
8
Breaking Changes
In government, we had a saying, “The only thing the government hates more than change is the way things are.” The same inertia lingers over legacy systems. It is impossible to improve a large, complex, debt-ridden system without breaking it. If you’re lucky, the resulting outages will be resolved quickly and result in minimum data loss, but they will happen.
Another expression that was popular among my colleagues in government was “air cover.” To have air cover was to have confidence that the organization would help your team survive such inevitable breakages. It was to have someone who trusted and understood the value of change and could protect the team. As a team lead, my job was to secure that air cover. When I moved back to the private sector, I applied the same principles as a manager—networking, relationship building, recruiting, doing favors—so I could give my team members the safety and security necessary to do the hard jobs for which I had hired them.
In this chapter, I explore the concept of breaking changes. How do you sell dangerous changes while being honest about their risks? When should you break stuff, and how do you recover quickly?
But, I want to start with the concept of air cover. Business writers sometimes refer to “psychological safety,” which is another great way to describe the same concept. To do effective work, people need to feel safe and supported. Leadership buy-in is one part of creating the feeling of air cover, but for air cover to be effective, it has to alter an organization’s perception of risk.
Risk is not a static number on a spreadsheet. It’s a feeling that can be manipulated, and while we may justify that feeling with statistics, probabilities, and facts, our perception of level of risk often bears no relationship to those data points.
Being Seen
A year or two ago, I was invited to give a guest lecture on working with software engineers at Harvard’s Kennedy School for Government. When it came time to give practical advice, the first slide on my deck said in big letters, “How do people get seen?”
Being seen is not specifically about praise. It’s more about being noticed or acknowledged, even if the sentiment expressed in that acknowledgment is neutral. Just as status-seeking behavior influences what people say in meetings, looking to be seen influences what risks people are willing to tolerate. Fear of change is all about perception of risk. People construct risk assessments based on two vectors: level of punishment or reward and odds of getting caught.
Of those two, people are more sensitive to changes in odds of getting caught than level of punishment or reward.1 If you want to deter crime, increase the perception that the police are effective, and criminals will be caught. If you want to incentivize behavior, pay attention to what behaviors get noticed within an organization.
Organizations can pay a lot of lip service to good behaviors but still not notice them. Being seen is not about matching an organization’s theoretical ideals, it’s about what your peers will notice. It’s easy for the organization’s rhetoric to be disconnected from the values that govern the work environment. What colleagues pay attention to are the real values of an organization. No matter how passionate or consistent the messaging, attention from colleagues will win out over the speeches.
The specific form of acknowledgment also matters a lot. Positive reinforcement in the form of social recognition tends to be a more effective motivator than the traditional incentive structure of promotions, raises, and bonuses. Behavioral economist Dan Ariely attributes this to the difference between social markets and traditional monetary-based markets.2 Social markets are governed by social norms (read: peer pressure and social capital), and they often inspire people to work harder and longer than much more expensive incentives that represent the traditional work-for-pay exchange. In other words, people will work hard for positive reinforcement; they might not work harder for an extra thousand dollars.
Ariely’s research suggests that even evoking the traditional market by offering small financial incentives to work harder causes people to stop thinking about the bonds between them and their colleagues and makes them think about things in terms of a monetary exchange3—which is a colder, less personal, and often less emotionally rewarding space.
The idea that one needs a financial reward to want to do a good job for an organization is cynical. It assumes bad faith on the part of the employee, which builds resentment. Traditional incentives have little positive influence, therefore, because they disrupt what was otherwise a personal relationship based on trust and respect. Behavioralist Alfie Kohn puts it this way:
Punishment and rewards are two sides of the same coin. Rewards have a punitive effect because they, like outright punishment, are manipulative. “Do this and you’ll get that” is not really very different from “Do this or here’s what will happen to you.” In the case of incentives, the reward itself may be highly desired; but by making that bonus contingent on certain behaviors, managers manipulate their subordinates, and that experience of being controlled is likely to assume a punitive quality over time.4
Here’s an example of this in practice. When I worked for USDS, my boss constantly complained about people doing the exact opposite of what he told them time and time again was what he wanted them to do. Specifically, he kept telling teams not to take systems away from the organizations that owned them. USDS operated, at least in theory, on a consulting model. We were supposed to assist and advise agencies, not adopt their legacy systems long term without any exit plan. My boss complained about this approach over and over again. He could not understand why people kept gravitating toward a strategy that was more difficult, less likely to succeed, and against his wishes.
