
Successfully developed and launched software spends the vast majority of its lifecycle in a state where it needs maintenance and support. In an environment where the number of services can easily outnumber the number of developers in your engineering organization, it is business-critical that operational support runs efficiently and effectively, without impacting the productivity and retention of your engineering staff.
This chapter will look at the processes and some of the available tools to help with achieving excellence in supporting your services. We will intersperse the discussion and recommendations with examples to underline the lessons learned from our experience of being on-call for many years.
What is Operational Support?
Let’s first define what we understand by operational support.
To us these are all activities that are aimed at supporting the functioning of an already launched service or feature according to the expectations—explicitly and implicitly stated—of the clients.
Implicitly stated expectations are requirements that are common sense, but were not explicitly stated in any specifications of the service or feature. If, for example, a newly introduced API functions as designed, but it causes the service to degrade in stability, responsiveness, or correctness of other APIs or features, or it results in scaling issues under increased load, then these issues should be accounted for as operational support.
The activities included in operational support work can be rather wide-ranging. They include not just root cause analysis for, and fixing of, obvious bugs and errors reported by automated monitoring or client reports, but also general maintenance work related to library or service framework upgrades, adding missing documentation, proactive searching for potential security bugs or edge cases that have not been accounted for, and answering technical questions by the client team.
Embracing Ownership
One of the major advantages that many developers (ourselves included) report getting out of working in a well-functioning microservices environment is that they feel empowered by the level of autonomy given to them. The “you build it, you run it” approach leads to encouraging the team to feel like true owners of their domain, and hence also feel more like they own an actual part in the business as a whole. And along with the feeling of true ownership comes a feeling of responsibility that needs embracing; your new-found autonomy means that the buck stops with you, as well.
Customers First
The first rule of business you should embrace is that if you don’t add value for your customers, then your business is doomed to failure. The best teams have it engrained in their culture to settle situations of disagreement and conflict asking themselves this question:
What is the best thing to do for ourcustomers?
If you have this mindset, then not only will decisions be easier to make, but you will also elevate the discussion of disagreements to a level where the egos of the people on your team are easier to extract from making business-savvy decisions. The focus will be on designing services for usability and solving real problems and thereby adding maximum business value.
Is the Customer Always Right?
Note that we intentionally did not phrase the question as “What does the customers say they want?” The question we did ask, about what is best for the customer, means that you should make sure you understand what the customer is trying to achieve, balancing the mission and architectural constraints of the services you own against the requests.
As an example, if a client team asked the books-service team to vend all books sold in the US, sorted by revenue in the shop, then the owners of the books-service should figure out whether such an API can be reasonably exposed in an efficient manner. At the very least, the service team should try to understand the constraints in which they can operate. Will the API really need to vend all books in the US? What would the client do with this data? Can the information be paged? Is there room for staleness in the revenue numbers by which to sort, or in the list of books? What is the anticipated call volume?
Only then can the service team make educated decisions about how best to serve the needs of this particular client, and also implement such an API without impacting other clients and overall system stability and responsiveness.
Operational Support Benefits Customer Trust
Many companies spent a lot of money on acquiring new customers. But how much budget does your business dedicate to keeping the customers you have happy and engaged?
A big factor in repeat business from your clients is how well you manage to establish and maintain their trust. But customer trust is hard to earn, and it is easily lost when you disappoint the clients’ expectations. That is exactly where operational support comes in: it is all about making sure that your service maintains client expectations. Therefore, investing in operational support is an investment in customer trust.
Making sure all systems are operational is not just contributing in the obvious and direct way, for example, by enabling your customers to make purchases on your site, or to sign up for your services. It is also an investment in keeping current customers’ trust that the site will be up, running, and behaving as they expect when they visit it.
It is much harder to regain a customer’s trust after it was lost due to a bad experience, and the money and time you’ve spent on acquiring the client in the first place is wasted. When a judgment call needs to be made between allocating developers to implementing new features and fixing already launched functionality, then a monetary value needs to be attached to the estimated loss of customer trust incurred per day of broken functionality, and it needs to be factored into the prioritization process.
For that reason, in the majority of successful businesses we have worked for, addressing operational issues always outranked new projects or feature work. When an outage arises and is noticed in a service that has launched, then this underlying issue should best be seen as a use case that was missed during development. It is just seen as though the launched feature is not entirely finished and hence needs fixing first before any new functionality is released.
No Code without an Owning Team
There should be absolutely no line of code (or whatever unit of software is run in the infrastructure) for which it is unclear who owns the maintenance and support issues.
Another very important point in this context is that software ownership is never assigned to a single person. Every service is owned by a team of people, and they share all ownership privileges and responsibilities . That does not mean that you cannot have subject matter experts in your team; in fact, you probably want to encourage developers to dive as deeply as they would like into the services they own.
It just means that shared ownership reduces the risk for the team, and the company as a whole, that all expert knowledge about a service in your system would depart with the single owner. Sharing ownership and knowledge in a team also sets up the team to support several services via an on-call rotation, the details of which we will discuss later in this chapter.
Any team can of course own several services, and in a microservices environment where the number of deployment units is often a multiple of the number of team members this is in fact the only practical approach.1 Therefore make sure that the team knows and documents exactly at each point in time which services, applications, libraries, and/or third-party software packages they own and maintain.
Keeping such complete and up-to-date mappings of software-to-team can be implemented and enforced in different ways. Your code control system could make sure that code repositories need to be owned by an existing team, and your deployment infrastructure scripts could check that an ownership field is present and validate its value with an up-to-date list of teams. To advertise the team-to-software details, you could introduce a simple, well-known engineering-wide documentation page, or a web UI on top of an ownership database, or even an actual service discovery registry in your microservices infrastructure.
The most important part is that maintaining such a mapping is universally accepted as part of your engineering team culture. Such acceptance and visibility needs to go so far that plans for engineering-internal team reorganizations always include a line item that makes sure that, after the reorganization, all software systems have a new owning team. If reorganizations do not include reassigning the services owned by disbanded teams, then you will end up with unowned but live systems, which therefore will become unsupported and hence are an accident waiting to happen.
Finally, avoid set-ups where some software is tagged to be owned by multiple teams. We have never seen such cross-team ownership arrangements work out well, as in practice such shared responsibility leads to confusion and often ultimately leads to no team feeling responsible for services that are officially of shared ownership.
