
Chapter 4. Grouping and Joining Data
Goals of this chapter:
• Define the capabilities of LINQ joining and grouping features.
• Demonstrate grouping and joining data sources.
• Discuss the best practices and pitfalls to avoid when grouping and joining data sources.
The main goal of this chapter is to define the capabilities of LINQ to Objects’ extensive grouping and joining features. Best practices and the most likely pitfalls to be avoided when grouping and joining data sources are discussed. By the end of this chapter you will be well-versed in how to write queries that group input data into subcollections and how to join data in one collection with matching data from another.
How to Group Elements
Grouping in LINQ enables you to return partitioned sets of data from a collection based on a given key value. An example might be to group all Contact records by the State property. In LINQ this query can be simply written
![]()
Or if you prefer the extension method query syntax
![]()
The result from a LINQ grouping operation is an enumerable sequence of groups (themselves sequences), with each group having a distinct key value. The key value is determined by the “key selection” expression, which is an expression that equates the key value for each element (c.State in the previous example). All source elements that equate to an equal key value using the key selection expression will be partitioned into the same group.
The GroupBy extension method operator has many overloads; the simplest has just a single key selection argument. The remaining overloads of this operator allow specific control of how element equality is evaluated, the select projection to use for the resulting groups, and what select projection is used for generating each element in any resulting group.
The following GroupBy extension method signature shows all of the possible arguments:

Independent from how the GroupBy projects the results, the resulting sequence exposes groups that have a common Key property value. The members of these groupings can themselves be enumerated to obtain the individual group elements.
Working with Groups
The return collection from a GroupBy or group x by y query is
IEnumerable<IGrouping<TKey, TElement>>
IGrouping interface inherits from IEnumerable<TElement> (making itself enumerable) and exposes a Key property that indicates the unique result that formed this grouping. This interface has the following form:

LINQ to Objects returns by default an internal concrete class implementation of IGrouping<Tkey, TElement>, called Grouping. It is exposed via the IGrouping interface through the extension method signatures so that Microsoft can develop this over time. The only property you should rely on is the Key property. Most methods on the underlying Grouping collection type throw a NotSupportedException and should be avoided.
Enumerating over the result of a GroupBy extension method or group x by y query expression yields one IGrouping<TKey, TElement> element per unique key. Each group instance has the mandatory Key property, and each group can be iterated to get the elements in that group.
The normal pattern for working with groups once they are generated is to use a nested foreach loop; the first enumerates the groups, and then an inner loop iterates the elements. The general pattern is

Specifying a Key to Group By
During evaluation, all elements that share common key values as evaluated by the keySelector expression will be grouped. Value equality is determined using the default Equals operator, although this behavior can be overridden by specifying a custom equality comparison function, as seen shortly.
The keySelector expression can be any expression that evaluates a consistent return result for the desired grouping scheme. It is often a single field value from the source collection, but it can be as complex as needed. Listing 4-1 demonstrates how to group using the first three characters of a set of strings (the final groupings are shown in Output 4-1).
Listing 4-1. Elements that share the same return key value from the key selector function will be grouped—see Output 4-1

Output 4-1

Handling Null Values in keySelector Expressions
Some care when writing the key selector is required for handling null values in the source data. The code shown in Listing 4-1 will fail if any of the part-number strings are null in value the moment the Substring method is attempted. Null values are safely handled in general, but if the range variable is processed within the key selector function, the normal null handling rules apply. Thus it is necessary to confirm an element isn’t null before attempting to access properties or call methods on these range variables.
The following code throws a NullReferenceException when the query q is first accessed for iteration:

To protect against this circumstance, check the key selection expression for null values and throw all those elements into a group of your choosing to keep the exception from being thrown and to allow the null grouping to be orderly processed, as the following code demonstrates:

The ternary operator (?) and the null-coalescing operator (??) offer a convenient syntax for handling potential null values in the keySelector expression. Listing 4-2 demonstrates their use in protecting against a null property value. In this case both operators handle the State property being null and groups these elements under the key value string of (null).
Listing 4-2. Example of using the null-coalescing operator and the ternary operator to protect keySelector expressions from null values

Grouping by Composite Keys (More Than One Value)
To group using more than one value as the key (often referred to as a composite key), you specify the grouping selector clause as an anonymous type (anonymous types are introduced in Chapter 2, “Introducing LINQ to Objects”). Any number of key values can be specified in this anonymous type, and any element that contains identical values will dutifully be co-located in a group.
Listing 4-3 demonstrates the simplicity of specifying multiple key values in the group by expression. In this case, the LastName and the State fields are used for grouping, placing all contacts with the same last name from the same state in a group. The Console output from this example is shown in Output 4-2.
Listing 4-3. Anonymous types can be used to group by more than one value (composite key)—see Output 4-2
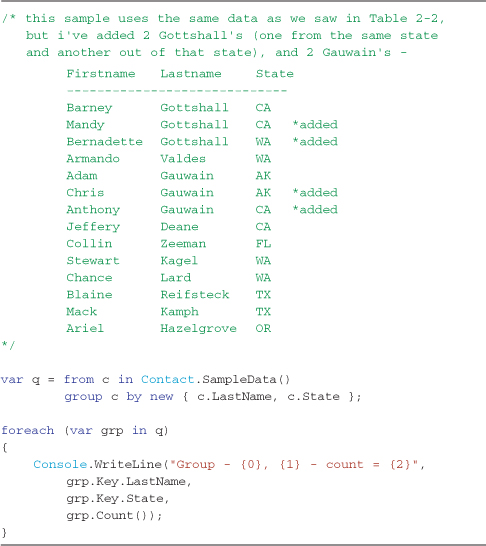
Output 4-2

