
In this section, we will look at building an application to do sentiment analysis on text using the NLTK tools. There are several different options for how to direct NLTK to do sentiment analysis on text, so our experiments with these various methods will teach us a bit about what is going on inside NLTK and also about how sentiment analysis works.
You might recall that we installed and tested NLTK in Chapter 1, Expanding Your Data Mining Toolbox, and we used NLTK for entity matching back in Chapter 3, Entity Matching, so if you skipped those chapters, you may need to install or upgrade NLTK now. To do this from within Anaconda, open the Tools menu, select Open a terminal, and type:
conda upgrade nltk
This will fetch all the relevant NLTK packages and upgrade your Anaconda installation.
With this housekeeping task finished, we are ready to start thinking about what kind of sentiment analysis we want to experiment with. Throughout this book, we have been using data from free, libre, and open source software (FLOSS) development teams. Here, we will analyze some of their chat archives and e-mails for sentiment.
One nice thing about FLOSS development teams is that most, if not all, of their work is done in public. That includes posting source code and reporting bugs, but also most project chat and decision-making communication is done publicly as well. The reason is that the discussion and decision making that goes into writing and fixing the software is critical to understanding how the software works, and for getting new team members up to speed quickly. So, traditionally the communication channels in FLOSS development have been transparent, just like the code. This means that e-mail mailing lists are archived and posted publicly, Internet Relay Chat (IRC) discussion channels are archived and the logs made public, and so on. In fact, using Twitter or other so-called walled garden social media channels for conducting important discussions has been discouraged in some projects, as it tends to make archiving more difficult.
If we are able to collect and analyze the archived communications from some of these projects, we might be able to answer simple sentiment-oriented questions. Examples of sentiment-oriented questions would include whether the mood or tone of the developer-oriented chats differs from the tone observed in the user-oriented chats, whether some of the team members have a particular positive or negative speech style, or whether certain days, times, or topics elicit more emotional language. Are there any differences in the emotional level of developer and user IRC chat?
Our first step in completing such a project will be to construct two giant lists of sentences, one from a developer chat and one from an associated user chat. For the sake of running a coherent and manageable test, we will collect these chats from the same project, and we will limit ourselves to comparing chats from just one single day, at least for the time being. We will only use chat data from a project with publicly posted archives of the chat logs.
In the Ubuntu project, IRC chat dialogue is archived and available at http://irclogs.ubuntu.com. From that site, we chose Monday, April 4, 2016 as our target date. On this day, the #ubuntu-devel developers channel shows 516 lines in the archive file, including both 503 dialogue messages and 13 system status messages. For comparison, the channel for general users, known simply as #ubuntu, contains 1,717 lines, of which 84 are system messages and 1,633 are dialogue. The following table summarizes the differences between these two channels:
|
Developer Channel |
General User Channel | |
|---|---|---|
|
URL for text archive | ||
|
Lines in file (2016-04-04) |
516 |
1717 |
|
Number of system messages |
13 |
84 |
|
Number of dialogue messages |
503 |
1633 |
To begin to analyze the sentiment of these two groups of messages, we first have to do some rudimentary data cleaning. To see why, consider this snippet of a few lines from the #ubuntu-devel archive file:
[06:27] <dholbach> good morning [07:18] <mwhudson> yay https://launchpad.net/ubuntu/+source/docker.io/1.10.3-0ubuntu4 === seb128_ is now known as seb128 [09:38] <mardy> Mirv: hi! ping ping :-) [09:52] <Mirv> mardy: pong pong [09:52] <mardy> Mirv: red alert :-) Do you think we can get this fixed by 16.04? bug 1564767
The line that is preceded with === is a system message. These include no real valuable information for this project, and so we will remove these from the final data collection. Next, the timestamps are not relevant for our purposes here, and so these can also be removed. Likewise, the usernames that appear between <> indicate the speaker of the line, and so these can also be removed.
One convention on IRC is to direct your comments to a particular user by using their name and a colon, like this line in which the user Mirv is addressing another user mardy by name:
[09:52] <Mirv> mardy: pong pong
If we were worried that a person had a username like Happy, or Joy, or Ecstasy, we may give some thought to removing all usernames so as not to unintentionally bias the sentiment analyzer. However, in analyzing this particular set of IRC logs, I do not see enough of these types of names to worry. The vast, vast majority of usernames in the Ubuntu IRC channels are not even words, much less happy or sad words. One user is called infinity on the #ubuntu-devel channel and another user is called exalt on the #ubuntu channel. Other than these, the rest of the usernames are not dictionary words at all.
