
Chapter 10. System Rescue, Recovery, and Repair
Hacks 89–100: Introduction
No computing system survives contact with the environment. The excellence of your sysadmin skills can’t stop hardware from failing—it can only help you best recover from failed disk drives, controllers, and other calamities that drown your inbox with support requests (if anyone can send mail at all) and result in long lines of cranky users standing outside your office like shoppers trying to return broken gifts after the holiday season. “You do have backups from 10 minutes ago, don’t you?” you hear them cry.
Data recovery is more critical today than ever, since the loss of a single disk or filesystem can mean hundreds of gigabytes of lost data. But don’t worry—all is not necessarily lost. You can come out of many systems failures with your wizard hat fully intact, and perhaps even sporting a few new stars.
The hacks in this chapter provide a variety of hard-won tips on how to deal with systems that suddenly won’t boot on their own, how to bring into line balky filesystems that you can’t access or unmount, and even how to recover deleted files or data from failed hard drives. Some of the techniques in this chapter have retrieved data from Linux systems whose disks more closely resembled blocks of wood than advanced storage devices.
As an interesting spin on recovery and restoration, this chapter also includes hacks on how to permanently delete files and wipe hard disks so that they can safely be disposed of without donating your corporate secrets to the competition or your music collection to the RIAA. We stop short of describing how to physically wipe hard disks, though (i.e., using a hammer)—most people can work that one out (and we looked a tad too gleeful in the figures we submitted).
Resolve Common Boot and Startup Problems
Malicious crackers, overenthusiastic software updates, or simple hardware failures can prevent you from rebooting or accessing a system. The first thing to do is to relax and try a few standard tips and tricks to get your ailing system back on its feet.
Sooner or later—usually just before one of your users is about to submit her thesis or you have a meeting to present the IT strategy document you’ve been working on for weeks—you’ll find that attempting to boot one of your systems results in a variety of cryptic error messages, a blinking cursor, or a graphical user interface that won’t accept any keyboard or mouse input. In other words, not the standard Linux login you’re used to at all. Of course, you have backups of your critical files elsewhere, but if your system isn’t running for one reason or another, backups are just a distant security blanket. In all likelihood, your data is probably still present on the host formerly known as “your desktop machine,” but you just can’t boot the box to get to it. What’s a girl to do?
Depending on the types of errors you’re seeing, you may need anything from a crash course in BIOS settings, a PhD in the use of fsck and its friends, or some way of booting your system and accessing your data quickly. This hack discusses some of the standard tips and tricks for trying to get your box running on its own. If the tips in this hack aren’t sufficient, see “Rescue Me!” [Hack #90] for the big hammer, which is creating a bootable CD containing a Linux distribution that provides the tools you need to repair an ailing Linux box. You can then apply the tools provided on that CD to repair your filesystems, recover partitions, and perform the other hacks listed at the end of this one that will enable you to get your system back and booting on its own.
Check BIOS Settings
If your system doesn’t boot at all, the first thing to check is whether it’s actually finding the device from which you expect it to boot. If you’ve recently added a disk to your system or changed its hardware configuration in any way, chances are that your BIOS settings are simply wrong. For example, I have a 64-bit server with a variety of removable drives that boots off an internal disk. For some reason, each time I add, remove, or change one of the removable drives, the BIOS forgets that it’s supposed to boot off an internal SATA drive and insists on trying to boot from one of my music archives or one of the disks containing user home directories. Crap.
The standard symptoms of a system that has become confused about its boot settings are a blinking cursor after the system has tried to initiate the boot process, or a message saying something like “No bootable devices found.” To make sure that your system is actually attempting to boot from the right device, you’ll have to investigate its Basic Input/Output System (BIOS) settings.
On many systems, either there’s a boot splash screen that hides the command needed to enter the BIOS, or the display comes up after this information has already been displayed. Most modern systems enable you to access their BIOS settings by pressing the Delete key (the one in the cluster of keys with Home, End, Page Up, and Page Down) as soon as the system powers up. The system will still perform some initial checks, but it will then display a BIOS settings screen. If pressing Delete does not provide access to your system’s BIOS, other popular keys/key combinations to try (in order) are F2, F1, F3, F10, Esc, Ctrl-Alt-Esc, Ctrl-Alt-Insert, and Control-Alt-S. One of these should give you access to your system’s BIOS, though trying them all can be somewhat tedious and time-consuming.
Most modern x86 boxes feature one of a small number of different BIOS types. Two of the more popular BIOS types are the different Award BIOS screens shown in Figures 10-1 and 10-2.
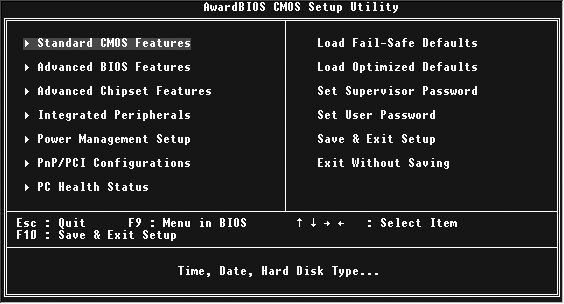
In the BIOS shown in Figure 10-1, the boot settings are stored in the Advanced Settings screen, which you can navigate to using the down arrow key. Press Return to display this screen once its name is highlighted. On the Advanced Settings screen, use the down arrow key to navigate to the First Boot Device entry, and press Return to display your choices. Use the arrow keys to select the entry corresponding to your actual boot drive, and press Return. You can then press the Escape key to exit this screen, and press F10 to save the new settings, exit the BIOS settings screen, and reboot.
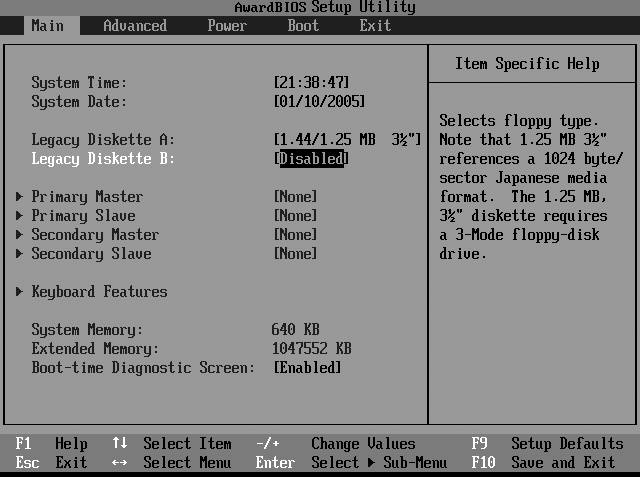
In the BIOS shown in Figure 10-2, the boot settings are stored in the Boot screen, which you can navigate to using the right arrow key. Press Return to display this screen once its name is highlighted. On the Boot screen, use the down arrow key to navigate to the Hard Drive entry, and press Return to display a list of available drives. You can then highlight the correct drive using the arrow keys and press Return to select it. Once the correct hard drive is selected, you can use the plus symbol to move that entry to be the first bootable device, and then press F10 to save the new settings, exit the BIOS settings screen, and reboot.
Tip
If the BIOS boot settings for the system on which you’re having problems appear to be correct, this is probably not the root of your problem, and you should change these settings only as a last resort. Changing too many variables at one time is a normal reaction to an unbootable system, but it’s rarely the right one.
Depending on the types and configuration of the drives in your system, you may have to experiment a bit with BIOS boot device settings before your system will boot correctly. If the BIOS doesn’t find a drive that you know to be physically present, the drive may have failed, in which case there isn’t all that much you can do without drive-specific hardware recovery techniques that are outside the scope of this book. If the BIOS finds the drive but you can’t read the disk’s partition table using the rescue CD, see “Recover Lost Partitions” [Hack #93] for suggestions about recreating the partition table. If the partition table is fine but you can’t mount or repair one or more partitions, see “Recover Data from Crashed Disks” [Hack #94] for suggestions about recovering data from the disk.
Fixing Runlevel or X Window System Problems
Most Linux distributions nowadays provide some sort of free online update service. These are great for keeping your system up to date with the newest, brightest, shiniest software available for your distribution. If you get a bogus update, however, they can also incapacitate your system—and some of the more common bogus updates that I’ve seen are updates to the X Window System (for X.org or, in the past, XFree86). Unfortunately, the fix that corrects someone else’s problem may take your GUI to its knees, where it doesn’t accept keyboard or mouse input. If you can’t get your X Window System display to respond to keyboard or mouse input, try the following:
Switch to another virtual console by pressing Ctrl-Alt-F1 or Ctrl-Alt-F2, log in there, and edit /etc/inittab to start at another runlevel until you can correct the problem. The specific inittab line you are looking for is:
id:5:initdefault:
You need to change the
5to another runlevel (usually3). Some distributions, such as Ubuntu and Gentoo, merely require you to stop the display manager from running, which usually means removing the xdm, gdm, or kdm service from the boot process. Once you’ve done this, reboot.Go to another machine and SSH or telnet into the system where you’re having problems. Once logged in,
suand edit /etc/inittab to start at another runlevel (usually 3) until you can correct the problem. Reboot.If you can’t do either of the previous suggestions (for example, if no other machine is handy or you’ve disabled virtual consoles and gettys to optimize performance), use the information provided later in this hack to reboot in single-user mode. You can then edit /etc/inittab to start at another runlevel until you can correct the problem. Reboot.
Once you’re in a nongraphical runlevel, you can perform repair tasks such as running filesystem repair utilities, repairing your X Window System configuration, and so on.
Regenerating a Default X Window System Configuration File
If you can boot your system successfully in a nongraphical runlevel but cannot start the X Window System automatically or manually, your configuration file may simply be hosed (in technical terms). Whether this happened because you’ve installed an updated version of the X Window System, your root filesystem took a hit and the file was deleted, or you’ve “fine-tuned” your configuration files to the point where X won’t start any more, you can start from scratch by generating a default X Window System configuration file that you can then use as a starting point to correct the problems you’re seeing. Both the X.org and XFree86 implementations of the X Window System provide a -configure option that enables you to generate a default configuration file. Depending on which X Window System server you have on your Linux system, log in as root and execute one of the following two commands to generate a default configuration file:
# Xorg -configure
# XFree86 -configureThese commands cause the X server to probe your graphics hardware and generate a default X Window System configuration file in the /root directory called xorg.conf.new or XF86Config.new. You can then test this generic configuration file by starting your X server with the following command:
# X -config/root/filename
If the X server starts correctly, replace your default X configuration file with the new one and (after creating a backup copy) resume normal use or finetuning. One common failing is that X won’t start because it can’t detect your mouse. If this happens, check the InputDevice section of the configuration file you created for the value of the Device option. If this is simply /dev/mouse, try changing it to /dev/input/mice and restarting X using the updated configuration file.
Tip
If you’re having problems starting or configuring X in general, your video card may use a chipset that is not yet supported by the version of the X Window System that you’re using. If this happens, you can try using a lowest common denominator as a fallback. Video Electronic Standards Association (VESA) is supported by most cards and should enable X to work at lower resolutions on almost any system with graphical capabilities. To use VESA, simply set the Driver line in your Device section to be vesa.
Booting to Single-User Mode
If you’re having problems booting to a specified runlevel, you may need to boot to single-user mode in order to repair your system. This can happen for a number of reasons, most commonly because of filesystem consistency problems, but also because of things such as the failure of any of the low-level system initialization scripts.
If you’re using the GRUB bootloader, press any key to interrupt the standard GRUB boot process, use the arrow keys to select the kernel you want to boot, and press the e key to edit the boot options for that kernel. Select the line containing the actual boot options (usually the first line), press e again to edit that command line, and append the command single to the end of the command line. You can then press b to boot with those boot options, and your system will go through the standard boot process but terminate either at a root shell prompt or by prompting you for your root password before starting that shell.
If you’re still using the LILO bootloader, you can do the same thing by entering the name of the boot stanza that you want to boot (usually linux), followed by a space and the -s directive. Again, you should get a root shell prompt or a request for the root password in a few seconds.
If you’re having problems starting a single-user shell, there may still be a problem in some low-level aspect of your boot process, or (gasp) you may have forgotten or be unable to supply the root password. In this case, see “Bypass the Standard Init Sequence for Quick Repairs” [Hack #91] for a quick way of bypassing the /sbin/init process and starting a shell directly.
Resolving Filesystem Consistency Problems
When a system doesn’t boot because it claims that one or more of your partitions is inconsistent and therefore needs to be repaired, you’re in luck—it’s hard to see disk corruption as a good thing, but it beats some of the alternatives. At least your system found the boot sector, booted off the right drive, and got to the point where it found enough applications to try to check your filesystems.
One of the most common problems when booting a system is resolving filesystem consistency problems encountered during boot time. When you shut down a system normally, the system automatically unmounts all of its filesystems, marking them as “clean” so that it can recognize that they are in a consistent state when you next boot the system. If a system crashes for some reason, the filesystems are not marked as clean and must therefore be checked for consistency and correctness the next time you boot the system. Different types of filesystems each have their own filesystem consistency verification and repair utilities. In most cases, your system will automatically run these for you as part of the boot process and will correct any filesystem consistency problems that these utilities detect. Sometimes, however, you’re not so lucky, and you’ll have to run these utilities manually to correct serious filesystem problems.
Similarly, if you’re using the XFS filesystem, all the vanilla repair utility does is return TRUE, since it expects that the XFS filesystem can correctly replay the journal and fix any problems as part of its mount process. If that’s not the case, you can find yourself in single-user mode if the boot and root partitions are OK. If not, see “Rescue Me!”
[Hack #90]
for information about getting a rescue CD, because you’re going to need it.
