
Because creating voice systems is such a hot topic, you can find lots of talks and online classes showing you how to build a VUI in a very short time. True, you can get something up and running very quickly, which is awesome. You already did exactly that in Chapter 3. And that’s enough if your goal is something for your own use. But if you want to build something robust for others, what then? How do you build something that works well and meets their needs and expectations? And is it even possible to build that with the resources you have available?
You need a plan built on the answers from asking the questions that are relevant for voice—answers that will guide your design and development. That’s what this chapter is about: asking the right questions and interpreting the answers. Even if you’ve written specifications before, you suspect VUIs are different. You’re right.
So what are these questions? It’s the ones usually grouped as functional requirements (What are you building? What does it do?) and nonfunctional requirements (Who will use it and why?). In this chapter, we step through discovery in a fair bit of detail to give you a sense of how we approach it. As you continue through the book, you’ll understand the reasons behind the questions, why the answers matter, and why things go wrong when the right questions aren’t asked or the answers are incorrect or ignored. Therefore, the focus is on requirements that matter most for voice. You might notice that we jump between categories of requirements questions. You’re right. We do it on purpose to emphasize that you’ll be more successful if you treat your discovery process as a whole, rather than separating it into functional vs. nonfunctional or business, user, and system requirements. Organizational separation is fine for documentation, not during the information gathering process. All answers are relevant to designers, developers, and product owners alike. Nobody gets to take a coffee break during a kickoff meeting because “their” portion isn’t currently discussed.1
Avoid knowledge silos. If you work within and across teams, everyone needs to have a solid appreciation of the strengths and constraints of voice. Involve everyone from the start and listen to each other’s concerns and advice. You cannot work well in a vacuum in this field: everything affects everything else, and no requirements are more important than others. Respect each other and include designers, speech scientists, and developers during discovery—they’ll ask questions from different angles. VUI design, VUX research, NLU and grammar development, database programming, system architecture, marketing—they all involve different skills and it’s rare to find all, or even most, in one person. You obviously need people with core expertise in their area for their role. If they have voice experience too, fantastic. If they don’t, focus on finding those with a demonstrable interest in real user behavior and data, people who understand that interacting with voice versus interacting with text and images are fundamentally different, people who want to learn and who work well as a team.
Building for voice is always a balance. Even for the simplest VUI, it helps to have a plan before you start implementing. Experienced VUI designers and developers start all voice projects with a discovery process using their experience with voice to mentally check off nonissues while flagging potential complexities. Start practicing this habit—with the background from the first few chapters, you can already get far. There’s a lot of text in this chapter. Use it as a resource when you need it. Just don’t ignore doing discovery with voice in mind.
General Functionality: What Are You Building?
Let’s start with the most basic question: what is the goal of your voice app? You have some reason for the idea: you saw a need, or someone is paying you to implement their idea. Your answer affects every aspect of developing your voice solution—the need for and availability of specific content, security, accuracy, and so on—which in turn affects design choices and leads to trade-offs.
No single VUI design guarantees success, but there are many ways to increase or decrease your success rate. Design choices always need to be made, and they’ll depend directly on requirements, resources, timelines, and other constraints. The more you know at the start, the more likely you are to make the decisions that result in a VUI people want to use.
A good starting point is to put your idea into words: a few sentences that describe the purpose and goal of your VUI, the domain and main task, and the basic flow if you already have something in mind. This brief high-level summary, an elevator pitch, for the restaurant finder can be as follows:
A restaurant finder for a specific city. Based on a search item, the app responds with a best-match suggestion. Users search for a local restaurant in city X by specifying a cuisine or hours of operation. The VUI responds with a match or asks for disambiguating restaurants if needed. Users can follow up with a request to make a reservation, specifying time, date, and number of guests.
Tell your pitch to a friend and ask them to describe to you in their own words what they heard and ask them what they’d expect to be able to accomplish, what they’d be able to say, and what responses it would provide. Did it match your view? Great. You’re on your way.
Now, asking for restaurant information is something most of us have done, so we have a pretty good idea what it should look like. But part of the challenge of voice is to build something others want to use, even when they’re different from you. What if you’re building something you have less familiarity with? And what if your app’s behavior could affect your users’ health?
The health and medical domain is complex while also incorporating the basics. It covers every key aspect of design and implementation complexity. It even involves food, so you didn’t waste your time with restaurants!
There’s a lot of interest in using voice in the health and medical domain. Who doesn’t want to do good? But this domain demands higher accuracy and confidence in the result than most simpler implementations can provide, making it a perfect topic for this real-life-focused book.
Both of us authors have first-hand voice design and development experience in this domain, making it a realistic context for sharing real-life experiences and the reality of voice-first development with you.2 We take you step-by-step through a process we’ve successfully used ourselves many times when creating voice interactions for mobile devices, smart home assistants, call center systems, and other devices.
A procedure preparation helper that guides a patient in the days leading up to a medical procedure to decrease chances of rescheduling due to lack of preparation. Users get timely notifications for necessary changes in diet or medication personalized for them based on the number of days before their procedure so they don’t miss something that could affect their procedure. They can also ask questions about the procedure, such as if it’s OK to eat a particular food or take some named medication, and hear a short informative response that they know is approved by their doctor. They can also contact their doctor.
Let’s pause the functionality and take a closer look at your future users—understanding them will guide your next set of questions.
User Needs: Who’ll Use It and What Do They Want?
The key to voice success is understanding your users’ needs and expectations and speaking and understanding their language. Your assumptions affect everything from style, wording, and content to overall flow and what needs explanation for users to enjoy the interaction. How do you really know what users want? Get in the habit of starting every voice project with quick research. Start online. You quickly learn that people have questions about the procedure (what it is, how and why it’s done) and the specific preparation tasks. Make note of the common questions and answers. In real life you’d base this on material provided by the health providers you build the app for, but the concept is the same. Also, you may need to scope the effort without much information to help create a sales quote. And if you do background research before meeting with the health provider, you can be much more effective in collecting the answers to your questions. Chapter 5 goes into some methods for finding user data. For now, let’s assume you have access to a reliable source.
Identify the user population (subject expertise, special terminology used, children’s voices, heavy accents, one or several users on one device, etc.)
Identify how the task is done today, in how many steps, and how does it “end.”
Identify any patterns in when and how often the task is done, including what triggers the start (prescription refill, wish to turn on a light or get directions, bill payment reminder, etc.)
Identify users’ environment, activity, and emotional state (type of background noise, stationary at home, walking outside, while driving, upset, etc.)
Determine if there’s a reason users can’t talk or listen to a device doing the task.