We can quickly and easily clean these files in a simple text editor or programmer's editor such as Text Wrangler. In Text Wrangler, the Find | Replace dialogue can be used with a grep expression to replace all timestamps and name prefixes. For example, we will want to remove beginnings of lines like this:
[09:52] <Mirv>
By leaving the Replace box empty, matching strings will be replaced with nothing. The grep string can be entered into Text Wrangler as shown in Figure 1. This regular expression finds lines that start with the [ character and removes everything from there to the first space following the > character.
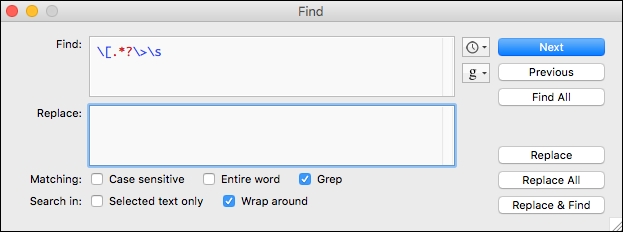
Figure 1. Text Wrangler regular expression to remove line prefixes
Following the removal of the line prefixes, we also need to remove the system messages. This can also be accomplished with the grep box in Text Wrangler as shown in Figure 2. This regular expression finds lines that start with three = characters and removes everything to the end of the line, plus any subsequent whitespace character.
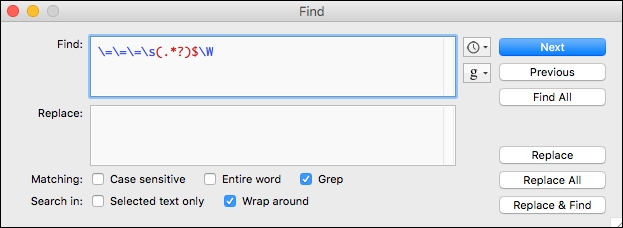
Figure 2. Text Wrangler regular expression to remove system messages
We should also remove the names that are found at the start of some of the lines. These are used to direct a message toward a particular reader, but these names do not really help us here since they are not part of the text that conveys sentiment. Figure 3 shows a regular expression to remove non-whitespace starting at the front of a line, followed by a colon and a space:
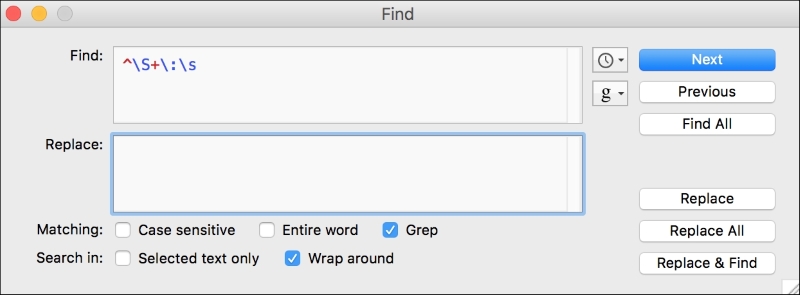
Figure 3. Text Wrangler regular expression to remove names and colon at front of line
We can also accomplish these same cleaning tasks in Anaconda Spyder if you are more comfortable working in that editor. First, read in the log file as a .txt file using the File | Open dialog, and then use the Search | Replace Text dialogue with the same regular expressions, as follows:

Figure 4. Spyder regular expression dialog box
To ensure that you are working in regular expression mode in the Replace dialogue box, make sure that you click the wheel icon to the right of the text box on the top line, shown in Figure 4.
Once you have completed these cleaning steps, you will have two files, consisting of dialogue from two different chat channels on the same day. Just in case you did not want to clean the data yourself, I have uploaded these files to the GitHub site for this book, available at https://github.com/megansquire/masteringDM/tree/master/ch5/data.
One thing to keep in mind before we get started in earnest with this project is that in sentiment analysis, the text is usually analyzed at the sentence level. However, most chat dialogue is not very well-punctuated, and may contain many partial sentences and many run-on sentences. Also, text tokenizers will split paragraphs into sentences based on the period character ('.'), but chat dialogue is replete with periods used in other ways, and many sentences do not even end in periods at all. This all means that dealing with chat text can be challenging.
