
Things to Consider for High Availability
Up to this point, we have described the typical high availability paths that you can pursue that are built with Microsoft SQL Server and the Microsoft Windows Server family software. Very often, these high availability options can be implemented extremely quickly and easily. There are, however, many other things that need to be considered when building a high availability platform. This chapter will re-emphasize the primary design considerations and some common configuration options for highly available hardware, OS, and network components, and highlight critical design points for each HA option that we have described thus far. In addition, we will stress database backup and recovery strategies, describe the high availability ramifications for MS Analysis Services (MSAS) since it is also included with MS SQL Server, and identify some possible HA alternatives from third-party vendors. We would even like to spend a little time talking about worst-case scenarios that would require you to recover following a major disaster (disaster recovery). Let's start with your hardware and operating system, and work up to the primary Microsoft HA options (MSCS, SQL Server clustering, SQL Server data replication, SQL Server log shipping, and distributed transaction processing).
Hardware/OS/Network Design Considerations
We have harped quite a bit about building a solid foundation from which to build high availability. This has included defining redundant hardware components such as multiple network cards, redundant power supplies, redundant cooling fans, error correcting memory (ECC), and even redundant boxes. Spending the extra time and money to incorporate these solutions directly affects your system's availability. Whether they achieve your high availability goals by themselves is another question (to which the answer is most likely “no”). But, they can take you a long way in the right direction. These are things like
Regularly swapping out hardware components that reach a certain life. All hardware has a life expectancy; it is up to you to know what this expectancy is, keep track of the life expectancy of each hardware component in your systems, and schedule maintenance such as swapping old ones out and replacing them with new ones on a regular basis. As an example, let's say a moderately high quality SCSI disk has a life expectancy of three years (of continuous operation). If you have one disk failure in a RAID array in the first year of a system then you just deal with correcting that one failed drive; if you have a failure in year two or later, then this is a sign that more disks of the same age will be failing soon. You should set a plan that never allows you to get tothis second failure situation. Be proactive here. Don't wait until you start having failures to deal with this approach. If you have a servicing agreement with a vendor, make sure you define the hardware replacement schedule for them (or they should be prepared to define one based on life expectancy and usage).
Start with the redundancies up front. Do not wait on this. When you put your first server into service (into production), it should already be at a base high availability foundation level. As you may recall, this should start with
Redundant hot swappable CPUs
RAID or other redundant disk array systems
ECC memory (that is hot swappable if possible)
Redundant cooling fans
Redundant power supplies
UPS—uninterruptible power supplies
Redundant network connectors (adapters)
We took a sampling of 10 leading highly available systems and found the following characteristics across the board:
Hot swappable I/O modules (network connectors and disk subsystems) on multiple channels
Isolation of faulty modules capability
User notification through module-level LEDs and relay alarms
N+1 hot swappable power supplies and fans
Backup generators available since UPSs only have a limited lifespan
You then combine this with multiple fault-tolerant disk arrays (RAID) and you are headed to five 9s.
Get OS-level and network-level software patches and upgrades applied on a very regular basis. This will guarantee that you have the most up to date fixes, security patches, OS or Network upgrades, and that the vendor (Microsoft) can support you readily. If you choose not to apply service packs, upgrades (like from Windows 2000 server to Windows 2003 server), or patches to your OS or network software for long periods of time, you are asking for trouble. I found a customer the other day that was still running NT 3.5 with SQL Server 6.0. They had a problem but Microsoft wouldn't support them because they were not on a fairly current OS and SQL Server release.
Use NAS—Network Attached Storage (or SANs) for data resiliency and data management ease. Now that accessing data via fibre level speeds is commonplace, we recommend that the robust capability offered with NAS be tapped in any high availability solution. These NAS devices can support most RAID level configurations and can expand to any storage requirement that you desire, particularly NAS devices that offer multiple channel connections (for redundancy).
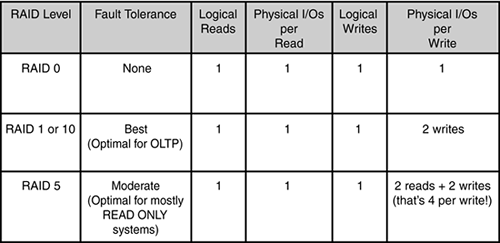
Sizing—When sizing the system, it is important to keep in mind not only the storage capacity that is needed, but also the performance levels that must be maintained. A single disk drive can handle approximately 85 I/Os per second before latencies increase and performance begins to degrade. If the choice is a SCSI disk subsystem and it is configured with a shared volume(s) as RAID 5, it will lead to a significant number of extra I/Os during writes as well as increased write latencies due to the RAID 5 parity. So, choose your RAID levels well. Figure 10.1 shows the fault-tolerance and the I/O cost of the most often used RAID configuration levels.