A colleague designing a VUI for an international bank started by looking at the bank’s website, making notes on types and names of accounts and services offered, style and formality of addressing readers, and so on. This information is critical for VUIs. It lays out the words and features people will expect and use. If there’s a mismatch between that and the voice system, users won’t be understood and get annoyed, and the VUI will look anything but “smart.” Our colleague incorporated this information in the sample dialogs he presented during kickoff, which impressed the bank. It helped focus the discovery session: learning about the typical customer, how many accounts they typically have, how often they contact the bank, what the most common tasks are, how often they do one or several tasks in one session, when statements typically arrive, the format of account numbers and login access, and so on. It all informs design decisions, flow, prompt wording, confirmation needs, backend calls, recognition challenges, and where users are more likely to need contextual help.
Demographics and Characteristics
Who are your intended users? A broad population you know little about or a narrower user group, like kids, or a company’s customers who have accounts and therefore available interaction history? You want to know if there are any significant characteristics different from a general population. You may need to tailor prompt wording, the speed and sound of the voice, how long to wait for a response, and various aspects of the flow and handling if a large chunk of users represents a particular generation or geographical location or has (a lack of) familiarity with the content or if they’re non-native speakers unfamiliar with some words or pronounce words with a heavy accent. If you have several distinct user groups, such as novice and expert users, you can incorporate different handling for each group. More on this topic in Chapter 15.
In a multilingual app, the same name of a feature was used across all available languages. This was a trademarked name, so the company naturally wanted to use that name. The problem was that the name was an English word, not translated into the other languages. Recognition underperformed on the very phrase that was most important to the company because recognition is based on language models and non-native speakers don’t pronounce a word the same as a native speaker does.
For general information, you don’t need to know who the user is; the answers are the same for everyone in the same context. But the more you know about the user, the more interesting conversational voice dialogs you can design, from incorporating preferences to providing recommendations or handling secure data. More development work, but also greater potential payoff. Also, anything that narrows down options or potential matches can assist recognition and therefore contribute to success. And using context to predict something about the user behavior is key to success because it also narrows the search space for recognition and NL interpretation and speeds up the conversation.
You’ll typically hear about gathering the business stakeholders during discovery, as well as involving technical representatives early. Make sure your end users are also accurately represented from the start. Business stakeholders, system implementers, and end users need to have equal representation at the table. Because voice is still typically less understood, plan for knowledge transfer and opportunities to involve everyone in learning about voice. The benefit is a better VUI.
Demographics and user characteristics requirements for the procedure prep app
Who are the users? | People who are scheduled for a specific procedure. Age skews older, but can be any adult. |
|---|---|
User profile known? | Yes, to allow accurate and targeted responses. |
Multiple users to differentiate? | No . |
Access limitations? | Anyone can access general information. For personal information, some authentication is needed. |
Engagement Patterns
In a financial stock voice system, we thought something was wrong when we saw calls as long as an hour or more. Turns out, multitasking traders continuously asked for real-time stock quotes by voice until they liked the price they heard. The dialog flow, quick pace, and information content worked well for the core power users.
Ignoring for now where to find the data, you need to know which functionality is most and least frequent. Remember: VUI differs from GUI in that the listener/user must keep everything in short-term memory. That’s why you need to make use of things like task frequency: present options and information in the order that minimizes cognitive load for the user. Frequency of use also influences how users respond to multi-slot requests and ambiguous requests. In general, the less familiar a user is with the task, the more likely they’ll let the VUI take the lead in requesting necessary information. You learn about this in depth in Part 3.
How often will your users engage with the VUI? If it’s often, you want to aim for shorter prompts and use information from past user utterances to speed things up. If the task is complex and use is infrequent, you’ll need more explanatory details, helpful hints, and error handling. And if you have both frequent and infrequent users, there are ways to personalize the experience on a “novice” vs. “expert” basis. Novice users can be presented with more detailed and explanatory prompts.
In some contexts, people have follow-on questions, even if their previous request was complete. Or they ask the same question again with different variables, like in the preceding stock quote example. You want to know if this is relevant for your voice app so you can make it easy for users in the flow. More on this in Chapter 14.
In the procedure prep app, you can expect mostly novice users and a mix of frequency depending on task. Expect lots of use for general questions, with more specific questions about foods increasing as the procedure gets close. Some tasks will happen only once, like specific procedure prep instructions. Within that task, the same step repeats multiple times, so assume you need to start with instructions for the task, but can taper off to short prompts quickly. You learn about tapering and other strategies in Chapter 13.
Mental Models and Domain Knowledge
A bank was concerned about the low completion rate for bill payment in their voice-first phone app. Turns out, users thought they were successful: they only wanted to know the due date and amount and happily hung up before completing any payment. It was a misunderstanding of users’ mental models. Not everything that looks bad is bad.
Mental models , peoples’ internal representations of how something works, are an important concept in voice. Mental models account for expectations for who says what when in a dialog, how to start and end a conversation, and even appropriate topics and words used. These expectations affect how users express themselves and what they expect to hear, which helps understanding what someone says when it’s noisy. Therefore, your VUI should reflect these expectations and take advantage of them rather than ignore them or break them. If you’re dealing with something that has a parallel method in real life or in an existing app, build on that. Users will be more successful if they can follow their expectations, express themselves naturally, and be understood.
If your restaurant finder expects users to search for the official name Na Na’s Kitchen but all locals know it simply as Na Na’s, you’d better handle both! Some people will give all information at once (Make a reservation at Na Na’s Kitchen for six people at 7 PM tomorrow), while others will specify one piece of information and then hand over the conversational control to the person—or VUI—to step them through filling the rest. A stock trading voice app for expert traders needs a flow that mirrors how those trades are spoken to a person. How to build a specific dialog type is the core topic of Chapter 6. Chapter 15 goes into more detail about mental models.
It’s natural for people to immediately follow a no in a confirmation with the corrected information—so responding No, 1965 instead of just saying No and waiting for the other person, or VUI, to ask for the correct information. In a voice-first banking app, success increased by 8% just by adding this as a path based on understanding how people correct a misrecognition. Success comes from understanding how users naturally speak.
Users’ mental model requirements of the procedure prep voice app
How do people do this today? | Look it up online, read instruction sheets, call the care team, and ask friends. |
|---|---|
Terminology | People don’t necessarily know the “right” terms for medical items. Users don’t know how to pronounce names of many medications. |
Expectations | High information accuracy, choices offered when relevant, confirmation before scheduling an appointment. |
Environment and State of Mind
In a voice-first prescription refill app, users needed to provide their prescription number but often didn’t have it nearby. We added the ability to pause the conversation until the user said continue to give them time to get the number without losing previous provided information and having to start over. Success comes from understanding users’ environment.