The details of manually running each filesystem’s consistency-checking utility are outside the scope of this hack, but it’s at least useful to know which utility to use if you have to manually repair a filesystem. Table 10-1 shows the filesystem consistency utilities that you use to manually repair various types of Linux filesystems.
|
Filesystem |
Utility |
|
ext2, ext3 |
e2fsck |
|
JFS |
jfs_fsck |
|
reiserfs |
reiserfsck |
|
XFS |
xfs_check, xfs_repair |
In the case of the XFS filesystem, xfs_check is a shell script that simply identifies problems in a specified filesystem, which you must then use the xfs_repair utility to correct.
See Also
RIP home page: http://www.tux.org/pub/people/kent-robotti/looplinux/rip/
“Rescue Me!” [Hack #90]
“Bypass the Standard Init Sequence for Quick Repairs” [Hack #91]
Rescue Me!
So you’ve tried all the standard tips and tricks to get your system to boot on its own, and nothing has worked. In that case, a bootable Linux system on a CD may be your new best friend.
Hardware failure, filesystem corruption, overzealous upgrades, and significant tweaking of your system’s startup process are among the things that can cause your system to fail to boot successfully. Assuming you’ve gotten to this point and the suggestions in “Resolve Common Boot and Startup Problems” [Hack #89] didn’t work out, your next good alternative is to download, burn, and boot from what is known as a "rescue disk.”
Tip
It’s always a good idea to keep a bootable rescue disk handy. Download and burn one before you have problems, so that you’ll have one to use should you ever need it.
A rescue disk is a small Linux distribution that boots and runs from a CD and provides the kernel and operating system capabilities that you need to access your hardware, as well as the tools you need to resolve problems with the interaction between that hardware and the desktop or server system you’re trying to boot. The things that a rescue disk must provide fall into four general categories:
A kernel and drivers for the storage devices attached to your system and, preferably, at least one of the network interface(s) available on that system.
Disk repair utilities for various types of filesystems, including logical volume management (LVM) utilities.
System utilities such as mount that enable you to access data from the filesystems on the ailing machine, boot tools such as GRUB that enable you to verify (and optionally update) the system’s boot process, and so on. These often include the tools used to recover from systems problems, as discussed in “Recover Lost Partitions” [Hack #93] (gpart) and “Recover Data from Crashed Disks” [Hack #94] (ddrescue).
Standard utilities, such as a text editor to correct and update text files used by the system during the boot process (such as /etc/inittab), the configuration files used by various services, and the system startup scripts in the /etc/rc.d or /etc/init.d directory (depending on your distribution)
Though there are plenty of rescue disks around, including many graphical Live-CD Linux distributions, my personal favorite for years has been Kent Robotti’s RIP (Recovery Is Possible!) disk, available from http://www.tux.org/pub/people/kent-robotti/looplinux/rip/. This is a relatively small (25 MB) rescue disk that does not offer any graphical user interface but does provide a complete set of up-to-date filesystem repair utilities for ext2, ext3, JFS, reiserfs, reiser4, and XFS filesystems, as well as the LVM2 utilities for mounting and managing logical volumes. As a nongraphical rescue disk, it targets experienced sysadmins who are comfortable at the command line, which you should be when trying to rescue or recover data from an ailing system.
Downloading and Burning the Rescue Disk
The two ISO images on the RIP page differ in terms of the bootloaders they use—one uses GRUB, and the other uses the standard ISOLINUX bootloader. I prefer to use the latter because it is simpler, so I always retrieve the file RIP-13.4.iso.bin, which is a binary CD image that you can burn directly to CD and then use to boot your system.
The standard Linux command-line CD-burning utility is called cdrecord. Prior to the 2.6 Linux kernel, using an IDE CD writer with cdrecord required the use of a loadable kernel module that provided SCSI emulation for IDE, because cdrecord expected SCSI identifiers when specifying the target output device. With the 2.6 kernel, CD-burning utilities can use ATA CD drives directly, without any special modules.
Once you’ve retrieved the file, you’ll need to identify your system’s CD burner(s). To do this, su to root and then execute the cdrecord -scanbus command. This causes cdrecord to probe the system for suitable devices and display the information that you’ll need to supply in order to write to them. Here’s an example:
# cdrecord -scanbus
Cdrecord 2.0 (i686-pc-linux-gnu) Copyright (C) 1995-2002 J#rg Schilling
Linux sg driver version: 3.1.24
Using libscg version 'schily-0.7'
scsibus0:
0,0,0 0) 'TOSHIBA ' 'DVD-ROM SD-R1202' '1026' Removable CD-ROM
0,1,0 1) *
0,2,0 2) *
0,3,0 3) *
0,4,0 4) *
0,5,0 5) *
0,6,0 6) *
0,7,0 7) *Once you’ve identified the device associated with your CD burner, burn the CD image to a writable CD-ROM using a command such as the following:
# cdrecord -v dev=0,0,0 speed=4 RIP-13.4.iso.binThis command will produce very verbose output (due to the use of the -v option) and will wait nine seconds before actually starting to write to the disc, just in case you change your mind. Once writing begins, the cdrecord command displays a status line that it continues to update until the entire file is written to the CD.
Using the Rescue CD
Once you’ve created the rescue CD, you need only put it in the ailing system and reboot. If your system is not configured to boot from the CD drive before booting from a hard disk partition, you may need to change your system’s boot sequence in the BIOS settings in order to get the system to boot from the CD.
Once you’ve booted from the rescue CD, you can quickly and easily perform tasks such as the following:
Run standard system repair commands to repair filesystem consistency [ Hacks #89 and #95 ].
Configure your system’s network interface so that you can bring the system up on your network.
Create archive files of critical files and directories and transfer those files to other systems using the ncftp utility supplied on the rescue disk.
Correct other boot problems [Hack #89] .
See Also
RIP home page: http://www.tux.org/pub/people/kent-robotti/looplinux/rip/
Bypass the Standard Init Sequence for Quick Repairs
Get as close to the metal as you can when resolving startup problems.
If you’re having problems booting a system to single-user mode, both the LILO and GRUB Linux bootloaders provide a great shortcut to help you get a shell prompt on an ailing system. This hack is especially useful if your password or shadow file has been damaged, a critical system binary is damaged or missing, or—heaven forbid—you’ve actually forgotten the root password on one of your systems.
By default, Linux systems use the /sbin/init process to start all other processes, including the root shell that you get when you boot a system in single-user mode. Both LILO and GRUB enable you to specify an alternate binary to run instead of the init process, though, using the init=
command boot option. By specifying /bin/bash as the command to start, you can get a quick prompt on your machine without exec‘ing init or going through any of the other steps in your system’s normal startup process.
Warning
The shell that is started when you exec /bin/bash directly does not have job control (Ctrl-Z) and does not respond to interrupts (Ctrl-C), so be very careful what commands you run from this shell. Don’t run any commands that do not automatically terminate or prompt for subcommands that enable you to exit and return to the shell.
If you’re using the GRUB bootloader, press any key to interrupt the standard GRUB boot process, use the arrow keys to select the kernel you want to boot, and press the e key to edit the boot options for that kernel. Select the line containing the actual boot options (usually the first line), press the e key again to edit that command line, and append the command init=/bin/sh to the end of the command line. You can then press b to boot with those boot options. You should see a shell prompt in a few seconds.
If you’re still using the LILO bootloader, you can do the same thing by entering the name of the boot stanza you want to boot (usually linux), followed by a space and the init=/bin/sh command. Again, you should get a shell prompt in a few seconds.
After getting a shell prompt, you should remount /proc to make sure that commands such as ps (and anything else that uses the /proc filesystem) work correctly. You can do this by executing the following command as root (or via sudo):
# mount -t proc none /procIf you need to create files on your system (for example, if you’re creating a file archive that you want to migrate to another system “just in case”), you must also remount your root filesystem in read/write mode, since at this early point in the boot process it is mounted read-only. To do this, execute the following command as root (or via sudo):
# mount -o remount,rw /You can now execute commands such as the filesystem repair commands [Hack #89] , start your Ethernet interface manually by executing /sbin/ifconfig with a static IP address, or perform any other commands that you need to do in order to repair your current system or migrate data from it to another system.
Find Out Why You Can’t Unmount a Partition
If you can’t unmount a disk because it’s busy, you can use the lsof and fuser commands to find open files or pesky attached processes.
The popularity of removable drives and their usability for things such as backups [Hack #50] makes mounting and unmounting partitions a fairly common activity while a system is running. Another not-so-common but more critical sysadmin activity is the need to unmount a drive in an emergency, such as when one of your users has accidentally deleted his thesis or the source code for your next-generation product, or the disk begins getting write errors and you need to initiate recovery ASAP. In either case, it’s truly irritating when you can’t unmount a partition because some unknown process is using it in one way or another. Shutting down a system just to unmount a disk so that you can remove or repair it is clearly overkill. Isn’t there a better way? Of course there is—read on.
Background
One of the most basic rules of Linux/Unix is that you can’t unmount a partition while a process is writing to or running from it. Trying to do so returns an informative but fairly useless message like the following:
$ sudo umount /mnt/music
umount: /mnt/music: device is busy
umount: /mnt/music: device is busyIn some cases, terminating the processes associated with a partition is as easy as looking through all your windows for suspended or background processes that are writing to the partition in question or using it as their current working directory and terminating them. However, on multi-user, graphical systems with many local and remote users, this isn’t always as straightforward as you’d like.
As progress toward an ultimate solution to this frustration, special-purpose Linux specifications such as Carrier-Grade Linux (CGL) require some “forced unmount” functionality in the kernel (http://developer.osdl.org/dev/fumount/), and the umount command includes a force (-F) option for NFS filesystems. That’s all well and good, but those of us who are using vanilla Linux distributions on local disks still need a practical solution that doesn’t require patching each kernel or killing a fly with a hammer through an immediate shutdown.
Tip
Recent versions of the umount command provide a –l option to “lazily” unmount a filesystem immediately, and then try to clean up references to the filesystem as the processes associated with them terminate. This is certainly interesting and can be useful, but I generally prefer to know what’s going on if I can’t unmount a filesystem that I think I should be able to unmount. Your mileage may vary.
Linux provides two commands that you can use to identify processes running on a filesystem so that you can (hopefully) terminate them in one way or another: fuser (find user process) and
lsof (list open files). The key difference between the two is that the fuser command simply returns the process IDs (PIDs) of any processes associated with the file or directory specified as an argument, while the lsof command returns a full process listing that provides a variety of information about the processes associated with its argument(s). Both are quite useful, and which you use is up to you. The next two sections show how to use each of these commands to help find the pesky process(es) that are keeping you from unmounting a partition.
Tip
The Open Source Development Lab’s forced unmount page, referenced at the end of this hack, provides a cool but crude script called funmount that tries to automatically combine a number of passes of fuser with the appropriate unmount commands to “do the right thing” for you when you need to forcibly unmount a specified partition. It’s worth a look.
Finding Processes That Are Using a Filesystem
The fuser command returns the PIDs of all the processes associated with the device or mounted filesystem that is specified as an argument, along with terse information that summarizes the way in which each process is using the filesystem. To search for all processes associated with a mounted filesystem or device, you need to specify the –m option, followed by the name of the filesystem or its mount point. For example, the following fuser command looks for processes associated with the filesystem mounted at /mnt/music on my system:
$ fuser -m /mnt/music
/mnt/music: 29846c 31763cEach process ID returned by the fuser command is followed by a single letter that indicates how the specified process is using the filesystem. The most common of these is the letter c, which indicates that the process is using a directory on that filesystem as its current working directory. In the previous example, you can see that both of the processes listed are using the filesystem as their current working directory.
Once you have this sort of output, you can use the grep command to search for each of the specified process IDs and see what they’re actually doing, as in the following example:
$ ps alxww | grep 29846
0 1000 29846 7797 16 0 9992 2284 wait Ss pts/13 0:00 /bin/bash
4 0 29912 29846 16 0 24608 1364 finish T pts/13 0:00 su
0 1000 31763 29846 16 0 10292 2480 - S+ pts/13 0:00 vi playlist.m3u
0 1000 31789 30009 17 0 3788 764 - R+ pts/14 0:00 grep -i 29846By default, the fuser command returns all active processes. However, as we can (accidentally) see in the above process listing, there is also a terminated su process that is a child of the process that fuser identified, which could prevent us from unmounting the filesystem in question. To provide a more complete fuser output listing, you should generally run the fuser command as root (or via sudo), and also specify the –a option to ensure that all processes are listed, regardless of their states, as in the following example:
$ sudo fuser -am /dev/mapper/data-music
/dev/mapper/data-music: 29846c 29912c 29916c 31763c 32088As you can see, fuser now picks up the process ID of the su process.
Tip
If you’re really in a hurry, you can also specify the fuser command’s –k option, which kills any processes it finds. It’s generally a good idea to try to find the processes in question and terminate them cleanly, but in some cases you may just want to kill the processes as quickly as possible (for example, when you’re hoping to subsequently recover deleted files and want to prevent filesystem updates).
Listing Open Files
The fuser command returns PIDs that require subsequent interpretation to figure out which files they’re actually using on the specified filesystem (though the status indicator appended to each PID gives you a quick idea of how each process is using the filesystem). In contrast, the
lsof command returns more detailed information about processes that have open files on a specified filesystem, and may tell you everything that you need to know in one swell foop. For example, the following is the output of the lsof command on the same filesystem used in the previous examples:
$ lsof /mnt/music
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 29846 wvh cwd DIR 253,0 64 131 /mnt/music/test
vi 31763 wvh cwd DIR 253,0 64 131 /mnt/music/test
vi 31763 wvh 4u REG 253,0 12288 133 /mnt/music/test/.playlist.
m3u.swpThe first column (COMMAND) shows each command that the system is running that is associated with the file, directory, or mount point that you specified as an argument. The last column (NAME) identifies the file or directory that each command is actually associated with. The FD column shows the active file descriptors associated with the process or, in the case of a shell or command, the fact that the shell or command is using the specified directory as its current working directory (cwd).
