32 checksum of the dictionary. Then invokesetDictionary()to set the dictionary data.Inflate the data repeatedly until
inflate() returns zero.If
needsInput()returnstrue, go back to step 2 to provide additional input data.The
finished()method returnstrue.
If you want to decompress more data with this
Inflater object, reset it.
You rarely use this class directly. Instead, you use an inflater
indirectly through one of the decompressing stream classes like
InflaterInputStream or
InflaterOutputStream. These classes provide much
more convenient programmer interfaces for stream-oriented
decompression.
There are two
Inflater()
constructors:
public Inflater(boolean zipped) public Inflater()
By passing true to the first constructor, you
indicate that data to be inflated has been compressed using the zip
or gzip format. Otherwise, the constructor assumes the data is in the
zlib format.
Once you have an Inflater to work with, you can
start feeding it compressed data with
setInput()
:
public void setInput(byte[] input) public synchronized void setInput(byte[] input, int offset, int length)
As usual, the first variant treats the entire
input array as data to be inflated. The second
uses the subarray of input, starting at
offset and continuing for
length bytes.
Next, you can determine whether this block of data was compressed
with a preset dictionary. If it was,
needsDictionary() returns true:
public synchronized boolean needsDictionary()
If needsDictionary() does return
true, you can get the Adler-32 checksum of the
requisite dictionary with the getAdler() method:
public native synchronized int getAdler()
This doesn’t actually tell you what the dictionary is (which would be a lot more useful); but if you have a list of commonly used dictionaries, you can probably use the Adler-32 checksum to determine which of those was used to compress the data.
If needsDictionary() returns
true, you’ll have to use one of the
setDictionary()
methods to provide the data for the dictionary. The first uses the
entire dictionary byte array as the dictionary.
The second uses the subarray of dictionary,
starting at offset and continuing for
length bytes.
public void setDictionary(byte[] dictionary) public native synchronized void setDictionary(byte[] dictionary, int offset, int length)
The dictionary is not generally available with the compressed data. Whoever writes files using a preset dictionary is responsible for determining some higher-level protocol for passing the dictionary used by the compression program to the decompression program. One possibility is to store the dictionary file, along with the compressed data, in an archive. Another possibility is that programs that read and write many very similar files may always use the same dictionary built into both the compression and decompression programs.
Once setInput() has filled the input buffer with
data, it is inflated through one of two
inflate() methods:
public int inflate(byte[] output) throws DataFormatException public native synchronized int inflate(byte[] output, int offset, int length) throws DataFormatException
The first method fills the output array with the
uncompressed data. The second fills the specified subarray, beginning
at offset and continuing for
length bytes, with the uncompressed data. The
actual number of uncompressed bytes written into the array is
returned. If one of these methods returns 0, then you should check
needsInput() to see if you need to call
setInput() again to insert more compressed input
data:
public boolean needsInput()
When more data is needed, needsInput()returns
true. At this point you call
setInput() again to feed in more compressed input
data, then call inflate(), then repeat the process
until there is no more input data to be decompressed. If more data is
not needed after inflate() returns zero, this
should mean that decompression is finished, and the
finished() method should return
true:
public synchronized boolean finished()
The inflate() methods throw a
java.util.zip.DataFormatException if they
encounter invalid data, generally indicating a corrupted input
stream. This is a direct subclass of
java.lang.Exception, not an
IOException.
This completes the sequence of method invocations required to
decompress data. If you’d like to use the same settings to
decompress more data with the same Inflater
object, you can invoke its
reset()
method:
public native synchronized void reset()
Otherwise, you call end() to throw away any
unprocessed input and free the resources used by the native code:
public native synchronized void end()
The finalize() method calls
end() before the inflater is garbage-collected,
even if you forget to invoke it explicitly:
protected void finalize()
Example 9.2 is a simple program that inflates files
named on the command line. First an Inflater
object, inf, is created. A file input stream named
fin is opened to each file. At the same time, a
file output stream named fout is opened to an
output file with the same name minus the three-letter extension
.df l. The program then enters a loop in which
it tries to read 1024 -byte chunks of data from
fin , though care is taken not to assume that 1024
bytes are actually read. Any data that is successfully read is passed
to the inflater’s setInput() method. This
data is repeatedly inflated and written onto the output stream until
the inflater indicates that it needs more input. Then the process
repeats itself until the end of the input stream is reached and the
inflater’s finished() method returns
true. At this point, the program breaks out of the
read() loop and moves on to the next file.
Example 9-2. The DirectInflater
import java.io.*;
import java.util.zip.*;
public class DirectInflater {
public static void main(String[] args) {
Inflater inf = new Inflater();
byte[] input = new byte[1024];
byte[] output = new byte[1024];
for (int i = 0; i < args.length; i++) {
try {
if (!args[i].endsWith(DirectDeflater.DEFLATE_SUFFIX)) {
System.err.println(args[i] + " does not look like a deflated file");
continue;
}
FileInputStream fin = new FileInputStream(args[i]);
FileOutputStream fout = new FileOutputStream(args[i].substring(0,
args[i].length() - DirectDeflater.DEFLATE_SUFFIX.length()));
while (true) { // Read and inflate the data.
// Fill the input array.
int numRead = fin.read(input);
if (numRead != -1) { // End of stream, finish inflating.
inf.setInput(input, 0, numRead);
} // end if
// Inflate the input.
int numDecompressed = 0;
while ((numDecompressed = inf.inflate(output, 0, output.length))
!= 0) {
fout.write(output, 0, numDecompressed);
}
// At this point inflate() has returned 0.
// Let's find out why.
if (inf.finished()) { // all done
break;
}
else if (inf.needsDictionary()) { // We don't handle dictionaries.
System.err.println("Dictionary required! bailing...");
break;
}
else if (inf.needsInput()) {
continue;
}
} // end while
// Close up and get ready for the next file.
fin.close();
fout.flush();
fout.close();
inf.reset();
} // end try
catch (IOException e) {System.err.println(e);}
catch (DataFormatException e) {
System.err.println(args[i] + " appears to be corrupt");
System.err.println(e);
} // end catch
}
}
}Once again, this program is more complicated than it needs to be,
because of the necessity of reading the input in small chunks. In
Example 9.4, you’ll see a much simpler program
that achieves the same result via an
InflaterOutputStream.
The Inflater class also provides several methods
that return information about the Inflater
object’s state. The
getAdler()
method returns the Adler-32
checksum of the uncompressed data. This is not a
java.util.zip.Checksum object but the actual
int value of the checksum:
public native synchronized int getAdler()
The getTotalIn()
method returns the number of
compressed bytes passed to the setInput() method:
public native synchronized int getTotalIn()
The
getTotalOut()
method returns the total number of
decompressed bytes output via inflate():
public native synchronized int getTotalOut()
The
getRemaining()
method returns the number of compressed bytes left in the input
buffer:
public native synchronized int getRemaining()
[7]
There’s no reason a third party can’t write compression
classes that exist outside the java.util.zip
package, of course. However, such classes would not be able to
replace Deflater and Inflater
in the rest of the core API.
[8] In fact, the deflation algorithm described here is the exact algorithm used by PNG images; it was first invented specifically for the PNG file format.