In what environment will your voice app be used? Is it noisy? If so, what kind of noise? Loud white noise or mechanical noise is not as problematic for recognition as multiple voices (side speech) in the user’s vicinity, including TV background noise. If you expect noise and have distracted or stressed users while also expecting high accuracy or difficult recognition, you’ll need some methods to increase your success. Can you incorporate voice biometrics—recognition of the user based on their voice—to minimize responding to other voices? If you do, how do you handle multiple users, including guests and visitors? More about that in Chapter 15.
Why do users decide it’s time to engage with the VUI: what’s the triggering event? That one is obvious for the procedure prep app. Are they distracted? Are they stressed or relaxed? Are they multitasking, busy with hands or eyes or both? If you have a screen available for output, would that be useful in context or not? If the task is mentally or physically stressful, like most medical applications, your VUI should speak a bit slower and calmly, use simpler words, reiterate key information, or verify that the user understood by asking a simple comprehension question. The answers to all these questions will lead to different VUI solutions.
Environment and user state of mind requirements of the procedure prep app
What environment?Noise or privacy impact? | Home or in store; private or semiprivate; stationary or moving. For notifications, avoid potential embarrassment in wording. |
|---|---|
User state of mind? | More nervous than normal, possibly distracted and tired. |
User-provided information? | Needed for initial setup. |
Modality benefit and challenge ? | Screen is helpful but not required. |
Special behaviors? | Just-in-time (JIT) hints; behavior tied to timing of procedure. |
From General to Detailed Functionality
Now that we have a better sense of the user needs, let’s return to defining the functionality. The goal is to define each task your VUI should handle and identify any red flags where voice will face challenges.
Step 1: Define the Core Features

Typical questions users have help you define the health assistant core features
People have questions about the procedure itself: Will it hurt?, Is there parking by the lab?, or Is it covered by insurance? A voice app is great for this: targeted answers instead of having to search through pages of material.
People also have questions related to the low-fiber diet changes needed before the procedure. Some type of diet change is typical for many medical procedures. You want to allow users to ask about what foods are OK at any point before the procedure, both general (What can I eat (today)?) and specific (Can I eat <food>? Can I drink coffee?) Again, perfect for voice: quick information retrieval in a broad search space without stepping through menus.
The same is true for medication questions related to medication change . Users should be able to ask both general questions (What medications can I (not) take?) and specific ones (Can I take <medication>?) No better way than voice: users don’t need to spell weird names!
It’s important for people to do any prep task corrections, such as measuring blood pressure or consuming some liquid to prepare your body for the procedure. So you want to include step-by-step instructions for that. A spoken dialog allows for hands-free interactions, so again, great use of voice.
The VUI can’t answer all questions, so people need a way to contact their health team (I’m running late for my appointment or I need to talk to my doctor). Scheduling or rescheduling appointments is another important feature.
Some people like to track what they ate each day. So let’s include a food diary.
General high-level initial description of sample procedure prep functionality
Functionality | Description |
|---|---|
Overall | A health assistant that helps a user prepare for their medical procedure. The voice assistant can answer questions relevant to preparing for a procedure, including general information, dietary and medication constraints, and day-of instructions. Users who are appropriately authenticated can get personalized answers, access their appointment calendar, and contact their care team. |
Even if you know some functionality will be a bit tricky to get right with voice or you think only a few users want it, you don’t know yet. We’ve seen project managers hurry the discovery discussion, not understanding the value of letting the technical team ask seemingly vague questions and allowing the stakeholder or customer to meander a bit. You’ll learn about hidden expectations and even internal power struggles that become important later. Listening between the lines is not underhanded; it enables you to find the best solution.
Step 2: From Features to Intents and Slots
It’s accessible from the VUI’s top level.
It covers a clearly different meaning and the outcome from other intents.
It requires a dialog with distinct steps, different from others.
It relies on a different data access from others.
Features of the procedure prep voice app
1. Get today’s to-do list of tasks. | 5. Navigate step-by-step instructions. |
2. Ask for information about the procedure. | 6. Contact the health care team. |
3. Search for a food/beverage by name. | 7. Schedule/change an appointment. |
4. Search for a medication by name. | 8. Update food diary. |
- 1.
Get to-do list: Responses depend on time of query relative to the user’s procedure: What do I need to do today? The VUI needs to calculate relative time based on the date and time of the procedure.
- 2.
Search for general info: This info is not time sensitive and can be available to anyone with access to the voice app without privacy concerns: How common is this procedure?, How long does the procedure take?
- 3.
Search for foods (and beverages): Queries for specific items: Can I eat pepperoni pizza today?, Can I still drink milk? That means some database dip to find the answer.
- 4.
Search for meds: Also queries for specific items (Can I still take Aspirin?) so another database dip to find these answers. Since food and meds need very different data sets, they should be handled separately while still allowing for very similarly worded requests.
- 5.
Prep: A set of step-by-step interactions that allows some user navigation: Repeat that, Continue.
- 6.
Contact provider: Contact details are user-specific and need information from the care team as well: Send a message to my doctor, Call Dr. Smith’s cell phone. It’s a task that starts with a data lookup.
- 7.
Schedule and change appointments: Depends both on the user’s and the care team’s schedules: I need to reschedule my follow-up appointment.
- 8.
Update a food diary: Updates involve the same database as the food search, plus handling multiple items in a single utterance.
- 9.
Receive reminders: Initiated by the app. Reminder content is tied to time relative until the scheduled procedure, so some background process will continuously check if it’s time to play a reminder.
Naming core intents
1. ToDoInfo | 5. PrepNav |
2. GeneralInfo | 6. Contact |
3. FoodSearch | 7. Schedule |
4. MedSearch | 8. FoodDiary |
Detailed description of purpose and goal of each core user-initiated intent for the procedure prep voice app
Intent | Functionality description | Archetype sentence | Task completion |
|---|---|---|---|
ToDoInfo | User asks for upcoming prep tasks, based on procedure date. No TIME specified = “today”. | <What should I do today?> | User hears a response of tasks. |
GeneralInfo | User asks a question related to their procedure. | <How long will the procedure take?> | User hears a response to their question. |
FoodSearch | User asks if they can eat or drink a named FOOD item. No TIME specified = “now”. | <Can I eat $FOOD (today)?> | User hears a response to their food question. |
MedSearch | User asks if they can take a named MEDication item. No TIME specified = “now”. | <Can I (still) take $MED?> | User hears a response to their medication question. |
PrepNav | VUI leads the user through multistep instructions to prepare and consume a prep solution. | <Continue>; <Pause> | Each step is completed, and end of task is reached. |
Contact | User wants to contact their doctor or the procedure facility. | <Message my doctor>; <Call $NAME cell phone> | User hears the phone number for a care team member. Dialing is offered (if available). |
Schedule | User wants to know when their appointment is or wants to change or cancel it. | <I need to reschedule>; <When is my appointment?> | User hears and confirms appointment. Appointment is made (if available). |
FoodDiary | User lists >=1 FOOD and >=1 DRINK items they consumed for a specified meal. VUI confirms. Log result. | <(For $MEAL) I had $FOOD1, $FOOD2, and DRINK> | All necessary information is collected and added to their food diary. |
Next, time to define successful task completion. Think about what information your voice app needs to fulfill each intent. Slots are the answer. A restaurant reservation request must fill three slots: TIME, DAY, and number of GUESTS. In the prep app, most intents need only one slot filled, but the food diary could take more than one slot, one for each FOOD and DRINK item. For contacting a care team member, it could be one slot (the person to call) or two (person plus which phone, if several). The information in Table 4-7 will be your input for high-level VUI dialog flows later in this chapter.
