
Appendix B. Groovy by feature
Some people learn by example. Some people learn by feature. In this book I’m trying to satisfy both. If you’re a Java developer with only passing familiarity with Groovy, hopefully either this appendix or chapter 2, “Groovy by example,” will bring you up to speed on the Groovy language.
This appendix walks through most of the major features of Groovy and provides short snippets of code illustrating them. While this chapter does not claim to be an exhaustive reference like Groovy in Action (Manning, 2007; called GinA in the rest of this appendix), it has a couple of features that favor it over the more comprehensive treatment: (1) it’s considerably shorter, and (2) it has the words “Don’t Panic!” written in nice, friendly letters in the appendix (in this sentence, actually).[1] More seriously, in this appendix I review the major features of the Groovy programming language that are used throughout the book.
1 For those born too late, that was a Hitchhiker’s Guide to the Galaxy reference. I could go on to say that this chapter “contains much that is apocryphal, or at least wildly inaccurate,” but that probably wouldn’t be good for sales.
Because this isn’t going to be a comprehensive treatment, I’ve chosen aspects of Groovy to review based on two criteria: (1) how often they’re used in practice and (2) how much they offer an advantage over corresponding features in Java (assuming the corresponding feature in Java even exists). After getting the basics of Groovy out of the way (like how to run Groovy programs and basic data types like numbers and strings), I’ll move on to issues like collections, I/O, XML, and more. Some topics, like SQL, are covered in other chapters, but you’ll find the essentials here.
B.1. Scripts and the traditional example
Assuming you already have Groovy installed,[2] I’ll start with the traditional “Hello, World!” program, as shown here:
2 See appendix A for details.
println 'Hello, Groovy!'
That’s the whole program. In Java, you need a main method inside a class, and inside the main method you call System.out.println to write to the console. Java developers are used to it, but there are roughly 8 to 10 different object-oriented concepts involved, depending on how you count them.[3] In Groovy, the whole program is a single line.
3 A rough count includes classes, methods, strings, arrays, public access, static methods and attributes, void return types, overloaded methods like println, and more. It’s no accident that Bruce Eckel’s Thinking in Java (Prentice-Hall, 2002) takes over 100 pages just to get to his first “Hello, World” program.
To demonstrate, consider one of the two execution environments that come with Groovy, the groovysh command, which starts the Groovy shell. The Groovy shell is a REPL[4] that allows you to execute Groovy code a line at a time. All of the lines in the following listing produce the same result.
4 Read-Eval-Print Loop; see http://en.wikipedia.org/wiki/REPL for details.
Listing B.1. Running “Hello, World!” in the Groovy shell

In each case the println method prints to the console and returns null. When there’s no ambiguity, the parentheses can be omitted. Semicolons work as in Java, but they’re optional.
This is an example of a Groovy script. A script is a code listing that doesn’t explicitly include a class definition. In Java, everything has to be inside a class. Groovy is able to work with both scripts and classes.
A Groovy script is a form of syntactic sugar.[5] A class is, in fact, involved. If I compile this script and then run the javap command on it, I get the following response:
5 Syntactic sugar is syntax that simplifies writing code but doesn’t change anything under the hood. There may be some evidence that an overuse of syntactic sugar leads to syntactic diabetes.
> groovyc hello_world.groovy
> javap hello_world
Compiled from "hello_world.groovy"
public class hello_world extends groovy.lang.Script{
public static transient boolean __$stMC;
public static long __timeStamp;
public static long __timeStamp__239_neverHappen1309544582162;
public hello_world();
public hello_world(groovy.lang.Binding);
public static void main(java.lang.String[]);
public java.lang.Object run();
...
There are about 30 more lines of output from the javap command, mostly involving superclass methods. The interesting part is that the groovy command generates a class called hello_world, along with a pair of constructors and a main method. The class is generated at compile time and extends a class from the Groovy library called groovy.lang.Script. In effect, scripts in Groovy become classes in Java, where the code in the script ultimately (after a few layers of indirection) is executed by the main method. I don’t want to give the impression that Groovy is generating Java, however. Groovy code is compiled directly into bytecodes for the JVM.
Compiled Groovy
Groovy is compiled, not interpreted. It’s not a code generator; the compiler generates Java bytecodes directly.
Because the bytecodes run on the JVM, you can execute Groovy scripts using the java command as long as you include the necessary JAR file in your classpath:
> java –cp .;%GROOVY_HOME%embeddablegroovy-all-2.1.5.jar hello_world Hello, World!
Executing Groovy
At runtime, Groovy is just another JAR file. As long as the groovy-all JAR file is in the classpath, Java is perfectly happy to execute compiled Groovy code.
The groovy command is used to execute Groovy programs. It can be used with either the compiled code (similar to the java command) or Groovy source. If you use the source, the groovy command first compiles the code and then executes it.
B.2. Variables, numbers, and strings
Groovy is an optionally typed language. Groovy uses classes to define data types, just as Java does, but Groovy variables can either have a static type or use the def keyword.
For example, I’m perfectly free to declare variables of type int, String, or Employee, using the standard Java syntax:
int x String name Employee fred
If I don’t know the type of the variable, or I don’t care, Groovy provides the keyword def:
def arg
When should you use def as opposed to the actual type? There’s no strict answer, but recently I had a (very mild) Twitter debate about this issue with Dierk Koenig (lead author of GinA), Andres Almiray (lead author of Griffon in Action and head of the Griffon project), and Dave Klein (lead author of Grails: A Quick-Start Guide). Dierk had the best recommendation I’ve ever heard on the subject. He said, “If I think of a type, I type it (pun intended).”
My own experience is that as I get more experienced with Groovy, I tend to use def less and less. I agree with Dierk’s recommendation, with the added advice that now when I declare a type, I pause for a moment to see if any actual type occurs to me. If so, I use it.
In some cases def is preferred, most notably when using mock objects in testing. That subject is discussed in chapter 6.
Moving on to data types themselves, Java makes a distinction between primitives and classes. In Groovy there are no primitives. Numbers in Groovy are first-class objects, with their own set of methods.
B.2.1. Numbers
Because in Groovy numbers are objects, I can determine their data types. For integer literals, the data type depends on the value, as shown in this script:
x = 1 assert x.class == java.lang.Integer x = 10000000000000000 assert x.class == java.lang.Long x = 100000000000000000000000 assert x.class == java.math.BigInteger
There are a few points to be made about this script. First, the variable x doesn’t have a declaration at all. This is only legal in a script, where the variable becomes part of the script’s binding and can be set and accessed from outside. Details of this procedure are shown in chapter 3 on integration with Java. Suffice it to say here that this is legal in a script, but not in a class. If it makes you feel more comfortable, you’re free to add the word def in front of x.