Boosting Team Cohesion
Working on operational support for the services they own as a team is essential for embracing true ownership as part of the team’s culture. In a “you build it, you run it” environment, the team soon realizes that the systems they create spend the vast majority of their lifecycle in production and needing operational support; implementing and launching services is only a minute episode in the existence of a successful software application.
Organizing all the team’s activities and practices around making the software it owns easy and efficient to maintain becomes an objective that is in the team’s self-interest. This way, the team’s interests are well aligned with the clients’ interests, and—by extension—those of the entire business.
Another team-internal practice that helps team cohesion and the happiness of engaged and curious developers is to rotate team members through the feature development projects for all the software owned by the team. As mentioned above, there surely are advantages of having subject matter experts for each service, but allowing them to work on other services owned by the team can be a cost-effective risk reduction strategy.
The team will be able to shake the dangerous reliance on individual “heroes,” thereby mitigating the risk of time-intensive research and coming up-to-speed of other team members when the hero leaves the team. In short: the real heroes share their special powers to enable others to rely less and less on them.
When team members start working on services they previously did not engage with, there is great potential for cross-pollination: they see how things are done in a different code base, and so might recognize patterns that can be applied to the service in which they usually work. Conversely, having a new set of eyes on an existing service might contribute ideas about how to handle tricky problems or inelegant solutions in an improved way.
An advantage of rotating team members during feature development that applies directly to the team’s operational support efforts is that all team members become more familiar with the entire set of services the team owns. As a consequence, they usually also become more comfortable with being on-call for the full set of systems owned.
Our final advice regarding ownership and team cohesion is to avoid placing developers in a position where they straddle multiple teams at the same time.
This does not mean that we advise against loaning team members out to other teams; loaning is especially useful when a project in the developer’s home team is blocked by missing functionalities in a service dependency that is owned by a team is not staffed to dedicate time to implementing such feature.
In our experience it is simply not advisable to expect the developer who is on loan to another team in such situations to still fulfill responsibilities on the home team. When someone is on loan, she will be truly and fully embedded in the team to which she is on loan. This way, the loaned-out developer has enough time to focus on the task and give the members of her temporary team time to gain confidence that the code contributed by the embedded person can be maintained and supported by the receiving team.
What It Means to Be On-Call
In order for a team to implement operational support effectively and efficiently for the systems it owns, a (set of) developer team member(s) need(s) to be nominated and act as the point person(s) for addressing any and all support issues.
This role is usually referred to as being on call, and this section will explain the responsibilities and privileges of the person filling it. We will lay out an etiquette and code of conduct to be followed by the on-call person herself, as well as by the rest of the team and the organization in which they work.
While many of the points mentioned in the next section are applicable regardless of the architecture that is chosen for the overall business application, we will conclude this section by touching on some points that are particularly important to on-calls supporting microservices architectures.
Defining the Role and Process for Being On-Call
The most succinct, to-the-point definition of the role of an on-call developer comes from a presentation our former colleague Jon Daniel delivered at the 2015 DevOpsDays in Pittsburgh:2
The on-call’s role is to react to failure and prevent catastrophe.
This accurately summarizes the priorities of the person in charge of supporting a team’s production-deployed systems. First and foremost, the on-call person needs to make sure that new and current failure situations are addressed as they are ongoing, all with the overarching goal of preventing even greater impact through a potential total outage.
Issue Receipt and Triage
The ways production issues are reported or noticed can differ greatly. Some are manually generated bug reports from colleagues. Others are created automatically, via integration of your monitoring and alarming systems with your ticketing system. Where such integration is lacking,3 the on-call will have to manually create issues for tracking when aberrations become obvious from monitoring or alarming. Sometimes issues that are reported to the on-call are mere hunches about potentially faulty behavior, or requests for an in-depth analysis of the expected behavior under a given set of circumstances regarding one of the systems owned by the team.
In all such cases, the first step for an on-call is to make sure a support ticket4 for the issue exists; and if that is not the case, to create a ticket herself. It is essential that the team has a template for trouble tickets, with fields for minimally required information, such as ”expected behavior,” “observed behavior,” ”steps to reproduce the issue,” and so on. This helps to cut down on avoidable back-and-forth communication attempting to clarify information the on-call needs to track down the issue, thereby leading to faster resolution of the problem.
Once a ticket is created, it needs to be triaged based on the severity of its impact, and prioritized in relation to other unresolved production issues. For that it is important that the team think about generalized rules for severity and priority assessment. We will discuss an example for such rules in the subsection "Defining and Advertising Team Policy" later in this chapter.
Note that in organizations where development happens against services that are deployed to a shared sandbox fabric, it is usually the policy that the team’s on-call is also responsible for the proper functioning of the sandbox instance of the team’s services. While it is of course a serious impediment for the organization if the development efforts for teams that depend on the affected sandbox instances are impeded, the on-call generally applies a lower priority to such issues than is applied to problems surfacing in production.
Deciding What Work to Pick Up
Once the issues are properly triaged, the on-call will always pick the top priority-item on the list to work on and resolve. If the on-call person ever gets into a situation where all trouble tickets are resolved, then most teams all have a backlog of items that serve operational improvements. Examples of such operational improvement backlogs are tasks to address missing documentation for some of the systems owned by the team, or to add additional metrics to the team’s monitoring dashboard, or to fine-tune alarming rules. It is often also very useful to update the Standard Operating Procedure (SOP) documentation for the team’s services when new approaches to address recurring issues are discovered during the on-call’s current duty. Often, the on-call will also be tasked with writing or following up on post-mortems for outages in which her team has stakes or was directly involved5.
If the on-call still has spare cycles left to invest, they can often best be used to try to anticipate errors, hunt for issues that could arise in edge cases, delete unused code, or generally “kick the tires” of the application in use.
Whatever the on-call person chooses to spend her time with, she should decidedly try to steer clear of signing up for feature development or necessary technical improvement work that is tracked in the team’s sprint. In our experience, counting on the on-call to contribute to the team’s project work will lead to suffering: the team cannot rely on the on-call person’s availability for working on features, so they might over-promise features to representatives of the business-focused departments, which will lose trust in the team’s ability to deliver on their promises. At the same time, the on-call person—feeling pressured to deliver features—runs the danger of dropping the ball on critical operational issues.
As a corollary, this means that the number of members in an on-call rotation (usually, the team size) should be large enough to support a dedicated on-call person, which in our experience means that it should include around five to eight developers.
