
Chapter 21. Advanced Module Topics
This chapter concludes Part V with a collection of more advanced module-related topics—relative import syntax, data hiding, the _ _future_ _ module, the _ _name_ _ variable, sys.path changes, and so on—along with the standard set of gotchas and exercises related to what we’ve covered in this part of the book. Like functions, modules are more effective when their interfaces are well defined, so this chapter also briefly reviews module design concepts, some of which we have explored in prior chapters.
Despite the word “advanced” in this chapter’s title, some of the topics discussed here (such as the _ _name_ _ trick) are widely used, so be sure you take a look before moving on to classes in the next part of the book.
Data Hiding in Modules
As we’ve seen, a Python module exports all the names assigned at the top level of its file. There is no notion of declaring which names should and shouldn’t be visible outside the module. In fact, there’s no way to prevent a client from changing names inside a module if it wants to.
In Python, data hiding in modules is a convention, not a syntactical constraint. If you want to break a module by trashing its names, you can, but fortunately, I’ve yet to meet a programmer who would. Some purists object to this liberal attitude toward data hiding, and claim that it means Python can’t implement encapsulation. However, encapsulation in Python is more about packaging than about restricting.
Minimizing from * Damage: _X and _ _all_ _
As a special case, you can prefix names with a single underscore (e.g., _X) to prevent them from being copied out when a client imports a module’s names with a from * statement. This really is intended only to minimize namespace pollution; because from * copies out all names, the importer may get more than it’s bargained for (including names that overwrite names in the importer). Underscores aren’t “private” declarations: you can still see and change such names with other import forms, such as the import statement.
Alternatively, you can achieve a hiding effect similar to the _X naming convention by assigning a list of variable name strings to the variable _ _all_ _ at the top level of the module. For example:
_ _all_ _ = ["Error", "encode", "decode"] # Export these only
When this feature is used, the from * statement will copy out only those names listed in the _ _all_ _ list. In effect, this is the converse of the _X convention: _ _all_ _ identifies names to be copied, while _X identifies names not to be copied. Python looks for an _ _all_ _ list in the module first; if one is not defined, from * copies all names without a single leading underscore.
Like the _X convention, the _ _all_ _ list has meaning only to the from * statement form, and does not amount to a privacy declaration. Module writers can use either trick to implement modules that are well behaved when used with from *. (See also the discussion of _ _all_ _ lists in package _ _init_ _.py files in Chapter 20; there, these lists declare submodules to be loaded for a from *.)
Enabling Future Language Features
Changes to the language that may potentially break existing code are introduced gradually. Initially, they appear as optional extensions, which are disabled by default. To turn on such extensions, use a special import statement of this form:
featurename
This statement should generally appear at the top of a module file (possibly after a docstring) because it enables special compilation of code on a per-module basis. It’s also possible to submit this statement at the interactive prompt to experiment with upcoming language changes; the feature will then be available for the rest of the interactive session.
For example, in prior editions of this book, we had to use this statement form to demonstrate generator functions, which required a keyword that was not yet enabled by default (they use a featurename of generators). We also used this statement to activate true division for numbers in Chapter 5, and we’ll use it again in this chapter to turn on absolute imports and again later in Part VII to demonstrate context managers.
All of these changes have the potential to break existing code, and so are being phased in gradually as optional features presently enabled with this special import.
Mixed Usage Modes: _ _name_ _ and _ _main_ _
Here’s a special module-related trick that lets you import a file as a module, and run it as a standalone program. Each module has a built-in attribute called _ _name_ _, which Python sets automatically as follows:
If the file is being run as a top-level program file,
_ _name_ _is set to the string"_ _main_ _"when it starts.If the file is being imported,
_ _name_ _is instead set to the module’s name as known by its clients.
The upshot is that a module can test its own _ _name_ _ to determine whether it’s being run or imported. For example, suppose we create the following module file, named runme.py, to export a single function called tester:
This module defines a function for clients to import and use as usual:
python>>>import runme>>>runme.tester( )It's Christmas in Heaven...