Script Variables
If a variable in a script is not declared, it becomes part of the script’s binding.
As mentioned earlier, the script lacks semicolons. Semicolons as statement separators are optional in Groovy and can be omitted if there’s no ambiguity. Again, you’re free to add them in without a problem.
Semicolons
In Groovy, semicolons work but are optional.
Next, Groovy uses the method called assert extensively. The word assert can be written without parentheses, as done here, or you can surround an expression with them. The resulting expression must evaluate to a Boolean, but that’s a much looser requirement than in Java. In Java, the only available Booleans are true and false. In Groovy, non-null references are true, as are nonzero numbers, non-empty collections, non-empty strings, and the Boolean value true.
That bears repeating and goes by the term The Groovy Truth.
The Groovy Truth
In Groovy, non-null references, non-empty collections, non-empty strings, nonzero numbers, and the Boolean value true are all true.
Finally, the default data type for floating-point values in Java is double, but in Groovy it’s java.math.BigDecimal. The double type in Java has approximately 17 decimal places of precision, but if you want to get depressed about its accuracy, try this tiny sample:
println 2.0d – 1.1d
The d appended to the literals makes them doubles. You would expect the answer here to be 0.9, but in fact it’s 0.8999999999999999. That’s not much of a difference, but I’ve only done a single subtraction and I’m already off. That’s not good. That’s why any serious numerical calculations in Java require java.math.BigDecimal, but that means you can’t use the standard operators (+, -, *, /) anymore and have to use method calls instead.
Groovy handles that issue without a problem. Here’s the analogous Groovy script:
println 2.0 – 1.1
The answer in this case is 0.9, as expected. Because the calculations are done with BigDecimal, the answer is correct. Groovy also has operator overloading, so the plus operator can be used with the BigDecimal values. To summarize:
Literals
Numbers without a decimal point are of type Integer, Long, or java.math.BigInteger, depending on size. Numbers with a decimal point are of type java.math.BigDecimal.
Because numbers are objects, they have methods as well. Listing B.2 shows a script putting some numbers through their paces. Several of the expressions use closures, which are the subject of section B.4. The simplest definition is to consider them a block of code that’s executed as though it’s an anonymous method call.
Listing B.2. numbers.groovy, showing method calls on numeric literals
assert 2**3 == 8
assert 2**-2 == 0.25 // i.e., 1/(2*2) = 1/4
def x = ""
3.times { x += "Hello" }
assert x == "HelloHelloHello"
def total = 0
1.upto(3) { total += it }
assert total == 1 + 2 + 3
def countDown = []
5.downto 1, { countDown << "$it ..." }
assert countDown == ['5 ...', '4 ...', '3 ...', '2 ...', '1 ...']
Groovy has an exponentiation operator, unlike Java. Numbers have methods like times, upto, and downto. The times operation takes a single argument of type Closure. When the last argument to a method is a closure, you can put it after the parentheses. Because the method has no other arguments, you can leave out the parentheses altogether.
Closure Arguments
If the last argument to a method is a closure, it can be placed after the parentheses.
The upto and downto methods take two arguments, so the parentheses are shown in the former and a comma is used in the latter to indicate that both the number and the closure are arguments to the method. The countDown variable is a list, which will be discussed in section B.3. The left-shift operator has been overloaded to append to the collection, and its argument here is a parameterized string. Groovy has two types of strings, discussed in the next section.
B.2.2. Strings and Groovy strings
In Java, single quotes delimit characters (a primitive) and double quotes surround instances of java.lang.String. In Groovy, both single and double quotes are used for strings, but there’s a difference. Double-quoted strings are used for parameter replacement. They’re not instances of java.lang.String, but rather instances of groovy.lang.GString.
Here are a couple of examples to show how they’re used:
def s = 'this is a string'
assert s.class == java.lang.String
def gs = "this might be a GString"
assert gs.class == java.lang.String
assert !(gs instanceof GString)
gs = "If I put in a placeholder, this really is a GString: ${1+1}"
assert gs instanceof GString
Single-quoted strings are always instances of java.lang.String. Double-quoted strings may or may not be Groovy strings, depending on whether parameter replacement is done or not.
Groovy also has multiline strings, with either single or double quotes. The difference again is whether or not parameter replacement is done:
def picard = '''
(to the tune of Let It Snow)
Oh the vacuum outside is endless
Unforgiving, cold, and friendless
But still we must boldly go
Make it so, make it so, make it so!
'''
def quote = """
There are ${Integer.toBinaryString(2)} kinds of people in the world:
Those who know binary, and those who don't
"""
assert quote == '''
There are 10 kinds of people in the world:
Those who know binary, and those who don't
'''
There’s one final kind of string, used for regular expressions. Java has had regular-expression capabilities since version 1.4, but most developers either aren’t aware of them or avoid them.[6] One particularly annoying part of regular expressions in Java is that the backslash character, , is used as an escape character, but if you want to use it in a regular expression, you have to backslash the backslash. This leads to annoying expressions where you have to double-backslash the backslashes, making the resulting expressions almost unreadable.
6 Perl programmers love regular expressions. Ruby developers are fond of them, but reasonable about it. Java developers take one look at the JavaDocs for the java.util.regex.Pattern class and recoil in horror.
Groovy provides what’s called the slashy syntax. If you surround an expression with forward slashes, it’s assumed to be a regular expression, and you don’t have to double-backslash anymore.
Strings
Groovy uses single quotes for regular strings, double quotes for parameterized strings, and forward slashes for regular expressions.
Here’s an example that checks strings to see if they are palindromes: that is, if they are the same forward and backward. To check for palindromes you first need to remove any punctuation and ignore case before reversing the string:
def palindromes = '''
Able was I ere I saw Elba
Madam, in Eden, I'm Adam
Sex at noon taxes
Flee to me, remote elf!
Doc, note: I dissent. A fast never prevents a fatness. I diet on cod.
'''
palindromes.eachLine {
String str = it.trim().replaceAll(/W/,'').toLowerCase()
assert str.reverse() == str
}
Once again, a little Groovy code packs a lot of power. The method eachLine has been added to the String class to break multiline strings at line breaks. It takes a closure as an argument. In this case, no dummy variables were used in the closure, so each string is assigned to the default variable called it.
The it variable
In a closure, if no dummy name is specified the term it is used by default.
The trim method is applied to the line to remove any leading and trailing spaces. Then the replaceAll method is used to replace all non-word characters with an empty string. Finally, the string is converted to lowercase.
The assert test uses another method added by Groovy to String, called reverse. Java has a reverse method in StringBuffer, but not String. Groovy adds the reverse method to String for convenience.
Groovy adds lots of methods to the Java standard libraries. Collectively these are known as the Groovy JDK and are one of the best features of Groovy. The Groovy documentation includes GroovyDocs for both the Groovy standard library and the Groovy JDK.