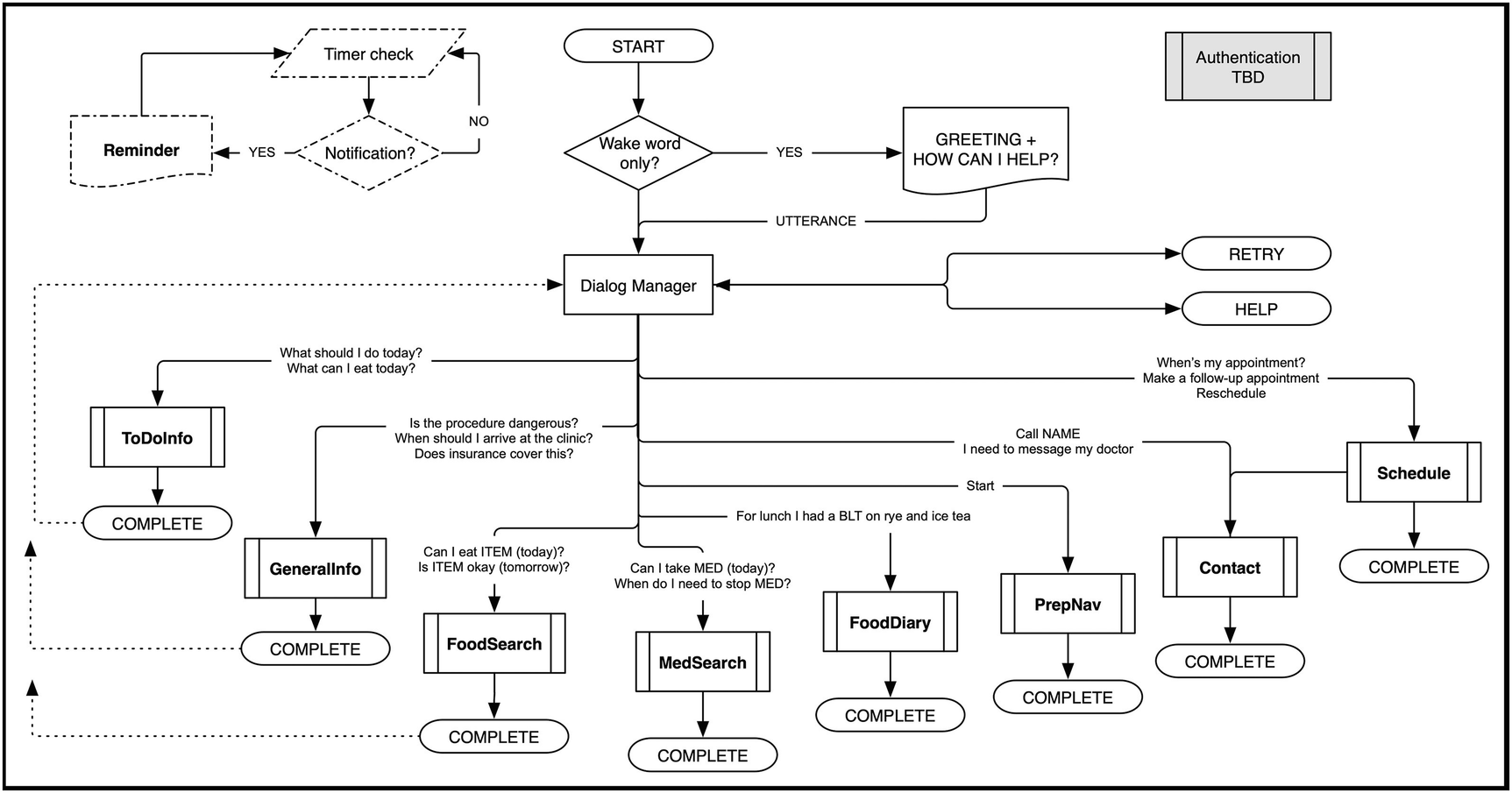
High-level dialog flow of the sample procedure prep voice app
Step 3: Identify Potential Complications
Once you’ve defined the features you’d like to include, determine what challenges a voice solution will face for each feature. Your conclusions directly affect how you structure the dialog flow, as you learn throughout this book. It also identifies which features are best left for later. Here’s where understanding voice becomes important.
The rest of this chapter goes into detailed discovery exactly with this focus, asking, “With the available resources, platform choice, timeline, and so on, where are the complexities for voice and where can things go wrong?” Two core aspects of complexity are variation and cost.
Starting with variation, take another look at Figure 4-2. You can probably see some potential challenges right away: you learned in Chapter 2 that unconstrained variation in user utterances is a challenge for the VUI. Well, there’s a lot of food people can ask about! And some of it is vague: If the user asks if rice is OK, the VUI needs to clarify, or disambiguate, the type of rice, since white and brown rice differ in fiber. So FoodSearch will be tricky. And because variation and complexity increase with more slots to fill, FoodDiary is even trickier: someone could list a whole meal in a single utterance. MedSearch will take some effort—not only do you need to understand the names of thousands of medications but you also need data access to provide the correct response. Contact means access to some contact list, as well as finding a way to actually connect. But the list of names is constrained, so it should be easier than all the foods. What about Schedule? Telling someone when their procedure is taking place isn’t difficult assuming that info has been entered, but making or changing that appointment is a lot more work.
What about cost? Cost isn’t about money here, but the consequences of misinterpreting something. If your VUI misrecognizes the name of a food, it’s less costly if the question is about number of calories or to find a restaurant than if it concerns what’s OK to eat the day before surgery. The costlier a potential mistake, the more effort you need to spend on minimizing that it happens. For this app, any response that results in inadequate prep has consequences of poor procedure results, rescheduling, time and money lost, and so on. Clearly not good. Again, FoodSearch and MedSearch are the red flags. For Contact the risk is that the wrong person gets contacted and for Schedule that the wrong appointment time is offered.
