
Chapter 4. Using Groovy features in Java
- Basic code-level simplifications
- Useful AST transformations
- XML processing
In chapter 1 I reviewed many of Java’s arguable weaknesses and drawbacks and suggested ways that Groovy might help ameliorate them. Because that chapter was intended to be introductory I only suggested how Groovy can help, without showing a lot of code examples. Now that I’ve established how easy it is to add Groovy classes to Java applications, when is it helpful to do so? What features, if any, does Groovy bring to Java systems that make them easier to develop?
A guide to the techniques covered in this chapter is shown in figure 4.1. I’ll review several Groovy advantages, like POGOs, operator overloading, the Groovy JDK, AST transformations, and how to use Groovy to work with XML and JSON data. To start, I’ll show that from Groovy code POJOs can be treated as though they were POGOs.
Figure 4.1. Groovy features that can be added to Java classes
4.1. Treating POJOs like POGOs
POGOs have more capabilities than POJOs. For example, all POGOs have a map-based constructor that’s very convenient for setting properties. The interesting thing is that even if a class is written in Java, many of the same conveniences apply as long as it’s accessed from Groovy.
Consider a simple POJO representing a person, possibly created as part of a domain model in Java, shown in the next listing. To keep it simple I’ll only include an ID and a name. I’ll put in a toString override as well but won’t include the inevitable equals and hashCode overrides.
Listing 4.1. A simple POJO representing a person
public class Person {
private int id;
private String name;
public Person() {}
public Person(int id, String name) {
this.id = id;
this.name = name;
}
public void setId(int id) { this.id = id; }
public int getId() { return id; }
public void setName(String name) { this.name = name; }
public String getName() { return name; }
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + "]";
}
}
Any typical Java persistence layer has dozens of classes just like this, which map to relational database tables (figure 4.2).
Figure 4.2. Groovy adds a map-based constructor to Java classes, regardless of what constructors are already included.
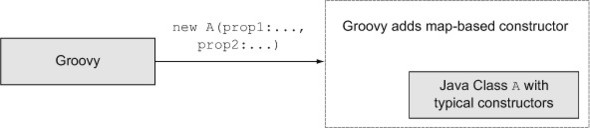
If I instantiate this class from Groovy I can use a map-based[1] constructor to do so, even though the Java version already specifies two constructors and neither is the one I want. The following Groovy script creates some Person instances using three different mechanisms, none of which appear in the Java class:
1 The term map-based refers to the fact that the attributes are set using the key-value notation used in Groovy maps. The constructor doesn’t actually use a map to do its job.
def buffy = new Person(name:'Buffy') assert buffy.id == 0 assert buffy.name == 'Buffy' def faith = new Person(name:'Faith',id:1) assert faith.id == 1 assert faith.name == 'Faith' def willow = [name:'Willow',id:2] as Person assert willow.getId() == 2 assert willow.getName() == 'Willow'
The instances buffy and faith are created using the map-based constructor, first setting only the name, and then setting both the name and the id. I’m then able to verify, using Groovy’s built-in assert method (omitting its optional parentheses), that the person’s properties are set correctly.
Incidentally, all the assert statements that seem to be accessing private properties of the class directly really aren’t. Groovy goes through the getter and setter methods provided in the Java class when it looks like properties are being accessed or assigned. I can prove this by modifying the implementation of the getter method to return more than just the name:
public String getName() {
return "from getter: " + name;
}
Now I have to modify each of the asserts to include the string "from getter: " for them to still return true.
The third person, willow, is constructed using the as operator in Groovy. This operator has several uses, one of which is to coerce a map into an object as shown here. In this case the operator instantiates a person and supplies the map as properties for the resulting instance.
Moving on, I can also add the person instances to a Groovy collection, which isn’t all that surprising but has some nice additional benefits. For example, Groovy collections support operator overloading, making it easy to add additional persons and have additional methods for searching:
def slayers = [buffy, faith]
assert ['Buffy','Faith'] == slayers*.name
assert slayers.class == java.util.ArrayList
def characters = slayers + willow
assert ['Buffy','Faith','Willow'] == characters*.name
def doubles = characters.findAll { it.name =~ /([a-z])1/ }
assert ['Buffy','Willow'] == doubles*.name
Groovy has a native syntax for collections, which simplifies Java code. Putting the references inside square brackets creates an instance of the java.util.ArrayList class and adds each element to the collection. Then, in the assert statement, I used the so-called “spread-dot” operator to extract the name property from each instance and return a list of the results (in other words, the spread-dot operator behaves the same way collect does). By the way, I restored the getName method to its original form, which returns just the attribute value.
I was able to use operator overloading to add willow to the slayers collection, resulting in the characters collection. Finally, I took advantage of the fact that in Groovy, the java.util.Collection interface has been augmented to have a findAll method that returns all instances in the collection matching the condition in the provided closure. In this case the closure contains a regular expression that matches any repeated lowercase letter.
Many existing Java applications have extensive domain models. As you can see, Groovy code can work with them directly, even treating them as POGOs and giving you a poor-man’s search capability.
Now to demonstrate a capability Groovy can add to Java that Java doesn’t even support: operator overloading.
4.2. Implementing operator overloading in Java
So far I’ve used the fact that both the + and – operators have been overloaded in the String class. The overloaded + operator in String should be familiar to Java developers, because it’s the only overloaded operator in all of Java; it does concatenation for strings and addition for numerical values. Java developers can’t overload operators however they want.
That’s different in Groovy. In Groovy all operators are represented by methods, like the plus method for + or the minus method for—. You can overload[2] any operator by implementing the appropriate method in your Groovy class. What isn’t necessarily obvious, though, is that you can implement the correct method in a Java class, too, and if an instance of that class is used in Groovy code, the operator will work there as well (see figure 4.3).
