
Chapter 9. Logfiles and Monitoring
Hacks 78–88: Introduction
The only thing worse than disastrous disk failures, runaway remote hosts, and insidious security incidents is the gut-wrenching feeling that comes with the realization that they probably could’ve been avoided.
To avert catastrophe, often the best tool you can have is access to data that enables you to take proactive steps. Whether it’s having a disk tell you when it’s about to expire or being informed of network or service outages, tools that aggregate data and alert you to anomalies are invaluable to system and network administrators. The goal of this chapter is to show you how to get data you don’t currently have, and how to use data you do have in more useful ways.
Avoid Catastrophic Disk Failure
Access your hard drive’s built-in diagnostics using Linux utilities to predict and prevent disaster.
Nobody wants to walk in after a power failure only to realize that, in addition to everything else, because of a dead hard drive they now have to rebuild entire servers and grab backed-up data from tape. Of course, the best way to avoid this situation is to be alerted when something is amiss with your SCSI or ATA hard drive, before it finally fails. Ideally the alert would come straight from the hard drive itself, but until we’re able to plug an RJ-45 directly into a hard drive we’ll have to settle for the next best thing, which is the drive’s built-in diagnostics. For several years now, ATA and SCSI drives have supported a standard mechanism for disk diagnostics called “Self Monitoring, Analysis, and Reporting Technology” (SMART), aimed at predicting hard drive failures. It wasn’t long before Linux had utilities to poll hard drives for this vital information.
The smartmontools project (http://smartmontools.sourceforge.net) produces a SMART monitoring daemon called smartd and a command-line utility called smartctl, which can do most things on demand that the daemon does in the background periodically. With these tools, along with standard Linux filesystem utilities such as debugfs and tune2fs, there aren’t many hard drive issues you can’t fix.
But before you can repair anything or transform yourself into a seemingly superpowered hard-drive hero with powers on loan from the realm of the supernatural, you have to know what’s going on with your drives, and you need to be alerted to changes in the status of the health of your drives.
First, you should probably get to know your drives a bit, which smartctl can help out with. If you know that there are three drives in use on the system, but you’re not sure which one the system is labeling /dev/hda, run the following command:
# smartctl -i /dev/hdaThis will tell you the model and capacity information for that drive. This is also very helpful in figuring out which vendor you’ll need to call for a replacement drive if you bought the drive yourself. Once you know what’s what, you can move on to bigger tasks.
Typically, before I even set up the smartd daemon to do long-term, continuous monitoring of a drive, I first run a check from the command line (using the smartctl command) to make sure I’m not wasting time setting up monitoring on a disk that already has issues. Try running a command like the following to ask the drive about its overall health:
# smartctl -H /dev/hda
smartctl version 5.33 [i386-redhat-linux-gnu] Copyright (C) 2002-4 Bruce
Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSEDWell, this is good news—the drive says it’s in good shape. However, there really wasn’t much to look at there. Let’s get a more detailed view of things using the -a, or “all,” flag. This gives us lots of output, so let’s go over it in pieces. Here’s the first bit:
# smartctl -a /dev/hda
smartctl version 5.33 [i386-redhat-linux-gnu] Copyright (C) 2002-4 Bruce
Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF INFORMATION SECTION ===
Device Model: WDC WD307AA
Serial Number: WD-WMA111283666
Firmware Version: 05.05B05
User Capacity: 30,758,289,408 bytes
Device is: In smartctl database [for details use: -P show]
ATA Version is: 4
ATA Standard is: Exact ATA specification draft version not indicated
Local Time is: Mon Sep 5 17:48:09 2005 EDT
SMART support is: Available - device has SMART capability.
SMART support is: EnabledThis is the exact same output that smartctl
-i would’ve shown you earlier. It tells you the model, the firmware version, the capacity, and which version of the ATA standard is implemented with this drive. Useful, but not really a measure of health per se. Let’s keep looking:
=== START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED
This is the same output that smartctl
-H showed earlier. Glad we passed, but if we just barely made it, that’s not passing to a discriminating administrator. More!
General SMART Values: Offline data collection status: (0x05) Offline data collection activity was aborted by an interrupting command from host. Auto Offline Data Collection: Disabled. Self-test execution status: ( 113) The previous self-test completed having the read element of the test failed.
These are the values of the SMART attributes the device supports. We can see here that offline data collection is disabled, which means we can’t run “offline” tests (which run automatically when the disk would otherwise be idle). We can enable it using the command smartctl -o on, but this may not be what you want, so let’s hold off on that for now. The self-test execution status shows that a read operation failed during the last self-test, so we’ll keep that in mind as we continue looking at the data:
Total time to complete Offline data collection: (2352) seconds. Offline data collection capabilities: (0x1b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. No Conveyance Self-test supported. No Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. No General Purpose Logging support.
This output is just a list of the general SMART-related capabilities of the drive, which is good to know, especially for older drives that might not have all of the features you would otherwise assume to be present. Capabilities and feature support in the drives loosely follow the version of the ATA standard in place when the drive was made, so it’s not safe to assume that an ATA-4 drive will support the same feature set as an ATA-5 or later drive.
Let’s continue on our tour of the output:
Short self-test routine recommended polling time: ( 2) minutes. Extended self-test routine recommended polling time: ( 42) minutes.
When you tell this drive to do a short self-test, it’ll tell you to wait two minutes for the results. A long test will take 42 minutes. If this drive were new enough to support other self-test types (besides just “short” and “extended”), there would be lines for those as well. Here’s the next section of output:
SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000b 200 200 051 Pre-fail Always - 0 3 Spin_Up_Time 0x0006 101 091 000 Old_age Always - 2550 4 Start_Stop_Count 0x0012 100 100 040 Old_age Always - 793 5 Reallocated_Sector_Ct 0x0012 198 198 112 Old_age Always - 8 9 Power_On_Hours 0x0012 082 082 000 Old_age Always - 13209 10 Spin_Retry_Count 0x0013 100 100 051 Pre-fail Always - 0 11 Calibration_Retry_Count 0x0013 100 100 051 Pre-fail Always - 0 12 Power_Cycle_Count 0x0012 100 100 000 Old_age Always - 578 196 Reallocated_Event_Count 0x0012 196 196 000 Old_age Always - 4 197 Current_Pending_Sector 0x0012 199 199 000 Old_age Always - 10 198 Offline_Uncorrectable 0x0012 199 198 000 Old_age Always - 10 199 UDMA_CRC_Error_Count 0x000a 200 253 000 Old_age Always - 0 200 Multi_Zone_Error_Rate 0x0009 200 198 051 Pre-fail Offline - 0
Details on how to read this chart, in gory-enough detail, are in the sysctl manpage. The most immediate values to concern yourself with are the ones labeled Pre-fail. On those lines, an indicator of the need for immediate action is if the VALUE column output descends to or below the value in the THRESH column. Continuing on:
SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 10% 97 57559262 # 2 Extended offline Aborted by host 50% 97 - # 3 Short offline Completed without error 00% 97 - Device does not support Selective Self Tests/Logging
This output is the log output from the last three tests. The numbering of the tests is actually the reverse of what you might think: the one at the top of the list, labeled as #1, is actually the most recent test. In that test we can see that there was a read error, and the LBA address of the first failure is posted (57559262). If you want to see how you can associate that test with an actual file, Bruce Allen has posted a wonderful HOWTO for this at http://smartmontools.sourceforge.net/BadBlockHowTo.txt.
Now that you’ve seen what smartctl can find out for us, let’s figure out how to get smartd configured to automate the monitoring process and let us know if danger is imminent.
Fortunately, putting together a basic configuration takes mere seconds, and more complex configurations don’t take a great deal of time to put together, either. The smartd process gets its configuration from /etc/smartd.conf on most systems, and for a small system (or a ton of small systems that you don’t want to generate copious amounts of mail), a line similar to the following will get you the bare essentials:
/dev/hda -H -m [email protected]This will do a (very) simple health status check on the drive, and email me only if it fails. If a health status check fails, it means the drive could very well fail in the next 24 hours, so have an extra drive handy!
There are more sophisticated setups as well that can alert you to changes in the status that don’t necessarily mean certain death. Let’s look at a more complex configuration line:
/dev/hda -l selftest -l error -I 9 -m [email protected] -s L/../../
7/02This one will look for changes in the self-test and error logs for the device, run a long self-test every Sunday between 2 and 3 A.M. and send me messages about any attribute except for ID 9, the Power_On_Hours attribute, which I don’t care about for the purposes of determining whether a disk is bad (you can check the sysctl
-a output to determine an attribute’s ID). The -I attribute is often used with attribute numbers 194 or 231, which usually is the temperature. It would be bad to get messages about the constantly changing temperature of the drive!
Once you have your configuration file in order, the only thing left to do is start the service. Inevitably, you’ll get more mail than you’d like in the first initial runs, but as time goes on (and you read more of the huge manpage) you’ll learn to get what you want from smartd. For me, just the peace of mind is worth the hours I’ve spent getting a working configuration. When you’re able to avert certain catastrophe for a client or yourself, I’m sure you’ll say the same.
Monitor Network Traffic with MRTG
The Multi-Router Traffic Grapher provides a quick visual snapshot of network traffic, making it easy to find and resolve congestion.
There are many reasons it’s a good idea to capture data pertaining to your network and bandwidth usage. Detailed visual representations of such data can be incredibly useful in determining the causes of network outages, bottlenecks, and other issues. Collecting such detailed data used to require sophisticated and expensive equipment, but with the advent of Linux and the widespread use of SNMP, we now have a new tool to simplify and expand the possibilities of bandwidth monitoring. This tool is called the Multi-Router Traffic Grapher (MRTG), and this hack shows you how to set it up and use it.
