
Files are used for a large number of tasks in the Linux world, such as persistent data storage in regular files, networking through sockets, and device access through device files. The variety of applications for files has led to the development of many specialized ways of manipulating files. Chapter 11 introduced the most common operations on files, and this chapter discusses some more specialized file operations. In this chapter, we cover using multiple files simultaneously, mapping files into system memory, file locking, and scatter/gather reads and writes.
Many client/server applications need to read input from or write output to multiple file descriptors at a time. For example, modern Web browsers open many simultaneous network connections to reduce the loading time for a Web page. This allows them to download the multiple images that appear on most Web pages more quickly than consecutive connections would allow. Along with the interprocess communication (IPC) channel that graphical browsers use to contact the X server on which they are displayed, browsers have many file descriptors to keep track of.
The easiest way to handle all these files is for the browser to read from each file in turn and process whatever data that file delivers (a read() system call on a network connection, as on a pipe, returns whatever data is currently available and blocks only if no bytes are ready). This approach works fine, as long as all the connections are delivering data fairly regularly.
If one of the network connections gets behind, problems start. When the browser next reads from that file, the browser stops running while the read() blocks, waiting for data to arrive. Needless to say, this is not the behavior the browser’s user would prefer.
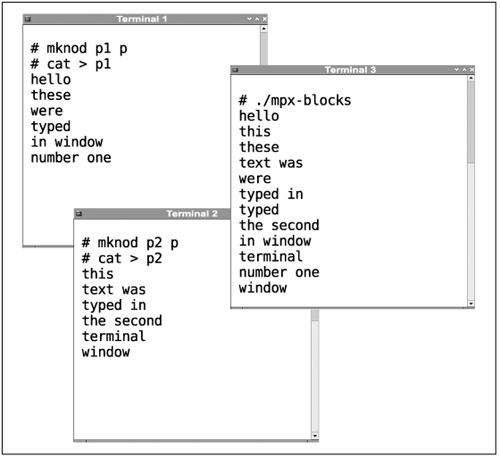
To help illustrate these problems, here is a short program that reads from two files: p1 and p2. To try it, open three X terminal sessions (or use three virtual consoles). Make named pipes named p1 and p2 (with the mknod command), then run cat > p1 and cat > p2 in two of the terminals while running mpx-blocks in the third. Once everything is running, type some text in each of the cat windows and watch how it appears. Remember that the two cat commands will not write any data into the pipes until the end of a line.
1: /* mpx-blocks.c */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <unistd.h>
6:
7: int main(void) {
8: int fds[2];
9: char buf[4096];
10: int i;
11: int fd;
12:
13: if ((fds[0] = open("p1", O_RDONLY)) < 0) {
14: perror("open p1");
15: return 1;
16: }
17:
18: if ((fds[1] = open("p2", O_RDONLY)) < 0) {
19: perror("open p2");
20: return 1;
21: }
22:
23: fd = 0;
24: while (1) {
25: /* if data is available read it and display it */
26: i = read(fds[fd], buf, sizeof(buf) - 1);
27: if (i < 0) {
28: perror("read");
29: return 1;
30: } else if (!i) {
31: printf("pipe closed
");
32: return 0;
33: }
34:
35: buf[i] = '�';
36: printf("read: %s", buf);
37:
38: /* read from the other file descriptor */
39: fd = (fd + 1) % 2;
40: }
41: }
Although mpx-blocks does read from both pipes, it does not do a very nice job of it. It reads from only one pipe at a time. When it starts, it reads from the first file until data becomes available on it; the second file is ignored until the read() from the first file returns. Once that read does return, the first file is ignored until data is read from the second file. This method does not perform anything like smooth data multiplexing. Figure 13.1 shows what mpx-blocks looks like when it is run.
Recall from Chapter 11 that we may specify a file is nonblocking through the fcntl() system call. When a slow file is nonblocking, read() always returns immediately. If no data is available, it simply returns 0. Nonblocking I/O provides a simple solution to multiplexing by preventing operations on files from ever blocking.
Here is a modified version of mpx-blocks that takes advantage of nonblocking I/O to alternate between p1 and p2 more smoothly:
1: /* mpx-nonblock.c */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <stdio.h>
6: #include <unistd.h>
7:
8: int main(void) {
9: int fds[2];
10: char buf[4096];
11: int i;
12: int fd;
13:
14: /* open both pipes in nonblocking mode */
15: if ((fds[0] = open("p1", O_RDONLY | O_NONBLOCK)) < 0) {
16: perror("open p1");
17: return 1;
18: }
19:
20: if ((fds[1] = open("p2", O_RDONLY | O_NONBLOCK)) < 0) {
21: perror("open p2");
22: return 1;
23: }
24:
25: fd = 0;
26: while (1) {
27: /* if data is available read it and display it */
28: i = read(fds[fd], buf, sizeof(buf) - 1);
29: if ((i < 0) && (errno != EAGAIN)) {
30: perror("read");
31: return 1;
32: } else if (i > 0) {
33: buf[i] = '�';
34: printf("read: %s", buf);
35: }
36:
37: /* read from the other file descriptor */
38: fd = (fd + 1) % 2;
39: }
40: }
One important difference between mpx-nonblock and mpx-blocks is that mpx-nonblock does not exit when one of the pipes it is reading from is closed. A nonblocking read() from a pipe with no writers returns 0 bytes; from a pipe with writers but no data read() returns EAGAIN.
Although nonblocking I/O allows us to switch easily between file descriptors, it has a high price. The program is always polling the two file descriptors for input—it never blocks. As the program is constantly running, it inflicts a heavy performance penalty on the system as the operating system can never put the process to sleep (try running 10 copies of mpx-nonblock on your system and see how it affects system performance).
To allow efficient multiplexing, Linux provides the poll() system call, which allows a process to block on multiple file descriptors simultaneously. Rather than constantly check each file descriptor it is interested in, a process makes a single system call that specifies which file descriptors the process would like to read from or write to. When one or more of those files have data available for reading or can accept data written to them, the poll() returns and the application can read and write from those file descriptors without worrying about blocking. Once those files have been handled, the process makes another poll() call, which blocks until a file is ready for more attention. Here is the definition of poll():
#include <sys/poll.h> int poll(struct pollfd * fds, int numfds, int timeout);
The last two parameters are straightforward; numfds specifies the number of items in the array pointed to by the first parameter and timeout specifies how long poll() should wait for an event to occur. If 0 is used as the timeout, poll() never times out.
The first parameter, fds, describes which file descriptors should be monitored and what types of I/O they should be monitored for. It is a pointer to an array of struct pollfd structures.
struct pollfd {
int fd; /* file descriptor */
short events; /* I/O events to wait for */
short revents; /* I/O events that occurred */
};
The first element, fd, is a file descriptor being monitored, and the events element describes what types of events are of interest. It is one or more of the following flags logically OR’ed together:
| Normal data is available for reading from the file descriptor. |
| Priority (out-of-band[1]) data is available for reading. |
| The file descriptor is able to accept some data being written to it. |
[1] This is almost the only place in this book we ever mention out-of-band data. For more information, consult [Stevens, 2004]. | |
The revents element of struct pollfd is filled in by the poll() system call, and reflects the status of file descriptor fd. It is similar to the events member, but instead of specifying what types of I/O events are of interest to the application, it specifies what types of I/O events are available. For example, if the application is monitoring a pipe both for reading and writing (events is set to POLLIN | POLLOUT), then after the poll() succeeds revents has the POLLIN bit set if the pipe has data ready to be read, and the POLLOUT bit set if there is room in the pipe for more data to be written. If both are true, both bits are set.
There are a few bits that the kernel can set in revents that do not make sense for events;
| There is an error pending on the file descriptor; performing a system call on the file descriptor will cause |
| The file has been disconnected; no more writing to it is possible (although there may be data left to be read). This occurs if a terminal has been disconnected or the remote end of a pipe or socket has been closed. |
| The file descriptor is invalid (it does not refer to an open file). |
The return value of poll() is zero if the call times out, -1 if an error occurs (such as fds being an invalid pointer; errors on the files themselves cause POLLERR to get set), or a positive number describing the number of files with nonzero revents members.