But, the module also includes code at the bottom that is set up to call the function when this file is run as a program:
python runme.pyIt's Christmas in Heaven...
Perhaps the most common place you’ll see the _ _name_ _ test applied is for self-test code. In short, you can package code that tests a module’s exports in the module itself by wrapping it in a _ _name_ _ test at the bottom of the file. This way, you can use the file in clients by importing it, and test its logic by running it from the system shell, or via another launching scheme. In practice, self-test code at the bottom of a file under the _ _name_ _ test is probably the most common and simplest unit-testing protocol in Python. (Chapter 29 will discuss other commonly used options for testing Python code—as you’ll see, the unittest and doctest standard library modules provide more advanced testing tools.)
The _ _name_ _ trick is also commonly used when writing files that can be used both as command-line utilities, and as tool libraries. For instance, suppose you write a file finder script in Python. You can get more mileage out of your code if you package it in functions, and add a _ _name_ _ test in the file to automatically call those functions when the file is run standalone. That way, the script’s code becomes reusable in other programs.
Unit Tests with _ _name_ _
In fact, we’ve already seen a prime example in this book of an instance where the _ _name_ _ check could be useful. In the section on arguments in Chapter 16, we coded a script that computed the minimum value from the set of arguments sent in:
This script includes self-test code at the bottom, so we can test it without having to retype everything at the interactive command line each time we run it. The problem with the way it is currently coded, however, is that the output of the self-test call will appear every time this file is imported from another file to be used as a tool—not exactly a user-friendly feature! To improve it, we can wrap up the self-test call in a _ _name_ _ check, so that it will be launched only when the file is run as a top-level script, not when it is imported:
We’re also printing the value of _ _name_ _ at the top here to trace its value. Python creates and assigns this usage-mode variable as soon as it starts loading a file. When we run this file as a top-level script, its name is set to _ _main_ _, so its self-test code kicks in automatically:
python min.pyI am: _ _main_ _ 1 6
But, if we import the file, its name is not _ _main_ _, so we must explicitly call the function to make it run:
import minI am: min >>>min.minmax(min.lessthan, 's', 'p', 'a', 'm')'a'
Again, regardless of whether this is used for testing, the net effect is that we get to use our code in two different roles—as a library module of tools, or as an executable program.
Changing the Module Search Path
In Chapter 18, we learned that the module search path is a list of directories that can be customized via the environment variable PYTHONPATH, and possibly .pth path files. What I haven’t shown you until now is how a Python program itself can actually change the search path by changing a built-in list called sys.path (the path attribute in the built-in sys module). sys.path is initialized on startup, but thereafter, you can delete, append, and reset its components however you like:
import sys>>>sys.path['', 'D:\PP3ECD-Partial\Examples', 'C:\Python25',...more deleted...] >>>sys.path.append('C:\sourcedir')# Extend module search path >>>import string# All imports search the new dir
Once you’ve made such a change, it will impact future imports anywhere in the Python program, as all imports and all files share the single sys.path list. In fact, this list may be changed arbitrarily:
sys.path = [r'd: emp']# Change module search path >>>sys.path.append('c:\lp3e\examples')# For this process only >>>sys.path['d:\temp', 'c:\lp3e\examples'] >>>import stringTraceback (most recent call last): File "<stdin>", line 1, in ? ImportError: No module named string
Thus, you can use this technique to dynamically configure a search path inside a Python program. Be careful, though: if you delete a critical directory from the path, you may lose access to critical utilities. In the prior example, for instance, we no longer have access to the string module because we deleted the Python source library’s directory from the path.
Also, remember that such sys.path settings only endure for the Python session or program (technically, process) that made them; they are not retained after Python exits. PYTHONPATH and .pth file path configurations live in the operating system instead of a running Python program, and so are more global: they are picked up by every program on your machine, and live on after a program completes.