Requirements
MRTG has a few simple dependencies that you may need to fulfill before you dive right into the installation. For starters, you need to have a web server up and running. Apache is typically recommended, but you may be able to get it to work with other web servers. You’ll also need Perl installed and working on your system, and MRTG will require three libraries to build its graphs. The first, gd, is used to generate the graphs that make MRTG what it is. The second is libpng, which is used to generate the images of the graphs. Finally, to compress these images, you’ll need the zlib library. Download locations for all three of these libraries can be found at the MRTG home page (http://people.ee.ethz.ch/~oetiker/webtools/mrtg/).
Installation
Once you have the dependencies installed, you can begin the MRTG installation. First, download and untar the source to your build location. Start the MRTG installation with the following command:
$ ./configure–prefix=/usr/local/mrtg-2If this produces an error message, you may have to specify where you installed the previously mentioned libraries:
# ./configure–prefix=/usr/local/mrtg-2 --with-gf=/path/to/gd--with-z=/path/to/z --with-png=/path/to/png
If you need help determining where those libraries were installed, run the following command for each library to find its location:
# find / -type f–name libpngOnce configuration is complete, follow it up with a typical make install:
# make && make installThe next step is to create the mrtg.cfg file that MRTG will use to determine which devices on your network to query. If you had to create this by hand, things could get a little hairy. Fortunately for us, however, MRTG comes with a command-line configuration tool called cfgmaker that greatly simplifies the creation of the .cfg. Detailed documentation on cfgmaker is available at the MRTG home page, but the following example should be enough to get you started:
# cfgmaker–global 'WorkDir:/path/to/web/root/mrtg'--output=/etc/mrtg.cfg--global'Options[_]: bits, growright' --output=/etc/mrtg.cfg[email protected][email protected]Global 'Options[_]: bits, growright' --ifref=descry--ifdescr=alias[email protected]
This will create the configuration file /etc/mrtg.cfg, which will tell MRTG to create bandwidth graphs for router1, router2, and switch1. The graphs will use bits as the primary measurement on the y-axis and will grow toward the righthand side. The–global options add entries that apply to this configuration as a whole, while those that are not specified as global apply only to the devices in which we specify them. The location of the configuration file to create is specified by the–output option.
With a valid config file in hand, we can now run MRTG for the first time. Each time you run MRTG, you’ll need to specify the location from which you want it to read the config file. Also, unless you’ve added it to your path, you’ll need to type out the full path to the executable.
# /usr/local/bin/mrtg-2/bin/mrtg /etc/mrtg.cfgYou will see some errors the first two times you run MRTG, but pay them no mind—it’s simply complaining because it can’t find any previous MRTG data. After running the command, your MRTG web root should be filled with PNG files. This is great, except it’s a pain to look at them like this, and they’re not exactly labeled in a human friendly format. The solution to this problem can be found in the indexmaker tool. indexmaker works just like the cfgmaker tool, only instead of generating config files, it generates an HTML template with which we can display our MRTG graphs:
# indexmaker–output=/path/to/web/root/index.html–title="My Network MRTG"–sort=title
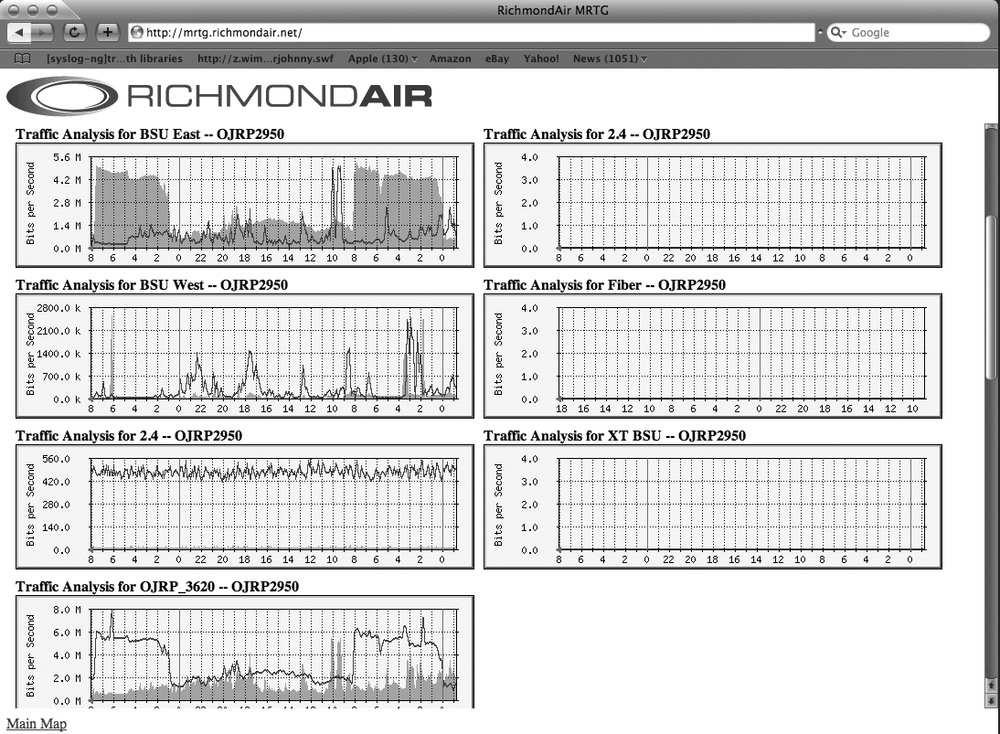
This will create an index.html file that sorts and displays our data in a much more user-friendly format, as shown in Figure 9-1. You can then modify the index file just as you would any HTML file to make it display any other information you wish.
Automating MRTG
The only thing left to do is to automate the process. MRTG wouldn’t be very useful if you had to start it manually every time, so we’ll have to automate it by adding it to cron. Add the following entry to root’s crontab to run MRTG every five minutes:
*/5 * * * * /usr/local/mrtg-2/bin/mrtg /etc/mrtg.cfg --logging /var/log/mrtg.log
Don’t get impatient waiting to see your pretty new graphs. It will take a day or so for them to begin displaying truly useful data. Once you’ve had them running for a while, though, you’ll be able to pick out all kinds of useful trends in your bandwidth utilization. For instance, you might notice that your bandwidth tends to spike between 8:30 and 9:00 A.M., and then again after lunch. This will help you better understand the utilization of your network, and in turn better serve it. It can be fascinating to simply watch your bandwidth utilization materialize, and then use the information to track and follow trends in network activity. MRTG will create yearly graphs as well as hourly, monthly, and daily graphs. Having such detailed information at your fingertips can help you understand just how much traffic you gained after your web site was Slashdotted, and how your popularity increased even after the story ran.
MRTG has a million uses, and they’re not just limited to tracking bandwidth utilization. With a little modification, you can use it to measure almost anything you want. For more information on modifying MRTG to display other statistics, see the MRTG home page.
Keep a Constant Watch on Hosts
Monitor load or other statistics for multiple hosts on your desktop or on the command line.
rstatd is an RPC-based kernel statistics server that is either included with or available for every form of Unix I’ve ever used. It isn’t something new. In fact, I suspect that its age might cause it to slip under the radar of younger admins, who might not know it if it hasn’t appeared on the front page of Freshmeat recently. Hopefully, the information here will pique your interest in this very useful tool.
When I say that rstatd provides “kernel statistics,” I’m referring to things such as CPU load, page swapping statistics, network IO statistics, and the like. Of course, providing this information to administrators in a way that is useful can sometimes be challenging, but there are a few tools available to help.
To make these tools useful, you must have a running rstatd daemon. Note that rstatd is dependent on the portmap daemon, which should already be running if you’re using other RPC-based services such as NIS or NFS. To do a quick check to make sure these are running, you can run the following command:
$ rpcinfo –p
program vers proto port
100000 2 tcp 111 portmapper
100000 2 udp 111 portmapper
100001 3 udp 646 rstatd
100001 2 udp 646 rstatd
100001 1 udp 646 rstatdWithout any other arguments, this will show you the status of the local host. If you put a hostname on the end of the above command, it will show you the status of a remote host. Now we’re ready to point some tools at this host!
First and foremost among these tools is the standard rup command, which is available on Linux and other Unix platforms. It’s a simple rstatd client utility, but with the right tools you can use it to produce output similar to that produced by the top command—only instead of monitoring processes on the local host, you can monitor the load on multiple machines. Here’s a command you can run to have a list of hosts, sorted by load average, updated every five seconds:
$ watch -n 5 rup -lhost1 host2 host3 host4 host5host3 up 12 days, 7:33, load average: 0.00, 0.00, 0.00 host4 up 12 days, 7:28, load average: 0.00, 0.00, 0.00 host1 up 12 days, 6:11, load average: 0.05, 0.04, 0.05 host2 up 12 days, 6:11, load average: 0.05, 0.04, 0.05 host5 up 12 days, 7:29, load average: 0.09, 0.06, 0.01
This is okay if you have no access to any kind of graphical environment. Of course, it takes over your terminal, so you’ll at least need to run it inside a screen session [Hack #34] or in a separate virtual terminal. Another problem here is that it’s just simple raw data output; it doesn’t alert you to any events, like host4’s load going through the stratosphere.
For that, we can move into graphical clients. An old favorite of mine is xmeter, which was developed long ago and has since seemingly been forgotten and abandoned. Its configuration takes a little time to sift through (it’s not graphical), but it does come with a manpage to help out, and once it’s configured the only thing you’ll ever have to change is the list of hosts to monitor. It provides configuration options to change the color of the output based on thresholds, so if the load of a machine gets to be a bit out of control, the color change is likely to catch your eye. Figure 9-2 shows a shot of xmeter monitoring the load on multiple hosts.

A more recent development in the world of rstatd data-collection tools is jperfmeter, which is a Java-based, cross-platform monitor with a more polished interface and a graphical configuration tool. It does not yet (at the time of writing) support thresholds, and it’s missing a few other finer details, but it’s a brand new tool, so I’m sure it will get there at some point.