2 Incidentally, changing the behavior of operators this way is normally called operator overloading, because the same operator has different behavior in different classes. Arguably, though, what I’m actually doing is operator overriding. Effectively they’re the same thing here, so I’ll use the terms interchangeably.
Figure 4.3. Groovy operators are implemented as methods, so if the Java class contains the right methods, Groovy scripts can use the associated operators on their instances.
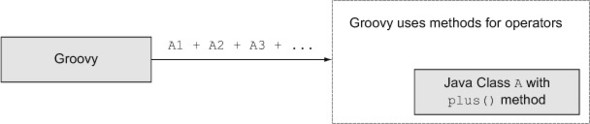
To demonstrate this I’ll create a Java class that wraps a map. A Department contains a collection of Employee instances and will have a hire method to add them and a layOff method to remove them (hopefully not very often). I’ll implement operator overloading through three methods: plus, minus, and leftShift. Intuitively, plus will add a new employee, minus will remove an existing employee, and leftShift will be an alternative way to add. All three methods will allow chaining, meaning that they’ll return the modified Department instance.
Here’s the Employee class, which is just the Person POJO by another name:
public class Employee {
private int id;
private String name;
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getId() { return id; }
public void setId(int id) { this.id = id; }
}
Now for the Department class, shown in the following listing, which maintains the employee collection in a Map keyed to the employee id values.
Listing 4.2. A Department with a map of Employees and operator overriding
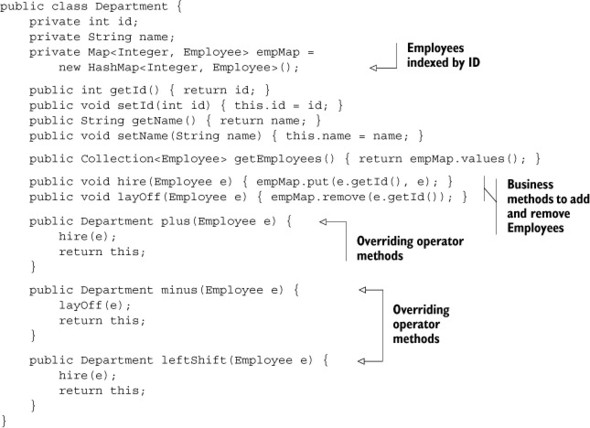
By the way, notice that the plus method doesn’t add two Department instances; rather, it adds an Employee to a Department. Groovy only cares about the name of the method for the operator.[3]
3 As an example from the Groovy JDK, the java.util.Date class has a plus method that takes an integer representing the number of days. See also the multiply method in Collection that takes an integer.
To test this I’ll use the Spock testing framework. As in chapter 1, I’ll present the test without going into much detail about the Spock framework itself, which I’ll deal with in chapter 6. Fortunately, Spock tests are easy to read even if you don’t know the details. The next listing shows a Spock test that’s focused on just the operator methods.
Listing 4.3. A Spock test to check the operator overloading methods in a Java class
class DepartmentTest extends Specification {
private Department dept;
def setup() { dept = new Department(name:'IT') }
def "add employee to dept should increase total by 1"() {
given: Employee fred = new Employee(name:'Fred',id:1)
when: dept = dept + fred
then:
dept.employees.size() == old(dept.employees.size()) + 1
}
def "add two employees via chained plus"() {
given:
Employee fred = new Employee(name:'Fred',id:1)
Employee barney = new Employee(name:'Barney',id:2)
when:
dept = dept + fred + barney
then:
dept.employees.size() == 2
}
def "subtract emp from dept should decrease by 1"() {
given:
Employee fred = new Employee(name:'Fred',id:1)
dept.hire fred
when:
dept = dept - fred
then:
dept.employees.size() == old(dept.employees.size()) - 1
}
def "remove two employees via chained minus"() {
given:
Employee fred = new Employee(name:'Fred',id:1)
Employee barney = new Employee(name:'Barney',id:2)
dept.hire fred; dept.hire barney
when: dept = dept - fred - barney
then: dept.employees.size() == 0
}
def "left shift should increase employee total by 1"() {
given:
Employee fred = new Employee(name:'Fred',id:1)
when:
dept = dept << fred
then:
dept.employees.size() == old(dept.employees.size()) + 1
}
def "add two employees via chained left shift"() {
given:
Employee fred = new Employee(name:'Fred',id:1)
Employee barney = new Employee(name:'Barney',id:2)
when:
dept = dept << fred << barney
then:
dept.employees.size() == 2
}
}
The Spock test is written in Groovy, so I can use +, –, and << and know that the associated methods will be used, even though they’re implemented in a Java class.
The list of operators that can be overridden in Groovy includes plus, minus, and leftShift, as shown in the listing, and many others as well. You can implement array-like access through an index by implementing getAt, for example. Pre-and post-increment are implemented through the next and previous methods, respectively. The spaceship operator, <=>, is implemented through compareTo. You can even override the dot operator, believe it or not. The cool part is that you can implement these methods in either POJOs or POGOs, and Groovy will take advantage of them either way.
The next feature of Groovy that simplifies Java is one I’ve taken advantage of several times already: the Groovy JDK.
4.3. Making Java library classes better: the Groovy JDK
Every Groovy class contains a metaclass. In addition to providing information about a class, the metaclass contains methods that come into play if a method or property that doesn’t exist is accessed through an instance. By intercepting those method or property “missing” failures, developers can provide whatever they want.