Be proactive with monitoring tools and understand your resource utilization levels. A saturated CPU is sometimes equally as crippling as a downed server. When CPU and memory utilizations stay above 75% for prolonged periods of time, proactively plan upgrades to bring these down to an average sustained utilization of around 30%. That's about right.
Training on hardware/OS/network components is critical to your high availability goals. Make sure you budget and get your folks trained in all aspects of recoverability and administration in support of high availability. Not every part of a high availability solution is automated. Someone has to push the right button or administer upgrades, and so on.
Service level agreements with your vendors must correspond to the promised service level agreements you make with your end-users. If you have a hardware failure and your SLA with hardware vendor has a 24-hour service window, but your SLA with your end-users is 1 hour max downtime, you can be caught just sitting around waiting for your vendor to casually stroll in. This happens all too often. In addition, a comprehensive SLA with your vendors should also include keeping your hardware and software components as current as possible. Do not skimp in this area. Money may be tight, but extended downtime can quickly translate into huge money losses.
Network load balancing is multi-faceted in that it supports scalability along with availability. If your user base is large and growing, this is an area that you will want to expand into. Microsoft has made this fairly easy to embrace and should be designed into your larger user application implementations from the start.
Backup and recovery at the disk level is an extra insurance policy that many wish to pursue for highly available systems. Most NAS vendors offer high-powered disk backup mechanisms that can back up huge amounts of data in very short amounts of time. This includes leveraging mirroring techniques, writing to disk-based backup devices, traditional tape backup devices, and remote devices (via internet connections). It is critical to make sure all logically related components of a highly available system get backed up (and usually need to be done together). Then, you also need to understand and test recovering a system from its backup. The amount of time it takes to recover dictates what backup device media you use for backups. This is very different from database backups and recovery. This will be covered later in this chapter.
Remote Mirroring
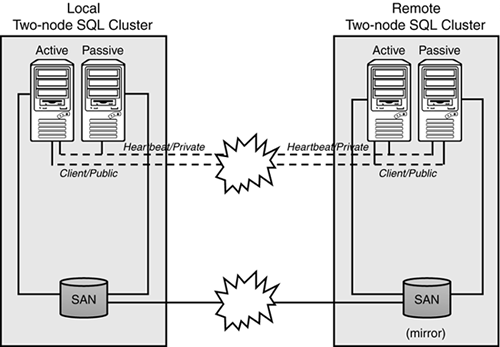
An approach that is growing in popularity is remote mirroring. Remote mirroring is a solution offered by third-party vendors that allows you to maintain a real-time mirror of your primary storage device at a remote site and to protect your data on that mirror from site destruction. In a remote mirror, redundant server hardware and a redundant storage system are maintained at the remote site (which is a bit costly). Most often, remote mirroring is accomplished over a direct IP address connection or within the confines of a virtual private network (VPN). Figure 10.2 illustrates a remote mirroring configuration.

A remote mirroring solution ensures absolute transactional currency and consistency for the mirrored data. If the primary server fails for any reason, the remote mirrored copy can be used in its place. It is not a completely transparent solution, but the data integrity is guaranteed to be intact. Typically, a SAN is used in each site. Each SAN is connected with fibre (if the sites are separated by less than 100 kilometers [km]) or with conventional Internet Protocol (IP) circuits with fibre channel to IP gateways. At any one time, only one of the SANs is active, updating its own local store and forwarding updates to the other SAN (the mirror). This approach is probably only valid if you can guarantee the stability of the communication lines and speed of these lines. If this communication is reliable, you will be able to build a solid fail-over site that could even cover your disaster recovery needs.
Microsoft Cluster Services Design Considerations
The things to consider with MSCS are primarily related to what you need MSCS groups to manage together or manage separately. In other words, you should plan on putting SQL Server items together, and resources that need isolated protection such as the quorum disk and MSDTC in separate groups. As you remember, a cluster group is a collection of logically grouped cluster resources, and may contain cluster-aware application services such as SQL Server 2000. This cluster group is sort of like a folder that has all the things you need to keep together (that you want to fail-over together). Figure 10.3 shows the basic MSCS configuration topology of a two-node cluster.