It is not essential to use an anonymous type as the grouping key selector to achieve multiple-property groups. A named type containing all of the properties participating in the key can be used for the same purpose, although the method is more complex because the type being constructed in the projection needs a custom override of the methods GetHashCode and Equals to force comparison by property values rather than reference equality. Listing 4-4 demonstrates the mechanics of creating a class that supports composite keys using the fields LastName and State. The results are identical to that shown in Output 4-2.
Note
Writing good GetHashCode implementations is beyond the scope of this book. I’ve used a simple implementation in this example—for more details see the MSDN article for recommendations of how to override the GetHashCode implementation available at http://msdn.microsoft.com/en-us/library/system.object.gethashcode.aspx.
Listing 4-4. Creating a composite join key using a normal class type

Specifying Your Own Key Comparison Function
The default behavior of grouping is to equate key equality using the normal equals comparison for the type being tested. This may not always suit your needs, and it is possible to override this behavior and specify your own grouping function. To implement a custom comparer, you build a class that implements the interface IEqualityComparer<T> and pass this class as an argument into the GroupBy extension method.
The IEqualityComparer<T> interface definition has the following definition:
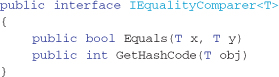
The Equals method is used to indicate that one instance of an object has the same equality to another instance of an object. Overriding this method allows specific logic to determine object equality based on the data within those objects, rather than instances being the same object instance. (That is, even though two objects were constructed at different times and are two different objects as far as the compiler is concerned, we want them to be deemed equal based on their specific combination of internal values or algorithm.)
The GetHashCode method is intended for use in hashing algorithms and data structures such as a hash table. The implementation of this method returns an integer value based on at least one value contained in the instance of an object. The resulting hash code can be used by other data structures as a unique value (but not guaranteed unique). It is intended as a quick way of segmenting instances in a collection or as a short-cut check for value equality (although a further check needs to be carried out for you to be certain of object value equality). The algorithm that computes the hash code should return the same integer value when two instances of an object have the same values (in the data fields being checked), and it should be fast, given that this method will be called many times during the grouping evaluation process.
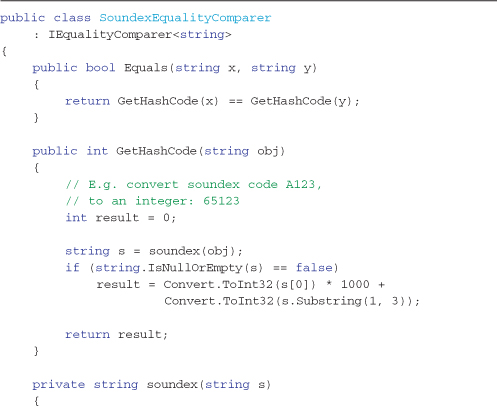
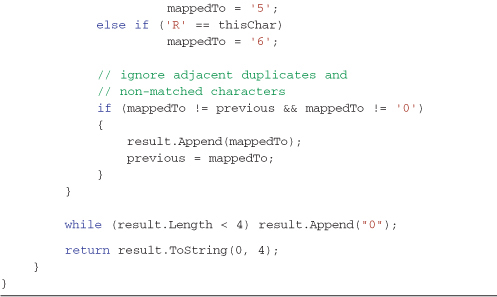
The following example demonstrates one possible use of a custom equality comparer function in implementing a simple Soundex comparison routine (see http://en.wikipedia.org/wiki/Soundex for a full definition of the Soundex algorithm) that will group phonetically similar names. The code for the SoundexEqualityComparer is shown in Listing 4-5. Soundex is an age-old algorithm that computes a reliable four character string value based on the phonetics of a given word; an example would be “Katie” is phonetically identical to “Katy.”
The approach for building the Soundex equality operator is to
- Code the Soundex algorithm to return a four-character string result representing phonetic sounding given a string input. The form of the Soundex code is a single character, followed by three numerical digits, for example A123 or V456.
- Implement the
GetHashCodefor a given string. This will call the Soundex method and then convert the Soundex code to an integer value. It builds the integer by using the ASCII value of the character, multiplying it by 1000 and then adding the three digit suffix of the Soundex code to this number, for example A123 would become, (65 × 1000) + 123 = 65123. - Implement the
Equalsmethod by callingGetHashCodeon both input argumentsxandyand then comparing the return integer results. Return true if the hash codes match (GetHashCodecan be used in this implementation of overloading theEqualsoperator because it is known that the Soundex algorithm implementation returns a unique value—this is not the case with otherGetHashCodeimplementations).
Care must be taken for null values and empty strings in deciding what behavior you want. I decided that I wanted null or empty string entries to be in one group, but this null handling logic should be considered for each specific implementation. (Maybe an empty string should be in a different group than null entries; it really depends on the specific situation.)
Listing 4-5. The custom SoundexEqualityComparer allows phonetically similar sounding strings to be easily grouped