There are other tools available for remote server statistics monitoring, but you may also want to look into building your own, using either the Rstat::Client Perl module or the RPC or rstat interfaces for other languages, such as Python, Java, or C/C++.
Remotely Monitor and Configure a Variety of Networked Equipment
Using SNMP, you can collect information about almost any device attached to your network.
For everything that has a network interface, chances are there’s some form of Simple Network Management Protocol (SNMP) daemon that can run on it. Over the years, SNMP daemons have been added to everything from environmental sensors to UPSs to soda vending machines. The point of all of this is to be able to remotely access as much information about the host as humanly possible. As an added bonus, proper configuration can allow administrators to change values on the host remotely as well.
SNMP daemon packages are available for all of the widely used distributions, along with possibly separate packages containing a suite of SNMP command-line tools. You might have come across the snmpwalk or snmpget commands before in your travels, or you might’ve seen similarly named functions in scripting languages such as Perl and PHP.
Let’s have a look at a small bit of a “walk” on an SNMP-enabled Linux host and use it to explain how this works:
$ snmpwalk -v2c -c public livid interfaces
IF-MIB::ifNumber.0 = INTEGER: 4
IF-MIB::ifIndex.1 = INTEGER: 1
IF-MIB::ifIndex.2 = INTEGER: 2
IF-MIB::ifIndex.3 = INTEGER: 3
IF-MIB::ifIndex.4 = INTEGER: 4
IF-MIB::ifDescr.1 = STRING: lo
IF-MIB::ifDescr.2 = STRING: eth0
IF-MIB::ifDescr.3 = STRING: eth1
IF-MIB::ifDescr.4 = STRING: sit0
IF-MIB::ifType.1 = INTEGER: softwareLoopback(24)
IF-MIB::ifType.2 = INTEGER: ethernetCsmacd(6)
IF-MIB::ifType.3 = INTEGER: ethernetCsmacd(6)
IF-MIB::ifType.4 = INTEGER: tunnel(131)
IF-MIB::ifPhysAddress.1 = STRING:
IF-MIB::ifPhysAddress.2 = STRING: 0:a0:cc:e7:24:a0
IF-MIB::ifPhysAddress.3 = STRING: 0:c:f1:d6:3f:32
IF-MIB::ifPhysAddress.4 = STRING: 0:0:0:0:3f:32
IF-MIB::ifAdminStatus.1 = INTEGER: up(1)
IF-MIB::ifAdminStatus.2 = INTEGER: up(1)
IF-MIB::ifAdminStatus.3 = INTEGER: down(2)
IF-MIB::ifAdminStatus.4 = INTEGER: down(2)
IF-MIB::ifOperStatus.1 = INTEGER: up(1)
IF-MIB::ifOperStatus.2 = INTEGER: up(1)
IF-MIB::ifOperStatus.3 = INTEGER: down(2)
IF-MIB::ifOperStatus.4 = INTEGER: down(2)As you can see, there’s a good bit of information here, and I’ve cut out the bits that aren’t important right now. Furthermore, this is only one part of one SNMP “tree” (the “interfaces” tree). Under that tree lie settings and status information for each interface on the system. If you peruse the list, you’ll see separate values for each interface corresponding to things like the interface description (the name the host calls the interface), the physical address, and the interface type.
But what is this “tree” I’m speaking of? SNMP data is actually organized much like LDAP data, or DNS data, or even your Linux system’s file hierarchy—they’re all trees! Our output above has hidden some of the detail from us, however. To see the actual path in the tree for each value returned, we’ll add an option to our earlier command:
$ snmpwalk -Of -v2c -c public livid interfaces
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifNumber.0 = INTEGER: 4
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifIndex.1 =
INTEGER: 1
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifIndex.2 =
INTEGER: 2
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifIndex.3 =
INTEGER: 3
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifIndex.4 =
INTEGER: 4
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifDescr.1 =
STRING: lo
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifDescr.2 =
STRING: eth0
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifDescr.3 =
STRING: eth1
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifDescr.4 =
STRING: sit0
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifType.1 =
INTEGER: softwareLoopback(24)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifType.2 =
INTEGER: ethernetCsmacd(6)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifType.3 =
INTEGER: ethernetCsmacd(6)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifType.4 =
INTEGER: tunnel(131)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifPhysAddress.1 =
STRING:
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifPhysAddress.2 =
STRING: 0:a0:cc:e7:24:a0
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifPhysAddress.3 =
STRING: 0:c:f1:d6:3f:32
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifPhysAddress.4 =
STRING: 0:0:0:0:3f:32
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifAdminStatus.1 =
INTEGER: up(1)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifAdminStatus.2 =
INTEGER: up(1)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifAdminStatus.3 =
INTEGER: down(2)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifAdminStatus.4 =
INTEGER: down(2)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifOperStatus.1 =
INTEGER: up(1)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifOperStatus.2 =
INTEGER: up(1)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifOperStatus.3 =
INTEGER: down(2)
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifOperStatus.4 =
INTEGER: down(2)Now we can clearly see that the “interfaces” tree sits underneath all of those other trees. If you replaced the dot separators with a forward slashes, it would look very much like a directory hierarchy, with the value after the last dot being the filename and everything after the equals sign being the content of the file. Now this should start to look a little more familiar—more like the output of a find command than something completely foreign (I hope).
A great way to get acquainted with an SNMP-enabled (or “managed”) device is to simply walk the entire tree for that device. You can do this by pointing the snmpwalk command at the device without specifying a tree, as we’ve done so far. Be sure to redirect the output to a file, though, because there’s far too much data to digest in one sitting! To do this, use a command like the following:
$ snmpwalk -Ov -v2c -c public livid > livid.walkYou can run the same command against switches, routers, firewalls, and even some specialized devices such as door and window contact sensors and environmental sensors that measure the heat and humidity in your machine room.
The Code
Even just sticking to Linux boxes offers a wealth of information. I’ve written a script in PHP, runnable from a command line, that gathers basic information and reports on listening TCP ports, using only SNMP. Here’s the script:
#!/usr/bin/php
<?php
snmp_set_quick_print(1);
$string = "public";
$host = "livid";
check_snmp($host);
spitinfo($host);
function check_snmp($box)//see if this box is running snmp before we throw
//requests at it.
{
$string="public";
$infocheck = @snmpget("$box", "$string", "system.sysDescr.0");
if(! $infocheck)
{
die("SNMP doesn't appear to be running on $box");
}
else
{
return $infocheck;
}
}
function spitinfo($host)//retrieves and displays snmp data.
{
$string = "public";
$hostinfo = @snmpget("$host","$string","system.sysDescr.0");
list ($k)=array(split(" ", $hostinfo));
$os = $k[0];
$hostname = @snmpget("$host","$string","system.sysName.0");
$user = @snmpget("$host","$string","system.sysContact.0");
$location = @snmpget("$host","$string","system.sysLocation.0");
$macaddr = @snmpget
("$host","$string","interfaces.ifTable.ifEntry.
ifPhysAddress.2");
$ethstatus =
@snmpget("$host","$string","interfaces.ifTable.ifEntry.
ifOperStatus.2");
$ipfwd = @snmpget("$host","$string","ip.ipForwarding.0");
$ipaddr = @gethostbyname("$host");
$info=array("Hostname:"=>"$hostname","Contact:"=>"$user",
"Location:"=>"$location","OS:"=>"$os","MAC Address:"=>
"$macaddr","IP Address:"=>"$ipaddr","Network Status"=>
"$ethstatus",
"Forwarding:"=>"$ipfwd");
print "$host
";
tabdata($info);
print "
TCP Port Summary
";
snmp_portscan($hostname);
}
function tabdata($data)
{
foreach($data as $label=>$value)
{
if($label){
print "$label ";
}else{
print "Not Available";
}
if($value){
print "$value
";
}else{
print "Not Available";
}
}
}
function snmp_portscan($target)
{
$listen_ports = snmpwalk("$target", "public", ".1.3.6.1.2.1.6.13.1.3.
0.0.0.0");
foreach($listen_ports as $key=>$value)
{
print "TCP Port $value (" . getservbyport($value, 'tcp') . ")
listening
";
}
}
?>Running the Code
Save this script to a file named report.php, and make it executable (chmod 775 report.php). Once that’s done, run it by issuing the command ./report.php.
I’ve hard-coded a value for the target host in this script to shorten things up a bit, but you’d more likely want to feed a host to the script as a command-line argument, or have it read a file containing a list of hosts to prod for data. You’ll also probably want to scan for the number of interfaces, and do other cool stuff that I’ve left out here to save space. Here’s the output when run against my Debian test system:
Hostname: livid Contact: jonesy([email protected] Location: Upstairs office OS: Linux MAC Address: 0:a0:cc:e7:24:a0 IP Address: 192.168.42.44 Network Status up Forwarding: notForwarding TCP Port Summary TCP Port 80 (http) listening TCP Port 111 (sunrpc) listening TCP Port 199 (smux) listening TCP Port 631 (ipp) listening TCP Port 649 ( ) listening TCP Port 2049 (nfs) listening TCP Port 8000 ( ) listening TCP Port 32768 ( ) listening
You’ll notice in the script that I’ve used numeric values to search for in SNMP. This is because, as in many other technologies, the human-readable text is actually mapped from numbers, which are what the machines use under the covers. Each record returned in an snmpwalk has a numeric object identifier, or OID. The client uses the Management Information Base (MIB) files that come with the Net-SNMP distribution to map the numeric OIDs to names. In a script, however, speed will be of the essence, so you’ll want to skip that mapping operation and just get at the data.
You’ll also notice that I’ve used SNMP to do what is normally done with a port scanner, or with a bunch of calls to some function like (in PHP) fsockopen. I could’ve used function calls here, but it would have been quite slow because we’d be knocking on every port in a range and awaiting a response to see which ones are open. Using SNMP, we’re just requesting the host’s list of which ports are open. No guessing, no knocking, and much, much faster.