For example, consider the following lines from the #ubuntu-devel chat:
maybe look through http://code.qt.io/cgit/qt/qtbase.git/ log/src/plugins/platforms/xcb/qxcbwindow.cpp too if there's something to backport instead of your patch but are they still interested in Qt 5.5? no, they'd be interested in 5.6 though if it's affected by the same bug and most likely 5.6 branch is the best place to offer a fix too in, they merge from there to 5.7 and dev. I'll now test 5.6, but looking at their code, I believe they've already fixed it the problem is, it's not just one patch to backport, but many ok, to me it'd look like the line of code in question is still unchanged, just a variable name changed. but maybe it was fixed elsewhere? we actually have a lot of XCB fixes already in, in order to try to fix multi-monitor issues that plagued 5.5 still (and maybe even 5.6 still too). but at this point I'd tend to agree that if it's yet another multiple patches, it would be better to take your two-liner patch instead yes, that function is still there in Qt 5.6, but handleConfigureNotifyEvent() doesn't call that method anymore :-)
Some of the challenging parts of this text are:
- Only one of the lines is punctuated by a period, and one by a question mark
- Capitalization does not necessarily indicate a start of a sentence
- There is a URL, which contains many periods, and several version numbers, which also contain periods
- There is a function name that uses parentheses, but also a parenthetical expression, and an emoticon smiley that uses a right parenthesis
The best sentiment techniques available now will try to take parts of speech and sentence placement into account, as well as punctuation. For example, the Vader tool discussed earlier gives the following examples in its documentation:
VADER is smart, handsome, and funny. compound: 0.8316, neg: 0.0, neu: 0.254, pos: 0.746, VADER is smart, handsome, and funny! compound: 0.8439, neg: 0.0, neu: 0.248, pos: 0.752,
Positive, negative, and neutral scores are given as percentages that add up to 1. The first sentence is scored as 74.6% positive and 25.4% neutral, but the second one, with the addition of an exclamation point, is scored slightly higher, at 75.2% positive. The compound score is the normalized sum of the positive and negative scores after punctuation emphasis points have been added and scores amplified accordingly. In the Vader source code, the compound is calculated on these scores as:
compound = score/math.sqrt((score*score) + alpha)
The alpha value is set to 15 in the Vader code. Alpha is described as a value that approximates the max expected value.
So, if we are considering using an off-the-shelf, pre-trained sentiment analyzer such as Vader, we will need to make the executive decision about how to handle our lines with weird punctuation and incomplete sentences. We can treat each line as a separate sentence, but we need to know that the shortcoming of this is that the sentences might not be grammatically correct and still may contain many URLs and strange words, acronyms, usernames, function names, code snippets, and so forth. Remember that most pre-trained sentiment analyzers, such as Vader, have been trained on tweets, or on English sentences such as in movie or product reviews. These pre-trained sentiment analyzers also use part-of-speech information and punctuation to help decide whether a string is positive or negative. Depending on how similar our dialogue lines are to the training dialogue, Vader may interpret our sentences differently from what we are expecting.
There is only one way to find out whether Vader will work with our data. It is time to run some experiments with NLTK and Vader a bit and see what it does with our chat data.
Let's write a short program to read in one of our files of chat text, and for the first few lines, determine the sentiment score (positive, negative, and neutral), as well as what the compound value is for that line. The code for this program is available on the GitHub site for this book at https://github.com/megansquire/masteringDM/blob/master/ch5/scoreSentences.py:
from nltk.sentiment.vader import SentimentIntensityAnalyzer
with open('ubuntu.txt', encoding='utf-8') as ubuntu:
ubuntuLines = [line.strip() for line in ubuntu.readlines()]
ubuntu.close()
sid = SentimentIntensityAnalyzer()
finalScore = 0
# just print the first 20 lines of the chat log & scores
for line in ubuntuLines[0:20]:
print(line)
ss = sid.polarity_scores(line)
for k in sorted(ss):
print(' {0}: {1}
'.format(k,ss[k]), end='')
print()From this set of lines, we can see that the majority of sentences are scored as 100% neutral. Some examples of neutral scoring lines that occur near the beginning of the file are:
which ubuntu release? compound: 0.0 neg: 0.0 neu: 1.0 pos: 0.0 Hi! Is there any software on Ubuntu that can replace Itunes for syncing files on the Ipod? compound: 0.0 neg: 0.0 neu: 1.0 pos: 0.0
Not nearly as many lines are scored on the negative side, for example these:
no its not compound: -0.296 neg: 0.524 neu: 0.476 pos: 0.0 this is so ridiculous compound: -0.5009 neg: 0.519 neu: 0.481 pos: 0.0
There are a few clearly positive comments, which are scored accordingly:
that would be awesome, really compound: 0.6249 neg: 0.0 neu: 0.494 pos: 0.506 different people like different support media compound: 0.6369 neg: 0.0 neu: 0.435 pos: 0.565 ok thanks compound: 0.6249 neg: 0.0 neu: 0.0 pos: 1.0
We should remember that the compound score is normalized using only the sum of the positive and negative scores, so the compound score can occasionally be calculated as higher than a positive score, or lower than a negative score. In the case of the sentence different people like different support media, the compound score ended up being .6369 while the positive score was only .5650.
