
Chapter 2. An Approach to Performance Testing
This chapter discusses four principles of getting the results from performance testing; these principles form the basis of the advice given in later chapters. The science of performance engineering is covered by these principles.
Most of the examples given in later chapters use a common application, which is also outlined in this chapter.
Test a real application
The first principle is that testing should occur on the actual product in the way the product will be used. There are, roughly speaking, three categories of code which can be used for performance testing, each with their own advantages and disadvantages. The category that includes the actual application will provide the best results.
Microbenchmarks
The first of these categories is the microbenchmark. A microbenchmark is a test designed to measure a very small unit of performance: the time to call a synchronized method vs. a non-synchronized method; the overhead in creating a thread vs. using a thread pool; the time to execute one arithmetic algorithm vs. an alternate implementation; and so on.
Microbenchmarks may seem like a good idea, but they are very difficult to write correctly. Consider the following code, which is an attempt to write a microbenchmark that tests the performance of different implementations of a method to compute the Nth Fibonacci number:
publicvoiddoTest(){// Main Loopdoublel;longthen=System.currentTimeMillis();for(inti=0;i<nLoops;i++){l=fibImpl1(50);}longnow=System.currentTimeMillis();System.out.println("Elapsed time: "+(now-then));}...privatedoublefibImpl1(intn){if(n<0)thrownewIllegalArgumentException("Must be > 0");if(n==0)return0d;if(n==1)return1d;doubled=fibImpl1(n-2)+fibImpl(n-1);if(Double.isInfinite(d))thrownewArithmeticException("Overflow");returnd;}
This may seem simple, but there are many problems with this code.
Microbenchmarks must use their results
The biggest problem with this code is that it never actually changes any program state. Because the result of the Fibonacci calculation is never used, the compiler is free to discard that calculation. A smart compiler (including current Java 7 and 8 compilers) will end up executing this code:
longthen=System.currentTimeMillis();longnow=System.currentTimeMillis();System.out.println("Elapsed time: "+(now-then));
As a result, the elapsed time will be only a few milliseconds, regardless of the implementation of the Fibonacci method, or the number of times the loop is supposed to be executed. Details of how the loop is eliminated are given in Chapter 4.
There is a way around that particular issue: ensure that each result
is read, not simply
written. In practice, changing the definition of l from a local variable
to an instance variable (declared with the volatile keyword) will allow
the performance of the method to be measured.[3]
Microbenchmarks must not include extraneous operations
Even then, potential pitfalls exist. This code only performs one operation: calculating the 50th Fibonacci number. A very smart compiler can figure that out and execute the loop only once—or at least discard some of the iterations of the loop since those operations are redundant.
Additionally, the performance of
fibImpl(1000)
is likely to be very different than the performance of
fibImpl(1);
if the goal is
to compare the performance of different implementations, then a range of
input values must be considered.
To
overcome that, the parameter passed to the
fibImpl1()
method must vary.
The solution is to use a random value, but that must also
be done carefully.
The easy way to code the use of the random number generator is to process the loop as follows:
for(inti=0;i<nLoops;i++){l=fibImpl1(random.nextInteger());}
Now the time to calculate the random numbers is included in the time
to execute the loop, and so the test now measures the time to calculate
a the Fibonacci sequence
nLoops
times, plus the time to generate
nLoops
random integers.
That likely isn’t the goal.
In a microbenchmark, the input values must be pre-calculated, e.g.:
int[]input=newint[nLoops];for(inti=0;i<nLoops;i++){input[i]=random.nextInt();}longthen=System.currentTimeMillis();for(inti=0;i<nLoops;i++){try{l=fibImpl1(input[i]);}catch(IllegalArgumentExceptioniae){}}longnow=System.currentTimeMillis();
Microbenchmarks must measure the correct input
The third pitfall here is the input range of the test: selecting arbitrary random values isn’t necessarily representative of how the code will be used. In this case, an exception will be immediately thrown on half of the calls to the method under test (anything with a negative value). An exception will also be thrown anytime the input parameter is greater than 1476, since that is the largest Fibonacci number that can be represented in a double.
What happens in an alternate implementation where the Fibonacci calculation is significantly faster, but where the exception condition is not detected until the end of the calculation? Consider this alternate implementation:
publicdoublefibImplSlow(intn){if(n<0)thrownewIllegalArgumentException("Must be > 0");if(n>1476)thrownewArithmeticException("Must be < 1476");returnverySlowImpl(n);}
It’s hard to imagine an implementation slower than the original recursive implementation, but assume one was devised and used in this code. Comparing this implementation to the original implementation over a very wide range of input values will show this new implementation is much faster than the original implementation—simply because of the range checks at the beginning of the method.
If, in the real world, users are only every going to pass values less than
100 to the method, then that comparison will give us the wrong answer.