Force Standalone Apps to Use syslog
Some applications insist on maintaining their own set of logs. Here’s a way to shuffle those entries over to the standard syslog facility.
The dream is this: working in an environment where all infrastructure services are running on Linux machines [Hack #44] using easy-to-find open source software such as BIND, Apache, Sendmail, and the like. There are lots of nice things about all these packages, not the least of which is that they all know about and embrace the standard Linux/Unix syslog facilities. What this means is that you can tell the applications to log using syslog, and then configure which log entries go where in one file (syslog.conf), instead of editing application-specific configuration files.
For example, if I want Apache to log to syslog, I can put a line like this one in my httpd.conf file:
ErrorLog syslog
This will, by default, log to the local7 syslog facility. You can think of a syslog facility as a channel into syslog. You configure syslog to tell it where entries coming in on a given channel should be written. So, if I want all messages from Apache coming in on the local7 channel to be written to /var/log/httpd, I can put the following line in /etc/syslog.conf:
local7.* /var/log/httpd
You can do this for the vast majority of service applications that run under Linux. The big win is that if an application misbehaves, you don’t have to track down its logfiles—you can always consult syslog.conf to figure out where your applications are logging to.
In reality, though, most environments are not 100% Linux. Furthermore, not all software is as syslog-friendly as we’d like. In fact, some software has no clue what syslog is, and these applications maintain their own logfiles, in their own logging directory, without an option to change that in any way. Some of these applications are otherwise wonderful services, but systems people are notoriously unrelenting in their demand for consistency in things like logging. So here’s the meat of this hack: an example of a service that displays selfish logging behavior, and one way to go about dealing with it.
Fedora Directory Server (FDS) can be installed from binary packages on Red Hat–based distributions, as well as on Solaris and HP-UX. On other Linux distributions, it can be built from source. However, on no platform does FDS know anything about the local syslog facility. Enter a little-known command called
logger.
The
logger command provides a generic shell interface to the syslog facility on your local machine. What this means is that if you want to write a shell or Perl script that logs to syslog without writing syslog-specific functions, you can just call logger from within the script, tell it what to write and which syslog facility to write it to, and you’re done!
Beyond that, logger can also take its input from stdin, which means that you can pipe information from another application to logger, and it will log whatever it receives as input from the application. This is truly beautiful, because now I can track down the FDS logs I’m interested in and send them to syslog with a command like this:
# exec tail -f /opt/fedora-ds/slapd-ldap/logs/access.log | logger -p local0. debug &I can then tell my syslog daemon to watch for all of the messages that have been piped to logger and sent to syslog on local0 and to put them in, say, /var/ log/ldap/access.log.
The debug on the end of the facility name is referred to in syslog parlance as a priority. There are various priority levels available for use by each syslog facility, so a given application can log messages of varying severity as being of different priorities
[Hack #86]
. FDS is a good example of an application where you’d want to utilize priorities—the access log for FDS can be extremely verbose, so you’re likely to want to separate those messages into their own logfile. Its error log is rarely written to at all, but the messages there can pertain to the availability of the service, so you might want those messages to go to /var/log/messages. Rather than using up another whole syslog facility to get those messages to another file, just run a command like this one:
# tail -f /opt/fedora-ds/slapd-ldap/logs/error.log | logger -p local0.noticeNow let’s tell syslog to log the messages to the proper files. Here are the configuration lines for the access and error logs:
local0.debug /var/log/ldap/access.log local0.notice /var/log/messages
There is one final enhancement you’ll probably want to make, and it has to do with logger’s output. Here’s a line that made it to a logfile from logger as we ran it above, with just a -p flag to indicate the facility to use:
Aug 26 13:30:12 apollo logger: connection refused from 192.168.198.50
Well, this isn’t very useful, because it lists logger as the application reporting the log entry! You can tell logger to masquerade as another application of your choosing using the -t flag, like this:
# tail -f access.log | logger -p local0.debug -t FDSNow, instead of the reporting application showing up as logger:, it will show up as FDS:.
Of course, there are probably alternatives to using logger, but they sometimes involve writing Perl or PHP daemons that perform basically the same function as our logger solution. In the long run, you may be able to come up with a better solution for your site, but for the “here and now” fix, logger is a good tool to have on your toolbelt.
Monitor Your Logfiles
Use existing tools or simple homemade scripts to help filter noise out of your logfiles.
If you support a lot of services, a lot of hosts, or both, you’re no doubt familiar with the problem of making efficient use of logfiles. Sure, you can have a log reporting tool send you log output hourly, but this information often goes to waste because of the extremely high noise-to-signal ratio. You can also try filtering down the information and using a tool such as logwatch to report on just those things most important to you on a daily basis. However, these reports won’t help alert you to immediate, impending danger. For that, you need more than a reporting tool. What you really need is a log monitor; something to watch the logs continually and let you know about anything odd.
Log monitors in many environments come in human form: administrators often keep several terminal windows open with various logs being tailed into them, or they use something like root-tail to get those logs out of windows and right into their desktop backgrounds. You can even send your output to a Jabber client
[Hack #84]
. This is wonderful stuff, but again, it doesn’t help filter out any of the unwanted noise in logfiles, and it’s not very effective if all the humans are out to lunch (so to speak).
There are a number of solutions to this problem. One is simply to make sure that your services are logging at the right levels and to the right syslog facilities, and then make sure your syslog daemon is configured to break things up and log things to the right files. This can help to some degree, but what we want is to essentially have a real-time, always-running “grep” of our logs that will alert us to any matches that are found by sending us email, updating a web page, or sending a page.
Using log-guardian
There are a couple of tools out there that you can use for log monitoring. One is log-guardian, which is a Perl script that allows you to monitor multiple logfiles for various user-supplied patterns. You can also configure the action that log-guardian takes when a match is found. The downside to using log-guardian is that you must have some Perl knowledge to configure it, since actions supplied by the user are in the form of Perl subroutines, and other configuration parameters are supplied in the form of Perl hashes. All of these are put directly into the script itself or into a separate configuration file. You can grab log-guardian from its web site: http://www.tifaware.com/perl/log-guardian/. Once downloaded, you can put the log-guardian.pl script wherever you store local system tools, such as under /opt or in /var/local. Since it doesn’t come with an init script, you’ll need to add a line similar to this one to your system’s rc.local file:
/var/local/bin/log-guardian &
The real power of log-guardian comes from Perl’s File::Tail module, which is a fairly robust bit of code that acts just like tail -f. This module is required for log-guardian. To determine whether you have it installed, you can run something like locate perl | grep Tail, or run a quick Perl one-liner like this at the command line:
$ perl -e "use File::Tail;"If that returns a big long error beginning with “Can’t find Tail/File.pm” or something similar, you’ll need to install it using CPAN, which should be dead simple using the following command:
# perl -MCPAN -e shellThis will give you a CPAN shell prompt, where you can run the following command to get the module installed:
> install File::TailThe File::Tail module is safe for use on logfiles that get moved, rolled, or replaced on a regular basis, and it doesn’t require you to restart or even think about your script when this happens. It’s dead-easy to use, and its more advanced features will allow you to monitor multiple logfiles simultaneously.
Here’s a simple filter I’ve added to the log-guardian script itself to match on sshd connections coming into the server:
'/var/log/messages' => [
{
label => 'SSH Connections',
pattern => "sshd",
action => sub {
my $line = $_[1];
print $line;
}
},
],That’s about as simple a filter you can write for log-guardian. It matches anything that gets written to /var/log/messages that has the string sshd in it and prints any lines it finds to stdout. From there, you can send it to another tool for further processing or pipe it to the mail command, in which case you could run log-guardian like this:
# /var/local/bin/log-guardian | mail [email protected]Of course, doing this will send every line in a separate email, so you might prefer to simply let it run in a terminal. You’ll be able to monitor this output a little more easily than the logfiles themselves, since much of the noise has been filtered out for you.
This sshd filter is just one example—the “pattern” can consist of any Perl code that returns some string that the program can use to match against incoming log entries, and the “action” performed in response to that match can be literally anything you’re capable of inventing using Perl. That makes the possibilities just about endless!
Using logcheck
The logcheck utility is not a real-time monitor that will alert you at the first sign of danger. However, it is a really simple way to help weed out the noise in your logs. You can download logcheck from http://sourceforge.net/projects/sentrytools/.
Once downloaded, untar the distribution, cd to the resulting directory, and as root, run make linux. This will install the logcheck files under /usr/local. There are a few files to edit, but the things that need editing are simple one-liners; the configuration is very intuitive, and the files are very well commented.
The main file that absolutely must be checked to ensure proper configuration is /usr/local/etc/logcheck.sh. This file contains sections that are marked with tags such as CONFIGURATION and LOGFILE CONFIGURATION, so you can easily find those variables in the file that might need changing. Probably the most obvious thing to change is the SYSADMIN variable, which tells logcheck where to send output.
[email protected]You should go over the other variables as well, because path variables and paths to binaries are also set in this file.
Once this is ready to go, the next thing you’ll want to do is edit root’s crontab file, which you can do by becoming root and running the following command:
# crontab -eYou can schedule logcheck to run as often as you want. The following line will schedule logcheck to run once an hour, every day, at 50 minutes after the hour:
50 * * * * /bin/sh /usr/local/etc/logcheck.sh
You can pick any time period you want, but once per hour (or less in smaller sites or home networks) should suffice.
Once you’ve saved the crontab entry, you’ll start getting email with reports from logcheck about what it’s found in your logs that you might want to know about. It figures out which log entries go into the reports by using the following methodology:
It matches a string you’ve noted as significant by putting it in /usr/local/etc/logcheck.hacking.
It does not match a string you’ve noted as being noise by putting it in /usr/local/etc/logcheck.ignore.