One application of this is for Groovy to add methods to existing classes. This is especially useful when you want to add methods to classes where you cannot change the source code. As mentioned earlier, Groovy makes extensive use of the existing Java standard libraries. It does not, however, simply use them as it finds them. In many cases, a range of new methods has been added to the Java libraries to make them easier and more powerful.
Collectively the set of enhanced Java libraries is known as the Groovy JDK. Groovy has two sets of Javadoc documentation. One is the Groovy API, which contains information about the included Groovy libraries. The other is the Groovy JDK, which shows only those methods and properties that have been added to the standard Java libraries, in order to, as the saying goes, make them groovier (see figure 4.4).
Figure 4.4. Groovy adds convenience methods to classes in the Java standard library.
For example, Groovy adds many methods to the java.util.Collection interface, including collect, count, find, findAll, leftShift, max, min, sort, and sum. These methods are then available in any Groovy collection, whether they include objects from Java or Groovy.
I’ve already spent a fair amount of time on collections, though, and I’ll revisit them frequently in the book. So to choose an example from a different Java class, let’s illustrate why it’s a bad idea to use basic authentication over HTTP.
In basic authentication a username and password are transmitted in encoded form to a server. Basic authentication concatenates the username and the password together, separated by a colon, performs a Base 64 encoding on the resulting string, and sends the result as part of the authenticated HTTP request header.
There’s a big difference, however, between encoding and encrypting. Encoded strings can just as easily be decoded. Groovy makes it easy to demonstrate this, because the Groovy JDK adds a method called encodeBase64 to, of all things, byte arrays. It also adds a decodeBase64 method to String. The following listing demonstrates both.
Listing 4.4. Base 64 encoding and decoding username/password information

There’s a lot going on in this short script. First, a username and password are assembled into a Groovy string. Then the getBytes method is invoked on the combined string, which encodes the string into a sequence of bytes using the default character encoding. That method is from Java. The result is a byte array. Check the Groovy JDK and you’ll find that Groovy has added the method encodeBase64 to byte[], which returns an instance of groovy.lang.Writable. Here I just use its toString method (from Java, of course, though it’s overridden in the Groovy class) to see the resulting values. In effect I went from Java to Groovy to Java in one chained method call.
To go the other direction, first I use the decodeBase64 method that Groovy adds to java.lang.String, which returns a byte[] again. Then String has a constructor that takes a byte array, and I use the split method from Java to separate the username from the password again and verify that they haven’t been modified by the transformations.
Other than showing how the Groovy JDK adds new methods to standard Java data types, this example also demonstrates that encoded text isn’t encrypted. Anyone who intercepts the request and accesses the encoded header can extract the username and password. Using basic authentication therefore is not at all secure if the requests are transmitted over an unencrypted connection, like HTTP. At a minimum the request should be sent over HTTPS instead.[4]
4 For several years Twitter supported basic authentication as part of its RESTful API. Hopefully all the many Twitter clients who used it transmitted their authentication over secure sockets. If not you might want to consider changing your password. These days Twitter has switched to OAuth, which may be overly complicated but is much better than basic authentication.
There are lots and lots of useful methods in the Groovy JDK. As another example, date manipulation is always painful in Java.[5] Groovy doesn’t necessarily fix the many problems, but the Groovy JDK adds several methods to make date-related classes more powerful. Here’s an example, which hopefully will be both interesting and at least mildly amusing to some readers.
5 Java 8 is supposed to fix this, at long last. In the meantime, the open source date/time library of choice in the Java world is Joda time: http://joda-time.sourceforge.net/.
In the United States and Canada, February 2 is known as Groundhog Day. On Groundhog Day, the groundhog is supposed to emerge from his hole and look for his shadow. If he doesn’t see it he’ll stay out of the burrow, and winter is nearly over. If he sees his shadow, he goes back to sleep in his burrow, and we’ll sadly have to suffer through six more weeks of winter.
Let’s check the math on that, though, as shown in the next listing.
Listing 4.5. GroundHog Day—an example of Date and Calendar in the Groovy JDK

I get an instance of the Calendar class by accessing its instance property. Of course, there’s no instance property in Calendar, but the syntax actually means that I invoke the static getInstance method with no arguments. Then I call set with the appropriate arguments for Groundhog Day and the first day of spring. Extracting a Date instance from the Calendar is done through the getTime method (sigh[6]), which again is invoked by accessing the time property. So far this is straight Java, except that I’m invoking methods via properties and omitting optional parentheses.
6 Seriously, couldn’t the method getDate have been used to extract a Date from a Calendar?
I can subtract dates, though, because the Groovy JDK shows that the minus method in Date returns the number of days between them. The Date class has a next method and a previous method and implements compareTo. Those are the requirements necessary for a class to be used as part of a range, so I can check the math by invoking the size method on a range. The size of a range counts both ends, so I have to correct for the potential off-by-one error by subtracting one.
The bottom line is that there are six weeks and four days between Groundhog Day and the first day of spring (March 20). In other words, if the groundhog sees his shadow the resulting six more weeks of winter is actually a (slightly) early spring anyway.[7]
7 Yes, that’s a long way to go for a gag, but it does clearly show a mix of Java and Groovy that takes advantage of both Groovy JDK methods and operator overloading. The joke is just a side benefit.
One last convenience should be noted here. In Java, arrays have a length property, strings have a length method, collections have a size method, NodeLists have a getLength method, and so on. In Groovy you can invoke size on all of them to get the proper behavior. In this case the Groovy JDK has been used to correct a historical inconsistency in Java.
The Groovy JDK is full of helpful methods. Even if your application is planning to use only Java library classes I encourage you to check the Groovy JDK for possible simplifications and enhancements.