In the common case, the
fibImpl()
method will be faster, and as Chapter 1 explained, we should optimize
for the common case.[4]
Taken all together, the proper coding of the micro-benchmark looks like this:
packagenet.sdo;importjava.util.Random;publicclassFibonacciTest{privatevolatiledoublel;privateintnLoops;privateint[]input;publicstaticvoidmain(String[]args){FibonacciTestft=newFibonacciTest(Integer.parseInt(args[0]));ft.doTest(true);ft.doTest(false);}privateFibonacciTest(intn){nLoops=n;input=newint[nLoops];Randomr=newRandom();for(inti=0;i<nLoops;i++){input[i]=r.nextInt(100);}}privatevoiddoTest(booleanisWarmup){longthen=System.currentTimeMillis();for(inti=0;i<nLoops;i++){l=fibImpl1(input[i]);}if(!isWarmup){longnow=System.currentTimeMillis();System.out.println("Elapsed time: "+(now-then));}}privatedoublefibImpl1(intn){if(n<0)thrownewIllegalArgumentException("Must be > 0");if(n==0)return0d;if(n==1)return1d;doubled=fibImpl1(n-2)+fibImpl(n-1);if(Double.isInfinite(d))thrownewArithmeticException("Overflow");returnd;}}
Even this microbenchmark measures some things that are not germane to the
Fibonacci implementation: there is a certain amount of loop and method overhead
in setting up the calls to the
fibImpl1()
method, and the need to
write each result to a
volatile
variable is additional overhead.
Beware, too, of additional compilation effects. The compiler uses profile feedback of code to determine the best optimizations to employ when compiling a method. The profile feedback is based on which methods are frequently called, the stack depth when they are called, the actual type (including subclasses) of their arguments, an so on—it is dependent on the environment in which the code actually runs. The compiler will frequently optimize code differently in a microbenchmark than it optimizes that same code when used in an application. If the same class measures a second implementation of the Fibonacci method, then all sort of compilation effects can occur, particularly if the implementation occurs in different classes.
Finally, there is the issue of what the microbenchmark actually means. The overall time difference in a benchmark such as the one discussed here may be measured in seconds for a large number of loops, but the per-iteration difference is often measured in nanoseconds. Yes, nanoseconds add up, and death by 1000 cuts is a frequent performance issue. But particularly in regression testing, consider whether tracking something at the nanosecond level actually makes sense. It may be important to save a few nanoseconds on each access to a collection that will be accessed millions of times (for example, see Chapter 12). For an operation that occurs less frequently—e.g., maybe once per request for a servlet—fixing a nanosecond regression found by a microbenchmark will take away time that could be more profitably spent on optimizing other operations.
Writing a microbenchmark is hard. There are very limited times when it can be useful. Be aware of the pitfalls involved, and make the determination if the work involved in getting a reasonable microbenchmark is worthwhile for the benefit—or if it would be better to concentrate on more macro-level tests.
Macrobenchmarks
The best thing to use to measure performance of an application is the application itself, in conjunction with any external resources it uses. If the application normally checks the credentials of a user by making LDAP calls, it should be tested in that mode. Stubbing out the LDAP calls may make sense for module-level testing, but the application must be tested in its full configuration.
As applications grow, this maxim becomes both more important to fulfill, and more difficult to achieve. Complex systems are more than the sum of their parts; they will behave quite differently when those parts are assembled. Mocking out database calls, for example, may mean that you no longer have to worry about the database performance—and hey, you’re a Java person; why should you have to deal with someone else’s performance problem? But database connections consume lots of heap space for their buffers; networks become saturated when more data is sent over them; code is optimized differently when it calls a simpler set of methods (as opposed to the complex code in a JDBC driver); CPUs pipeline and cache shorter code paths more efficiently than longer code paths.
The other reason to test the full application is one of resource allocation. In a perfect world, there would be enough time to optimize every line of code in the application. In there real world, deadlines loom, and optimizing only one part of a complex environment may not yield immediate benefits.
Consider the data flow shown in Figure 2-1. Data comes in from a user, some proprietary business calculation is made, some data based on that is loaded from the database, more proprietary calculations are made, changed data is stored back to the database, and an answer is sent back to the user. The numbers in each box is the number of requests per second (e.g., 200 RPS) that the module can process when tested in isolation.
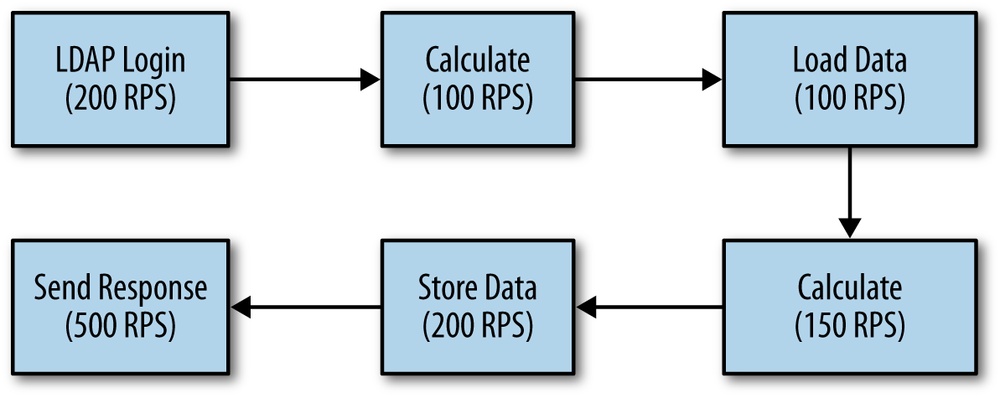
From a business perspective, the proprietary calculations are the most important thing; they are the reason the program exists, and the reason we are paid. Yet making them 100% faster will yield absolutely no benefit in this example. Any application (including a single, standalone JVM) can be modeled as a series of steps like this, where data flows out of a box (module, subsystem, etc.) at a rate determined by the efficiency of that box.[5] Data flows into a subsystem at a rate determined by the output rate of the previous box.