On-Call People Increase Team Efficiency
If this approach of dedicating a person to operational issues meets resistance in your organization, then the arguments raised usually amount to not being able to afford a dedicated on-call person , given other business pressures. Our advice in such a situation is to raise awareness of the costs of neglecting operational emergencies. It is not a question if outages will happen, but only when they will hit you, and if you can afford to not be prepared and—as a consequence—lose business or customer trust.
Try to compare the decision to save on operational support to an “unhedged call option” for stocks, rather than using the usual metaphor of “technical debt”6: unhedged calls can cost an unpredictable amount of money should they be exercised, whereas debt is predictable and can be managed.
Another part of the on-call role is to defend the rest of the team from interruptions. By being dedicated to all interrupt-driven issues and distractions, the on-call person shields the rest of the team from being disrupted, thereby guarding their focus.
Very conclusive arguments can be made that dedicating a single person to working on all the unpredictable, highly disruptive and stressful tasks increase the team’s overall productivity. Again, disruptions are a fact of life with technology, and even more so in an environment of distributed systems. Acknowledging this reality and preparing for the inevitable outage is a smart decision for every business to make.
The acting on-call person will act as the single point of contact for all operational and technical inquiry issues. Any other developer on the team should only be contacted and interrupted by the on-call person, and only if she deems it necessary (in cases where an urgent technical issues requires the knowledge or advice of another team member).
A Responsibility to Rest
In order to be successful in the role of acting as the team’s firewall, it is the responsibility for the on-call person to be alert and focused while dealing with operational problems. In most around-the-clock businesses, on-call people will need to be able to tend to problems as they arise, any time of the day or night. For that reason, they usually carry a pager or similar device, on which they can be made aware of urgent issues 24 hours a day.
In order for the on-call person to stay awake at the wheel, she cannot be allowed to be sleep-deprived and worn out for longer than is required to take care of high-severity operational problems. As a result, it should be expected that the on-call person is entirely autonomous regarding her time management. In short, if the on-call person feels worn out and tired after a night of dealing with outages, then they should feel obligated to sleep and relax during times with less trouble. During such times, the on-call should notify the secondary on-call person (whose role and responsibilities we will explain a little later) that he should step in when any urgent issues need addressing.
The On-Call Person in Relation to the Team
As laid out above, on-call duty play an important part in a development team that is also concerned with the operational aspects of the software they deliver. That is why investing thought into how to set up on-call duty for the team is valuable.
While being on-call means that you get exposure to a broad range of operational aspects of all services owned by the team, it can also be very distracting and stressful. So, in order to prevent developer burnout, make sure to establish a rotational assignment for on-call duty within your team. We have seen weekly rotations work best in practice, as shorter rotations impact effectiveness on follow-through of ongoing issues, while longer rotations easily can lead to loss of focus and fatigue.
It is important for team morale to include all team members in the rotation schedule. Make sure to respect the schedule and raise the expectation that it is important to integrate into planning. For example, make sure that, if your time-off overlaps with your on-call rotation slot, you trade slots with another team member before leaving.
Note that we also recommend including new team members and junior engineers into the rotation schedule as soon as possible. While it is natural that there are justified concerns from both the new or inexperienced team members and the more experienced ones that operational issues may not be addressed appropriately, new team members can always shadow the on-call person, or be a secondary on-call—a concept we explain more later. We have found this to be an excellent way to familiarize new team members quickly in a hands-on setting with the breadth of the systems that the team owns.
Another good tip we have is to make the on-call rotation overlap for an hour or so. This way, the previous on-call has time to walk through any operational issues still in flight, and the next on-call person is sure to hit the ground running.
While it is certainly true that the on-call people act as a protector of the team’s productivity by being a single point of contact for all interruptions, they should definitely not hesitate to escalate issues to team members when they feel stuck or in need of assistance. They need to be made comfortable to use their best judgement about when investing more time to understand the issue has diminishing returns given the severity of the issue and the expected contribution from another team member who is considered the expert in the area affected by an issue at hand. Operational issues are another realm where pig-headed attempts at heroism are unwarranted, as they might hurt the business. It is much better to admit defeat early and learn from pairing with the expert on resolving the issue.
Asking team members for input is especially important during the triage phase. You want to make sure that the impact and severity assessment of an unfamiliar issue is correct. In teams with a dedicated Technical Project Manager (TPM), the on-call person can often direct questions about prioritization of work relating to operational issues to the TPM, in case there are competing high-severity issues to be addressed.
We have seen that it usually takes at most one full rotation of on-call duty through the team until the benefits become very obvious for everyone involved. Especially the team members that are alleviated from distractions by the on-call person come to really appreciate the role she takes on. They soon start to develop the necessary empathy for the person currently on call, and they will even start to excuse grumpiness and irritability caused by constant interruptions and operating in fire-fighting mode. Everyone knows that they will be on-call sooner or later, as well, and that they can expect empathy, as well.
Being On-Call in a Microservices Environment
While it does not diminish their validity or importance in a microservices setting, any of the previous points about operational support apply more generally than just to microservices. This subsection addresses the finer points that are more directly focused on microservices.
Because of the extremely distributed nature of a microservices application, it is especially necessary to identify and document the list of all direct service dependencies. Outages of each of these dependencies not only need to be mitigated in the code, but they also need to be tracked, and potentially alarmed on, by teams owning dependent services.
For that reason, it is very handy for the team’s on-call to have access to the on-call logs and ticket list for all services that the team’s systems depend upon. Additionally, try to set up direct communication channels between team on-calls for related inquiries (for example, support chat rooms for well-known operations).
In the case of more widespread and impactful outages, it is advisable to spin up dedicated “war rooms,” which can be used to coordinate efforts to resolve ongoing cross-team issues. Note that such war rooms should not be abused to ask for extensive or repeated status updates; while an issue is still “hot,” no focus should be diverted from resolving it first. Status updates should be performed by the on-call person in charge, recorded alongside the ticket inside the ticketing system, and at a prenegotiated frequency (such as every 15 minutes, or even better, based on the issue’s severity).
Another great trait for an on-call person to have is to be very suspicious and follow hunches. If the metrics graphs on the team’s services dashboard just simply don’t look right, or if a seemingly transient issue remains unexplained, then an on-call person is more often than not well advised to investigate such oddities; more than once in our careers have we seen “icebergs of problems” hiding beneath seemingly small irregularities, so resist the temptation to sweep issues under the rug.