The import as Extension
Both the import and from statements have been extended to allow a module to be given a different name in your script. The following import statement:
is equivalent to:
After such an import, you can (and in fact must) use the name listed after the as to refer to the module. This works in a from statement, too, to assign a name imported from a file to a different name in your script:
This extension is commonly used to provide short synonyms for longer names, and to avoid name clashes when you are already using a name in your script that would otherwise be overwritten by a normal import statement. It also comes in handy for providing a short, simple name for an entire directory path when using the package import feature described in Chapter 20.
Relative Import Syntax
Python 2.5 modifies the import search path semantics of some from statements when they are applied to the module packages we studied in the previous chapter. Some aspects of this change will not become apparent until a later Python release (currently this is planned for version 2.7 and version 3.0), though some are already present today.
In short, from statements can now use dots (“.”) to specify that they prefer modules located within the same package (known as package-relative imports) to modules located elsewhere on the module import search path (called absolute imports). That is:
Today, you can use dots to indicate that imports should be relative to the containing package—such imports will prefer modules located inside the package to same-named modules located elsewhere on the import search path,
sys.path.Normal imports in a package’s code (without dots) currently default to a relative-then-absolute search path order. However, in the future, Python will make imports absolute by default—in the absence of any special dot syntax, imports will skip the containing package itself and look elsewhere on the
sys.pathsearch path.
For example, presently, a statement of the form:
means “from a module named spam located in the same package that this statement is contained in, import the variable name.” A similar statement without the leading dot will still default to the current relative-then-absolute search path order, unless a statement of the following form is included in the importing file:
If present, this statement enables the future absolute default path change. It causes all imports without extra dots to skip the relative components of the module import search path, and look instead in the absolute directories that sys.path contains. For instance, when absolute imports are thus enabled, a statement of the following form will always find the standard library’s string module, instead of a module of the same name in the package:
Without the from _ _future_ _ statement, if there’s a string module in the package, it will be imported instead. To get the same behavior when the future absolute import change is enabled, run a statement of the following form (which also works in Python today) to force a relative import:
Note that leading dots can only be used with the from statement, not the import statement. The import modname statement form still performs relative imports today, but these will become absolute in Python 2.7.
Other dot-based relative reference patterns are possible, too. Given a package named mypkg, the following alternative import forms used by code within the package work as described:
To understand these latter forms better, we need to understand the rationale behind this change.
Why Relative Imports?
This feature is designed to allow scripts to resolve ambiguities that can arise when a same-named file appears in multiple places on the module search path. Consider the following package directory:
This defines a package named mypkg containing modules named mypkg.main and mypkg.string. Now, suppose that the main module tries to import a module named string. In Python 2.4 and earlier, Python will first look in the mypkg directory to perform a relative import. It will find and import the string.py file located there, assigning it to the name string in the mypkg.main module’s namespace.
It could be, though, that the intent of this import was to load the Python standard library’s string module instead. Unfortunately, in these versions of Python, there’s no straightforward way to ignore mypkg.string and look for the standard library’s string module located further to the right on the module search path. We cannot depend on any extra package directory structure above the standard library being present on every machine.
In other words, imports in packages can be ambiguous—within a package, it’s not clear whether an import spam statement refers to a module within or outside the package. More accurately, a local module or package can hide another hanging directly off of sys.path, whether intentionally or not.
In practice, Python users can avoid reusing the names of standard library modules they need for modules of their own (if you need the standard string, don’t name a new module string). But this doesn’t help if a package accidentally hides a standard module; moreover, Python might add a new standard library module in the future that has the same name as a module of your own. Code that relies on relative imports is also less easy to understand because the reader may be confused about which module is intended to be used. It’s better if the resolution can be made explicit in code.