I mentioned runtime metaprogramming, which is done through the metaclass. One of the more interesting features of Groovy, though, is compile-time metaprogramming done through AST transformations, which is the subject of the next section.
4.4. Cool AST transformations
Groovy 1.6 introduced Abstract Syntax Tree (AST) transformations. The idea is to place annotations on Groovy classes and invoke the compiler, which builds a syntax tree as usual and then modifies it in interesting ways. Writing AST transformations is done through various builder classes, but that’s not my primary concern here. Instead I want to show some of the AST transformations that Groovy provides in the standard library and demonstrate that they can be applied to Java classes, too.
4.4.1. Delegating to contained objects
Let’s start with delegation. Current design principles tend to favor delegation over inheritance, viewing inheritance as too highly coupled. Instead of extending a class in order to support all its methods, with delegation you wrap an instance of one class inside another. You then implement all the same methods in the outer class that the contained class provides, delegating each call to the corresponding method on the contained object. In this way your class has the same interface as the contained object but is not otherwise related to it.
Writing all those “pass-through” methods can be a pain, though. Groovy introduced the @Delegate annotation to take care of all that work for you.
Phones keep getting more and more powerful, so that the term phone is now something of a misnomer. The current generation of “smart phones” includes a camera, a browser, a contact manager, a calendar, and more.[8] If you’ve already developed classes for all the components, you can then build a smart phone by delegation. The interesting part is that the component classes can be in Java, and the container in Groovy.
8 Here’s a good quote attributed to Bjarne Stroustrup, inventor of C++: “I’ve always wished for my computer to be as easy to use as my telephone; my wish has come true because I can no longer figure out how to use my telephone.”
Consider a trivial Camera class in Java:
public class Camera {
public String takePicture() {
return "taking picture";
}
}
Here also is a Phone class, in Java.
public class Phone {
public String dial(String number) {
return "dialing " + number;
}
}
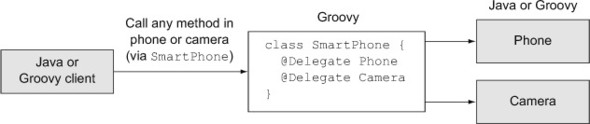
Now here’s a SmartPhone class in Groovy that uses the @Delegate annotation to expose the component methods through the SmartPhone class (see figure 4.5):
class SmartPhone {
@Delegate Camera camera = new Camera()
@Delegate Phone phone = new Phone()
}
Figure 4.5. The @Delegate AST transformation exposes all methods in the delegates through the composite object. The transformation only works in Groovy classes, but the delegates themselves can be in Groovy, Java, or both.
A JUnit test (written in Groovy this time) demonstrates the delegated methods in the next listing.
Listing 4.6. A JUnit test in Groovy to demonstrate the delegated methods
class SmartPhoneTest {
SmartPhone sp = new SmartPhone()
@Test
void testPhone() {
assert 'dialing 555-1234' == sp.dial('555-1234')
}
@Test
void testCamera() {
assert 'taking picture' == sp.takePicture()
}
}
Simply add whatever components are needed, and the @Delegate annotation will expose their methods through the SmartPhone class. I could also add smart phone-specific methods as desired. The @Delegate annotation makes including capabilities easy, and the components themselves can be written in Java or Groovy, whichever is more convenient. The only requirement is that the SmartPhone class itself must be written in Groovy, because only the Groovy compiler understands the AST transformation.
I’ll have another practical example of @Delegate later, in appendix C on SOAP-based web services (available for free download), but for now let’s move on to making objects that can’t be changed.
4.4.2. Creating immutable objects
With the rise of multi-core machines, programs that handle concurrency well are becoming more and more important. One mechanism for handling operations in a thread-safe manner is to use immutable objects as much as possible whenever shared information is required.
Unlike C++, Java has no built-in way to make it impossible to modify an object. There’s no “const” keyword in Java, and applying the combination of static and final to a reference only makes the reference a constant, not the object it references. The only way to make an object immutable in Java is to remove all ways to change it.
This turns out to be a lot harder than it sounds. Taking out all setter methods is a good first step, but there are other requirements. Making a class support immutability requires that
- All mutable methods (setters) must be removed.
- The class should be marked final.
- Any contained fields should be private and final.
- Mutable components like arrays should defensively be copied on the way in (through constructors) and the way out (through getters).
- equals, hashCode, and toString should all be implemented through fields.
That sounds like work. Fortunately Groovy has an @Immutable AST transformation, which does everything for you (see figure 4.6).
Figure 4.6. The @Immutable AST transformation results in an immutable object that can be used in both Java and Groovy clients.

The @Immutable transformation can only be applied to Groovy classes, but those classes can then be used in Java applications. I’ll start by showing how the @Immutable annotation works and what its limitations are, and then use an immutable object in a Java class.
Here’s an immutable point class. It contains two fields, x and y, which represent the location of the point in a two-dimensional space:
@Immutable
class ImmutablePoint {
double x
double y
String toString() { "($x,$y)" }
}
The @Immutable annotation is applied to the class itself. It still allows the properties to be set through a constructor, but once set the properties can no longer be modified. The next listing shows a Spock test to demonstrate that fact.
Listing 4.7. Testing the ImmutablePoint class

In the test the ImmutablePoint class is instantiated by specifying the values of x and y as constructor arguments. This is necessary, because there are no set methods available. I can access the properties through the regular dynamically generated get methods, but if I try to modify a property the attempt will throw a ReadOnlyPropertyException.
