
This chapter describes future developments that are triggered by the MDA. It describes what is not yet realized, but what is achievable if we follow in the direction the MDA is going. Some of these developments may take place within a couple of years, others might take longer.
In Chapter 1 we explained that the MDA development life cycle is not very different from the traditional life cycle. What is crucial is that the MDA, when fully implemented, will establish a shift of focus within the life cycle. To explain this vision on the MDA we will take a look at the history of programming.
In short, we can characterize the history of programming along the time line given in Table 12-1. Each period is characterized by the dominant type of programming language. The programming languages used in each period are built on the assets of the previous period.
First there was raw machine code, which automated the wiring of computers. Next, symbolic representations of this raw machine language, called assembly languages, were made, and assembly language programs were converted to machine code by an automated tool called an assembler. Following, there was the time of the procedural programming languages. These were built on top of assembly languages. They were designed to be easier than an assembly language for a human to understand, including things like named variables, procedures, subroutines, and so on. Compilers or interpreters were used to convert the programs into assembly or raw machine code.
Object-oriented programming languages were built on the assets of procedural languages. They extend the procedural languages with much more powerful structuring mechanisms. Often compilers for object-oriented programming languages use a two-step method. First the program is translated into a low-level third-generation language, next this result is compiled into machine code.
Looking back, we see that there has been a shift of focus in the development of computer programs over the years. In the early years the focus was on writing programs using low-level constructs. Later the focus shifted to writing programs using higher level constructs. The fact that these higher level programs had to be translated to programs using lower level constructs is almost forgotten. Programmers need not worry about generating assembly or raw machine code, because the task has been automated and one can rely on a compiler.
Taking the MDA approach, the focus will shift to another level. Nowadays the focus is on code, often written in an object-oriented programming language. In the future the focus will shift to writing the PSM, and from there to writing the PIM. People will forget the fact that the PSM needs to be transformed into code because generating the code will be automated. Maybe some years later there will even be people who will forget that a PIM needs to be transformed into a PSM.
In the future the MDA development life cycle will not be shown to include an artifact called code as we did in Figure 1-2 in Chapter 1. Instead, it will look more like Figure 12-1, leaving out the gray parts. Most people will think that when the PSM is completed, one can go directly to the testing phase.

When explaining the MDA to software developers, we often get a sceptical response. A typical reply is, “This can never work. You cannot generate a complete working program from a model. You will always need to adjust the code.” Is the MDA really too good to be true?
Well, we don't think so; otherwise, we would not have bothered writing this book. We believe that the MDA will change the future of software development radically. One argument for this is that although the MDA is still in its infancy, you can today achieve great gains in productivity, portability, interoperability, and maintenance effort by applying the MDA using a good transformation tool. Therefore it is, and will be, used even when not all of the elements of the framework have been established yet, like the transformation definition language. A second argument comes from the history of computing.
In the early 1960s our industry was in the middle of a revolution. The use of existing assembly languages was substituted by the use of procedural languages. In those days, too, there was a lot of skepticism, and not without reason. The first compilers were not very good. The Algol programming language, for instance, offered a possibility to give hints to the compiler on how to translate a piece of code. Many programmers were concerned that the generated assembler code would be far less efficient than handwriting the assembler code themselves. Many could not believe that compilers would become so good that they could stop worrying about this.
To a certain extent, the skeptics were right. You lost efficiency and speed, and you couldn't program all the assembler tricks in a procedural language. However, the advantages of procedural languages became more and more obvious. Using higher level languages you can write more complex software much faster, and the resulting code is much easier to maintain. At the same time, better compiler technology diminished the disadvantages. The generated assembler code became more efficient. Today we accept the fact that we shouldn't program our systems in assembler. It is even the opposite, if someone says he is planning to write his new customer relationship management system in assembler, he would be declared insane.
What MDA brings us is a similar revolution. Eventually, PIMs can be compiled (read: transformed) into PSMs, which are compiled into procedural language code (which itself is compiled into assembly or raw machine code). The PIM to PSM compilers (read: transformation tools) will not be very efficient for some years to come. Its users will need to give hints on how to transform parts of a model. But eventually, the advantage of working on a higher level of abstraction will become clear to everyone in the business.