In a good microservices architecture, failures are kept from propagating by introducing expectations for acceptable response times, error counts, or other sensible business metrics (like sales per hour, and so on.). A team’s on-call person should be particularly wary of adapting alarm thresholds. Make sure to discuss any adaptations of alarming limits with the rest of the team and other potential stakeholders in your business. If your monitoring detects increased failures in services on which you depend, make sure you pass these issues on to the teams that own the dependencies. Insisting on having SLAs, and on adhering to them, is in everyone’s interest, as ultimately they benefit the consumers of your business’s application.
Tracking and Scheduling Operations Support Work
Even when microservices teams dedicate a (set of) developer(s) to operations support tasks, it is often unrealistic for all operational tasks to be resolved as part of an on-call duty; keeping the service up and running, or responding in adherence to its SLAs, simply outranks issues like version upgrades of frameworks used in the services.
A Lightweight Process Proposal
Whenever an operational issue arises that is estimated to take more time than a given low threshold (such as 15 minutes), a trouble ticket should be created. This guarantees visibility and traceability of operational support efforts. This means that reports can be run to identify the services that generate the most operational workload. Such visibility gives the team great input for prioritization efforts: a maintenance-intensive service can often easily justify refactoring work to fix the underlying issues that cause the frequent production issues .
Sometimes, when a team inherits a service that they did not develop themselves (for example, as a result of company department reorganization), they have a hard time answering requests or researching issues that relate to the correctness or expectations concerning the inherited service’s behavior. Such situations should be taken seriously, and often the creation of a “research and document” ticket is appropriate.
When the tickets generated outnumber the tickets resolved during any given on-call rotation shift, the operational workload is carried forward. In that case, it is important that you have a trouble ticketing system in which to track all backlogged operational tasks. The tickets in the backlog need to be tagged with an assessed impact severity level (based on team or company policy).7 Work on the tickets is generally guided by the SLAs associated with the tickets, but for tickets with similar resolution deadlines and severity, prioritization is handled ad hoc with input from other team members.
An important role in this could fall to a Technical Project Manager (TPM). A TPM is a person who acts as the interface between the business departments and the engineering team. The TPM is usually a very technically proficient person (such as a former software developer), who has acquired management skills and is also well informed about the business’s current priorities and future direction. Both the technical and business skills are needed to coordinate the development team’s day-to-day work priorities. The TPM should not just be aware of the team’s project work, but should also have enough information to help clarify an on-call person’s questions regarding the prioritization of trouble tickets.
In order to schedule work effectively in a microservices development team, it will help to have a tool in which all tasks currently workable by the team are visible. Such an overall team work items board should identify tasks in progress, as well as backlogged, ordered by priority, and it should include both project work and operational tasks. If your team implements agile software development principles, then such an overall work items backlog can be very useful during sprint planning. For example, we have worked in teams that decided to have an “all hands on deck” sprint dedicated to clearing out a backlog of important operational issues, after explaining the impact of addressing long-standing operational problems to the TPM, who then in turn successfully communicated to the business stakeholders that project work would temporarily be put on hold.
Under ordinary circumstances, though, all work items in the operational backlog should only be handled by the people on call. As mentioned before, this is important for shielding the rest of the team from distractions, so they can be more focused when contributing feature work. While on-calls should the only people allowed to contact the rest of the team for help with operational issues, they should still use this tool wisely to respect the team’s overall productivity.
Features to Look for When Picking a Trouble Ticket System
When choosing the right toolset for managing operational support it is important to understand the use cases you envision your organization to have. Once you understand your needs, you can research the features of existing trouble ticket systems that cover your use cases directly, or at least allow for customization. Following are the features we find most important when working with trouble ticketing systems in a microservices organization:
Company-wide use: Make sure the entire company has access to the list of operational issues, past and ongoing, so that research about outages can be performed without unnecessarily contacting and distracting on-calls. On a related note, we recommend not to expose the internal trouble ticket communications directly to external customers, as you do not want to burden the fire-fighting on-call people with public relations concerns, or matters of inadvertently exposing classified information or hints about security vulnerabilities.
Tracking by severity: A view of the list of issues, with the ability to sort and filter by a user-assigned severity, is essential. The on-call person can use this view to guide her decisions about which issue to work on next, while (internal) customers can understand the severity attached to an issue they are following, and how much workload is placed on the team’s on-call.
Tracking by SLA: Trouble ticket systems need a way to attach expected and agreed-upon deadlines for their resolution. It would be great to make these fields mandatory and potentially even prepopulated based on the ticket’s impact severity. This way, the team can communicate a date to the customers which they can use for their own planning purposes. Additionally, on-call people should be able to sort tickets by proximity to their respective deadlines, so that they can make sure to meet the issue’s resolution timeline based on the team’s published operational SLAs.
Help in identifying issue owner: In an environment with hundreds of services and multiple teams, it is often not self-evident which team’s on-call person should investigate an issue. The trouble ticket tool should be set up to guide the person filing the ticket in identifying the right team that can resolve the cause of the problem. As a corollary, the ticket system should allow for reassignment of issues, in case it was previously misassigned.
Ticket history and searchability: Trouble tickets should never be deleted, even when they are closed or resolved. This helps in being able to search the ticket database during issue analysis and severity assessment. Also, all changes to a ticket’s properties, as well as comments, status updates, changes in assignee or impact severity, and the like, should be logged in an audit trail entry, alongside a timestamp and handle of the acting user. This will help in later reviewing the exact timeline as part of a potentially triggered post-mortem (discussed later in this section).
Relating tickets: It should be possible to relate tickets to each other. In particular, it should be able to tag a given ticket as being blocked due to another, related ticket. The team’s on-call should be notified once the blocking ticket is resolved, so that she can make a decision about continuing work on the now unblocked task. To take this feature further, all internal customers should be able to subscribe to filterable status changes (like comments or updated severity), so that they don’t need to waste time actively checking status.
Integration with on-call scheduling tool: In order to correctly notify the team’s current on-call person of new tickets, and all other ticket-related communications, the trouble ticket system should be able to find out which (set of) developer(s) to notify. If your team runs on-call duty via a rotation schedule, then you want to be sure that changes in the rotation are automatically picked up by the trouble ticket system, to avoid delay and confusion in tending to operational issues. Often, the tool that is used to administer the on-call rotation schedule is also in charge of alerting the on-call of high severity issues, and escalating to a potential secondary on-call person, or the team’s manager. In that case, the trouble ticket system needs to be able to notify the on-call rotation system that new high-severity tickets have been filed, or that they are past their SLA date.