Assume that an algorithmic improvement is made to the business calculation so that it can process 200 RPS, the load injected into the system is correspondingly increased. The LDAP system can handle the increased load: so far, so good, and 200 RPS will flow into the calculation module, which will output 200 RPS.
But the database can still process only 100 RPS. Even though 200 RPS flow into the database, only 100 RPS flow out of it and into the other modules. The total throughput of the system is still only 100 RPS, even though the efficiency of the business logic has doubled. Further attempts to improve the business logic will prove futile until time is spent improving the other aspects of the environment.
It’s not the case that the time spent optimizing the calculations in this example is entirely wasted: once effort is put into the bottlenecks elsewhere in the system, the performance benefit will finally be apparent. Rather, it is a matter of priorities: without testing the entire application, it is impossible to tell where spending time on performance work will pay off.
Mesobenchmarks
I work with the performance of both Java SE and EE, and each of those groups have a set of tests they characterize as microbenchmarks. To a Java SE engineer, that term connotes an example like that in the first section: the measurement of something quite small. Java EE engineers tend to use that term to apply to something else: benchmarks that measure one aspect of performance, but that still execute a lot of code.
An example of a Java EE “microbenchmark” might be something that measures how quickly the response from a simple JSP can be returned from an application server. The code involved in such a request is substantial compared to a traditional microbenchmark: there is a lot of socket-management code, code to read the request, code to find (and possibly compile) the JSP, code to write the answer, and so on. From a traditional standpoint, this is not microbenchmarking.
This kind of test is not a macrobenchmark either: there is no security (e.g., the user does not log into the application), no session management, and no use of a host of other Java EE features. Because it is only a subset of an actual application, it falls somewhere in the middle—it is a mesobenchmark. Mesobenchmarks are not limited to the Java EE arena: it is a term I use for benchmarks that do some real work, but are not full-fledged applications.
Mesobenchmarks have fewer pitfalls than microbenchmarks and are easier to work with than macrobenchmarks. It is unlikely that mesobenchmarks will contain a large amount of dead code that can be optimized away by the compiler (unless that dead code actually exists in the application, in which case optimizing it away is a good thing). Mesobenchmarks are more easily threaded: they are still more likely to encounter more synchronization bottlenecks than the code will encounter when run in a full application, but those bottlenecks are something the real application will eventually encounter on larger hardware systems under larger load.
Still, mesobenchmarks are not perfect. A developer who uses a benchmark like this to compare the performance of two application servers may be easily led astray. Consider the hypothetical response times of two application servers shown in Table 2-1.
| Test | App Server 1 | App Server 2 |
Simple JSP | 19 ms | 50 ms |
JSP with session | 75 ms | 50 ms |
The developer who uses only a simple JSP to compare the performance of the two servers might not realize that server two is automatically creating a session for each request. She may then conclude that server one will give her the fastest performance. Yet if her application always creates a session (which is typical), she will have made the incorrect choice, since it takes server one much longer to create a session.[6]
Even so, mesobenchmarks offer a reasonable alternative to testing a full-scale application; their performance characteristics are much more closely-aligned to an actual application than are the performance characteristics of microbenchmarks. And there is of course a continuum here. A later section in this chapter presents the outline of a common application used for many of the examples in subsequent chapters. That application has an EE mode, but that mode doesn’t use session replication (high availability), nor the EE platform-based security, and though it can access an enterprise resource (i.e., a database), in most examples it just makes up random data. In SE mode, it mimics some actual (but quick) calculations, there is no GUI or user interaction occurring, nor anything else likely to be found in a real application.
Mesobenchmarks are also good for automated testing, particularly at the module level.
Quick Summary
- Good microbenchmarks are hard to write and offer limited value. If you must use them, do so for a quick overview of performance, but don’t rely on them.
- Testing an entire application is the only way to know how code will actually run.
- Isolating performance at a modular or operational level—a mesobenchmark—offers a reasonable compromise but is no substitute for testing the full application.
Common Code Examples
Many of the examples throughout the book are based on a sample application that calculates the “historical” high and low price of a stock over a range of dates, as well as the standard deviation during that time. Historical is in quotes here because in the application, all the data is fictional; the prices and the stock symbols are randomly generated.
The full source code for all examples in this book are online at
www.oreilly.com, but this section covers basic points about the code.
The basic object with in the application is a
StockPrice
object that represents the price range of a stock on a given day:
publicinterfaceStockPrice{StringgetSymbol();DategetDate();BigDecimalgetClosingPrice();BigDecimalgetHigh();BigDecimalgetLow();BigDecimalgetOpeningPrice();booleanisYearHigh();booleanisYearLow();Collection<?extendsStockOptionPrice>getOptions();}
The sample applications typically deal with a collection of these prices, representing the history of the stock over a period of a year (or 25 years, depending on the example):
publicinterfaceStockPriceHistory{StockPricegetPrice(Dated);Collection<StockPrice>getPrices(DatestartDate,DateendDate);Map<Date,StockPrice>getAllEntries();Map<BigDecimal,ArrayList<Date>>getHistogram();BigDecimalgetAveragePrice();DategetFirstDate();BigDecimalgetHighPrice();DategetLastDate();BigDecimalgetLowPrice();BigDecimalgetStdDev();StringgetSymbol();}
The basic implementation of this class loads a set of prices from the database:
publicclassStockPriceHistoryImplimplementsStockPriceHistory{...publicStockPriceHistoryImpl(Strings,DatestartDate,DateendDate,EntityManagerem){DatecurDate=newDate(startDate.getTime());symbol=s;while(!curDate.after(endDate)){StockPriceImplsp=em.find(StockPriceImpl.class,newStockPricePK(s,(Date)curDate.clone()));if(sp!=null){Dated=(Date)curDate.clone();if(firstDate==null){firstDate=d;}prices.put(d,sp);lastDate=d;}curDate.setTime(curDate.getTime()+msPerDay);}}...}
The architecture of the samples is designed to be loaded from a database, and that functionality will be used in the examples in Chapter 11. However, for ease of running the examples, most of the time the examples will use a mock entity manager which generates random data for the series. In essence, most examples are module-level mesobenchmarks which are suitable for illustrating the performance issues at hand—but we would only have an idea of the actual performance of the application when the full application is run (as in Chapter 11).