Complications caused by variation in requests and cost of incorrect handling for each functionality of the procedure prep app
Intent | Expected variation | Example | Cost of error |
|---|---|---|---|
ToDoInfo | Some synonym variation. | What can/should I do today? | Low–Mid |
GeneralInfo | Vague or ambiguous in wording. Broad topic; some answers won’t be included. | How common is this? How many people my age have this procedure? | Low |
FoodSearch | Ambiguity and large search space: many food and drink names. Pronunciation: Names borrowed from other languages. | Can I eat cheese? (different types) Is nasi goreng still OK? | Mid–High |
MedSearch | Ambiguity (similar names, different versions): many drug names. Medication names are unfamiliar and can be hard to pronounce. | Can I take Tylenol? (different types) Is idarucizumab OK? | High |
PrepNav | Different navigation commands. Some synonyms. | Next, repeat/say again, go back. | Low–Mid |
Contact | Ambiguity (contacts with the same name, multiple phones). Contact list is user-dependent and limited in size. | Call Joe. Message Dr. Brown. | Low–Mid |
Schedule | Ambiguity. Multistep dialog possible, filling time, day, appointment type, location. Dependent on user and health team calendar access. | I’d like to move my appointment to Friday, February 12. | Low–Mid |
FoodDiary | Ambiguity: many food and drink names. Pronunciation: foods from other languages. Multiple items possible in one utterance. | For breakfast, I had crumpets with bacon jam and Swiss cheese and some coffee. | Low |
Business Requirements: Why Are You Building It?
All voice implementations benefit from “doing it right.” Even if it’s just you building something for fun, you make choices (platform, domain, scope, task, flow, etc.) that affect your development effort and the VUI’s performance. Make your choices consciously—it will help you later when you build more complex apps and products.
Settle on scope and features.
Determine why voice is a preferred solution and what pain points can it improve most.
Determine how to measure success—especially if that’s tied to your payment!
Determine if and how the VUI connects with other communication methods and if it supports backoff.
Identify existing branding and style guides—or the need to create those.
Identify any legal or compliance needs to affect design or development.
Verify access to all necessary data sources and expert knowledge contributors, including resource needs if VUI is multilingual.
Plan for performance improvement activities.
One fundamental decision is the type of device your VUI will exist on. Is it an Alexa/Google implementation, a hardware device, a multimodal app on a mobile phone, a telephone IVR, a stationary or moving robot, or an in-car solution? Can recognition happen in the cloud, or does it need to be local on-device because of the user’s location? Does the device have a screen or not? To keep the discussion agnostic and maximally relevant to any voice solution, we assume it’s a device that may or may not have a screen. In voice-first development, users should not need to rely on any visual feedback.
The answer lies in setting the right limits for voice. Yes, people can say anything, but they don’t. That would break Grice’s Cooperative Principle. Be clear about what your app can do, set expectations, and fulfill them. The biggest complaint by voice users is “It doesn’t understand me,” meaning “I asked for what I expect it to do in a reasonable way, and I didn’t get what I wanted.” The fastest way to get a one-star review is setting expectations you can’t fulfill. Limit the number of features, not your coverage, what users must say to access those features. Pointing users to an FAQ with rules about how exactly to say something also breaks Grice’s Cooperative Principle. Focus on fewer features and make those features robust by handling the expected variation in user utterances and fulfilling any requests. Some users will try to ask for things you haven’t included yet, but if you’re clear about your feature limits, that’s OK. In the procedure prep app, if users are told they can ask about foods, you have to handle a large list of items (e.g., not just cheese but all common types of cheese) and the carrier phrases people use to ask the question (Can I have…, Can I eat…, Is…OK to eat, etc.). But you can let users know that you don’t handle food brand names or restaurant specials. And if some user tries to order food in this dialog, that’s not your problem. ☺
General Purpose and Goal
How will you measure success? That depends in part on your overall goals—and the goals of anyone paying for your work! This means this can be a bit of a sensitive topic. A solution focused on automation above all else may try to keep users in the system, hiding options to speak to a live agent; others offer automation for simple tasks to free up those agents when needed. IVR callers are usually happy to deal with a VUI for simple tasks if they know agents are available when needed, but they will not give your VUI good reviews if you put up hurdles when they ask to speak with a human. Whatever the purpose and goal, the more you understand voice, the better your chances of measuring success well.
Primary and Secondary Goals
Are you just creating something for your own use at home or making a demo, or are you building a product for others to use? When building a voice agent for an established company, you’ll deal with a lot of constraints, including voice persona, data flow, and performance expectations. Every constraint will affect choices in your design and development.
Sometimes there are secondary goals that affect design. Are you pushing a particular product or brand? Are there reasons for engaging the user in a long conversation or giving them a response quickly, or are you trying to differentiate from other products? An answer might be “future monetization.” Whatever it is, be honest and clear about it, because it will affect your dialogs and VUI responses. If your goal is to automate customer service, be aware of user backlash if you try to keep them from speaking to a person. There are better ways, as you’ll learn.
Success Metrics
How will you even know if you succeed? That’s the success metrics. It’s not uncommon that VUI performance is tied to bonus payment amounts to the developer. If you have specific quantifiable metrics in mind, you should figure that out before you start building anything since your dialogs will impact things like time to completion. You may want a way to measure if the user reached a specific point in the dialog flow with a minimal number of steps or within some time frame. If accuracy is important, you’ll need some way to track and measure that. Your choice of success metrics affects design decisions: higher accuracy means more explicit confirmation of what’s recognized. If dialogs need to be short, you’ll need to avoid superfluous conversational expressions. Track when specific changes are deployed for comparison with statistics on customer satisfaction, misrouted calls, or solved customer service tickets. If user engagement, repeat usage, or satisfaction is important, your dialogs need to maximize that. Chapters 16 and 17 go into further details.
In a healthcare voice-only system, each percentage point increase in containment was tied to payment by the customer to the voice service organization. By changing prompts and flows and tuning the recognition and grammars, containment increased by 10% and user satisfaction (CSAT) increased. Everyone was happy. In a banking voice-only system, increased customer satisfaction was key and was the result of design changes paired with speech tuning.
Domain, Device, and Other Modalities
VUIs can be built for any domain : medical, health, sports, entertainment, information, education, and so on. For procedure prep, the domains are “health and medical” and “food.” Domain affects the dialog flow and terminology you’ll use in responses, the need for confirmation and accuracy, and the utterances and behavior you can expect from users. It’s more important to accurately interpret an utterance that deals with a user’s money or health than to make sure you play the song they requested. Your flow will reflect that.
