
Microsoft SQL Server Data Replication Overview
Yes, you can use data replication as a high availability solution! It depends on your HA requirements, though (as usual). Originally Microsoft's SQL Server implementation of data replication was created to off-load processing from a very busy server such as an online transaction processing (OLTP) application. Data replication enabled big chunks of processing (like that of reporting) to be isolated “away from” the primary OLTP without having to sacrifice performance. It also was well suited to support naturally distributed data that has very distinct users (such as a geographically oriented order entry system). As data replication became more stable and reliable (post MS SQL Server 6.5's implementation), it could be used to create “warm,” almost “hot” standby SQL Servers. If failures ever occurred with the primary server in a replication topology, the secondary (replicate) server would still be able to be used for work. When the failed server was brought back up, the replication of data that had changed would catch up and all of the data could be resynchronized. When doing transactional replication in the “instantaneous replication” mode, data changes on the primary server (publisher) are replicated to one or more secondary servers (subscribers) extremely quickly. This type of replication can essentially create a “warm standby” SQL Server that is as fresh as the last transaction log entries that made it through the distribution server mechanism to the subscriber. And, along the way, there are numerous side benefits such as achieving higher degrees of scalability and mitigating failure risk. Figure 7.1 shows a typical SQL Server data replication configuration that can serve as a basis for high availability and which also fulfills a reporting server requirement (at the same time).
Figure 7.1. Data replication basic configuration for HA.
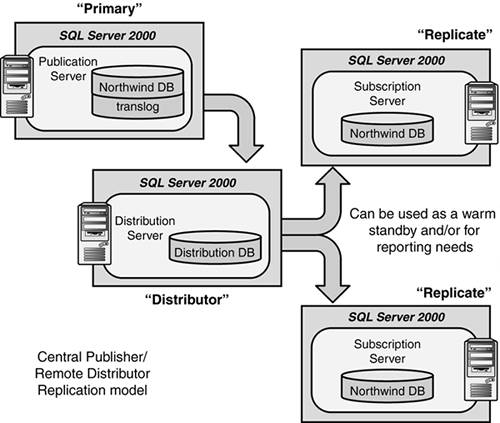
This particular data replication configuration is a “central publisher, remote distributor” replication model. It maximizes on isolating processing away from the primary server (publisher) including the data distribution mechanism (the distribution server) part of the replication model.
There are a few things to deal with if ever the “replicate” is needed to become the primary server (take over the work from the primary server). Essentially, it takes a bit of administration that is NOT transparent to the end-user. Connection strings have to be changed, ODBC data sources need to be updated, and so on. But, this may be something that would take minutes as opposed to hours of potential database recovery time, and may well be tolerable to the end-users. There also exists a risk of not having all of the transactions from the primary server make it over to the replicate (subscriber). Remember, the replicated database will only be as fresh as the last updates that were distributed to it. Often, however, a company is willing to live with this small risk in favor of availability. For databases that are primarily read-only with low to medium data and schema volatility, this is a great way to distribute the load and mitigate risk of failure thus achieving high availability.