One caveat is that a number of the examples are therefore dependent on the performance of the random number generator in use. Unlike the microbenchmark example, this is by design, as it allows the illustration of several performance issues in Java.[7]
The examples are also heavily dependent on the performance of the
BigDecimal
class, which is used to store all the data points. This is
a standard choice for storing currency data; if the currency data is stored
as primitive
double
objects, then rounding of half-pennies and smaller
amounts becomes quite problematic. From the perspective of writing examples,
that choice is also useful as it allows some “business logic” or
lengthy calculation to occur—particularly in calculating the standard
deviation of a series of prices. The standard deviation relies on knowing
the square root of a
BigDecimal
number. The standard Java API doesn’t
supply such a routine, but the examples use this method:
publicstaticBigDecimalsqrtB(BigDecimalbd){BigDecimalinitial=bd;BigDecimaldiff;do{BigDecimalsDivX=bd.divide(initial,8,RoundingMode.FLOOR);BigDecimalsum=sDivX.add(initial);BigDecimaldiv=sum.divide(TWO,8,RoundingMode.FLOOR);diff=div.subtract(initial).abs();diff.setScale(8,RoundingMode.FLOOR);initial=div;}while(diff.compareTo(error)>0);returninitial;}
This is an implementation of the Babylonian method for estimating the square root of a number. It isn’t the most efficient implementation; in particular, the initial guess could be much better, which would save some iterations. That is deliberate since it allows the calculation to take some time (emulating business logic), though it does illustrate the basic point made in Chapter 1: often the better way to have faster Java code is to write a better algorithm, independent of any Java tuning or Java coding practices that are employed.
The standard deviation, average price, and histogram of an implementation of
the
StockPriceHistory
interface are all derived values. In different
examples, these value will be calculated eagerly (when the data is loaded from
the entity manager) or lazily (when the method to retrieve the data is called).
Similarly, the
StockPrice
interface references a
StockOptionPrice
interface, which is the price of certain options for the given stock on the
given day. Those option values can be retrieved from the entity manager
either eagerly or lazily. In both cases, the definition of these interfaces
allows these different approaches to be compared in different situations.
These interfaces also fit naturally into a Java EE application: a user can visit a JSP page that lets her enter the symbol and date range for a stock she is interested in. In the standard example, the request will go through the a standard servlet which parses the input parameters, calls a stateless EJB with an embedded JPA bean to get the underlying data, and forwards the response to a JSP page which formats the underlying data into an HTML presentation:
protectedvoidprocessRequest(HttpServletRequestrequest,HttpServletResponseresponse)throwsServletException,IOException{try{Stringsymbol=request.getParameter("symbol");if(symbol==null){symbol=StockPriceUtils.getRandomSymbol();}...similarprocessingfordateandotherparams...StockPriceHistorysph;DateFormatdf=localDf.get();sph=stockSessionBean.getHistory(symbol,df.parse(startDate),df.parse(endDate),doMock,impl);StringsaveSession=request.getParameter("save");if(saveSession!=null){....Storethedataintheuser'ssession........Optionallystorethedatainaglobalcachefor....usebyotherrequests}if(request.getParameter("long")==null){// Send back a page with about 4K of datarequest.getRequestDispatcher("history.jsp").forward(request,response);}else{// Send back a page with about 100K of datarequest.getRequestDispatcher("longhistory.jsp").forward(request,response);}}
This class can inject different implementations of the history bean (for eager or lazy initialization, among other things); it will optionally cache the data retrieved from the back end database (or mock entity manager). Those are the common options when dealing with the performance of an enterprise application (in particular, caching data in the middle tier is sometimes considered to be the big performance advantage of an application server). Examples throughout the book will examine those trade-offs as well.
Understand Throughput, Batching, and Response Time
The second principle in performance testing involves various ways to look at the application’s performance. Which one to measure depends on which factors are most important to your application.
Elapsed Time (Batch) Measurements
The simplest way of measuring performance is to see how long it takes to accomplish a certain task: retrieve the history of 10,000 stocks for a 25-year period and calculate the standard deviation of those prices; produce a report of the payroll benefits for the 50,000 employees of a corporation; execute a loop 1,000,000 times.
In the non-Java world, this testing is straightforward: the application is written, and the time of its execution is measured. In the Java world, there is one wrinkle to this: just-in-time compilation. That process is described in Chapter 4; essentially it means that it takes a few minutes (or longer) for the code to be fully optimized and operate at peak performance. For that (and other) reasons, performance studies of Java are quite concerned about warm-up periods: performance is most often measured after the code in question has been executed long enough for it to have been compiled and optimized.