Every week, we had a staff meeting where people demoed what they were working on and gave status updates. Inevitably, USDSers would censor their updates, wanting to talk about things only once they had achieved success. This meant product launches. All we talked about at staff meetings were product launches. Eventually, this convention became self-reinforcing. People began to think they shouldn’t talk about a project before it had a launch coming up or a milestone reached, that the little wins were not worth mentioning.
The problem was that most USDS projects involved old systems where the solutions would take months of untangling, even if the government bureaucracy wasn’t a factor. Talking only about product launches meant certain teams might work for a full year on something before their peers ever heard about their projects.
My boss’s advice of not taking things away from the organizations that owned them was great advice for long-term sustainability, but it would mean feelings of isolation as colleagues talked about their work and you had nothing to contribute, because it would take months to get to a product launch. What’s the best way to speed that up? Take over the system, remove or otherwise bypass the government client who owns it, and bring in a team of bright young USDSers to do all the work. This got products to launch quicker, but handing them off to the government stakeholders became close to impossible. They didn’t know anything about the new system. This is what my boss was trying to prevent, but people ignored his advice to prioritize the methods that were going to get them seen by their peers early and often.
When we realized this, we decided to schedule a 10-minute block at the end of every staff meeting for “kudos.” Kudos were acknowledgments and congratulations of small wins throughout the organization. Did a meeting go well? Write a kudos. Did someone go above and beyond the call of duty to fix something? Write a kudos. Did a team show integrity and resolve through a project failure? Write a kudos. We would collect all the kudos in a specific repository throughout the week, and then at the end of the staff meeting, someone would read them all out loud.
Given a choice between a monetary incentive and a social one, people will almost always choose the behavior that gets them the social boost. So when you’re examining why certain failures are considered riskier than others, an important question to ask yourself is this: How do people get seen here? What behaviors and accomplishments give them an opportunity to talk about their ideas and their work with their colleagues and be acknowledged?
If you want to improve people’s tolerance for certain types of risks, change where the organization lands on those two critical vectors of rewards and acknowledgment. You have four options: increase the odds that good behavior will get noticed (especially by peers), decrease the odds that bad outcomes will get noticed, increase the rewards for good behavior, or decrease the punishment for bad outcomes. All of these will alter an organization’s perception of risk and make breaking changes easier.
Note the distinction between good behavior and bad outcomes. When deciding how they should execute on a given set of tasks, workers consider two questions: How does the organization want me to behave? And, will I get punished if things go wrong despite that correct behavior? If you want people to do the right thing despite the risk, you need to accept that failure.
One of the most famous examples of these principles in play to raise engineering standards is Etsy’s 3-Arm Sweater award.5 The image of the 3-Arm Sweater is used throughout Etsy to signify a screw-up. It is featured prominently on its 404 File Not Found page, for example. The 3-Arm Sweater award is given out to the engineer who triggers the worst outage. Celebrating failure wasn’t just an annual tradition; Etsy employees had an email list to broadcast failure stories company-wide.6 Because Etsy wanted to establish a just culture, where people learned from mistakes together instead of trying to hide them, the company found ways to integrate the acknowledgment of those behaviors into day-to-day operations. These practices helped Etsy scale its technology to 40 million unique visitors every month.7
If you want your team to be able to handle breaking things, pay attention to what the organization celebrates. Blameless postmortems and just culture are a good place to start, because they both manipulate how people perceive failure and establish good engineering practices.
Who Draws the Line?
But, can blameless postmortems ever really be blameless?
In 2008, system safety researcher Sidney Dekker published an article titled “Just Culture: Who Gets to Draw the Line?”8 Dekker’s article addresses whether true “blameless” postmortems, where no one was ever punished for errors, are the desired end state of just cultures. People want psychological safety, but they also want accountability. No one wants to excuse actual negligence, but if there’s a line between mistakes that should be blameless and those where people should be held accountable, who should be able to draw it?
A popular exercise with first-year computer science students is to write a hypothetical program instructing a robot to walk across the room. Students soon find that the simplest of instructions, when taken literally, can lead to unexpected results, and the purpose of the exercise is to teach them something about algorithms as well as what assumptions computers can and cannot make.