In conclusion, we can say that although the MDA is still in its infancy, it already shows the potential of changing software development radically. No, we will not tell you that from this day on you and your team will not have to write a single line of code. Of course you will need to bother with code for the next few years. Instead, we argue that you are witnessing the birth of a paradigm shift, and that in the near future software development will shift its focus from code to models.
The shift of focus from code to models will have consequences on the software development process, the languages used to write models, and the software development tools. We will examine the consequences for each in the following sections.
What are the consequences of applying the MDA on the software development process? Comparing the MDA process to the traditional process, much will remain the same. Requirements still need to be captured and systems still need to be tested and deployed. What will change are the activities of analysis, low-level design, and coding.
During analysis a PIM will need to be developed. There will probably be a special group of people who will perform this task. They will be aware of the functionality that needs to be implemented, and they will be driven by the needs of the business and by the business model.
Most likely there will be a different group of people responsible for the transformation of the PIM to one or more PSMs. They will have knowledge of different platforms, different system architectures, and of the transformation definitions that are available for the transformation tools they are using. They will decide with what parameter values the transformations are to be applied. They will choose between various target platforms and target system architectures. Does the system require a three-layer architecture, or is a simple fat client-server architecture sufficient? Do we use J2EE or the .net as target platform? These are the kind of questions the PSM creator will need to answer. It is the responsibility of the PSM creator to be aware of and act upon quality of service aspects.
To find the answer to these questions, the PSM creator will need some information from the PIM analyst other than the PIM itself. He will need to know about the non-functional business requirements. For instance, when a PIM analyst tells the PSM creator that the system will be used intensively by over five thousand persons, the PSM creator will wisely choose another target architecture, and use another transformation definition than if the system were to be used by a group of five.
Another task of the PSM creator is to respond to changes in both the PIM and the transformation definitions. The PIM and the transformation definitions may change independently of each other. When the business requirements change, only the PIM will be affected. When the target platform changes, for instance because a new version is installed, only the transformation definition will have to be renewed. The PSM creator must respond to these changes because any change must be reflected in the generated PSM. Meanwhile, the previous version of the system that has already been deployed, may contain lots of data that has to migrate to the new version of the system. In the future this task of the PSM creator will need to be supported by tools. These tools may or may not be integrated in the transformation tool.
Because the PSM creator will need transformation definitions, buying or writing transformation definitions will be a task new to the MDA development process. In our view, there will be a third group of people who will write transformation definitions. They will partly be employed by the companies that build software systems, but a large part of this group will be employed by transformation tool vendors. Their tools will only have customer value when transformation definitions are available. Figure 12-2 shows the different participants in the MDA process, the tools they are using, and the artifacts they are producing.
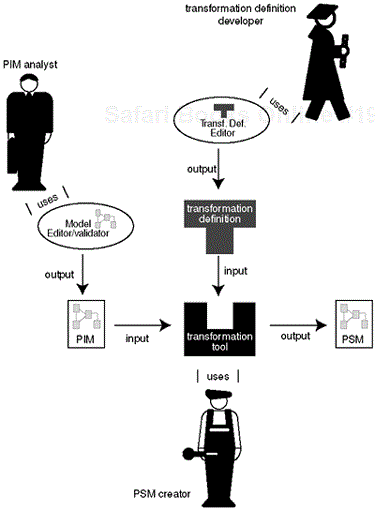
What are the consequences of applying the MDA on the software development tools? Again, looking at the difference between the traditional development process and the MDA development process, we find three groups of people who will need new or better tools, and one group who will not need any tools, because it will not be involved in the MDA process.
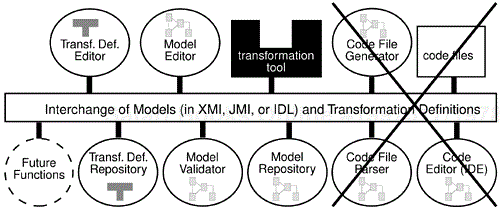
The last group is the group of code writers. When the MDA approach has matured, this group will not be needed anymore. Current code writing tools, like IDEs specific to a certain programming language, will cease to be relevant in the development process. The trend is already noticeable. Currently, many IDE vendors are progressing their environments to integrate a modeling tool as well. Figure 12-3 shows how in the future the functionality supporting activities concerning code will be less important. Instead, new functionality will be demanded on the high end of the software factory pipeline.