If we wanted to test whether the general #ubuntu chat channel was more negative or positive on that day than the #ubuntu-devel chat channel, we could calculate sentiment for all the lines in each, sum the compound scores, and divide by the number of messages. The code for the following example is available at https://github.com/megansquire/masteringDM/blob/master/ch5/sumCompounds.py:
from nltk.sentiment.vader import SentimentIntensityAnalyzer
with open('ubuntu.txt', encoding='utf-8') as ubuntu:
ubuntuLines = [line.strip() for line in ubuntu.readlines()]
ubuntu.close()
with open('ubuntu-devel.txt', encoding='utf-8') as ubuntuDevel:
ubuntuDevelLines = [line.strip() for line in ubuntuDevel.readlines()]
ubuntuDevel.close()
listOfChannels = [ubuntuLines,ubuntuDevelLines]
sid = SentimentIntensityAnalyzer()
for channel in listOfChannels:
finalScore = 0
for line in channel:
ss = sid.polarity_scores(line)
score = ss['compound']
finalScore = finalScore + score
roundedFinalScore = round(finalScore/len(channel),4)
print("Score", roundedFinalScore)The results print a score for the #ubuntu and #ubuntu-devel channels in turn:
Score 0.0774 Score 0.1012
We should be cautious about trying to read too much into these results or any results of sentiment analysis, actually since we already determined that our pre-trained examples are from a different domain. At the very least, we should be straightforward about the limitations of this approach. From these results, it appears that the #ubuntu-devel channel reached a slightly higher score, or a marginally more positive score, than the general chat channel did.
Another interesting test for sentiment analysis would be to see how it handles e-mail messages. E-mails tend to be longer and have more text in them than IRC chat messages. Another difference with e-mail messages is that they typically tend to include punctuation, whereas IRC messages may not, and the punctuation in e-mails is used in a more predictable way. Since systems like Vader do use punctuation to infer emphasis, we may find that it performs differently on e-mails than it does on chat.
To test our sentiment analysis technique on e-mails, we decided to look at a single e-mail user who is known for his very emotionally charged speech style: Linus Torvalds, the eponymous leader of the Linux project. Torvalds started Linux as a free (and later, open source) operating system in the early 1990s, and has been its leader since. The development of this project has been conducted entirely on an e-mail mailing list called the Linux Kernel Mailing List (LKML). In its 20-plus-year history, the LKML has amassed millions of messages from tens of thousands of users and developers. Torvalds himself writes and responds to thousands of messages per year, and his brash writing style in these messages has been the subject of many news articles. The website, Reddit even has an entire section devoted to his rants, called linusrants, available at https://www.reddit.com/r/linusrants.
Since Torvalds' e-mails are longer than chat text, highly emotive, and usually properly punctuated, it will be an interesting test for the sentiment analyzer to see if it can score these e-mails more easily than the chat messages. Can the sentiment analyzer help us find the most brash, forceful, or strident e-mails that Torvalds wrote? To do this, we will first need a text collection of Torvalds' public e-mails sent to the LKML. Luckily for us, one of my former students, Daniel Schneider, built a very large collection of LKML e-mails which he donated to the FLOSSmole project for research purposes. One particular advantage of this e-mail collection is that all the messages have been cleaned thoroughly to support text mining. Specifically, he removed as many reply texts, signature lines, and source code lines from the e-mails as possible, leaving us with a collection that includes only the words written by the e-mail sender.