Safety researchers like Dekker view organizational procedures largely the same way. Prescribed safety, security, and reliability processes are useful only if operators can exercise discretion when applying them. When organizations take the ability to adapt away from the software engineers in charge of a system, any gap in what procedure covers becomes an Achilles heel.
That’s why the issue of who gets to draw the line is so critical to a just culture. The closer the line-drawing pattern is to the people who must maintain the system, the greater the resilience. The further away, the more bureaucratic and dysfunctional.
Also, the line is never drawn once; it is actively renegotiated. No rule maker can possibly predict every conceivable situation or circumstance an organization and its technology might confront. So the line between blameless behavior and behavior that people should be held accountable for is redrawn. These corrections can be influenced by cultural, social, or political forces.
Just as understanding how people get seen is important to constructing incentives that moderate people’s perception of risk, understanding who gets to draw the line between mistakes that are acceptable and those that are not is important to understanding how privilege is distributed around an organization. The highest probability of success comes from having as many people engaged and empowered to execute as possible. Those who cannot draw the line or renegotiate the placement of the line are the organization members with the least privilege and the most in need of investment to get the full benefit of their efforts.
Building Trust Through Failure
The suggestion that failure should be embraced or that a modernization team should deliberately break something makes people uncomfortable. The assumption is that failure is a loss—failure always leaves you worse off.
Or does it?
The science paints a much more complex picture. Although a system that constantly breaks, or that breaks in unexpected ways without warning, will lose its users’ trust, the reverse isn’t necessarily true. A system that never breaks doesn’t necessarily inspire high degrees of trust.
Italian researchers Cristiano Castelfranchi and Rino Falcone have been advancing a general model of trust in which trust degrades over time, regardless of whether any action has been taken to violate that trust.9 People take systems that are too reliable for granted. Under Castelfranchi and Falcone’s model, maintaining trust doesn’t mean establishing a perfect record; it means continuing to rack up observations of resilience. If a piece of technology is so reliable it has been completely forgotten, it is not creating those regular observations. Through no fault of the technology, the user’s trust in it will slowly deteriorate.
Those of us who work in the field of legacy modernization see this happen all the time. Organizations become gung-ho to remove a system that has been stable and efficient for decades because it is old, and therefore, management has become convinced that a meltdown is imminent.
We also see this happen on more modern systems. Google has repeatedly promoted the notion that when services are overperforming their SLOs, teams are encouraged to create outages to bring the performance level down.10 The rationale for this is that perfectly running systems create a false sense of security that lead other engineering teams to stop building proper fail-safes. This might be true, but a different way to look at it is that the more a service overperforms, the less confident Google’s SREs become in overall system stability.
The idea that something is more likely to go wrong only because there’s been a long gap when nothing has gone wrong is a version of the gambler’s fallacy. It’s not the lack of failure that makes a system more likely to fail, it’s the inattention in the maintenance schedule or the failure to test appropriately or other cut corners. Whether the assumption that a too reliable system is in danger is sensible depends on what evidence people are calling on to determine the odds of failure.
The gambler’s fallacy is one of those logical fallacies that is so pervasive, it shows up in all kinds of weird ways. In 1796, for example, a French philosopher documented how expecting fathers felt anxiety and despair when other local women gave birth to sons because they were convinced it lowered their likelihood of having a son within the same period.11
For this reason, the occasional outage and problem with a system—particularly if it is resolved quickly and cleanly—can actually boost the user’s trust and confidence. The technical term for this effect is the service recovery paradox.12
Researchers haven’t been able to pin down the exact nature of the service recovery paradox—why it happens in some cases but not others—therefore, you shouldn’t take things as far as trying to optimize customer satisfaction by triggering outages. That being said, what we do know is that recovering fast and being transparent about the nature of the outage and the resolution often improves relationships with stakeholders. Factoring in the boost to psychological safety and productivity that just culture creates, technical organizations shouldn’t shy away from breaking things on purpose. Under the right conditions, the cost of user trust is minimal, and the benefits might be substantial.
Breaking Change vs. Breaking
Before I go into the nitty-gritty details of deliberately breaking systems, I should acknowledge that I’m using the phrase breaking change to refer to all changes that break a system. Breaking change is not normally that broad.