As with fuser, when run by a standard user the output of lsof shows only active processes. To get more complete output, you should generally run the lsof command as root (or via sudo), as in the following example:
$ sudo lsof /mnt/music
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 29846 wvh cwd DIR 253,0 64 131 /mnt/music/test
su 29912 root cwd DIR 253,0 17 128 /mnt/music
bash 29916 root cwd DIR 253,0 17 128 /mnt/music
vi 31763 wvh cwd DIR 253,0 64 131 /mnt/music/test
vi 31763 wvh 4u REG 253,0 12288 133 /mnt/music/test/.playlist.
m3u.swpYou can see that the output of this instance of the lsof command picked up the suspended su process, and also identifies the bash shell associated with this process.
Unlike the fuser command, the lsof command doesn’t provide an option to automatically terminate the processes it has located, but it provides a good deal more information to begin with. Once you know exactly what they’re doing and are sure that it’s safe to kill them, you can always quickly terminate each process manually from the command line in order to unmount the filesystem.
Summary
The fuser and lsof commands are useful additions to your Linux sysadmin toolset. fuser quickly delivers information about active processes and provides an option to automatically and instantly terminate processes associated with the filesystems or files that you specify as arguments, but its output requires subsequent interpretation (if you have time to play detective). The lsof command returns more detailed information about the associated processes (although additional interpretation may still be required), and can also display information about network-related files and sockets that may be open (see its manpage or FAQ for more details). However, it doesn’t include an option to quickly terminate all of the processes in one go. In my experience, fuser is faster, but lsof provides a much richer spectrum of information. Each is useful at different times, depending on what you’re looking for and how quickly you need to find (and perhaps kill) it.
Recover Lost Partitions
If you can’t mount any of the partitions on a hard drive, you may simply need to recreate the partition table. Here’s a handy utility for identifying possible partition entries.
Seeing messages like “/dev/FOO: device not found” is never a good thing. However, this message can be caused by a number of different problems. There isn’t much you can do about a complete hardware failure, but if you’re “lucky” your disk’s partition table may just have been damaged and your data may just be temporarily inaccessible.
Tip
If you haven’t rebooted, execute the cut lproc /partitions command to see if it still lists your device’s partitions.
Unless you have a photographic memory, your disk contains only a single partition, or you were sufficiently disciplined to keep a listing of its partition table, trying to guess the sizes and locations of all of the partitions on an ailing disk is almost impossible without some help. Thankfully, Michail Brzitwa has written a program that can provide exactly the help you need. His gpart (guess partitions) program scans a specified disk drive and identifies entries that look like partition signatures. By default, gpart displays only a listing of entries that appear to be partitions, but it can also automatically create a new partition table for you by writing these entries to your disk. That’s a scary thing to do, but it beats the alternative of losing all your existing data.
Tip
If you’re just reading this for information and aren’t actually in the midst of a lost data catastrophe, you may be wondering how to back up a disk’s partition table so that you don’t have to depend on a recovery utility like gpart. You can easily back up a disk’s master boot record (MBR) and partition table to a file using the following dd command, where FOO is the disk and FILENAME is the name of the file to which you want to write your backup:
# dd if=/dev/FOO of=FILENAME bs=512 count=1If you subsequently need to restore the partition table to your disk, you can do so with the following dd command, using the same variables as before:
# dd if=FILENAME of=/dev/FOO bs=1 count=64 skip=446
seek=446The gpart program works by reading the entire disk and comparing sector sequences against a set of filesystem identification modules. By default, gpart includes filesystem identification modules that can recognize the following types of partitions: beos (BeOS), bsddl (FreeBSD/NetBSD/386BSD), ext2 and ext3 (standard Linux filesystems), fat (MS-DOS FAT12/16/32), hpfs (remember OS/2?), hmlvm (Linux LVM physical volumes), lswap (Linux swap), minix (Minix OS), ntfs (Microsoft Windows NT/2000/XP/etc.), qnx4 (QNX Version 4.x), rfs (ReiserFS Versions 3.5.11 and greater), s86dl (Sun Solaris), and xfs (XFS journaling filesystem). You can write additional partition identification modules for use by gpart (JFS fans, take note!), but that’s outside the scope of this hack. For more information about expanding gpart, see its home page at http://www.stud.uni-hannover.de/user/76201/gpart and the README file that is part of the gpart archive.
Looking for Partitions
As an example of gpart’s partition scanning capabilities, let’s first look at the listing of an existing disk’s partition table as produced by the fdisk program. (BTW, if you’re questioning the sanity of the partition layout, this is a scratch disk that I use for testing purposes, not a day-to-day disk.) Here’s fdisk’s view:
# fdisk -l /dev/hdb
Disk /dev/hdb: 60.0 GB, 60022480896 bytes
255 heads, 63 sectors/track, 7297 cylinders Units = cylinders of 16065 * 512
= 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hdb1 1 25 200781 83 Linux
/dev/hdb2 26 57 257040 82 Linux swap / Solaris
/dev/hdb3 58 3157 24900750 83 Linux
/dev/hdb4 3158 7297 33254550 5 Extended
/dev/hdb5 3158 3337 1445818+ 83 Linux
/dev/hdb6 3338 3697 2891668+ 83 Linux
/dev/hdb7 3698 4057 2891668+ 83 Linux
/dev/hdb8 4058 4417 2891668+ 83 Linux
/dev/hdb9 4418 4777 2891668+ 83 Linux
/dev/hdb10 4778 5137 2891668+ 83 Linux
/dev/hdb11 5138 5497 2891668+ 83 Linux
/dev/hdb12 5498 5857 2891668+ 83 Linux
/dev/hdb13 5858 6217 2891668+ 83 Linux
/dev/hdb14 6218 6577 2891668+ 83 Linux
/dev/hdb15 6578 6937 2891668+ 83 Linux
/dev/hdb16 6938 7297 2891668+ 83 LinuxLet’s compare this with gpart’s view of the partitions that live on the same disk:
# gpart /dev/hdb
Begin scan…
Possible partition(Linux ext2), size(196mb), offset(0mb)
Possible partition(Linux swap), size(251mb), offset(196mb)
Possible partition(Linux ext2), size(24317mb), offset(447mb)
Possible partition(Linux ext2), size(1411mb), offset(24764mb)
Possible partition(Linux ext2), size(2823mb), offset(26176mb)
Possible partition(Linux ext2), size(2823mb), offset(29000mb)
Possible partition(Linux ext2), size(2823mb), offset(31824mb)
Possible partition(Linux ext2), size(2823mb), offset(34648mb)
Possible partition(Linux ext2), size(2823mb), offset(37471mb)
Possible partition(Linux ext2), size(2823mb), offset(40295mb)
Possible partition(Linux ext2), size(2823mb), offset(43119mb)
Possible partition(Linux ext2), size(2823mb), offset(45943mb)
Possible partition(Linux ext2), size(2823mb), offset(48767mb)
Possible partition(Linux ext2), size(2823mb), offset(51591mb)
Possible partition(Linux ext2), size(2823mb), offset(54415mb)
End scan.
Checking partitions…
* Warning: more than 4 primary partitions: 15.
Partition(Linux ext2 filesystem): primary
Partition(Linux swap or Solaris/x86): primary
Partition(Linux ext2 filesystem): primary
Partition(Linux ext2 filesystem): primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Partition(Linux ext2 filesystem): invalid primary
Ok.
Guessed primary partition table:
Primary partition(1)
type: 131(0x83)(Linux ext2 filesystem)
size: 196mb #s(401562) s(63-401624)
chs: (0/1/1)-(398/6/63)d (0/1/1)-(398/6/63)r
Primary partition(2)
type: 130(0x82)(Linux swap or Solaris/x86)
size: 251mb #s(514080) s(401625-915704)
chs: (398/7/1)-(908/6/63)d (398/7/1)-(908/6/63)r
Primary partition(3)
type: 131(0x83)(Linux ext2 filesystem)
size: 24317mb #s(49801496) s(915705-50717200)
chs: (908/7/1)-(1023/15/63)d (908/7/1)-(50314/10/59)r
Primary partition(4)
type: 131(0x83)(Linux ext2 filesystem)
size: 1411mb #s(2891632) s(50717268-53608899)
chs: (1023/15/63)-(1023/15/63)d (50314/12/1)-(53183/6/58)rDoing the math can be a bit tedious, but calculating the partition size and offsets shows that they are actually the same. gpart found all of the partitions, including all of the logical partitions inside the disk’s extended partition, which can be tricky. If you don’t want to do the math yourself, gpart provides a special -c option for comparing its idea of a disk’s partition table against the partitions that are listed in an existing partition table. Using gpart with the -c option returns 0 if the two are identical or the number of differences if the two differ.
Writing the Partition Table
Using fdisk to recreate a partition table can be a pain, especially if you have multiple partitions of different sizes. As mentioned previously, gpart provides an option that automatically writes a new partition table to the scanned disk. To do this, you need to specify the disk to scan and the disk to write to on the command line, as in the following example:
# gpart -W /dev/FOO/dev/FOO
If you’re paranoid (and you should be, even though your disk is already hosed), you can back up the existing MBR before writing it by adding the -b option to your command line and specifying the name of the file to which you want to back up the existing MBR, as in the following example:
# gpart -bFILENAME-W /dev/FOO/dev/FOO
As mentioned at the beginning of this hack, a disk failure may simply be the result of a bad block that happens to coincide with your disk’s primary partition table. If this happens to you and you don’t have a backup of the partition table, gpart does an excellent job of guessing and rewriting your disk’s primary partition table. If the disk can’t be mounted because it is severely corrupted or otherwise damaged, see “Recover Data from Crashed Disks” [Hack #94] and “Piece Together Data from the lost+found” [Hack #96] for some suggestions regarding more complex and desperate data recovery hacks.
See Also
“Rescue Me!” [Hack #90]
Recover Data from Crashed Disks
You can recover most of the data from crashed hard drives with a few simple Linux tricks.
As the philosopher once said, “Into each life, a few disk crashes must fall.” Or something like that. Today’s relatively huge disks make it more tempting than ever to store large collections of data online, such as your entire music collection or all of the research associated with your thesis. Backups can be problematic, as today’s disks are much larger than most backup media, and backups can’t restore any data that was created or modified after the last backup was made. Luckily, the fact that any Linux/Unix device can be accessed as a stream of characters presents some interesting opportunities for restoring some or all of your data even after a hard drive failure. When disaster strikes, consult this hack for recovery tips.
Tip
This hack uses error messages and examples produced by the ext2fs filesystem consistency checking utility associated with the Linux ext2 and ext3 filesystems. You can use the cloning techniques in this hack to copy any Linux disk, but the filesystem repair utilities will differ for other types of Linux filesystems. For example, if you are using ReiserFS filesystems, see “Repair and Recover ReiserFS Filesystems” [Hack #95] for details on using the special commands provided by its filesystem consistency checking utility, reiserfsck.
Popular Disk Failure Modes
Disks generally go bad in one of three basic ways:
Hardware failure that prevents the disk heads from moving or seeking to various locations on the disk. This is generally accompanied by a ticking noise whenever you attempt to mount or otherwise access the filesystem, which is the sound of disk heads failing to launch or locate themselves correctly.
Bad blocks on the disk that prevent the disk’s partition table from being read. The data is probably still there, but the operating system doesn’t know how to find it.
Bad blocks on the disk that cause a filesystem on a partition of the disk to become unreadable, unmountable, and uncorrectable.
The first of these problems can generally be solved only by shipping your disk off to a firm that specializes in removing and replacing drive internals, using cool techniques for recovering data from scratched or flaked platters, if necessary. The second of these problems is discussed in “Recover Lost Partitions” [Hack #93] . This hack explains how to recover data that appears to be lost due to the third of these problems: bad blocks that corrupt filesystems to the point where standard filesystem repair utilities cannot correct them.
Tip
If your disk contains more than one partition and one of the partitions that it contains goes bad, chances are that the rest of the disk will soon develop problems. While you can use the techniques explained in this hack to clone and repair a single partition, this hack focuses on cloning and recovering an entire disk. If you clone and repair a disk containing multiple partitions, you will hopefully find that some of the copied partitions have no damage. That’s great, but cloning and repairing the entire disk is still your safest option.
Attempt to Read Block from Filesystem Resulted in Short Read…
The title of this section is one of the more chilling messages you can see when attempting to mount a filesystem that contained data the last time you booted your system. This error always means that one or more blocks cannot be read from the disk that holds the filesystem you are attempting to access. You generally see this message when the fsck utility is attempting to examine the filesystem, or when the mount utility is attempting to mount it so that it is available to the system.
A short read error usually means that an inode in the filesystem points to a block on the filesystem that can no longer be read, or that some of the metadata about your filesystem is located on a block (or blocks) that cannot be read. On journaling filesystems, this error displays if any part of the filesystem’s journal is stored on a bad block. When a Linux system attempts to mount a partition containing a journaling filesystem, its first step is to replay any pending transactions from the filesystem’s journal. If these cannot be read—voilà!—short read.
Standard Filesystem Diagnostics and Repair
The first thing to try when you encounter any error accessing or mounting a filesystem is to check the consistency of the filesystem. All native Linux filesystems provide consistency-checking applications. Table 10-2 shows the filesystem consistency checking utilities for various popular Linux filesystems.
|
Filesystem type |
Diagnostic/repair utilities |
|
ext2, ext3 |
e2fsck, fsck.ext2, fsck.ext3, tune2fs, debugfs |
|
JFS |
jfs_fsck, fsck.jfs |
|
reiserfs |
reiserfsck, fsck.reiserfs, debugresiserfs |
|
XFS |
fsck.xfs, xfs_check |
The consistency-checking utilities associated with each type of Linux filesystem have their own ins and outs. In this section, I’ll focus on trying to deal with short read errors from disks that contain partitions in the ext2 or ext3 formats, which are the most popular Linux partition formats. The ext3 filesystem is a journaling version of the ext2 filesystem, and the two types of filesystems therefore share most data structures and all repair/recovery utilities. If you are using another type of filesystem, the general information about cloning and repairing disks in later sections of this hack still applies.
