
Chapter 3. Writing Basic Queries
Goals of this chapter:
• Understand the LINQ syntax options.
• Introduce how to write basic queries.
• Demonstrate how to filter, project, and order data using LINQ queries.
The main goal of this chapter is to introduce the basics of writing queries. These basics include the syntax options available for writing queries, how to filter data, how to order data, and how to return the exact result set you want. By the end of this chapter, you will understand how to write the most common query elements and, in the following chapter, you will expand this understanding into the more advanced query features of grouping and joining with other sources.
Query Syntax Style Options
Most previous examples in this book have used the query expression syntax, but there are two styles for writing LINQ queries. Not all operators are available through the query expression syntax built into the C# compiler, and to use the remaining operators (or to call your own operators), the extension method query syntax or a combination of the two is necessary. You will continually need to know both styles of query syntax in order to read, write, and understand code written using LINQ.
• Extension method format (also known as the dot notation syntax)—The extension method format is simply where multiple extension methods are cascaded together, each returning an IEnumerable<T> result to allow the next extension method to flow on from the previous result and so on (known as a fluid interface).

• Query Expression format (preferred, especially for joins and groups)—Although not all standard query operators are supported by the query expression syntax, the benefit to the clarity of code when they are is very high. The query expression syntax is much gentler than the extension method syntax in that it simplifies the syntax by removing lambda expressions and by introducing a familiar SQL-like representation.

• Query Dot syntax (a combination of the two formats)—This format combines a query expression syntax query surrounded by parentheses, followed by more operators using the Dot Notation syntax. As long as the query expression returns an IEnumerable<T>, it can be followed by an extension method chain.

Each query syntax has its own merits and pitfalls, which the following sections cover in detail.
Query Expression Syntax
The query expression syntax provided in C# 3.0 and later versions makes queries clearer and more concise. The compiler converts the query expression into extension method syntax during compilation, so the choice of which syntax to use is based solely on code readability.
Figure 3-1 shows the basic form of query expressions built into C# 3.0.
Figure 3-1. The basic query expression syntax form. The C# 3.0 Language Specification outlines exactly how this form is translated into extension methods for compilation.

Note
The fact that the order of the keywords is different in SQL is unfortunate for those who are SQL masters; however, one very compelling reason for the difference was to improve the developer experience. The From-Where-Select order allows the editing environment (Visual Studio in this case) to provide full Intellisense support when writing the query. The moment you write the from clause, the properties of that element appear as you then write the where clause. This wouldn’t be the case (and isn’t in SQL Server’s query editing tools) if the C# designers followed the more familiar Select-From-Where keyword ordering.
Most of the query expression syntax needs no explanation for developers experienced with other query syntax, like SQL. Although the order is different than in traditional query languages, each keyword name gives a strong indication as to its function, the exception being the let and into clauses, which are described next.
Let—Create a Local Variable
Queries can often be written with less code duplication by creating a local variable to hold the value of an intermediate calculation or the result of a subquery. The let keyword enables you to keep the result of an expression (a value or a subquery) in scope throughout the rest of the query expression being written. Once assigned, the variable cannot be reassigned with another value.
In the following code, a local variable is assigned, called average, that holds the average value for the entire source sequence, calculated once but used in the Select projection on each element:
![]()
The let keyword is implemented purely by the compiler, which creates an anonymous type that contains both the original range variable (element in the previous example) and the new let variable. The previous query maps directly to the following (compiler translated) extension method query:

Each additional let variable introduced will cause the current anonymous type to be cascaded within another anonymous type containing itself and the additional variable—and so on. However, all of this magic is transparent when writing a query expression.
Into—Query Continuation
The group, join, and select query expression keywords allow the resulting sequence to be captured into a local variable and then used in the rest of the query. The into keyword allows a query to be continued by using the result stored into the local variable at any point after its definition.
The most common point into is employed is when capturing the result of a group operation, which along with the built-in join features is covered extensively in Chapter 4, “Grouping and Joining Data.” As a quick preview, the following example groups all elements of the same value and stores the result in a variable called groups; by using the into keyword (in combination with the group keyword), the groups variable can participate and be accessed in the remaining query statement.