Business purpose and primary and secondary goals of the procedure prep app
Purpose and main goal? | Create a production-quality procedure prep helper that is easy to use, highly accurate, and secure. |
|---|---|
Secondary goals? | Building user data for future apps; creating stickiness through user engagement to encourage better eating habits. |
Success metrics? | Significant increase of users completing procedure. Percentage TBD. |
Domain? | Health and medical. |
Underlying Service and Existing Automation
Think about the service your voice app is providing. If it were a live person performing the same task, what would their role be? Friend, DJ, teacher, entertainer, domain specialist? What’s the relationship between the VUI and the user: equals, teacher-student, doctor-patient? This will affect the assistant’s persona—the style of speaking, the words chosen, level of formality, emotional delivery, and so on. Any existing similar interactions will influence users’ expectations of the order of the steps involved and how to respond. This is part of the users’ mental model—you’ll utilize existing dialog expectations and don’t want to break them unnecessarily. If you do, you risk users behaving in ways you didn’t account for, so you may need some just-in-time (JIT) hints or add additional paths to help more users succeed. For a restaurant finder, you’d want a local friend—not the same person you’d take medical advice from.
Metaphor and persona requirements of the procedure prep app
Underlying service? | Always-available topic-specific hand-holding, information, timely reminders. |
|---|---|
What would be the role if performed by a person? | A nurse or doctor, experienced and trustworthy health expert with specific knowledge about the user’s situation. Doesn’t provide medical diagnosis. |
What exists today? Current pain points? | Some medical and health-related voice apps exist, but mostly with a different focus. Actual doctor or nurse not always available. |
Available backoff? | Informational messaging. Contact information for the care team, possibly dialing. |
Branding and Terminology
If your voice app needs strong product branding, you need to consider your system voice options. If your prompts use a lot of jargon, will users understand? If your users use a lot of specialized vocabulary, will your voice system understand?
The metaphor and persona question bleeds into the VUI branding. If you’re building something for a company, this is a very important consideration. The brand needs to be reflected throughout the VUI, in the style, voice, and terminology. It needs to work well with other channels. If sound effects are appropriate for the task, branding affects those too. You need to be careful with branding requirements—they must never get in the way of the user’s ability to succeed. Heavy-handed branding with sound effects and extraneous prompt verbiage can easily get in the way of success. Also think about how a company brand can coexist with a voice platform brand.
A bank wanted to appeal to a younger population, so they changed their voice app’s greeting from “Welcome” to “Hey.” Unfortunately, it didn’t have the desired effect and instead resulted in scathing commentary during (fortunately) early testing.
A mobile phone company changed their voice talent to sound more “hip” thinking it would appeal to a younger population. This also resulted in negative reactions from users.
Prompt Format: Text-to-Speech or Recordings
The biggest question here is whether to use text-to-speech (TTS) synthesis or recorded prompts by a voice talent. There are benefits and drawbacks of both, and your choice affects your system architecture and level of effort. If the company has a famous spokesperson, can you use their voice? Should you? If you’re using the Alexa or Google environment, TTS is a fine choice (assuming you don’t need branding) because of the high quality for most situations.
Terminology and Pronunciation
Branding and terminology requirements of the procedure prep app
Brand constraints on persona? | No branding constraints. Voice should be calm and mature. |
|---|---|
TTS or recorded prompts? | TTS, with custom pronunciations as needed. |
Terminology or pronunciation specifics? | Names of foods, names of medications, names in the contact list. Terminology needs to be accurate while also being easy to understand for all users. |
Sound effects expected? | None planned—let’s not imagine what those would be for a gastrointestinal app! |
Data Needs
Data type requirements of the procedure prep app
External data needed | User data needed | |
|---|---|---|
ToDoInfo | Procedure-relevant information; curated and mapped to procedure timing. | Date and time of procedure; procedure type details. |
GeneralInfo | Procedure information and general health; curated. | Procedure location. |
FoodSearch | Food names and ingredients; curated. | Date and time of procedure. |
MedSearch | Drug names and category; curated. | Medications taken. |
PrepNav | Food names and ingredients; curated. | Past food diary entries. |
Contact | Access to latest updated instructions. | Prep type details. |
Schedule | Care team contact info. | User contact list. |
ToDoInfo | Care team schedule and availability. | User calendar. |
FoodDiary | Food names and ingredients; curated. | Past food diary entries. |
Access and Availability
There’s more to privacy than pure data security. Imagine the potential embarrassment to the user if your VUI suddenly starts talking about procedure prep needs while other people are nearby. It happened with an early alpha version of our multimodal procedure app to the horror of one of our test users.
Your users must have easy access to their data while also believing their information is secure. Should your VUI respond differently to different people asking the same question? Should it respond differently to the same person in different contexts?
Privacy and Security Concerns
Will you need to handle any secure or private user data? Your answers affect backend integration and dialog design: you may need to authenticate the user—in the right way at the appropriate time in the flow—and you may need to be careful what information you read back. It’s an area that’s highly dependent on the platform and device your VUI runs on: you can make different assumptions about identity if something runs as an app on a mobile phone compared to as an IVR. Not all features within a voice app need the same level of security.
Access Limitations Based on Time or Place
Access and availability requirements of the procedure prep app
Any privacy or security needs? | Yes, personal health information; check HIPAA regulations. |
|---|---|
What’s the geographical scope of usage? | United States. Assume any state, but expansion is gradual. |
Any builder-side security or privacy demands? | User data must be kept secure and private. |
Any limitation on availability: time of day, day of week, number of uses? | Information available 24-7. User requests referring to “now” or “today” need accurate time-sensitive responses. Calls should only be attempted when phones are staffed unless there’s voice mail. |
A medical company wanted to “not recognize” user questions on a specific topic so that they wouldn’t have to respond. Problem: You can’t not recognize something, but you can choose how to respond. And if it’s a reasonable request for the app, why wouldn’t they ask? Instead, tell users why you can’t give them what they want.
Special Announcements
Some companies have announcements they want to communicate to users, such as holiday closures or special offers. There’s nothing wrong with that per se, but it’s important to consider the placement and frequency of such announcements. Users will welcome some of them, but once they’ve heard it, having to listen to the end of the same announcement again will only feel like a waste of time. An offer to upgrade the app for a special price is good; playing the same offer every time the user interacts with the VUI is bad. Notifying users about new updates or service outages is good; notifying them by voice at 3 AM on a device in their bedroom is bad. An IVR that has changed drastically, maybe from touch-tone to speech, can start with a very short concrete comment to that effect; saying Please listen carefully as our options have changed is pointless (if those options don’t provide clarity on their own, you have a bigger issue). A pop-up on a screen is annoying but easy to close, and sometimes you can read “around” it. Because it’s audio, voice announcements are more intrusive—you can’t talk or listen to the VUI until the announcements are done. You learn more about this in Chapter 15. During the definition phase, settle on what announcements are necessary and the circumstances for playing them.