If you’re using an ext2 or ext3 filesystem, your first hint of trouble will come from a message like the following, generally encountered when restarting your system. This warning comes from the e2fsck application (or a symbolic link to it, such as fsck.ext2 or fsck.ext3):
# e2fsck /dev/hda1
e2fsck: Attempt to read block from filesystem resulted in short readIf you see this message, the first thing to try is to cross your fingers and hope that only the disk’s primary superblock is bad. The superblock contains basic information about the filesystem, including primary pointers to the blocks that contain information about the filesystem (known as inodes). Luckily, when you create an ext2 or ext3 filesystem, the filesystem-creation utility (mke2fs or a symbolic link to it named mkfs.ext2 or mkfs.ext3) automatically creates backups copies of your disk’s superblock, just in case. You can tell the e2fsck program to check the filesystem using one of these alternate superblocks by using its -b option, followed by the block number of one of these alternate superblocks within the filesystem with which you’re having problems. The first of these alternate superblocks is usually created in block 8193, 16384, or 32768, depending on the size of your disk. Assuming that this is a large disk, we’ll try the last as an alternative:
# e2fsck -b 32768 /dev/hda1
e2fsck: Attempt to read block from filesystem resulted in short read while
checking ext3 journal for /dev/hda1Tip
You can determine the locations of the alternate superblocks on an unmounted ext3 filesystem by running the mkfs.ext3 command with the –n option, which reports on what the mkfs utility would do but doesn’t actually create a filesystem or make any modifications. This may not work if your disk is severely corrupted, but it’s worth a shot. If it doesn’t work, try 8192, 16384, and 32768, in that order.
This gave us a bit more information. The problem doesn’t appear to be with the filesystem’s superblocks, but instead is with the journal on this filesystem. Journaling filesystems minimize system restart time by heightening filesystem consistency through the use of a journal [Hack #70] . All pending changes to the filesystem are first stored in the journal, and are then applied to the filesystem by a daemon or internal scheduling algorithm. These transactions are applied atomically, meaning that if they are not completely successful, no intermediate changes that are part of the unsuccessful transactions are made. Because the filesystem is therefore always consistent, checking the filesystem at boot time is much faster than it would be on a standard, non-journaling filesystem.
Removing an ext3 Filesystem’s Journal
As mentioned previously, the ext3 and ext2 filesystems primarily differ only in whether the filesystem contains a journal. This makes repairing most journaling-related problems on an ext3 filesystem relatively easy, because the journal can simply be removed. Once the journal is removed, the consistency of the filesystem in question can be checked as if the filesystem was a standard ext2 filesystem. If you’re very lucky, and the bad blocks on your system were limited to the ext3 journal, removing the journal (and subsequently fsck‘ing the filesystem) may be all you need to do to be able to mount the filesystem and access the data it contains.
Removing the journal from an ext3 filesystem is done using the tune2fs application, which is designed to make a number of different types of changes to ext2 and ext3 filesystem data. The tune2fs application provides the -O option to enable you to set or clear various filesystem features. (See the manpage for tune2fs for complete information about available features.) To clear a filesystem feature, you precede the name of that feature with the caret (^) character, which has the classic Computer Science 101 meaning of “not.” Therefore, to configure a specified existing filesystem so that it thinks that it does not have a journal, you would use a command line like the following:
# tune2fs -f -O ^has_journal /dev/hda1
tune2fs 1.35 (28-Feb-2004)
tune2fs: Attempt to read block from filesystem resulted in short read
while reading journal inodeDarn. In this case, the inode that points to the journal seems to be bad, which means that the journal can’t be cleared. The next thing to try is the debugfs command, which is an ext2/ext3 filesystem debugger. This command provides an interactive interface that enables you to examine and modify many of the characteristics of an ext2/ext3 filesystem, as well as providing an internal features command that enables you to clear the journal. Let’s try this command on our ailing filesystem:
# debugfs /dev/hda1debugfs 1.35 (28-Feb-2004) /dev/hda1: Can't read an inode bitmap while reading inode bitmap debugfs:featuresfeatures: Filesystem not open debugfs:open /dev/hda1/dev/hda1: Can't read an inode bitmap while reading inode bitmap debugfs:quit
Alas, the debugfs command couldn’t access a bitmap in the filesystem that tells it where to find specific inodes (in this case, the journal’s inode).
Tip
If you are able to clear the journal using the tune2fs or debugfs command, you should retry the e2fsck application, using its -c option to have e2fsck check for bad blocks in the filesystem and, if any are found, add them to the disk’s bad block list.
Since we can’t fsck or fix the filesystem on the ailing disk, it’s time to bring out the big hammer.
Cloning a Bad Disk Using ddrescue
If bad blocks are preventing you from reading or repairing a disk that contains data you want to recover, the next thing to try is to create a copy of the disk using a raw disk copy utility. Unix/Linux systems have always provided a simple utility for this purpose, known as dd, which copies one file/partition/disk to another and provides commands that enable you to proceed even in the face of various types of read errors. You must put another disk in your system that is at least the same size or larger than the disk or partition that you are attempting to clone. If you copy a smaller disk to a larger one, you’ll obviously be wasting the extra space on the larger disk, but you can always recycle the disk after you extract and save any data that you need from the clone of the bad disk.
To copy one disk to another using dd, telling it not to stop on errors, you would use a command like the following:
# dd if=/dev/hda of=/dev/hdb conv=noerror,syncThis command would copy the bad disk (here, /dev/hda) to a new disk (here, /dev/hdb), ignoring errors encountered when reading (noerror) and padding the output with an appropriate number of nulls when unreadable blocks are encountered (sync).
dd is a fine, classic Unix/Linux utility, but I find that it has a few shortcomings:
It is incredibly slow.
It does not display progress information, so it is silent until it is done.
It does not retry failed reads, which can reduce the amount of data that you can recover from a bad disk.
Therefore, I prefer to use a utility called ddrescue, which is available from http://www.gnu.org/software/ddrescue/ddrescue.html. This utility is not included in any Linux distribution that I’m aware of, so you’ll have to download the archive, unpack it, and build it from source code. Version 0.9 was the latest version when this book was written.
The ddrescue command has a large number of options, as the following help message shows:
# ./ddrescue -h
GNU ddrescue - Data recovery tool.
Copies data from one file or block device to another,
trying hard to rescue data in case of read errors.
Usage: ./ddrescue [options] infile outfile [logfile]
Options:
-h, --help display this help and exit
-V, --version output version information and exit
-B, --binary-prefixes show binary multipliers in numbers [default SI]
-b, --block-size=<bytes> hardware block size of input device [512]
-c, --cluster-size=<blocks> hardware blocks to copy at a time [128]
-e, --max-errors=<n> maximum number of error areas allowed
-i, --input-position=<pos> starting position in input file [0]
-n, --no-split do not try to split error areas
-o, --output-position=<pos> starting position in output file [ipos]
-q, --quiet quiet operation
-r, --max-retries=<n> exit after given retries (-1=infinity) [0]
-s, --max-size=<bytes> maximum size of data to be copied
-t, --truncate truncate output file
-v, --verbose verbose operation
Numbers may be followed by a multiplier: b = blocks, k = kB = 10^3 = 1000,
Ki = KiB = 2^10 = 1024, M = 10^6, Mi = 2^20, G = 10^9, Gi = 2^30, etc…
If logfile given and exists, try to resume the rescue described in it.
If logfile given and rescue not finished, write to it the status on exit.
Report bugs to [email protected] #As you can see, ddrescue provides many options for controlling where to start reading, where to start writing, the amount of data to be read at a time, and so on. I generally only use the --max-retries option, supplying -1 as an argument to tell ddrescue not to exit regardless of how many retries it needs to make in order to read a problematic disk. Continuing with the previous example of cloning the bad disk /dev/hda to a new disk, /dev/hdb, that is the same size or larger, I’d execute the following command:
# ddrescue --max-retries=-1 /dev/hda /dev/hdb
Press Ctrl-C to interrupt
rescued: 3729 MB, errsize: 278 kB, current rate: 26083 kB/s
ipos: 3730 MB, errors: 6, average rate: 18742 kB/s
opos: 3730 MB
Copying data…The display is constantly updated with the amount of data read from the first disk and written to the second, including a count of the number of disk errors encountered when reading the disk specified as the first argument.
Once ddrescue completes the disk copy, you should run e2fsck on the copy of the disk to eliminate any filesystem errors introduced by the bad blocks on the original disk. Since there are guaranteed to be a substantial number of errors and you’re working from a copy, you can try running e2fsck with the -y option, which tells e2fsck to answer yes to every question. However, depending on the types of messages displayed by e2fsck, this may not always work—some questions are of the form Abort? (y/n), to which you probably do not want to answer “yes.”
Here’s some sample e2fsck output from checking the consistency of a bad 250-GB disk containing a single partition that I cloned using ddrescue:
# fsck -y /dev/hdb1fsck 1.35 (28-Feb-2004) e2fsck 1.35 (28-Feb-2004) /dev/hdb1 contains a file system with errors, check forced. Pass 1: Checking inodes, blocks, and sizes Root inode is not a directory. Clear?yesInode 12243597 is in use, but has dtime set. Fix?yesInode 12243364 has compression flag set on filesystem without compression support. Clear?yesInode 12243364 has illegal block(s). Clear?yesIllegal block #0 (1263225675) in inode 12243364. CLEARED. Illegal block #1 (1263225675) in inode 12243364. CLEARED. Illegal block #2 (1263225675) in inode 12243364. CLEARED. Illegal block #3 (1263225675) in inode 12243364. CLEARED. Illegal block #4 (1263225675) in inode 12243364. CLEARED. Illegal block #5 (1263225675) in inode 12243364. CLEARED. Illegal block #6 (1263225675) in inode 12243364. CLEARED. Illegal block #7 (1263225675) in inode 12243364. CLEARED. Illegal block #8 (1263225675) in inode 12243364. CLEARED. Illegal block #9 (1263225675) in inode 12243364. CLEARED. Illegal block #10 (1263225675) in inode 12243364. CLEARED. Too many illegal blocks in inode 12243364. Clear inode?yesFree inodes count wrong for group #1824 (16872, counted=16384). Fix?yesFree inodes count wrong for group #1846 (16748, counted=16384). Fix?yesFree inodes count wrong (30657608, counted=30635973). Fix?yes[much more output deleted]
Once e2fsck completes, you’ll see the standard summary message:
/dev/hdb1: ***** FILE SYSTEM WAS MODIFIED ***** /dev/hdb1: 2107/30638080 files (16.9% non-contiguous), 12109308/61273910 blocks
Checking the Restored Disk
At this point, you can mount the filesystem using the standard mount command and see how much data was recovered. If you have any idea how full the original filesystem was, you will hopefully see disk usage similar to that in the recovered filesystem. The differences in disk usage between the clone of your old filesystem and the original filesystem will depend on how badly corrupted the original filesystem was and how many files and directories had to be deleted due to inconsistency during the filesystem consistency check.
Tip
Remember to check the lost+found directory at the root of the cloned drive (i.e., in the directory where you mounted it), which is where fsck and its friends place files and directories that could not be correctly linked into the recovered filesystem. For more detailed information about identifying and piecing things together from a lost+found directory, see “Piece Together Data from the lost+found” [Hack #96] .
You’ll be pleasantly surprised at how much data you can successfully recover using this technique—as will your users, who will regard you as even more wizardly after a recovery effort such as this one. Between this hack and your backups (you do backups, right?), even a disk failure may not cause significant data loss.
See Also
“Recover Lost Partitions” [Hack #93]
“Repair and Recover ReiserFS Filesystems” [Hack #95]
“Piece Together Data from the lost+found” [Hack #96]
“Recover Deleted Files” [Hack #97]
Repair and Recover ReiserFS Filesystems
Different filesystems have different repair utilities and naming conventions for recovered files. Here’s how to repair a severely damaged ReiserFS filesystem.
“Recover Data from Crashed Disks” [Hack #94] explained how to use the ddrescue utility to clone a disk or partition that you could not check the consistency of or read, and how to use the ext2/ext3 e2fsck utility to check and correct the consistency of the cloned disk or partition. This hack explains how to repair and recover severely damaged ReiserFS filesystems.
The ReiserFS filesystem was the first journaling filesystem that was widely used on Linux systems. Journaling filesystems such as ext3, JFS, ReiserFS, and XFS save pending disk updates as atomic transactions in a special on-disk log, and then asynchronously commit those updates to disk, guaranteeing filesystem consistency at any given point. Developed by a team led by Hans Reiser, ReiserFS incorporates many of the cutting-edge concepts of the time into a stable journaling filesystem that is the default filesystem type on Linux distributions such as SUSE. For more information about the ReiserFS filesystem, see its home page at http://www.namesys.com.
ReiserFS filesystems have their own utility, reiserfsck, which provides special options for repairing and recovering severely damaged ReiserFS filesystems. Like fsck, the reiserfsc utility uses a lost+found directory, located at the root of the filesystem, to store undamaged files or directories that could not be relinked into the filesystem correctly during the consistency check. However, unlike with ext2/ext3 filesystems, this directory is not created when a ReiserFS filesystem is created; it is only created when it is needed. If it has already been created by a previous reiserfsck consistency check, the existing lost+found directory is used.