In Python 2.5, we can control the behavior of imports, forcing them to be absolute by using the from _ _future_ _ import directive listed earlier. Again, bear in mind that this absolute-import behavior will become the default in a future version (planned currently for Python 2.7). When absolute imports are enabled, a statement of the following form in our example file mypkg/main.py will always find the standard library’s version of string, via an absolute import search:
You should get used to using absolute imports now, so you’re prepared when the change takes effect. That is, if you really want to import a module from your package, to make this explicit and absolute, you should begin writing statements like this in your code (mypkg will be found in an absolute directory on sys.path):
Relative imports are still possible by using the dot pattern in the from statement:
This form imports the string module relative to the current package, and is the relative equivalent to the prior example’s absolute form (the package’s directory is automatically searched first).
We can also copy specific names from a module with relative syntax:
This statement again refers to the string module relative to the current package. If this code appears in our mypkg.main module, for example, it will import name1 and name2 from mypkg.string. An additional leading dot performs the relative import starting from the parent of the current package. For example:
will load a sibling of mypkg—i.e., the spam module located in the parent directory, next to mypkg. More generally, code located in some module A.B.C can do any of these:
Relative import syntax and the proposed absolute-by-default imports change are advanced concepts, and these features are still only partially present in Python 2.5. Because of that, we’ll omit further details here; see Python’s standard manual set for more information.
Module Design Concepts
Like functions, modules present design tradeoffs: you have to think about which functions go in which modules, module communication mechanisms, and so on. All of this will become clearer when you start writing bigger Python systems, but here are a few general ideas to keep in mind:
You’re always in a module in Python. There’s no way to write code that doesn’t live in some module. In fact, code typed at the interactive prompt really goes in a built-in module called
_ _main_ _; the only unique things about the interactive prompt are that code runs and is discarded immediately, and expression results are printed automatically.Minimize module coupling: global variables. Like functions, modules work best if they’re written to be closed boxes. As a rule of thumb, they should be as independent of global names in other modules as possible.
Maximize module cohesion: unified purpose. You can minimize a module’s couplings by maximizing its cohesion; if all the components of a module share a general purpose, you’re less likely to depend on external names.
Modules should rarely change other modules’ variables. We illustrated this with code in Chapter 16, but it’s worth repeating here: it’s perfectly OK to use globals defined in another module (that’s how clients import services, after all), but changing globals in another module is often a symptom of a design problem. There are exceptions, of course, but you should try to communicate results through devices such as function argument return values, not cross-module changes. Otherwise, your globals’ values become dependent on the order of arbitrarily remote assignments in other files, and your modules become harder to understand and reuse.
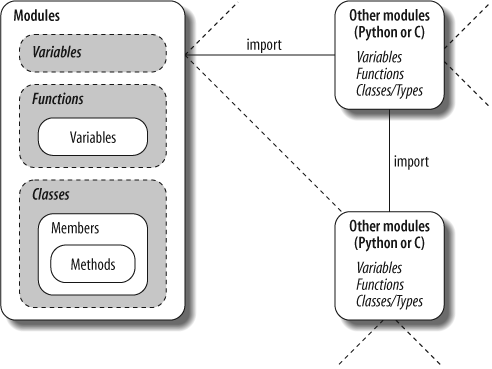
As a summary, Figure 21-1 sketches the environment in which modules operate. Modules contain variables, functions, classes, and other modules (if imported). Functions have local variables of their own. You’ll meet classes—other objects that live within modules—in Chapter 22.
Modules Are Objects: Metaprograms
Because modules expose most of their interesting properties as built-in attributes, it’s easy to write programs that manage other programs. We usually call such manager programs metaprograms because they work on top of other systems. This is also referred to as introspection because programs can see and process object internals. Introspection is an advanced feature, but it can be useful for building programming tools.