Integration with project work tracker: We advise that each team have easy access to, and visibility into, all work that the team needs to handle. Having an integration point that relates trouble tickets to tasks inside the project work tracking tool helps to address these needs.
Integration with post-mortems: We will explain the detailed contents and processes behind post-mortems later, but for now let’s focus on the fact that outages of a certain severity trigger deeper research into possible actions to take to prevent similar outages from reoccurring. The action items identified in a post-mortem should manifest themselves in trouble tickets with the appropriate owner, severity, and SLA, and status updates need to be visible in the post-mortem tracking tool.
Reporting capabilities: Many teams try to improve on dealing with operational workload, and you cannot improve in areas for which you have no metrics and measurements. Reports about new vs. resolved tickets per month, adherence to SLAs, and the services and features that are the heaviest contributors to operational issues are just some immediately obvious examples of reports your team would want to run. Many successful businesses (including Amazon.com) have very high visibility of trouble ticket reports, and the senior leadership level focuses on keeping operational churn low.
Analyzing all available trouble ticket systems is definitely not in the scope of this book, as the range of available features in each of them varies significantly. However, Wikipedia has an excellent overview and comparison page for issue tracking systems,8 which not only lists most of systems, but also tries to show an updated feature matrix.
While we have worked with a fair number of trouble ticket systems over the course of our work experience, we have not come to find a tool that we could unequivocally recommend. That said, we have worked in organizations that have successfully employed and customized Atlassian’s JIRA and BMC’s Remedy to handle operational issues satisfying the majority of the use cases we’ve discussed.
Dashboards to Support Operations
Another essential tool for on-call duty is a set of dashboards that graph the behavior of the systems owned by, or of interest to, the on-call’s team.
A service owning team should try to include metrics in dashboards that are based on at least two sources: data collected on the service-side, and data as seen from the service clients’ perspective.
Good candidates for inclusion in a dashboard that focuses on service-side metrics are, for example:
Endpoint response times: Add graphs per service API endpoint that track the API’s response time as measured in the service application. Make sure to monitor not just average response times, but also the times in which 95%, 99%, or even 99.9% of all requests are processed.
Response times per client: Draw the same response times per service API endpoint broken down by the client applications. As before, make sure to visualize not just average values, but also the outliers.
Call volume by endpoint: Seeing the call frequencies for each API endpoint is very useful as a way to detect peak times, and to relate potentially longer response times to a root cause.
Call volume by client: Displaying the API calls on a per-client basis is useful for analyzing sudden drops or surges, as they might indicate a client-side outage or unintended change in behavior. This is also very useful for verifying intended behavior in call patterns, for example, when a migration from a deprecated API to a new service API has been deployed and needs confirmation of having taken effect.
Error responses per code: Seeing the number of error responses returned by a client can give you indications about bad data or other service-side outages.
Error responses per client: If one particular client is affected by most error responses, then it is easier to pinpoint the client in which logic has changed causing bad requests, or requests for data that causes service-side data processing problems.
Messages consumed and published: If your service relies on consuming or publishing messages on an internal message bus, then visualizing metrics about the frequency of messages consumed or published on each of the relevant topics is useful information to observe.
Business metrics: Tracking business metrics around purchase rates, number of new customers, number of comments or reviews, and so on gives very expressive feedback and can help uncover problems that remain undetected when simply tracking the proper functioning of the technology involved. They can also help track down the root cause for changes in other metrics (like call volumes or service response times), or provide good indications for when planned outages or feature launches can be least impactful or risky (for example, to launch changes to the comment-service between 2AM and 4AM Eastern time because business metrics show that this is the period when the fewest customers post comments on the site).
Figure 14-1 shows operational metrics for an internal service in LivingSocial’s infrastructure. The metrics shown are extracted from service-side logs, aggregated and graphed using Splunk’s operational intelligence and log management tool.
Figure 14-1. Splunk dashboard showing service-side log-based real-time metrics
Client-side metrics that can help track down issues with a service can include:
Client-side error code data: Tracking success and failure rates of requests to the service inside a particular client can be used to alert a team to outages in a dependency, or indicate that a client-side library update did not go as expected.
Client-side performance data: The service performance data that matters the most is how it is perceived inside the client. Clients care deeply about the SLAs of their service dependencies, as their own responsiveness often is directly tied to their dependencies being performant.
Object deserialization costs: Wrapping code that turns the wire format of transmitted data back into programming language objects might indicate that perceived service slowness is in fact more accurately rooted in slow deserialization in the client, which might be fixed by requesting smaller response objects from the service.
Timeouts: While dependency timeouts should not lead to cascading issues, they are a welcome indicator for why the clients’ own functionality might degrade.
Circuit breaker status: Getting an overview of all open circuits for a client can help to identify which circuit settings might be overly stringent, or which dependency teams should be consulted about SLA improvements.
The graphs shown in Figure 14-2 are part of a dashboard that displays operational data collected in the client library of the internal service shown in Figures 14-1. The data was collected using StatsD ( https://github.com/etsy/statsd ), and the dashboard tool Grafana ( http://grafana.org/ ).

Figure 14-2. Grafana dashboard for client-side metrics based on StatsD held data
One reason for the usefulness of dashboards is that automated alarms to alert the team of exceptional behaviors are great when they work, but monitoring and alarming automation is never complete. Human intelligence often notices trends earlier and more reliably than algorithms do, and therefore can aid in detecting holes in alarming.
Some teams even go so far as to display the most important dashboards on large screens visible from their work and break room areas. The rationale for featuring these live metrics so prominently is that the cost involved is a good investment in raising awareness of how the system dashboards look under normal circumstances. Humans are incredibly efficient at pattern matching even when subconsciously observing visual clues, and we have seen engineers infer operational aberrations on numerous occasions simply by looking at out-of-the-ordinary patterns in graphs they regularly observe. As mentioned above, being suspicious and not shrugging of irregularities is an essential trait of someone taking on-call duty seriously.
Outage Etiquette
No matter how good your development and test processes are, outages will happen. The real question will be how quickly your team will be able to recover from the failure of a launched system. This section covers tuning your process for dealing with outages and working preparedness for these cases into your team’s routines.
Every Pager Alarm is a Failure
An organization is well advised to consider every occasion when a pager goes off—and a person is potentially woken up—as a failure whose root cause needs fixing. An intrusive alert should not happen unless it is unavoidable because the underlying problem has not been identified and addressed.
