

CHAPTER
3
Introduction to Streams and Pipelines
In Chapter 1 we saw two main themes in the motivations for introducing lambdas to Java. These two themes—better code and easier parallelism—come together in the introduction of streams for processing collections. Although lambda expressions are (in practice) essential for programming with streams, they are not enough: to use streams effectively, we need some new ideas specific to the programming model that they enable. In this chapter, we’ll explore the basic ideas underlying streams, with relatively straightforward examples of stream operations that should help to develop a basic intuition about how they work. In later chapters, we will go further, exploring some more theoretical topics, seeing how stream code can simplify common collection processing tasks, and finally investigating the performance of sequential and parallel streams in different situations.
The individual stream operations that we will learn about may not seem very powerful on their own. The power of the Stream API lies in the possibilities that are created by composing these operations together. In this, its design draws on long historical precedent in computing. One of its closest antecedents is the so-called “Unix philosophy,” of which the authors of The Unix Programming Environment (Kernighan and Pike, 1984) wrote
At its heart is the idea that the power of a system comes more from the relationships among programs than from the programs themselves. Many UNIX programs do quite trivial things in isolation, but, combined with other programs, become general and useful tools.
If you are familiar with the realization of that philosophy in the Unix pipeline, you will see that reflected clearly in the intermediate operations of streams. But, more broadly, the principle of composability was central throughout the design of the Java 8 changes: in §1.4 we saw how lambda expressions enable the design of finer-grained, more composable operations, and later we will see its influence in the design of stream collectors.
In following the trail that takes us through the technical detail of streams, we should be sure not to lose sight of their fundamental justification: the more expressive formulation of common aggregate operations. The success of the stream mechanism will be assessed by how far it achieves the goal of clearer expression of common business logic.
3.1 Stream Fundamentals
Streams were introduced in §1.2 as optionally ordered value sequences. In operational terms, they differ from collections in that they do not store values; their purpose is to process them. For example, consider a stream having a collection as its source: creating it causes no data to flow; when values are required by the terminal operation, the stream provides them by pulling them from the collection; finally, when all the collection values have been provided by the stream, it is exhausted and cannot be used any further. But this is not the same as being empty; streams never hold values at any point. Streams with non-collection sources behave very similarly: for example, we could generate and print the first ten powers of two by means of the following code:

Although, as we will see later, the method iterate generates an infinite stream, the function represented by the lambda is called only as often—in this case, nine times—as a value is required for downstream processing.
The central idea behind streams is lazy evaluation: no value is ever computed until it is required. Java programmers already know about laziness:1 iterators, which we use every day—explicitly or implicitly—have this characteristic. Creation of an iterator doesn’t cause any value processing to take place; only a call to its next method makes it actually return values from its collection. Streams are conceptually quite similar to iterators, but with important improvements:
• They handle exhaustion in a more client-friendly way. Iterators can signal exhaustion only by returning false from a hasNext call, so clients must test for it each time they require an element. This interaction is inherently fault-prone, because the time gap between the call of hasNext and next is a window of opportunity for thread interference. Moreover, it forces element processing into a sequential straitjacket, implemented by a complex and often inefficient interaction between client and library.
• Unlike iterators, which always yield their values in a deterministic sequence, streams can be unordered. We’ll explore this in detail in Chapter 6; for the moment, all you need to know is that opportunities for optimizing a parallel stream arise when we are unconcerned about the order in which its values are presented.
• They have methods (the intermediate operations) that accept behavioral parameters—transformations on streams—and return the stream resulting from the transformation. This allows streams to be chained together into pipelines, as we saw in Chapter 1, providing not only a fluent style of programming, but also the opportunity of big performance gains. We’ll study intermediate operations in detail later in this chapter.
• They retain information about the properties of their source—for example, whether the source values are ordered, or whether their count is known—that allows optimizations of value processing in ways not possible with iterators, which retain no information besides the values themselves.
One big advantage of lazy evaluation can be seen in the “search” methods of Stream: findFirst, findAny, anyMatch, allMatch, and noneMatch. These are called “short-circuit” operators because they often make it unnecessary to process all the elements of a stream. For example, anyMatch has to find only a single stream element that satisfies its predicate (boolean-valued function) for stream processing to be complete, just as allMatch has only to find one that fails to satisfy its predicate. The ability to avoid generating and processing unnecessary elements can obviously save a great deal of work—and, in the case of infinite streams, it is only the combination of lazy evaluation and short-circuit operators that makes it possible to complete stream processing at all. True, this advantage of lazy evaluation can also, in principle, be realized by iterators (in the case of collections processing) or explicit looping (in the case of generator functions), but code using the Stream API is much easier to read and (eventually) to write.
Lazy evaluation provides another major advantage: it allows multiple logical operations to be fused together into a single pass on the data. Recall the code developed in Chapter 1 to first illustrate the idea of a pipeline:

The fluent style is natural and easy to read, but to understand what is happening you need to bear in mind the implication of lazy evaluation. It is easier to see this if, for demonstration purposes, the pipeline is broken into a stream declaration and the terminal operation call:

Separating out the terminal operation call clarifies the situation: it is directly calling the transformational code of the behavioral parameters, which is all executed in a single pass. Moreover, because for each element these operations are executed by a single thread, optimizations that depend on code and data locality can operate.
This is a very different model from bulk collection processing, which is normally implemented by a series of passes, each one transforming every element of a collection and storing the results in a new one. In Chapter 1 we saw how a sequence of loops (e.g., p. 10) can be translated into an equivalent sequence of stream operations (p. 12). The stream code is both pithier and more efficient (as reported on p. 148), because it is implemented by fusing the separate loop operations.
3.1.1 Parallel-Ready Code
Lazy value sequences are a very old idea in programming; what distinguishes their implementation in Java is the extension of this concept to include parallel processing of their elements. Although sequential processing is still a very important model for computing, it is no longer the unique reference model: as Chapter 1 explained, parallel processing has become so important that we have to rethink our model of computation towards one that results in code that is agnostic about how it is executed, whether sequentially or in parallel. In that way, both our code—and even more importantly, our coding style—is insured against the need to change when, in the future, the balance of advantage tilts towards parallel execution. The Stream API encourages this view; a key to understanding it is the insight that all operations are defined to have equivalent effect in sequential and in parallel modes, provided that the programmer follows some simple rules. In fact, this way of thinking about processing modes could be deduced from the choice of the single Stream interface to represent both sequential and parallel streams; the API designers explored the idea of providing sequential-only and parallel-only methods in separate interfaces, and rejected it.
Notice that this definitely does not mean operations will always produce exactly the same result in each mode: forEach, for example, is explicitly allowed to execute in nondeterministic order. In sequential mode it may preserve ordering, by happy accident of the implementation, but it is a mistake to depend on this; forEach and other nondeterministic operations are equally nondeterministic in sequential and in parallel mode. Conversely, an operation that is defined to be deterministic in either mode is guaranteed to work deterministically in both. The motivation for providing nondeterministic operations like forEach is provided by situations where unnecessary determinism has a significant performance cost.2 Choosing a deterministic alternative, like forEachOrdered, requires a conscious judgement that ordering is a requirement of the problem, rather than just an accidental by-product of the implementation.
This insight also helps to explain the choice of operations defined in the API, which avoids any that could not be implemented equally well in sequential and parallel modes. Some “obvious” operations conceal a deep sequential bias—for example, the “takeWhile” operation, which on other platforms processes a stream until it encounters a sentinel value. While this operation is not actually infeasible in parallel, its implementation would have been so expensive—both in design and execution—that it was deprioritized.
This change in thinking can be reframed: programs with iteration contain two different kinds of information: what is to be done, and how it is to be done. Decoupling these two kinds of content leads to a development model in which we write parallel-ready code specifying functional behavior alone, and then separately specify its execution mode—ideally, delegating the implementation of the execution to a library. This is a big change: for many of us, the sequential model is so deeply ingrained that it will take an effort to adjust to the implications of dethroning it. But that effort will be worthwhile; not only will the resulting programs be future-proof, but our code will be clearer, more concise, and more maintainable.
3.1.2 Primitive Streams
The introduction of auto-boxing and -unboxing in Java 5 gave programmers some license to ignore the difference between values of a primitive type and those of the corresponding wrapper type. The compiler can often detect that a primitive value is being supplied in a method call or assignment in place of a wrapper value (or vice versa) and will insert the appropriate conversion. This is convenient and often gives rise to more readable programs; generic collection classes can now appear to contain primitive values, and wrapper types fit much better than do primitives with Java’s basic object-oriented programming model. But it can lead to repeated boxing and unboxing operations, with high performance costs. For example, incrementing the variable i in the innocent-looking code

involves executing the Integer methods intValue and valueOf, respectively, before and after every addition. We would like to avoid such overheads in applications that process large collections of values; one way of doing this is to define streams whose elements are already primitive rather than reference values. This decision brings advantages besides improved performance, in the form of useful numeric-only methods like sum and the ability to create streams containing ranges of numbers. For example, using the type IntStream, representing a stream of primitive int values, the preceding code can be rewritten:

The improvements here are both in readability, with specialized range and max methods, and in efficiency, with no requirement for boxing and unboxing. §6.6 reports the performance difference between these two code fragments, for various range sizes. For sufficiently large data sets, the unboxed code is an order of magnitude faster.
The primitive stream types are IntStream, LongStream, and DoubleStream—chosen as the most commonly used numeric types, the ones for which the cost-benefit trade-off was most favorable. In case your application requires streams of one of the other numeric types, these are also supported: float values can be embedded in a DoubleStream, and char, short, and byte values in an IntStream. The APIs of the primitive streams are very similar to one another, and all are sufficiently similar to the reference stream type Stream to be discussed together in this chapter. As a preliminary, it is worth noting the possible stream type interconversions:
• The primitive stream types IntStream and LongStream have methods asDoubleStream and (for IntStream) asLongStream, which apply the appropriate widening coercion to each primitive value, for example:
DoubleStream ds = IntStream.rangeClosed(1, 10).asDoubleStream();
• For boxing, each of the primitive stream types has a method boxed, which returns a Stream of the appropriate wrapper type, for example:
Stream<Integer> is = IntStream.rangeClosed(1, 10).boxed();
• For unboxing, a Stream of wrapper values can be converted to a primitive stream by calling the appropriate map conversion operations (which we will see in more detail later in this section), supplying the appropriate unboxing method. For example, the following code creates a Stream<Integer>, then converts it to an IntStream:
Stream<Integer> integerStream = Stream.of(1, 2);
IntStream intStream = integerStream.mapToInt(Integer::intValue);
3.2 Anatomy of a Pipeline
The full power of streams is realized by the pipelines we create by composing them together. We have seen examples of the various stages of a pipeline: its origin in a stream source, its successive transformations through intermediate operations, and its ending in a terminal operation. In the remainder of this chapter we will look at each of these stages closely enough to build an intuition for the possibilities of stream programming; subsequent chapters will explore the features that give them their full power.
3.2.1 Starting Pipelines
Up to this point, the data for our stream processing examples have been drawn from collections. In fact, since the advantages of the stream processing model apply to all kinds of bulk data, many classes in the platform library that can produce bulk data can now also create streams supplying that data. However, in this chapter we are mainly concerned with gaining an intuition of how streams work, so the complete list of stream-creating methods in the platform library is delayed to Chapter 5. For now, all that we need are the stream-bearing methods of Collection and the factory methods in the stream interfaces:
• java.util.Collection<T>: The default methods on this interface will probably be the most commonly used ways of generating streams:3