The @Immutable annotation is very powerful, but it has limitations. You can only apply it to classes that contain primitives or certain library classes, like String or Date. It also works on classes that contain properties that are also immutable. For example, here’s an ImmutableLine, which contains two ImmutablePoint instances:
@Immutable
class ImmutableLine {
ImmutablePoint start
ImmutablePoint end
def getLength() {
double dx = end.x - start.x
double dy = end.y - start.y
return Math.sqrt(dx*dx + dy*dy)
}
String toString() { "from $start to $end" }
}
The start and end fields are both of type ImmutablePoint. I’ve added a method to return a dependent length property, which is computed using the Pythagorean theorem in the usual manner. This means I can access the length property of an ImmutableLine and the access will go through the getLength method, but because there’s no setter I can’t change the value from outside. The corresponding test for this class is shown in the following listing.
Listing 4.8. A Spock test for the ImmutableLine class

In order to create an ImmutableLine I need to first create a pair of ImmutablePoint instances that can be used in the ImmutableLine constructor. The first test checks that the contained points are set properly and then checks the getLength implementation by accessing the length “field.” Finally, I make sure that I can’t reassign the start or end properties of the line.
Taking this one step further, what happens if the class contains a collection? The @Immutable annotation will cause the collection to be wrapped by one of its unmodifiable alternatives. For example, let’s say that a path is a collection of lines, so here’s the definition of an ImmutablePath:
@Immutable
class ImmutablePath {
List<ImmutableLine> segments = []
}
This time I can’t just declare the segments variable using def. If I want the @Immutable annotation to work I need to specify that I’m using some sort of collection. On the right-hand side of the segments definition I still just have [], which normally means an instance of java.util.ArrayList. In this case, however, what I actually get (by printing segments.class.name) is java.util.Collections$UnmodifiableRandomAccessList, believe it or not. The Collections class has utility methods like unmodifiableList that take a regular list and return a new list that can’t be changed, but to be honest I wouldn’t have necessarily expected it to be a RandomAccessList in this case. It doesn’t make any difference what the actual class is, of course, as long as the contract is maintained.
Speaking of that contract, those unmodifiable methods in Collections don’t remove the available mutator methods. Instead, they wrap them and throw an Unsupported-OperationException if they’re accessed. That’s arguably a strange way to implement an interface, but so be it. The Spock test for this class is shown in the following listing. Everything works as expected. It takes some doing to build up all the immutable objects needed to create an ImmutablePath instance, but once everything is set it all works.
Listing 4.9. A Spock test for the ImmutablePath class
class ImmutablePathTest extends Specification {
ImmutablePath path
def setup() {
def lines = []
ImmutablePoint p1 = new ImmutablePoint(x:0,y:0)
ImmutablePoint p2 = new ImmutablePoint(x:3,y:0)
ImmutablePoint p3 = new ImmutablePoint(x:0,y:4)
lines << new ImmutableLine(start:p1,end:p2)
lines << new ImmutableLine(start:p2,end:p3)
lines << new ImmutableLine(start:p3,end:p1)
path = new ImmutablePath(segments:lines)
}
def "points should be set through ctor"() {
expect:
path.segments.collect { line -> line.start.x } == [0,3,0]
path.segments.collect { line -> line.start.y } == [0,0,4]
path.segments.collect { line -> line.end.x } == [3,0,0]
path.segments.collect { line -> line.end.y } == [0,4,0]
}
def "cant add new segments"() {
given:
ImmutablePoint a = new ImmutablePoint(x:5,y:5)
ImmutablePoint b = new ImmutablePoint(x:4,y:4)
when:
path.segments << new ImmutableLine(start:a,end:b)
then:
thrown UnsupportedOperationException
}
}
Everything I’ve shown about the @Immutable annotation so far falls in the category of the good news. Now for the bad news, though again it’s not all that bad. First, the @Immutable annotation, like many of the AST transformations, wreaks havoc on Integrated Development Environments (IDEs). The transformations occur at compile time, which the IDEs have a hard time anticipating. Even though everything I’ve done so far is legal and works just fine, my IDE[9] continually struggled with it. At this point the IDE issues are mostly annoying, but fixing them is legitimately a Hard Problem and probably won’t go away soon.
9 Most of the code in this chapter was written using Groovy / Grails Tool Suite (STS) version 3.2.
The next problem occurs when I try to use my ImmutablePoint in a Java program. How am I supposed to assign the x and y values? Groovy gives me a map-based constructor that I’ve been using so far, but Java won’t see that.
Fortunately, the developers of @Immutable anticipated that problem. The transformation also generates a tuple constructor that takes each of the properties in the order they’re defined. In this case, it’s as though the ImmutablePoint class has a two-argument constructor that takes doubles representing x and y in that order.
Here’s a JUnit 4 test (written in Java, so it’s an example of Java/Groovy integration itself) that takes advantage of that constructor:
public class ImmutablePointJUnitTest {
private ImmutablePoint p;
@Test
public void testImmutablePoint() {
p = new ImmutablePoint(3,4);
assertEquals(3.0, p.getX(), 0.0001);
assertEquals(4.0, p.getY(), 0.0001);
}
}
This, again, works just fine. At the moment, my IDE even understands that the two-argument constructor exists, which is pretty sweet. I’m using the three-argument version of the Assert.assertEquals method, by the way, because I’m comparing doubles, and for that you need to specify a precision.
There’s also no need to try to check for immutability, because from the Java point of view the class has no methods to invoke that might change x or y. Unlike the getX and getY methods shown, there are no corresponding setters.
As I say, this all works, but if you’re trying to use the generated constructor and your system refuses to believe that one exists, there’s a simple workaround. Simply add a factory class in Groovy that can instantiate the points in the usual way:
class ImmutablePointFactory {
ImmutablePoint newImmutablePoint(xval,yval) {
return new ImmutablePoint(x:xval,y:yval)
}
}
Now the Java client can instantiate ImmutablePointFactory and then invoke the newImmutablePoint factory method, supplying the desired x and y values.
