
Search is an inescapable feature in every portal application. Liferay Portal also provides search functionality out of the box. Liferay Portal includes the search framework which can be integrated with external search engines. In this section, we will look at various search integration options available with Liferay Portal.
Liferay Portal, by default, uses the embedded Apache Lucene search engine. Apache Lucene is the leading open source search engine available in the market. By default, Liferay Portal's search API connects with the local embedded Lucene search engine. It stores search indexes on the local filesystem. When we use Lucene in a clustered environment, we need to make sure the indexes are replicated across the cluster. There are different approaches to make sure the same search indexes are available to all Liferay Portal nodes.
One of the options is to configure Lucene to store indexes on a centralized network location. Hence, all the Liferay Portal nodes will refer to the same version of indexes. Liferay provides a way to configure indexes on a particular location. This approach is recommended only if we have SAN installed, and the SAN provider handles file locking issues. As indexes are accessed and changed too often, if SAN is not able to handle file locking issues, we will end up having problems with the search functionality. This option gives the best performance. To configure the location of the index directory, we need to add the following property in portal-ext.properties:
lucene.dir=<SAN lucene index location>
We have learned about the Cluster Link feature of Liferay Portal which replicates Ehcache. Cluster Link also replicates Lucene indexes across the Liferay Portal nodes. Cluster Link connects to all the Liferay Portal nodes using UDP multicast. When Cluster Link is enabled, the Liferay search engine API raises an event on Cluster Link to replicate specific index changes across the cluster. The Cluster Link dispatcher threads distribute index changes to other nodes. This is a very powerful feature. This feature doesn't require specialized hardware. But it adds overhead on the network and the Liferay Portal server. This option is recommended if we cannot go with centralized index storage on SAN.
Apache Solr is one of the powerful open source search engines. It is based on the Apache Lucene search engine. In simple words, it wraps the Lucene search engine and provides access to Lucene search engine APIs through web services. Unlike Lucene, Solr runs as a separate web application. Liferay provides integration with Apache Solr as well. To integrate Apache Solr with Liferay, we need to install the Solr web plugin. We can configure the URL of the Solr server by modifying the configuration of the Solr web plugin. It is recommended to use Solr with Liferay Portal when the Portal is expected to write a large amount of data in search indexes. In such situations, Apache Lucene will add a lot of overhead due to index replication over the cluster. As Apache Solr runs as a separate web application, it makes the Portal architecture more scalable. The following diagram explains the basic Liferay-Solr integration:
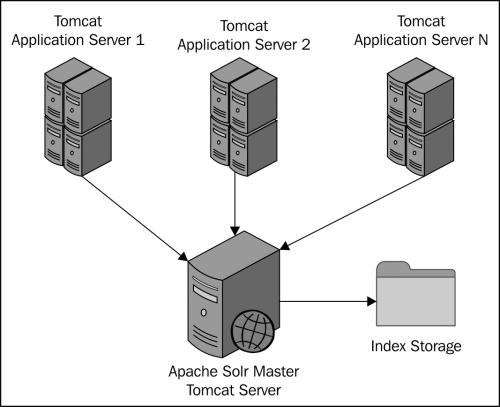
As shown in the preceding diagram, Apache Solr is installed on a separate server. The Apache Solr server internally stores indexes on the filesystem. All Liferay Portal servers are connected with the Apache Solr server. Every search request and index write request will be sent to the Apache Solr server.
In the preceding architecture, we are using a single Solr server for both read and write operations. Internally, the Solr server performs concurrent read and write operations on the same index storage. If the Portal application is expected to perform heavy write and search operations on the Solr server, this architecture as explained earlier will not give good performance. In such situations, it is recommended to use the master-slave Solr setup. In this approach, one master and many slave Solr servers are configured to work together. The master server will handle all the write operations and the slave servers will handle all read and search operations. Here is the diagram explaining the master-slave Solr setup:
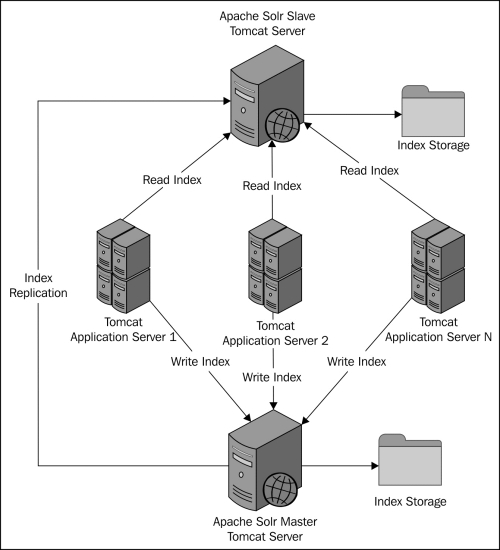
As shown in the preceding diagram, we have one Solr master server and one Solr slave server. The Solr master server is configured such that it automatically replicates indexes to the slave server. Each Liferay Portal application server will be connected to both master and slave servers. The Liferay Solr web plugin provides a way to configure separate Solr servers for read and write operations. To scale the search functionality further, we can also configure separate slave servers for each Liferay portal node. This will reduce the load on the slave server by limiting search requests.