The contract for parallelStream actually states that its return is a “possibly parallel Stream.” As we will see, it is the collection’s responsibility to present its data in parallel, and not every collection can achieve that. Although this will affect performance, it has no impact on functional behavior. We will explore this issue fully in Chapter 6.
• java.util.stream.Stream<T>: This interface exposes a number of static factory methods, with default implementations. In this chapter, we shall be using Stream.empty and two overloads of Stream.of (the primitive stream types have analogous methods):
These methods are enough to start our exploration of the features of streams and pipelines; in Chapter 5 we will investigate other stream-bearing methods of the platform libraries.
3.2.2 Transforming Pipelines
Following stream creation, the next stage of a pipeline consists of a number (possibly zero) of intermediate operations. As we have seen, intermediate operations are lazy: they only compute values as required by the eager operation that terminates the pipeline.
This and the following two chapters explore the Stream API with examples of its use on a tiny example domain. I’ve just moved to an apartment with enough bookshelf space to allow me to organize my collection of a few hundred books haphazardly acquired over the last several decades. The system I’m planning will model this library as a Collection of Book objects:

To understand the examples, the properties need some explanation:
• Topic is an enum, with members HISTORY, PROGRAMMING, and so on.
• The property pageCounts refers to the page counts of the volumes that comprise multi-volume titles. It has been given an array type, not to recommend the use of arrays—for most purposes, Java arrays should be regarded as a legacy type, to be replaced by List implementations where possible—but because arrays of primitive types are still often encountered in maintaining legacy code, and we need to become familiar with the stream idioms for processing them.
• Multiple editions of a book, all with the same title and authors, can coexist in the library if they have different publication dates.
• The physical height of a book is important to me; my built-in bookshelves have different heights, so I will need to take book heights into account when I’m deciding where to shelve the different topics.
In exploring the different stream operations, it will be useful to have a few concrete examples to focus on. Here are declarations for three books from my library:
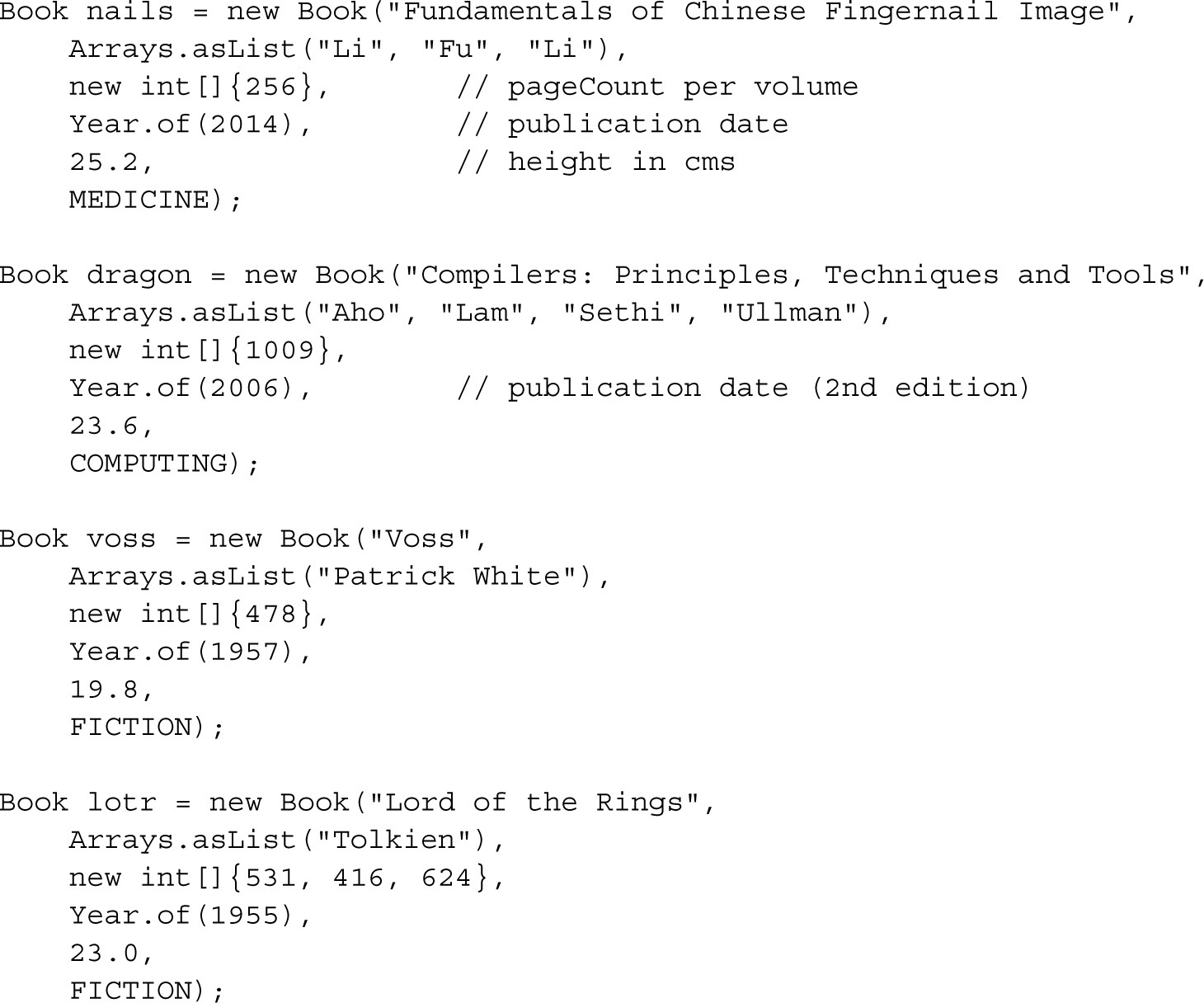
In the examples that follow, a real-life persistence mechanism has been replaced by a placeholder variable library, declared as a List<Book>. Figure 3-1 presents examples of code using streams to process my library; they are all explained later in this chapter, but are collected together here to give you an idea of what is possible using stream processing.