On the other hand, in many cases the performance of the application from start to finish is what matters. A report generator that processes 10,000 data elements will complete in a certain amount of time; to the end user, it doesn’t matter if the first 5,000 elements are processed 50% more slowly than the last 5,000 elements. And even in something like an application server—where the server’s performance will certainly improve over time—the initial performance matters. It may take 45 minutes for an application server to reach peak performance in certain configurations. To the users accessing the application during that time, the performance during the warm-up period does matter.
For those reasons, many examples in this book are batch-oriented (even if that is a little uncommon).
Throughput Measurements
A throughput measurement is based on the amount of work that can be accomplished in a certain period of time. Although the most common examples of throughput measurements involve a server processing data fed by a client, that is not strictly necessary: a single, standalone application can measure throughput just as easily as it measures elapsed time.
In a client-server test, a throughput measurement means that clients have no think time. If there is a single client, that client sends a request to the server. When it receives a response, it immediately sends a new request. That process continues; at the end of the test, the client reports the total number of operations it achieved. Typically, the client has multiple threads doing the same thing, and the throughput is the aggregate measure of the number of operations all clients achieved. Usually this number is reported as the number of operations per second, rather than the total number of operations over the measurement period. This measurement is frequently referred to as transactions per second (TPS), requests per second (RPS), or operations per second (OPS).
All client-server tests run the risk that the client cannot send data quickly enough to the server. This may occur because there aren’t enough CPU cycles in the client machine to run the desired number of client threads, or because the client has to spend a lot of time processing the request before it can send a new request. In those cases, the test is effectively measuring the client performance rather than the server performance, which is usually not the goal.
This risk depends on the amount of work that each client thread performs (and the size and configuration of the client machine). A zero think-time (throughput-oriented) test is more likely to encounter this situation, since each client thread is performing a lot of work. Hence, throughput tests are typically executed with fewer client threads (less load) than a corresponding test that measures response time.
It is common for tests that measure throughput to report also the average response time of its requests. That is an interesting piece of information, but changes in that number aren’t indicative of a performance problem unless the reported throughput is the same. A server that can sustain 500 operations per second with a 0.5 second response time is performing better than a server than reports a 0.3 second response time but only 400 operations per second.
Throughput measurements are almost always taken after a suitable warmup period, particularly since what is being measured is not a fixed set of work.
Response Time Tests
The last common test is one that measures response time: the length of time it takes between sending a request from a client until the response is received.
The difference between a response time test and a throughput test (assuming the latter is client-server based) is that client threads in a response-time test sleep for some period of time between operations. This time is referred to as think time. A response time test is designed to mimic more closely what a user does: she enters a URL in a browser, spends some time reading the page that comes back, clicks on a link in the page, spends some time reading that page, and so on.
When think time is introduced into a test, throughput becomes fixed: a given number of clients executing requests with a given think time will always yield the same TPS (with some slight variance; see sidebar). At that point, the important measurement is the response time for the request: the effectiveness of the server is based on how quickly it responds to that fixed load.
There are two ways of measuring response time. Response time can be reported as an average: the individual times are added together and divided by the number of requests. Response time can also be reported as a percentile request, for example the 90th% response time. If 90% of responses are less than 1.5 seconds and 10% of responses are greater than 1.5 seconds, then 1.5 seconds is the 90th% response time.
One difference between the two numbers is in the way outliers affect the calculation of the average—since they are included part of the average, large outliers will have a large effect on the average response time.
Figure 2-2 shows a graph of 20 requests with a somewhat typical range for response times. The response times range from 1 to 5 seconds. The average response time (represented by the lower heavy line along the X-axis) is 2.35 seconds, and 90% of the responses occur in 4 or less seconds (represented by the upper heavy line along the X-axis).
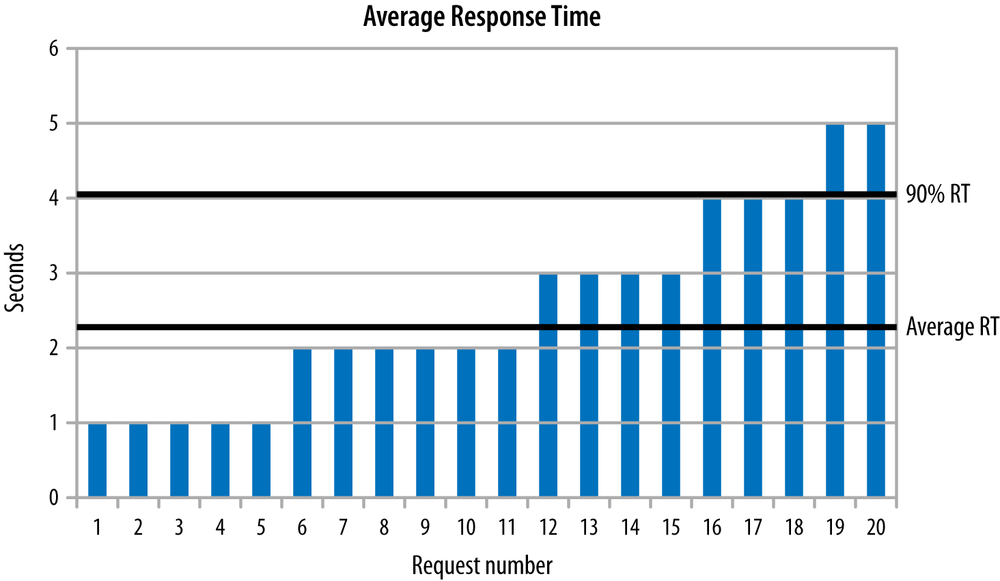
This is the usual scenario for a well-behaved test. Outliers can skew that analysis, as the data in Figure 2-3 shows.