Typically, what we mean when we say breaking change is a violation of the data contract that impacts external users. A breaking change is something that requires customers or users to upgrade or modify their own systems to keep everything working. It is a change that breaks technology owned by other organizations.
For the sake of convenience, I’m using the expression breaking change here to refer to any kind of change—internally or externally—that alters system functionality in a negative way. The rest of this chapter discusses both the changes we make as part of deprecations and redesigns that break contacts on external-facing APIs and the changes we make when seeking to reduce a system’s overall complexity.
Why Break Things on Purpose?
It’s unlikely that any significant legacy modernization project can complete without breaking the system at least once. But, breaking a system as an unfortunate consequence of other changes, knowing there’s a risk that a break might occur, and deliberately breaking things on purpose are different scenarios. I’m arguing that your organization shouldn’t just embrace resilience over risk aversion, but it should also occasionally break things on purpose.
What kind of scenarios justify breaking things on purpose? The most common one when dealing with legacy systems is loss of institutional memory. On any old system, one or two components exist that no one seems to know exactly what they do. If you are seeking to minimize the system’s complexity and restore context, such knowledge gaps can’t just be ignored. Mind you, the situations when you can’t figure out what a component is doing from studying logs or digging up old documentation tend to be rare, but they do happen. Provided the system doesn’t control nuclear weapons, turning the component off and seeing what breaks is a tool that should be available when all other avenues are exhausted.
Having a part of a system that no one understands is a weakness, so avoiding the issue for fear of breaking things should not be considered the safer choice. Using failure as a tool to make systems and the organizations that run them stronger is one of the foundational concepts behind resilience engineering. It’s important to know how each part of a system works in a variety of conditions, including how interactions between parts work. Unfortunately, no one person can hold all of that information in his or her head. Knowledge about a system must be regularly shared among the different operational units of a technical organization. An organization needs processes to expose relevant details and scenarios, communicate them, and judge their significance. That’s why the second reason to break things on purpose is to verify that what an organization believes about its system is actually true. Resilience engineering tests—also called failure drills—look to trigger failure strategically so that the true behavior of the system can be documented and verified.
The simplest and least threatening of failure drills is to restore from backup. Remember, if an organization has never restored from backup, it does not have working backups. Waiting for an actual outage to figure that out is not a safer strategy than running a failure drill at a time you’ve chosen, supervised by your most experienced engineers.
You can justify any failure test the same way. Is it better to wait for something to fail and hope you have the right resources and expertise at the ready? Or is it better to trigger failure at a time when you can plan resources, expertise, and impact in advance? You don’t know that something doesn’t work the way you intended it to until you try it.
Projecting Impact
Two types of impact are relevant to failure tests. The first is technical impact: the likelihood of cascading failures, data corruption, or dramatic changes in security or stability. The second is user impact: How many people are negatively affected and to what degree?
Technical impact will be the harder of the two to project. You should have some idea of how different parts of the system are coupled and where the complexity is in your system from exercises in previous chapters; now you’ll want to put that information into a model of potential failures.
A good way to start is with a 4+1 architectural view model. Developed by Philippe Kruchten,13 a 4+1 architectural view model breaks an architectural model into separate diagrams that reflect the concerns of one specific viewpoint.
- Logical view maps out how end users experience a system. This might take the form of a state diagram, where system state changes (such as updates to the database) are tracked along user behavior. When the user clicks a particular button, what happens? What actions could the user take from that point, and how would the system state adjust?
- Process view looks at what the system is doing and in what order. Process views are similar to logical views except the orientation is flipped. Instead of focusing on what the user is doing, the focus is on what processes the machine is initiating and why.
- Development view is the system how software engineers see it. The architecture is broken out by components reflecting the application code structure.
- Physical view shows us our systems as represented across physical hardware. What actually gets sent across the network? What else lives on the same servers?
The +1 in the 4+1 architecture refers to scenarios. Scenarios take a small sample of features that can be connected to a specific technique or functionality and focus on it. In other words, these are use cases.
These views are easier to understand by example. Let’s consider a hypothetical system where users upload scanned documents that are converted to text files. These text files are tagged automatically based on their context, but users may edit both this metadata and the transcription itself.
The logical view of this system might look like Figure 8-1.