If you start seeing every instance of a pager alerting as an exception to root out, then you do not run the danger of simply accepting it as a fact of life as an on-call. You will start to see delaying the true resolution as the only unacceptable course of action. Sweeping the issue under the rug via some rationalization you or someone else comes up with cannot be acceptable.
The very least you should do is to analyze whether the problem is truly worth alarming someone about, and you should not take the research lightly. If you and the team determine that the problem was not truly worth waking up someone, then you need to find ways to make the alarming rules smarter to improve on discerning between relatively benign issues and issues that cause a pager to alert.
If you do not address such “false positives” in your alarming, you will see that fatigue and indifference to alarms will set in, and truly impactful exceptions run the danger of being ignored. Additionally, having overly sensitive alerting rules that require your person on call to investigate in a very stressful and disruptive setting will burn out your developers, and you will see increased levels of attrition.
If your company implements a policy that humans can manually trigger pager alerts—for example, when they have reason to believe they noticed a significant outage that has not yet been brought to anyone’s attention—then you need to set clear expectations about which class of issues are “pageable.” Therefore, a team—or even better, company—policy for operational support and SLAs is essential to implement. We will discuss the contents of such a policy later in this chapter. It should be made clear that, for example, requests for information regarding behavior of a system or the existence of, or implementation request for, a given feature are not acceptable reasons to page an engineer.
On the other hand, engineers need to keep a professional attitude when being paged by a colleague, irrespective of the time of day or night the pager rings. Ask the reporter for enough details needed to investigate and reproduce the issue. It is very reasonable to require that a ticket exist for any issue that is worth being paged about, so make sure you insist on recording all information as comments in the trouble ticket. If the issue is serious enough, based on criteria also defined in your operational SLA policy, then such information will be essential when you have to create a post-mortem.
Playbooks for Operational Support
Imagine you are the team’s on-call person, and your pager wakes you up at 3:00 AM. You are trying to adjust, wake up and not well enough rested to have all your mental capacity.
We have seen many teams address this problem by writing down Standard Operating Procedures (SOPs) in the form of step-by-step recipes, useful links, checks to perform or investigations to start. These are meant to be very explicit and easy to follow, so they can be consulted by an on-call person who is new, stressed out, or otherwise not in the best state of mind to analyze the root cause of an outage.
Here are a few things we encourage including in SOP playbooks:
Links to operational dashboards: Quick access to an overview page for all operationally relevant metrics is very useful for analyze root causes of issues.
Links to access and error logs: Looking at error traces and client access patterns is often invaluable when trying deal with an outage.
Contact information for owner team: Links to communication channels (such as a Slack channel) where to discuss outages, contact information for subject matter experts.
Architectural overview: Adding overview diagrams for the service’s architecture and its main component and dependencies helps tremendously when attempting to reason about the cause for an outage, or where to best place a patch.
If-then scenarios: This section lists known issues or previously experienced outages that could recur, keyed by how such issues usually manifest themselves, plus a checklist for verifying that the issue is encountered, and steps for fixing or mitigating. This is especially useful if it includes listing investigative steps for researching business alarms.
List of service dependencies: In a massively distributed microservices environment it is unfortunately rather common that an on-call person receives an alarm that is caused by degradation of a service dependency. While circuit breakers should prevent cascading failures, it is still essential that the dependent team know about the situation. Links to trouble ticket boards of all service dependencies and the contact details for all service dependencies’ on-call people should be easily found.
Health-check URLs: Verifying that an issue is no longer present, or helping to reproduce an exception, include URLs or cURL statements for every feature or API endpoint in your service application.
Production server access details: Sometimes problems can only be tracked down or reproduced by having direct access to the production hosts, where data or server condition can be checked or a service console needs to be opened. This also includes access to time-based jobs (such as crontasks) and their logs.
FAQs: Answering often-asked questions about the way some functionality works can be made much more efficient when listing them in an easy to find section on the SOP page. Also, such a section can list recipes for common administrative tasks, for example, modifying data not exposed by an API, running diagnostics queries on a secondary database, or whitelisting new client applications.
Note that such playbooks are only useful if they are followed often, and maintained and updated when found outdated, incorrect, or lacking. Whenever you find them in such a state, either directly update, or add to them as part of following these instructions, or create a support ticket to take care of it in the near future.
What to Do When the Pager Goes Off
In a team that takes addressing and fixing operational issues seriously, no two outages are exactly the same, simply because the previous outage was fixed in a way that will not allow it to recur. It is still worth providing some general proven rules and behavioral patterns that are appropriate when being alerted about an urgent production issue.
First and foremost, there is no use in falling prey to the temptation of panicking. Being informed by a very loud alert about an impactful outage certainly gets your blood flowing, but that should only go so far as making you aware that your undivided attention is needed to investigate the issue. Dealing with production system failures needs to take the highest precedence for you and the rest of your team, so if you feel like you are stuck or ineffective in fixing the issue, then this is an “all hands on deck” situation, and the entire rest of your team can be pulled in to help.
Next, make sure that you acknowledge the alarm, so and others do not get unnecessarily alerted. Getting alerted over and over is just annoying and distracting, and consequently counterproductive to quick resolution of the problem at hand. In many pager-duty support systems , tickets escalate automatically when not acknowledged, so be respectful of other people on the escalation path.
Once you have acknowledged the alert, create a trouble ticket (unless it already exists) and do just as much research as it takes to be reasonably confident you know enough to either fix the root cause, or improve the situation significantly. If you find a quick route to improve conditions, then take it! This often buys you time to work on a more complicated fix in a less impactful setting.
If you are in the unfortunate position that you get woken up by an alarm, then feel free to patch as little as necessary to address the immediate problem, but do make sure to work on a more permanent fix once you are fully rested.
While you research root cause and potential fixes, take a small amount of time to update the trouble ticket whenever there is news to share. Do not feel obligated to answer questions about status or progress while you work on researching or otherwise addressing an issue. If the inquiries become distracting, inform the person inquiring politely that answering questions distracts you from resolving the issue. Most teams make it a point in their team policy for operation support to mention intervals in which an in-progress trouble ticket of a particular severity is updated. Try your best to adhere to such a published SLA, but favor acting on fixing the issue over updating the ticket.
If, on the other hand, you need help or information from other on-call people or other team members, do not hesitate to reach out to them. Unless they themselves are busy dealing with issues of the same or higher operational severity, they should make every effort to help you.