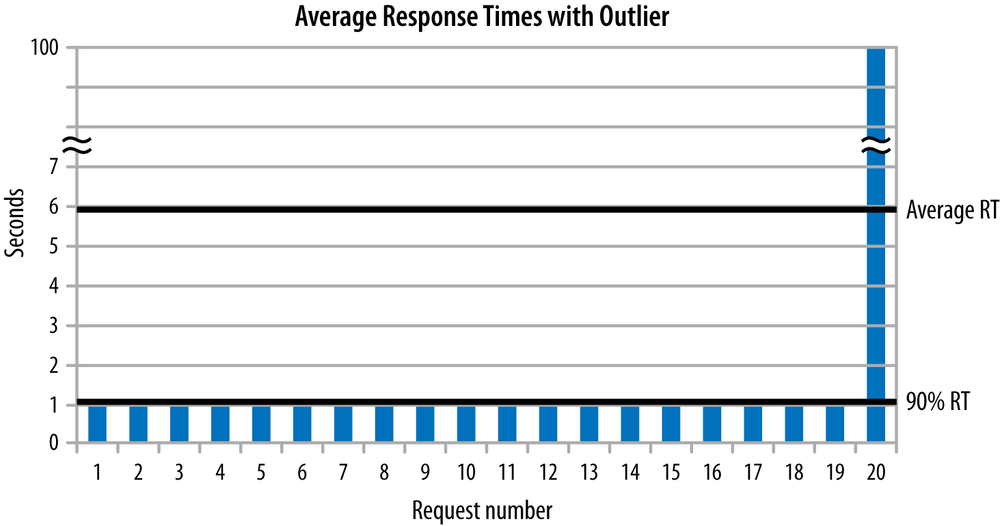
This data set includes a huge outlier: one request took 100 seconds. As a result, the positions of the 90th% and average response times are reversed. The average response time is a whopping 5.95 seconds, but the 90th% response time is 1.0 seconds. Focus in this case should be given to reducing the effect of the outlier (which will drive down the average response time).
Outliers like that are rare in general, though they can more easily occur in Java applications because of the pause times introduced by garbage collection.[8] In performance testing, the usual focus is on the 90th% response time (or sometimes the 95th% or 99th% response time; there is nothing magical about 90%). If you can only focus on one number, a percentile-based number is the better choice, since achieving a smaller number there will benefit a majority of users. But it is even better to look at both the average response time and at least one percentile-based response time, so that you do not miss the case where there are large outliers.
Quick Summary
- Batch-oriented tests (or any test without a warm-up period) have been infrequently used in Java performance testing, but they can yield valuable results.
- Other tests can measure either throughput or response time, depending on whether the load comes in at a fixed rate (i.e., based on emulating think-time in the client).
Understand Variability
The third principle involves understanding how test results vary over time. Programs that process exactly the same set of data will produce a different answer each time they are run. Background processes on the machine will affect the application, the network will be more or less congested when the program is run, and so on. Good benchmarks also never process exactly the same set of data each time they are run; there will be some random behavior built into the test to mimic the real world. This creates a problem: when comparing the result from one run to the result from another run, is the difference due to a regression, or due to the random variation of the test?
This problem can be solved by running the test multiple times and averaging those results. Then when a change is made to the code being tested, the test can be rerun multiple times, the results averaged, and then the two averages compared. It sounds so easy.
Unfortunately, it isn’t quite as simple as that. Understanding when a difference is a real regression and when it is a random variation is difficult—and it is a key area where science leads the way, but art will come into play.
When averages in benchmark results are compared, it is impossible to know with certainty whether the difference in the averages is real, or whether it is due to random fluctuation. The best that can be done is to hypothesize that “the averages are the same” and then determine the probability that such a statement is true. If the statement is false with a high degree of probability, then we are comfortable in believing the difference in the averages (though we can never be 100% certain).
Testing code for changes like this is called regression testing. In a regression test, the original code is known as the baseline and the new code is called the specimen. Take the case of a batch program where the baseline and specimen are each run three times, yielding the times given in Table 2-2.
| Baseline | Specimen | ||
1st Iteration | 1.0 sec | 0.5 sec | |
2nd Iteration | 0.8 sec | 1.25 sec | |
3rd Iteration | 1.2 sec | 0.5 sec | |
Average | 1 sec | 0.75 sec |
The average of the specimen says there is a 25% improvement in the code. How confident can we be that the test really reflects a 25% improvement? Things look good: two of three specimen values are less than the baseline average, the size of the improvement is large—yet when the analysis described in this section is performed on those resultss, it turns out that the probability the specimen and the baseline have the same performance is 43%. 43% of the time when numbers such as these are observed, the underlying performance of the two tests are the same. Hence, performance is different only 57% of the time. This, by the way, is not exactly the same thing as saying that 57% of the time the performance is 25% better, but more about that a little later.
The reason these probabilities seem different than might be expected is due to the large variation in the results. In general, the larger the variation in a set of results, the harder it is to guess the probability that the difference in the averages is real or due to random chance.