If users have to listen to the VUI talking about things they don’t care about, they’ll tune out. This can result in them missing what the VUI says when they needed to pay attention.
Legal and Business Constraints
Legal disclaimers can be required, especially when dealing with sensitive information such as medical or financial advice and records. It’s then important to follow best practices to lessen the impact on users. Can you ask only once or break it up in smaller chunks that are easier to process when heard? Can you get buy-in via email or text instead? Can you reword something to be less “legalese”? If you’re offering a service that lets your users access external content, do they have to sign up for and link to other content providers? If so, can that be done with a link in email?
Additional product constraints of the procedure prep app
Are you the decision maker? | No. Medical staff need to sign off on information provided to users. Need approval of product images on screen. |
|---|---|
Are legal disclaimers needed? | Yes. Needed since medical. Needed when utterances are collected for tuning. |
How many users are expected? | TBD. Unlikely to have many in parallel nor many per day. |
Interaction with other channels or systems? | Yes. Food diary, procedure calendar, contact information, changes in procedure prep. |
Cost-control issues? | Assume free for end users. Unlikely to be high use that affects cost or service. |
Usage constraints? | No limitations. User can keep asking questions and keep trying if not recognized. Normal response rate and latency expected. Some tracking of behavior for subsequent use. Expect tuning and updates needed to keep users happy and data reliable . |
Logistics and timeline? | TBD. Urgent, but quality implementation is more important than schedule. |
Compliance
Requesting, accessing, and storing personal data isn’t just a question about finding the right database, finding space to store it, or following best practices. As time goes on and electronically collected and stored user data of any kind gets compromised, more regulation is put in place by necessity. If you collect any information about the user, as audio or text logs, that data must be kept secure, especially if it’s financial or health data. A word of warning: For medical systems, regulations differ between countries—in the United States, for example, you need to use HIPAA-compliant servers for many tasks. You also need a Business Associate Addendum (BAA). These regulations change over time—it’s your responsibility to comply. If your app is international, make sure you understand each country’s regulations.
Identification and Authentication
A bank improved customer success significantly in a voice-only solution by changing how authentication was done. They offered different methods depending on the level of security needed for the task and different approaches depending on what the user knew.
Will you know the identity of each user ? Do you need to? Think carefully about this because it affects the dialog flow, user experience, and system architecture. For most simple dialogs running on an in-home assistant, you probably don’t need to worry about security. We differentiate between identification, recognizing who the speaker is, and authentication, verifying their identity to give them secure access. Identification is something you’ll want to do if several people are likely to access the VUI on the same device and you want to incorporate past context and user preferences. Authentication is necessary when security and privacy is at stake, but only then.
For many tasks, user identity is not important: the answer to Will it rain today? is the same for me and you, assuming we’re speaking to a device in the same location, and there’s nothing private about the question or the answer. What’s important in that case is user location, which is a trait of the user but not enough to identify them. Some tasks benefit from knowing who is talking: my request to Play my workout music is probably different from yours. When dealing with financial or medical information, it’s obviously crucial to know who’s talking. There are many ways to do either; you’ll learn more in Chapter 15. For now, determine if you need to know who the user is. For the procedure prep voice app, you’d need to know something about the user: the date and time of their procedure, procedure type, procedure location, contact list, and maybe their calendar. You need to make sure to only give health information to the right user. You’d also need to track the user’s food diary. How do you access the right diary if several people in the same household track their food intake using the same device? Again, you’re only noting down your concerns, not potential solutions yet.
Error Handling and Navigation Behaviors
Supporting functionality needs of the procedure prep app
Authentication needs? | Some needed. Could be one-time device based, up front before any response, or just-in-time as needed. |
|---|---|
Identification needs? | Possibly. Multiple users in one household may have different preferences and usage history . |
Error handling? | Standard for tasks and domain. |
Navigation and control behavior? | Yes, for prep task (pause, next, repeat). |
System Requirements: How Will You Build It?
If you’re creating something small and simple, you can rely on the platform infrastructure. But if you go beyond those limits to where you need more control over the data—including collecting utterances—then system details become crucial.
AND COMPUTERS It’s popular to say you should design for humans and not for computers. We’d argue that’s too simplistic. Your goal should be to design for success. To succeed, you need to consider both dialog participants and their different strengths and weaknesses. Designing for humans means designing for humans interacting with computers that sound and behave like humans. By creating a conversational VUI, you set user expectations. You succeed only if you fulfill those expectations.
Recognizer, Parser, and Interpreter
In a bank app, new account types were introduced in a marketing blitz. A disappointingly small number of users seemed interested in the number of users reaching that part of the conversation flow. The problem was that the voice app couldn’t understand any questions about the new products because those names had not been added to the grammars.
The Internet of Things (IoT) use case : AGENT, dim the lights in the living room or AGENT, set the temperature to 70—controlling appliances via spoken commands addressed to and directed at an Alexa Echo device or Google Home device. The appliances themselves don’t have microphones or speakers for voice responses. These are connected devices, usually referred to as smart home. The vocabulary is more limited to not conflict with other requests.
Third-party devices with built-in microphones and speakers that make use of the recognition and NL “smarts” of Alexa or Google: AGENT, play music by Queen. The spoken commands are directed at a device that has its own microphones and speakers but is “inhabited” by one of the two voice assistants. These are built-in devices.
General VUI best practices apply across all, but details differ because the users’ needs differ, devices have different functionalities, and different overlapping architectures and ecosystems need to interact. Custom skills and actions need invocation, smart home and built-ins don’t, but need an explicit destination, like in the kitchen. Because of the platform-specific needs of smart home and built-in applications, we don’t focus on those in this book.
Expected recognition, parsing, and interpretation challenges of each functionality in the procedure prep voice app
Recognition challenge | Parsing or interpretation challenge | |
|---|---|---|
ToDoInfo | Low. | Low. |
GeneralInfo | Medium. | Medium. Broad open-ended set. Expect ambiguity. |
FoodSearch | High. Huge list, varied pronunciation. | Low. Expect ambiguity. |
MedSearch | High. Large list, hard to pronounce, varied pronunciation. | Medium. Users might include irrelevant info for the task (potency) or leave out relevant info (full drug name) or use generic names. |
PrepNav | High. Huge list, varied pronunciation. | Medium. Users can say a whole meal at once including details of size and amounts. |
Contact | Low. Hands-free use likely. | Low. |
Schedule | Medium. Personal names from limited list. | Low. |
ToDoInfo | Medium. Personal names, dates, times . | Medium. Users might request appointments with the wrong care team member. |
FoodDiary | High. Huge list, varied pronunciation. | Medium. Users can say a whole meal at once including details of size and amounts. |
As you move from smart home, via custom skills/actions, to fully custom solutions, you need more control over recognition performance, NL, and flow. If you’re creating a voice app or IVR for medical or financial use, you’ll be on the hook to get things right. You need to know exactly what went right and wrong.