Everything works, that is, until you succumb to the temptation to follow standard practices in the Java API and make the factory class a singleton. That’s the subject of the next subsection.
4.4.3. Creating singletons
When a new Java developer first discovers the wide, wonderful world of design patterns, one of the first ones they tend to encounter is Singleton. It’s an easy pattern to learn, because it’s easy to implement and only involves a single class. If you only want one instance of a class, make the constructor private, add a static final instance variable of the class type, and add a static getter method to retrieve it. How cool is that?
Unfortunately, our poor new developer has wandered into a vast jungle, full of monsters to attack the unwary. First of all, implementing a true singleton isn’t nearly as easy as it sounds. If nothing else, there are thread safety issues to worry about, and because it seems no Java program is every truly thread-safe the results get ugly fast.
Then there’s the fact that a small but very vocal contingent of developers view the whole Singleton design pattern as an anti-pattern. They trash it for a variety of reasons, and they tend to be harsh in their contempt for both the pattern and anyone foolish or naïve enough to use it.
Fortunately I’m not here to resolve that issue. My job is to show you how Groovy can help you as a Java developer, and I can do that here. As you may have anticipated based on the title of this section, there’s an AST transformation called @Singleton.
To use it all I have to do is add the annotation to my class. Here I’ve added it to the ImmutablePointFactory from earlier:
@Singleton
class ImmutablePointFactory {
ImmutablePoint newImmutablePoint(xval,yval) {
return new ImmutablePoint(x:xval,y:yval)
}
}
Again, I can’t resist saying it: that was easy. The result is that the class now contains a static property called instance, which contains, naturally enough, the one and only instance of the class. Also, everything is implemented in as correct a manner as possible by the author[10] of the transformation. In Groovy code I can now write the following:
10 Paul King, one of the coauthors of Groovy in Action (Manning, 2007) and a fantastic developer. Let me be blunt about this: everything Paul King writes is good. He tends to add his presentations to SlideShare.net as well, so go read them as soon as humanly possible.
ImmutablePoint p = ImmutablePointFactory.instance.newImmutablePoint(3,4)
That works just fine. It’s when I try to do the same thing in Java that I run into problems. Again, the compiler understands, but I’ve never been able to coax my IDE into believing that the factory class has a public static field called instance in it.
Still, the annotation works and the IDEs will eventually understand how to deal with it. In fact, all the cool new AST transformations work, and I encourage you to consider them significant shortcuts to writing applications.
There are other AST transformations available and more being written all the time. I encourage you to keep an eye on them in case one comes along that can simplify your code the same way the ones just discussed do.
As cool as AST transformations are, though, our last task is so much easier to do in Groovy than in Java that it practically sells Groovy to Java developers all by itself. That issue is parsing and generating XML.
4.5. Working with XML
Way back in the late 90s, when XML was young, new, and still popular (as hard to imagine as that may be now), the combination of XML and Java was expected to be a very productive one. Java was the portable language (write once, run anywhere, right?), and XML was the portable data format. Unfortunately, if you’ve ever tried working with XML through the Java built-in APIs you know the results have fallen far short of the promise. Why are the Java APIs for working with XML so painful to use?
Here’s a trivial example. I have a list of books in XML format, as shown here:
<books>
<book isbn="...">
<title>Groovy in Action</title>
<author>Dierk Koenig</author>
<author>Paul King</author>
...
</book>
<book isbn="...">
<title>Grails in Action</title>
<author>Glen Smith</author>
<author>Peter Ledbrook</author>
</book>
<book isbn="...">
<title>Making Java Groovy[11]</title>
<author>Ken Kousen</author>
</book>
</books>11 I had to find some way to include my book in that august company, just to bask in the reflected glory.
Now assume that my task is to print the title of the second book. What could be easier? Here’s one Java solution, based on parsing the data into a document object model (DOM) tree and finding the right element:
public class ProcessBooks {
public static void main(String[] args) {
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
Document doc = null;
try {
DocumentBuilder builder = factory.newDocumentBuilder();
doc = builder.parse("src/jag/xml/books.xml");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
if (doc == null) return;
NodeList titles = doc.getElementsByTagName("title");
Element titleNode = (Element) titles.item(1);
String title = titleNode.getFirstChild().getNodeValue();
System.out.println("The second title is " + title);
}
}
This is actually the short version of the required program. To make it any shorter I’d have to collapse the exception handling into catching just Exception, or add a throws clause to the main method.
Many APIs in Java are designed around a set of interfaces, with the assumption that there will be many different alternative implementations. In the Java API for XML Processing (JAXP) world there are many parsers available, so the API is dominated by interfaces. Of course, you can’t instantiate an interface, so using the API comes down to factories and factory methods.
To parse the XML file using a simple DOM parser, therefore, I first need to acquire the relevant factory, using its newInstance method. Then I use the factory method newDocumentBuilder, which is admittedly a really good name for a factory method. Parsing the file is then done through the parse method, as expected. Inside the DOM parser the tree is constructed using, interestingly enough, a SAX parser, which is why I need to prepare for SAX exceptions.
Assuming I get that far, the result at that point is a reference to the DOM tree. Finding my answer by traversing the tree is quite frankly out of the question. Traversals are highly sensitive to the presence of white-space nodes, and the available methods (getFirstChild, getNextSibling, and the like) aren’t really a direct method to my answer. If whoever put together the XML file had been kind enough to assign each element an ID I could have used the great getElementByID method to extract the node I need, but no such luck there. Instead I’m reduced to collecting the relevant nodes using getElementsByTagName, which doesn’t return something from the Collections framework as you might expect, but a NodeList instead. The NodeList class has an item method that takes an integer representing the zero-based index of the node I want, and at long last I have my title node.