This number—43%—is based on the result of Student’s t-test, which is a statistical analysis based on the series and their variances. Student, by the way, is the pen name of the scientist who first published the test; it isn’t named that way to remind you of graduate school where you (or at least I) slept through statistics class. The t-test produces a number called the p-value, and the p-value refers to the probability that the null hypothesis for the test is false.[9]
The null hypothesis in regression testing is the hypothesis that the two tests have equal performance. The p-value for this example is roughly 43%, which means the confidence we can have that the series converge to the same average is 43%. Conversely, the confidence we have that the series do not converge to the same average is 57%.
What does it mean to say that 57% of the time, the series do not converge to the same average? Strictly speaking, it doesn’t mean that we have 57% confidence that there is a 25% improvement in the result—it means only that we have 57% confidence that the results are different. There may be a 25% improvement; there may be a 125% improvement; it is even conceivable that the specimen actually has worse performance than the baseline. The most probable likelihood is that the difference in the test is similar to what has been measured (particularly as the p-value goes down), but certainty can never be achieved.
The t-test is typically used in conjunction with an alpha-value, which is a (somewhat arbitrary) point at which the the result is assumed to have statistical significance. The alpha-value is commonly set to 0.1—which means that a result is considered statistically significant if it means that the specimen and baseline will be the same only 10% (0.1) of the time (or conversely, that 90% of the time there is a difference between the specimen and baseline). Other commonly used alpha-values are 0.5 (95%) or 0.01 (99%). A test is considered statistically significant if the p-value is smaller than 1 - alpha-value.
Hence, the proper way to search for regressions in code is to determine a level of statistical significance—say, 90%—and then to use the t-test to determine if the specimen and baseline are different within that degree of statistical significance. Care must be taken to understand what it means if the test for statistical significance fails. In the example, the p-value is 0.43; we cannot say that that there is statistical significance within a 90% confidence level that the result indicates that the averages are different. The fact that the test is not statistically significant does not mean that it is an insignificant result; it simply means that the test is inconclusive.
The usual reason a test is statistically inconclusive is that there isn’t enough data in the samples. So far, the example here has looked at a series with three results in the baseline and the specimen. What if three additional results are added— again yielding 1, 1.2, and 0.8 seconds for the baseline, and 0.5, 1.25, and 0.5 seconds for the specimen? With the additional data, the p-value drops from 0.43 to 0.19: the probability that the results are different has risen from 57% to 81%. Running additional tests and adding the three data points again increases the probability to 91%—past the usual level of statistical significance.
Running additional tests until a level of statistical significance is achieved isn’t always practical. It isn’t, strictly speaking, necessary either. The choice of the alpha-value that determines statistical significance is arbitrary, even if the usual choice is common. A p-value of 0.11 is not statistically significant within a 90% confidence level, but it is statistically significant within an 89% confidence level.
The conclusion here is that regression testing is not a black-and-white science. You cannot look at a series of numbers (or their averages) and make a judgment that compares them without doing some statistical analysis to understand what the numbers mean. Yet even that analysis cannot yield a completely definitive answer due to the laws of probabilities. The job of a performance engineer is to look at the data, understand those probabilities, and determine where to spend time based on all the available data.
Quick Summary
- Correctly determining whether results from two tests are different requires a level of statistical analysis to make sure that perceived differences are not the result of random chance.
- The rigorous way to accomplish that is to use Student’s t-test to compare the results.
- Data from the t-test tells us the probability that a regression exists, but it doesn’t tell us which regressions should be ignored and which must be pursued. Finding that balance is part of the art of performance engineering.
Test Early, Test Often
Fourth and finally: performance geeks (like me) like to recommend that performance testing be an integral part of the development cycle. In an ideal world, performance tests would be run as part of the process when code is checked into the central repository; code that introduces performance regressions would be blocked from being checked in.
There is some inherent tension between that recommendation and other recommendations in this chapter—and between that recommendation and the real world. A good performance test will encompass a lot of code—at least a medium-sized mesobenchmark. It will need to be repeated multiple times to establish confidence that any difference found between the old code and the new code is a real difference and not just random variation. On a large project, this can take a few days or a week, making it unrealistic to run performance tests of code before checking it into a repository.
The typical development cycle does not make things any easier. A project schedule often establishes a feature-freeze date: all feature changes to code must be checked into the repository at some early point in the release cycle, and the remainder of the cycle is devoted to shaking out any bugs (including performance issues) in the new release. This causes two problems for early testing:
- Developers are under time constraints to get code checked in to meet the schedule; they will balk at having to spend time fixing a performance issue when the schedule has time for that after all the initial code is checked in. The developer who checks in code causing a 1% regression early in the cycle will face pressure to fix that issue; the developer who waits until the evening of the feature freeze can check in code that causes a 20% regression and deal with it later.
- Performance characteristics of code will change as the code changes. This is the same principle that argued for testing the full application (in addition to any module-level tests that may occur): heap usage will change, code compilation will change, and so on.
Despite these challenges, frequent performance testing during development is important, even if the issues cannot be immediately addressed. A developer who introduces code causing a 5% regression may have a plan to address that regression as development proceeds: maybe her code depends on some as-yet-to-be integrated feature, and when that feature is available, a small tweak will allow the regression to go away. That’s a reasonable position, even though it means that performance tests will have to live with that 5% regression for a few weeks (and the unfortunate but unavoidable issue that said regression is masking other regressions).
On the other hand, if the new code causes a regression which can only be fixed with some architectural changes, it is better to catch the regression and address it early, before the rest of the code starts to depend on the new implementation. It’s a balancing act, requiring analytic and often political skills.