There are other choices for recognition, parsing, and interpretation beyond what’s made available by Amazon and Google, including the open source DeepSpeech, Kaldi, and Sphinx and paid-for solutions from Nuance and others.
Your choices depend on your need for recognition accuracy and functionality, including challenging tasks like address or name recognition, large data sets, or long alphanumeric strings. Your ability to combine modules is quite limited. Google and Alexa provide statistical language models that allow you to get far fast without a huge amount of your own parsing and interpreting . But eventually you’ll run into limitations on what you can control because of decisions that have been made for you to enable simpler integrations. In Chapters 11 and 12, you learn some more hands-on techniques that allow you more flexibility and demand access to the speech data.
Content data for voice has a particular level of complexity and needs to be curated for voice. Even if you can find a database of food items or drug names, it’s unlikely that the content has been curated for recognition or categorized for your intent handling needs. Working with large data sets is a key component for accurate recognition and intent resolution. Incorporating it correctly allows a restaurant finder to understand a request for “The Brisbane Inn” even when transcription gives you “the brisbane in.” How do you handle names of artists that include symbols—and how do people pronounce those? You can get official lists of all current drug names, but they’re categorized based on chemistry and usage, not on common mispronunciations of the names. Even if you find a comprehensive ontology or listing of all food terms, it won’t include all regional names of some foods. That means someone needs to make sure that “grinder,” “hero,” “hoagie,” “sandwich,” “spuckie,” “sub,” “submarine,” and “zeppelin” are all handled the same, especially if they’re common on local menus. And that someone must verify that “faisselle,” “organic small-curd cottage cheese,” and “cottage cheese that’s homemade” are recognized and mapped to the same food—assuming it should be for the VUI’s context. And even if you create an in-house version with all the pronunciation and synonym details you need, you need to plan for updates. Who’ll update your data and retest everything when a new drug list is published? It’s very time-consuming and very important.
External Data Sources
Data is at the core of your recognition and intent resolution, as well as for output content and responses. Where do you find this data? Can you buy it or license it, or do you need to create it yourself? If you integrate with someone else’s data, are there cost or access limits? If it’s something like music or video content, do your users need to have their own direct account access to the content? Who keeps the data current? Will you need to handle updates to information that changes, or do you subscribe to updates? And what about secure info, like medical or financial records? What level of authentication is needed?
Is there some side benefit from building and maintaining the data? There can be. Even if you can get the data from somewhere, like names of foods or a drug name database, you need the right format for voice, for example, alternative pronunciations or content that’s accessible when heard instead of read.
You need someone qualified to create and verify your voice responses. This is both content creation and QA testing; it’s a crucial task when the information is in response to a health question. Responses need to convey content accurately as well as be designed for conversational voice dialogs. Very few people have the experience to do both well. Remember from Chapter 2 that you can never be sure that your VUI correctly understood the user. You’ll learn more about how to minimize the risk of providing the wrong responses. For now, each intent in the procedure prep app relies on some level of data processing for lookup and updates, as well as careful content response curation.
Data Storage and Data Access
Storing and accessing data is not as tricky an issue if you rely on a platform like Amazon or Google, but very important if you’re able to collect utterance data for tuning. Speech data takes a lot of space—plan for it.
Data storage requirements for the sample procedure prep voice app
Collecting speech data? | Yes. |
|---|---|
Collecting/updating user data? | Yes. |
Security needs ? | Yes. |
Expected latency issues? | Investigate. Expect data lookup to be fast. |
Other System Concerns
If you’re building a business product, you’ll need to interact and coordinate with other systems within the business, like websites, call centers, or mobile apps. Even if that’s not what you’re doing, you might interact with external systems to access ratings, send emails, or connect calls. Or you might want content output, like music. You’ll need transitions of data coordination as well as wording.
Some interactions are better suited for voice-only and others for multimodal solutions. Find out early if your VUI has a screen for input and/or output, the size and format of any screen, and what type of interaction is possible: touch/tap or remote control point-and-click. Is something already in place that you’re voice-enabling? Previously implemented navigation controls can limit your implementation choices (or at least slow you down), as well as the effectiveness of voice interactions. If most users are expected to look at options and results on a screen, you rely less on longer explanatory prompts or the need to pause spoken information. If face detection or recognition will be available, you can use it both to know if the user is looking at the screen and for personalized responses. Any on-screen button labels need to be coordinated with prompts—they need to be short to fit on the screen and distinct enough to be recognized well. Establish a process early for keeping prompts and images in sync during all phases of development.
Additional system concerns of the sample procedure prep voice app
Interactions? | Initiate calls. |
|---|---|
Language? | US English. |
Content output (music, video)? | None. |
Multimodality (screen)? | Incorporate images for multimodal devices. |
The default approach for multilingual VUIs is to first design the app in one language and start prototyping and implementation before adding other languages. At the planning stage, add time for translation and localization work and for every type of testing and tuning in each additional language. Plan the architecture: Will a VUI voice prompt have the same file name in all languages and be stored in separate directories, or will each name include a language tag? How will users pick a language? In an IVR it’s likely a menu up front. A mobile app can rely on screen menu or the device settings. What if it’s a new hardware device? Clarify who will ultimately handle translations and localization—you can’t just outsource it to someone with no voice experience, and you can’t rely on online translation tools. More on this in Chapter 15.
What’s Next?
That was a lot of information! What you learned here feeds directly into Chapter 5, where you learn about how to find real data to answer the questions raised here and how that data feeds into design.
Summary
Learn to look at all aspects of discovery and resource needs from a voice perspective.
You can’t limit the limitless, but you can set your scope to do fewer things and handle those well and then add functionality over time.
Technology choices made up front can limit your effort and success later in unexpected ways. Tradeoffs will be needed to handle the desired scope well.
Different voice tasks have different risks and needs; calculating the cost of being wrong is crucial and affects design and development at every step. During planning, designers, developers, and product owners all need to be equally represented and heard during every planning phase.
Databases and content need specialized curation for voice, both for information lookup and for result output.
You need to know what your users expect, what words they use, and why they’re talking to your app when they do.
Keep design out of discovery—this is the time to understand what’s behind the actual needs (user wants, business goals, resource limitations).