Figure 10.3. MSCS configuration topology for an active/passive two-node cluster.
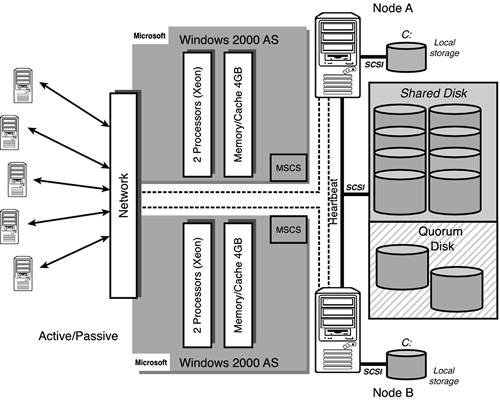
As you can see in this diagram, the quorum drive should be isolated to a drive all by itself and be mirrored to guarantee that it is available to the cluster at all times. Without it, the cluster won't come up at all and you won't be able to access your SQL databases. A General rule of thumb is to isolate the quorum resource to a separate cluster group if it is possible!
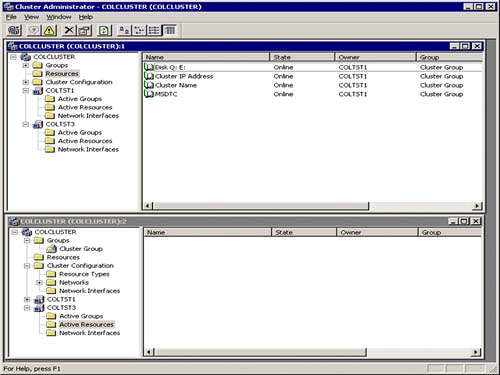
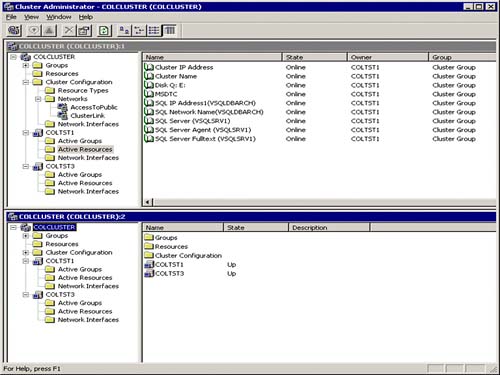
Figure 10.4 shows the minimum resources controlled by Cluster Services prior to installing SQL Server clustering. These are
Shared physical disks (quorum and data disks)
The cluster IP address
The cluster name itself (network name)
Figure 10.4. Cluster Administrator console view of the resources managed by MSCS.
SQL Server Clustering Design Considerations
SQL clustering is rapidly becoming the default high availability configuration for many organizations. But, it still should only be used when it fits your particular high availability needs. SQL clustering requires a fairly advanced set of hardware, OS, and network configuration to be in place and is fairly administrative intensive. SQL clustering is not for the faint at heart! SQL clustering builds on top of Microsoft Cluster Services and is said to be a “cluster-aware” application. In other words, MSCS manages all the resources needed to run SQL Server. If you have a SQL Server based application and your availability requirements are above 95% uptime (high and extreme availability), you are likely to be using a two, four, or more node SQL clustering configuration.
When you install a SQL Server in a clustered server configuration, you create it as a “virtual” SQL Server. In other words, a virtual SQL Server will not be tied to a specific physical server. Figure 10.5 shows a two-node cluster configuration with all of the SQL Server components identified. This “virtual” SQL Server will be the only thing the end-user will ever see (the virtual server name is VSQLDBARCH and the SQL Server instance name is VSQLSRV1).
Figure 10.5. Two-node SQL clustering topology in an active/passive configuration.