Comparing the Query Syntax Options
Listing 3-1 uses extension method syntax, and Listing 3-2 uses query expression syntax, but they are functionally equivalent, with both generating the identical result shown in Output 3-1. The clarity of the code in the query expression syntax stems from the removal of the lambda expression semantics and the SQL style operator semantics. Both syntax styles are functionally identical, and for simple queries (like this example), the benefit of code clarity is minimal.
Listing 3-1. Query gets all contacts in the state of “WA” ordered by last name and then first name using extension method query syntax—see Output 3-1

Listing 3-2. The same query as in Listing 3-1 except using query expression syntax—see Output 3-1

Output 3-1

There are extensive code readability advantages to using the query expression syntax over the extension method syntax when your query contains join and/or group functionality. Although not all joining and grouping functionality is natively available to you when using the query expression syntax, the majority of queries you write will not require those extra features. Listing 3-3 demonstrates the rather clumsy extension method syntax for Join (clumsy in the fact that it is not clear what each argument means in the GroupBy extension method just by reading the code). The functionally equivalent query expression syntax for this same query is shown in Listing 3-4. Both queries produce the identical result, as shown in Output 3-2.
If it is not clear already, my personal preference is to use the query expression syntax whenever a Join or GroupBy operation is required in a query. When a standard query operator isn’t supported by the query expression syntax (as is the case for the .Take method for example), you parenthesize the query and use extension method syntax from that point forward as Listing 3-4 demonstrates.
Listing 3-3. Joins become particularly complex in extension method syntax. This query returns the first five call-log details ordered by most recent—see Output 3-2

Listing 3-4. Query expression syntax of the query identical to that shown in Listing 3-3—see Output 3-2

Output 3-2

How to Filter the Results (Where Clause)
One of the main tasks of a LINQ query is to restrict the results from a larger collection based on some criteria. This is achieved using the Where operator, which tests each element within a source collection and returns only those elements that return a true result when tested against a given predicate expression. A predicate is simply an expression that takes an element of the same type of the items in the source collection and returns true or false. This predicate is passed to the Where clause using a lambda expression.
The extension method for the Where operator is surprisingly simple; it iterates the source collection using a foreach loop, testing each element as it goes, returning those that pass. Here is a close facsimile of the actual code in the System.Linq library:

The LINQ to Objects Where operator seems pretty basic on the surface, but its implementation is simple due to the powerful yield return statement that first appeared in the .NET Framework 2.0 to make building collection iterators easier. Any code implementing the built-in enumeration pattern (as codified by any collection that implements the interface IEnumerable) natively supports callers asking for the next item in a collection—at which time the next item for return is computed (supported by the foreach keyword as an example). Any collection implementing the IEnumerable<T> pattern (which also implements IEnumerable) will be extended by the Where operator, which will return a single element at a time when asked, as long as that element satisfies the predicate expression (returns true).
Filter predicate expressions are passed to the extension method using a lambda expression (for a recap on what a lambda expression is see Chapter 2, “Introducing LINQ to Objects”), although if the query expression syntax is used, the filter predicate takes an even cleaner form. Both of these predicate expression styles are explained and covered in detail in the following sections.
Where Filter Using a Lambda Expression
When forming a predicate for the Where operator, the predicate takes an input element of the same type as the elements in the source collection and returns true or false (a Boolean value). To demonstrate using a simple Where clause predicate, consider the following code:

In this code, each string value from the animals array is passed to the Where extension method in a range variable called a. Each string in a is evaluated against the predicate function, and only those strings that pass (return true) are returned in the query results. For this example, only two strings pass the test and are written to the console window. They are
Spider
Sting-Ray
The C# compiler behind the scenes converts the lambda expression into a standard anonymous method call (the following code is functionally equivalent):
![]()
Where Filter Query Expressions (Preferred)
The query expression where clause syntax drops the explicit range variable definition and the lambda expression operator (=>), making it more concise and more familiar to the SQL-style clauses that many developers understand. It is the preferred syntax for these reasons. Rewriting the previous example using query expression syntax demonstrates these differences, as follows:

Using an External Method for Evaluation
Although you can write queries and inline the code for the filter predicate, you don’t have to. If the predicate is lengthy and might be used in more than one query expression, you should consider putting it in its own method body (good practice for any duplicated code). Rewriting the previous examples using an external predicate function shows the technique:

To further demonstrate this technique with a slightly more complex scenario, the code shown in Listing 3-5 creates a predicate method that encapsulates the logic for determining “a deadly animal.” By encapsulating this logic in one method, it doesn’t have to be duplicated in multiple places in an application.
Listing 3-5. Where clause using external method—see Output 3-3

Output 3-3

Filtering by Index Position
The standard query operators expose a variation of the Where operator that surfaces the index position of each collection element as it progresses. The zero-based index position can be passed into a lambda expression predicate by assigning a variable name as the second argument (after the element range variable). To surface the index position, a lambda expression must be used, and this can only be achieved using the extension method syntax. Listing 3-6 demonstrates the simplest usage, in this case simply returning the first and only even-index positioned elements from the source collection, as shown in Output 3-4.
Listing 3-6. The index position can be used as part of the Where clause predicate expression when using lambda expressions—see Output 3-4

Output 3-4

How to Change the Return Type (Select Projection)
When you write queries against a database system in SQL, specifying a set of columns to return is second nature. The goal is to limit the columns returned to only those necessary for the query in order to improve performance and limit network traffic (the less data transferred, the better). This is achieved by listing the column names after the Select clause in the following format. In most cases, only the columns of interest are returned using the SQL syntax form:
Select * from Contacts
Select ContactId, FirstName, LastName from Contacts
The first query will return every column (and row) of the contacts table; the second will return only the three columns explicitly listed (for every row), saving server and network resources. The point is that the SQL language syntax allows a different set of rows that does not match any existing database table, view, or schema to be the structure used in returning data. Select projections in LINQ query expressions allow us to achieve the same task. If only few property values are needed in the result set, those properties or fields are the only ones returned.
LINQ selection projections allow varied and powerful control over how and what data shape is returned from a query expression.
The different ways a select projection can return results are
• As a single result value or element
• In an IEnumerable<T> where T is of the same type as the source items
• In an IEnumerable<T> where T is any existing type constructed in the select projection
• In an IEnumerable<T> where T is an anonymous type created in the select projection
• In an IEnumberable<IGrouping<TKey, TElement>>, which is a collection of grouped objects that share a common key
Each projection style has its use, and each style is explained by example in the following sections.
Return a Single Result Value or Element
Some of the standard query operators return a single value as the result, or a single element from the source collection; these operators are listed in Table 3-1. Each of these operators end any cascading of results into another query, and instead return a single result value or source element.
Table 3-1. Sample Set of Operators that Return a Specific Result Value Type (covered in Chapters 5 and 6)

As an example, the following simple query returns the last element in the integer array, writing the number 2 to the Console window:
![]()
Return the Same Type as the Source—IEnumerable<TSource>
The most basic projection type returns a filtered and ordered subset of the original source items. This projection is achieved by specifying the range variable as the argument after the select keyword. The following example returns an IEnumerable<Contact>, with the type Contact being inferred from the element type of the source collection:

A more appropriate query would filter the results and order them in some convenient fashion. You are still returning a collection of the same type, but the number of elements and their order will be different.