Early, frequent testing is most useful if the following guidelines are followed.
- Automate Everything
All performance testing should be scripted (or programmed, though scripting is usually easier). Scripts must be able to install the new code, configure it into the full environment (creating database connections, setting up user accounts, and so on), and run the set of tests. But it doesn’t stop there: the scripts must be able to run the test multiple times, perform t-test analysis on the results, and produce a report showing the confidence level that the results are the same, and the measured difference if they are not the same.
The automation must make sure that the machine is in a known state before tests are run: it must check that no unexpected processes are running, that the OS configuration is correct, and so on. A performance test is only repeatable if the environment is the same from run to run; the automation must take care of that.
- Measure Everything
The automation must gather every conceivable piece of data that will be useful for later analysis. This includes system information sampled throughout the run: CPU usage, disk usage, network usage, memory usage, and so on. It includes logs from the application—both those the application produces, and the logs from the garbage collector. Ideally it can include JFR recordings (see Chapter 3) or other low-impact profiling information, periodic thread stacks, and other heap analysis data like histograms or full heap dumps (though the full heap dumps, in particular, take a lot of space and cannot necessarily be kept long-term).
The monitoring information must also include data from other parts of the system, if applicable: e.g., if the program uses a database, then include the system statistics from the database machine as well as any diagnostic output from the database (including performance reports like Oracle’s Automatic Workload Repository [AWR] reports).
This data will guide the analysis of any regressions that are uncovered. If the CPU usage has increased, it’s time to consult the profile information to see what is taking more time. If the time spent in GC has increased, it’s time to consult the heap profiles to see what is consuming more memory. If CPU time and GC time have decreased, contention somewhere has likely slowed down performance: stack data can point to particular synchronization bottlenecks (see Chapter 9), JFR recordings can be used to find application latencies, or database logs can point to something that has increased database contention.
When figuring out the source of a regression, it is time to play detective, and the more data that is available, the more clues there are to follow. As discussed in Chapter 1, it isn’t necessarily the case that the JVM is the regression. Measure everything, everywhere, to make sure the correct analysis can be done.
- Run on the Target System
A test that is run on a single-core laptop will behave very differently than a test run on a machine with a 256-thread SPARC CPU. That should be clear in terms of threading effects: the larger machine is going to run more threads at the same time, reducing contention among application thread for access to the CPU. At the same time, the large system will show synchronization bottlenecks that would be unnoticed on the small laptop.
There are other performance differences that are just as important even if they are not as immediately obvious. Many important tuning flags calculate their defaults based on the underlying hardware the JVM is running on. Code is compiled differently from platform to platform. Caches—software and, more importantly, hardware—behave differently on different systems, and under different loads. And so on…
Hence, the performance of a particular production environment can never be fully known without testing the expected load on the expected hardware. Approximations and extrapolations can be made from running smaller tests on smaller hardware, and in the real world, duplicating a production environment for testing can be quite difficult or expensive. But extrapolations are simply predictions, and even in the best case, predictions can be wrong. A large-scale system is more than the sum of its parts, and there can be no substitute for performing adequate load testing on the target platform.
Quick Summary
- Frequent performance testing is important, but it doesn’t occur in a vacuum; there are trade-offs to consider regarding the normal development cycle.
- An automated testing system that collects all possible statistics from all machines and programs will provide the necessary clues to any performance regressions.
Summary
Performance testing involves a number of trade-offs. Making good choices among competing options is crucial to successfully tracking the performance characteristics of a system.
Choosing what to test is the first area where experience with the application and intuition will be of immeasurable help when setting up performance tests. Microbenchmarks tend to be the least helpful test; they are useful really only to set a broad guideline for certain operations. That leaves a quite broad continuum of other tests, from small module-level tests to a large, multi-tiered environment. Tests all along that continuum have some merit, and choosing the tests along that continuum is one place where experience and intuition will come into play. However, in the end there can be no substitute for testing a full application as it is deployed in production; only then can the full effect of all performance-related issues be understood.
Similarly, understanding what is and is not an actual regression is code is not always a black-and-white issue. Programs always exhibit random behavior, and once randomness is injected into the equation, we will never be 100% certain about what data means. Applying statistical analysis to the results can help to turn the analysis to a more objective path, but even then some subjectivity will be involved. Understanding the underlying probabilities and what they mean can help to lessen that subjectivity.
Finally, with these foundations in place, an automated testing system can be put in place that gathers full information about everything that occurred during the test. With the knowledge of what’s going on and the what the underlying tests mean, the performance analyst can apply both science and art so that the program can exhibit the best possible performance.
[4] This is obviously a contrived example, and simply adding a bounds test to the original implementation makes it a better implementation anyway. In the general case, that may not be possible.
[5] In this model, that time includes the code in that subsystem and also includes network transfer times, disk transfer times and so on. In a module model, the time includes only the code for that module.
[6] Whether the performance of subsequent calls differs is yet another matter to consider, but it is impossible to predict from this data which server will do better once the session is created.
[7] For that matter, the goal of the examples is to measure the performance of some arbitrary thing, and the performance of the random number generator fits that goal. That is quite different than a microbenchmark, where including the time for generating random numbers would affect the overall calculation.
[8] Not that garbage collection should be expected to introduce a 100-second delay, but particularly for tests with small average response times, the GC pauses can introduce significant outliers.
[9] There are several programs and
class libraries that can calculate t-test results; the numbers produced in
this section come from using the
TTest class of the Apache commons-math class library.