Rather than the inefficient method we used earlier to multiplex input and output from pipes, poll() lets us solve the same problem quite elegantly. By using poll() on the file descriptors for both pipes simultaneously, we know when poll() returns, one of the pipes has data ready to be read or has been closed. We check the revents member for both file descriptors to see what actions need to be taken and go back to the poll() call once we are done. Most of the time is now spent blocking on the poll() call rather than continuously checking the file descriptors using nonblocking I/O, significantly reducing load on the system. Here is mpx-poll:
1: /* mpx-poll.c */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <sys/poll.h>
6: #include <unistd.h>
7:
8: int main(void) {
9: struct pollfd fds[2];
10: char buf[4096];
11: int i, rc;
12:
13: /* open both pipes */
14: if ((fds[0].fd = open("p1", O_RDONLY | O_NONBLOCK)) < 0) {
15: perror("open p1");
16: return 1;
17: }
18:
19: if ((fds[1].fd = open("p2", O_RDONLY | O_NONBLOCK)) < 0) {
20: perror("open p2");
21: return 1;
22: }
23:
24: /* start off reading from both file descriptors */
25: fds[0].events = POLLIN;
26: fds[1].events = POLLIN;
27:
28: /* while we're watching one of fds[0] or fds[1] */
29: while (fds[0].events || fds[1].events) {
30: if (poll(fds, 2, 0) < 0) {
31: perror("poll");
32: return 1;
33: }
34:
35: /* check to see which file descriptors are ready to be
36: read from */
37: for (i = 0; i < 2; i++) {
38: if (fds[i].revents) {
39: /* fds[i] is ready for reading, go ahead... */
40: rc = read(fds[i].fd, buf, sizeof(buf) - 1);
41: if (rc < 0) {
42: perror("read");
43: return 1;
44: } else if (!rc) {
45: /* this pipe has been closed, don't try
46: to read from it again */
47: fds[i].events = 0;
48: } else {
49: buf[rc] = '�';
50: printf("read: %s", buf);
51: }
52: }
53: }
54: }
55:
56: return 0;
57: }
The poll() system call was originally introduced as part of the System V Unix tree. The BSD development efforts solved the same basic problem in a similar way by introducing the select() system call.
#include <sys/select.h>
int select(int numfds, fd_set * readfds, fd_set * writefds,
fd_set * exceptfds, struct timeval * timeout);
The middle three parameters, readfds, writefds, and exceptfds, specify which file descriptors should be watched. Each parameter is a pointer to an fd_set, a data structure that allows a process to specify an arbitrary number of file descriptors.[2] It is manipulated through the following macros:
FD_ZERO(fd_set * fds);
Clears
fds—no file descriptors are contained in the set. This macro is used to initializefd_setstructures.
FD_SET(int fd, fd_set * fds);
Adds
fdto thefd_set.
FD_CLR(int fd, fd_set * fds);
Removes
fdfrom thefd_set.
FD_ISSET(int fd, fd_set * fds);
The first of select()’s file descriptor sets, readfds, contains the set of file descriptors that will cause the select() call to return when they are ready to be read from[3] or (for pipes and sockets) when the process on the other end of the file has closed the file. When any of the file descriptors in writefds are ready to be written, select() returns. exceptfds contains the file descriptors to watch for exceptional conditions. Under Linux (as well as Unix), this occurs only when out-of-band data has been received on a network connection. Any of these may be NULL if you are not interested in that type of event.
The final parameter, timeout, specifies how long, in milliseconds, the select() call should wait for something to happen. It is a pointer to a struct timeval, which looks like this:
#include <sys/time.h>
struct timeval {
int tv_sec; /* seconds */
int tv_usec; /* microseconds */
};
The first element, tv_sec, is the number of seconds to wait, and tv_usec is the number of microseconds to wait. If the timeout value is NULL, select() blocks until something happens. If it points to a struct timeval that contains zero in both its elements, select() does not block. It updates the file descriptor sets to indicate which file descriptors are currently ready for reading or writing, then returns immediately.
The first parameter, numfds, causes the most difficulty. It specifies how many of the file descriptors (starting from file descriptor 0) may be specified by the fd_sets. Another (and perhaps easier) way of thinking of numfds is as one greater than the maximum file descriptor select() is meant to consider.[4] As Linux normally allows each process to have up to 1,024 file descriptors, numfds prevents the kernel from having to look through all 1,024 file descriptors each fd_set could contain, providing a performance increase.
On return, the three fd_set structures contain the file descriptors that have input pending, may be written to, or are in an exceptional condition. Linux’s select() call returns the total number of items set in the three fd_set structures, 0 if the call timed out, or -1 if an error occurred. However, many Unix systems count a particular file descriptor in the return value only once, even if it occurs in both readfds and writefds, so for portability, it is a good idea to check only whether the return value is greater than 0. If the return value is -1, do not assume the fd_set structures remain pristine. Linux updates them only if select() returns a value greater than 0, but some Unix systems behave differently.
Another portability concern is the timeout parameter. Linux kernels[5] update it to reflect the amount of time left before the select() call would have timed out, but most other Unix systems do not update it.[6] However, other systems do not update the timeout, to conform to the more common implementation. For portability, do not depend on either behavior and explicitly set the timeout structure before calling select().
Now let’s look at a couple of examples of using select(). First of all, we use select for something unrelated to files, constructing a subsecond sleep() call.
#include <sys/select.h>
#include <sys/stdlib.h>
int usecsleep(int usecs) {
struct timeval tv;
tv.tv_sec = 0;
tv.tv_usec = usecs;
return select(0, NULL, NULL, NULL, &tv);
}
This code allows highly portable pauses of less than one second (which BSD’s usleep() library function allows, as well, but select() is much more portable). For example, usecsleep(500000) causes a minimum of a half-second pause.
The select() call can also be used to solve the pipe multiplexing example we have been working with. The solution is very similar to the one using poll().
1: /* mpx-select.c */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <sys/select.h>
6: #include <unistd.h>
7:
8: int main(void) {
9: int fds[2];
10: char buf[4096];
11: int i, rc, maxfd;
12: fd_set watchset; /* fds to read from */
13: fd_set inset; /* updated by select() */
14:
15: /* open both pipes */
16: if ((fds[0] = open("p1", O_RDONLY | O_NONBLOCK)) < 0) {
17: perror("open p1");
18: return 1;
19: }
20:
21: if ((fds[1] = open("p2", O_RDONLY | O_NONBLOCK)) < 0) {
22: perror("open p2");
23: return 1;
24: }
25:
26: /* start off reading from both file descriptors */
27: FD_ZERO(&watchset);
28: FD_SET(fds[0], &watchset);
29: FD_SET(fds[1], &watchset);
30:
31: /* find the maximum file descriptor */
32: maxfd = fds[0] > fds[1] ? fds[0]: fds[1];
33:
34: /* while we're watching one of fds[0] or fds[1] */
35: while (FD_ISSET(fds[0], &watchset) ||
36: FD_ISSET(fds[1], &watchset)) {
37: /* we copy watchset here because select() updates it */
38: inset = watchset;
39: if (select(maxfd + 1, &inset, NULL, NULL, NULL) < 0) {
40: perror("select");
41: return 1;
42: }
43:
44: /* check to see which file descriptors are ready to be
45: read from */
46: for (i = 0; i < 2; i++) {
47: if (FD_ISSET(fds[i], &inset)) {
48: /* fds[i] is ready for reading, go ahead... */
49: rc = read(fds[i], buf, sizeof(buf) - 1);
50: if (rc < 0) {
51: perror("read");
52: return 1;
53: } else if (!rc) {
54: /* this pipe has been closed, don't try
55: to read from it again */
56: close(fds[i]);
57: FD_CLR(fds[i], &watchset);
58: } else {
59: buf[rc] = '�';
60: printf("read: %s", buf);
61: }
62: }
63: }
64: }
65:
66: return 0;
67: }
Although poll() and select() perform the same basic function, there are real differences between the two. The most obvious is probably the timeout, which has millisecond precision for poll() and microsecond precision for select(). In reality, this difference is almost meaningless as neither are going to be accurate down to the microsecond.