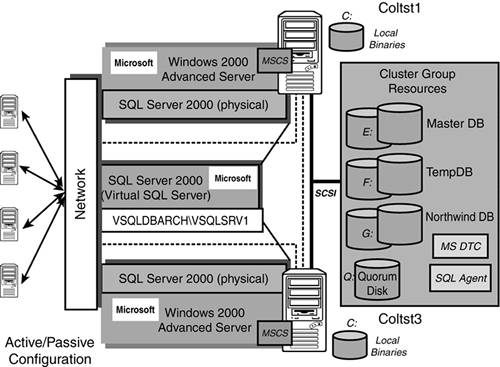
From the network's point of view, the fully qualified SQL Server instance name will be “VSQLDBARCHVSQLSRV1”. Figure 10.5 also shows the other cluster group resources that will be part of your SQL clustering configuration. These, of course, are MS DTC, SQL Agent, and the shared disk where your databases will live. A SQL Agent will be installed as part of the SQL Server installation process and is associated with the SQL Server instance it is installed for. The same is true for MS DTC; it will be associated with the particular SQL Server instance that it is installed to work with (VSQLSRV1 in this case). Remember, the quorum drive should be isolated to a drive all by itself and be mirrored to guarantee that it is available to the cluster at all times. Without it, the cluster won't come up at all and you won't be able to access your SQL databases.
One or more physically separate shared disk arrays can house your SQL Server managed database files. In a SQL Server database, it is highly desirable to isolate your data files away from your transaction log files for any database that has volatility (like with OLTP systems). In addition, perhaps one of the most critical databases is a SQL Server instance is the internal shared database of TempDB. TempDB should be isolated away from your other databases and perhaps placed on some high performing disk configuration such as RAID 10. SQL Server requires TempDB to be allocated at server startup time so the location of TempDB should be protected rigorously. Do not place TempDB on a RAID 5 disk array! The write overhead is far too much for this internally used (and shared) database. In general, put your OLTP SQL Server database data/transaction log files on RAID 10 or RAID 1 (including master DB, model DB, and MSDB) and your DSS/READ Only data/transaction log files on RAID 5. As you set up SQL clustering you will also need to be aware of the following:
SQL Server service accounts and passwords should be kept the same on all nodes or the node will not be able to restart a SQL Server service. Use “Administrator” or, better yet, a designated account (like “cluster”) that has administrator rights within the domain and on each server.
Drive letters for the cluster disks must be the same on all nodes (servers).
Create an alternative method to connect to SQL Server if the network name is offline and you cannot connect using TCP/IP. The method is to use named pipes specified as
Default instance: \.pipesqlquery
or
Named instance: \.pipeMSSQL$instancenamesqlquery
Figure 10.6 shows the full list of the SQL Server resources controlled by Cluster Services once SQL clustering has been setup. These are
Physical disks (shared SCSI in this example)
Quorum disk (on the Disk Q: E: resource)
Data disk(s) (on the Disk Q: E: resource)
Transaction log disk(s) (on the Disk Q: E: resource)
Cluster IP address
Cluster name (network name)
MSDTC
SQL Server virtual IP address (for VSQLDBARCH virtual server)
SQL Server virtual name (VSQLDBARCH in this example)
SQL Server (VSQLSRV1 in this example)
SQL Agent (for VSQLSRV1 SQL Server instance)
SQL Full Text Service Instance (for VSQLSRV1 SQL Server instance)
Figure 10.6. Cluster Administrator console view of the all SQL Server resources managed by MSCS.
Stretch Clustering
There is also a notion of stretch clustering that allows SQL Server transactions to be concurrently written to both the local storage system and a remote storage system. You are essentially going to be using remote mirroring, MSCS, and SQL clustering.
Stretch clustering includes most of the benefits of standard fail-over clustering but is really designed to protect the local nodes from site destruction (the local SQL clustering configuration). In particular, stretch clustering ensures absolute transactional currency and consistency to a remote SQL clustering configuration and makes fail-over virtually transparent to the client if the local SQL cluster should ever become unavailable. Consider using stretch clustering to protect against site destruction if the risk of site destruction is high, the cost of an unavailable node is high, and you require transactional currency.
As shown in Figure 10.7, stretch clustering maintains at least one passive (standby) server in the local MSCS cluster, in case the active server fails, and at least one passive (standby) server in the remote site. If you use Windows 2000 Datacenter Server, you can have an MSCS cluster with two local servers and two remote servers providing server redundancy in each site and fail-over in the event of site destruction. Costs of building stretch clustering configurations often eliminate this as a viable option. It is very expensive to keep entire system redundancies and maintain the dedicated communication between the local and remote sites that this demands.
Figure 10.7. Possible “stretch clustering” configuration to support highly available systems and site destruction protection.