FIGURE 3-1. Examples of Stream operations from this chapter
This section will explore the action of the various intermediate operations by looking at examples of how each could be used in operations to process my library. Although it will mainly discuss operations on the reference stream type Stream, the ideas carry over to primitive stream types also; for intermediate operations, their API closely resembles that of Stream.
Filtering
The method filter allows selective processing of stream elements:
Its output is a stream containing only those elements of the input stream that satisfy the supplied Predicate (p. 29). For example, we could isolate the computing books in my collection by constructing this stream:
![]()
Figure 3-2 illustrates the action of filter. In part (a) two Book elements are arriving on the input stream: nails, followed by dragon; in part (b) the output stream contains only dragon, as that is the only one whose topic is COMPUTING.
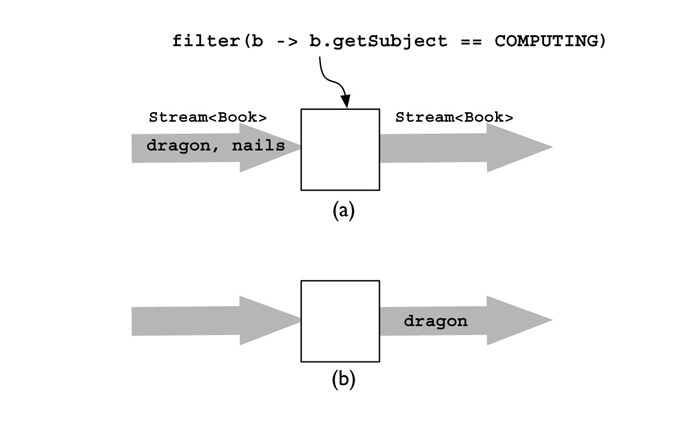
FIGURE 3-2. How Stream.filter works
Mapping
The method map transforms each stream element individually using the supplied Function<T,R> (p. 29):

Its output is a stream containing the results of applying the Function to each element of the input stream. For example, it could be used to create a Stream of publication dates:
![]()
Figure 3-3 illustrates the action of map. In part (a) the input elements are the same two Book instances; in part (b) the resulting stream contains references to the Year objects obtained by calling getPubDate on each instance.
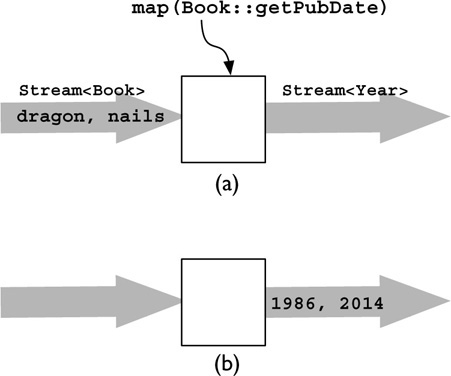
FIGURE 3-3. How Stream.map works
The methods mapToInt, mapToLong, and mapToDouble correspond to map. They convert reference type streams to primitive streams using instances of ToIntFunction<T>, ToLongFunction<T>, or ToDoubleFunction<T>, each of which take a T and return a primitive value:

On p. 49 we saw that these methods can be used to unbox a stream of wrapper values. For another example, I could count the total number of authorships (defining an authorship as the contribution of an author to a book) of all books in my library like this:

Converting to primitive streams in this way allows us to take advantage of their better performance and of their specialized arithmetic terminal operations, like sum.
The Stream API supports interconversion between each of the four Stream types. So, besides the Stream methods discussed here, each of the primitive streams has three conversion map operations, one for each of the three other types. For example, IntStream has, besides map, conversion operations mapToLong, mapToDouble, and mapToObj.
One-to-Many Mapping
An alternative (though less efficient) way of implementing the last example would be to convert the stream of Book into a stream of Author, each one representing an authorship. We could then simply apply the terminal operation count to find the number of elements in the stream. But map isn’t suitable for this purpose, because it performs a one-to-one transformation on elements of the input stream whereas this problem requires a single Book to be transformed to several Author elements in the output stream. The operation we need will map each Book into a stream of Author—writing, say, book.getAuthors().stream()—then flatten the resulting series of streams into a single stream of Author for all books. That is the operation flatMap:

For this example we would write:
![]()
Figure 3-4 shows how it works. In part (a) the same two Book instances are on the input stream, in (b) each is mapped to a stream of String, and in (c) these individual streams are fed into the output stream.
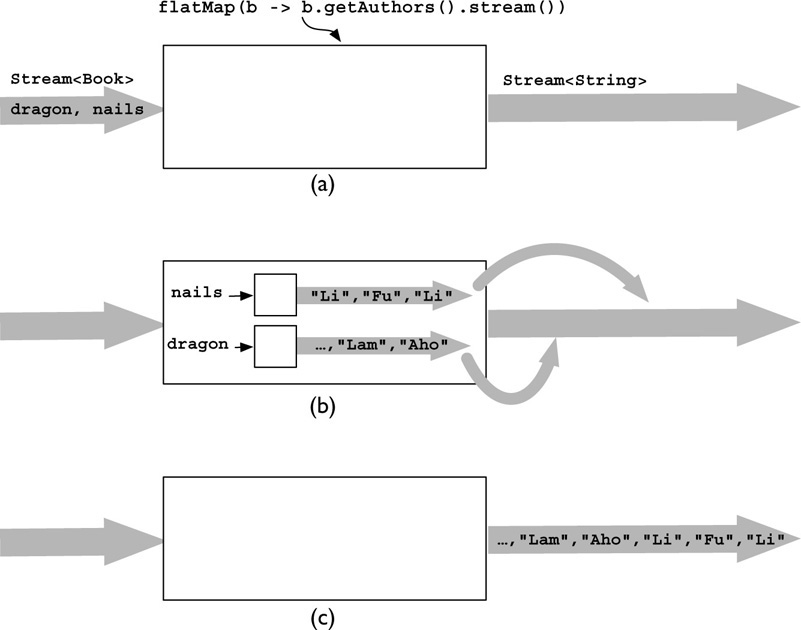
FIGURE 3-4. How Stream.flatMap works
Like the methods corresponding to map for conversion to primitive streams, there are primitive conversion methods: flatMapToInt, flatMapToLong, and flatMapToDouble. For example, we could get the total page count of all volumes of all books by creating an individual IntStream for each Book using IntStream.of and then concatenating them using flatMapToInt:

The primitive stream types have only flatMap; there are no type conversion flat-mapping operations.
Debugging
As we saw in §3.1, calling the terminal operation of a pipeline results in the execution of a fusion of its intermediate operations. As a result, the usual debugging technique of stepping through operations is not available for streams. The alternative provided by the Stream API, the operation peek, differs from other intermediate operations in that the output stream contains the same elements, and in the same order, as the input stream. The purpose of peek is to allow processing to be carried out on elements of streams that are intermediate in a pipeline; for example, we could print the title of every book that passes a filter before sending them downstream for further processing (in this case, accumulating them to a List: see §3.2.4):

If you are familiar with Unix pipelines, you will recognize the similarity to tee, though peek is more general, accepting any appropriately typed Consumer as its argument. This method was provided to support debugging and, because it works by means of side-effects, should not be used for any other purpose. The issues of side-effects and interference are explored in §3.2.3.
Sorting and Deduplicating
The operation sorted behaves as we would expect: the output stream contains the elements of the input stream in sorted order.

The sorting algorithm is stable on streams having an encounter order (see Chapter 6); this means that when ordered streams are sorted, the relative order of elements with equal keys will be maintained between the input and the output.
The first sorted overload sorts objects using their natural order (footnote, p. 15). For example, we might use it to create a stream of Book titles, sorted alphabetically:

The second overload accepts a Comparator; for example, the static method Comparator.comparing (p. 16) creates a Comparator from a key extractor:
![]()
This provides an alternative to natural ordering on the stream elements by creating a Comparator from a key. Notice that here also you are not confined to natural ordering: another overload of Comparator.comparing accepts a Comparator on the extracted keys, allowing you to impose a different ordering on them. For example, to sort my books by the number of authors, I could write

The second operation in this group, distinct, removes duplicates from a stream. Its output is a stream containing only a single occurrence of each of the elements in its input—all duplicates, according to the equals method, are dropped. For example, to use the sorted stream of books we just created to produce a list of authors, but with duplicates removed, we would write

Since the equals method may not take account of all the fields of a stream element, “duplicates” may in fact be distinguishable by other methods. So the idea of stability, discussed in connection with sorted, also applies to distinct: if the input stream is ordered, the relative order of elements is maintained. From a number of equal elements, the first will be chosen; if the input stream is unordered, any element may be chosen (likely to be a less expensive operation in parallel pipelines).
Truncating
This category groups two operations that constrain the output from streams:
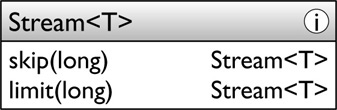
The operations skip and limit are duals: skip discards the first n stream elements, returning a stream with the remainder, whereas limit preserves the first n elements, returning a stream containing only those elements. For example, we could get the first 100 books in alphabetical order of title by writing:
Of course, there may be fewer than 100 books in the library; in that case, the stream that limit returns will contain all of them. Analogously, skip could be used to create a stream containing all but the first 100 elements:

3.2.3 Non-interference
Among the features that the Stream API offers programmers is the execution of parallel operations—even on non-threadsafe data structures. This is a valuable benefit, so it should not be surprising that it does not come entirely free of charge. The cost is cooperation with the programming model, according to the rules described in this section. These are not arbitrary restrictions; indeed, they restrict you only if you are thinking in sequential mode. If you are already designing parallel-ready code, they will seem natural because your thinking will be free of hidden assumptions about which thread will execute the behavioral parameters to stream operations, and about the order in which elements will be processed. You will be aware that, potentially, every behavioral parameter can be executed in a different thread, and that the only ordering constraint is imposed by the encounter order (§6.4) of the stream.
The rules are mostly to protect your program from interference between the multiple threads required for parallel execution. Sometimes the framework itself provides that guarantee, as we will see that it does for collectors. But it makes no such guarantee for the behavioral parameters to stream operations. Here is an example of how not to create a classification map, mapping each topic to a list of books on that topic:

The lambda that forms the behavioral parameter to peek is not threadsafe. When it is executed in parallel, only bad things can happen: map entries will be lost (up to 1 percent of them on my modestly parallel Core 2 Duo machine); very possibly, the call of currentBooksForTopic.add will throw an ArrayIndexOutOfBoundsException. To correct this problem in the wrong way, the body of the lambda would have to be synchronized, leading to a clumsy and inefficient solution. To correct it in the right way requires attention to the principle that behavioral parameters should be stateless. The Stream API is designed to provide safe and performant parallel-friendly alternatives to code like this—in this case, the group-ingBy collectors, which we will meet in the next section.
It’s tempting to think that such problems needn’t concern you if you never use parallel streams in your own code, just as a previous generation of programmers mistakenly thought that problems of synchronization needn’t concern them if they weren’t using threads. As library APIs make increasing use of streams in the future, you will find yourself calling methods accepting Stream parameters. If you create a pipeline with non-threadsafe behavioral parameters like the one we just saw:
![]()
and then call a library method supplying books as an argument, the library method may well call parallel on your stream before calling a terminal operation, resulting in the same race conditions as before. The method parallel, like sequential, provides a hint to the implementation about which execution mode to choose; the execution mode is fixed for the entire pipeline only at the point that terminal operation execution begins, so control over it does not remain with you as the creator of the pipeline. The lesson of this example is once again that a stream with a non-threadsafe behavioral parameter is an accident waiting to happen.
The classification map example of this section might lead you to think that the main problem with stateful behavioral parameters is thread safety. In fact, the documentation of java.util.stream gives a general description of a stateful operation as “one whose result depends on any state that might change during the execution of the stream pipeline.” For an example of a stateful operation that goes wrong despite being threadsafe, let’s allow each Book to refer to another and to contain a boolean field indicating whether it is referred to. For a test, we could set up a List<Book>, each referring to an adjacent element in the list (treating the list as circular), then execute this code:

If I run this sequentially on a list of 1000 elements, I get either 1 or 999 as a result, depending on whether each element refers to its predecessor or successor. (This difference, which is entirely dependent on the implementation’s choice of evaluation order, is sufficient reason in itself to avoid code like this.) But running it in parallel gives inconsistent results varying unpredictably between 1 and 4 or else 995 and 999.
An equally important requirement on parallel-ready code is that pipelines must avoid mutating their source during the execution of their terminal operation. Considering only collections for a moment, that prohibition may remind you of the rule that disallows structural alterations during iteration: a “fail-fast” iterator—one created by a non-threadsafe collection—throws ConcurrentModificationException if it detects structural changes to its collection (other than those that it has itself made). Spliterators (§5.2), the parallel analog of iterators, behave similarly if they detect structural changes to a stream source during terminal operation execution.
This is the most likely symptom of concurrent stream source modification, but by no means the only one: ConcurrentModificationException is thrown only by structural modifications—typically, addition or removal of a collection element. But the rules for streams forbid any modification of stream sources—including, for example, changing the value of an element—by any thread, not only pipeline operations. (The only exceptions to this rule are threadsafe concurrent data structures, like those in java.util.concurrent.) This is actually a rather modest restriction, considering what it makes possible: the ability to perform parallel operations on non-threadsafe data structures.
3.2.4 Ending Pipelines
The examples of the previous section have one thing in common: because the stream operations that they illustrate are all lazy, their effect is to combine individual streams into pipelines without initiating any element processing. By contrast, the operations in this section are all eager; calling any of them on a stream starts the evaluation of the stream elements, pulling the elements through the stream from its source. Since all of them produce non-stream results, they could all be said in some sense to reduce the stream contents to a single value. But it is useful to further divide them into three categories:
• Search operations, which are used to detect a stream element satisfying some constraint, so may sometimes complete without processing the entire stream.
• Reductions, which return a single value that in some way summarizes the values of the stream elements. This topic is big enough to require the next chapter all to itself. For now, we will restrict our view to two aspects: convenience reduction methods like count and max, and simple collectors, which terminate streams by accumulating their elements in a collection.
• Side-effecting operations, a category that contains only two methods: forEach and forEachOrdered. These are the only terminal operations in the Stream API that are designed to be used with side-effects.
Search Operations
The Stream methods that can be classified as “search” operations fall into two groups: the first group comprises matching operations, which test whether any or all stream elements satisfy a given Predicate:

The names are indicative: anyMatch returns true on finding an element that satisfies the predicate; allMatch returns false on finding any element that does not satisfy it, and returns true otherwise; noneMatch is analogous, returning false on finding any element that does satisfy it, and returning true otherwise.
For example, planning the organization of my bookshelves is complicated by the fact that these built-in shelves are not all of the same height. If I need to know whether my history books can be placed on the top shelf, whose headroom is only 19 cm, I can write:

But this is not really what I want if I am planning the allocation of topics to shelves. It would be much better to determine in a single operation all of the topics that would fit on this low shelf (or, better still, to calculate for each topic what headroom it requires). This aim can be achieved by wrapping this code in a loop, but only at the cost of repeatedly calling library.stream—an inefficient and ugly solution. In Chapter 4 we will see much better solutions using collectors.
Note that, in accordance with the standard rules of logic, allMatch called on an empty stream will always return true.
The second group of search operations is made up of the two “find” methods: findFirst and findAny:
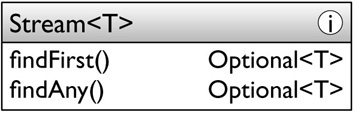
These return a stream element if any is available, possibly differing in which one they return. The return type needs a little explanation. At first sight, we might naïvely expect to write

But what if library contains no elements, so the stream that it sources is empty? In this situation, there is no answer for findAny to return. The traditional Java solution of returning null is unsatisfactory: it is ambiguous as to whether a null was actually matched in the stream or whether it indicates the absence of a value, as in the result of Map.get. Moreover, null cannot be used with primitive streams. The alternative created in Java 8 is the class java.util.Optional<T>; an instance of this class is a wrapper that may or may not contain a non-null value of type T. The “find” methods allow for the possibility of an empty stream by returning Optional, so the correct version of the preceding code is