The more important difference is performance. The poll() interface differs from select() in a few ways that make it much more efficient.
When
select()is used, the kernel must check all of the file descriptors between 0 andnumfds - 1to see if the application is interested in I/O events for that file descriptor. For applications with large numbers of open files, this can cause substantial waste as the kernel checks which file descriptors are of interest.The set of file descriptors is passed to the kernel as a bitmap for
select()and as a list forpoll(). The somewhat complicated bit operations required to check and set thefd_setdata structures are less efficient than the simple checks needed forstruct pollfd.As the kernel overwrites the data structures passed to
select(), the application is forced to reset those structures every time it needs to callselect(). Withpoll()the kernel’s results are limited to thereventsmember, removing the need for data structures to be rebuilt before every call.Using a set-based structure like
fd_setdoes not scale as the number of file descriptors available to a process increases. Since it is a static size (rather than dynamically allocated; note the lack of a corresponding macro likeFD_FREE), it cannot grow or shrink with the needs of the application (or the abilities of the kernel). Under Linux, the maximum file descriptor that can be set in anfd_setis 1023. If a larger file descriptor may be needed,select()will not work.
The only advantage select() offers over poll() is better portability to old systems. As very few of those implementations are still in use, you should consider select() of interest primarily for understanding and maintaining existing code bases.
To illustrate how much less efficient select() is than poll(), here is a short program that measures the number of system calls that can be performed in a second:
1: /* select-vs-poll.c */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <sys/poll.h>
6: #include <sys/select.h>
7: #include <sys/signal.h>
8: #include <unistd.h>
9:
10: int gotAlarm;
11:
12: void catch(int sig) {
13: gotAlarm = 1;
14: }
15:
16: #define HIGH_FD 1000
17:
18: int main(int argc, const char ** argv) {
19: int devZero;
20: int count;
21: fd_set selectFds;
22: struct pollfd pollFds;
23:
24: devZero = open("/dev/zero", O_RDONLY);
25: dup2(devZero, HIGH_FD);
26:
27: /* use a signal to know when time's up */
28: signal(SIGALRM, catch);
29:
30: gotAlarm = 0;
31: count = 0;
32: alarm(1);
33: while (!gotAlarm) {
34: FD_ZERO(&selectFds);
35: FD_SET(HIGH_FD, &selectFds);
36:
37: select(HIGH_FD + 1, &selectFds, NULL, NULL, NULL);
38: count++;
39: }
40:
41: printf("select() calls per second: %d
", count);
42:
43: pollFds.fd = HIGH_FD;
44: pollFds.events = POLLIN;
45: count = 0;
46: gotAlarm = 0;
47: alarm(1);
48: while (!gotAlarm) {
49: poll(&pollFds, 0, 0);
50: count++;
51: }
52:
53: printf("poll() calls per second: %d
", count);
54:
55: return 0;
56: }
It uses /dev/zero, which provides an infinite number of zeros so that the system calls return immediately. The HIGH_FD value can be changed to see how select() degrades as the file descriptor values increase.
On one particular system and a HIGH_FD value of 2 (which is not very high), this program showed that the kernel could handle four times as many poll() calls per second as select() calls. When HIGH_FD was increased to 1,000, poll() became forty times more efficient than select().
The 2.6 version of the Linux kernel introduced a third method for multiplexed I/O, called epoll. While epoll is more complicated than either poll() or select(), it removes a performance bottleneck common to both of those methods.
Both the poll() and select() system calls pass a full list of file descriptors to monitor each time they are called. Every one of those file descriptors must be processed by the system call, even if only one of them is ready for reading or writing. When tens, or hundreds, or thousands of file descriptors are being monitored, those system calls become bottlenecks; the kernel spends a large amount of time checking to see which file descriptors need to be checked by the application.
When epoll is used, applications provide the kernel with a list of file descriptors to monitor through one system call, and then monitor those file descriptors using a different system call. Once the list has been created, the kernel continually monitors those file descriptors for the events the application is interested in,[7] and when an event occurs, it makes a note that something interesting just happened. As soon as the application asks the kernel which file descriptors are ready for further processing, the kernel provides the list it has been maintaining without having to check every file descriptor.
The performance advantages of epoll require a system call interface that is more complicated than those of poll() and select(). While poll() uses an array of struct pollfd to represent a set of file descriptors and select() uses three different fd_set structures for the same purpose, epoll moves these file descriptor sets into the kernel rather than keeping them in the program’s address space. Each of these sets is referenced through an epoll descriptor, which is a file descriptor that can be used only for epoll system calls. New epoll descriptors are allocated by the epoll_create() system call.
#include <sys/epoll.h> int epoll_create(int numDescriptors);
The sole parameter numDescriptors is the program’s best guess at how many file descriptors the newly created epoll descriptor will reference. This is not a hard limit, it is just a hint to the kernel to help it initialize its internal structures more accurately. epoll_create() returns an epoll descriptor, and when the program has finished with that descriptor it should be passed to close() to allow the kernel to free any memory used by that descriptor.
Although the epoll descriptor is a file descriptor, there are only two system calls it should be used with.
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event * event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents,
int timeout);
Both of these use parameters of the type struct epoll_event, which is defined as follows:
#include <sys/epoll.h>
struct epoll_event {
int events;
union {
void * ptr;
int fd;
unsigned int u32;
unsigned long long u64;
} data;
};
This structure serves three purposes: It specifies what types of events should be monitored, specifies what types of events occurred, and allows a single data element to be associated with the file descriptor. The events field is for the first two functions, and is one or more of the following values logically OR’ed together:[8]
| Indicates that a |
| The associated file is ready to be written to. |
| The file has out-of-band data ready for reading. |
The second member of struct epoll_event, data, is a union that contains an integer (for holding a file descriptor), a pointer, and 32-bit and 64-bit integers.[9] This data element is kept by epoll and returned to the program whenever an event of the appropriate type occurs. The data element is the only way the program has to know which file descriptor needs to be serviced; the epoll interface does not pass the file descriptor to the program, unlike poll() and select() (unless data contains the file descriptor). This method gives extra flexibility to applications that track files as something more complicated than simple file descriptors.
The epoll_ctl() system call adds and removes file descriptors from the set the epfd epoll descriptor refers to.
The second parameter, op, describes how the file descriptor set should be modified, and is one of the following:
| The file descriptor |
| The file descriptor |
| The |
The final system call used by epoll is epoll_wait(), which blocks until one or more of the file descriptors being monitored has data to read or is ready to be written to. The first argument is the epoll descriptor, and the last provides a timeout in seconds. If no file descriptors are ready for processing before the timeout expires, epoll_wait() returns 0.
The middle two parameters specify a buffer for the kernel to copy a set struct epoll_event structures into. The events parameter points to the buffer, maxevents specifies how many struct epoll_event structures fit in that buffer, and the return value tells the program how many structures were placed in that buffer (unless the call times out or an error occurs).
Each struct epoll_event tells the program the full status of a file descriptor that is being monitored. The events member can have any of the EPOLLIN, EPOLLOUT, or EPOLLPRI flags set, as well as two new flags.
| An error condition is pending on the file; this can occur if an error occurs on a socket when the application is not reading from or writing to it. |
| A hangup occurred on the file descriptor; see page 138 for information on when this can occur. |
While all of this seems complicated, it is actually very similar to how poll() works. Calling epoll_create() is the same as allocating the struct pollfd array, and epoll_ctl() is the same step as initializing the members of that array. The main loop that is processing file descriptors uses epoll_wait() instead of the poll() system call, and close() is analogous to freeing the struct pollfd array. These parallels make switching programs that were originally written around poll() or select() to epoll quite straightforward.