For our purposes in this chapter, I have extracted a small selection of e-mails from the collection, namely the e-mails from Linus Torvalds that were sent to the LKML during the month of January 2016. There are 78 e-mails in this subset. The following code will CREATE a simple MySQL table to hold the e-mails, and both the CREATE and INSERT statements are available at https://github.com/megansquire/masteringDM/tree/master/ch5/data/lkmlLT2016-01:
CREATE TABLE IF NOT EXISTS `lkml_ch5` ( `url` varchar(200) COLLATE utf8_unicode_ci NOT NULL DEFAULT '', `sender` varchar(100) COLLATE utf8_unicode_ci NOT NULL, `datesent` datetime NOT NULL, `body` text COLLATE utf8_unicode_ci NOT NULL, `sentiment_score` decimal(6,4) DEFAULT NULL, `max_pos_score` decimal(6,4) DEFAULT NULL, `max_neg_score` decimal(6,4) DEFAULT NULL, PRIMARY KEY (`url`)) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
The url column is the primary key for this table, and points to the original link to that e-mail message at the Indiana University LKML archive. In this small collection of 78 e-mails, the sender column will only ever include one person, Linus Torvalds. The datesent column holds the original date and time from the e-mail message. The body of the e-mail holds the remaining text after the reply text, source code, and signatures have been removed. We also stripped out carriage returns and newlines from this text, as well as any HTML artifacts that were left in the message from when we downloaded it from the Indiana University web archive.
The remaining three columns are calculated fields whose values will come from our sentiment analysis process. Recall that Vader calculates a percent positive, percent negative, and percent neutral sentiment score for each sentence, as well as a compound, adjusted score for each sentence. Since these e-mails are made up of many sentences, we elected to calculate and store three values at the e-mail level:
- We calculate an average compound score for each e-mail
- We store the highest positive score for any sentence in the e-mail
- We store the highest negative score for any sentence in the e-mail
Storing all of these values ensures that an e-mail with one highly negative sentence can still be detected and evaluated, even if the average compound scores for the e-mail were unremarkable.
The following is the code to sentiment analyze the Torvalds e-mails. We begin by importing our required libraries and connecting to the database.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk import tokenize
import pymysql
import sys
password = sys.argv[1]
db = pymysql.connect(host='localhost',
db='test',
user='megan',
passwd=password,
port=3306,
charset='utf8mb4')
selectCursor = db.cursor()
updateCursor = db.cursor()We then set up our SELECT and UPDATE queries. We run the SELECT query and fetch all the records:
selectEmailQuery = "SELECT url, body FROM lkml_ch5"
updateScoreQuery = "UPDATE lkml_ch5
SET sentiment_score = %s,
max_pos_score = %s,
max_neg_score = %s
WHERE url = %s"
selectCursor.execute(selectEmailQuery)
emails = selectCursor.fetchall()Next we start a loop through each of the e-mails returned from the SELECT:
for email in emails: url = email[0] body = email[1] # variables to hold overall average compound score for message finalScore = 0 roundedFinalScore = 0 # variables to hold the highest positive score in the message # and highest negative score in the message maxPosScore = 0 maxNegScore = 0
The next bit of code sets up the Vader sentiment analyzer, tokenizes each e-mail into sentences, and for each sentence, figures out the polarity of that sentence. The code then builds a final score comprised of the compound sentence scores, and keeps track of the highest positive and negative score for any sentence in the e-mail:
print("===")
sid = SentimentIntensityAnalyzer()
emailLines = tokenize.sent_tokenize(body)
for line in emailLines:
ss = sid.polarity_scores(line)
line = line.replace('
', ' ').replace('
', '')
print(line)
for k in sorted(ss):
print(' {0}: {1}
'.format(k,ss[k]), end='')
lineCompoundScore = ss['compound']
finalScore += lineCompoundScore
if ss['pos'] > maxPosScore:
maxPosScore = ss['pos']
elif ss['neg'] > maxNegScore:
maxNegScore = ss['neg']The final portion of the code just calculates the average compound score by dividing the sum of all the compounds by how many sentences were in the e-mail. We print the scores, update the database, and close our database connection:
# calculate avg compound score for the entire message
roundedFinalScore = round(finalScore/len(emailLines),4)
print("***Final Email Score", roundedFinalScore)
print("Most Positive Sentence Score:", maxPosScore)
print("Most Negative Sentence Score:", maxNegScore)
# update table with calculated fields
try:
updateCursor.execute(updateScoreQuery,(roundedFinalScore,
maxPosScore, maxNegScore, url))
db.commit()
except:
db.rollback()
db.close()When this code runs, it updates the database table with the three values we are most interested in: the overall average sentiment compound score for each e-mail, as well as the highest negative score and highest positive score for every e-mail.
From the 78 e-mails and their scores then, how do we determine the most interesting e-mails to look at, from a sentiment point of view? For instance, what if we wanted to find the messages that were the most negative? If we sort by the sentiment score alone, we might miss some messages that have one or two really negative sentences, but on the whole appear to have a mediocre negativity score. Alternatively, if we sort only by the max_neg_score column, we will see a lot of messages that have the word No. in them, but all the remaining text could be fairly innocuous.
