
General Design Approach for Achieving High Availability
A good overall approach for achieving high availability for any application can be accomplished by
Shoring up your “software” system stack from the center out (operating system, database, middleware, antivirus, and so on, in this order). This would include upgrading to the latest OS levels and other software component releases, and putting into place all the support service contracts for these (this turns out to be extremely important for being able to get that quick fix for a bug that happened to bring your system down).
Shoring up your hardware devices (redundant network cards, ECC memory, RAID disk arrays, disk mirroring, clustered servers, and so on). Be careful with the RAID levels since these will vary depending on your applications characteristics.
Reducing human errors by way of strict system controls, standards, procedures, extensive QA testing, and other application insulation techniques. Human errors account for many a system being unavailable.
Defining the primary variables of a potential highly available system. This should also include defining your applications' service level requirements along with defining a solid disaster recover plan.
Figure 1.9 depicts a “one-two” punch approach that blends all of these areas into two basic steps that need to be taken to achieve high availability for an application.
Figure 1.9. “One-Two” punch for achieving high availability.

The basic premise is to (1) “build the proper foundation first” followed by (2) applying the appropriate HA solution that matches your applications' needs.
This proper foundation would consist of
Building the proper hardware/network redundancies.
Putting into place all software and upgrades at the highest release levels possible, including antivirus software, and so on.
Designing/deploying disk backups and DB backups that best service your application platforms.
Establishing the necessary vendor service level agreements/contracts.
Comprehensive end-user, administrator, and developer training including extensive QA testing of all applications and rigid programming, system, and database standards.
You must then gather the details of the high availability requirements for your application. Start with the HA primary variables and go from there. Then, based on the software available, the hardware available, and the high availability requirements, you can match and build out the appropriate HA solution on top of this solid foundation.
The types of high availability solutions that will be emphasized in this book are
Cluster services (MSCS)
SQL clustering (MS SQL Server 2000)
Data replication (MS SQL Server 2000)
Log shipping (MS SQL Server 2000)
Distributed transactions (MS Distributed Transaction Coordinator)
Application clustering will only be described in concept and not in any technical detail, since it is programming oriented and really would require a complete programming book to give it the proper treatment.
Development Methodology with High Availability “Built In”
Figure 1.10 shows a traditional “waterfall” software development methodology. As you can see, understanding and gathering information that will yield the proper high availability designs for your application can start as early as the initial assessment and scoping phase (phase 0).

The general software development phases and the corresponding high availability tasks within each phase are
Phase 0: Assessment (scope)
Project Planning
Project Sizing
Deliverables Identified (Statement of Work)
Schedules/milestones
High-Level Requirements (scope)
Estimate the High Availability Primary Variables (gauges)
Phase 1: Requirements
Phase 2: Design
Detail Design (data/process/technology)
Choose and design the matching High Availability solution for the application
Phase 3: Code & Test
Code Development/Unit Testing
Fully integrate the High Availability solution with the application
Phase 4: System Test & Acceptance
Full System Test/User Acceptance
Full High Availability Testing/Validation/Acceptance
Phase 5: Implementation
Production Build/Implementation
Production High Availability build/monitoring begins
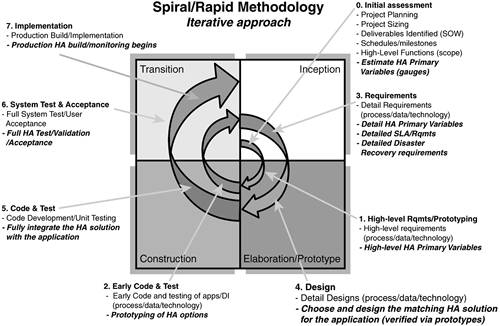
For those following a rapid development, “iterative” life cycle (commonly referred to as a rapid/spiral methodology), Figure 1.11 lays out the same type of high availability elements within this iterative development approach.
Assessing Existing Applications
If you haven't integrated high availability into your development methodology, or if you are retrofitting your existing applications for high availability, a more focused mini-assessment project can be launched that will yield all of the right answers and point you to the proper high availability solution that best matches your existing applications' needs. I call this “Phase 0 (zero) high availability assessment” (aka the “weakest link assessment”).
Essentially, you must quickly understand
What are the current and future characteristics of your application?
What are your service level requirements?
What is the impact (cost) of downtime?
What are your vulnerabilities (hardware, software, human errors, and so on)?
What is your timeline for implementing a high availability solution?
What is your budget for a high availability solution?
These types of assessments can be crunched out in five to seven days. This is an extremely short amount of time considering the potential impact to your company's goodwill and to its bottom line. Completing this type of “Phase 0 high availability” assessment will also provide you with the proper staging platform for the next several steps. These next steps would include defining your formal service level requirements, selecting the right high availability solution, building it, testing it, and implementing it. Oh, and enjoying the comfort of having a rock-solid high available solution in place (that works!).
If you have time, make sure you include as much detail as possible in the following areas:
Analysis of the current state/future state of the application
Hardware configuration/options available
Software configuration/options available
Backup/recovery procedures used
Standards/guidelines used
Testing/QA process employed
Personnel administering systems assessed
Personnel developing systems assessed
One deliverable from this assessment should be the complete list of primary variables for high availability. This will be one of your main decision-making tools for choosing which high availability solution matches your application.
Service Level Agreement
Service level agreements (or requirements) have been mentioned over and over in this chapter. Determining what these are and if they are needed is essential to understanding a high availability need.
Basically, a service level agreement (SLA) is a contract between the application owner (custodian) and the application user. As an example, an employee of a company is the application user of a self-service benefits application and the HR department is the application owner. The HR department signs up (via an internal SLA) to have this application be available to employees during normal business hours. This is what the HR department is held to (measured against). Then, in turn, the HR department might have its own SLA with the IT department that administers and maintains their application. An SLA will have the following basic elements:
Application Owner
Application User
Application Description
Application hours of operation/availability
Agreement Terms:
Duration of agreement (often yearly)
Response time levels (to failures, application enhancements, so on)
Procedures/steps to follow
Penalties if levels not met (very often monetary)
Describing penalties is especially important if you want this kind of agreement to have “teeth,” as it should have. Companies such as application service providers (ASPs) probably have the most comprehensive and most severe SLAs on the planet. Of course their livelihood depends on meeting their SLAs, and perhaps they get huge bonuses when they exceed their SLAs as well.