For instance, to get to an attribute called name in a module called M, we can use qualification, or index the module’s attribute dictionary (exposed in the built-in _ _dict_ _ attribute). Python also exports the list of all loaded modules as the sys.modules dictionary (that is, the modules attribute of the sys module) and provides a built-in called getattr that lets us fetch attributes from their string names (it’s like saying object.attr, but attr is a runtime string). Because of that, all the following expressions reach the same attribute and object:
By exposing module internals like this, Python helps you build programs about programs.[52] For example, here is a module named mydir.py that puts these ideas to work to implement a customized version of the built-in dir function. It defines and exports a function called listing, which takes a module object as an argument, and prints a formatted listing of the module’s namespace:
We’ve also provided self-test logic at the bottom of this module, which narcissistically imports and lists itself. Here’s the sort of output produced:
python mydir.py------------------------------ name: mydir file: mydir.py ------------------------------ 00) _ _file_ _ <built-in name> 01) _ _name_ _ <built-in name> 02) listing <function listing at 885450> 03) _ _doc_ _ <built-in name> 04) _ _builtins_ _ <built-in name> 05) verbose 1 ------------------------------ mydir has 6 names ------------------------------
We’ll meet getattr and its relatives again later. The point to notice here is that mydir is a program that lets you browse other programs. Because Python exposes its internals, you can process objects generically.[53]
Module Gotchas
In this section, we’ll take a look at the usual collection of boundary cases that make life interesting for Python beginners. Some are so obscure that it was hard to come up with examples, but most illustrate something important about the language.
Statement Order Matters in Top-Level Code
When a module is first imported (or reloaded), Python executes its statements one by one, from the top of the file to the bottom. This has a few subtle implications regarding forward references that are worth underscoring here:
Code at the top level of a module file (not nested in a function) runs as soon as Python reaches it during an import; because of that, it can’t reference names assigned lower in the file.
Code inside a function body doesn’t run until the function is called; because names in a function aren’t resolved until the function actually runs, they can usually reference names anywhere in the file.
Generally, forward references are only a concern in top-level module code that executes immediately; functions can reference names arbitrarily. Here’s an example that illustrates forward reference:
When this file is imported (or run as a standalone program), Python executes its statements from top to bottom. The first call to func1 fails because the func1 def hasn’t run yet. The call to func2 inside func1 works as long as func2’s def has been reached by the time func1 is called (it hasn’t when the second top-level func1 call is run). The last call to func1 at the bottom of the file works because func1 and func2 have both been assigned.
Mixing defs with top-level code is not only hard to read, it’s dependent on statement ordering. As a rule of thumb, if you need to mix immediate code with defs, put your defs at the top of the file, and top-level code at the bottom. That way, your functions are guaranteed to be defined and assigned by the time code that uses them runs.
Importing Modules by Name String
The module name in an import or from statement is a hardcoded variable name. Sometimes, though, your program will get the name of a module to be imported as a string at runtime (e.g., if a user selects a module name from within a GUI). Unfortunately, you can’t use import statements directly to load a module given its name as a string—Python expects a variable name here, not a string. For instance:
import "string"File "<stdin>", line 1 import "string" ^ SyntaxError: invalid syntax
It also won’t work to simply assign the string to a variable name:
Here, Python will try to import a file x.py, not the string module.
To get around this, you need to use special tools to load a module dynamically from a string that is generated at runtime. The most general approach is to construct an import statement as a string of Python code, and pass it to the exec statement to run:
modname = "string">>>exec "import " + modname# Run a string of code >>>string# Imported in this namespace <module 'string'>
The exec statement (and its cousin for expressions, the eval function) compiles a string of code, and passes it to the Python interpreter to be executed. In Python, the byte code compiler is available at runtime, so you can write programs that construct and run other programs like this. By default, exec runs the code in the current scope, but you can get more specific by passing in optional namespace dictionaries.