It is also important that in your role as on-call person you refrain from passing blame while an issue is being actively worked. The time to assess what went wrong and how it can be prevented from recurring is after the issue is no longer causing production issues. A post-mortem, which is discussed in the next section, is the best place for such analysis.
Supporting Tools
There are quite a lot of choices for tool support for the above-mentioned measures to establish a well-functioning operational emergency protocol.
SOP pages and playbooks should first and foremost be easily found. If your company has not already launched an internal tool to enable teams to self-publish documentation, then it is definitely worth evaluating tools like Atlassian’s Confluence ( https://www.atlassian.com/software/confluence ) or a self-hosted Wiki (see http://www.wikimatrix.org/ for a site that lets you compare features of Wiki implementations).
As far as incident management and escalation tools go, we have personally had experiences with PagerDuty (in use at LivingSocial) and a heavily customized version of BMC’s Remedy (in use at Amazon.com). Other alternatives include VictorOps ( https://victorops.com/ ), OpsGenie ( https://www.opsgenie.com/ ), and the open-source tool Openduty ( https://github.com/ustream/openduty ).
The main features we have found indispensable for such a tool to be effective are:
An ability to acknowledge an incident and hence stop further alerting for it
Being able to de-duplicate incidents, so that no more than one alarm is generated for the same issue
The ability to integrate with a trouble ticket system for automatic ticket creation and relation
The ability to maintain an on-call rotation schedule that allows correctly routing alarms to team members based on the current rotation shift
Another valuable feature, albeit in the nice-to-have category, is to offer integration points to group communication tools like email, Slack, or Campfire to alert all stakeholders of incident status.
How to Learn from Outages:—Post-Mortems
The best engineering organizations strive to achieve operational excellence by learning from past outages. A post-mortem can be a powerful instrument to achieve this goal.
Post-mortems—originally used in the context of medical examinations otherwise known as autopsies—generally refer to the process of assessing successes and failures of a task or process after its conclusion. In the realm of on-call duty and operational excellence, their main purpose and value is to help with identifying lessons learned from an incident with a large impact.
When Is a Post-Mortem the Right Tool?
Good indicators for the usefulness of a post-mortem are that:
The issue that occurred, or could have occurred, is severe.
The occurrence of the issue appears preventable at first sight.
The root cause for the (near-)outage appears to need more research.
The issue analysis is worth sharing with a wider audience or preserving for posterity.
We recommend creating a post-mortem for every high-impact incident of a severity level that is negotiated within the engineering organization. As a rough guideline, you should discuss the value of creating a post-mortem each time your team’s on-call person gets paged, or should have been paged.
Additionally, it should be acceptable for anyone in the company to call for creation of a post-mortem, if she can argue that there is enough value to the business to outweigh the costs of going through the motions of a full post-mortem.
Note
Try to make sure that post-mortems are not understood as punitive in your organization. It needs to be made clear that the reason for the effort involved is the chance to improve on what you do, and to prevent further operational issues.
Structural Elements of a Post-Mortem
While there is no globally accepted table of contents for a post-mortem, we strongly advise that your engineering organization adopt a template that is shared across all teams. The following list outlines such a template, listing the contents we suggest discussing as part of every post-mortem:
Action summary: This lead-in contains a very brief, “executive summary” description of the outage that was dealt with and the actions that were taken to address the issue.
Business impact: A very succinct, to-the-point synopsis of the loss to the business is mentioned in here, with calculations that are as accurate as currently possible. The loss could be in various areas, for example, negative revenue impact, exposure of sensitive data, or loss of customer trust.
Actors: This section should include all people involved in causing or fixing the issue discussed.
Turn of events: A post-mortem should lay out a detailed and accurate timeline of all relevant events, starting from the initiation of the outage (such as the deployment of unsafe code artifacts), all the way to the (potentially temporary) resolution of the underlying issue. All significant actions and findings should be included and attributed.
Successes:In this part, the author of the post-mortem lists actions and practices that contributed to lessening the impact of the outage.
Root cause analysis: This section starts out with a more in-depth technical explanation of the cause of the issue and continues by analyzing the actions and circumstances that contributed to causing the outage. We highly recommend using the "Five Whys" technique to aid in these efforts (see the accompanying sidebar).
Lessons learned: Areas for improvements are identified and listed in this part, and they should be based on the results of the root cause analysis.
Action items: The points listed in this section are concrete, actionable improvements. They should directly relate to the cause(s) of the outage, and they should explain how they help to fix the identified root of the problem.
Post-Mortem Ownership
Every post-mortem has exactly one owner. The owner is not necessarily the same person or team who will work on addressing all action items identified as part of the post-mortem. Usually this role is filled by the author of the post-mortem, but often we seen the author’s manager take on ownership of all post-mortems authored by his team.
The owner of the post-mortem is tasked with helping to identify and track all resulting action items. She creates trouble tickets for each of them, each of which has a deadline and a ticket owner (or owning team) associated with it.
The owner will chase all tickets to completion by the assigned teams, and then she will resolve the post-mortem itself. She will also notify all parties involved of the resolution, and will make sure that the finished document is stored in a searchable repository, so that the knowledge gained is usable in the resolution of future issues.
While this process of following up and coordinating post-mortem action item resolutions can be time-consuming, it is nevertheless of utmost importance to make the process useful; if follow-through is not taken seriously, then the post-mortem process is mostly ineffective and should most likely be dropped entirely, as it will then only incur costs for very little value in return.
Defining and Advertising Team Policy
A lot of what makes an organization achieve efficiency and excellence in operational matters is rooted in the quality of the processes and policies they apply to support the systems they own. This section will lay out which points should be addressed in a policy for operational excellence, and we will give examples of policy points we have seen work well in practice.
Impact Severity and SLAs
In order to improve focus and enable the on-call person to make decisions about which operational issue to work on at any given point in time, it helps to categorize trouble tickets by level of severity.
To do that, define a handful of distinct levels of severity and classify each of them with its level of impact. Additionally, assign a priority level to each severity level, so that client expectations can be set about the on-call person’s attention to incidents in each severity category. For clarity, it usually also helps to add examples of outage situations that would fall into the specified severity and impact levels.
Figure 14-3 shows an example of how such incident severity, impact, and priority levels could be defined.

Figure 14-3. Definitions for issue impact and severity, with examples and priority levels
Once you have defined the severities, your customers need to know what level of service they can expect from your team. As a customer-focused team, you should set expectations for, and facilitate, communication with your customers. SLAs are an essential tool to achieve such customer focus, and they will also let you know when your on-call process is working and, more importantly, when it is not.