The epoll interface allows one more trick that cannot really be compared to poll() or select(). Since the epoll descriptor is really a file descriptor (which is why it can be passed to close()), you can monitor that epoll descriptor as part of another epoll descriptor, or via poll() or select(). The epoll descriptor will appear as ready to be read from whenever calling epoll_wait() would return events.
Our final solution to the pipe multiplexing problem we have used throughout this section uses epoll. It is very similar to the other examples, but some of the initialization code has been moved into a new addEvent() function to keep the program from getting longer than necessary.
1: /* mpx-epoll.c */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <stdlib.h>
6: #include <sys/epoll.h>
7: #include <unistd.h>
8:
9: #include <sys/poll.h>
10:
11: void addEvent(int epfd, char * filename) {
12: int fd;
13: struct epoll_event event;
14:
15: if ((fd = open(filename, O_RDONLY | O_NONBLOCK)) < 0) {
16: perror("open");
17: exit(1);
18: }
19:
20: event.events = EPOLLIN;
21: event.data.fd = fd;
22:
23: if (epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &event)) {
24: perror("epoll_ctl(ADD)");
25: exit(1);
26: }
27: }
28:
29: int main(void) {
30: char buf[4096];
31: int i, rc;
32: int epfd;
33: struct epoll_event events[2];
34: int num;
35: int numFds;
36:
37: epfd = epoll_create(2);
38: if (epfd < 0) {
39: perror("epoll_create");
40: return 1;
41: }
42:
43: /* open both pipes and add them to the epoll set */
44: addEvent(epfd, "p1");
45: addEvent(epfd, "p2");
46:
47: /* continue while we have one or more file descriptors to
48: watch */
49: numFds = 2;
50: while (numFds) {
51: if ((num = epoll_wait(epfd, events,
52: sizeof(events) / sizeof(*events),
53: -1)) <= 0) {
54: perror("epoll_wait");
55: return 1;
56: }
57:
58: for (i = 0; i < num; i++) {
59: /* events[i].data.fd is ready for reading */
60:
61: rc = read(events[i].data.fd, buf, sizeof(buf) - 1);
62: if (rc < 0) {
63: perror("read");
64: return 1;
65: } else if (!rc) {
66: /* this pipe has been closed, don't try
67: to read from it again */
68: if (epoll_ctl(epfd, EPOLL_CTL_DEL,
69: events[i].data.fd, &events[i])) {
70: perror("epoll_ctl(DEL)");
71: return 1;
72: }
73:
74: close(events[i].data.fd);
75:
76: numFds--;
77: } else {
78: buf[rc] = '�';
79: printf("read: %s", buf);
80: }
81: }
82: }
83:
84: close(epfd);
85:
86: return 0;
87: }
The differences between poll() and epoll are straightforward; poll() is well standardized but does not scale well, while epoll exists only on Linux but scales very well. Applications that watch a small number of file descriptors and value portability should use poll(), but any application that needs to monitor a large number of descriptors is better off with epoll even if it also needs to support poll() for other platforms.
The performance differences between the two methods can be quite dramatic. To illustrate how much better epoll scales, poll-vs-epoll.c measures how many poll() and epoll_wait() system calls can be made in one second for file descriptor sets of various sizes (the number of file descriptors to put in the set is specified on the command line). Each file descriptor refers to the read portion of a pipe, and they are created through dup2().
Table 13.1 summarizes the results of running poll-vs-epoll.c for set sizes ranging from a single file descriptor to 100,000 file descriptors.[10] While the number of system calls per second drops off rapidly for poll(), it stays nearly constant for epoll.[11] As this table makes clear, epoll places far less load on the system than poll() does, and scales far better as a result.
Table 13.1. Comparing poll() and epoll
File Descriptors |
|
|
|---|---|---|
1 | 310,063 | 714,848 |
10 | 140,842 | 726,108 |
100 | 25,866 | 726,659 |
1,000 | 3,343 | 729,072 |
5,000 | 612 | 718,424 |
10,000 | 300 | 730,483 |
25,000 | 108 | 717,097 |
50,000 | 38 | 729,746 |
100,000 | 18 | 712,301 |
1: /* poll-vs-epoll.c */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <stdio.h>
6: #include <sys/epoll.h>
7: #include <sys/poll.h>
8: #include <sys/signal.h>
9: #include <unistd.h>
10: #include <sys/resource.h>
11: #include <string.h>
12: #include <stdlib.h>
13:
14: #include <sys/select.h>
15:
16: int gotAlarm;
17:
18: void catch(int sig) {
19: gotAlarm = 1;
20: }
21:
22: #define OFFSET 10
23:
24: int main(int argc, const char ** argv) {
25: int pipeFds[2];
26: int count;
27: int numFds;
28: struct pollfd * pollFds;
29: struct epoll_event event;
30: int epfd;
31: int i;
32: struct rlimit lim;
33: char * end;
34:
35: if (!argv[1]) {
36: fprintf(stderr, "number expected
");
37: return 1;
38: }
39:
40: numFds = strtol(argv[1], &end, 0);
41: if (*end) {
42: fprintf(stderr, "number expected
");
43: return 1;
44: }
45:
46: printf("Running test on %d file descriptors.
", numFds);
47:
48: lim.rlim_cur = numFds + OFFSET;
49: lim.rlim_max = numFds + OFFSET;
50: if (setrlimit(RLIMIT_NOFILE, &lim)) {
51: perror("setrlimit");
52: exit(1);
53: }
54:
55: pipe(pipeFds);
56:
57: pollFds = malloc(sizeof(*pollFds) * numFds);
58:
59: epfd = epoll_create(numFds);
60: event.events = EPOLLIN;
61:
62: for (i = OFFSET; i < OFFSET + numFds; i++) {
63: if (dup2(pipeFds[0], i) != i) {
64: printf("failed at %d: %s
", i, strerror(errno));
65: exit(1);
66: }
67:
68: pollFds[i - OFFSET].fd = i;
69: pollFds[i - OFFSET].events = POLLIN;
70:
71: event.data.fd = i;
72: epoll_ctl(epfd, EPOLL_CTL_ADD, i, &event);
73: }
74:
75: /* use a signal to know when time's up */
76: signal(SIGALRM, catch);
77:
78: count = 0;
79: gotAlarm = 0;
80: alarm(1);
81: while (!gotAlarm) {
82: poll(pollFds, numFds, 0);
83: count++;
84: }
85:
86: printf("poll() calls per second: %d
", count);
87:
88: alarm(1);
89:
90: count = 0;
91: gotAlarm = 0;
92: alarm(1);
93: while (!gotAlarm) {
94: epoll_wait(epfd, &event, 1, 0);
95: count++;
96: }
97:
98: printf("epoll() calls per second: %d
", count);
99:
100: return 0;
101: }
Linux allows a process to map files into its address space. Such a mapping creates a one-to-one correspondence between data in the file and data in the mapped memory region. Memory mapping has a number of applications.
High-speed file access. Normal I/O mechanisms, such as
read()andwrite(), force the kernel to copy the data through a kernel buffer rather than directly between the file that holds the device and the user-space process. Memory maps eliminate this middle buffer, saving a memory copy.[12]Executable files can be mapped into a program’s memory, allowing a program to dynamically load new executable sections. This is how dynamic loading, described in Chapter 27, is implemented.
New memory can be allocated by mapping portions of /dev/zero, a special device that is full of zeros,[13] or through an anonymous mapping. Electric Fence, described in Chapter 7, uses this mechanism to allocate memory.
New memory allocated through memory maps can be made executable, allowing it to be filled with machine instructions, which are then executed. This feature is used by just-in-time compilers.
Files can be treated just like memory and read using pointers instead of system calls. This can greatly simplify programs by eliminating the need for
read(), write(), andlseek()calls.Memory mapping allows processes to share memory regions that persist across process creation and destruction. The memory contents are stored in the mapped file, making it independent of any process.
System memory is divided into chunks called pages. The size of a page varies with architecture, and on some processors the page size can be changed by the kernel. The getpagesize() function returns the size, in bytes, of each page on the system.