The only real drawback to exec is that it must compile the import statement each time it runs; if it runs many times, your code may run quicker if it uses the built-in _ _import_ _ function to load from a name string instead. The effect is similar, but _ _import_ _ returns the module object, so assign it to a name here to keep it:
modname = "string">>>string = _ _import_ _(modname)>>>string<module 'string'>
from Copies Names but Doesn’t Link
Although it’s commonly used, the from statement is the source of a variety of potential gotchas in Python. The from statement is really an assignment to names in the importer’s scope—a name-copy operation, not a name aliasing. The implications of this are the same as for all assignments in Python, but subtle, especially given that the code that shares the objects lives in different files. For instance, suppose we define the following module (nested1.py):
If we import its two names using from in another module (nested2.py), we get copies of those names, not links to them. Changing a name in the importer resets only the binding of the local version of that name, not the name in nested1.py:
python nested2.py99
If we use import to get the whole module, and then assign to a qualified name, however, we change the name in nested1.py. Qualification directs Python to a name in the module object, rather than a name in the importer (nested3.py):
python nested3.py88
from * Can Obscure the Meaning of Variables
I mentioned this in Chapter 19, but saved the details for here. Because you don’t list the variables you want when using the from module import * statement form, it can accidentally overwrite names you’re already using in your scope. Worse, it can make it difficult to determine where a variable comes from. This is especially true if the from * form is used on more than one imported file.
For example, if you use from * on three modules, you’ll have no way of knowing what a raw function call really means, short of searching all three external module files (all of which may be in other directories):
from module1 import *# Bad: may overwrite my names silently >>>from module2 import *# Worse: no way to tell what we get! >>>from module3 import *>>> . . . >>>func( )# Huh???
The solution again is not to do this: try to explicitly list the attributes you want in your from statements, and restrict the from * form to at most one imported module per file. That way, any undefined names must by deduction be in the module named in the single from *. You can avoid the issue altogether if you always use import instead of from, but that advice is too harsh; like much else in programming, from is a convenient tool if used wisely.
reload May Not Impact from Imports
Here’s another from-related gotcha: as discussed previously, because from copies (assigns) names when run, there’s no link back to the module where the names came from. Names imported with from simply become references to objects, which happen to have been referenced by the same names in the importee when the from ran.
Because of this behavior, reloading the importee has no effect on clients that import its names using from. That is, the client’s names will still reference the original objects fetched with from, even if the names in the original module are later reset:
To make reloads more effective, use import and name qualification instead of from. Because qualifications always go back to the module, they will find the new bindings of module names after reloading:
reload, from, and Interactive Testing
Chapter 3 warned that it’s usually better not to launch programs with imports and reloads because of the complexities involved. Things get even worse when from is brought into the mix. Python beginners often encounter the gotcha described here. After opening a module file in a text edit window, say you launch an interactive session to load and test your module with from:
Finding a bug, you jump back to the edit window, make a change, and try to reload the module this way:
But this doesn’t work—the from statement assigned the name function, not module. To refer to the module in a reload, you have to first load it with an import statement at least once:
However, this doesn’t quite work either—reload updates the module object, but as discussed in the preceding section, names like function that were copied out of the module in the past still refer to the old objects (in this instance, the original version of the function). To really get the new function, you must call it module.function after the reload, or rerun the from:
Now, the new version of the function will finally run.
As you can see, there are problems inherent in using reload with from: not only do you have to remember to reload after imports, but you also have to remember to rerun your from statements after reloads. This is complex enough to trip up even an expert once in a while.
You should not expect reload and from to play together nicely. The best policy is not to combine them at all—use reload with import, or launch your programs other ways, as suggested in Chapter 3 (e.g., using the Run → Run Module menu option in IDLE, file icon clicks, or system command lines).
reload Isn’t Applied Transitively
When you reload a module, Python only reloads that particular module’s file; it doesn’t automatically reload modules that the file being reloaded happens to import. For example, if you reload some module A, and A imports modules B and C, the reload applies only to A, not to B and C. The statements inside A that import B and C are rerun during the reload, but they just fetch the already loaded B and C module objects (assuming they’ve been imported before). In actual code, here’s the file A.py:
python>>> . . . >>>reload(A)
Don’t depend on transitive module reloads—instead, use multiple reload calls to update subcomponents independently. If desired, you can design your systems to reload their subcomponents automatically by adding reload calls in parent modules like A.
Better still, you could write a general tool to do transitive reloads automatically by scanning modules’ _ _dict_ _ attributes (see "Modules Are Objects: Metaprograms" earlier in this chapter) and checking each item’s type (see Chapter 9) to find nested modules to reload recursively. Such a utility function could call itself recursively to navigate arbitrarily shaped import dependency chains.