An example for a team SLA, based on incident severities, is shown in Figure 14-4.
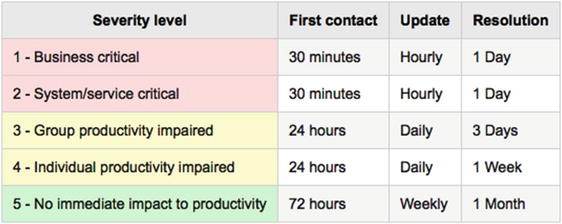
Figure 14-4. SLA for first contact, updates, and resolution of incidents by severity level
The meaning of first contact in the SLA definition is the most important part of the issue lifecycle, next to resolution. This initial contact informs the client that the issue has been acknowledged. Without such an entry in your SLA, the wait time can be frustrating for your clients. With a defined SLA, it becomes clear when follow-up will be warranted. In addition to reducing client uncertainty, the SLA reduces unnecessary and inefficient back-and-forth, allowing the on-call person more time to focus on issue resolution.
Similar arguments hold for the update SLAs. Sometimes, resolving a trouble ticket can take the on-call person several days. Updating a ticket that is in progress serves a similar purpose to the first contact, as each update shows the client that their issue has not been abandoned. Updates that simply state that the efforts continue to be blocked still demonstrate strong ownership. By keeping your customers abreast of progress, anxiety and uncertainty is reduced.
Also advertise which type of incidents you consider worthy of analyzing in a post-mortem. You can use the severity level as an indicator (for example, all incidents of severity 1 and 2 trigger post-mortems), or you could take the stance that they apply mainly to more systemic issues that need to be addressed. As we have shown earlier in this chapter, a post-mortem is an effective tool to address process failures for systemic issues.
Publishing an SLA for issue resolution is the most important step for your clients, as it sets expectations they can rely on. If this underlying problem is blocking work on the client side, this expectation can help your customers identify risks in their own roadmaps.
While it is first and foremost the team’s responsibility to set the SLAs and severities, the results need to be acceptable to the clients and other stakeholders in your company. Deciding whether an SLA or a severity judgement needs to be adapted is up to negotiations between your team and the internal customers, but it is very important to publish your policy up front.
Share the Steps of Your Process
Publishing the details of how your team goes about processing your operational issues helps clients to understand each phase involved in resolving an incident.
A sample list of steps could be as follows:
Generation: When an operational issue for one of the systems owned by the team arises, a trouble ticket will be created and assigned to the correct on-call person. Make sure to advertise how to find the correct group in the trouble ticket system so that the ticket does not get misassigned and therefore might linger longer than needed.
Triage: The team’s current on-call person will investigate the issue to a level where he can assess its severity, and an appropriate label (such as SEV-3) will be added to the ticket.
Processing: The on-call person is in charge of deciding which issues take priority, and hence will be worked at any given point in time. Decision guidelines for the on-call are based on issue severity and published SLAs, along with feedback from other team members and other engineers. All communication about a ticket’s cause, technical details, and status will be captured in ticket comments. This mainly serves historical and documentation purposes. External inquiries about status should be kept to a minimum in order to avoid distracting the on-call from actually working on the issue’s resolution. In return, the on-call aims to update ongoing issues based on the published SLAs, so that ticket stakeholders can be kept abreast of developments.
Resolution: The team will strive to adhere to the published resolution SLAs, and it will alert stakeholders with as much advance notice as possible about any risks that could cause such deadlines to slip. Issues of severity 1 and 2 should automatically result in a post-mortem.
Finally, it is within each team’s ability to customize its on-call policy, but strive to streamline the policies, process and SLAs across the entire company. This will help internal clients to have confidence that their issues will be addressed, that no time is lost trying to contact owners, and they can set their own customers’ expectations correctly based on a generally accepted the process.
Summary
This chapter focused on all aspects of what it means to be part of a team that works under the “you build it, you run it” premise. After defining what operational support means, we explained what comes along with the obligations of true ownership for microservices.
Next we looked at the role of being on call for the services owned by your team. We discussed responsibilities for the on-call person, in relation to the rest of the team, as well as when serving client teams that rely on the software you own.
We also gave tips for how to organize and prioritize operational workload compared to the project work requests handled in a microservices team, and we discussed important features for tools that are meant to support the team’s efforts to track both types of work.
After a brief examination of operational dashboards, we gave an overview of a practical approach to handling system outages when being the on-call person in charge.
We showed the importance of learning from outages, and walked through the process of analyzing such incidents using post-mortems.
We concluded this chapter by discussing the topic of defining and sharing a policy of how your team handles operational ticket work, and how to best set client expectations using SLAs and incident severity definitions.
Footnotes
1 While it is very hard to give meaningful guidance about optimal team sizes or the best number of services per team developer, in our experience the sweet spot most successful microservices companies choose is between 5 and 8 developers per team. If automation is advanced in an organization, then the ratio of microservices per team member (or developer) does not have a clear upper bound. Running multiple services per developer is definitely possible if development and deployment processes are streamlined.
2 Jon Daniel, "Ethical and Sustainable On-Call,” August 13 2015, DevOpsDays Pittsburgh; An overview of Jon's inspirational talk, including slides and a link to a video recording of the talk, can be found on his personal blog at: https://chronicbuildfailure.co/ethical-and-sustainable-on-call-c0075e03a7b
3 Automatic ticket creation is hard to get right, as often this leads to many duplicated or similar trouble tickets that are rooted in the same underlying issue. An on-call person will then spend a lot of time on de-duplication and other unnecessary ticket management tasks.
4 We will discuss properties of useful trouble ticketing system later in this chapter.
5 We will talk in more detail in later subsections about dashboards, SOPs, and post-mortems.
6 See Steve Freeman's blog post "Bad code isn't Technical Debt, it's an unhedged Call Option" (July 23 2010) for a more detailed explanation of this argument; http://higherorderlogic.com/2010/07/bad-code-isnt-technical-debt-its-an-unhedged-call-option/
7 The “Defining and advertising team policy” section later in this chapter lays out points to address in a policy for severity assessment and issue prioritization.
8 “Comparison of issue-tracking systems” Wikipedia. https://en.wikipedia.org/wiki/Comparison_of_issue-tracking_systems
9 See “5 Whys,” on Wikipedia, for more details about the origin and history of this technique. https://en.wikipedia.org/wiki/5_Whys