The Groovy JDK
Through its metaprogramming capabilities, Groovy adds many convenient methods to the standard Java libraries. These additional methods are known as the Groovy JDK.
In summary, Groovy uses numbers and objects and has both regular and parameterized strings with additional methods. Another area where Groovy greatly simplifies Java is collections.
B.3. Plain Old Groovy Objects
Java classes with getters and setters for the attributes are often known as POJOs, or Plain Old Java Objects. In Groovy, the same classes are Plain Old Groovy Objects, or POGOs.[7] POGOs have additional characteristics that are discussed in this section.
7 Python occasionally uses the term POPOs, which sounds vaguely disgusting. If you really want to annoy a Ruby developer, refer to POROs. Ruby people hate anything that sounds like Java.
Consider the following Person class in Groovy:
class Person {
String firstName
String lastName
String toString() { "$firstName $lastName" }
}
POGOs don’t require access modifiers, because in Groovy attributes are private by default and methods are public by default. The class is public by default, as well. Any property without an access modifier automatically gets a public getter and setter method. If you want to add public or private you can, and either on an attribute will prevent the generation of the associated getter and setter.
Groovy properties
In Groovy, property access is done through dynamically generated getter and setter methods.
Here’s a script using the Person class:
Person mrIncredible = new Person()
mrIncredible.firstName = 'Robert'
mrIncredible.setLastName('Parr')
assert 'Robert Parr' ==
"${mrIncredible.firstName} ${mrIncredible.getLastName()}"
Person elastigirl = new Person(firstName: 'Helen', lastName: 'Parr')
assert 'Helen Parr' == elastigirl.toString()
The script shows that you also get a default, map-based constructor, so called because it uses the same property:value syntax used by Groovy maps.
This idiom is so common in Groovy that getter and setter methods anywhere in the standard library are typically accessed with the property notation. For example, Calendar.instance is used to invoke the getInstance method on the Calendar class.
Moving now to collections of instances, I’ll start with ranges, then move to lists, and finally look at maps.
B.4. Collections
Since J2SE 1.2, the Java standard library has included the collections framework. The framework defines interfaces for lists, sets, and maps, and provides a small but useful set of implementation classes for each interface, as well as a set of polymorphic utility methods in the class java.util.Collections.
Groovy can use all of these collections but adds a lot:
- Native syntax for lists and maps
- A Range class
- Many additional convenience methods
I’ll present examples of each in this section.
B.4.1. Ranges
Ranges are collections in Groovy consisting of two values separated by a pair of dots. Ranges are normally used as parts of other expressions, like loops, but they can be used by themselves.
The class groovy.lang.Range has methods for accessing the boundaries of a range, as well as checking whether it contains a particular element. Here’s a simple example:
Range bothEnds = 5..8 assert bothEnds.contains(5) assert bothEnds.contains(8) assert bothEnds.from == 5 assert bothEnds.to == 8 assert bothEnds == [5, 6, 7, 8]
Using two dots includes the boundaries. To exclude the upper boundary, use a less-than sign:
Range noUpper = 5..<8 assert noUpper.contains(5) assert !noUpper.contains(8) assert noUpper.from == 5 assert noUpper.to == 7 assert noUpper == [5, 6, 7]
A range of numbers iterates over the contained integers. Other library classes can be used in ranges. Strings go letter by letter:
assert 1..5 == [1,2,3,4,5] assert 'A'..'E' == ["A","B","C","D","E"]
Dates iterate over the contained days, as shown in the next listing.
Listing B.3. Using dates in a range with Java’s Calendar class

For all its gifts, even Groovy can’t tame Java’s awkward java.util.Date and java.util .Calendar classes, but it can make the code for using them a bit simpler. Calendar is an abstract class with the factory method getInstance, so in Groovy I call it by accessing the instance property. The Groovy JDK adds the format method to Date, so it isn’t necessary to separately instantiate SimpleDateFormat.
In the listing, after setting the year, month, and day, the Date instance is retrieved by invoking getTime.[8] In this case, that’s equivalent to accessing the time property. The dates are used as the boundaries of a range by the each method, which appends each one to a list.
8 Yes, you read that correctly. You get the date by calling ... getTime. Hey, I didn’t write it.
In fact, any class can be made into a range if it includes three features:
- A next() method, for forward iteration
- A previous() method, for backward iteration
- An implementation of the java.util.Comparable interface, for ordering
Here the range is used as the basis of a loop, where the dates are appended to a list.
B.4.2. Lists
Lists in Groovy are the same as lists in Java, except that the syntax is easier and there are some additional methods available. Create a list in Groovy by including values between square brackets:
def teams = ['Red Sox', 'Yankees'] assert teams.class == java.util.ArrayList
The default list is of type java.util.ArrayList. If you prefer to use a LinkedList, instantiate it in the normal way.
Groovy has operator overloading. The Groovy JDK shows that the plus, minus, and left-shift operators have been defined to work with lists:
teams << 'Orioles'
assert teams == ['Red Sox', 'Yankees', 'Orioles']
teams << ['Rays', 'Blue Jays']
assert teams ==
['Red Sox', 'Yankees', 'Orioles', ['Rays', 'Blue Jays']]
assert teams.flatten() ==
['Red Sox', 'Yankees', 'Orioles', 'Rays', 'Blue Jays']
assert teams + 'Angels' - 'Orioles' ==
['Red Sox', 'Yankees', ['Rays', 'Blue Jays'], 'Angels']
Accessing elements of a list can be done with array-like syntax. Again, this is done by overriding a method—in this case, the getAt method:
assert teams[0] == 'Red Sox' assert teams[1] == 'Yankees' assert teams[-1] == ['Rays','Blue Jays']
As shown in figure B.1, access to elements from the left end starts at index 0. Access from the right end starts at index –1. You can use a range in the square brackets, too:
def cities = ['New York', 'Boston', 'Cleveland','Seattle'] assert ['Boston', 'Cleveland'] == cities[1..2]
Figure B.1. Access any linear collection using an index from either end. The first element is at index 0. The last element is at index –1. You can also use subranges, as in mylist[-4..-2].
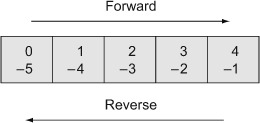
Array-like Access
Linear collections support element access through an index from either end, or even using a range.
Groovy adds methods like pop, intersect, and reverse to collections. See the GroovyDocs for details.
There are two ways to apply a function to each element. The spread-dot operator (.*) makes it easy to access a property or apply a method to each element:
assert cities*.size() == [8, 6, 9, 7]
The collect method takes a closure as an argument and applies it to each element of the collection, returning a list with the results. This is similar to the spread-dot operator, but can do more general operations:
def abbrev = cities.collect { city -> city[0..2].toLowerCase() }
assert abbrev == ['new', 'bos', 'cle', 'sea']
The word city here used before the arrow is like a dummy argument for a method call. The closure extracts the first three letters of each element of the list and then converts them to lowercase.