Return a Different Type Than the Source—IEnumerable<TAny>
Any type can be projected as part of the select clause, not just the source type. The target type can be any available type that could otherwise be manually constructed with a plain new statement from the scope of code being written.
If the type being constructed has a parameterized constructor containing all of the parameters you specifically need, then you simply call that constructor. If no constructor matches the parameter’s needed for this projection, either create one or consider using the C# 3.0 type initializer syntax (as covered in Chapter 2). The benefit of using the new type initializer semantics is that it frees you from having to define a specific constructor each time a new projection signature is needed to cater for different query shapes. Listing 3-7 demonstrates how to project an IEnumerable<ContactName> using both constructor semantics.
Note
Resist the temptation to overuse the type initializer syntax. It requires that all properties being initialized through this syntax be read and write (have a getter and setter). If a property should be read-only, don’t make it read/write just for this feature. Consider making those constructor parameters optional using the C# 4.0 Optional Parameter syntax described in Chapter 8, “C# 4.0 Features.”
Listing 3-7. Projecting to a collection of a new type—constructed using either a specific constructor or by using type initializer syntax


Return an Anonymous Type—IEnumerable<TAnonymous>
Anonymous types is a new language feature introduced in C# 3.0 where the compiler creates a type on-the-fly based on the object initialization expression (the expression on the right side of the initial = sign). Discussed in detail in Chapter 2, this new type is given an uncallable name by the compiler, and without the var keyword (implicitly typed local variables), there would be no way to compile the query. The following query demonstrates projecting to an IEnumerable<T> collection where T is an anonymous type:

The anonymous type created in the previous example is composed of two properties, FullName and YearsOfAge.
Anonymous types free us from having to write and maintain a specific type definition for every different return result collection needed. The only drawback is that these types are method-scoped and cannot be used outside of the method they are declared by (unless passed as a System.Object type, but this is not recommended because property access to this object subsequently will need to use reflection).
Return a Set of Grouped Objects—IEnumerable<IGrouping<TKey,TElement>>
It is possible for LINQ to Objects to group results that share common source values or any given characteristic that can be equated with an expression using the group by query expression keyword or the GroupBy extension method. This topic is covered in great detail in Chapter 4.
How to Return Elements When the Result Is a Sequence (Select Many)
The SelectMany standard query operator flattens out any IEnumerable<T> result elements, returning each element individually from those enumerable sources before moving onto the next element in the result sequence. In contrast, the Select extension method would stop at the first level and return the IEnumerable<T> element itself.
Listing 3-8 demonstrates how SelectMany differs from Select, with each variation aiming to retrieve each individual word within a set of phrase strings. To retrieve the words in Option 1, a sub for loop is required, but SelectMany automatically performs this subiteration of the original result collection, as shown in Option 2. Option 3 demonstrates that the same result can be achieved using multiple from statements in a query expression (which maps the query to use SelectMany operator behind the scenes). The Console output is shown in Output 3-5.
Listing 3-8. Select versus SelectMany—SelectMany drills into an IEnumerable result, returning its elements—see Output 3-5

Output 3-5

How does the SelectMany extension method work? It creates a nested foreach loop over the original result, returning each subelement using yield return statements. A close facsimile of the code behind SelectMany takes the following form:

How to Get the Index Position of the Results
Select and SelectMany expose an overload that surfaces the index position (starting at zero) for each returned element in the Select projection. It is surfaced as an overloaded parameter argument of the selector lambda expression and is only accessible using the extension method query syntax. Listing 3-9 demonstrates how to access and use the index position value in a Select projection. As shown in Output 3-6, this example simply adds a ranking number for each select result string.
Listing 3-9. A zero-based index number is exposed by the Select and SelectMany operators—see Output 3-6

Output 3-6

How to Remove Duplicate Results
The Distinct standard query operator performs the role of returning only unique instances in a sequence. The operator internally keeps track of the elements it has returned and skips the second and subsequent duplicate elements as it returns resulting elements. This operator is covered in more detail in Chapter 6, “Working with Set Data,” when its use in set operations is explored.
The Distinct operator is not supported in the query expression syntax, so it is often appended to the end of a query using extension method syntax. To demonstrate how it is used, the following code removes duplicate strings. The Console output from this code is