#include <unistd.h> size_t getpagesize(void);
For each page on the system, the kernel tells the hardware how each process may access the page (such as write, execute, or not at all). When a process attempts to access a page in a manner that violates the kernel’s restrictions, a segmentation fault (SIGSEGV) results, which normally terminates the process.
A memory address is said to be page aligned if it is the address of the beginning of a page. In other words, the address must be an integral multiple of the architecture’s page size. On a system with 4K pages, 0, 4,096, 16,384, and 32,768 are all page-aligned addresses (of course, there are many more) because the first, second, fifth, and ninth pages in the system begin at those addresses.
New memory maps are created by the mmap() system call.
#include <sys/mman.h>
caddr_t mmap(caddr_t address, size_t length, int protection, int flags,
int fd, off_t offset);
The address specifies where in memory the data should be mapped. Normally, address is NULL, which means the process does not care where the new mapping is, allowing the kernel to pick any address. If an address is specified, it must be page aligned and not already in use. If the requested mapping would conflict with another mapping or would not be page aligned, mmap() may fail.
The second parameter, length, tells the kernel how much of the file to map into memory. You can successfully map more memory than the file has data, but attempting to access it may result in a SIGSEGV.[14]
The process controls which types of access are allowed to the new memory region. It should be one or more of the values from Table 13.2 bitwise OR’ed together, or PROT_NONE if no access to the mapped region should be allowed. A file can be mapped only for access types that were also requested when the file was originally opened. For example, a file that was opened O_RDONLY cannot be mapped for writing with PROT_WRITE.
Table 13.2. mmap() Protections
Flag | Description |
|---|---|
| The mapped region may be read. |
| The mapped region may be written. |
| The mapped region may be executed. |
The enforcement of the specified protection is limited by the hardware platform on which the program is running. Many architectures cannot allow code to execute in a memory region while disallowing reading from that memory region. On such hardware, mapping a region with PROT_EXEC is equivalent to mapping it with PROT_EXEC | PROT_READ.The memory protections passed to mmap() should be relied on only as minimal protections for this reason.
The flags specify other attributes of the mapped region. Table 13.3 summarizes all the flags. Many of the flags that Linux supports are not standard but may be useful in special circumstances. Table 13.3 differentiates between the standard mmap() flags and Linux’s extra flags. All calls to mmap() must specify one of MAP_PRIVATE or MAP_SHARED; the remainder of the flags are optional.
Table 13.3. mmap() Flags
Flag | POSIX? | Description |
|---|---|---|
| Yes | Ignore |
| Yes | Fail if |
| Yes | Writes are private to process. |
| Yes | Writes are copied to the file. |
| No | Do not allow normal writes to the file. |
| No | Grow the memory region downward. |
| No | Lock the pages into memory. |
| Rather than mapping a file, an anonymous mapping is returned. It behaves like a normal mapping, but no physical file is involved. Although this memory region cannot be shared with other processes, nor is it automatically saved to a file, anonymous mappings allow processes to allocate new memory for private use. Such mapping is often used by implementations of |
| If the mapping cannot be placed at the requested |
| Modifications to the memory region should be private to the process, neither shared with other processes that map the same file (other than related processes that are forked after the memory map is created) nor reflected in the file itself. Either |
| Changes that are made to the memory region are copied back to the file that was mapped and shared with other processes that are mapping the same file. (To write changes to the memory region, |
| Usually, system calls for normal file access (like |
Trying to access the memory immediately before a mapped region normally causes a | |
The only limit on | |
| This flag works just like |
| The region is locked into memory, meaning it will never be swapped. This is important for real-time applications ( |
After the flags comes the file descriptor, fd, for the file that is to be mapped into memory. If MAP_ANONYMOUS was used, this value is ignored. The final parameter specifies where in the file the mapping should begin, and it must be an integral multiple of the page size. Most applications begin the mapping from the start of the file by specifying an offset of zero.
mmap() returns an address that should be stored in a pointer. If an error occurred, it returns the address that is equivalent to -1. To test for this, the -1 constant should be typecast to a caddr_t rather than typecasting the returned address to an int. This ensures that you get the right result no matter what the sizes of pointers and integers.
Here is a program that acts like cat and expects a single name as a command-line argument. It opens that file, maps it into memory, and writes the entire file to standard output through a single write() call. It may be instructional to compare this example with the simple cat implementation on page 174. This example also illustrates that memory mappings stay in place after the mapped file is closed.
1: /* map-cat.c */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <sys/mman.h>
6: #include <sys/stat.h>
7: #include <sys/types.h>
8: #include <stdio.h>
9: #include <unistd.h>
10:
11: int main(int argc, const char ** argv) {
12: int fd;
13: struct stat sb;
14: void * region;
15:
16: if ((fd = open(argv[1], O_RDONLY)) < 0) {
17: perror("open");
18: return 1;
19: }
20:
21: /* stat the file so we know how much of it to map into memory */
22: if (fstat(fd, &sb)) {
23: perror("fstat");
24: return 1;
25: }
26:
27: /* we could just as well map it MAP_PRIVATE as we aren't writing
28: to it anyway */
29: region = mmap(NULL, sb.st_size, PROT_READ, MAP_SHARED, fd, 0);
30: if (region == ((caddr_t) -1)) {
31: perror("mmap");
32: return 1;
33: }
34:
35: close(fd);
36:
37: if (write(1, region, sb.st_size) != sb.st_size) {
38: perror("write");
39: return 1;
40: }
41:
42: return 0;
43: }
After a process is finished with a memory mapping, it can unmap the memory region through munmap(). This causes future accesses to that address to generate a SIGSEGV (unless the memory is subsequently remapped) and saves some system resources. All memory regions are unmapped when a process terminates or begins a new program through an exec() system call.
#include <sys/mman.h> int munmap(caddr_t addr, int length);
The addr is the address of the beginning of the memory region to unmap, and length specifies how much of the memory region should be unmapped. Normally, each mapped region is unmapped by a single munmap() call. Linux can fragment maps if only a portion of a mapped region is unmapped, but this is not a portable technique.
If a memory map is being used to write to a file, the modified memory pages and the file will be different for a period of time. If a process wishes to immediately write the pages to disk, it may use msync().
#include <sys/mman.h> int msync(caddr_t addr, size_t length, int flags);
The first two parameters, addr and length, specify the region to sync to disk. The flags parameter specifies how the memory and disk should be synchronized. It consists of one or more of the following flags bitwise OR’ed together:
| The modified portions of the memory region are scheduled to be synchronized “soon.” Only one of |
| The modified pages in the memory region are written to disk before the |
| This option lets the kernel decide whether the changes are ever written to disk. Although this does not ensure that they will not be written, it tells the kernel that it does not have to save the changes. This flag is used only under special circumstances. |
| Passing |
Under Linux and most other modern operating systems, memory regions may be paged to disk (or discarded if they can be replaced in some other manner) when memory becomes scarce. Applications that are sensitive to external timing constraints may be adversely affected by the delay that results from the kernel paging memory back into RAM when the process needs it. To make these applications more robust, Linux allows a process to lock memory in RAM to make these timings more predictable. For security reasons, only processes running with root permission may lock memory.[15] If any process could lock regions of memory, a rogue process could lock all the system’s RAM, making the system unusable. The total amount of memory locked by a process cannot exceed its RLIMIT_MEMLOCK usage limit.[16]
The following calls are used to lock and unlock memory regions:
#include <sys/mman.h> int mlock(caddr_t addr, size_t length); int mlockall(int flags); int munlock(caddr_t addr, size_t length); int munlockall(void);
The first of these, mlock(), locks length bytes starting at address addr. An entire page of memory must be locked at a time, so mlock() actually locks all the pages between the page containing the first address and the page containing the final address to lock, inclusively. When mlock() returns, all the affected pages will be in RAM.