One particularly interesting feature of collections is that they support type coercion using the as operator. What does that mean? It’s not terribly difficult to convert a Java list into a set, because there’s a constructor for that purpose. Converting a list into an array, however, involves some awkward, counterintuitive code. Here’s Groovy’s take on the process:
def names = teams as String[] assert names.class == String[] def set = teams as Set assert set.class == java.util.HashSet
That was easy.[9] A set in Groovy is just like a set in Java, meaning it doesn’t contain duplicates and doesn’t guarantee order.
9 I know I say that a lot, but with Groovy I think it a lot, too.
The as operator
Groovy uses the keyword as for many purposes. One of them is type coercion, which converts an instance of one class into an instance of another.
One of the nicest features of Groovy collections is that they’re searchable. Groovy adds both find and findAll methods to collections. The find method takes a closure and returns the first element that satisfies the closure:
assert 'New Hampshire' ==
['New Hampshire','New Jersey','New York'].find { it =~ /New/ }
The findAll method returns all the elements that satisfy the closure. This example returns all the cities that have the letter e in their name:
def withE = cities.findAll { city -> city =~ /e/ }
assert withE == ['Seattle', 'New York', 'Cleveland']
Groovy also supplies the methods any and every, which also take closures:
assert cities.any { it.size() < 7 }
assert cities.every { it.size() < 10 }
The first expression states that there’s at least one city whose name is less than 7 characters. The second expression says that all of the city names are 10 characters or less.
Table B.1 summarizes the searchable methods.
Table B.1. Searchable methods added to Groovy collections
|
Method |
Description |
|---|---|
| any | Returns true if any element satisfies closure |
| every | Returns true if all elements satisfy closure |
| find | Returns first element satisfying closure |
| findAll | Returns list of all elements satisfying closure |
Finally, the join method concatenates all the elements of the list into a single string, using the supplied separator:
assert cities.join(',') == "Boston,Seattle,New York,Cleveland"
The combination of native syntax and added convenience methods makes Groovy lists much easier to work with than their Java counterparts. As it turns out, maps are improved the same way.
B.4.3. Maps
Groovy maps are like Java maps, but again with a native syntax and additional helper methods. Groovy uses the same square-bracket syntax for maps as for lists, but each entry in the map uses a colon to separate the key from its corresponding value.
You can populate a map right away by adding the elements when you declare the map itself:
def trivialMap = [x:1, y:2, z:3] assert 1 == trivialMap['x'] assert trivialMap instanceof java.util.HashMap
This defines a map with three entries. When adding elements to the map, the keys are assumed to be strings, so you don’t need to put quotes around them. The values can be anything.
Map keys
When adding to a map, the keys are assumed to be of type string, so no quotes are necessary.
You can add to a map using either Java or Groovy syntax:
def ALEast[10] = [:] ALEast.put('Boston','Red Sox') assert 'Red Sox' == ALEast.get('Boston') assert ALEast == [Boston:'Red Sox'] ALEast['New York'] = 'Yankees'
10 For non-baseball people, ALEast is short for the Eastern division of the American League.
Accessing values can be done with either the array-like syntax shown, or using a dot. If the key has spaces in it, wrap the key in quotes:
assert 'Red Sox' == ALEast.Boston assert 'Yankees' == ALEast.'New York'
I’ve been using def to define the map reference, but Groovy understands Java generics:
Map<String,String> ALCentral = [Cleveland:'Indians', Chicago:'White Sox',Detroit:'Tigers'] assert 3 == ALCentral.size() assert ALCentral.Cleveland == 'Indians'
Maps have a size method that returns the number of entries. Actually, the size method is universal.
Size
In Groovy, the size method works for arrays, lists, maps, strings, and more.
Maps have an overloaded plus operation that combines the entries from two maps:
def both = ALEast + ALCentral assert 5 == both.size()
Like Java maps, you can extract the set of keys from a map using the keySet method:
assert ALEast.keySet() == ['Boston','New York'] as Set
Maps also have a rather controversial method that lets you add a new element with a default in case the element doesn’t exist:
assert 'Blue Jays' == ALEast.get('Toronto','Blue Jays')
assert 'Blue Jays' == ALEast['Toronto']
Here I’m trying to retrieve a value using a key that isn’t in the map (Toronto). If the key exists, its value is returned. If not, it’s added to the map, with the second argument to the get method being its new value. This is convenient, but it means that if you accidentally misspell a key when trying to retrieve it you don’t get an error; instead, you wind up adding it. That’s not true when using the single-argument version of get.
Finally, when you iterate over a map using a closure, the number of dummy arguments determines how the map is accessed. Using two arguments means that the map is accessed as keys and values:
String keys1 = ''
List<Integer> values1 = []
both.each { key,val ->
keys1 += '|' + key
values1 << val
}
The each iterator has two dummy variables, so the first represents the key and the second the value. This closure appends the keys to a string, separated by vertical bars. The values are added to a list.
Alternatively, using a single argument assigns each entry to the specified argument, or it if none:
String keys2 = ''
List<Integer> values2 = []
both.each { entry ->
keys2 += '|' + entry.key
values2 << entry.value
}
Because a single dummy argument was used in the closure, I need to access its key and value properties (equivalent to invoking the getKey and getValue methods, as usual) to do the same operation as in the previous example.
Both mechanisms produce the same results:
assert keys1 == keys2 assert values1 == values2
Throughout this section I’ve used closures in examples without defining what they are. That’s the subject of the next section.
B.5. Closures
Like many developers, I started out in the procedural world. I started my career as a research scientist, studying unsteady aerodynamics and acoustics. Most of that involved numerically solving partial differential equations.
That meant that unless I wanted to write all my own libraries, I had to adopt Fortran as my professional language of choice.[11] My first assignment in my first job was to take a 3000-line program my boss had written in Fortran IV[12] and add functionality to it. The best part was that the original program had only two subroutines in it: one that was about 25 lines long, and the other 2975. Needless to say, I learned refactoring long before I knew the actual term.
11 The fact that I seriously considered writing those libraries in a different language anyway was yet another sign I was in the wrong profession.
12 Shudder. Holy arithmetic-if statements, Batman. The nightmares have stopped, but it took a while.
I rapidly learned what at the time were considered good development practices, meaning that I wrote structured programs that used existing libraries as much as possible. It was only in the mid-90s, when I first learned Java, that I was introduced to object-oriented programming.