How to Sort the Results
LINQ to Objects has comprehensive support for ordering and sorting results. Whether you need to sort in ascending order, descending order using different property values in any sequence, or all the way to writing a specific ordering algorithm of your own, LINQ’s sorting features can accommodate the full range of ordering requirements.
Basic Sorting Syntax
The resulting collection of results from a query can be sorted in any desired fashion, considering culture and case sensitivity. When querying using extension method syntax, the OrderBy, OrderByDescending, ThenBy, and ThenByDescending standard query operators manage this process. The OrderBy and ThenBy operators sort in an ascending order (for example, a to z), and the OrderByDescending and ThenByDescending operators sort in descending order (z to a). Only the first sorting extension can use the OrderBy operators, and each subsequent sorting expression must use the ThenBy operators, of which there can be zero or many depending on how much control you want over the subsorting when multiple elements share equal order after the previous expressions.
The following samples demonstrate sorting a source sequence first by the [w] key, then in descending order by the [x] key, and then in ascending order by the [y] key:
![]()
When using the query expression syntax, each sorting key and the optional direction keyword needs to be separated by a comma character. If the descending or ascending direction keywords are not specified, LINQ assumes ascending order.
![]()
The result from ordering a collection will be an IOrderedEnumerable<T>, which implements IEnumerable<T> to allow further query operations to be cascaded end-to-end.
The ordering extension methods are implemented using a basic but efficient Quicksort algorithm (see http://en.wikipedia.org/wiki/Quicksort for further explanation of how this algorithm works). The implementation LINQ to Objects uses is a sorting type called unstable, which simply means that elements that compare to equal key values may not retain their relative positions to the source collections (although this is simply solved by cascading the result into a ThenBy or ThenByDescending operator). The algorithm is fairly fast, and it lends itself to parallelization, which is certainly leveraged by Microsoft’s investment in Parallel LINQ.
Reversing the Order of a Result Sequence (Reverse)
Another ordering extension method that reverses an entire sequence is the Reverse operator. It is simply called in the form: [source].Reverse();. An important point to note when using the Reverse operator is that it doesn’t test the equality of the elements or carry out any sorting; it simply returns elements starting from the last element, back to the first element. The order returned will be the exact reciprocal of the order that would have been returned from the result sequence. The following example demonstrates the Reverse operator, returning T A C in the Console window:

Case Insensitive and Cultural-specific String Ordering
Any standard query operator that involves sorting has an overload that allows a specific comparer function to be supplied (when written using extension method syntax). The .NET class libraries contain a handy helper class called StringComparer, which has a set of predefined static comparers ready for use. The comparers allow us to alter string sorting behavior, controlling case-sensitivity and current culture (the language setting for the current thread). Table 3-2 lists the static Comparer instances that can be used in any OrderBy or ThenBy ascending or descending query operator. (In addition, see the “Custom EqualityComparers When Using LINQ Set Operators” section in Chapter 6, which is specifically about the built-in string comparers and custom comparers.)
Table 3-2. The Built-in StringComparer Functions to Control String Case Sensitivity and Culture-aware String Ordering

Listing 3-10 demonstrates the syntax and effect of using the built-in string comparer instances offered by the .NET Framework. The Console output is shown in Output 3-7, where the default case-sensitive result can be forced to case-insensitive.
Listing 3-10. Case and culture sensitive/insensitive ordering using StringComparer functions—see Output 3-7
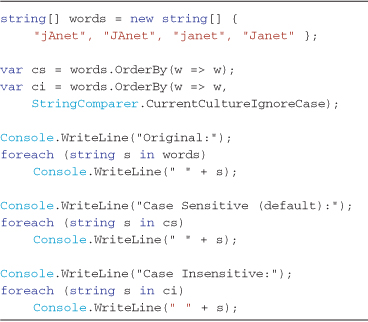
Output 3-7