These two files are simply lists of strings that logcheck will try to match up against entries in the logs it goes through to create the reports. There is actually a third file as well, /usr/local/etc/logcheck.violations.ignore, which contains strings that are matched only against entries that are already flagged as violations. There’s an example of this in the INSTALL file that comes with the distribution that is more perfect than anything I can think of, so I’ll reiterate it here:
Feb 28 21:00:08 nemesis sendmail[5475]: VAA05473: to=crowland, ctladdr=root (0/0), delay=00:00:02, xdelay=00:00:01, mailer=local, stat=refused Feb 28 22:13:53 nemesis rshd: refused connect from [email protected]:1490 The top entry is from sendmail and is a fairly common error. The stat line indicates that the remote host refused connections (stat=refused). This can happen for a variety of reasons and generally is not a problem. The bottom line however indicates that a person ([email protected]) has tried unsuccessfully to start an rsh session on my machine. This is bad (of course you shouldn't be running rshd to begin with). The logcheck.violations file will find the word 'refused' and will flag it to be logged; however, this will report both instances as being bad and you will get false alarms from sendmail (both had the word 'refused').
To get around these false positive without also throwing out things you want to know about, you put a line like this in /usr/local/etc/logcheck.violations.ignore:
mailer=local, stat=refused
This will match only the Sendmail log entry and will be ignored. Any other entries will be caught if they contain the string “refused”.
Of course, it will likely take you some time to fine-tune the reports logcheck sends, but the model of forcing you to tell the tool to explicitly ignore things ensures that it ignores only what you tell it to, instead of making assumptions about your environment.
Send Log Messages to Your Jabber Client
Use hidden features of syslog and a quick script to send syslog messages straight to your desktop.
So you’ve finally gotten your machine room set up with centralized logging. Now you no longer need to open 50 different terminal windows to tail logs on all of your web servers. Instead, you just open one session to the central log host, tail the log, and go about your business.
But what if you could have the really important log messages, maybe only those going to the auth.warning facility, sent directly to your desktop in a way that will catch your attention even if you leave and come back only after the message has already scrolled by in your tail session?
You can actually accomplish this in a number of ways, but my favorite is by sending anything that comes through my syslog filter to my Jabber client. As most of you probably know, Jabber is an open source instant messaging protocol supported by Linux clients such as GAIM and Kopete.
This hack works because it turns out that syslog has the ability to send or copy messages to a named pipe (or FIFO). A pipe in the Linux world is a lot like a pipe in a plumber’s world: you send something in one end, and it comes out (or is accessible through) the other end. By this logic, you can see that if I can have warnings sent to a pipe, I should be able to attach to that pipe some form of faucet from which I can access those messages. This is exactly what we’ll do. For example, to send only those messages that pertain to failed login attempts (auth.warning) to a named pipe, you’d put the following line in /etc/syslog.conf:
auth.warning |/var/log/log-fifo
With that in place, you next need to create the log-fifo named pipe, which you can do with the following command:
# mkfifo /var/log/log-fifoThe next time you restart your syslog daemon, messages will be sent to log-fifo. You can quickly test that it’s working by running the following command and watching the output:
# less -f /var/log/log-fifoTo get these messages to an open Jabber client, you can have a script read from log-fifo, wrap it in the appropriate XML, and send it off for routing to your target Jabber account. The script I use is a hacked up version of DJ Adams’s original jann Perl script and requires the Net::Jabber module, which is readily available for (if not already installed on) most distributions. I call it jann-log.
The Code
This script reads syslog output from a FIFO and forwards it as a Jabber message:
#!/usr/bin/perl
use Net::Jabber qw(Client);
use strict;
# Announce resources
my %resource = (
online => "/announce/online",
);
# default options
my %option = (
server => "moocow:5222",
user => "admin",
type => "online",
);
# Default port if none specified
$option{server} = "moocow:5222";
# Ask for password if none given
unless ($option{pass}) {
print "Password: ";
system "stty -echo";
$option{pass} = <STDIN>;
system "stty echo";
chomp $option{pass};
print "
";
}
# Connect to Jabber server
my ($host, $port) = split(":", $option{server}, 2);
print "Connecting to $host:$port as $option{user}
";
my $c = new Net::Jabber::Client;
$c->Connect(
hostname => $host,
port => $port,
) or die "Cannot connect to Jabber server at $option{server}
";
my @result;
eval {
@result = $c->AuthSend(
username => $option{user},
password => $option{pass},
resource => "GAIM",
);
};
die "Cannot connect to Jabber server at $option{server}
" if $@;
if ($result[0] ne "ok") {
die "Authorisation failed ($result[1]) for user $option{user} on
$option{server}
";
}
print "Sending $option{type} messages
";
# The message. Change the file name in this 'open' line to
# the name of your fifo.
open(STATUS, "cat /var/log/log-fifo 2>&1 |")
|| die "UGH: there's issues: $!";
while (<STATUS>) {
my $xml .= qq[<subject>] .
($option{type} eq "online" ? "Admin Message" : "MOTD") .
qq[</subject>];
my $to = $host . $resource{$option{type}};
$xml .= qq[<message to="$to">];
$xml .= qq[<body>];
my $message = $_;
$xml .= XML::Stream::EscapeXML($message);
$xml .= qq[</body>];
$xml .= qq[</message>] ;
$c->SendXML($xml);
print $xml;
}Running the Code
Place this script in a place accessible only by you and/or your admin team (for example, /var/local/adm/bin/jann-log) and change the permissions so that the script is writable and executable only by your admin group. Then open up a Jabber client on your desktop and connect to your Jabber server. Once that’s done, run the script. It should confirm that it has connected to the Jabber server and is awaiting messages from the FIFO.
A simple way to test your auth.warning facility on the server where jann-log is listening for messages is to SSH to the host and purposely use the wrong password to try to log in.
Monitor Service Availability with Zabbix
It’s nice to have some warning before those help calls come flooding in. Be the first to know what’s happening with critical servers on your network!
It will happen to everyone sooner or later: you’ll be minding your own business, blissfully unaware that the network is crashing to its knees until a secretary claims that the Internet is down. By that time, the bosses have all noticed, and everyone wants answers. Full-blown panic kicks in, and you race around the office, pinging things at random to try to figure out what’s happening. Wouldn’t it be nice if you had some sort of detailed real-time network map that could monitor services and tell you what was going on? Zabbix to the rescue! Zabbix is a host monitoring tool that can do amazing things. Read on to see how you can apply it in your own network.
Dependencies
Zabbix is a complicated beast, so there are naturally a few dependencies to note before you rush headlong into the installation. Zabbix is written in PHP, so make sure you have a relatively recent version installed. If you haven’t upgraded in a while, this might be the time to do so. Since Zabbix is completely web-based, you’ll obviously need a web server as well. Par for the course, Apache or Apache2 is the recommended server of choice. Make sure when you install Apache that you configure it with mod-php enabled as well. This ensures that Apache can understand the embedded PHP that makes Zabbix what it is. Then, make sure you have the PHP GD library installed (available from http://www.boutell.com/gd/). While Zabbix will technically run without this, it’s not recommended, as this is the library that generates the network maps and graphs that make Zabbix so useful. Finally, you’ll need a SQL database. While Zabbix supports both PostgreSQL and MySQL, in this example we’ll be using MySQL.
Installing Zabbix
Unfortunately, installing Zabbix isn’t as straightforward as many applications we’ve discussed so far. Some parts of its installation, which I’ll highlight as we go along, are optional.
The first step in getting Zabbix up and running is to download and untar the source code. You can find this at the home page (http://www.zabbix.com). At the time this book was written, the latest version was 1.0. Download the archive file of the latest version, untar it in your normal build location, and navigate to the new directory. First, we’ll need to configure Zabbix to make use of the database choice we’ve selected (MySQL) and to use SNMP. Run the following command to prepare the installation:
$ ./configure–with-mysql–with net-snmpThis shouldn’t take too long, so don’t grab a beer just yet! Before you move on to the make, you’ll need to take a second to prepare the MySQL database for Zabbix. Navigate to the create/ directory and then start MySQL, create the Zabbix database, and concatenate the .sql scripts to populate the tables:
# mysql–u<username>-p<password>Mysql> create database Zabbix; Mysql> quit;# cd create/mysql# cat schema.sql |mysql–u<username>-p<password>Zabbix# cd ../data# cat data.sql |mysql–u<username>-p<password>Zabbix
You can now jump back to the root of the Zabbix directory and issue the make command.
Once the make completes, take a moment to copy the contents of the bin/directory to somewhere in your path. I tend to use /usr/local/bin.
# cp bin/* /usr/local/binThis is a fairly unsophisticated installation mechanism, but you’re almost done. Now we have to set a few variables so that PHP knows how to properly access your database. Navigate to frontend/php/include in your Zabbix source directory and open the file db.inc.php in your favorite text editor. Make the following changes:
$DB_TYPE ="MySQL"; $DB_SERVER ="localhost"; $DB_DATABASE ="Zabbix"; $DB_USER ="<MySQL username here>"$DB_PWD ="<MySQL password here>"
The $DB_DATABASE variable is the name of the database you created in MySQL for Zabbix earlier. Once these changes have been made, copy the PHP files to your web root:
# cp–R frontends/php/*/srv/www/htdocs/
Now make the directory /etc/zabbix and copy the sample configuration files to it:
# mkdir /etc/zabbix# cp misc/conf/zabbix_suckerd.conf /etc/zabbix/zabbix_suckerd.conf# cp misc/conf/zabbix_trapperd.conf /etc/zabbix/zabbix_trapperd.conf
These sample configuration files are fine for small-time applications, but if you’re planning on deploying Zabbix on a large-scale or enterprise rollout you should read the configuration files section of the online Zabbix manual, available at http://www.zabbix.com/manual/v1.1/config_files.php. Doing so will save you many headaches in the future. Once these files are moved, you’re done with the installation! All that’s left is to fire up the Zabbix daemons and ensure that they work:
# zabbix_suckerd# zabbix_trapperd
Assuming everything went as planned, you can now point your web browser to http://127.0.0.1 and see your new Zabbix installation. When you get to the login screen, enter Admin for your username and leave the password field blank. Once logged in, take a moment to change the default password.