That’s when I first encountered what influential blogger Steve Yegge has since referred to as the subjugation of verbs in the kingdom of the nouns.[13] In most OO languages, methods (verbs) can only exist as part of nouns (classes). Java certainly works that way. Even static methods that don’t require objects still have to be defined inside classes somewhere.
13 “Execution in the Kingdom of Nouns,” at http://mng.bz/E4MB
The first language I learned that changed all that was JavaScript, which is an object-based language rather than object-oriented. In JavaScript, even the classes are functions. Then, because the methods in the classes are also functions, you wind up with functions operating inside of functions, possibly passing around references to still other functions, and suddenly everything gets confusing and difficult. Closures in JavaScript are confusing not because functions are difficult, but because a closure includes the environment in which it executes. A closure may have references to variables declared outside of it, and in JavaScript it’s easy to get lost determining the values.
I had no idea how simple closures could be until I encountered Groovy.[14] In Groovy, it’s easy enough to treat a closure as a block of code, but it’s always clear where the nonlocal variables are evaluated because there’s no confusion about the current object.
14 Others can say the same about Ruby or other JVM languages. This is my history, though.
Closures
In practice, a closure is a block of code along with its execution environment.
In Groovy, the term closure is used broadly to refer to blocks of code, even if they don’t contain explicit references to external variables. Closures feel like methods and can be invoked that way. Consider this trivial example, which returns whatever it’s sent:
def echo = { it }
assert 'Hello' == echo('Hello')
assert 'Hello' == echo.call('Hello')
The echo reference is assigned to the block of code (a closure) delimited by curly braces. The closure contains a variable whose default name is it, whose value is supplied when the closure is invoked. If you think of the variable like a method parameter, you’ve got the basic idea.
The closure can be invoked in one of two ways: either by using the reference as though it’s a method call, or by explicitly invoking the call method on it. Because the last value computed by a closure is returned automatically, both ways return the argument to the closure, which is why it was called echo in the first place.
Closure Return Values
The last evaluated expression in a closure is returned automatically.
If a closure takes more than one argument, or if you don’t want to use the default name, use an arrow to separate the dummy argument names from the body of the closure. Here’s a simple sum, once with the default and once with a named argument:
def total = 0
(1..10).each { num -> total += num }
assert (1..10).sum() == total
total = 0
(1..10).each { total += it }
assert (1..10).sum() == total
Closures are used throughout this book and fill an entire chapter in GinA. This little amount of information is enough to make a lot of progress.
Returning to the basic constructs of the language, I’ll now show how Groovy differs from Java when using loops and conditional tests.
B.6. Loops and conditionals
In this section, I’ll discuss two features that appear in any programming language: looping through a set of values and making decisions.
B.6.1. Loops
When Groovy was first created, and for some time afterward, it didn’t support the standard Java for loop:
for (int i = 0; i < 5; i++) { ... }
In version 1.6, however, the core committers decided that it was more important to support Java constructs than to try to keep the language free of that somewhat awkward syntax that Java inherited from its predecessors. Many demonstrations of Groovy start with a Java class, rename it with a .groovy extension, and show that it still compiles successfully with the Groovy compiler. The result is far from idiomatic Groovy, but it does illustrate a valid point: Groovy is the closest to Java of the new family of JVM languages.
Java Loops
Groovy supports the standard Java for loop and for-each loop, as well as the while loop. It does not, however, support the do-while construct.
The for-each loop in Java was introduced in Java SE 1.5 and works for any linear collection, including both arrays and lists:
for (String s : strings) { ... }
The for-each loop is helpful, because it means you don’t always need to get an iterator to loop over the elements of a list. The price you pay is that there’s no explicit index. Inside the loop, you know what element you’re currently on, but not where it appears in the list. If you need to know the index, you can either keep track of the index yourself or go back to the traditional for loop.
Groovy supplies a variation on the for-each loop that avoids the colon syntax, called a for-in loop:
def words = "I'm a Groovy coder".tokenize()
def capitalized = ''
for (word in words) {
capitalized += word.capitalize() + ' '
}
assert capitalized == "I'm A Groovy Coder "
Note that unlike the for-each loop, the value variable is not declared to have a type: not even def.
Still, none of those loops are the most common way of iterating in Groovy. Rather than write an explicit loop, as in the previous examples, Groovy prefers a more direct implementation of the Iterator design pattern. Groovy adds the each method, which takes a closure as an argument, to collections. The each method then applies the closure to each element of the collection:
(0..5).each { println it }
Again, because the closure is the last argument of the method, it can be placed after the parentheses. Because there are no other arguments to the each method, the parentheses can be eliminated entirely.
Each
The each method is the most common looping construct in Groovy.
The Iterator design pattern recommends separating the way you walk through the elements of a collection from what you plan to do with those elements. The each method does the iterating internally. The user determines what to do with the elements by supplying a closure, as shown. Here the closure prints its argument. The each method supplies each value in the range, one by one, to the closure, so the result is to print the numbers from zero to five.
Like the for-in loop, inside the closure you have access to each element, but not to the index. If you want the index, though, there’s an additional method available called eachWithIndex:
def strings = ['how','are','you']
def results = []
strings.eachWithIndex { s,i -> results << "$i:$s" }
assert results == ['0:how', '1:are', '2:you']
The closure supplied to the eachWithIndex method takes two dummy arguments. The first is the value from the collection, and the second is the index.
I should mention that although all these loops work correctly, there can be differences in how much time each of them takes. If you’re dealing with a collection of a few dozen elements or less, the differences will probably not be noticeable. If the number of iterations is going to be in the tens of thousands or more, you probably should profile the resulting code.
B.6.2. Conditionals
Java has two types of conditional statements: the if statement and its related constructs, like if-else and switch statements. Both are supported by Groovy. The if statement works pretty much the same way it does in Java. The switch statement, however, has been taken from Java’s crippled form and restored to its former glory.
Groovy’s version of the if statement is similar to Java’s, with the difference being the so-called Groovy Truth. In Java, the argument to an if statement must be a Boolean expression, or the statement won’t compile. In Groovy, lots of things evaluate to true other than Boolean expressions.
For example, nonzero numbers are true:
if (1) {
assert true
} else {
assert false
}
The result is true. This expression wouldn’t work in Java. There you would have to compare the argument to another value, resulting in a Boolean expression.
The Groovy Truth is a case where Java restricted something C supported (non-Boolean expressions in decision statements), but Groovy brought it back. That can certainly lead to bugs that Java would avoid.
From a philosophical point of view, why do it? By restricting what was allowed, Java made certain types of bugs much less likely. Groovy, by restoring those features, increases the possibility of those bugs again. Is the gain worth it?