If a process wants to lock its entire address space, mlockall() should be used. The flags argument is one or both of the following flags bitwise OR’ed together:
| All the pages currently in the process’s address space are locked into RAM. They will all be in RAM when |
All pages added to the process’s address space will be locked into RAM. |
Unlocking memory is nearly the same as locking it. If a process no longer needs any of its memory locked, munlockall() unlocks all the process’s pages. munlock() takes the same arguments as mlock() and unlocks the pages containing the indicated region.
Locking a page multiple times is equivalent to locking it once. In either case, a single call to munlock() unlocks the affected pages.
Although it is common for multiple processes to access a single file, doing so must be done carefully. Many files include complex data structures, and updating those data structures creates the same race conditions involved in signal handlers and shared memory regions.
There are two types of file locking. The most common, advisory locking, is not enforced by the kernel. It is purely a convention that all processes that access the file must follow. The other type, mandatory locking, is enforced by the kernel. When a process locks a file for writing, other processes that attempt to read or write to the file are suspended until the lock is released. Although this may seem like the more obvious method, mandatory locks force the kernel to check for locks on every read() and write(), substantially decreasing the performance of those system calls.
Linux provides two methods of locking files: lock files and record locking.
Lock files are the simplest method of file locking. Each data file that needs locking is associated with a lock file. When that lock file exists, the data file is considered locked and other processes do not access it. When the lock file does not exist, a process creates the lock file and then accesses the file. As long as the procedure for creating the lock file is atomic, ensuring that only one process at a time can “own” the lock file, this method guarantees that only one process accesses the file at a time.
This idea is pretty simple. When a process wants to access a file, it locks the file as follows:
fd = open("somefile.lck", O_RDONLY, 0644);
if (fd >= 0) {
close(fd);
printf("the file is already locked");
return 1;
} else {
/* the lock file does not exist, we can lock it and access it */
fd = open("somefile.lck", O_CREAT | O_WRONLY, 0644");
if (fd < 0) {
perror("error creating lock file");
return 1;
}
/* we could write our pid to the file */
close(fd);
}
When the process is done with the file, it calls unlink("somefile.lck"); to release the lock.
Although the above code segment may look correct, it would allow multiple processes to lock the same file under some circumstances, which is exactly what locking is supposed to avoid. If a process checks for the lock file’s existence, sees that the lock does not exist, and is then interrupted by the kernel to let other processes run, another process could lock the file before the original process creates the lock file! The O_EXCL flag to open() is available to make lock file creation atomic, and hence immune to race conditions. When O_EXCL is specified, open() fails if the file already exists. This simplifies the creation of lock files, which is properly implemented as follows.
fd = open("somefile.lck", O_WRONLY | O_CREAT | O_EXCL, 0644);
if (fd < 0 && errno == EEXIST) {
printf("the file is already locked");
return 1;
} else if (fd < 0) {
perror("unexpected error checking lock");
return 1;
}
/* we could write our pid to the file */
close(fd);
Lock files are used to lock a wide variety of standard Linux files, including serial ports and the /etc/passwd file. Although they work well for many applications, they do suffer from a number of serious drawbacks.
Only one process may have the lock at a time, preventing multiple processes from reading a file simultaneously. If the file is updated atomically,[17] processes that read the file can ignore the locking issue, but atomic updates are difficult to guarantee for complex file structures.
The
O_EXCLflag is reliable only on local file systems. None of the network file systems supported by Linux preserveO_EXCLsemantics between multiple machines that are locking a common file.[18]The locking is only advisory; processes can update the file despite the existence of a lock.
If the process that holds the lock terminates abnormally, the lock file remains. If the pid of the locking process is stored in the lock file, other processes can check for the existence of the locking process and remove the lock if it has terminated. This is, however, a complex procedure that is no help if the pid is being reused by another process when the check is made.
To overcome the problems inherent with lock files, record locking was added to both System V and BSD 4.3 through the lockf() and flock() system calls, respectively. POSIX defined a third mechanism for record locking that uses the fcntl() system call. Although Linux supports all three interfaces, we discuss only the POSIX interface, as it is now supported by nearly all Unix platforms. The lockf() function is implemented as an interface to fcntl(), however, so the rest of this discussion applies to both techniques.
There are two important distinctions between record locks and lock files. First of all, record locks lock an arbitrary portion of the file. For example, process A may lock bytes 50-200 of a file while another process locks bytes 2,500-3,000, without having the two locks conflict. Fine-grained locking is useful when multiple processes need to update a single file. The other advantage of record locking is that the locks are held by the kernel rather than the file system. When a process is terminated, all the locks it holds are released.
Like lock files, POSIX locks are also advisory. Linux, like System V, provides a mandatory variant of record locking that may be used but is not as portable. File locking may or may not work across networked file systems. Under recent versions of Linux, file locking works across NFS as long as all of the machines participating in the locks are running the NFS locking daemon lockd.
Record locking provides two types of locks: read locks and write locks. Read locks are also known as shared locks, because multiple processes may simultaneously hold read locks over a single region. It is always safe for multiple processes to read a data structure that is not being updated. When a process needs to write to a file, it must get a write lock (or exclusive lock). Only one process may hold a write lock for a record, and no read locks may exist for the record while the write lock is in place. This ensures that a process does not interfere with readers while it is writing to a region.
Multiple locks from a single process never conflict.[19] If a process has a read lock on bytes 200-250 and tries to get a write lock on the region 200-225, it will succeed. The original lock is moved and becomes a read lock on bytes 226-250, and the new write lock from 200-225 is granted.[20] This rule prevents a process from forcing itself into a deadlock (although multiple processes can still deadlock).
POSIX record locking is done through the fcntl() system call. Recall from Chapter 11 that fcntl() looks like this:
#include <fcntl.h> int fcntl(int fd, int command, long arg);
For all of the locking operations, the third parameter (arg) is a pointer to a struct flock.
#include <fcntl.h>
struct flock {
short l_type;
short l_whence;
off_t l_start;
off_t l_len;
pid_t l_pid;
};
The first element, l_type, tells what type of lock is being set. It is one of the following:
| A read(shared) lock is being set. |
| A write (exclusive) lock is being set. |
| An existing lock is being removed. |
The next two elements, l_whence and l_start, specify where the region begins in the same manner file offsets are passed to lseek(). l_whence tells how l_start is to be interpreted and is one of SEEK_SET, SEEK_CUR, and SEEK_END; see page 171 for details on these values. The next entry, l_len, tells how long, in bytes, the lock is. If l_len is 0, the lock is considered to extend to the end of the file. The final entry, l_pid, is used only when locks are being queried. It is set to the pid of the process that owns the queried lock.
There are three fcntl() commands that pertain to locking the file. The operation is passed as the second argument to fcntl(). fcntl() returns -1 on error and 0 otherwise. The command argument should be set to one of the following:
| Sets the lock described by |
| Similar to |
| Checks to see if the described lock would be granted. If the lock would be granted, the |
Although F_GETLK allows a process to check whether a lock would be granted, the following code sequence could still fail to get a lock:
fcntl(fd, F_GETLK, &lockinfo);
if (lockinfo.l_type != F_UNLCK) {
fprintf(stderr, "lock conflict
");
return 1;
}
lockinfo.l_type = F_RDLCK;
fcntl(fd, F_SETLK, &lockinfo);
Another process could lock the region between the two fcntl() calls, causing the second fcntl() to fail to set the lock.
As a simple example of record locking, here is a program that opens a file, obtains a read lock on the file, frees the read lock, gets a write lock, and then exits. Between each step, the program waits for the user to press return. If it fails to get a lock, it prints the pid of a process that holds a conflicting lock and waits for the user to tell it to try again. Running this sample program in two terminals makes it easy to experiment with POSIX locking rules.
1: /* lock.c */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <stdio.h>
6: #include <unistd.h>
7:
8: /* displays the message, and waits for the user to press
9: return */
10: void waitforuser(char * message) {
11: char buf[10];
12:
13: printf("%s", message);
14: fflush(stdout);
15:
16: fgets(buf, 9, stdin);
17: }
18:
19: /* Gets a lock of the indicated type on the fd which is passed.