Correcting a Damaged ReiserFS Filesystem
Though ReiserFS filesystems guarantee filesystem consistency through journaling, hardware problems can still prevent a ReiserFS filesystem from reading or correctly replaying its journal. Like inconsistencies in any Linux filesystem that is automatically mounted at boot time, this will cause your system’s boot process to pause and drop you into a root shell (after you supply the root password). The following is a sample problem report from the reiserfsck application:
reiserfs_open: the reiserfs superblock cannot be found on /dev/hda2. Failed to open the filesystem. If the partition table has not been changed, and the partition is valid and it really contains a reiserfs partition, then the superblock is corrupted and you need to run this utility with --rebuild-sb.
When you see a problem such as this, check /var/log/messages for any reports of problems on the specified partition or the disk that contains it. For example:
Jun 17 06:48:20 64bit kernel: hdb: drive_cmd: status=0x51
{ DriveReady SeekComplete Error }
Jun 17 06:48:20 64bit kernel: hdb: drive_cmd: error=0x04 { DriveStatusError }
Jun 17 06:48:20 64bit kernel: ide: failed opcode was: 0xefIf you see drive errors such as these, clone the drive before it actually fails [Hack #94] , and then attempt to correct filesystem problems on the cloned disk. If you see no disk errors, it’s safe to try to resolve the problem on the original disk. Either way, you should then use the following steps to correct ReiserFS consistency problems (I’ll use /dev/hda2 as an example, but you should replace this with the actual name of the partition with which you’re having problems):
If the disk reported superblock problems, execute the
reiserfsck -rebuild-sbpartitioncommand to rebuild the superblock. You’ll be prompted for the ReiserFS version (3.6 if you are running a Linux kernel newer than 2.2.x), the block size (4096 by default, unless you specified a custom block size when you created the filesystem), the location of the journal (an internal default unless you changed it when you created the partition), and whether the problem occurred as a result of trying to resize the partition. After reiserfsck performs its internal calculations, you’ll be prompted as to whether you should accept its suggestions. The answer to this should always be “yes,” unless you want to try resolving the problem manually using the reiserfstune application, which would require substantial wizardry on your part. Here’s an example:# reiserfsck --rebuild-sb /dev/hda2reiserfsck 3.6.18 (2003 www.namesys.com) [verbose messages deleted] Do you want to run this program?[N/Yes] (note need to type Yes if you do):Yesreiserfs_open: the reiserfs superblock cannot be found on /dev/hda2. what the version of ReiserFS do you use[1-4] (1) 3.6.x (2) >=3.5.9 (introduced in the middle of 1999) (if you use linux 2. 2, choose this one) (3) < 3.5.9 converted to new format (don't choose if unsure) (4) < 3.5.9 (this is very old format, don't choose if unsure) (X) exit1Enter block size [4096]:4096No journal device was specified. (If journal is not available, re-run with --no-journal-available option specified). Is journal default? (y/n)[y]:yDid you use resizer(y/n)[n]:nrebuild-sb: no uuid found, a new uuid was generated (9966c3a3-7962-4a9b b027-7ea921e567ac) Reiserfs super block in block 16 on 0x302 of format 3.6 with standard journal Count of blocks on the device: 2048272 Number of bitmaps: 63 Blocksize: 4096 Free blocks (count of blocks - used [journal, bitmaps, data, reserved] blocks): 0 Root block: 0 Filesystem is NOT clean Tree height: 0 Hash function used to sort names: not set Objectid map size 0, max 972 Journal parameters: Device [0x0] Magic [0x0] Size 8193 blocks (including 1 for journal header) (first block 18) Max transaction length 1024 blocks Max batch size 900 blocks Max commit age 30 Blocks reserved by journal: 0 Fs state field: 0x1: some corruptions exist. sb_version: 2 inode generation number: 0 UUID: 9966c3a3-7962-4a9b-b027-7ea921e567ac LABEL: Set flags in SB: Is this ok ? (y/n)[n]:yThe fs may still be unconsistent. Run reiserfsck --check.Try running the
reiserfs–checkpartitioncommand, as suggested. If you’re lucky, this will resolve the problem, in which case you can skip the rest of the steps in this list and go to the next section. However, if the partition contains additional errors, this command will fail with a message like the one shown here:# reiserfsck --check /dev/hda2reiserfsck 3.6.18 (2003 www.namesys.com) [verbose messages deleted] Do you want to run this program?[N/Yes] (note need to type Yes if you do):Yes########### reiserfsck --check started at Sun Jun 26 21:54:58 2005 ########### Replaying journal.. Reiserfs journal '/dev/hda2' in blocks [18..8211]: 0 transactions replayed Checking internal tree.. Bad root block 0. (--rebuild-tree did not complete) AbortedIf the
reiserfsck–checkpartitioncommand fails, you need to rebuild the data structures that organize the filesystem tree by using thereiserfsck–rebuild-treepartitioncommand, as suggested. You will also want to specify the–Soption, which tells reiserfsck to scan the entire disk. This forces reiserfsck to do a complete rebuild, as opposed to trying to minimize its data structure updates. The following shows an example of using this command:# reiserfsck --rebuild-tree -S /dev/hda2reiserfsck 3.6.18 (2003 www.namesys.com) [verbose messages deleted] Do you want to run this program?[N/Yes] (note need to type Yes if you do): Yes Replaying journal.. Reiserfs journal '/dev/hda2' in blocks [18..8211]: 0 transactions replayed ########### reiserfsck --rebuild-tree started at Sun Jun 26 21:56:29 2005 ########### Pass 0: ####### Pass 0 ####### The whole partition (2048272 blocks) is to be scanned Skipping 8273 blocks (super block, journal, bitmaps) 2039999 blocks will be read 100% left 0, 9230 /sec 383 directory entries were hashed with "r5" hash. Selected hash ("r5") does not match to the hash set in the super block (not set). "r5" hash is selected Flushing..finished Read blocks (but not data blocks) 2039999 Leaves among those 2032 Objectids found 390 Pass 1 (will try to insert 2032 leaves): ####### Pass 1 ####### Looking for allocable blocks .. finished 100% left 0, 225 /sec Flushing..finished 2032 leaves read 1975 inserted 57 not inserted non-unique pointers in indirect items (zeroed) 444 ####### Pass 2 ####### Pass 2: 100% left 0, 0 /sec Flushing..finished Leaves inserted item by item 57 Pass 3 (semantic): ####### Pass 3 ######### Flushing..finished Files found: 359 Directories found: 25 Broken (of files/symlinks/others): 2 Pass 3a (looking for lost dir/files): ####### Pass 3a (lost+found pass) ######### Looking for lost directories: done 1, 1 /sec Looking for lost files: Flushing..finished Objects without names 4 Files linked to /lost+found 4 Pass 4 - finished Deleted unreachable items 23 Flushing..finished Syncing..finished ########### reiserfsck finished at Sun Jun 26 22:00:26 2005 ###########Once this command completes, try manually mounting the partition that you had problems with, as in the following example:
# mount -t reiserfs /dev/hda2 /mnt/restoreIf the mount completes successfully, check the lost+found directory for recovered files (their naming conventions are explained in the next section):
# ls -al /mnt/restore/lost+foundtotal 179355 drwx------ 2 root root 144 2005-06-26 20:44 . drwxr-xr-x 27 root root 1176 2005-06-26 20:24 .. -rw-r--r-- 1 root root 33745969 2005-06-26 20:24 350_355 -rw-r--r-- 1 root root 27046983 2005-06-26 20:24 350_356 -rw-r--r-- 1 root root 67049649 2005-06-26 20:24 350_357 -rw-r--r-- 1 root root 55630200 2005-06-26 20:24 350_358If you experienced problems with one partition on a drive and saw disk errors in the system log (/var/log/messages), you should also check the consistency of all other data partitions on the disk using reiserfsck or the consistency checker that is appropriate for any other type of filesystem you are using. You can list the partitions on the disk and their types using the
fdisk–lcommand, as in the following example:# fdisk -l /dev/hdaDisk /dev/hda: 60.0 GB, 60022480896 bytes 255 heads, 63 sectors/track, 7297 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Device Boot Start End Blocks Id System /dev/hda1 * 1 13 104391 83 Linux /dev/hda2 14 1033 8193150 83 Linux /dev/hda3 1034 1098 522112+ 82 Linux swap / Solaris /dev/hda4 1099 7297 49793467+ f W95 Ext'd (LBA) /dev/hda5 1099 2118 8193118+ 83 Linux /dev/hda6 2119 3138 8193118+ 83 Linux /dev/hda7 3139 4158 8193118+ 83 Linux /dev/hda8 4159 5178 8193118+ 83 Linux /dev/hda9 5179 6198 8193118+ 83 Linux /dev/hda10 6199 7218 8193118+ 83 Linux
Identifying Files and Directories in the ReiserFS lost+found
To explore a filesystem’s lost+found directory, you must first mount the filesystem, using the standard Linux mount command, which you must execute as the root user. When mounting ReiserFS filesystems, you must use the mount command’s –t reiserfs option to identify the filesystem as a ReiserFS filesystem and therefore mount it appropriately. Once the filesystem is mounted, cd to the lost+found directory at the root of that filesystem, which will be located in the directory where you mounted the filesystem. If this directory contains any files or directories, you’re in luck—there’s more data in your filesystem than just the standard files and directories it contains!
As with the lost+found directories used by other types of Linux filesystems, the entries in a ReiserFS lost+found directory are files and directories whose parent inodes or directories were damaged and discarded during the consistency check. You will have to do a bit of detective work to find out what these are, but two factors work in your favor:
The names of the files and directories in the lost+found directory for ReiserFS filesystems are based on the ReiserFS nodes associated with the lost files or directories and their parents and are in the form
NNN_NNN(parent_file/dir). Files and directories with the same numbers in the first portions of their names are usually associated with each other.The reiserfsck program simply re-links unconnected files and directories into the lost+found directory, which preserves the creation, access, and modification timestamps associated with those files and directories.
Aside from the different naming conventions used by the files in a ReiserFS lost+found directory, the process of identifying related files and directories is the same as that described in “Piece Together Data from the lost+found” [Hack #96] . See that hack for more information.
See Also
“Recover Lost Partitions” [Hack #93]
“Recover Data from Crashed Disks” [Hack #94]
“Recover Deleted Files” [Hack #97]
Piece Together Data from the lost+found
fsck and similar programs save lost or unlinked files and directories automatically. Here’s how to figure out what they are.
The fsck utility, created by Ted Kowalski and others at Bell Labs for ancient versions of Unix, removed much of the black magic from checking and correcting the consistency of Unix filesystems. No one wept many tears for the passing of fsck’s predecessors, icheck and ncheck, since fsck is far smarter and encapsulates a lot of knowledge about filesystem organization and repair. One of the coolest things that fsck brought to Unix filesystems was the notion of the lost+found directory at the root of a Unix filesystem. Though actually created by utilities associated with filesystem creation (newfs, mkfs, mklost+found, and so on, depending on the filesystem and version of Unix or Linux that you’re using), the lost+found directory is there expressly for the use of filesystem repair utilities such as fsck, e2fsck, xfs_repair, and so on.
The idea behind the lost+found directory was to preallocate a specific directory with a relatively large number of directory entries, to be used as an electronic catcher’s mitt for storing files and directories whose actual locations in the filesystem can’t be determined during a filesystem consistency check. When a utility such as fsck performs a full filesystem consistency check, its primary goal is to verify the integrity of the filesystem, which means that filesystem metadata such as lists of free and allocated blocks, inodes, or extents (typically stored as bitmaps) are correct, all files and directories in the filesystem are correctly linked into the filesystem, directory and file attributes are correct, and so on. Unfortunately, preserving corrupted data is a secondary concern during filesystem consistency checking and repair. Inconsistent files or directories are usually simply purged during a filesystem consistency check, but the contents of directories that are purged may still themselves be consistent. When this situation occurs during a filesystem consistency check, the contents of such directories are automatically linked to existing (empty) entries in that filesystem’s lost+found directory. On older Unix systems, the hard links to these “recovered” files and directories were given names corresponding to their inode numbers. On ext2 or ext3 Linux filesystems, the hard links to such files and directories are given names beginning with a hash mark (#) and followed by the inode number.
When you encounter a severely corrupted filesystem or recover one as part of a repair or recovery [Hack #94] , you will almost always find files and directories in that filesystem’s lost+found directory after fsck‘ing the filesystem. Here are some tips on how to figure out what they contain, what files and directories they may have been, and how to put them back into the actual filesystem.
Tip
This hack focuses on piecing things together for an ext2 or ext3 filesystem, but the procedure for identifying files and directories applies to other filesystems as well. For some ReiserFS-specific tips, see “Repair and Recover ReiserFS Filesystems” [Hack #95] .
Exploring the lost+found
To explore a filesystem’s lost+found directory, you must first mount the filesystem using the standard Linux mount command, which you must execute as the root user. Once the filesystem is mounted, cd to the lost+found directory at the root of that filesystem, which will be located in the directory where you mounted the filesystem. If this directory contains any files or directories, you’re in luck—there’s more data in your filesystem than just the standard files and directories it contains!
The entries in the lost+found directory are files and directories whose parent inodes or directories were damaged and discarded during the consistency check. You will have to do a bit of detective work to find out what these are, but two factors work in your favor:
The names of the files and directories in the lost+found directory for an ext2/ext3 filesystem are based on the numbers of the inodes associated with the lost files or directories.
The e2fsck program simply re-links unconnected files and directories into the lost+found directory, which preserves the creation, access, and modification timestamps associated with those files and directories.
The first thing to do when exploring an ext2 or ext3 lost+found directory is to prepare an area on another disk to which you can temporarily copy files and directories as you attempt to reconstruct their organization. In this hack, I’ll use the example /usr/restore, but you can use any location. As you proceed with exploration and reconstruction, it is important not to modify the files in the lost+found directory in any way other than by copying them elsewhere, or you may lose helpful timestamp information.