SQL Server Data Replication Design Considerations
Data replication has long been used to isolate big chunks of processing (like that of reporting) away from the primary OLTP processing without having to sacrifice performance. As data replication has become hugely more stable and reliable, it has been tapped to create “warm,” almost “hot” standby SQL Servers. If failures ever occurred with the primary server (publisher) in a replication topology, the secondary server (subscriber) would still be able to be used for work. In fact, it is possible for this secondary server to take over all processing from the primary server or just keep the reporting users happy (and available). When doing transactional replication in the ”instantaneous replication” mode, data changes on the primary server (publisher) can be replicated to one or more secondary servers (subscribers) extremely quickly. In other words, this “instantaneous replication” mode is creating a replicated SQL Server database that is as fresh as the last transaction log entries that made it through the distribution server mechanism. Figure 10.8 illustrates a typical SQL Server data replication configuration that can serve as a basis for high availability and which also fulfills a reporting server requirement (at the same time).
Figure 10.8. Central publisher, remote distributor replication model in support of HA.
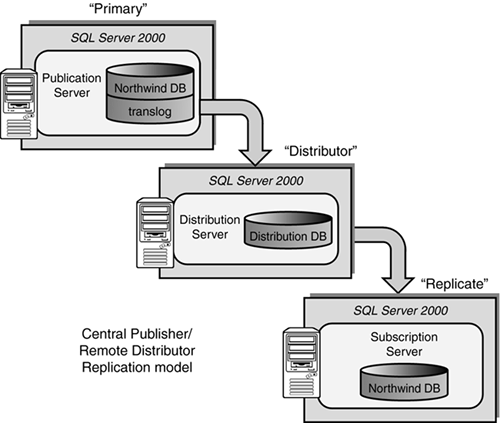
This particular data replication configuration is a “central publisher, remote distributor” replication model. It maximizes on isolating processing away from the primary server (publisher) including the data distribution mechanism (the distribution server) part of the replication model. There are a few things to deal with if ever the “replicate” is needed to become the primary server (take over the work from the “primary” server). Connection strings have to be changed, ODBC data sources need to be updated, and so on. But, this may be something that would take minutes as opposed to hours of potential database recovery time, and may well be tolerable to the end-users. There also exists a risk of not having all of the transactions from the primary server make it over to the replicate (subscriber). Remember, the replicated database will only be as fresh as the last updates that were distributed to it. Often, however, a company is willing to live with this small risk in favor of availability. For databases that are primarily read-only with low to medium data and schema volatility, this is a great way to distribute the load and mitigate risk of failure thus achieving high availability.
Primary things to consider if you have chosen data replication to support your high availability solution are
Latency between the publisher and the subscriber will determine how warm or hot the subscriber will be for fail-over. Instantaneous replication should be the default mode if you are targeting high availability.
Backup/recovery of a replication configuration embraces the publisher, the distributor, and the subscriber.
Impact and location of the distribution server (we recommend it be a remote distributor)!
Schema changes in the publisher that should be in the subscriber must be factored into your data replication support plans.
SQL Server logins/database user IDs' consistency is fairly easily administered by using DTS to synchronize the publisher and the subscriber on some type of a regular schedule (such as weekly).
Often seed values can become an issue with columns that use identity. Very often, the subscriber will define these columns as INT columns and can receive the identity values from the publisher without issue.
You may not want to propagate trigger code to the subscriber. But, if the subscriber is ever to take over for the publisher, the triggers will have to be added.
The client connection switch over process in the event of failure of the publisher needs to be thoroughly described and tested.
SQL Server Log Shipping Design Considerations
Log shipping is, perhaps, the easiest of the HA configurations to deal with from the administration point of view. Log shipping effectively replicates the data of one server (the source) to one or more other servers (the destinations) via transaction log dumps. Figure 10.9 shows a typical log shipping configuration with two destination pairs. A destination pair is any unique source/destination combination. You can have any number of source/destination pairs. This means that you can have from one to N replicated images of a database using log shipping. Then, if the source server should fail, you can upgrade one of the destination servers to become the source server. Although, you will still have to worry about the client connection changes that would be required if ever forced to use this secondary server.
Figure 10.9. Log shipping with two destination servers and a separate monitor server.
