
High Availability and MS Analysis Services/OLAP
Building business intelligence (BI) applications that utilize Microsoft SQL Server 2000 Analysis Services (MSAS) may be the most rapidly expanding area within SQL Server-based systems. Up until recently, OLAP applications were primarily developed with classic availability needs to support (5 days per week, 8 a.m. to 5 p.m. uptime requirements). However, in recent years, a higher and higher percentage of analysis services-based implementations have vaulted to near extreme availability requirements (to the point that many OLAP applications are now needed 24 hours a day, 365 days of the year). This is partly due to the improved decision capability that can be attained from OLAP applications (and with MS Analysis Services leading the way). Many fortune 5000 companies around the world have very key OLAP/MSAS applications up and running now that directly influence huge business and financial decisions continuously. If these OLAP applications become unavailable for any extended period of time, enormous financial losses from unresearched decisions could occur. These ramifications provide much fuel to fully integrate MS Analysis Services into a solid high availability framework from the start.
The purpose of OLAP is to provide for an online reporting environment that can support various end user reporting requirements. These OLAP applications are usually created by complex extraction, cleansing, and aggregation processes from multiple operational systems (ODSs) into multi-dimensional or star schema data marts or data warehouses with full hierarchical level drill down capabilities. These OLAP applications must also provide full querying, reporting, and complex analysis capabilities to guarantee that the critical business decisions of an organization can be serviced properly. And most importantly, these OLAP applications must be extremely reliable, fast, and highly available (near 100% uptime).
Cubes are created by preprocessing aggregations (pre-calculated summary data) that reflect the desired levels within dimensions and support the type of querying that will be done. These aggregations provide the mechanism for rapid and uniform response times to queries. All queries are utilizing either these aggregations, the cube's source data, a copy of this data on the MSAS, a client cache, or a combination of these sources. In some complex data situations, you may want to create cubes with little to no aggregates and then run usage-based optimization so that the aggregates that get designed match the user's query patterns. A single analysis server can manage many cubes.
A cube is defined by the measures and dimensions that it contains. Each cube dimension can contain a hierarchy of levels to specify the natural categorical breakdown that users need to drilldown into for more details.
You can write custom client applications using Multidimensional Extensions (MDX) with OLE DB for OLAP (using Pivot Table Services) orActiveX Data Objects Multidimensional (ADO MD) which is built on OLE DB for OLAP, or you can use a number of third-party OLE DB for OLAP-compliant tools. MDX is the multidimensional expression in SQL that enables you to formulate complex multidimensional queries.
Every cube has a schema from which the cube draws its source data. A cube contains a series of partitions. Each partition uses a fact table. In the simple case there is only one partition per cube, but in many large production implementations, partitioning is used extensively. Not only can each partition in a cube have a different data source, it can have different storage methods (one partition MOLAP; one ROLAP) and it can have different aggregates (you may have a lot of aggregates for the current month partition, but little or no aggregates for history five years ago). The central table in a schema is the fact table that will yield the cube's data measures. The other tables in the schema are the dimension tables that are the source of the cube dimensions. A classic star-schema data warehouse design will have this central fact table along with multiple dimension tables.
It has been found that highly available OLAP/MSAS systems increase the end-users' acceptance of this type of system and the data it delivers. If the OLAP data is unavailable, end-users may find it easier to interpret offline data on their own rather than waiting for the OLAP application to come back up. In addition, if the system is always available, end-users make decisions using the integrated analysis tools that you have painstakingly built into your OLAP/MSAS application, which yields more accurate, well-founded results, by design.
When designing for highly available OLAP/analysis services systems, you must be keenly aware of things like
Outages for dimension maintenance— If the dimensions in your OLAP cubes contain updates to data, then realignment of things such as customers, products, or sales will cause downtime during reprocessing.
Processing windows— When normal nightly processing is done, query response times and query data scopes can be affected during incremental processing of partitions. In some cases, a cube partition will be completely unavailable during full processing of that partition. However, as long as the dimension structure remains the same, doing a full process of a partition may not cause the cube to become unavailable. The processing is done in a shadow folder and then switched when processing completes.
OLAP storage mechanism— MSAS supports three OLAP storage methods, providing flexibility to the data warehousing solution and enabling powerful partitioning and aggregation optimization capabilities. These OLAP storage methods are MOLAP, ROLAP, and HOLAP. Choosing the right storage mechanism to best support your high availability requirement will be necessary very early on. Both ROLAP and HOLAP will result in Analysis Services having to make direct queries against another system (the source RDBMS, or the aggregate RDBMS). If one of those systems becomes unavailable, so does your Analysis Services server. It can be argued that to reduce dependencies and increase availability you should use the MOLAP storage method for your partitions.
Upstream data availability— A critical operational issue in a production OLAP/MSAS application is to guarantee the availability of the feeder systems (the providers of the detail operational data). A thorough understanding of data context, data latency, and data integrity from these upstream systems is essential.
Usage-based optimization— Running the Usage-Based Optimization Wizard on a regular basis to add new aggregations based on changing query patterns can increase the total number of aggregations, which in turn would increase processing times and might ultimately exceed the length of the nightly processing window.
OLAP Cubes Variations
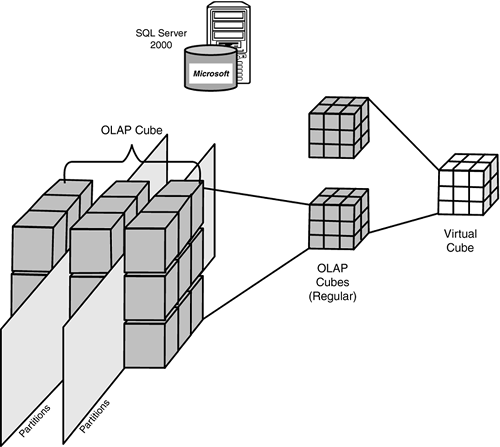
Cubes can be regular, virtual, or local cubes (as shown in Figure 10.17). Slight variations on this theme are linked cubes and real-time cubes. The following list explains these cubes in more detail:
Regular cubes— Regular cubes are based on real tables or views for their data source, will have aggregations, and will occupy physical storage space of some kind. If a data source that contributes to cubes partition changes, it must be reprocessed.