Just to be safe, first redirect a long directory listing of the contents of the lost+found directory into a file in your restore area, as in the following example:
# cd /mnt/baddisk
# ls–lt > /usr/restore/listing.txtThis listing is a precaution against accidental modification of those files. Here’s a section of the sample output from the lost+found directory from “Recover Lost Partitions” [Hack #93] :
# ls -lt
total 2116264
drwx------3 root root 16384 2005-06-17 18:14 .
drwxr-xr-x 6 root root 4096 2005-06-17 18:14 ..
-rw-r--r--1 wvh users 48873341 2005-02-12 08:41 #11993089
-rw-r--r--1 wvh users 26737789 2005-02-12 08:41 #11993090
-rw-r--r--1 wvh users 27987253 2005-02-12 08:41 #11993091
-rw-r--r--1 wvh users 24691821 2005-02-12 08:41 #11993092
-rw-r--r--1 wvh users 25752913 2005-02-12 08:41 #11993093
-rw-r--r--1 wvh users 15258373 2005-02-12 08:41 #11993094
-rw-r--r--1 wvh users 16291065 2005-02-12 08:41 #11993095
-rw-r--r--1 wvh users 25151049 2005-02-12 08:41 #11993096
-rw-r--r--1 wvh users 27290257 2005-02-12 08:41 #11993097
-rw-r--r--1 wvh users 31643 2005-02-12 08:41 #11993098
-rw-r--r--1 wvh users 2751 2005-02-12 08:41 #11993099
-rw-r--r--1 wvh users 2670 2005-02-12 08:41 #11993100
-rw-r--r--1 wvh users 35270097 2005-01-28 05:29 #14811137
-rw-r--r--1 wvh users 39914258 2005-01-28 05:29 #14811138
-rw-r--r--1 wvh users 39709879 2005-01-28 05:30 #14811139
-rw-r--r--1 wvh users 58648049 2005-01-28 05:30 #14811140
-rw-r--r--1 wvh users 29533858 2005-01-28 05:30 #14811141
-rw-r--r--1 wvh users 27692066 2005-01-28 05:30 #14811142
-rw-r--r--1 wvh users 29308352 2005-01-28 05:30 #14811143
-rw-r--r--1 wvh users 564 2005-01-28 05:30 #14811144
-rw-r--r--1 wvh users 809 2005-01-28 05:30 #14811145
-rw-r--r--1 wvh users 156 2005-01-28 05:30 #14811146
drwxr-xr-x 2 lmp users 4096 2005-01-22 21:46 #30507055
drwxr-xr-x 2 lmp users 4096 2005-01-22 21:45 #30507031
-rw-r--r--1 wvh users 29523256 2005-01-18 05:21 #3063821
[much more output removed]As you can see from this example, the files and directories in my lost+found directory are nicely grouped by date and inode number, and many of them were last modified on the same date. This is typical of partitions that are essentially written to once and then used as a source of data. In this case, the partition I lost was a repository for an online music collection for my server’s users, consisting of audio files and associated files such as playlists and recording descriptions, so I have a good idea of how the files and directories were originally organized on the disk that went bad. The disk consisted of directories named by artist and date, each of which contained the recordings and associated files for the artist’s performance on that date.
Recovering Directories from the lost+found
The first thing to do when exploring and recovering the contents of a lost+found directory is to copy out any directories that already contain related sets of files. You can then explore the contents of these directories at your leisure, putting the recovered files back into a live filesystem on your machine.
As you can see from the previous code listing, my lost+found directory contains two directories, #30507055 and #30507031. Listing both of these shows the following:
# ls -l #30507055 #30507031
#30507031:
total 0
#30507055:
total 222380
-rw-r--r-- 1 lmp users 915 2005-01-22 21:45 monroe1967-05-15d2.ffp.txt
-rw-r--r-- 1 lmp users 11694266 2005-01-22 21:45 monroe1967-05-15d2t01.flac
-rw-r--r-- 1 lmp users 14046056 2005-01-22 21:45 monroe1967-05-15d2t02.flac
-rw-r--r-- 1 lmp users 21405678 2005-01-22 21:45 monroe1967-05-15d2t03.flac
-rw-r--r-- 1 lmp users 10724376 2005-01-22 21:45 monroe1967-05-15d2t04.flac
-rw-r--r-- 1 lmp users 19590818 2005-01-22 21:45 monroe1967-05-15d2t05.flac
-rw-r--r-- 1 lmp users 13981201 2005-01-22 21:45 monroe1967-05-15d2t06.flac
-rw-r--r-- 1 lmp users 13576225 2005-01-22 21:45 monroe1967-05-15d2t07.flac
-rw-1r--r-- 1 lmp users 12057959 2005-01-22 21:45 monroe1967-05-15d2t08.flac
-rw-r--r-- 1 lmp users 15432553 2005-01-22 21:45 monroe1967-05-15d2t09.flac
-rw-r--r-- 1 lmp users 19475592 2005-01-22 21:46 monroe1967-05-15d2t10.flac
-rw-r--r-- 1 lmp users 13427860 2005-01-22 21:46 monroe1967-05-15d2t11.flac
-rw-r--r-- 1 lmp users 16973390 2005-01-22 21:46 monroe1967-05-15d2t12.flac
-rw-r--r-- 1 lmp users 12077969 2005-01-22 21:46 monroe1967-05-15d2t13.flac
-rw-r--r-- 1 lmp users 26182260 2005-01-22 21:46 monroe1967-05-15d2t14.flac
-rw-r--r-- 1 lmp users 6718719 2005-01-22 21:46 monroe1967-05-15d2t15.flac
-rw-r--r-- 1 lmp users 405 2005-01-22 21:46 playlist.m3uThe directory #30507031 is empty and can safely be ignored, but the directory #30507055 seems to contain an intact collection of related files. Based on the filenames, I know that this is a live performance by the bluegrass artist Bill Monroe from May 15, 1967, and that it was created by the user lmp. (By the way, you will rarely be this lucky!) To preserve this directory, I’ll recursively copy it to my restore area, giving it an appropriate name:
# cp–rp #30507055 /usr/restore/monroe1967-05-15Note the use of the cp command’s –p option, to preserve user and group ownership and timestamps.
If I can’t easily identify the contents of a directory in the lost+found, I generally copy it to my restore area, giving it a name based on the directory’s timestamp. The inode number in the old filesystem is meaningless after a copy, but a visual clue for knowing when the directory was last updated may be useful when trying to figure out what it contains, especially if a project or system user or group owns the directory.
Recovering Recognizable Groups of Files
When recovering files that are essentially preorganized by their creation dates, I usually create recovery directories in my restore area based on the timestamps and use this as a preliminary organizer when copying the files there. The previous code listing shows two groups of files, one created on Feb12, 2005 (2005-02-12) and another created on January 28, 2005 (2005-01-28). I would thus create two corresponding directories and use wildcards to copy the associated files into those directories, as in the following example:
# mkdir /usr/restore/2005-02-12 /usr/restore/2005-01-28
# cp–p #11993??? /usr/restore/2005-02-12
# cp–p #148111?? /usr/restore/2005-01-28Next, let’s try to figure out what each of these directories actually contains. Change directory to one of the restore directories and examine its contents using the file command:
# cd /usr/restore/2005-02-12
# file *
#11993089: data
#11993090: data
#11993091: data
#11993092: data
#11993093: data
#11993094: data
#11993095: data
#11993096: data
#11993097: data
#11993098: JPEG image data, JFIF standard 1.01
#11993099: ASCII English text, with CRLF line terminators
#11993100: ASCII text, with CRLF line terminators
#11993101: ASCII English textLooking at the text files in any directory usually provides some information about the contents of that directory. Let’s use the head command to examine the first 10 lines of each of the text files:
$ head *99 *100 *101
==> #11993099 <==
EAC extraction logfile from 8. February 2005, 23:22 for CD
Cheap Trick 1981-01-22d1t / Unknown Title
Used drive : HP DVD Writer 300n Adapter: 1 ID: 1
Read mode : Burst
Read offset correction : 0
Overread into Lead-In and Lead-Out : No
Used output format : Internal WAV Routines
44.100 Hz; 16 Bit; Stereo
==> #11993100 <==
EAC extraction logfile from 8. February 2005, 23:49 for CD
Cheap Trick 1981-01-22d2t / Unknown Title
Used drive : HP DVD Writer 300n Adapter: 1 ID: 1
Read mode : Burst
Read offset correction : 0
Overread into Lead-In and Lead-Out : No
Used output format : Internal WAV Routines
44.100 Hz; 16 Bit; Stereo
==> #11993101 <==
1981-01-22d1t01 Stop This Game.shn
1981-01-22d1t02 Go For The Throat (Use Your Own Imagination).shn
1981-01-22d1t03 Hello There.shn
1981-01-22d1t04 I Want You To Want Me.shn
1981-01-22d1t05 I Love You Honey But I Hate Your Friends.shn
1981-01-22d1t06 Clock Strikes Ten.shn
1981-01-22d1t07 Can't Stop It But I'm Gonna Try.shn
1981-01-22d1t08 Baby Loves To Rock And Roll.shn
1981-01-22d1t09 Gonna Raise Hell.shn
1981-01-22d2t01 Heaven Tonight.shnThis tells me that the first two files contain logfiles produced when ripping audio from the CDs that originally contained these live recordings, while the last (#11993101) contains a playlist for the files in the original directory. Let’s see if looking at more of one of the logfiles can tell us more about the files in this directory:
$ head -20 *99
EAC extraction logfile from 8. February 2005, 23:22 for CD
Cheap Trick 1981-01-22d1t / Unknown Title
Used drive : HP DVD Writer 300n Adapter: 1 ID: 1
Read mode : Burst
Read offset correction : 0
Overread into Lead-In and Lead-Out : No
Used output format : Internal WAV Routines
44.100 Hz; 16 Bit; Stereo
Other options :
Fill up missing offset samples with silence : Yes
Delete leading and trailing silent blocks : No
Installed external ASPI interface
Track 1
Filename G:Cheap TrickCheap Trick 1981-01-22 Dallas, Tx(Reunion Arena)
1981-01-22d1t01 Stop This Game.wavHooray! This appears to be a live concert by the band Cheap Trick from January 22, 1981, recorded in Dallas. Let’s verify that one of the files reported as data actually contains consistent data that is in the lossless Shorten (SHN) format, as listed in the playlist file. We can do this using the shninfo command, which is part of the Linux Shorten command suite:
# shninfo *11993089
----------------------------------------------------------------------------
---
file name: #11993089
handled by: shn format module
length: 8:19.10
WAVE format: 0x0001 (Microsoft PCM)
channels: 2
bits/sample: 16
samples/sec: 44100
average bytes/sec: 176400
rate (calculated): 176400
block align: 4
header size: 44 bytes
data size: 88047120 bytes
chunk size: 88047156 bytes
total size (chunk size + 8): 88047164 bytes
actual file size: 48873341 (compressed)
compression ratio: 0.5551
CD-quality properties:
CD quality: yes
cut on sector boundary: yes
long enough to be burned: yes
WAVE properties:
non-canonical header: no
extra RIFF chunks: no
Possible problems:
inconsistent header: no
file probably truncated: n/a
junk appended to file: n/a
Extra shn-specific info:
seekable: noAnother success! Unfortunately, there’s no way to verify which of the recovered files is which of the files listed in the playlist, but let’s see if we got all of the Shorten files that were in the original directory. We can do this in a number of ways, but the easiest is to count the number of lines in the playlist file and compare this number against the number of files in the recovered directory:
$ wc -l *10118 #11993101$ $ ls -l | wc -l14
Unfortunately, this shows that the playlist file contains 18 entries, while there are only 14 files in the recovered directory, 3 of which are text files and 1 of which is a JPEG file. This means that we only recovered 10 of the files containing music in the original directory: the others apparently were located on disk blocks that had gone bad on the original disk or were otherwise inconsistent. Oh well—10 is definitely better than 0!
To complete the recovery process for this directory, I would rename the directory with something more meaningful than its creation date (perhaps cheaptrick1981-22-01_dallas) and then play the Shorten files one by one, renaming them once I recognized them.
Examining Individual Files
The end of the listing of our lost+found directory at the beginning of this hack showed one file, #3063821, that was not accompanied by files with similar inode numbers or timestamps. This means either that the file is the only one that could be recovered from a damaged directory, or that the file was located at the top level of the recovered filesystem but could not be relinked into the filesystem correctly.
Examining individual files in a lost+found directory is similar to examining a group of files. First, use the file command to try to figure out the type of data contained in the file, as in the following example:
# file #3063821
#3063821: FLAC audio bitstream data, 16 bit, stereo, 44.1 kHz, 11665332
samplesDepending on the type of data contained in the file, you can use utilities associated with that file type to attempt to get more information about its contents. For text files, you can simply use utilities such as cat or more. For binary files in a nonspecific format, you can either make an educated guess based on the type of files that you know were stored on the filesystem, or you can use generic utilities such as strings to search for text strings in the binary file that may give you a clue to its identity. In this case, the file is a lossless FLAC audio file, so we can use the metaflac command’s –list and –block-number options to examine the comments in the FLAC header that are stored in block number 2, and see if we can get any useful information:
# metaflac --list #3063821–block-number=2
METADATA block #2
type: 4 (VORBIS_COMMENT)
is last: false
length: 254
vendor string: reference libFLAC 1.1.0 20030126
comments: 8
comment[0]: REPLAYGAIN_TRACK_PEAK=0.64492798
comment[1]: REPLAYGAIN_TRACK_GAIN=-5.84 dB
comment[2]: REPLAYGAIN_ALBUM_PEAK=0.98718262
comment[3]: REPLAYGAIN_ALBUM_GAIN=-4.77 dB
comment[4]: ALBUM=Old Waldorf SF
comment[5]: ARTIST=Pere Ubu
comment[6]: DATE=79
comment[7]: GENRE=AvantgardeI am indeed lucky! The creator of this file was thoughtful enough to include comments, which identify this file as a recording by Pere Ubu, created in 1979 at the Old Waldorf in San Francisco. Unfortunately, the title isn’t listed, but I can now play the file using flac123 in the hopes of identifying it so that I can copy it to the /usr/restore area with a meaningful filename.