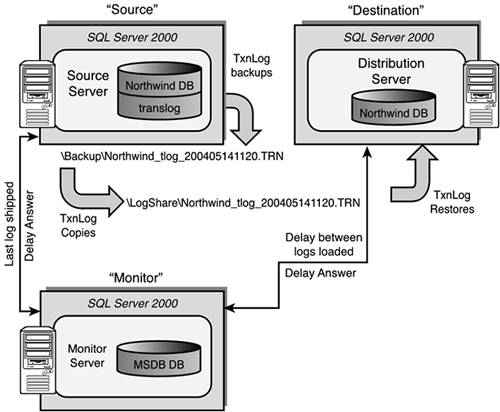
Figure 10.9 also shows how log shipping uses a Monitor Server to keep track of what the current state of the log shipping is. If there is a breakdown in log shipping, such as the loads on the destination are not being done or taking longer than what has been set up, the monitor server will generate alerts. The primary things to consider when using log shipping for high availability are
Understand the latency times (delays) between source and destination servers.
If the destination server is to be used as a fail-over, it will not be available for use until it is activated for use.
Make sure that there is ample space in the working directories for log shipping (the Backup directory and the Logshare directory). This is potentially a point of failure.
It is a good general practice to isolate the monitor server to a separate server by itself so that this critical monitoring of log shipping is not affected if the source server or any destination servers fail.
Understand the client connection switch over process in the event of failure of the source server. This needs to be thoroughly described and tested.
Distributed Transaction Processing Design Considerations
Distributed transaction processing as part of the application design itself changes the high availability orientation to be application driven, not database or disk oriented. The Microsoft distributed programming model consists of several technologies, including MSMQ, IIS, MS DTC, DCOM, and COM+. All of these services are designed for use by distributed applications.
You might want to design a highly available application to purposely distribute data redundantly. This type of application design can then guarantee the application more than one place to get data from in the event of a single server failure. This properly designed application would be “programmed” to be aware of a failed server (data source). Figure 10.10 shows an application that does its data access requests against one location, and if that data access fails (because the location has failed or is not accessible via the network), it would try a secondary location that had the same data. If data updates are being created (inserts/deletes/updates) at any one of the data source locations, a single distributed transaction would be used to guarantee that the updates are successful at all data locations. If one of the data locations is not available during this update, a resynchronization approach or a queuing approach can be devised that catches up any updates on the failed data location when it becomes available again.
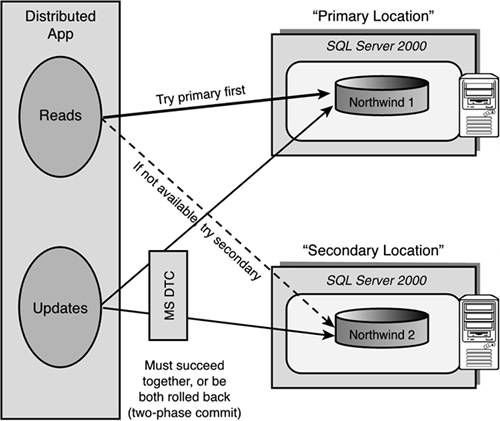
You can design and build these types of SQL Server[nd]based applications leveraging the distributed transaction coordinator (MS DTC). Each Microsoft SQL Server will have an associated distributed transaction coordinator (MS DTC) on the same machine with it. The MS DTC will act as the primary coordinator for these distributed transactions. MS DTC ensures that all updates are made permanent in all data locations (committed), or makes sure that all of the work is undone (rolled back) if it needs to be. MS DTC is essentially brokering a multi-server transaction. Each SQL Server (or XA compliant resource) is just a resource manager for their local data.
In addition, you can also consider building COM+ applications. COM+ handles many of the resource management tasks you previously had to program yourself, such as thread allocation and security. And, it automatically makes your applications more scalable by providing thread pooling, object pooling, and just-in-time object activation. COM+ also helps protect the integrity of your data by providing full transactional support, even if a transaction spans multiple databases over a network. Keep in mind that COM+ application logic will reside on server machines, not on client machines.
COM+ provides basic support for fault tolerance at the protocol level. A sophisticated pinging mechanism detects network and client-side hardware failures. Using a referral component technique, clients can detect the failure of a component, and can reconnect to the same referral component that established the first connection for them. This referral component has information about which servers are no longer available and automatically provides the client with a new instance of the component running on another machine. Applications will, of course, still have to deal with error recovery at higher levels (consistency, loss of information, and so forth). And, once you have built the COM+ application, you can deploy the application across a network or server cluster.