Listing 4-6 demonstrates using a custom equality comparer (in this case SoundexEqualityComparer). The Console output is shown in Output 4-3.
Listing 4-6. Calling code of the new SoundexEqualityComparer used for grouping phonetically similar names—see Output 4-3

Output 4-3

Projecting Grouped Elements into a New Type
The general group by function when using query expression syntax returns the same element type as the source collection elements. (The workaround is to use query continuation, which is discussed later in the chapter.) If you would like the grouped elements to be in a different form, you must use the extension method syntax and specify your own “element selector” expression. The element selector expression takes an instance of the original element and returns a new type based on the supplied expression.
Listing 4-7 demonstrates how to group Contact records by state and return a group of strings rather than a group of Contact instances for each element (Contact is the original element type). In this case, a string is returned by concatenating the contact’s first and last name. The Console output result is shown in Output 4-4.
Listing 4-7. Group elements can be projected to any type. This sample projects group elements as a string type, rather than the default Contact instance—see Output 4-4
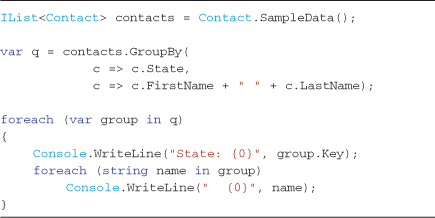
Output 4-4

To demonstrate a slightly more complicated example, Listing 4-8 demonstrates projecting each group element into an anonymous type. This example also shows how to use the Null-Coalescing Operator to handle missing data in either the grouping predicate or the element projection expression. The Console output is shown in Output 4-5.
Listing 4-8. Grouping elements and projecting into an anonymous type and how to handle null values using the null-coalescing operator—see Output 4-5

Output 4-5

How to Use Grouping Results in the Same Query (Query Continuation)
It is possible to use grouping results as a local variable within the same query by appending the into clause after the group when using the query expression syntax (when using extension method syntax, you just continue your query from the result of the GroupBy extension method). The into clause projects the grouping result into a local variable that you can reference throughout the rest of the query expression, giving you access to the key values and the grouped elements.
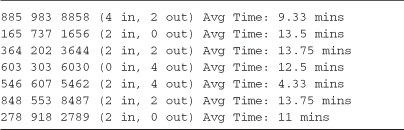
The simplest form of query continuation using groups is for providing aggregation results within the query’s select projection clause. Listing 4-9 demonstrates how to calculate various subtotals for a set of grouped data. This example aggregates the CallLog data introduced in Chapter 2 (Table 2-2) by first grouping by the call phone number; continuing the query with the into keyword; and then projecting subtotals, counts, and averages into an anonymous type. The Console results are shown in Output 4-6.
Listing 4-9. Query continuation allows you to calculate various aggregation values for each group (think subtotaling)—see Output 4-6
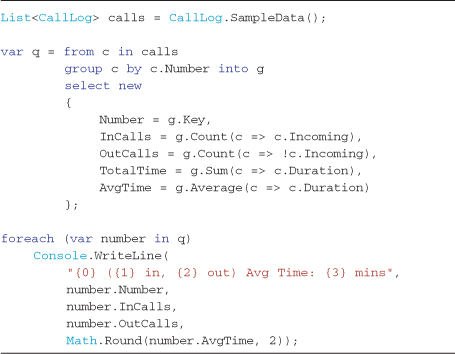
Output 4-6
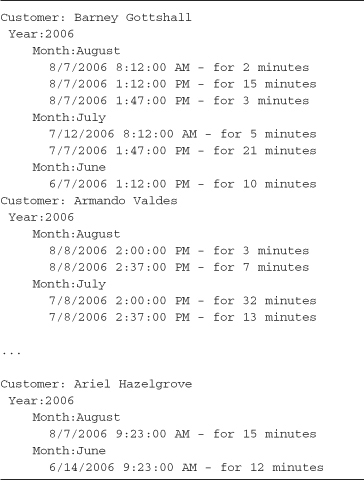
Query continuation allows very complex rollup analysis to be performed on grouped data with any level of nesting. Listing 4-10 demonstrates how to group two levels deep. This query groups phone calls by year and month for each customer record in the source collection. (The sample data used can be seen in Chapter 2, Tables 2-1 and 2-2.) The groupings are captured in an anonymous type field (YearGroup and MonthGroup), and these are accessible when iterating the result sequence using nested foreach loops. The Console output of this code is shown in Output 4-7.
Listing 4-10. The example demonstrates grouping data multiple levels deep—see Output 4-7