Summary
The examples provided in this hack show a variety ways of examining and reorganizing files that were saved by the e2fsck program in a filesystem’s lost+found directory. I was quite lucky in these examples (modulo the fact that I had filesystem consistency problems in the first place), since the disk that had problems contained a large number of sets of files that were for the most part organized in a specific way. However, you can use these same techniques to examine the contents of any lost+found directory—and even if you’ve lost many files and directories, remember that recovering anything is always much better than losing everything.
See Also
“Recover Lost Partitions” [Hack #93]
“Recover Data from Crashed Disks” [Hack #94]
“Recover Deleted Files” [Hack #97]
Recover Deleted Files
Deleting a file doesn’t make it lost forever. Here’s a quick method for finding deleted text files.
Sooner or later everyone has an “oh no second” when they realize that they’ve just deleted a critical file. The best feature of old Windows and DOS boxes was that they used a simplistic File Allocation Table (FAT) filesystem that made it easy to recover deleted files. Files could easily be recovered because they weren’t immediately deleted: deleting a file just marked its entries as unused in the file allocation table; the blocks that contained the file data might not be reused until much later. Zillions of utilities were available to undelete files by reactivating their FAT entries.
Linux filesystems are significantly more sophisticated than FAT filesystems, which has the unfortunate side effect of complicating the recovery of deleted files. When you delete a file, the blocks associated with that file are immediately returned to the free list, which is a bitmap maintained by each filesystem that shows blocks that are available for allocation to new or expanded files. Luckily, the fact that any Linux/Unix device can be accessed as a stream of characters gives you the chance to recover deleted files using standard Linux/Unix utilities—but only if you act quickly!
This hack focuses on explaining how to recover lost text files from partitions on your hard drive. Text files are the easiest type of file to recover, because you can use standard Linux/Unix utilities to search for sequences of characters that you know appear in the deleted files. In theory, you can attempt to undelete any file from a Linux partition, but you have to be able to uniquely describe what you’re looking for.
Preventing Additional Changes to the Partition
As quickly as possible after discovery that a critical file has been deleted, you should unmount the partition on which the file was located. (If you don’t think anyone is actually using that partition but you can’t unmount it, read “Find Out Why You Can’t Unmount a Partition” [Hack #92] .)
In some cases, such as partitions that are actively being used by the system or are shared by multiple users, this will require that you take the system down to single-user mode and unmount the partition at that point. The easiest way to do this is cleanly is with the shutdown command, as in the following example:
# shutdown now "Going to single-user mode to search for deleted files…"Of course, it would be kindest to your users to give them more warning, but your chances of recovering the deleted file decrease with every second that the system is running and users or the system can create files on the partition that holds your deleted file. Once the system is in single-user mode, unmount the partition containing the deleted file as quickly as possible. You’re now ready to begin your detective work.
Looking for the Missing Data
The standard Linux/Unix grep utility is your best friend when searching for a deleted text file on an existing disk partition. After figuring out a text string that you know is in the deleted file, execute a command like the following, and then go out for a cup of coffee while it runs—depending on the size of the partition you’re searching, this can take quite a while:
# grep–a–B10–A100–i fibonacci /dev/hda2 > fibonacci.outIn this case, I’m searching for the string “fibonacci” in the filesystem on /dev/hda2, because I accidentally deleted some sample code that I was writing for another book. As in this example, you’ll want to redirect the output of the grep command into a file, because it will be easier to edit. Also, because of the amount of preceding and trailing data that is actually incredibly long lines of binary characters, you will need to have several megabytes free on the partition where you are running the command.
The options I’ve used in my grep command are the following:
-a Treats the device that you’re searching as a series of ASCII characters. |
-B
N Saves N lines before the line that matches the string that you’re looking for. In this case, I’m saving 10 lines before the string “fibonacci.” |
-A
N Saves N lines after the line that matches the string you’re looking for. In this case, I’m saving 100 lines after the string “fibonacci” (this was a short code example). |
-i Searches for the target string without regard to whether any of the characters in the string are in upper- or lowercase. |
After the command finishes, start your favorite text editor to edit the output file (fibonacci.out, in our example) to remove preceding and trailing data that you don’t want, as shown in Figure 10-3. Some such data will almost certainly be present.
When the time it takes to edit and clean up the recovered file is weighed against the time needed to recreate the deleted file, you’ll usually find it’s worth the effort to attempt recovery. Once you’re satisfied that you have recovered your file, you can remount the partition where it was formerly located and make the system available to users again—and be more careful next time!
See Also
“Recover Lost Partitions” [Hack #93]
“Recover Data from Crashed Disks” [Hack #94]
“Repair and Recover ReiserFS Filesystems” [Hack #95]
“Recover Lost Files and Perform Forensic Analysis” [Hack #100]
Permanently Delete Files
Deleting a file typically just makes it harder to find, not impossible. Using a simple utility to write over files that you delete can help ensure that your data is gone for good.
We all store personal, secret, or potentially embarrassing data on our machines at one time or another. Whether it’s last year’s tax returns, instructions to your bank in the Cayman Islands, or a risque picture of your husband or wife, everybody has some data that they don’t want anyone else to see, and no one keeps their computers forever. What do you do with your old machines? In business environments, they often simply get passed down the user food chain until they die. Are they wiped clean before each transfer? Rarely.
As we all know from the various Windows utilities that have been around for years to enable you to recover files (and from “Recover Deleted Files” [Hack #97] and “Recover Lost Files and Perform Forensic Analysis” [Hack #100] ), just because you’ve deleted a file doesn’t mean that it’s actually gone from your disk. There’s a good chance that the data blocks associated with any deleted file are still present on your disk for quite a while, and could be recovered by someone who was desperate or persistent enough.
You probably won’t be surprised to hear that Linux, the OS of a thousand utilities, provides an out-of-the-box solution for truly deleting files. To recover a deleted file, you must reassemble the file, either by walking through the free list or by looking for the data that the file contained. The Linux shred utility makes files unrecoverable by overwriting all of their data blocks with random data patterns, meaning that even if you can piece a deleted file back together, its contents will be random garbage. The shred utility is part of the Linux coreutils package (the same package that brings you popular utilities such as ls, pwd, cp, and mv, which means that it is found at /usr/bin/shred on almost every desktop Linux distribution.
Using the shred Utility
Using the shred utility to overwrite the contents of an existing file with random junk is easy. As an example, my online banking service enables me to download information about banking transactions in Quicken Interchange Format (QIF), which gnucash can import into my personal copy of my banking records. A snippet of one of these files looks like the following:
!Type:Bank D10/08/2004 PWIRE TRANSFER FEE N T-11.00 ^ D10/07/2004 PPAYPAL INST XFER N T-217.20 ^ D10/07/2004 PNAT CITY ATM CASH WITHDRAWAL N T-240.00 ^ D10/06/2004 PGIANT EAGLE IN, VERONA,PA N T-11.76
Assuming that I have a copy of one of these files (named, say, EXPORT-11-oct-2004.QIF) on my laptop from work, I’d really like to make sure that this data is wiped when I trade up to a newer machine and my old laptop goes to someone else. Rather than actually wiping the entire hard drive [Hack #99] , I could simply use shred to overwrite and randomize this file, using the following command:
$ shred -n 3 -vz EXPORT-11-oct-2004.QIF
The output from this command looks like the following:
shred: EXPORT-11-oct-2004.QIF: pass 1/4 (random)…
shred: EXPORT-11-oct-2004.QIF: pass 2/4 (random)…
shred: EXPORT-11-oct-2004.QIF: pass 3/4 (random)…
shred: EXPORT-11-oct-2004.QIF: pass 4/4 (000000)…The options I’ve passed to the shred command cause it to overwrite the file with three passes of random data (-n 3), be verbose (v), and write a final pass of zeros over the file after completing the random overwrite passes (z). If you don’t specify the number of overwrite passes to perform, shred’s default behavior is to overwrite the file 25 times, which should be random enough for just about anyone.
Once this command has completed, let’s look at the file again:
$ cat -v EXPORT-11-oct-2004.QIF | more
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
[much more similar data deleted]As you can see, the contents of this file are gone.
In most cases, when shredding a file you would also use the -u option to tell shred to automatically truncate and delete the file after overwriting it, but I didn’t use that option here so that I could demonstrate that the contents of the file are actually gone. One very cool thing about using shred is that it overwrites the file in place, so you’re pretty much guaranteed that the contents of the file are irretrievably gone. Gee, I hope I imported that file into gnucash, now that I think about it….
See Also
man shred
Permanently Erase Hard Disks
Before discarding old hardware, make sure you’re not accidentally giving away proprietary or personal data.
Most government agencies—certainly the ones with three-letter names—have extremely stringent requirements for wiping hard drives before they discard old computing equipment. These requirements usually also extend to any contractors who have done work for them. Some security requirements are so stringent that disks must be destroyed, rather than simply erased, before the hardware can be discarded. The quickest and easiest way to do this (and the mechanism preferred by more militant sysadmins) is to take the disks in question to the local shooting gallery (guns, that is) and put a few rounds through them. For information on how to totally disable a disk using this mechanism, check out a recent copy of Field & Stream. However, if you prefer to erase a disk using software, read on.
Tip
Lest you think that finding embarrassing data on hard drives is simply anecdotal, I have some good experience with this myself. I collect old workstations, and I once bought an ancient, still-working Tektronix Unix system that I managed to hack into since I didn’t have the install media for uTek. Once in, I did a bit of exploring and found that the system had apparently last been used as a node in a Bondage and Domination BBS. Now that was some interesting (and scary) mail!
Using shred to Wipe Hard Drives
“Permanently Delete Files” [Hack #98] introduced the shred utility, which is designed to overwrite the contents of specified files on a Linux system with random data. Thanks to the approach that Linux and Unix take to devices (“everything is a file”), you can also use shred to wipe a hard drive by specifying the base name of the drive as the name of the target file, as in the following example:
# shred -n 3 -vz /dev/>drive-name
On most Linux systems, the first IDE hard drive is /dev/hda, the first SCSI disk is /dev/sda, the second IDE disk is /dev/hdb, and so on. The command to wipe a primary IDE disk would therefore be:
# shred -n 3 -vz /dev/hdaIf you’re using shred to randomize the contents of one or more hard drives, you’ll have to repeat your favorite shred command, specifying each drive as an argument. You can also let shred do its default 25 passes by excluding the -n 3 option on the command line, but this will take a really long time when wiping an entire hard drive. (If you have a very large disk, shred could conceivably still be running when the next edition of this book comes out!)
You’ll have to be logged in as root in order to access the device directly, and you must also have booted from a disk other than the one you want to wipe. Because shred is part of the standard coreutils package, it is found on most rescue disks, in CD-based Linux distributions such as Knoppix, and in the Rescue Mode boot option for most Linux distributions.
Using Darik’s Boot and Nuke
Another option when you want to completely erase a hard drive is to use a specialized boot floppy or CD that’s designed for only that purpose. Darik’s Boot and Nuke (DBAN) application (http://dban.sourceforge.net) is delivered in exactly that fashion and also supports an automated search-and-destroy mode that seeks out every hard drive in your system and does an extremely thorough job of overwriting the disks with random data. Because DBAN is delivered as a boot disk and is designed to wipe disks (and only wipe disks), you should consider it to be the sysadmin’s equivalent of a loaded gun. Be careful! Luckily, booting a system from a DBAN boot floppy or CD displays the screen shown in Figure 10-4, rather than simply beginning its search and destroy mission.
DBAN is provided as part of the System Rescue CD (http://www.sysresccd.org), but it must be started manually in that case. DBAN supports wiping IDE, SCSI, and SATA drives, and it even provides a variety of approaches to wiping your disks, as shown in Figure 10-5. To see this screen in DBAN, press F3 at the boot prompt. To select a specific wipe method, enter its name and press Return.
DBAN is widely used by government agencies with stringent security requirements, such as the Department of Energy and the National Nuclear Security Agency. For once, “good enough for government work” is a positive comment! DBAN can be your software hammer if you want to permanently erase a drive without physically beating it to death or shooting it. No software solution can beat physical destruction, and truly desperate people might still be able to recover something from a disk that was wiped with DBAN, but it’s unlikely that the eBay purchaser of one of your old systems is going to spend the five- or six-figure dollar amount required to do so.
Summary
Wiping disks is always a good idea when you take a machine out of circulation, sell it, or recycle it. Make sure you do backups of anything you want to save first, of course! DBAN is my preferred solution for wiping disks, but make sure that you label the CD carefully and then hide it just in case some of your more curious offspring or friends decide to use it as a boot disk and press Return at its boot prompt. Tools such as DBAN and shred will do a great job of making sure that only the most compulsive and wealthy randoms could even hope to resurrect any potentially embarrassing data from your old systems.
See Also
“Permanently Delete Files” [Hack #98]
Recover Lost Files and Perform Forensic Analysis
The Sleuth Kit and Autopsy are designed for computer forensics, but they also provide a great suite of tools for helping you recover lost data.
Most people know forensics—the application of domain knowledge to legal questions—best from television shows like Quincy (for old people and TV Land fans) or CSI (for younger people). Computer Forensics, a science that’s growing for a variety of reasons, tries to answer questions like “what the heck happened to my system?” “who hacked in here and what did they change?” and “how did my accountant get all my corporate funds into his Swiss bank account without my noticing?” Even if you don’t have one of these specific problems, it’s a downright interesting field. What self-respecting computer geek wouldn’t like the opportunity to legally burst in somewhere, seize or clone disk drives, do his best to hack in and examine them, and get paid for it, too?