For example, the module reloadall.py listed below has a reload_all function that automatically reloads a module, every module that the module imports, and so on, all the way to the bottom of each import chain. It uses a dictionary to keep track of already reloaded modules; recursion to walk the import chains; and the standard library’s types module (introduced at the end of Chapter 9), which simply predefines type results for built-in types.
To use this utility, import its reload_all function, and pass it the name of an already loaded module (like you would the built-in reload function). When the file runs standalone, its self-test code will test itself—it has to import itself because its own name is not defined in the file without an import. I encourage you to study and experiment with this example on your own:
Recursive from Imports May Not Work
I saved the most bizarre (and, thankfully, obscure) gotcha for last. Because imports execute a file’s statements from top to bottom, you need to be careful when using modules that import each other (known as recursive imports). Because the statements in a module may not all have been run when it imports another module, some of its names may not yet exist.
If you use import to fetch the module as a whole, this may or may not matter; the module’s names won’t be accessed until you later use qualification to fetch their values. But, if you use from to fetch specific names, you must bear in mind that you will only have access to names in that module that have already been assigned.
For instance, take the following modules, recur1 and recur2. recur1 assigns a name X, and then imports recur2 before assigning the name Y. At this point, recur2 can fetch recur1 as a whole with an import (it already exists in Python’s internal modules table), but if it uses from, it will be able to see only the name X; the name Y, which is assigned below the import in recur1, doesn’t yet exist, so you get an error:
import recur1Traceback (innermost last): File "<stdin>", line 1, in ? File "recur1.py", line 2, in ? import recur2 File "recur2.py", line 2, in ? from recur1 import Y # Error: "Y" not yet assigned ImportError: cannot import name Y
Python avoids rerunning recur1’s statements when they are imported recursively from recur2 (or else the imports would send the script into an infinite loop), but recur1’s namespace is incomplete when imported by recur2.
The solution? Don’t use from in recursive imports (no, really!). Python won’t get stuck in a cycle if you do, but your programs will once again be dependent on the order of the statements in the modules.
There are two ways out of this gotcha:
You can usually eliminate import cycles like this by careful design—maximizing cohesion, and minimizing coupling are good first steps.
If you can’t break the cycles completely, postpone module name accesses by using
importand qualification (instead offrom), or by running yourfroms either inside functions (instead of at the top level of the module), or near the bottom of your file to defer their execution.
Chapter Summary
This chapter surveyed some more advanced module-related concepts. We studied data hiding techniques, enabling new language features with the _ _future_ _ module, the _ _name_ _ usage mode variable, package-relative import syntax, and more. We also explored and summarized module design issues, and looked at common mistakes related to modules to help you avoid them in your code.
The next chapter begins our look at Python’s object-oriented programming tool, the class. Much of what we’ve covered in the last few chapters will apply there, too—classes live in modules, and are namespaces as well, but they add an extra component to attribute lookup called “inheritance search.” As this is the last chapter in this part of the book, however, before we dive into that topic, be sure to work through this part’s set of lab exercises. And, before that, here is this chapter’s quiz to review the topics covered here.
BRAIN BUILDER
BRAIN BUILDER
Part V Exercises
See "Part V, Modules" in Appendix B for the solutions.
Import basics. Write a program that counts the lines and characters in a file (similar in spirit to wc on Unix). With your text editor, code a Python module called mymod.py that exports three top-level names:
A
countLines(name)function that reads an input file and counts the number of lines in it (hint:file.readlinesdoes most of the work for you, andlendoes the rest).A
countChars(name)function that reads an input file and counts the number of characters in it (hint:file.readreturns a single string).A
test(name)function that calls both counting functions with a given input filename. Such a filename generally might be passed in, hardcoded, input withraw_input, or pulled from a command line via thesys.argvlist; for now, assume it’s a passed-in function argument.