20: The type should be either F_UNLCK, F_RDLCK, or F_WRLCK */
21: void getlock(int fd, int type) {
22: struct flock lockinfo;
23: char message[80];
24:
25: /* we'll lock the entire file */
26: lockinfo.l_whence = SEEK_SET;
27: lockinfo.l_start = 0;
28: lockinfo.l_len = 0;
29:
30: /* keep trying until we succeed */
31: while (1) {
32: lockinfo.l_type = type;
33: /* if we get the lock, return immediately */
34: if (!fcntl(fd, F_SETLK, &lockinfo)) return;
35:
36: /* find out who holds the conflicting lock */
37: fcntl(fd, F_GETLK, &lockinfo);
38:
39: /* there's a chance the lock was freed between the F_SETLK
40: and F_GETLK; make sure there's still a conflict before
41: complaining about it */
42: if (lockinfo.l_type != F_UNLCK) {
43: sprintf(message, "conflict with process %d... press "
44: "<return> to retry:", lockinfo.l_pid);
45: waitforuser(message);
46: }
47: }
48: }
49:
50: int main(void) {
51: int fd;
52:
53: /* set up a file to lock */
54: fd = open("testlockfile", O_RDWR | O_CREAT, 0666);
55: if (fd < 0) {
56: perror("open");
57: return 1;
58: }
59:
60: printf("getting read lock
");
61: getlock(fd, F_RDLCK);
62: printf("got read lock
");
63:
64: waitforuser("
press <return> to continue:");
65:
66: printf("releasing lock
");
67: getlock(fd, F_UNLCK);
68:
69: printf("getting write lock
");
70: getlock(fd, F_WRLCK);
71: printf("got write lock
");
72:
73: waitforuser("
press <return> to exit:");
74:
75: /* locks are released when the file is closed */
76:
77: return 0;
78: }
Locks are treated differently from other file attributes. Locks are associated with a (pid, inode) tuple, unlike most attributes of open files, which are associated with a file descriptor or file structure. This means that if a process
Opens a single file twice, resulting in two different file descriptors
Gets read locks on a single region in both file descriptors
Closes one of the file descriptors
then the file is no longer locked by the process. Only a single read lock was granted because only one (pid, inode) pair was involved (the second lock attempt succeeded because a process’s locks can never conflict), and after one of the file descriptors is closed, the process does not have any locks on the file!
After a fork(), the parent process retains its file locks, but the child process does not. If child processes were to inherit locks, two processes would end up with a write lock on the same region of a file, which file locks are supposed to prevent.
File locks are inherited across an exec(), however. While POSIX does not define what happens to locks after an exec(), all variants of Unix preserve them.[21]
Both Linux and System V provide mandatory locking, as well as normal locking. Mandatory locks are established and released through the same fcntl() mechanism that is used for advisory record locking. The locks are mandatory if the locked file’s setgid bit is set but its group execute bit is not set. If this is not the case, advisory locking is used.
When mandatory locking is enabled, the read() and write() system calls block when they conflict with locks that have been set. If a process tries to write() to a portion of a file that a different process has a read or write lock on, the process without the lock blocks until the lock is released. Similarly, read() calls block on regions that are included in mandatory write locks.
Mandatory record locking causes a larger performance loss than advisory locking, because every read() and write() call must be checked for conflicts with locks. It is also not as portable as POSIX advisory locks, so we do not recommend using mandatory locking in most applications.
Both advisory and mandatory locking are designed to prevent a process from accessing a file, or part of a file, that another process is using. When a lock is in place, the process that needs access to the file has to wait for the process owning the lock to finish. This structure is fine for most applications, but occasionally a program would like to use a file until someone else needs it, and is willing to give up exclusive access to the file if necessary. To allow this, Linux provides file leases (other systems call these opportunistic locks, or oplocks).[22]
Putting a lease on a file allows a process to be notified (via a signal) when that file is accessed by another process. There are two types of leases available: read leases and write leases. A read lease causes a signal to be sent when the file is opened for writing, opened with O_TRUNC, or truncate() is called for that file. A write lease also sends a signal when the file is opened for reading.[23] File leases work only for modifications made to the file by the same system running the application that owns the lease. If the file is a local file (not a file being accessed across the network), any appropriate file access triggers a signal. If the file is being accessed across the network, only processes on the same machine as the leaseholder cause the signal to be sent; accesses from any other machine proceed as if the lease were not in place.
The fcntl() system call is used to create, release, and inquire about file leases. Leases can be placed only on normal files (they cannot be placed on files such as pipes or directories), and write leases are granted only to the owner of a file. The first argument to fcntl() is the file descriptor we are interested in monitoring, and the second argument, command, specifies what operation to perform.
| A lease is created or released, depending on the value of the final argument to |
| The type of lease currently in place for the file is returned (one of |
[24] Older kernels could return either zero or one on success, while newer ones always return zero on success. In either case, checking for negative or nonnegative works fine. | |
When one of the monitored events occurs on a leased file, the kernel sends the process holding the lease a signal. By default, SIGIO is sent, but the process can choose which signal is sent for that file by calling fcntl() with the second argument set to F_SETSIG and the final argument set to the signal that should be used instead.
Using F_SETSIG has one other important effect. By default, no siginfo_t is passed to the handler when SIGIO is delivered. If F_SETSIG has been used, even if the signal the kernel is told to deliver is SIGIO, and SA_SIGINFO was specified when the signal handler was registered, the file descriptor whose lease triggered the event is passed to the signal handler as the si_fd member of the siginfo_t passed to the signal handler. This allows a single signal to be used for leases on multiple files, with si_fd letting the signal handler know which file needs attention.[25]
The only two system calls that can cause a signal to be sent for a leased file are open() and truncate(). When they are called by a process on a file that has a lease in place, those system calls block[26] and the process holding the lease is sent a signal. The open() or truncate() completes after the lease has been removed from the file (or the file is closed by the process holding the lease, which causes the lease to be released). If the process holding the lease does not remove the release within the amount of time specified in the file /proc/sys/fs/lease-break-time, the kernel breaks the lease and lets the triggering system call complete.
Here is an example of using file leases to be notified when another process needs to access a file. It takes a list of files from the command line and places write leases on each of them. When another process wants to access the file (even for reading, since a write lock was used) the program releases its lock on the file, allowing that other process to continue. It also prints a message saying which file was released.
1: /* leases.c */
2:
3: #define _GNU_SOURCE
4:
5: #include <fcntl.h>
6: #include <signal.h>
7: #include <stdio.h>
8: #include <string.h>
9: #include <unistd.h>
10:
11: const char ** fileNames;
12: int numFiles;
13:
14: void handler(int sig, siginfo_t * siginfo, void * context) {
15: /* When a lease is up, print a message and close the file.
16: We assume that the first file we open will get file
17: descriptor 3, the next 4, and so on. */
18:
19: write(1, "releasing ", 10);
20: write(1, fileNames[siginfo->si_fd - 3],
21: strlen(fileNames[siginfo->si_fd - 3]));
22: write(1, "
", 1);
23: fcntl(siginfo->si_fd, F_SETLEASE, F_UNLCK);
24: close(siginfo->si_fd);
25: numFiles--;
26: }
27:
28: int main(int argc, const char ** argv) {
29: int fd;
30: const char ** file;
31: struct sigaction act;
32:
33: if (argc < 2) {
34: fprintf(stderr, "usage: %s <filename>+
", argv[0]);
35: return 1;
36: }
37:
38: /* Register the signal handler. Specifying SA_SIGINFO lets
39: the handler learn which file descriptor had the lease
40: expire. */
41: act.sa_sigaction = handler;
42: act.sa_flags = SA_SIGINFO;
43: sigemptyset(&act.sa_mask);
44: sigaction(SIGRTMIN, &act, NULL);
45:
46: /* Store the list of filenames in a global variable so that
47: the signal handler can access it. */
48: fileNames = argv + 1;
49: numFiles = argc - 1;
50:
51: /* Open the files, set the signal to use, and create the
52: lease */
53: for (file = fileNames; *file; file++) {
54: if ((fd = open(*file, O_RDONLY)) < 0) {
55: perror("open");
56: return 1;
57: }
58:
59: /* We have to use F_SETSIG for the siginfo structure to
60: get filled in properly */
61: if (fcntl(fd, F_SETSIG, SIGRTMIN) < 0) {
62: perror("F_SETSIG");
63: return 1;
64: }
65:
66: if (fcntl(fd, F_SETLEASE, F_WRLCK) < 0) {
67: perror("F_SETLEASE");
68: return 1;
69: }
70: }
71:
72: /* As long as files remain open, wait for signals. */
73: while (numFiles)
74: pause();
75:
76: return 0;
77: }
While the read() and write() system calls are all applications need to retrieve and store data in a file, they are not always the fastest method. They allow a single piece of data to be manipulated; if multiple pieces of data need to be written, multiple system calls are required. Similarly, if the application needs to access data in different locations in the file, it must call lseek() between every read() or write(), doubling the number of system calls needed. To improve efficiency, there are other system calls that improve things.