The next section provides a brief overview of the Optional class.
By contrast to findAny, and provided the stream is ordered, findFirst will return the first element that it encounters. For example, we could find the first line in the text of this book containing the string “findFirst”:

The use case for findFirst is situations like this, where the problem statement concerns finding the first match in an ordered stream. If any match in an ordered stream is acceptable, on the other hand, you should prefer findAny; findFirst would be liable to do unnecessary work in maintaining an order that is not needed. With an unordered stream, there is no real distinction between the two methods.
The search operations combine with lazy evaluation to save work, as described at the beginning of this chapter: the matching methods can return after finding a single element that satisfies (or not, depending on the particular matching operation) its Predicate. The “find” methods always return on finding a single element. Lazy evaluation ensures that when, in these cases, stream processing stops, no (or few) unnecessary elements have been generated.
The class Optional
In the last section we saw Optional<T> used as a return value from find operations, and earlier (§3.1.2) we encountered one of its primitive variants OptionalInt. We need Optional and its variants when applying terminal operations to empty streams—for example, one for which a filter has eliminated all its elements. The last section described the problems of using null; Optional<T> avoids these by providing a special empty value that can never be confused with a T.
For the limited use we will make of Optional in this book, it is enough to briefly explain a few of the methods that allow client code to use its value:
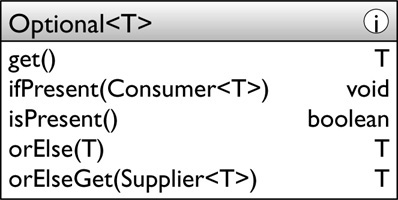
The purpose of these operations is as follows:
• get: Returns a value if one is present; otherwise, this method throws NoSuchElementException. This is the “unsafe” operation for accessing an Optional’s contents, normally to be avoided in favor of one of the following safe alternatives.
• ifPresent: If a value is present, supplies it to the Consumer; otherwise, does nothing.
• isPresent: Returns true if a value is present; otherwise, returns false.
• orElse: Returns the value if present; otherwise, returns the argument. This and orElseGet are the safe operations for accessing the contents. In the normal use of Optional, with the possibility of an empty value, these operations are more useful than get.
• orElseGet: Returns the value if present; otherwise, invokes the Supplier and returns its result.
Reduction Methods
The Stream API is designed, to borrow Larry Wall’s well-known slogan, to make the easy jobs easy without making the hard jobs impossible. We shall see how to do the hard jobs, using collectors and spliterators, in the next two chapters. But in practice, most jobs are easy ones, and for these we have convenience reductions—specialized variants of Stream.reduce (§4.4), designed for simplicity of use. Here the numeric primitive streams, for example IntStream, provide more features:

These methods are self-explanatory except for the last, summaryStatistics. This creates an instance of the class IntSummaryStatistics, a value object with five properties: average, count, max, min, and sum. It is useful in situations in which we want multiple results from a single pass over the data. For example, code to obtain and print the summary statistics of the page count of the books in my library (summing the page count for works spanning multiple volumes) like this:

produces this output:
![]()
The same pattern appears in LongStream and DoubleStream. Reference streams also have some convenience reduction methods:
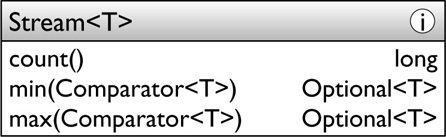
For example, this code will find the earliest-published book in my library:
![]()
Notice that to find the minimum or maximum of Stream elements that have a natural order, you have to provide an explicit Comparator. For example, to find the first book title in my library, in alphabetical order, I could write:

An analogous factory class Comparator.reverseOrder is provided for reverse natural ordering.
Collecting Stream Elements
The second kind of reduction, for reference streams, uses Stream.collect to accumulate stream values in mutable containers like the classes of the Java Collections Framework. This is called mutable reduction:

The argument to collect is an instance of the Collector interface. As the figure shows, Collector has three type parameters: the first is the type being collected, and the third is the type of the result container; the second one will be explained in §4.3.1, as part of a more detailed exploration of collectors.
Most collection use cases are covered by predefined Collector implementations returned by factory methods of the class Collectors. This chapter covers three of the simplest of these methods; in Chapter 4 we will see the full range, and—if you need something beyond what the predefined implementations provide—how you can write your own.
The three factory methods covered here collect to an implementation, chosen by the framework, of one of the three main Java Collections Framework interfaces: Set, List, and Map. Here are the declarations of the methods toSet and toList.

For example, to collect the titles of the books in my library into a Set, I can write:

The usual idiom is to statically import the Collectors factory methods, making the last line of this example
.collect(toSet());
Figure 3-5 shows how this collector works for these two books. In part (a) the input elements are the two Book instances we saw earlier. In (b) they are being placed in the Set; internally, that operation is implemented using the method Set.add, with the usual semantics: elements are unordered and duplicates discarded. In (c) the stream is exhausted and the populated container is being returned from the collector.
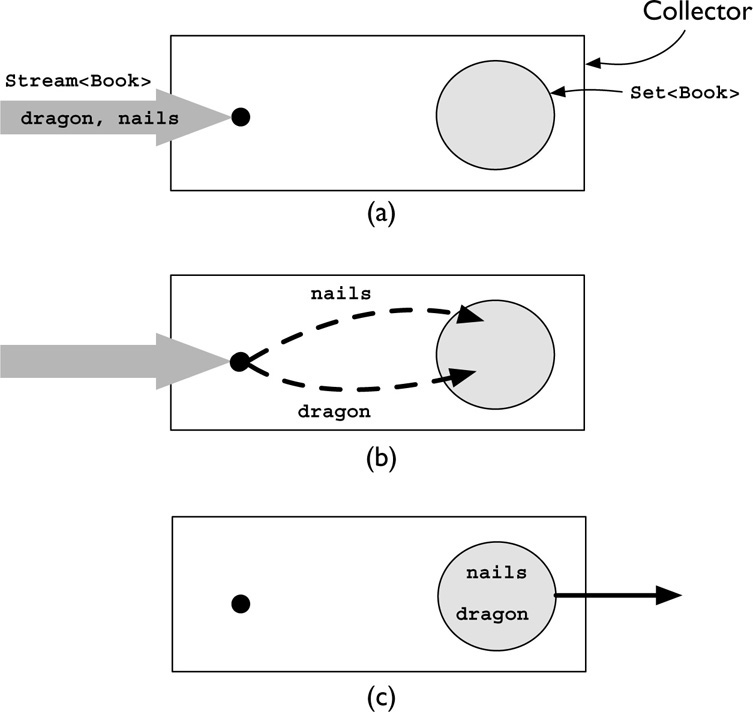
FIGURE 3-5. How Collectors.toSet works
The method toList is closely analogous to toSet, with the method List.add implementing the accumulation; so, if the stream is ordered, the created List has the same ordering. (If not, stream elements are added in nondeterministic order.) Creating a collector that accumulates to a Map, however, is a little more complex. Two method overloads of toMap are provided for this, each accepting a key-extracting function from T to K and a value-extracting function from T to U. Both of these functions are applied to each stream element to produce a key-value pair.

For example, I could use a collector from the first overload of toMap to map each book title in my collection to its publication date:
![]()
Figure 3-6 shows how the two functions provided to the toMap collector work to populate the Map.
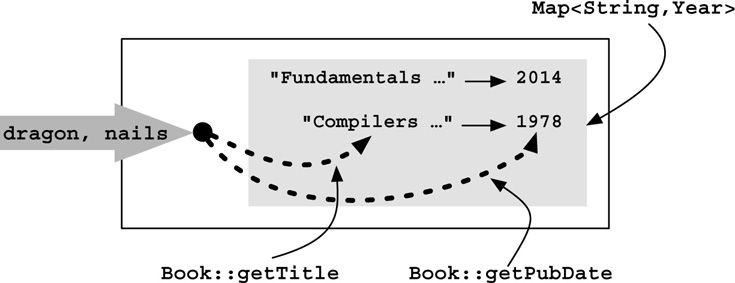
FIGURE 3-6. How Collectors.toMap works
The second overload of toMap is provided to take account of duplicate keys. If I am enthusiastic about a book, I may buy a copy of each new edition as it is published. Different editions have the same title but different publication dates. Of course a Map cannot contain duplicate keys, so with the code above a book in multiple editions will cause the collector to throw IllegalStateException. That overload, then, is the one to choose when duplicate keys are not expected.
When duplicate keys are expected, the second overload allows the programmer to specify what should happen, in the form of a merge function, of type BinaryOperator<U>, that produces a new value from the two existing ones—the one already in the map, and the one that is to be added. There are various ways in which two values could be used to produce a third one of the same type; two String values could be concatenated, for example. Here I might decide to include only the latest edition of each book in the mapping:

Because the collectors returned by toMap—like those returned by toSet and toList—are accumulating into non-threadsafe containers, managing the accumulation of results from multiple threads is an overhead that can hurt performance on parallel streams. We will see options for collecting more efficiently to Maps in Chapter 4, and in Chapter 6 we will explore the impact of collectors on stream performance.
Side-Effecting Operations
We first met these operations at the beginning of this book, as the simplest way of replacing external iteration. They terminate a stream, applying the same Consumer to each element in turn. They are the main exception to the convention that the Stream API does not support operations with side-effects:

We have seen both of these methods in use already. The main difference between them is obvious from the names: forEach is designed for efficient execution on parallel streams, so it does not preserve encounter order. Less obviously, it makes no guarantee about the synchronization of its operations, which can be executed on different threads. So, for example, suppose I wanted to calculate the total page count of all the books in my library, and naïvely declared an instance variable pageCount to calculate the total by writing, I might then write:

This code is incorrect because the additions to pageCount can occur in different threads without synchronization, so is subject to a race condition (simultaneous interfering execution). Of course, the principle of writing parallel-ready code should have warned me against this code even though the stream is sequential. As reinforcement, the API documentation for forEach warns me that the action will be executed “in whatever thread the library chooses.”
That code could be “corrected” by using forEachOrdered, which preserves ordering and guarantees synchronization, instead of forEach. Then I could rely on the result from this code:

but although this code works, it is not parallel-ready; the use of forEachOrdered forces execution into a sequential mode. Code written in the spirit of the Stream API is both much more readable and more efficient in the general case:

3.3 Conclusion
We now have an overview of the basic operation of streams and pipelines, but we have yet to see many practical examples of using this style of programming to solve real processing problems. In the next two chapters we will build on what we have learned, exploring the API in more detail and investigating strategies for breaking down complex queries into step-by-step operations on streams.
____________
1 All programmers should know about laziness, of course, since it is the first of the three great virtues of a programmer: Laziness, Impatience, and Hubris (Larry Wall et al., Programming Perl, O’Reilly, 2012.)
2 A well-known example of this is the ReentrantLock class, which can be created with either a fair (deterministic) or non-fair (nondeterministic) thread scheduling policy. Fair locks are at least an order of magnitude less efficient and in practice are rarely used, as fair scheduling is not often required (Brian Goetz et al., Java Concurrency in Practice, Addison-Wesley, 2006.)
3 The conventions for API diagrams are listed in the box on page 27. In brief: the icon at top right indicates whether the diagram contains static or instance methods; wildcard bounds on generic types are omitted; undeclared generic types in method signatures can be assumed to be method type parameters; diagrams show only selected methods of the class or interface.