Figure 8-1: Logical view, a state machine
We model the state of the data as it goes from document to processed verified output. Each of the stages is kicked off by a user action, and it’s easy to see the functional requirements of the system.
The process view, on the other hand, might look something like Figure 8-2.
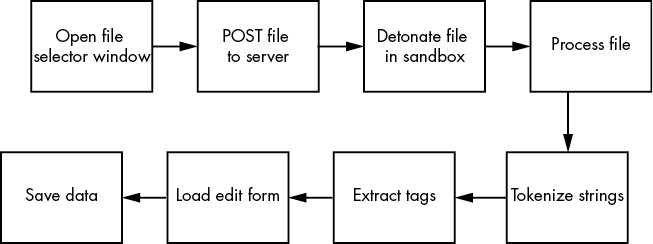
Figure 8-2: Process view, the technical processes being performed
Processing a file begins with triggering the interface to select the file for the user’s computer. Upon receiving the file, the server downloads it into a sandbox to ensure it’s safe. While processing, text data is tokenized so that tags of the most common significant words can be extracted. Then we load that data into an edit form so the user can validate it.
Although the two views describe the same system with the same set of functions, they highlight different things. The process view contains requirements around ensuring the file being uploaded is safe and how the tags are identified that are not visible to the user, but without the logical view, we might not realize that the intention of the system is that the data should not be considered final until the user has verified it.
Kruchten developed the 4+1 architectural view model because he observed that traditional architectural diagrams tried to capture all the perspectives in one visualization. As a result, instead of enriching and deepening our ability to reason about a system, knowledge gaps were created where one view was emphasized over all others.
For example, the impacts of a broken sandbox are obvious on the process view, but they do not even register on the logical view. Whereas the logical view highlights tags and text as separate things that might break independently of one another, the process view does not reveal this.
The development and physical views have a similar relationship. Figure 8-3 shows what this hypothetical system might look like in a development view.

Figure 8-3: Development view, how the code is structured
Code is organized into two classes: Documents and Tags. Each class has a set of methods reflecting a Create, Read, Update, and Delete (CRUD) structure. This system saves the document as soon as we’ve verified that it’s safe, so that if the parser fails, we don’t lose data. It tokenizes as it parses and creates tags after.
The physical view might look more like Figure 8-4.
Users access the system from browsers on their computers. The web application runs on a server that interacts with a separate VM for sandboxing, an object store for preprocessed documents, and a database for post-processed data.
Each of these views is different, and by considering them together, we get a clearer picture of the different ways that one component of the system might fail and what that failure would affect.
Once we’ve modeled the system and feel confident that we understand it, we can flesh out our analysis of potential failures by collecting data from the running system to try to determine how many stakeholders would be affected in case of failure and the likelihood of failure happening at all.

Figure 8-4: Physical view, servers in a cloud environment
The simplest and most obvious place to start is with the system’s logs. Is a log produced when this component of the system is active, and do we know what triggered it, when it was triggered, how long it ran, or other metadata? If we don’t have logs, can we add them? A week or two of data will not give you a complete picture, but it will validate what an outage would impact and clarify the order of magnitude.
Another trick to estimating impact is to consider whether the mitigation can actually be automated. We had this issue around templates once. For security reasons, we wanted to standardize on one templating language. We needed our users to convert their custom templates and didn’t want to spend months communicating and negotiating with customers, so we built a tool that did the conversion for the customer and tested that the new templates rendered identically.
Finally, there’s the most extreme method I mentioned before: turn the component off and see who complains. What if the request leaves your network and you can’t tell what the receiver is doing with it, if anything? In those cases, you need to chip away at the challenge until you’ve defined the impact. A micro-outage is similar to “turn it off and see who complains,” except that you remove the asset only for a small period of time and do not wait for a complaint to turn it back on.
The Kill Switch
As a result of your analysis, you should have a general idea of what is likely to go wrong. Given that information, part of the plan before deliberately breaking a component of a system should be establishing termination criteria. That is to say, if the breakage triggers impacts beyond a certain level, when and how do you revert the breakage? Having a rollback strategy is important for any kind of change to an operational system, but it’s effective only if everyone understands what the tolerance for failure really is.
Setting the criteria and process for undoing the break before anything is damaged gives people the ability to take on the risk with confidence.