Output 4-7
How to Join with Data in Another Sequence
The basis of any Relational Database Management System (DBMS) is the ability to draw together data from multiple sources (tables generally) as the result of a query; this is called “Joining” data. In relational databases, the joins are most often between primary key and foreign key-related columns, but a join can be achieved on any data as long as both data sources share a common column value. One fundamental reason for splitting data into multiple sources is to avoid duplicating data—this process is called normalization by database developers.
Although the concept of joining in-memory collections isn’t a common pattern today (it’s more likely that you nest a collection inside another object to indicate a parent-child relationship), LINQ to Objects introduces the concept of joining multiple data sources through its powerful Join and GroupJoin operators and their equivalent query expression syntax options. LINQ also enables join-like functionality by using a subquery expression within the Select clause. This subquery style of coding is often simpler to read and helps you avoid having to use any specific Join syntax in the query at all. Both techniques are covered in the examples throughout this chapter.
There are three basic styles of Joins that are commonly used when drawing together data from multiple sources based on a shared key value:
• Cross Join—Every element in the first sequence (the outer) is projected with every element in the second sequence (the inner), often called the Cartesian Product. An example use for this type of join is when you want to systematically access each pixel in a bitmap by x and y locations.
• One-to-One Inner Join—This type of join allows you to access data in both sequences based on a common column value. The resulting sequence is flat (there is no subgroup). An example use for this type of join is when you want to access data from another sequence to extend the data you have on some element.
• One-to-Many Join—This type of join allows you to use the first sequence record as a key for a subgroup sequence where a given column value is used as the referential key. An example of this type of join is having a list of orders for a set of given customers.
There are numerous ways in LINQ to achieve each of these join types. Each technique and its relative merit are discussed next.
Cross Joins
Cross joins project every element in one sequence against every element in a second sequence. Cross joins in LINQ to Objects ironically aren’t implemented using either of the Join operators, but rather a clever use of the SelectMany operator. The query expression syntax will be familiar (not identical) to anyone with knowledge of standard SQL joins. In LINQ query expression syntax, you simply specify multiple from statements, as shown in the following code:

The result from this query will be the Cartesian Product, which is a fancy term for all values in the outer range, x (with values 1, 2, and 3) against each value in the inner range, y (with values 1, 2, and 3) as shown in the following result:
![]()
The following code, which is identical to the previous query except that it is written in extension method syntax, shows how the query expression syntax (using multiple from statements) is mapped to the SelectMany operator. The result that it yields is identical as well:

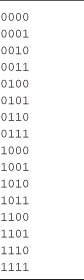
Cross joins allow you to expand the matrix of values, every combination of values between two or more sequences. There is no limit to the number of sequences that can participate in the cross-product operation. Listing 4-11 demonstrates how a binary sequence can be created by using a cross-join combination of four sequences. Output 4-8 shows the result, a sequence of every binary value for a 4-bit number. This might be useful when generating all combinations of a test case.
Listing 4-11. Any number of sequences can participate in a cross join. Every element will be projected against every element of included sequences—see Output 4-8

Output 4-8
Another common cross-join example is accessing every pixel in a bitmap, from 0 to the bitmap’s width (x) and 0 to the height (y) index position. The following code demonstrates how to combine a cross join and the Range operator to achieve access to every pixel in a bitmap:
A cross join can also be used to achieve a one-to-one join by creating every permutation between two collections and then filtering all but those elements that share a key value; although as you will see, this is generally the worst performing technique for this purpose in LINQ to Objects.
One-to-One Joins
A one-to-one join allows data from two different sequences related to each other by a common key value to be accessible in the select projection of a query. One-to-one joins are very commonplace in relational database systems, where the central theme is separating data into multiple tables related by parent and child key relationships. This process is called normalization. Although LINQ to Objects supports most of the common join types available in a relational database, it is not always the most efficient way to work with large volumes of data.
Note
A relational database will out-perform LINQ to Objects in cases where data volume is large. The join features across object collections should be used for local fine-tuning of data retrieved from a database, not in place of that database engine.
There are a number of ways to achieve one-to-one joins using LINQ, which include
• Using the join (or Join) operator
• Using a subquery in the select projection
• Using the SingleOrDefault operator in the select projection
• Using a cross join with a where filter
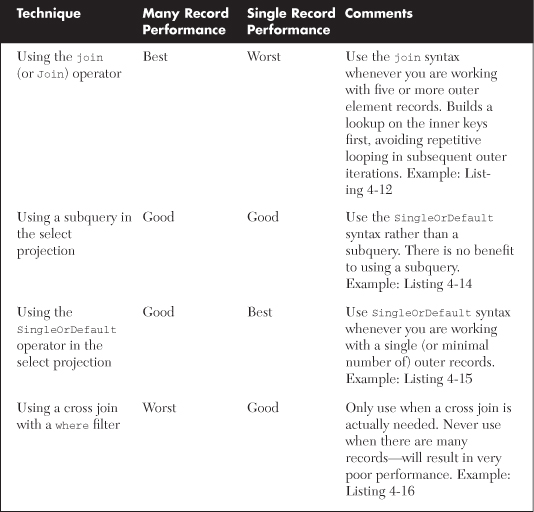
Each technique for one-to-one joining is covered in detail in this section, including the relative performance of each (summarized in Table 4-1 and described in detail later in this chapter in the “One-to-One Join Performance Comparisons” section).
Table 4-1. One-to-One Join Techniques and Their Performance Comparisons
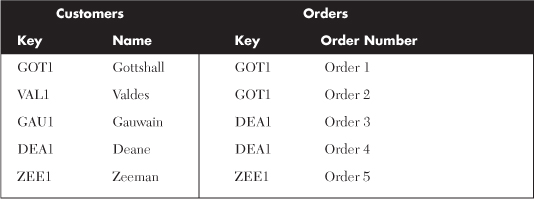
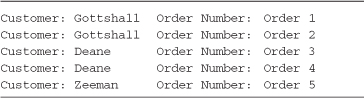
To add clarity it is necessary to depart from our running example data and use a very simple set of sample data to allow you to focus on the mechanics of the join syntax. Table 4-2 lists the sample data used throughout the rest of this chapter unless otherwise specified. The key field in this case is a string type, but any type can be used (integer values for instance if you retrieved data from primary keys in a database table).
Table 4-2. Sample Data Used for Demonstrating Joining Multiple Data Sources
The join (or Join) Operator
The simplest join of this type is built using the join operator in the query expression syntax, or the Join operator in extension method syntax. The query expression syntax for a join takes the following general form:

To understand the behavior of this operator, the following code shows a basic example of linking two arrays of strings:

![]()
Notice that any outer element with a matching inner element is included in the result sequence, and the select projection has access to both strings in this case (s1 and s2). Also notice that any elements where the key values didn’t match are skipped. This is called an inner join by relational database dictionaries, and you can simply think of it in these terms: Any record without a matching key value (a null key value for instance) is skipped.
To demonstrate how to use the join syntax over the data shown in Table 4-2, Listing 4-12 shows how to achieve an inner join from an order(s) to access all the customer data (in this case to retrieve the LastName property in the Select projection). The output from this code is shown in Output 4-9.
Listing 4-12. Simple join example between two collections—see Output 4-9. Notice there are no entries for Valdes or Gauwain.

Output 4-9

Simulating Outer Joins—Getting Unmatched Elements
Outer joins differ from inner joins in the way they handle missing and unmatched values. An outer join will return a result for outer elements that have no matching inner elements, whereas these elements would be skipped when using an inner join (as demonstrated in Listing 4-12).
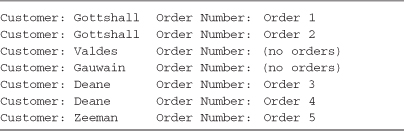
To carry out an outer-join style query in LINQ to Objects, the DefaultIfEmpty standard query operator is used in the from clause of a join, and the null value generated by this operator handled in the select projection. Although this sounds difficult, Listing 4-13 demonstrates an outer join using the sample data shown in Table 4-2, which generates the Console output shown in Output 4-10. This query is a little ambiguous at first glance, but in essence it injects a null element (the default value for an instance of Order type) for any Customer element that would have been removed by the inner join. This propagates a null value for order that any subsequent code working with that result property can process. In this example the ternary operator in the Console.WriteLine statement is catching and handling the null values by replacing those results with the string "(no orders)".
Listing 4-13. Structuring the query for an outer join where all outer-sequence records are returned, even though they have no orders—see Output 4-10

Output 4-10
The alternative to handling the null values in all places that will process the query result, is to handle the null instances in the actual select projection of the query itself, avoiding duplication of null handling code. The following example demonstrates this technique and produces the identical result shown in Output 4-10:

Joining by Composite Keys (More Than One Value)
Similar in approach to how multiple values can be used to specify the key value for grouping, composite keys are supported for joins by using anonymous types (see Listing 4-3 for an example of grouping by composite key). In the case of joins, two anonymous types must be specified for the inner and outer keys as defined by the arguments on either side of the equals keyword.
The following example performs a one-to-one inner join between two in-memory collections. The key values used for joining are phone number and extension, combined using an anonymous type.

The anonymous types must match exactly—in property names and property order. In the previous example, it was necessary to specifically name the phone property because that property wasn’t the same name in both collections; Extension was the same, so the property name in the initializer could be omitted. (The compiler inferred the name to be Extension for this field.)
How Join Works
The query expression join syntax (like all the query expression keywords) map to the extension method appropriately named Join. This extension method takes two sequences (one as an extension method source outer, the other as an ordinary argument inner), two key selection functions (one for each source), and a result selection function. The Join extension method signature takes the following form:

To understand how the Join operator works, the basic pseudo-code it carries out is as follows:
- Create a grouping on the inner sequence for all elements that share the same inner key selector function value (as determined by the
innerKeySelectorargument). Call this list of groups lookup. - Iterate the outer sequence. Call each current element item.
a. Create a grouping on the lookup sequence for all elements that share the same outer-key selector function value as this item (as determined by the
outerKeySelectorargument). If acomparerargument is supplied, use thiscomparerto calculate the equality.b. If there are any items in this grouping result
i. Loop through all elements in this group
ii. Yield the result returned by the result selector on each element (using the
resultSelectorargument)
The returned sequence will be in the order of the outer sequence elements, one record for each matching inner element, followed by the next outer element’s records. Outer elements without matching inner elements will be skipped. (I think you get that point by now—this is an inner join. If you want the unmatched elements, see the “Simulating Outer Joins—Getting Unmatched Elements” section.)
The key selection expression for the outer and inner sequence can be any expression that evaluates to a comparable type. The equals operator (what is called when you do an == evaluation) will determine if the keys are equal or a custom IEqualityComparer can be supplied to customize this equality comparison in the same way a custom equality comparer was used in the grouping examples earlier in this chapter. (See the “Specifying Your Own Key Comparison Function” section.)
From the final query select projection, you have access to both sequences’ matching elements. The range variable can be used for both the inner and outer records throughout the query and referenced within the select projection expression to create a new type or an anonymous type.
One-to-One Join Using a Subquery
A subquery in a queries Select projection can achieve a one-to-one join. In testing, this option did not perform as well as the alternatives and should only be considered for very small (less than ten-element) sequence sizes. This technique simply looks up related data from a second sequence within the first query’s select projection. Listing 4-14 demonstrates the subquery technique, and the result is shown in Output 4-11.
Listing 4-14. One-to-One Join using Subquery syntax—see Output 4-11