My opinion is that this is a side effect of the increased emphasis on testing that has swept through the development community. If you’re going to have to write tests to prove your code is correct anyway, why not take advantage of the greater power? Sure, you’ve introduced the possibility of getting some bugs past the compiler, but just because it compiles doesn’t mean it’s right. The tests prove correctness, so why not use shorter, more powerful code when you can?
Returning to decision statements, Java also supports a ternary operator, and Groovy does the same:
String result = 5 > 3 ? 'x' : 'y' assert result == 'x'
The ternary expression reads, is five greater than three? If so, assign the result to x, otherwise use y. It’s like an if statement, but shorter.
There’s a reduced form of the ternary operator that highlights both Groovy’s helpfulness and its sense of humor: the Elvis operator.
B.6.3. Elvis
Consider the following use case. You’re planning to use an input value, but it’s optional. If the client supplies it, you’ll use it. If not, you plan to use a default instead.
I’ll use a variable called name as an example:
String displayName = name ? name : 'default'
This means if name is not null, use it for displayName. Otherwise, use a default. I’m using a standard ternary operator to check whether name is null or not. The way this is written has some repetition in it. After all, I want to use name if it’s available, so why do I have to repeat myself?
That’s where the Elvis operator comes in. Here’s the revised code:
String displayName = name ?: 'default'
The Elvis operator is the combination of a question mark and a colon formed by leaving out the value in between them in the ternary operator. The idea is that if the variable in front of the question mark is not null, use it. The ?: operator is called Elvis because if you turn your head to the side, the result looks vaguely like the King:
def greet(name) { "${name ?: 'Elvis'} has left the building" }
assert greet(null) == 'Elvis has left the building'
assert greet('Priscilla') == 'Priscilla has left the building'
The greet method takes a parameter called name and uses the Elvis operator to determine what to return. This way it still has a reasonable value, even if the input argument is null.[15]
15 Thank you, thank you very much.
B.6.4. Safe de-reference
There’s one final conditional operator that Groovy provides that saves many lines of coding. It’s called the safe de-reference operator, written as ?..
The idea is to avoid having to constantly check for nulls. For example, suppose you have classes called Employee, Department, and Location. If each employee instance has a department, and each department has a location, then if you want the location for an employee, you would write something like this (in Java):
Location loc = employee.getDepartment().getLocation()
But what happens if the employee reference is null? Or what happens if the employee hasn’t been assigned a department, so the getDepartment method returns null? Those possibilities mean the code expands to
if (employee == null) {
loc = null;
} else {
Department dept = employee.getDepartment();
if (dept == null) {
loc = null;
} else {
loc = dept.getLocation();
}
}
That’s quite an expansion just to check for nulls. Here’s the Groovy version:
Location loc = employee?.department?.location
The safe de-reference operator returns null if the reference is null. Otherwise it proceeds to access the property. It’s a small thing, but the savings in lines of code is nontrivial.
Continuing on the theme of simplifying code over the Java version, consider input/output streams. Groovy introduces several methods in the Groovy JDK that help Groovy simplify Java code when dealing with files and directories.
B.7. File I/O
File I/O in Groovy isn’t fundamentally different from the Java approach. Groovy adds several convenience methods and handles issues like closing your files for you. A few short examples should suffice to give you a sense of what’s possible.
First, Groovy adds a getText method to File, which means that by asking for the text property you can retrieve all the data out of a file at once in the form of a string:
String data = new File('data.txt').text
Accessing the text property invokes the getText method, as usual, and returns all the text in the file. Alternatively, you can retrieve all the lines in the file and store them in a list using the readLines method:
List<String> lines = new File("data.txt").readLines()*.trim()
The trim method is used in this example with the spread-dot operator to remove leading and trailing spaces on each line. If your data is formatted in a specific way, the splitEachLine method takes a delimiter and returns a list of the elements. For example, if you have a data file that contains the following lines
1,2,3 a,b,c
then the data can be retrieved and parsed at the same time:
List dataLines = []
new File("data.txt").splitEachLine(',') {
dataLines << it
}
assert dataLines == [['1','2','3'],['a','b','c']]
Writing to a file is just as easy:
File f = new File("$base/output.dat")
f.write('Hello, Groovy!')
assert f.text == 'Hello, Groovy!'
In Java, it’s critical to close a file if you’ve written to it, because otherwise it may not flush the buffer and your data may never make into the file. Groovy does that for you automatically.
Groovy also makes it easy to append to a file:
File temp = new File("temp.txt")
temp.write 'Groovy Kind of Love'
assert temp.readLines().size() == 1
temp.append "
Groovin', on a Sunday afternoon..."
temp << "
Feelin' Groovy"
assert temp.readLines().size() == 3
temp.delete()
The append method does what it sounds like, and the left-shift operator has been overridden to do the same.
Several methods are available that iterate over files, like eachFile, eachDir, and even eachFileRecurse. They each take closures that can filter what you want.
Finally, I have to show you an example that illustrates how much simpler Groovy I/O streams are than Java streams. Consider writing a trivial application that does the following:
1. Prompts the user to enter numbers on a line, separated by spaces
2. Reads the line
3. Adds up the numbers
4. Prints the result
Nothing to it, right? The next listing shows the Java version.
Listing B.4. SumNumbers.java, an application to read a line of numbers and add them

That’s nearly 30 lines to do something extremely simple. All Java code has to be in a class with a main method. The input stream System.in is available, but I want to read a full line of data, so I wrap the stream in an InputStreamReader and wrap that in a BufferedReader, all so I can call readLine. That may throw an I/O exception, so I need a try/catch block for it. Finally, the incoming data is in string form, so I need to parse it before adding up the numbers and printing the results.
Here’s the corresponding Groovy version:
println 'Please enter some numbers'
System.in.withReader { br ->
println br.readLine().tokenize()*.toBigDecimal().sum()
}
That’s the whole program. The withReader method creates a Reader implementation that has a readLine method and automatically closes it when the closure completes. Several similar methods are available for both input and output, including withReader, withInputStream, withPrintWriter, and withWriterAppend.
That was fun, but here’s another version that has more capabilities. In this case, the code has a loop that sums each line and prints its result until no input is given:
println 'Sum numbers with looping'
System.in.eachLine { line ->
if (!line) System.exit(0)
println line.split(' ')*.toBigDecimal().sum()
}
The eachLine method repeats the closure until the line variable is empty.
Groovy’s contribution to file I/O is to add convenience methods that simplify the Java API and ensure that streams or files are closed correctly. It provides a clean façade on the Java I/O package.
Groovy makes input/output streams much simpler to deal with than in Java, so if I have a Java system and I need to work with files, I try to add a Groovy module for that purpose. That’s a savings, but nothing compared to the savings that result from using Groovy over Java when dealing with XML, as shown in the next section.