Then there’s the final indignity, which is that the value of a node is not the character content I want. No, I have to retrieve the first text child of the node, and only then can I get the value, which returns the text I needed.
I was once teaching a class about Java and XML, and one of the exercises was to extract a nested value. After taking the students through the awkward, ugly, Java solution, a woman in the back raised her hand.
“I kept waiting for you to say, ‘this is the hard way,’” she said, “and now here’s the easy way, but you never got to the easy way.”
In reply I had to say, “Want to see the easy way? Let’s look at the Groovy solution to this problem.”
def root = new XmlSlurper().parse('books.xml')
println root.book[1].title
How’s that for easy? I instantiated an XmlSlurper, called its parse method on the XML file, and just walked the tree to the value I want.
If I ever need to parse or generate XML I always add a Groovy module to do it.
Let’s look at another, somewhat more practical, example. Remember the Google geocoder used in chapter 3? When the geocoder went to version 3, Google removed the requirement to register for a key (good) but also removed the CSV output type (unfortunate). Now the only available output types are either JSON or XML. Google also changed the URL for accessing the web service (pretty typical when versioning a web service, actually), embedding the two available output types into the new URLs. In chapter 9 on RESTful web services I’ll have a lot more to say about the choice of output types (formally known as content negotiation), but here the type is embedded in the URL.
From a Java point of view, working with JSON output is a bit of a complication because it requires an external library to parse the JSON data. That’s not too much of a burden because there are several good JSON libraries available, but you still have to pick one and learn to use it. We’ve already talked about how involved it is to work with XML data in Java, so that’s not a great alternative either.
Groovy, however, eats XML for lunch. Let’s see just how easy it is for Groovy to access the new geocoder and extract the returned latitude and longitude data.
First, here’s a sample of the XML output returned from the web service for the input address of Google’s home office:
<GeocodeResponse>
<status>OK</status>
<result>
<type>street_address</type>
<formatted_address>1600 Amphitheatre Pkwy, Mountain View, CA 94043, USA</
formatted_address>
...
<geometry>
<location>
<lat>37.4217550</lat>
<lng>-122.0846330</lng>
</location>
...
</geometry>
</result>
</GeocodeResponse>
A lot of child elements have been omitted from this response in order to focus on what I actually want. The latitude and longitude values are buried deep inside the output. Of course, digging to that point is easy enough for Groovy. Here’s a script that creates the required HTTP request, transmits it to Google, and extracts the response, all in less than a dozen lines:
String street = '1600 Ampitheatre Parkway'
String city = 'Mountain View'; state = 'CA'
String base = 'http://maps.google.com/maps/api/geocode/xml?'
String url = base + [sensor:false,
address:[street, city, state].collect { v ->
URLEncoder.encode(v,'UTF-8')
}.join(',')].collect {k,v -> "$k=$v"}.join('&')
def response = new XmlSlurper().parse(url)
latitude = response.result[0].geometry.location.lat
longitude = response.result[0].geometry.location.lng
The code strongly resembles the version 2 client presented earlier, in that I have a base URL for the service (note that it includes the response type, XML, as part of the URL) and a parameters map that I convert into a query string. Transmitting the request and parsing the result is done in one line of code, because the XmlSlurper class has a parse method that takes a URL. Then extracting the latitude and longitude is simply a matter of walking the tree.
Several times I’ve written applications that took this script, after converting it to a class that used a Location like before, and added it as a service. The code savings over the corresponding Java version is just too great to ignore.
Parsing is one thing, but what about generation? For that, Groovy provides a builder class called groovy.xml.MarkupBuilder.
Consider another POJO representing a Song, as shown here:
public class Song {
private int id;
private String title;
private String artist;
private String year;
public Song() {}
public Song(int id, String title, String artist, String year) {
this.id = id;
this.title = title;
this.artist = artist;
this.year = year;
}
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
public String getArtist() { return artist; }
public void setArtist(String artist) { this.artist = artist; }
public String getYear() { return year; }
public void setYear(String year) { this.year = year; }
}
The Song class, implemented in Java, contains an id and strings for the title, artist, and year. The rest is just constructors, getters, and setters. In a real system the class would also probably have overrides of toString, equals, and hashCode, but I don’t need that here.
How should Song instances be represented in XML? One simple idea would be to treat the ID as an attribute of the song, and have title, artist, and year as child elements. In the following listing I show part of a Groovy class that converts Song instances to XML and back.
Listing 4.10. Converting songs to XML and back


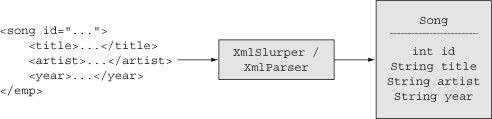
The SongXMLConverter class has four methods: one to convert a single song to XML, one to convert XML to a single song, and two to do the same for a collection of songs. Converting from XML to Song instances is done with the XmlSlurper illustrated earlier. The only new part is that the slurper accesses the song ID value using the @id notation, where the @ is used to retrieve an attribute. Figure 4.7 shows the job of the XmlSlurper, or its analogous class, XmlParser.
Figure 4.7. Using an XmlSlurper or XmlParser to populate an object from XML data
Going the other direction, from song to XML, is done with a MarkupBuilder. The MarkupBuilder class writes to standard output by default. In this class I want to return the XML as a string, so I used the overloaded MarkupBuilder constructor that takes a java.io.Writer as an argument. I supply a StringWriter to the constructor, build the XML, and then convert the output to a String using the normal toString method.