Specifying Your Own Custom Sort Comparison Function
To support any sorting order that might be required, custom sort comparison classes are easy to specify. A custom compare class is a class based on a standard .NET Interface called IComparer<T>, which exposes a single method: Compare. This interface is not specifically for LINQ; it is the basis for all .NET Framework classes that require sorting (or custom sorting) capabilities.
Comparer functions work by returning an integer result, indicating the relationship between a pair of instance types. If the two types are deemed equal, the function returns zero. If the first instance is less than the second instance, a negative value is returned, or if the first instance is larger than the second instance, the function returns a positive value. How you equate the integer result value is entirely up to you.
To demonstrate a custom IComparer<T>, Listing 3-11 demonstrates a comparison function that simply shuffles (in a random fashion) the input source. The algorithm simply makes a random choice as to whether two elements are less than or greater than each other. Output 3-8 shows the Console output from a simple sort of a source of strings in an array, although this result will be different (potentially) each time this code is executed.
Listing 3-11. Ordering using our custom IComparer<T> implementation to shuffle the results—see Output 3-8

Output 3-8

A common scenario that has always caused me trouble is where straight alphabetical sorting doesn’t properly represent alpha-numeric strings. The most common example is alphabetic sorting strings such as File1, File10, File2. Naturally, the desired sorting order would be File1, File2, File10, but that’s not alphabetical. A custom IComparer that will sort the alphabetic part and then the numeric part separately is needed to achieve this common scenario. This is called natural sorting.
Listing 3-12 and Output 3-9 demonstrate a custom sort class that correctly orders alpha strings that end with numbers. Anywhere this sort order is required, the class name can be passed into any of the OrderBy or ThenBy extension methods in the following way:

The code in Listing 3-12 first checks if either input string is null or empty. If either string is empty, it calls and returns the result from the default comparer (no specific alpha-numeric string to check). Having determined that there are two actual strings to compare, the numeric trailing section of each string is extracted into the variables numericX and numericY. If either string doesn’t have a trailing numeric section, the result of the default comparer is returned (if no trailing numeric section exists for one of the strings, then a straight string compare is adequate). If both strings have a trailing numeric section, the alpha part of the strings is compared. If the strings are different, the result of the default comparer is returned (if the strings are different, the numeric part of the string is irrelevant). If both alpha parts are the same, the numeric values in numericX and numericY are compared, and that result is returned. The final result is that all strings are sorted alphabetically, and where the string part is the same between elements, the numeric section controls the final order.
Listing 3-12. Sorting using a custom comparer. This comparer properly sorts strings that end with a number—see Output 3-9
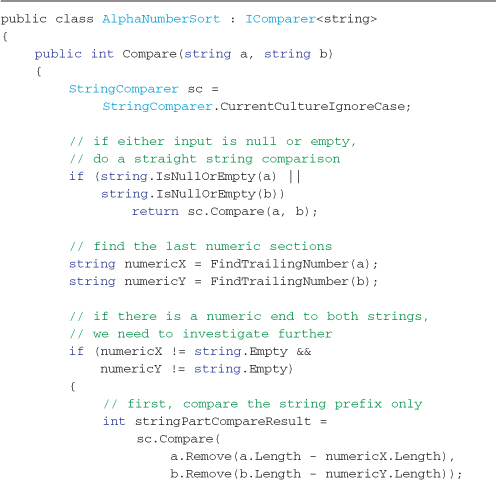


Output 3-9

Note
To achieve the same result in most Windows operating systems (not Windows 2000, but ME, XP, 2003, Vista, and Windows 7) and without guarantee that it won’t change over time (it bears the following warning “Note Behavior of this function, and therefore the results it returns, can change from release to release. It should not be used for canonical sorting applications”), Microsoft has an API that it uses to sort files in Explorer (and presumably other places).

Summary
This chapter has covered the essential query functionality of filtering, ordering, and projecting the results into any resulting form you might require. Once you have understood and mastered these basic query essentials, you can confidently experiment with the more advanced query features offered by the other 40-odd standard query operators and begin writing your own operators if necessary.