B.8. XML
I’ve saved the best for last. XML is where the ease-of-use gap between Groovy and Java is the largest. Working with XML in Java is a pain at best, while parsing and generating XML in Groovy is almost trivial. If I ever have to deal with XML in a Java system, I always add a Groovy module for that purpose. This section is intended to show why.
B.8.1. Parsing and slurping XML
Some time ago, I was teaching a training course on XML and Java. One of the exercises started by presenting an XML file similar to this one:
<books>
<book isbn="9781935182443">
<title>Groovy in Action (2nd edition)</title>
<author>Dierk Koenig</author>
<author>Guillaume Laforge</author>
<author>Paul King</author>
<author>Jon Skeet</author>
<author>Hamlet D'Arcy</author>
</book>
<book isbn="9781935182948">
<title>Making Java Groovy</title>
<author>Ken Kousen</author>
</book>
<book isbn="1933988932">
<title>Grails in Action</title>
<author>Glen Smith</author>
<author>Peter Ledbrook</author>
</book>
</books>
The goal of the exercise was to parse this file and print out the title of the second book. Because this file is small, you might as well use a DOM parser to read it. To do that in Java you need a factory, which then yields the parser, and then you can invoke a parse method to build the DOM tree. Then, to extract the data, there are three options:
- Walk the tree by getting child elements and iterating over them.
- Use the getElementById method to find the right node, and then get the first text child and retrieve its value.
- Use the getElementsByTagName method, iterate over the resulting NodeList to find the right node, and then retrieve the value of the first text child.
The first approach runs into problems with whitespace. This document has carriage returns and tabs in it, and because no DTD or schema is provided, the parser doesn’t know which whitespace elements are significant. Traversing the DOM is complicated by the fact that methods like getFirstChild will return whitespace nodes as well as elements. It can be done, but you’ll need to check the node type of each element to make sure you are working with an element rather than a text node.
The second approach only works if the elements have an attribute of type ID, and that’s not the case here.
You’re left with the getElementsByTagName method, which results in the following code:
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class ProcessBooks {
public static void main(String[] args) {
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
Document doc = null;
try {
DocumentBuilder builder = factory.newDocumentBuilder();
doc = builder.parse("books.xml");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
NodeList titles = doc.getElementsByTagName("title");
Element titleNode = (Element) titles.item(1);
String title = titleNode.getFirstChild().getNodeValue();
System.out.println("The second title is " + title);
}
}
Parsing the document can throw all sorts of exceptions, as shown. Assuming nothing goes wrong, after parsing, the code retrieves all the title elements. After getting the proper element out of the NodeList and casting it to type Element, you then have to remember that the character data in the element is in the first text child of the element rather than the element itself.
Here’s the Groovy solution:
root = new XmlSlurper().parse('books.xml')
assert root.book[1].title == 'Making Java Groovy'
Wow. Groovy includes the XmlSlurper class, which is in the groovy.util package (no import required). XmlSlurper has a parse method that builds the DOM tree and returns the root element. Then it’s a question of walking the tree, using the dot notation for child elements. Elements that appear multiple times form a collection that can be accessed with an index in the normal way. The contrast in both size and complexity between the Groovy version and the Java version is clear.
The next listing demonstrates working with the XML file.
Listing B.5. Slurping XML
String fileName = 'books.xml'
def books = new XmlSlurper().parse(fileName)
assert books.book.size() == 4
assert books.book[0].title == "Groovy in Action"
assert books.book.find {
it.@isbn == "9781935182948"
}.title == "Making Java Groovy"
def prices = []
books.book.price.each {
prices << it.toDouble()
}
assert prices == [39.99, 35.99, 35.99, 27.50]
assert prices.sum() == 139.47
Groovy uses two different classes for working with XML. The previous example used an XmlSlurper. Groovy also includes an XmlParser. The XmlParser creates a tree of Node instances, so if you need to approach the file from a node point of view, use the parser. The result is that you’ll need to invoke a text method on each node to retrieve the text data, but otherwise the two approaches are virtually the same.
Parsing XML is therefore quite easy. What about generating XML? That’s the subject of the next subsection.
B.8.2. Generating XML
So far, most of the Groovy capabilities presented are similar to what Java can do, just simpler or easier. In this section I’ll show a Groovy builder, which uses Groovy’s metaprogramming to go beyond what Java can do.
To generate XML, Groovy provides a class called groovy.xml.MarkupBuilder. You use a MarkupBuilder by invoking methods that don’t exist, and the builder interprets them by generating XML elements and attributes.
That sounds strange, but is simple in practice. The next listing shows an example.
Listing B.6. Generating XML using a MarkupBuilder
def builder = new groovy.xml.MarkupBuilder()
def department = builder.department {
deptName "Construction"
employee(id:1) {
empName "Fred"
}
employee(id:2) {
empName "Barney"
}
}
After instantiating the MarkupBuidler I invoke the department method on it, omitting the optional parentheses. There’s no department method on MarkupBuilder, so what does Groovy do?
If this was Java, I would fail with something like a MissingMethodException. Every class in Groovy has an associated meta class, however, and the meta class has a method called methodMissing. The meta class is the key to Groovy’s code generation capabilities. When the methodMissing method in MarkupBuilder is called, the implementation ultimately is to generate an XML element with the method name as the element name.
The braces that follow are interpreted to mean a child element is next. The name of the child element will be deptName, and its character data will be the supplied string. The next element is an employee, and the map-like syntax for the id implies an attribute on the employee element is needed, and so on.
The result of executing this script is
<department>
<deptName>Construction</deptName>
<employee id='1'>
<empName>Fred</empName>
</employee>
<employee id='2'>
<empName>Barney</empName>
</employee>
</department>
The MarkupBuilder generates the XML. It’s hard to imagine a simpler way to solve that problem.
I want to illustrate one final aspect of XML processing with Groovy, which involves validating a document.
B.8.3. Validation
XML documents are validated in one of two ways: through either a Document Type Definition (DTD) or an XML schema. The DTD system is older, simpler, and much less useful, but the Java parsers have been able to validate against them almost from the beginning. Schema validation came much later but is far more important, especially when dealing with, for example, web services.
Validating XML with Groovy is an interesting demonstration both of what Groovy provides, and what to do if Groovy doesn’t provide anything.
First, consider validation against a DTD. Here’s a DTD for the library XML shown earlier:
<!ELEMENT library (book+)>
<!ELEMENT book (title,author+,price)>
<!ATTLIST book
isbn CDATA #REQUIRED>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT price (#PCDATA)>
The idea is that a library element contains one or more books. A book element contains a title, one or more author elements, and a price, in that order. The book element has an attribute called isbn, which is a simple string but is required. The title, author, and price elements all consist of simple strings.