Communicating Failure
Of course, it’s not very diplomatic to break something that will affect colleagues and users without letting them know. Some level of communication is usually needed, but how much and with whom depends on the objectives of the breaking change.
If you are breaking something to test the system’s resilience, providing too much information can limit the effectiveness of the drill. The whole point of a failure drill is to test whether procedures for recovery work as expected. Real failures rarely announce themselves or provide a detailed description of how they are triggered.
Before a failure drill, it is not necessary to notify external users at all. In theory, your organization will recover successfully, and users will experience no negative impacts. Internal stakeholders, including system users and other engineering teams, should be notified that there will be a failure drill on a specific part of the system, but they don’t need to know how long the outage will last, when exactly it will be, or the nature of the failure to be triggered. If the drill is a routine test of backups and fail-safes, a week’s notice is usually acceptable. If the drill will affect areas of the system with unclear or complex recovery paths or if the drill is testing human factors in the recovery process, more notice is a good idea. You want to give teams enough time to assess the potential impact on the parts of the system they own and double-check their mitigation strategies. Typically, I recommend no more than 90 days’ advance notice for the most elaborate failure drills. If you provide too much time, people will procrastinate to the point where it is as if they were given no advanced notice at all. If you give too little notice, teams will need to stop normal development work to be ready in time.
It’s different if you are breaking something with the intention of decommissioning it or otherwise leaving it permanently altered. In that case, it is more important to communicate the change to external users. The traditional way to do this is to set a date for decommissioning the specific feature or service, declare it deprecated, and notify users a few months in advance. How much time to give users depends on how complex the migration away from the deprecated feature is likely to be. I don’t think there’s much value in providing years of notice versus months for the same reason I don’t usually give internal teams more than 90 days of notice for a failure drill: more time often leads to more procrastination.
If you are particularly unlucky, you might find yourself in a situation where you cannot inform users with an email, a phone call, or even a letter. You may not even know exactly who the users are. In those situations, you either have to get a little creative or take your chances that a component that looks unused actually is.
Posting a deprecation notice somewhere that users are likely to look for information is one solution. One time, when we could find no other way to figure out who was using a specific API, we put a message in the API itself. Since the attribute we wanted to get rid of happened to be a string, we just changed the content of the string to a message saying that, for security reasons, we would no longer be providing that value and to contact customer support for more information.
But, whatever the method, the most important part of your communication strategy is that you carry out the breaking change when you said you were going to do it. If you hesitate or delay, users will simply not bother migrating at all, and the impact of the breakage will be much more damaging.
Once you set a date for failure, whether it’s a drill or a permanent decommissioning, you need to honor that commitment.
Failure Is a Best Practice
To summarize, people’s perception of risk is not static, and it’s often not connected to the probability of failure so much as it is the potential feeling of rejection and condemnation from their peers. Since social pressures and rewards are better incentives than money and promotions, you can improve your odds of success by learning how to manipulate an organization’s perception of risk.
The first task is to understand what behaviors get individuals within an organization acknowledged. Those are the activities that people will ultimately prioritize. If they are not the activities that you think will advance your modernization process, explore constructs, traditions, and—there’s no better word for it—rituals that acknowledge complementary activities.
The second task is to look at which part of the organization gets to determine when the operator can exercise discretion and deviate from defined procedure. Those are the people who set the ratio of blamelessness to accountability in handling failure. Those are the people who will grant air cover and who need to buy in to any breaking change strategy for it to be successful. Once that air cover is established, anxiety around failure tends to relax.
Once you know how to manipulate the organization’s perception of risk, successfully managing the break is all about preparation. While you will not be able to predict everything that could go wrong, you should be able to do enough research to give your team the ability to adapt to the unknown with confidence. At a minimum, everyone should know and understand the criteria for rolling back a breaking change.
Failure does not necessarily jeopardize user trust. If the situation is quickly resolved and users receive clear and honest communication about the problem, the occasional failure can trigger the service recovery paradox and inspire greater user confidence.
Organizations should not shy away from failure, because failure can never be prevented. It can only be put off for a while or redirected to another part of the system. Eventually, every organization will experience failure. Embracing failure as a source of learning means that your team gains more experience and ultimately improves their skills mitigating negative impacts on users. Practicing recovering from failure, therefore, makes the team more valuable.