Applications often want to read and write various types of data to consecutive areas of a file. Although this can be done fairly easily through multiple read() and write() calls, this solution is not particularly efficient. Applications could instead move all the data into a consecutive memory region, allowing a single system call, but doing so results in many unnecessary memory operations.
Linux provides readv() and writev(), which implement scatter/gather reads and writes.[27] Instead of being passed a single pointer and buffer size, as their standard siblings are, these system calls are passed an array of records, each record describing a buffer. The buffers get read from or written to in the order they are listed in the array. Each buffer is described by a struct iovec.
#include <sys/uio.h>
struct iovec {
void * iov_base; /* buffer address */
size_t iov_len; /* buffer length */
};
The first element, iov_base, points to the buffer space. The iov_len item is the number of characters in the buffer. These items are the same as the second and third parameters passed to read() and write().
Here are the prototypes for readv() and writev():
#include <sys/uio.h> int readv(int fd, const struct iovec * vector, size_t count); int writev(int fd, const struct iovec * vector, size_t count);
The first argument is the file descriptor to be read from or written to. The second, vector, points to an array of count struct iovec items. Both functions return the total number of bytes read or written.
Here is a simple example program that uses writev() to display a simple message on standard output:
1: /* gather.c */
2:
3: #include <sys/uio.h>
4:
5: int main(void) {
6: struct iovec buffers[3];
7:
8: buffers[0].iov_base = "hello";
9: buffers[0].iov_len = 5;
10:
11: buffers[1].iov_base = " ";
12: buffers[1].iov_len = 1;
13:
14: buffers[2].iov_base = "world
";
15: buffers[2].iov_len = 6;
16:
17: writev(1, buffers, 3);
18:
19: return 0;
20: }
Programs that use binary files often look something like this:
lseek(fd, SEEK_SET, offset1); read(fd, buffer, bufferSize); offset2 = someOperation(buffer); lseek(fd, SEEK_SET, offset2); read(fd, buffer2, bufferSize2); offset3 = someOperation(buffer2); lseek(fd, SEEK_SET, offset3); read(fd, buffer3, bufferSize3);
The need to lseek() to a new location before every read() doubles the number of system calls, as the file pointer is never positioned correctly after a read() because the data is not stored in the file consecutively. There are alternatives to read() and write() that require the file offset as a parameter, and neither alternative uses the file pointer to know what part of the file to access or to update it. Both functions work only on seekable files, as nonseekable files can be read from and written to only at the current location.
#define _XOPEN_SOURCE 500 #include <unistd.h> size_t pread(int fd, void *buf, size_t count, off_t offset); size_t pwrite(int fd, void *buf, size_t count, off_t offset); #endif
These look just like the prototypes for read() and write() with a fourth parameter, offset. The offset specifies which point in the file the data should be read from or written to. Like their namesakes, these functions return the number of bytes that were transferred. Here is a version of pread() implemented using read() and lseek() that should make its function easy to understand:[28]
int pread(int fd, void * data, int size, int offset) {
int oldOffset;
int rc;
int oldErrno;
/* move the file pointer to the new location */
oldOffset = lseek(fd, SEEK_SET, offset);
if (oldOffset < 0) return -1;
rc = read(fd, data, size);
/* restore the file pointer, being careful to save errno */
oldErrno = errno;
lseek(fd, SEEK_SET, oldOffset);
errno = oldErrno;
return rc;
}
[2] This is similar to sigset_t used for signal masks.
[3] When a network socket being listen() ed to is ready to be accept() ed, it is considered ready to be read from for select()’s purposes; information on sockets is in Chapter 17.
[4] If you compare this to the numfds parameter for poll() you’ll see where the confusion comes from.
[5] Except for some experimental kernels in the 2.1 series.
[6] When Linus Torvalds first implemented select(), the BSD man page for select() listed the BSD kernel’s failure to update the timeout as a bug. Rather than write buggy code, Linus decided to “fix” this bug. Unfortunately, the standards commitees decided they liked BSD’s behavior.
[7] The kernel actually sets a callback on each file, and when those events occur the callback is invoked. This mechanism eliminates the scaling problems with very large numbers of file descriptors as polling is not used at any point.
[8] EPOLLET is one more value events can have, which switches epoll from being level-triggered to edge-triggered. This topic is beyond the scope of this book, and edge-triggered epoll should be used only under very special circumstances.
[9] The structure shown in the text gives the right member sizes on most platforms, but it is not correct for machines that define an int as 64 bits.
[10] The program needs to be run as root for sets larger than about 1,000 descriptors.
[11] This testing was not done particularly scientifically. Only a single test run was done, so the results show a little bit of jitter that would disappear over a large number of repetitions.
[12] Although saving a memory copy may not seem that important, thanks to Linux’s efficient caching mechanism, these copy latencies are the slowest part of writing to data files that do not have O_SYNC set.
[13] Although most character devices cannot be mapped, /dev/zero can be mapped for exactly this type of application.
[14] A segmentation fault will result when you try to access an unallocated page.
[15] This may change in the future as finer-grained system permissions are implemented in the kernel.
[16] See pages 118-119 for information on resource limits.
[17] /etc/passwd is updated only by processes that create a new copy of the file with the modifications and then replace the original through a rename() system call. As this sequence provides an atomic update, processes may read from /etc/passwd at any time.
[18] The Andrew Filesystem (AFS), which is available for Linux but not included in the standard kernel, does support O_EXCL across a network.
[19] This situation is more complicated for threads. Many Linux kernels and libraries treat threads as different processes, which raises the potential of file lock conflicts between threads (which is incompatible with the standard POSIX threads model).
[20] This lock manipulation happens atomically—there is no point at which any part of the region is unlocked.
Linux is moving toward a more conventional thread model which shares file locks between all of the threads of a single process, but threaded programs should use the POSIX thread locking mechanisms instead of relying on either behavior for file locks.
[21] The effect of fork() and exec() calls on file locks is the biggest difference between POSIX file locking (and hence lockf() file locking) and BSD’s flock() file locking.
[22] By far the most common user of file leases is the samba file server, which uses file leases to allow clients to cache their writes to increase performance.
[23] If it seems a little strange that a write lease notifies the process of opening the file for reading, think of it from the point of view of the process taking out the lease. It would need to know if another process wanted to read from the file only if it was itself writing to that file.
[25] If one signal is used for leases on multiple files, make sure the signal is a real-time signal so that multiple lease events are queued. If a regular signal is used, signals may get lost if the lease events occur close together.
[26] Unless O_NONBLOCK was specified as a flag to open(), in which case EWOULDBLOCK would be returned.
[27] They are so named because the reads scatter data across memory, and the writes gather data from different memory regions. They are also known as vector reads and writes, which is the origin of the v at the end of readv() and writev().
[28] This emulated version gets most of the behavior right, but it acts differently than the actual system call if signals are received while it is being executed.