A new kind of IDE will be demanded by the transformation definition developers. They will need specialized environments to create, edit, and test their transformation definitions. Because the aim is to reuse transformation definitions, the group of transformation definition developers will not be very large. Therefore, it is likely that there will not be a large choice of transformation definition IDEs.
The group of PSM creators will work with transformation tools. The desired functionality for these tools will include the following:
The ability to choose between different implementation platforms
The flexibility to switch within one platform between different implementation strategies, application architectures, and coding patterns
Openness to plug-in multiple modeling languages, transformation definitions
Support for standard domain specific models or blue prints
Integration with other tools that automate software development and maintenance (code maintenance, version control, requirement management, workflow automation, testing tools, performance tuning tools, and so on)
Most likely the different tools used in the MDA process will need to interoperate or perhaps even integrate. For instance, a PSM creator may want to make a small change in the transformation definition he is using in order to produce a more efficient system. Another example is a transformation definition developer who needs to test his definition. How will he do that? The obvious choice is to use a transformation tool. Therefore, it is important that all tools operate in a standard way. Looking back at Figure 3-1 from Chapter 3, we can say that these tools must at least be able to use the same standard interchange format for models and transformation definitions.
The PIM analysts are the group that is served already. There is a large number of modeling tools available, most of which are able to read and write the standard interchange format for UML models. Still, the PIM analysts will need better modeling tools; tools that provide more support on checking the model and on the integration of the model parts. For example, the flow of information between the various UML diagrams should be supported. But most of all the PIM analyst needs better modeling languages.
What are the consequences of applying the MDA on the modeling languages? To be able to write PIMs that completely specify the system to be generated, including both static and dynamic aspects, we need a different set of modeling languages.
Today's modeling languages provide us with the means to specify the structural part of the functionality in a PIM. For the dynamic part, they depend on ordinary programming languages to fill in the gaps in the model. The action language used in Executable UML (Mellor and Balcer 2002) tries to fill this gap, but as explained in section 3.2.2, the available concepts are at the same abstraction level as the current procedural and object oriented languages. Unless the action language gets to a higher level of abstraction, it will not be able to support the MDA process fully.
A modeling language suited for MDA should offer the following:
Expressive enough to specify systems completely. This includes both static and dynamic aspects of a system. There should be no need for the developers to fall back to ordinary programming languages.
A general applicable, non application-specific, language. Application specific languages like 4GLs never really set off. Most programming is still done using generally applicable programming languages.
Abstract often-used patterns of lower-level constructs into single higher-level constructs.
Suitable for n-tier application development, including three-tier, two-tier, and single-tier applications. The actual number of tiers should be of no consequence in the model, but should be adjusted in the settings of the transformation tool.
Suitable for distributed applications. Transformation tools should take care of building the bridges between the various nodes.
Seamlessness between the model and its implementation.
Support for managing large models, for instance by supporting an aspect-oriented manner of modeling (Kiczales 1997).
Note that when a modeling language is created that allows full specification of a system, including both static and dynamic aspects, it becomes more than a modeling language. In fact, the modeling languages of tomorrow will have the same status as the high-level programming languages of today.
In this chapter we have taken a look into the crystal ball and predicted what the future of software development might look like when the MDA is applied on a large scale.
Although the MDA is still in its infancy, it already shows the potential of changing software development radically. Nowadays the focus of the software development process is on writing code. In the future the focus will shift to writing the PSM, and from there to writing the PIM. People will forget the fact that the PSM needs to be transformed into code, because generating the code will be automated. This is such a major change in the development process that it can be called a paradigm shift.
The shift of focus from code to models will have consequences on the software development process, the languages used to write models, and the software development tools. In the software development process, three participants can be recognized:
The PSM creator, who is responsible for transforming a PIM to one or more PSMs.The PSM creator will be the one that uses transformation tools. He will choose the right transformation for the job and parameterize it.
The transformation definition developer, who is responsible for creating and maintaining transformation definitions. The transformation definition developer will need a specialized environment to create, edit, and test his transformation definitions.
The PIM analyst, who is responsible for creating and maintaining PIMs. The PIM analyst will need better modeling tools. But most of all the PIM analyst needs better modeling languages.
New modeling languages suited for MDA will be defined. They will allow full specification of a system, including both static and dynamic aspects. Such a language will have the same status as the programming languages of today.