Output 4-11
One-to-One Join Using SingleOrDefault Operator
The SingleOrDefault standard query operator returns the single matching element from another sequence or null if a matching value cannot be found (if more than one matching element is found, an exception is thrown). This is ideal for looking up a matching record in another sequence and making that data accessible to your query—in other words, a one-to-one join. This technique is fast and clean when looking up only a single or a few related records.
Listing 4-15 demonstrates a one-to-one join using the SingleOrDefault technique, which generates the output shown in Output 4-11.
Listing 4-15. One-to-One Join using the SingleOrDefault operator—see Output 4-11

One-to-One Join Using Cross Join
This join type matches traditional relational database join techniques. However, because LINQ to Objects doesn’t optimize the query (by maintaining indexes, building statistics, rewriting queries, and so on) like most good database server products, one-to-one joins using cross joins should be avoided because performance is poor and the alternatives previously shown are just as easy.
This technique cross joins two sequences to get the Cartesian Product (every element against every element) and then uses a where clause to keep only the matching outer and inner records. This achieves the goal of a one-to-one join, but at great expense in performance due to the number of elements enumerated and never passing the filter criteria. Use this technique sparingly and only if collection sizes are very small.
Listing 4-16 demonstrates a one-to-one join using the cross join/where technique and generates the code shown in Output 4-12.
Listing 4-16. One-to-one join using a cross join and where filter—see Output 4-12

Output 4-12

One-to-One Join Performance Comparisons
Choosing the most appropriate join technique will yield large performance gains as collection size grows. To have some guidance on which technique makes sense, a simple experiment is necessary (results of such an analysis are summarized in Table 4-1). As mentioned earlier, a database management system (such as SQL Server, MySQL, and Oracle) should be used when joining large amounts of data, and although you can join in-memory using LINQ to Objects, you should exhaust other opportunities first if high performance on larger data sets is a requirement.
One-to-one join performance is primarily dependent on how many different elements will need to be looked up from the inner sequence and how often that is necessary. The Join operator builds a lookup list of all inner sequence keys ahead of time. If many of these keys are then used in the outer sequence, this step aids performance; if only a few of the inner elements will ever be eventually looked up (because there are only a few outer records), then this step actually harms performance. You will need to examine the likely number of records in both the inner and outer sequences. In the small set of test data used for this profiling example, it was evident that five records or more was the sweet-spot for building this lookup table in advance. Though if the number of records in the inner sequence grows, so will the sweet-spot—you must test given your own sequence sizes, and consider their likely growth over time.
The experimental approach used in this test was to simply run a large number of join iterations over some sample data and determine the total elapsed time. Each of the four different techniques were tested for all records in an outer sequence and a single record in the outer sequence (by adding a where clause for a single element).
To measure the elapsed time, a simple helper method was written that takes an action delegate and measures the elapsed time of calling that delegate a given number of times (iterations):

This helper function is called by specifying an action inline, such as
![]()
In this example, q1 is our LINQ to Objects query under test. The method ToList is called on this query to ensure that the full sequence is yielded, meaning that every result element is processed avoiding deferred execution making all queries appear instant.
Each Join technique has a different performance profile for the two most basic scenarios:
- The outer sequence has many records, and you want all of them—An example of this scenario is when you are binding the full sequence of results to a grid or other repeater control. For example, the following code demonstrates a one-to-one join where outer collection has many records:

- The outer sequence has only a few records, either by count or because of a strict where clause (targeting a single record is the most common)—An example of this scenario is when you are looking up a single record for editing purposes. For example, the following code demonstrates a one-to-one join where a single record is isolated in the outer collection:

The actual code for each join type has been presented previously in this chapter (see Listings 4-12, 4-14, 4-15, and 4-16). A second set of each join type technique was tested, with the addition of a tight where clause filter to look up a single record (our second scenario).
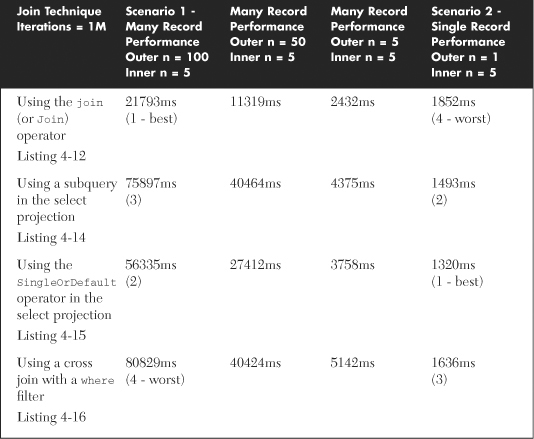
The test data used for this experiment is small—up to 100 orders and 5 customers (for a full listing, see Table 4-2). This is an unrealistic size of data, but it does provide a stable platform for understanding relative performance characteristics. This experiment is looking at how the relationship between outer and inner sequence collection size impacts query performance. Table 4-3 shows the results of this experiment.
Table 4-3. One-to-One Join Techniques and Their Performance Comparisons Using 1M Iterations
Note
The actual numbers in seconds are highly subject to hardware and available memory; they are shown here for relative purposes only. This experiment is to differentiate performance of the different join techniques.
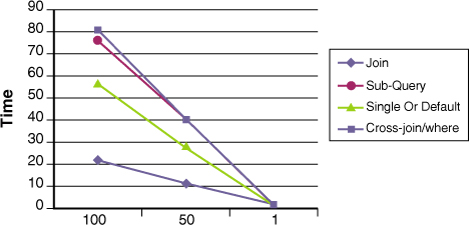
Plotting the results for 100, 50, and 1 demonstrates how linear the performance characteristic is against outer loop count. The join syntax always wins until the outer sequence size drops to below five. However, when the outer-sequence count is less than five, all syntax options are instant unless you are running one million iterations.
From this simple experiment, some conclusions can be drawn:
• Use the Join syntax for all one-to-one scenarios unless the outer sequence has less than five elements
• Use the SingleOrDefault syntax when the outer-sequence size is less than five elements and the number of iterations is in the hundreds of thousands.
Figure 4-1. Different one-to-one Join techniques. Time taken for 1M iterations against an outer sequence of 100, 50, and 1 element count. Join syntax is faster until around an outer-sequence size of five elements.
• Never use the cross join/where syntax for one-to-one joins. Enumerating every combination of element versus element only to filter out all but a few results impacts performance in a big way.
• Use a relational database system for large volume join operations where possible.
One-to-Many Joins
A one-to-many join allows a subgroup collection of related elements to a parent element in another sequence. The most common example of a one-to-many join is a listing of Customers, each with a collection of Orders. The same caveat applies to one-to-many joins as warned in one-to-one joins. LINQ to Objects will not perform joins as well as a relational database system like SQL Server. Joining data is what DBMSs are good at, and although you can perform these joins in LINQ to Objects, it should be reserved for small data volumes. Do the heavy lifting in SQL Server and fine-tuning in LINQ to Objects.
There are a number of ways to achieve one-to-many joins using LINQ, and these include
• Using the join/into combination (or GroupJoin) operator
• Using a subquery in the select projection
• Using the ToLookup operator
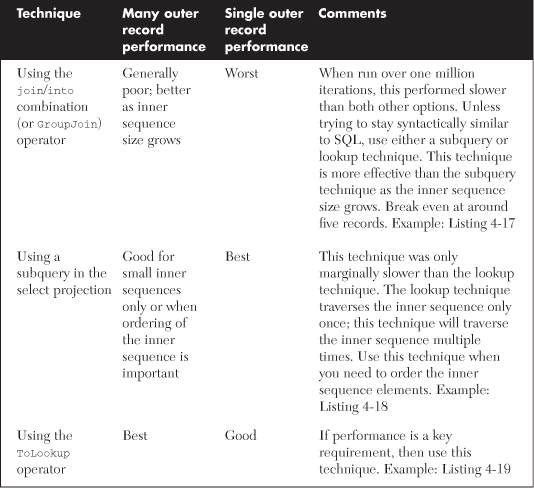
Each of these approaches are covered in detail next, including their performance behavior, but Table 4-4 summarizes the different performance traits for each syntax when working with many records at one time or only joining to a single record.
Table 4-4. One-to-Many Join Techniques and Their Performance Comparisons
The identical sample data used in the previous section on one-to-one joins (Table 4-2) will continue to be used throughout this section unless otherwise specified.
The join/into (GroupJoin) Operator
A small variation of the query expression join syntax allows joined records to be captured in a subgroup. Adding an into keyword after the join is similar to query continuation as discussed earlier in this chapter in the “How to Use Grouping Results in the Same Query (Query Continuation)” section. The result yields a single element for every outer record, and within these elements, a grouping of joined (related) records.
Listing 4-17 demonstrates how to achieve a one-to-many group relationship using the join and into keyword combination. The Console output is shown in Output 4-13. The into keyword captures each group, and this group can be accessed in the select projection and subsequently accessed as a property of each result element.
Listing 4-17. One-to-Many Join using the join/into keyword combination—see Output 4-13

Output 4-13

How join/into Works
The join/into keyword combination in query expression syntax maps to the GroupJoin standard query operator. The GroupJoin operator returns a sequence of inner elements with a matching key value for every outer element in a sequence. Unlike the pure join syntax, every outer-sequence element will have a represented group sequence, but those without matching inner-sequence elements will have an empty group. The GroupJoin extension method signature takes the following form:

The pseudo-code for this operator is similar to the Join operator, except the groupings, rather than the individual elements in each group, are returned. The pseudo-code for GroupJoin is
- Create a grouping on the inner sequence for all elements that share the same inner-key selector function value (as determined by the
innerKeySelectorargument). Call this list lookup. - Iterate the outer sequence. Call each current element item.
a. Create a grouping from the key of the lookup sequence for all elements that share the same outer-key selector function result each item returns (as determined by the
outerKeySelectorargument, and thecomparerequality comparer argument if specified).b. Yield the result by passing each item and the grouping to the
resultSelectorargument.
The returned sequence will be in the order of the outer-sequence elements, although it can be changed by any combination of order by clauses as required. The order of the elements in each group will be the same as the inner sequence, and if you want to change the order of the inner-sequence elements, consider using a subquery in the select projection with specific order by clauses instead of the GroupJoin syntax.
The key selection expression for the outer and inner sequence can be any expression that evaluates to a comparable type. The equals operator (what is called when you do an == evaluation) will determine if the keys are equal or a custom IEqualityComparer can be supplied to customize this equality comparison in the same way a custom equality comparer was used in the grouping examples in the “Specifying Your Own Key Comparison Function” section earlier in this chapter.
Using the extension method syntax for joins is almost never required (almost never—if you need a custom equality comparer, you have no choice). To demonstrate how a join/into query expression maps to the equivalent extension method syntax code, the following code is functionally equivalent to that shown in Listing 4-17:

One-to-Many Join Using a Subquery
A subquery in a query’s select projection can achieve a one-to-many join. If targeting a single record (or a small number, say less than five outer records), this technique performs adequately and is easy to read. Listing 4-18 demonstrates using a subquery for a one-to-many join, and this code produces the Console output shown in Output 4-14.
Listing 4-18. One-to-Many Join using a subquery in the select projection—see Output 4-14

Output 4-14

One-to-Many Join Using the ToLookup Operator
The ToLookup standard query operator builds an efficient lookup list based on a key selection function. The result is similar to a Hashtable, however the ToLookup operator returns a sequence for each key value rather than for a single element. Many of Microsoft’s standard query operators use ToLookup internally to perform their tasks, and it is a convenient helper method in all manner of programming problems. It was surprising in testing to find that by using this operator, a major performance gain was achieved over the other one-to-many techniques. An added advantage of creating your inner-sequence grouping first is that the result can be used multiple times across multiple queries. Listing 4-19 demonstrates how to achieve a one-to-many join using the ToLookup operator; this code produces the identical output to that shown in Output 4-14.
Listing 4-19. One-to-Many Join using the ToLookup Operator—see Output 4-14

One-to-Many Join Performance Comparisons
As seen in one-to-one joins, choosing the correct join technique is critical when working with large collection sizes, and the same holds true for one-to-many joins. The guidance offered here is in not a substitute for running tests on your own queries and data, however the guidance offered in Tables 4-4 and 4-5 show some critical join types to avoid. A database system is the best tool for undertaking joins over larger records sets; small data sizes work fine, but if performance is a critical requirement, exhaust all options of joining the data at the source database before using LINQ to Objects.
To derive the performance guidance for one-to-many joins, do a simple experiment of using the three different join techniques over a large number of iterations and measuring the total time. (For the experiment details, see the “One-to-One Join Performance Comparisons” section earlier in this chapter.) Each join technique has a different performance profile for the two most basic scenarios:
- The outer sequence has many records—An example of this scenario is when you are binding the full sequence of results to a grid or other repeater control and summarizing the results of a related set of records. For example, the following code demonstrates a one-to-many join where outer collection has many records:

- The outer sequence has only a few records, either by count or because of a strict
whereclause (targeting a single record is the most common)—An example of this scenario is when you are looking up a single record for editing purposes. For example, the following code demonstrates a one-to-many join where a single record is isolated in the outer collection:
Table 4-5. One-to-Many Join Techniques and Their Performance Comparisons Using 1M Iterations
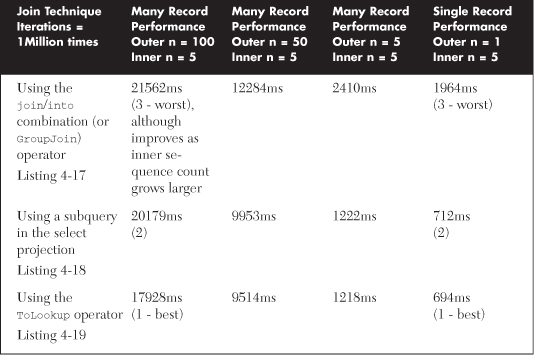
The actual code for each join type has been presented previously in this chapter (see Listings 4-17, 4-18, and 4-19). A second set of each join type technique was tested, with the addition of a tight where clause filter to lookup a single record (our second scenario). Each join type is measured with the collection sizes ranging from 1, 5, 50, and 100 elements for each collection.
Conclusions can be drawn from these simple experiments:
• Use the ToLookup syntax for all one-to-many scenarios, unless the inner query is complex and easier to achieve with a subquery.
• The join/into syntax is slower than the other techniques and should only be used with small inner sequence counts (it gets superior as inner sequence size grows) or when aggregation operators are going to be used over the join result.
• Use a relational database system for large volume join operations where possible.
Summary
LINQ to Objects offers a variety of features that support grouping and joining multiple sources of data. Although much of the syntax is borrowed from the relational database world, it is important to understand the performance profile when working with larger sequence sizes. Whenever possible, leave grouping and joining of large datasets to a relational database (after all, that is what they are intended to be used for); however, once these results are returned in-memory, feel free to use the power of LINQ to Objects’ suite of grouping and joining functionality to refine the result.