All fun aside, forensic analysis of computer data can save your company’s data or bacon (or perhaps both) in court, as well as helping law enforcement officials track down the crackers and thieves who give real hackers a bad name. This hack provides an overview of The Sleuth Kit, the best-known open source software package for computer forensics, and Autopsy, which provides a web-based, graphical frontend to The Sleuth Kit and integrated support for other security and consistency-checking software. The Sleuth Kit (TSK) is based on an earlier collection of forensics tools known as The Coroner’s Toolkit (TCT), which is available at http://www.porcupine.org/forensics/tct.html. The Sleuth Kit runs on Linux/Unix systems and can recover files and analyze data from NTFS, FAT, ext2, ext3, UFS1, and UFS2 filesystems.
Walking you through a complete forensic recovery session would require its own book, so the HOWTO portions of this hack will simply explain how to build and install both packages and how to use some of the tools in The Sleuth Kit to recover lost files more easily than you can with the mechanisms discussed in “Recover Deleted Files” [Hack #97] .
Building and Installing The Sleuth Kit
The Sleuth Kit and the associated Autopsy package are not provided by default with most Linux distributions, but they’re easy enough to build and install. If you’re building The Sleuth Kit and Autopsy yourself for installation on your primary system, you can download the latest version of The Sleuth Kit from http://www.sleuthkit.org/sleuthkit/download.php and the latest version of Autopsy from http://www.sleuthkit.org/autopsy/download.php.
Tip
One of the key concepts of forensic software is, of course, that you need to be able to run it from a safe, secure environment in order to analyze disks (or disk images) from other systems, so one of the best ways to get and use The Sleuth Kit and Autopsy is to get a bootable CD with these packages installed. My personal favorites are the Penguin Sleuth Kit (http://www.linuxforensics.com/downloads.html), the F.I.R.E. (Forensic and Incident Response Environment) CD (http://fire.dmzs.com), and, for BSD fans, the Snarl Bootable Forensics CD (https://sourceforge.net/projects/snarl/). Each of the CDs includes The Sleuth Kit and a variety of other forensics-related software.
You should always build and install The Sleuth Kit before building and installing Autopsy, because Autopsy’s configuration process will ask you for the location of the installed TSK. The downloadable TSK source is provided as a gzipped tar file. To extract its contents and build the software (using Version 2.02 as an example, which was the current version when this book was written), do the following:
$ tar zxvf sleuthkit-2.02.tar.gz
$ cd sleuthkit-2.02
$ makeThe Sleuth Kit does not offer an install option, so I generally build it in /usr/local/src and then use sudo or become root to create a symbolic link from /usr/local/sleuthkit to /usr/local/src/sleuthkit-version. I then add /usr/local/sleuthkit/bin to my path, and I’m good to go.
Building and Installing Autopsy and Related Software
The source code for Autopsy is also provided as a downloadable, gzipped tar file. You really only need to install Autopsy if you’re interested in forensic analysis. If you’re only interested in recovering files using The Sleuth Kit, that’s most easily done from the command line (as of the time this book was written—things may have changed by the time you read this).
As mentioned earlier, Autopsy also integrates some other forensics software with the core capabilities provided by The Sleuth Kit—namely, a Reference Data Set (RDS) consisting of the digital signatures of known, traceable software applications, which includes hash values for many common hacking scripts and can thus be very useful when trying to determine how a system was hacked. These digital signatures are available from the National Software Reference Library (NSRL), a National Institute of Science and Technology (NIST) project, at the download page http://www.nsrl.nist.gov/Downloads.htm. This page provides ISO images of four CDs, each of which provides signatures for a class of software:
ISO 1 contains the signatures of non-English software.
ISO 2 contains the signatures of common operating systems.
ISO 3 contains the signatures of a huge amount of application software.
ISO 4 contains the signatures of standard image and graphics files and formats.
These signatures are contained in the file NSRLFile.txt, which is itself contained in a ZIP file in each of the ISO images. You can produce one true signature file by downloading all of the ISOs, mounting them, and concatenating together all of the resulting files. You’ll need 8 GB of free space when you’re doing this, because the complete concatenated file is 4 GB in size! The following example uses RDS 2.9 as an example, which was the current version when this book was written. After creating the directory /usr/local/nsrl, do the following for each of the ISOs:
# mount -o loop RDS_29[ABCD].iso /mnt# unzip /mnt/rds_29[abcd].zip NSRLfile.txt # mv NSRLFile.txt NSRLFile.txt.[ABCD] # umount /mnt
You can then concatenate them using the following command:
$ cat NSRLFile.txt.A NSRLFile.txt.B NSRLFile.txt.C NSRLFile.txt.D >
NSRLFile.txtYou should then punt all of the NSRLFile.txt.X files, because you no longer need the individual versions.
You’re now ready to build and install Autopsy. To extract the Autopsy source code and build the software (using Version 2.05 as an example, which was the current version when this book was written), do the following:
$ tar zxvf autopsy-2.05.tar.gz
$ cd autopsy-2.05
$ make
Autopsy Forensic Browser Installation
perl found: /usr/bin/perl
---------------------------------------------------------------
Autopsy uses the grep utility from your local system.
grep found: /usr/bin/grep
---------------------------------------------------------------
Autopsy uses forensic tools from The Sleuth Kit.
http://www.sleuthkit.org/sleuthkit/
Enter the directory where you installed it:
/usr/local/sleuthkit
Sleuth Kit bin directory was found
Version 2.02 found
Required version found
---------------------------------------------------------------
The NIST National Software Reference Library (NSRL) contains
hash values of known good and bad files.
http://www.nsrl.nist.gov
Have you purchased or downloaded a copy of the NSRL (y/n) [n] y Enter the
directory where you installed it:
/usr/local/nsrl
NSRL database was found (NSRLFile.txt)
---------------------------------------------------------------
Autopsy saves configuration files, audit logs, and output to the
Evidence Locker directory.
Enter the directory that you want to use for the Evidence Locker:
/usr/local/evidence_locker
/usr/local/evidence_locker already exists
---------------------------------------------------------------
Settings saved to conf.pl.
Execute the './autopsy' command to start with default settings.You can then run the autopsy command via sudo or as the root user, because it needs root privileges in order to mount disk images, write to the evidence locker directory (unless you’ve set its ownership so that normal users can write there), and so on:
# ./autopsy
============================================================================
Autopsy Forensic Browser
http://www.sleuthkit.org/autopsy/
ver 2.05
============================================================================
Evidence Locker: /usr/local/evidence_locker
Start Time: Sun Sep 11 16:57:23 2005
Remote Host: localhost
Local Port: 9999
Open an HTML browser on the remote host and paste this URL in it:
http://localhost:9999/autopsy
Keep this process running and use <ctrl-c> to exitTo begin using Autopsy, simply connect to the specified URL using a web browser. As mentioned earlier, stepping through a complete forensic recovery session using Autopsy could easily require its own book, but Autopsy is quite user-friendly in terms of walking you through each step of creating a unique directory (referred to as a “case”) to hold the results of the forensic examination of a specific disk, disk image, or set of multiple disks or images. I’ve found Autopsy to be quite useful for identifying deleted files, such as those shown in Figure 10-6.
Using The Sleuth Kit to Recover Deleted Files
The extent to which you can recover files using The Sleuth Kit (and therefore Autopsy) is completely dependent on the characteristics of the type of filesystem used on each disk or disk image that you’re examining. ext2 and ext3 filesystems zero out inodes when the files associated with them are deleted, but the applications provided in The Sleuth Kit can simplify recovering any type of file whose contents you can uniquely identify. This can be problematic when trying to recover binaries, but it’s great for text files.
The Sleuth Kit can analyze disks or disk images. To copy an existing partition or disk to a file for forensic analysis, run a command like the following via sudo or as the root user:
# dd if=/dev/disk-or-partition bs=1024 of=name-of-image-file conv=noerrorOnce you have an image of the partition that contains the data you want to recover, make sure that /usr/local/sleuthkit/bin is in your path, and follow the steps below to recover deleted text files. I’ll look for the /etc/passwd file in the sample image file hd5_image_etc_files_deleted.img. This is a clone of my system’s root disk, in which I’ve deleted every text file in /etc. (Good thing I only did that as an example!)
Looking for a deleted text file requires the following steps:
Use TSK’s
dlscommand to extract all of the unallocated space from the disk image into a single file, which expedites the process of searching for the file that you’ve deleted:$ dls hd5_image_etc_files_deleted.img > dls_output.dlsNext, use the standard
stringscommand to search for all text strings in the output file produced by the previous step, and write that information to a file:$ strings -t d dls_output.dls > dls_output.dls.strUse grep to search for a string that identifies the file you’re looking for as uniquely as possible. I’ll search for the string :0:0:, which shouldn’t appear in too many files other than the /etc/passwd file:
$ grep ":0:0:" dls_output.dls.str130746025 (scsi0:0:0:0) 130998233 if ( !strncmp( line, "PSPCAM", 6 ) )root:x:0:0:root:/root:/bin/bash 131698688 root:x:0:0:root:/root:/bin/bash 150589440 root:x:0:0:root:/root:/bin/bash 156106752 root:x:0:0:root:/root:/bin/bash 176209920 root:x:0:0:root:/root:/bin/bash 182677504 root:x:0:0:root:/root:/bin/bash 187670528 root:x:0:0:root:/root:/bin/bash [snip]The numeric value at the beginning of each line identifies the numeric byte offset for the string you’re looking for in the file that contains text strings from the file containing unallocated blocks. Use the standard Linux
dc(desktop calculator) command to divide this offset by the filesystem’s block size (4096 for ext2/ext3 filesystems, by default) in order to get the right value. I’m looking for the block/fragment that contains the string found in the third entry in the previous output, which is located at byte offset 131698688:$ dc131698688 4096 / p 32153 qNext, use the
dcalccommand to convert the address from the unallocated block file into the address in the original disk image file:$ dcalc -u 32153 hd5_image_etc_files_deleted.img34152Finally, use the
dcatcommand to display the contents of the specified block in the fragment:$ dcat hd5_image_etc_files_deleted.img 34152root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/bash daemon:x:2:2:Daemon:/sbin:/bin/bash lp:x:4:7:Printing daemon:/var/spool/lpd:/bin/bash mail:x:8:12:Mailer daemon:/var/spool/clientmqueue:/bin/false games:x:12:100:Games account:/var/games:/bin/bash wwwrun:x:30:8:WWW daemon apache:/var/lib/wwwrun:/bin/false ftp:x:40:49:FTP account:/srv/ftp:/bin/bash nobody:x:65534:65533:nobody:/var/lib/nobody:/bin/bash man:x:13:62:Manual pages viewer:/var/cache/man:/bin/bash news:x:9:13:News system:/etc/news:/bin/bash uucp:x:10:14:Unix-to-Unix CoPy system:/etc/uucp:/bin/bash at:x:25:25:Batch jobs daemon:/var/spool/atjobs:/bin/bash messagebus:x:100:101:User for D-BUS:/var/run/dbus:/bin/false mdnsd:x:78:65534:mDNSResponder runtime user:/var/lib/mdnsd:/bin/false postfix:x:51:51:Postfix Daemon:/var/spool/postfix:/bin/false ntp:x:74:65534:NTP daemon:/var/lib/ntp:/bin/false sshd:x:71:65:SSH daemon:/var/lib/sshd:/bin/false haldaemon:x:101:102:User for haldaemon:/var/run/hal:/bin/false gdm:x:50:15:Gnome Display Manager daemon:/var/lib/gdm:/bin/bash ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^ @^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^ @^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^ @^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^ @^@^@ [snip]
Voilà! If it looks like a password file and smells like a password file…
Tip
Whenever I use this approach, I typically redirect the output of the dcat command into a file, which I can then edit to remove the trailing junk that you see at the end of the last example.
Had I been fumble-fingered enough to actually delete all the files in a real /etc directory, I’d also have to recover /etc/group, possibly /etc/shadow (depending on the authentication mechanism that the system uses), and /etc/fstab, but all of these could easily be recovered using the same approach.
Summary
The Sleuth Kit and Autopsy are powerful packages that do an incredible amount of work for you if you’re trying to recover deleted text files and are basically essential if you’re trying to do computer forensics work on the Linux platform.
A huge number of other open source packages that purportedly help recover deleted files are also available. One of the most promising of these is Foremost (http://foremost.sourceforge.net), which is open source but was written by two special agents in the United States Air Force Office of Special Investigations. (No, I’m not kidding.) Foremost uses file header and footer signatures and internal data structures to help identify binary files on a disk or in a disk image. It is currently being updated—the current version (1.0 Beta when this book was written) is hard-wired to accept specific file formats, but they’re adding a flexible configuration, which is very promising for sysadmins who need to be able to recover binary files such as Microsoft Office documents, image files, and so on. If you’ve always wanted to get involved in open source software, this is a great project to start with.
See Also
“Recover Data from Crashed Disks” [Hack #94]
“Recover Deleted Files” [Hack #97]
File System Forensic Analysis, by Brian Carrier (Addison Wesley)
Forensic Discovery, by Dan Farmer and Wietse Venema (Addison Wesley)
The Sleuth Kit: http://www.sleuthkit.org/sleuthkit/
Autopsy: http://www.sleuthkit.org/autopsy/
The Sleuth Kit’s newsletter: http://www.sleuthkit.org/informer/
The Coroner’s Toolkit: http://www.porcupine.org/forensics/tct.html
Foremost: http://foremost.sourceforge.net
More forensics links: http://www.sleuthkit.org/links.php