To tie the XML file to the DTD, I add the following line before the root element:
<!DOCTYPE library SYSTEM "library.dtd">
Validating the XML file against the DTD is then almost trivial. The XmlSlurper class has an overloaded constructor that takes two arguments, both of which are Booleans. The first is to trigger validation, and the second is namespace awareness. Namespaces aren’t relevant when discussing a DTD, but it doesn’t hurt to turn on both properties:
def root = new XmlSlurper(true, true).parse(fileName)
That’s all that’s needed to do the validation. If the XML data doesn’t satisfy the DTD, errors will be reported by the parsing process.
Validation against an XML schema has always been more of a challenge. Schemas understand namespaces and namespace prefixes, and there are many things you can do in a schema that you can’t do in a DTD.
Consider the next listing, which shows a schema for the library.
Listing B.7. An XML schema for the library XML
<?xml version="1.0" encoding="UTF-8"?>
<schema
xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.kousenit.com/books"
xmlns:tns="http://www.kousenit.com/books"
elementFormDefault="qualified">
<element name="library" type="tns:LibraryType" />
<complexType name="LibraryType">
<sequence>
<element ref="tns:book" maxOccurs="unbounded" />
</sequence>
</complexType>
<element name="book">
<complexType>
<sequence>
<element name="title" type="string" />
<element name="author" type="string"
maxOccurs="unbounded" />
<element name="price" type="tns:PriceType" />
</sequence>
<attribute name="isbn" type="tns:ISBNtype" />
</complexType>
</element>
<simpleType name="PriceType">
<restriction base="decimal">
<fractionDigits value="2" />
</restriction>
</simpleType>
<simpleType name="ISBNtype">
<restriction base="string">
<pattern value="d{10}|d{13}" />
</restriction>
</simpleType>
</schema>
This is the same as the DTD, except that it says that price elements have two decimal places, and isbn attributes are composed of either 10 or 13 decimal digits. Tying the XML document to this schema can be done by modifying the root element as follows:
<library
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.kousenit.com/books"
xsi:schemaLocation="
http://www.kousenit.com/books
books.xsd">
The rest of the library is the same as before. Here’s the code used to validate the XML document against the schema:
String file = "books.xml"
String xsd = "books.xsd"
SchemaFactory factory = SchemaFactory.newInstance(
XMLConstants.W3C_XML_SCHEMA_NS_URI)
Schema schema = factory.newSchema(new File(xsd))
Validator validator = schema.newValidator()
validator.validate(new StreamSource(new FileReader(file)))
This looks relatively simple, but here’s the interesting part: the mechanism used is Java. If I was to write this code in Java, it would look almost identical. Unlike the XmlSlurper used for DTD validation, Groovy doesn’t add anything special to do schema validation. So you fall back on the Java approach and write it in Groovy. Because Groovy didn’t add anything, these lines could be written in either language, depending on your needs.
Still, Groovy normally does help, as most of the code in this appendix shows.
Whenever the issue of XML comes up these days, someone always asks about JSON support. I’ll address that issue in the next section.
B.9. JSON support
The trend in the industry has been away from XML and toward JavaScript Object Notation, known as JSON. If your client is written in JavaScript, JSON is a natural, because JSON objects are native to the language. Java doesn’t include a JSON parser, but several good libraries are available.
As of Groovy 1.8, Groovy includes a groovy.json package, which includes a JSON slurper and a JSON builder.
B.9.1. Slurping JSON
The groovy.json package includes a class called JsonSlurper. This class is not quite as versatile as the XmlSlurper class because it has fewer methods. It contains a parse method that takes a Reader as an argument, as well as a parseText method that takes a String.
A JSON object looks like a map inside curly braces. Parsing it results in a map in Groovy:
import groovy.json.JsonSlurper;
def slurper = new JsonSlurper()
def result = slurper.parseText('{"first":"Herman","last":"Munster"}')
assert result.first == 'Herman'
assert result.last == 'Munster'
Instantiate the slurper and call its parseText method, and the result is a map that can be accessed in the usual way, as shown. Lists work as well:
result = slurper.parseText(
'{"first":"Herman","last":"Munster","kids":["Eddie","Marilyn"]}')
assert result.kids == ['Eddie','Marilyn']
The two children wind up in an instance of ArrayList. You can also add numbers and even contained objects:
result = slurper.parseText(
'{"first":"Herman","last":"Munster","address":{"street":"1313 Mockingbird
Lane","city":"New York","state":"NY"},"wife":"Lily",
"age":34,"kids":["Eddie","Marilyn"]}')
result.with {
assert wife == 'Lily'
assert age == 34
assert address.street == '1313 Mockingbird Lane'
assert address.city == 'New York'
assert address.state == 'NY'
}
The age becomes an integer. The address object is also parsed into a map, whose properties are also available in the standard way. Here, by the way, I used the with method, which prepends whatever value it’s invoked on to the contained expressions. wife is short for result.wife, and so on.
If parsing is easy, building is also a simple operation, much like using MarkupBuilder.
B.9.2. Building JSON
I discussed builders earlier, and I use them throughout the book. In various chapters I use MarkupBuilder (shown in this chapter), SwingBuilder, and AntBuilder. Here I’ll illustrate the builder for generating JSON, called JsonBuilder.
The JsonBuilder class can be used with lists, maps, or methods. For example, here’s a trivial list:
import groovy.json.JsonBuilder; def builder = new JsonBuilder() def result = builder 1,2,3 assert result == [1, 2, 3]
This builder takes a list of numbers as an argument and builds a JSON object containing them. Here’s an example of using a map:
result = builder {
first 'Fred'
last 'Flintstone'
}
assert builder.toString() == '{"first":"Fred","last":"Flintstone"}'
The result is a standard JSON object (contained in braces), whose properties are the strings provided in the builder.
In the builder syntax you can use parentheses to build a contained object, so let’s continue on with the example:
result = builder.people {
person {
first 'Herman'
last 'Munster'
address(street:'1313 Mockingbird Lane',
city:'New York',state:'NY')
wife 'Lily'
age 34
kids 'Eddie','Marilyn'
}
}
assert builder.toString() ==
'{"people":{"person":{"first":"Herman","last":"Munster",' +
'"address":{"street":"1313 Mockingbird Lane",' +
'"city":"New York","state":"NY"},"wife":"Lily","age":34,' +
"kids":["Eddie","Marilyn"]}}}'
The generated JSON can get difficult to read, so the class adds a toPrettyString() method:
println builder.toPrettyString()
This results in nicely formatted output, as shown:
{
"people": {
"person": {
"first": "Herman",
"last": "Munster",
"address": {
"street": "1313 Mockingbird Lane",
"city": "New York",
"state": "NY"
},
"wife": "Lily",
"age": 34,
"kids": [
"Eddie",
"Marilyn"
]
}
}
}
JSON data is therefore almost as easy to manage as XML, both when creating it and when managing it.