Monitoring Hosts
After that installation, you certainly deserve to do something easy now! Fortunately, Zabbix seems to be designed with ease in mind. Let’s start adding some hosts to monitor. The upper section of the screen has the navigation bars that you’ll use to navigate around Zabbix. Click Hosts to add a new host to your monitoring. Figure 9-3 shows the fields available when adding a new host on the Hosts tab in Zabbix.
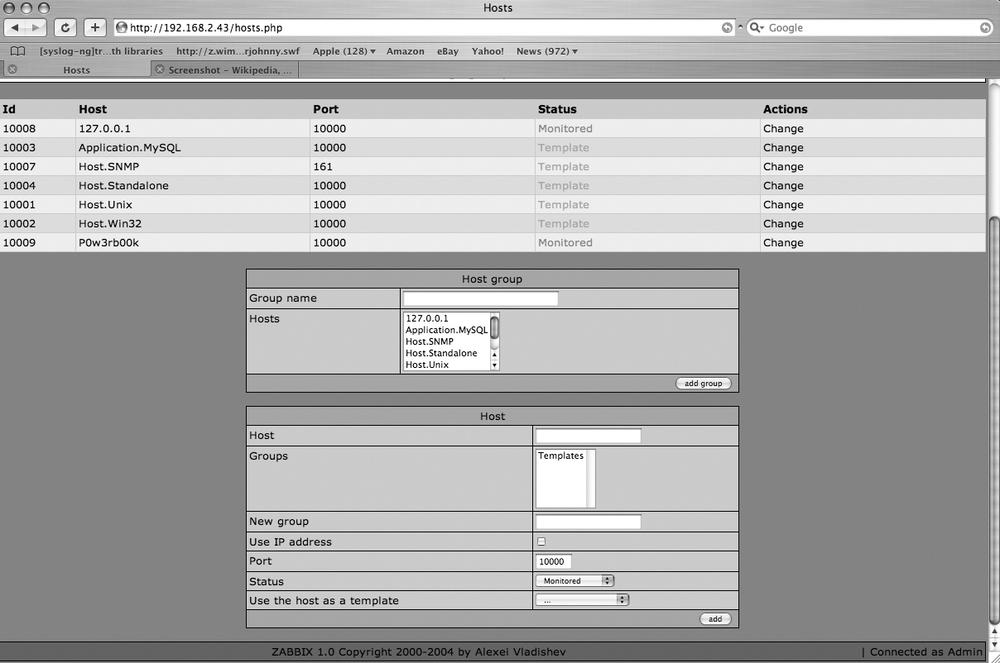
You’ll see here that you have several options when adding your new hosts. Fill in the options to suit your needs and click Add. Note that if you’d rather monitor by hostname than by DNS (which is often an excellent idea), checking the Use IP Address box will give you an additional box to provide the IP address to monitor. For example, let’s assume we want to configure Zabbix to notify us if 192.168.2.118 ever stops serving FTP traffic. To do so, on the Hosts tab, we would enter 192.168.2.118 in the Host field. We’d then change the port to 22 since we’re interested in FTP traffic. Next, move over to the Items tab. We’ll need to type in a description for this item, so we’ll call it Home-FTP. Under Type, select “Simple check.” In the Key field, enter “ftp.” The rest we can leave as it is. Now wait a few minutes, and check the Latest Values tab. You should see an option there for 192.168.2.118 (or the hostname if you gave it one). Since the FTP server is running, we get a return value of 1. Had the server not been running, we would see 0 in that field. Notice that to the right you have the option to graph, trend, and compare data collected over time. This allows for detailed data analysis on the uptime and availability of your servers. It is also an excellent demonstration of the graphical qualities of Zabbix.
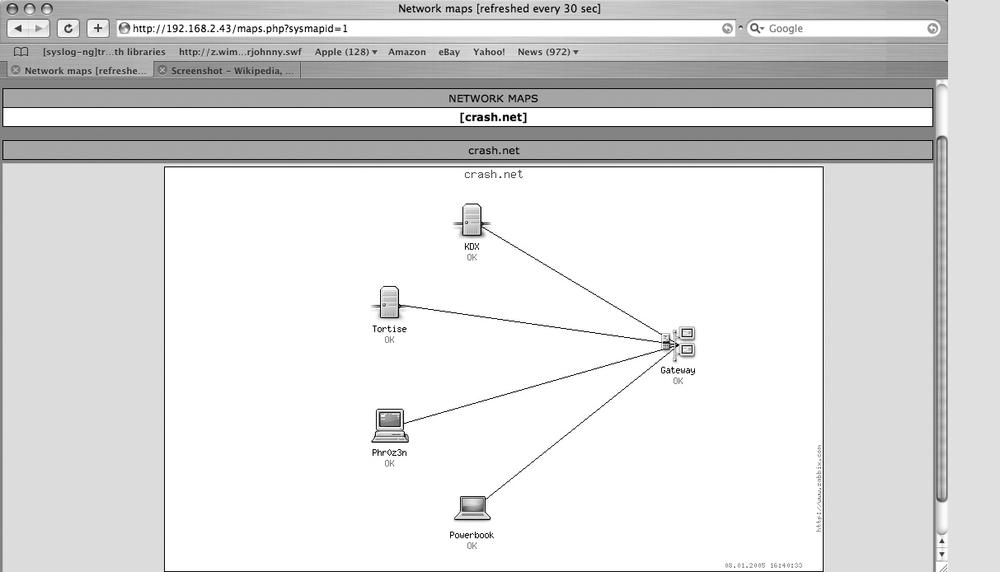
Mapping the Network
The last aspect of Zabbix that we’ll look at is the mapping feature (shown in Figure 9-4). This is an excellent tool for providing a quick reference map of the network showing detailed status. To begin, click on the lower Network Maps button. Create a new network map by filling in the name you wish to call your new map. If you’ll have a lot of hosts to monitor, change the size of the map to make it bigger. Click Add to continue. Once you’ve created your map, it’s time to add some hosts to it. Select the host we created in the previous example, Home-FTP. You can then select the coordinates you wish for the icon representing Home-FTP to be displayed on. Select the Server icon and click Add. The page will refresh, and when it finishes loading, you’ll see your icon representing Home-FTP on the map. You can continue adding hosts and placing them on the map until you have a full representation of your network.
The Details
What we’ve covered here is a fraction of the capabilities of Zabbix. If you’d like to get more in depth with it, you can install the Zabbix agents on the machines you wish to monitor. Once you’ve done that, you can monitor statistics such as CPU utilization, drive space, and anything else that can be monitored via SNMP. You can also define custom triggers to alert you right away to emergency situations. Trigger definition is highly detailed and can get quite elaborate and complex. If you’d like to learn more about this incredibly flexible network monitoring tool, check out the Zabbix web page at http://www.zabbix.com for more information. There is a fairly active forum there dedicated to helping users in need and sharing configuration tips and tricks.
—Brian Warshawsky
Fine-Tune the syslog Daemon
You can’t see problems that aren’t being reported. Correctly setting up the system log daemon and logging levels ensures that you always know what’s going on.
Linux systems log boot information, process status information, and a significant amount of access and error information in the system logfile, /var/log/messages, using a system daemon known as syslog. But when was the last time you looked at this file? If you’ve never spent any time fine-tuning the syslog daemon, your system logfile probably contains a tragically jumbled mess of cron completion notices, boot notices, MARK entries, and any number of other service or daemon log messages. Imagine if you could configure syslog to dump all that information where you wanted it, and sort it all too…. Well, this is Linux we’re talking about here, so of course you can configure syslog any way you want!
Making Sense of syslog.conf
A configuration file called /etc/syslog.conf controls the syslog daemon. As unimaginative as the config file’s name might be, learn it well because this is a file you’ll need to become very familiar with if you want to master the intricacies of Linux system logging. The file may not make a whole lot of sense upon first glance, but here’s a simple syslog.conf file that I’ll use to explain the syntax further:
# Log all kernel messages to the console. # Logging much else clutters up the screen. # kern.* /dev/console # Log anything (except mail) of level info or higher. # Don't log private authentication messages! *.info;mail.none;authpriv.none;cron.none /var/log/messages # The authpriv file has restricted access. authpriv.* /var/log/secure # Log all the mail messages in one place. mail.* -/var/log/maillog # Log cron stuff cron.* /var/log/cron # Everybody gets emergency messages *.emerg * # Save news errors of level crit and higher in a special file. uucp,news.crit /var/log/spooler # Save boot messages also to boot.log local7.* /var/log/boot.log
As you can see in the noncommented lines in this example, there are three main parts to each active line of the configuration file. The first entry on a line is called the facility, which is the underlying subsystem that creates the log messages for the logfiles. There are 13 predefined system facility values: auth, authpriv, cron, daemon, ftp, kern, lpr, mail, mark, news, syslog, user, and uucp. In addition to these, there are also eight others, named local0 through local7, which are for programs to use when implementing their own syslog messages. Each of the predefined facilities refers to a specific aspect of the system. For instance, auth refers to the Linux authorization system, including programs such as login and su. The mark facility is used internally for syslog, and should be left alone for the time being. The daemon facility is for other system daemons that are not listed specifically. You can represent all available facilities by using the asterisk (*) symbol.