Once I have a MarkupBuilder I write out the song’s properties as though I was building the XML itself. Let’s focus on the conversion of a single song to XML form, as shown next:
MarkupBuilder builder = new MarkupBuilder(sw)
builder.song(id:s.id) {
title s.title
artist s.artist
year s.year
}
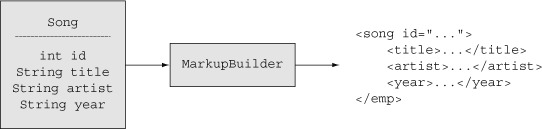
The job of the MarkupBuilder is illustrated in figure 4.8.
Figure 4.8. Generating an XML representation of an object using a groovy.xml.MarkupBuilder
This is an example of Groovy’s metaprogramming capabilities, though it doesn’t look like it at first. The idea is that inside the builder, whenever I write the name of a method that doesn’t exist, the builder interprets it as an instruction to create an XML element. For example, I invoke the song method on the builder with the argument being a map with a key called id and a value being the song’s ID. The builder doesn’t have a song method, of course, so it interprets the method call as a command to build an element called song, and the argument is an instruction to add an id attribute to the song element whose value is the song ID. Then, when it encounters the curly brace it interprets that as an instruction to begin child elements.
I have three more method calls: one to title, one to artist, and one to year. The lack of parentheses can be misleading in this case, but each is actually a method call. Once again the builder interprets each of the non-existent methods as commands to create XML elements, and the arguments this time, because they’re not in map form, become character data contained in the elements. The result of the builder process is the XML shown next:
<song id="...">
<title>...</title>
<artist>...</artist>
<year>...</year>
</song>
The method that converts a list of songs into a larger XML file just does the same thing for each song.
- Groovy’s XmlParser and XmlSlurper make parsing XML trivial, and values can be extracted by walking the resulting DOM tree.
- Generating XML is just as easy, using MarkupBuilder.
Groovy Sweet Spot
Groovy is excellent at parsing and generating XML. If your Java application works with XML, strongly consider delegating to a Groovy module.
4.6. Working with JSON data
Groovy processes JSON data as easily as it processes XML. To conclude this chapter, let me present a trivial example of JSON response data from a web service.
The service is known as ICNDB: the Internet Chuck Norris Database. It is located at http://icndb.com and has a RESTful API for retrieving the associated jokes. If you send an HTTP GET request to http://api.icndb.com/jokes/random?limitTo=[nerdy] you get back a string in JSON form.
Groovy makes it easy to send a GET request. In the Groovy JDK the String class has a toURL method, which converts it to an instance of java.net.URL. Then the Groovy JDK adds a method to the URL class called getText. Accessing the web service is therefore as simple as
String url = 'http://api.icndb.com/jokes/random?limitTo=[nerdy]' String jsonTxt = url.toURL().text println jsonTxt
Executing this returns a JSON object of the form
{ "type": "success", "value": { "id": 563, "joke": "Chuck Norris causes the
Windows Blue Screen of Death.", "categories": ["nerdy"] } }
In all the Google geocoder demonstrations I’ve used so far in this book I introduced the XmlSlurper class, whose parse method takes the URL in string form and automatically converts the result to a DOM tree. Since version 1.8, Groovy also includes a JsonSlurper, but it doesn’t have as many overloads of the parse method as the XmlSlurper does. It does, however, contain a parseText method, which can process the jsonTxt returned from the previous code.
If I add that to the earlier lines, the complete ICNDB script is shown in the next listing.
Listing 4.11. chuck_norris.groovy, which processes data from ICNDB
import groovy.json.JsonSlurper String url = 'http://api.icndb.com/jokes/random?limitTo=[nerdy]' String jsonTxt = url.toURL().text def json = new JsonSlurper().parseText(jsonTxt) def joke = json?.value?.joke println joke
The parseText method on JsonSlurper converts the JSON data into Groovy maps and lists. I then access the value property of the json object, which is a contained JSON object. It has a joke property, which contains the string I’m looking for.
The result of executing this script is something like this:
Chuck Norris can make a method abstract and final
Just as generating XML is done by scripting the output through a MarkupBuilder, generating JSON data uses the groovy.json.JsonBuilder class. See the GroovyDocs for JsonBuilder for a complete example.
This completes the tour of Groovy features that can be added to Java applications regardless of use case.
- When Groovy access a POJO it can use the map-based constructor as though it were a POGO.
- Every operator in Groovy delegates to a method, and if that method is implemented in a Java class the operator in Groovy will still use it. This means you can do operator overloading even in a Java class.
- The Groovy JDK documents all the methods that Groovy adds to the Java standard API through metaprogramming.
- Groovy AST transformations can only be applied to Groovy classes, but the classes can be mixed with Java in interesting ways. This chapter includes examples of @Delegate, @Immutable, and @Singleton.
4.7. Summary
This chapter reviewed many ways that Groovy can help Java at the basic level, from POJO enhancements to AST transformations to building XML and more. I’ll use these techniques in future chapters wherever they can help. I’ll also review other helpful techniques along the way, though these are most of the major ones.
The next couple of chapters, however, change the focus. Although mixing Java and Groovy is easy and is a major theme of this book, some companies are reluctant to add Groovy to production code until their developers have a certain minimum comfort level with the language. As it happens, there are two major areas where Groovy can strongly impact and simplify Java projects without being integrated directly. The first of those is one of the major pain points in enterprise development: the build process. The other is testing, which is valued more highly the better the developer.
By covering these two techniques early in the book I can then use, for example, Gradle builds and Spock tests when I attack the use cases Java developers typically encounter, like web services, database manipulation, or working with the Spring framework.