One approach would be to find messages that scored low (negative) on an average compound e-mail score, and which also have one or more highly negative sentences. To do this, first we need to create a set of e-mails with the lowest (most negative) sentiment score. Then, we need a set of e-mails which have at least one very negative sentence. The intersection of these two sets represents a group of messages that should be very interesting in their negativity. If we limit our search to the top 20 in both sets, which messages appear in both lists?
Since MySQL does not have the INTERSECT keyword, but does support a UNION ALL with a subquery, we can construct a clunky-but-functional SQL command to return the intersection of the top 20 messages in both sets as follows:
SELECT a.url, a.body, a.sentiment_score, a.max_neg_score, COUNT(*)
FROM(
(SELECT b.url, b.body, b.sentiment_score, b.max_neg_score
FROM `lkml_stripped_torvalds_2016_01` AS b
ORDER BY b.sentiment_score ASC
LIMIT 20)
UNION ALL
(SELECT c.url, c.body, c.sentiment_score, c.max_neg_score
FROM `lkml_stripped_torvalds_2016_01` AS c
ORDER BY c.max_neg_score DESC
LIMIT 20)) AS a
GROUP BY 1,2,3,4
HAVING COUNT(*) > 1;This query finds the top 20 in one set and the top 20 from the other set, and shows that there are 10 messages that appear in both sets. Figure 5 shows a screen capture of the results from this query, as displayed in the PhpMyAdmin query tool. For space reasons, I truncated the URL column to only show the rightmost 10 characters:
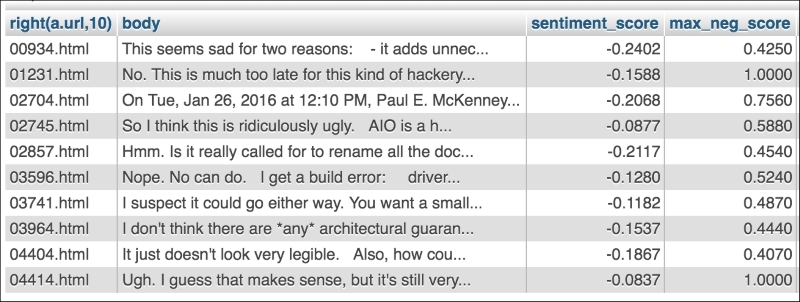
Figure 5. The 10 records in both the top 20 sentiment_score and the top 20 max_neg_score
When these 10 messages are sorted by the overall sentiment score, the most negative message is 934.html, which has a sentiment_score of -0.2402 and a max_neg_score of 0.4250 (or one sentence that scored 42.5% negative). Here is the text of the message:
This seems sad for two reasons: - it adds unnecessary overhead on non-pcid setups (32-bit being an example of that) - on pcid setups, wouldn't invpcid_flush_single_context() be better? So on the whole I hate it.Why isn't this something like And yes, that means that we'd require X86_FEATURE_INVPCID in order to use X86_FEATURE_PCID, but that seems fine. Or is there some reason you wanted the odd flags version? If so, that should be documented.
The sentence that scored the 42.5% negative was So on the whole I hate it. One sentence appears to be incomplete due to removing source code (Why isn't this something like…) It is interesting that the most negative sentence in that e-mail only scores a 42.5% and this is still high enough to make the top 20 list. When we look at the second-highest scoring message, sorted by the sentiment score, we see that this one happened to score a perfect 100% for max_neg_score. Why? The text of that message is as follows:
No. This is much too late for this kind of hackery. That second patch in particular is both subtle and ugly, and is messing with lockdep. No way will I take something like this the last fay [sic] before a release. It's not even a regression, nor did you send me anything at all for this release. Trying to sneak something in just before 4.4 is not ok.
This one had a sentiment_score of -0.1588. The max_neg_score of 100% was for the sentence No.
At this point we have the ability to analyze the sentiment of various types of text, including short bursts of chat text and longer e-mail messages. We have a good understanding of what the scores mean, how to compare them, and how to figure out what the interesting messages are. So far we have only used the Vader sentiment intensity analyzer that came with NLTK, but if we wanted to continue this experiment with other sentiment tools, I would recommend looking at the NLTK documentation to see what other options are available and how to use them. The documentation page about sentiment is a great place to start: http://www.nltk.org/api/nltk.sentiment.html.