The second part to a configuration line is the priority, which is separated from its associated facility by a period. Every time a part of the system sends a message to syslog, that message is coded with a priority. Basically, the program is letting syslog know how important this message is. From lowest to highest, the priority levels are debug, info, notice, warning, err, crit, alert, and emerg. The higher the priority, the more important the message is. Once you hit the emerg priority, the system is rapidly approaching a kernel panic and is probably unusable. You can represent messages of any priority by using the asterisk symbol. For example, local7.* means “messages of any priority from the local7 facility.”
The third and final aspect of the configuration line is the action. This is basically just a short section that tells syslog what to do with the information it has received. To better explain this, let’s look at an example line from the sample configuration file provided above:
# Log cron stuff cron.* /var/log/cron
Few things are more annoying than scrolling through /var/log/messages and having to wade through all the cron messages, so this kind of configuration option comes in handy. This example means that messages of all priorities issued by the cron facility should be sent to the /var/log/cron logfile. As mentioned previously, the asterisk is a wildcard feature that tells syslog to apply the same rule to every message from cron, regardless of its priority. You can do similar things with the asterisk wildcard for the facility, such as instructing syslog to send every message of priority warning or higher to a specific logfile:
*.warning /var/log/problems
Real-Time Alerts from the System Log
Other wildcard features that can be used include the at sign (@), for sending messages to remote syslog hosts; a dash (-), for telling syslog not to sync the disks after every message; and an asterisk in the actions section of the configuration to alert everyone on the system to an issue. For instance, look at the following example from the sample configuration file:
# Everybody gets emergency messages *.emerg *
The final asterisk on this line tells syslog to send a message out to every user online via the wall (Write to ALL users) command to let them know of any emergency conditions. These messages will appear in every active terminal window on the system. You can think of configurations like this as Linux’s emergency broadcast system.
Another interesting line in the example syslog.conf file shown earlier in this hack is the line that addresses kernel syslog messages. Rather than being sent to a logfile, all these messages are sent to the console instead. One popular trick using this feature is to direct many of the syslog messages to a virtual console instead of the main console. I often do this on machines that aren’t used much for local work but still have monitors. For example, specifying this line:
auth,kern.* /dev/tty5
allows me to see the syslog messages of everyone who logs on—and any issues with the kernel—simply by switching the machine to virtual console 5 (Alt-F5) and leaving it there with the monitor on. Now, whenever I walk by that machine, I can keep track of users logging on and off, or anything else I’ve set it up to do. When I need to work on the server and that would be in the way, I just switch back to my primary console (Alt-F1), and the messages continue to be sent to console 5.
Centralizing Logs for Convenient Access
Another interesting syslog option is remote logging. While syslog itself allows for remote logging, there is a more robust solution to be found in syslog-ng
[Hack #87]
, a new version of syslog. syslog allows you to send messages to remote hosts, but it does so in plain text across the network, so you should use this feature with caution. Here’s how it works: by adding an at sign and a hostname or IP address in the action section of the configuration file, you can specify that syslog send its messages to another waiting remote syslog server. The remote syslog server will need to have the syslog daemon started with the –r option to allow it to listen on port 514 for incoming syslog messages. The following line shows an example of sending all critical kernel messages to the remote machine aardvark for safekeeping.
kern.crit @aardvark
Remote logging can be extremely helpful in the event of a system crash, as it allows you to see log messages that you might otherwise be unable to access (since the system that issued them is down). As previously mentioned, these messages are sent in plain text across the network, so be sure to use syslog’s remote logging with caution—and never do it across the Internet. Also, note that if you send certain types of messages to a remote log server, they are not recorded locally unless you create another entry that also sends those same messages to the local log, as in the following example:
kern.crit @aardvark kern.crit /var/log/messages
Tip
Another interesting potential security issue with syslog’s remote logging is that starting the syslog daemon with the –r option to receive remote log entries means that any host can send a log message to that host. The syslog facility doesn’t have a way of identifying specific hosts that it should receive messages from, so it just holds up a big electronic catcher’s mitt and accepts anything that comes its way.
The syslog daemon can be customized in many different ways, but it’s somewhat dated in terms of both capabilities and security. “Centralize System Logs Securely” [Hack #87] provides newer and even more configurable approach to system logging.
Centralize System Logs Securely
Protect your valuable logfiles from prying eyes
In “Fine-Tune the syslog Daemon” [Hack #86] , we discussed configuration of the syslog daemon. As useful and even necessary as this logging service is, though, it’s beginning to show its age. In response to that, a company name BalaBit has devoted both time and resources to bringing us the next generation of syslog, syslog-ng, which addresses many of the problems that plague the original. Improvements include using TCP instead of UDP to communicate with remote log hosts and a much more configurable interface to your system’s logging capabilities. From a security standpoint, the implementation of TCP is a great advancement—that allows us to use additional applications such as stunnel to create encrypted tunnels to protect the contents of logfiles as they are sent to the central log host. In this hack, we examine such a deployment.
Getting Started
To implement encrypted remote logging, you’ll need to download and compile three programs. Let’s start with stunnel. Grab the latest instance of the source code from http://www.stunnel.org/download/source.html. Once you’ve got the tarball, unpack it and navigate to your newly created directory. You can now follow the typical installation procedure:
$ ./configure$ make# make install
You’ll now need to grab the source for syslog-ng and libol, a library required by syslog-ng. You can download each of these from http://www.balabit.com/downloads/syslog-ng/. Untar and install libol first, then syslog-ng. Installation of these two applications uses the previous typical source install three-step.
Once you’ve successfully installed stunnel, syslog-ng, and libol, you’ll need to create encryption certificates for all the machines between which you want to transfer secure log information.
Creating Your Encryption Certificates
To transfer log data securely between a remote host and a central log host, communication between the two must be encrypted. In order to successfully use encryption, both hosts must be able to verify their identities and share the encryption keys used for reading and writing the encrypted data. This information is provided by SSL certificates, which can either be granted by a third party or created yourself for use within your organization. (For more than you probably want to know about SSL and certificates, see the SSL HOWTO at http://www.tldp.org/HOWTO/SSL-Certificates-HOWTO/.)
At this point, you must create multiple certificates: one for use by the central log server, and one for each client that sends log information to the server. Later in this section, you’ll install the server certificate on your server and distribute the client certificates to the hosts for which they were created.
The process for creating certificates varies slightly based on the Linux distribution you’re using. For a Red Hat system, it is as follows:
# cd /usr/share/ssl/certs # make syslog-ng-server.pem # make syslog-ng-client.pem
As each certificate is generated, the script will ask you several questions regarding your location, hostname, organization, and email address. Once all the questions have been answered, your certificates are generated. Your next step is to verify that only root has access to them:
[root@aardvark certs]# ls -l *.pem
-rw-------1 root root 2149 Aug 14 12:12 syslog-ng-client.pem
-rw-------1 root root 2165 Aug 14 12:12 syslog-ng-server.pem
[root@aardvark certs]#There is one last thing you’ll need to do before you start distributing your certificates: extract the CERTIFICATE section from each certificate that is going to a client machine and concatenate the extracted sections into a single file named syslog-ng-client.pem, which you will put on your server along with the server key. The CERTIFICATE key data in a certificate file is the information between the following two lines:
-----BEGIN CERTIFICATE----- -----END CERTIFICATE-----
Copy the syslog-ng-client.pem file over to the /etc/stunnel directory on the server and place a copy of each client’s own certificate in that client’s /etc/stunnel directory. This may sound somewhat complicated, so let’s summarize: all you’re doing here is extracting the CERTIFICATE from each client’s certificate file, concatenating that information into one large client certificate that will reside on your server (along with the server’s certificate), and then copying the individual client certificates to the hosts for which they were intended.
Configuring stunnel
Now, on the server side, edit your stunnel.conf file to read as follows:
cert = /etc/stunnel/syslog-ng-server.pem CAfile = /etc/stunnel/syslog-ng-client.pem verify = 3 [5140] accept = your.server.ip:5140 connect = 127.0.0.1:514
Then make similar changes to stunnel.conf on the client side:
client = yes cert = /etc/stunnel/syslog-ng-client.pem CAfile = /etc/stunnel/syslog-ng-server.pem verify = 3 [5140] accept = 127.0.0.1:514 connect = your.server.ip:5140
Configuring syslog-ng
Once those changes have been made, it’s time to start working on creating your syslog-ng.conf file. The syntax of this file has a steep learning curve and is well beyond the scope of this hack, so use what I’m about to show you as a starting point, and work from there. Far more detail can be found online and in the manpages. On your central log server, add the following to /etc/syslog-ng/syslog-ng.conf:
options { long_hostnames(off);
sync(0);
keep_hostname(yes);
chain_hostnames(no); };
source src {unix-stream("/dev/log");
pipe("/proc/kmsg");
internal();};
source stunnel {tcp(ip("127.0.0.1")
port(514)
max-connections(1));};
destination remoteclient {file("/var/log/remoteclient");};
destination dest {file("/var/log/messages");};
log {source(src); destination(dest);};
log {source(stunnel); destination(remoteclient);};Then, add the following to your syslog-ng.conf file on each client:
options {long_hostnames(off);
sync(0);};
source src {unix-stream("/dev/log"); pipe("/proc/kmsg");
internal();};
destination dest {file("/var/log/messages");};
destination stunnel {tcp("127.0.0.1" port(514));};
log {source(src);destination(dest);};
log {source(src);destination(stunnel);};Testing
Once you’ve done all this, you can start stunnel and syslog-ng to see if everything is working. Before you do so, though, make sure you stop the syslogd service. You don’t want the two of them stepping on each other. To test whether your remote logging is working, use the logger command:
# logger This is a TestThen, on your log server, search (or grep) /var/log/messages (or wherever you have remote logs) for “This is a Test”. If you get a response, congratulations—everything is working fine, and you now have encrypted remote logging!
Where Next?
While remote logging has always been a useful and even necessary process, sending valuable system information unencrypted across the void has long been a security risk. Thanks to syslog-ng and stunnel, we no longer have to worry about that. In addition, the flexibility of syslog-ng has moved leaps and bounds beyond what syslogd was ever capable of. It truly is the Next Generation of system logging daemons.