All three
mymodfunctions should expect a filename string to be passed in. If you type more than two or three lines per function, you’re working much too hard—use the hints I just gave!Next, test your module interactively, using
importand name qualification to fetch your exports. Does yourPYTHONPATHneed to include the directory where you created mymod.py? Try running your module on itself: e.g.,test("mymod.py"). Note thattestopens the file twice; if you’re feeling ambitious, you may be able to improve this by passing an open file object into the two count functions (hint:file.seek(0)is a file rewind).from/from *. Test yourmymodmodule from exercise 1 interactively by usingfromto load the exports directly, first by name, then using thefrom *variant to fetch everything._ _main_ _. Add a line in your
mymodmodule that calls thetestfunction automatically only when the module is run as a script, not when it is imported. The line you add will probably test the value of_ _name_ _for the string"_ _main_ _"as shown in this chapter. Try running your module from the system command line; then, import the module and test its functions interactively. Does it still work in both modes?Nested imports. Write a second module, myclient.py, that imports
mymod, and tests its functions; then, runmyclientfrom the system command line. Ifmyclientusesfromto fetch frommymod, willmymod’s functions be accessible from the top level ofmyclient? What if it imports withimportinstead? Try coding both variations inmyclientand test interactively by importingmyclientand inspecting its_ _dict_ _attribute.Package imports. Import your file from a package. Create a subdirectory called mypkg nested in a directory on your module import search path, move the mymod.py module file you created in exercise 1 or 3 into the new directory, and try to import it with a package import of the form
import mypkg.mymod.You’ll need to add an _ _init_ _.py file in the directory your module was moved to make this go, but it should work on all major Python platforms (that’s part of the reason Python uses “.” as a path separator). The package directory you create can be simply a subdirectory of the one you’re working in; if it is, it will be found via the home directory component of the search path, and you won’t have to configure your path. Add some code to your _ _init_ _.py, and see if it runs on each import.
Reloads. Experiment with module reloads: perform the tests in Chapter 19’s changer.py example, changing the called function’s message, and/or behavior repeatedly, without stopping the Python interpreter. Depending on your system, you might be able to edit
changerin another window, or suspend the Python interpreter, and edit in the same window (on Unix, a Ctrl-Z key combination usually suspends the current process, and anfgcommand later resumes it).Circular imports.[54] In the section on recursive import gotchas, importing
recur1raised an error. But, if you restart Python, and importrecur2interactively, the error doesn’t occur—test and see this for yourself. Why do you think it works to importrecur2, but notrecur1? (Hint: Python stores new modules in the built-insys.modulestable (a dictionary) before running their code; later imports fetch the module from this table first, whether the module is “complete” yet or not.) Now, try runningrecur1as a top-level script file:python recur1.py. Do you get the same error that occurs whenrecur1is imported interactively? Why? (Hint: when modules are run as programs, they aren’t imported, so this case has the same effect as importingrecur2interactively;recur2is the first module imported.) What happens when you runrecur2as a script?
[52] * As we saw in Chapter 16, because a function can access its enclosing module by going through the sys.modules table like this, it’s possible to emulate the effect of the global statement. For instance, the effect of global X; X=0 can be simulated (albeit with much more typing!) by saying this inside a function: import sys; glob=sys.modules[_ _name_ _]; glob.X=0. Remember, each module gets a _ _name_ _ attribute for free; it’s visible as a global name inside the functions within the module. This trick provides another way to change both local and global variables of the same name inside a function.
[53] * Tools such as mydir.listing can be preloaded into the interactive namespace by importing them in the file referenced by the PYTHONSTARTUP environment variable. Because code in the startup file runs in the interactive namespace (module _ _main_ _), importing common tools in the startup file can save you some typing. See Appendix A for more details.
[54] * Note that circular imports are extremely rare in practice. In fact, this author has never coded or come across a circular import in a decade of Python coding. On the other hand, if you can understand why they are a potential problem, you know a lot about Python’s import semantics.