That flexibility comes with a price, though—the syslog-ng configuration file is a complex beast. If you spend a little time getting to know it, however, you’ll find that it’s not quite as hard as it looks. I can assure you that the complexity of the syntax is proportional to its adaptability once you understand it. Listed below are some resources you can consult online for help in configuring your syslog-ng instance to meet your needs.
Keep Tabs on Systems and Services
Consolidate home-grown monitoring scripts and mechanisms using Nagios.
Monitoring is a key task for administrators, whether you’re in a small environment of 50–100 servers or are managing many sites globally with 5,000 servers each. At some point, trying to keep up with the growth in the number of new services and servers deployed, and reflecting changes across many disparate monitoring solutions, becomes a full-time job!
Admins often monitor not only the availability of a system (using simple tools such as ping), but also the health of the services running on the system—the network devices that connect the systems to each other; peripheral devices such as printers, copiers, uninterruptible power supplies (UPSs); and even air conditioners and other equipment. Often, these tools perform simple connections to services and use SNMP and rstatd data collection and specialized environmental monitoring devices to gain a complete view of the data centers.
While there are plenty of solutions out there for collecting and aggregating this data in some sane way, I’ve found Nagios to provide the perfect balance between simplicity and power. Nagios is a solution that meets the requirements of our mid-sized organization’s computing environment quite well, for reasons such as these:
- Dependency checking
If all your printers are on a single switch, and that switch goes down, would you rather get a page about each of 50 unavailable printers or a single page saying “the printer switch is down”? Nagios can be configured (or not) to follow a logical path, so that one unreachable device triggers the checking of other devices upon which the first failure is dependent. If a printer is down, Nagios first checks to make sure the printer switch is up before notifying anyone. If that printer switch is up and someone is running around unplugging printers, you’ll get a lot of pages, but if the switch is down you’ll be notified of the larger problem, not its consequences. Further, if that printer switch is unreachable because a router between Nagios and the printer switch is down or unavailable, you’ll get that message instead, which can save you some troubleshooting time and makes the pages far more interesting and useful.
- Downtime scheduling
When you have a host of different tools monitoring your environment, or a single tool that doesn’t allow for downtime scheduling, your pager will go nuts as you bring down your environment and possibly again on the way back up. Mix this with a situation in which there is no dependency checking and you’ll soon find a group of administrators walking around while their pagers lie vibrating in their desk drawers. With Nagios, you can schedule downtimes and avoid the hassle.
- Recovery notification
Many people use monitoring solutions that do simple “ping” monitoring, which tells you if a machine is unreachable. However, if it was unreachable because of a temporary power glitch that caused a switch to momentarily freak out, and the agent never lets you know that the machine became available again one minute later, you could be wasting gobs of time driving over to the site for a problem that has already corrected itself. Nagios will notify you of recoveries.
A lot of solutions don’t provide these benefits. Throw in solutions that are tough to customize, don’t provide service checks for specialized appliances or services, and are tough to integrate with the few tools you might have that do work well, and you have big headaches and a downhill trend in the morale of your administrators.
Enter Nagios
I’ve found that Nagios provides an extremely simple way of taking many of our disparate scripts, notification modules, ping checkers, and other tools, and putting them all under the Nagios umbrella as “plug-ins” without my having to change much of anything. In fact, the monitoring functionality that comes preconfigured with Nagios is all handled through shell, Perl, or C programs that Nagios calls in the background.
The barrier to entry was actually so low that within a day I had a very basic Nagios configuration up and running, with a web interface, email notifications, and basic service and host checks working. By the end of the week, I had configured Nagios to be more discriminating in its notifications (e.g., notify only the DBA if the database service became unavailable, but only the Sun admins if the database server went down). I had also configured host and service dependencies, and told it about our next two scheduled downtimes. I had even found existing plug-ins for Nagios that allowed for the retirement of a couple of our home-grown scripts for monitoring things like a NetApp filer and a MySQL database. Things were looking up!
What’s more is that the Nagios web interface, while it keeps useful enough statistics to help pinpoint when a problem started or predict your disk needs on a file server over the next year, can also easily be integrated with standard tools such as MRTG [Hack #79] or Cacti.
If you want to get really hardcore, you can also use Nagios to collect SNMP traps, or go fully distributed by using Nagios agents, rather than a central polling mechanism, across your machine room.
The only downside to Nagios that I’ve found so far is that, while configuration is pretty brainless, there is no configuration GUI or automation, so it all has to be done by hand (which can be somewhat cumbersome and very time-consuming). The payoff is there, though, so let’s check out some configuration details. I’ll cover only the most basic configuration, because documenting a full-blown Nagios deployment could be another book unto itself!
First you’ll need to install Nagios, either using your distribution’s package management system (for a binary install) or by going to http://www.nagios.org to grab the source and installing according to the plentiful documentation.
Hosts, Services, and Contacts, Oh My!
We’ll start simple. Your machine room consists of hosts. These hosts run services. If either a host or a service that it runs becomes unavailable, you’ll want Nagios to notify a contact. Thus, the first thing to do is tell Nagios about these entities. To do this, we add entries in the hosts.cfg, services.cfg, and contacts.cfg files. These files may be located under /etc/nagios if your installation was preconfigured (as on a SUSE system or a Red Hat RPM install), or wherever you told it to put configuration files during a source install (/usr/local/etc/nagios, by default).
Here’s a simple hosts.cfg entry that tells Nagios some basic information about a host:
define host{
use generic-host
host_name newhotness
alias Jonesy's Desktop
address 128.112.9.52
parents myswitch
}You’ll notice that all this information is specific to my desktop machine. There’s nothing here about how to check the availability of the host, when to check it, or anything else. This is because Nagios allows you to configure a template host entry to hold all of that information (since it’s likely to be identical for large numbers of hosts). The template used in the above entry is called generic-host, and can be found near the top of the hosts.cfg file. The generic-host template entry looks like this:
define host{
name generic-host
notifications_enabled 1
event_handler_enabled 1
flap_detection_enabled 1
process_perf_data 1
notification_interval 360
notification_period 24x7
notification_options d,u,r
contact_groups sysstaff
check_command check-host-alive
max_check_attempts 10
retain_status_information 1
retain_nonstatus_information 1
register 0
}This one entry does all the heavy lifting for the rest of the devices that reference this template. They will all be checked using the check-host-alive check command, which is a scripted ping command. Per the notification_period key’s value, they’ll be monitored 24 hours a day, 7 days a week. The notification_options line says to send notifications if the status of the machine is either down (d), unreachable (u), or recovered (r). The flap_detection_enabled option is turned on here, as well. This is a feature of Nagios that seeks to save you from getting pages from services or hosts that change state frequently due to temporary aberrations in network connectivity, host response times, or services that are purposely restarted to pick up automated updates. You have to admit, putting all this detail into one entry is better than putting it into every host entry!
Let’s move on to services. A typical services.cfg entry looks like this:
define service{
use generic-service
host_name ftpserver
service_description FTP
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 5
retry_check_interval 1
contact_groups sysstaff
notification_interval 120
notification_period 24x7
notification_options w,u,c,r
check_command check_ftp
}This is the entry for my FTP server. Again, it includes only the information specific to the FTP server; all the rest of the information comes from the template named generic-service, whose settings are applied to all of the services whose entries refer to it using the use generic-service directive. Notice that I use a service-specific check command called check_ftp. The check_ftp command is just a shell script that attempts to make a connection to the FTP service on ftpserver.
You’ve no doubt noticed that both the host and service checks send mail to sysstaff if there’s a problem. But what is sysstaff? It’s actually not an email alias (although you can use one if you like). Instead, it’s configured within Nagios itself, in the contacts.cfg and contactgroups.cfg files. Let’s have a look! Here’s an entry for a contact from the contacts.cfg file:
define contact{
contact_name jonesy
alias Jonesy
service_notification_period 24x7
host_notification_period 24x7
service_notification_options c,r
host_notification_options d,r
service_notification_commands notify-by-email
host_notification_commands host-notify-by-email
email [email protected]
}This is my contact entry. It says that I’m to be notified of any host or service failures 24 hours a day, 7 days a week. However, I’ve hacked my entry so that instead of being notified of every change in state, I’m only notified when services (service_notification_options) are critical (c) and when they recover (r), and when hosts (host_notification_options) are down (d) and when they recover (r). There’s an entry like this for everyone who will receive notifications about service or host status from Nagios.
Once all of the contacts are defined, you can group them together to form Nagios-specific groups in contactgroups.cfg. Here’s an example:
define contactgroup{
contactgroup_name sysstaff
alias The Systems Guys
members jonesy,bill,joe
}That wasn’t so hard, was it? Just remember that anyone in a contact group must first be defined as a contact in contacts.cfg.
At this point you have only a very simple configuration, but it’s enough to fire up Nagios and have it monitor the hosts and services you defined and notify those who are defined as contacts. Before you do that, though, you should run the following command to do a syntax check:
$ nagios -v /etc/nagios/nagios.cfgThis runs Nagios in “verify” mode, and we’ve fed it the main Nagios configuration file, which contains a line for every other configuration file in use. If there’s a problem, Nagios will spit out plenty of information for you to find, check out, and fix the problem. In these early stages, the most common issues will probably be related to configuration files defined in nagios.cfg that are not yet being used. For example, since we haven’t used the dependency configuration file, you’ll want to comment out any references to it in nagios.cfg.
If you received no errors, you’re in good shape. You might see “warnings” that point out possible problems to you during config verification, but in many cases these warnings are for things that are intentional, such as contacts that are not assigned to a contact group (which is not required and not always desirable). Once you’ve verified that the warnings are harmless, or fixed whatever issues existed and reverified things, you can fire up Nagios and begin receiving notifications via email about the hosts and services you’ve configured.