Virtual cubes— Virtual cubes are logical cubes based on one or more regular cubes (or linked cubes). Similar to relational views, virtual cubes use the aggregations of their component regular cubes, in which case storage space is not needed.
Linked cubes— Linked cubes are based on regular cubes defined and stored on another analysis server. Linked cubes also use the aggregations (and storage) of the regular cube they reference.
Local cubes— Local cubes are entirely contained in portable files (tables) and can be browsed without a connection to an analysis server. They do not have aggregations. This is really like being in “disconnected” mode.
Real-time cubes— These are regular cubes that have dimensions or partitions that have been enabled for “real-time OLAP.” In other words, real-time cubes receive updates dynamically from the data sources that are defined in their dimensions/partitions.
Write-enabled cubes— These are cubes in which updates (writes) are allowed and can be shared back with the data sources.
Figure 10.17. The MSAS cube representations — regular OLAP cubes, partitions, and virtual cubes.
MSAS supports three OLAP storage methods, providing flexibility to the data warehousing solution and enabling powerful partitioning and aggregation optimization capabilities. These OLAP storage methods are MOLAP, ROLAP, and HOLAP.
MOLAP
Multidimensional OLAP (MOLAP) is a storage approach in which cubes are built directly from OLTP data sources or from operational databases and stored in a native Microsoft OLAP format. No zero-activity records are stored (zero-activity records occur when an original value is zeroed out but the record remains in the database; it will be included in the count of records and affects other calculations like sums and so on).
The dimension keys in the fact tables are compressed, and bitmap indexing is used. A high-speed MOLAP query processor retrieves the data.
ROLAP
Relational OLAP (ROLAP) uses fact data in summary tables in the OLTP data source to speed retrieval. The summary tables are populated by processes in the OLTP system and are not downloaded to MSAS. The summary tables are known as materialized views and contain various levels of aggregation, depending on the options you select when building data cubes with MSAS. MSAS builds the summary tables with a column for each dimension and each measure. It indexes each dimension column and creates an additional index on all the dimension columns.
HOLAP
MSAS also implements a combination of MOLAP and ROLAP called hybrid OLAP (HOLAP). Here, the facts are left in the OLTP data source (RDBMS), and aggregations are stored in the native Microsoft OLAP format on the MSAS server.
However, keep in mind that when using MSAS, both ROLAP and HOLAP require more storage space because they don't use the storage optimizations of the pure MOLAP-compressed implementation.
Recommended MSAS Implementation for High Availability
If your requirements are clearly pushing you into implementing your MSAS environment to support high availability, we would recommend that you consider the following:
Leverage NLB if possible— If you have a large number of MSAS end-user requests to be serviced, more than one server can be configured with the network load balancing settings and loaded with a copy of the latest OLAP data to fulfill these requests (as depicted in Figure 10.18). Availability at the analysis server level is maintained because network load balancing detects when a server that is not responding to network requests and dynamically removes it from the NLB cluster. The remaining nodes pick up the load of the unresponsive server to service the end-user requests.
Figure 10.18. Leveraging multiple NLB clustered analysis servers and SQL clustering for high availability.
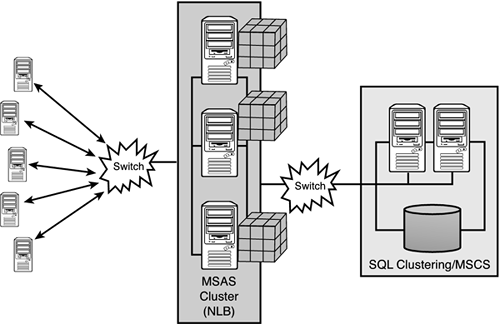
OLAP Storage mechanism for HA— MOLAP is recommended because the data is self-contained in the Analysis Services data folder and can easily be moved from any processing server to the analysis servers. To ensure 100 percent availability of the OLAP facility, you need a mechanism that allows multiple versions of the data to be spread out among the members of a cluster. The data must be independently configured and controlled along with the server being converged into the network load balancing cluster. If you use ROLAP or HOLAP, a single relational database contains (at minimum) the fact data and possibly the aggregates. This complicates the movement of data, because you must copy both relational databases and data files throughout the cluster.
Windows Clustering— At a very minimum, you will be implementing your Analysis Services and SQL Server within a Windows clustered configuration (MSCS) so that all files needed by the master copy of Analysis Services and SQL Server are completely managed by the cluster. This offers a very stable base platform from which to build varying degrees of high availability.
RAID configuration for Analysis Services:
For the best performance with full recoverability, use RAID 10.
RAID 5 for the Analysis Services data folder (because the data is mostly read-only).
Use RAID 0 (just disk striping) for the Analysis Services temp folder. The temp folder does not require recoverability. It is used only for cube or partition processing.
Controller and disk technologies:
Use a controller that supports hot standby disks that are automatically added to the RAID set if a disk failure occurs.
Use fibre-channel RAID controllers whenever possible. Small Computer System Interface (SCSI) is acceptable for mid-range systems, but not for large RAID or system area network (SAN) configurations.
Consider using SAN technology to obtain snapshots of data (to move data from staging to production). This greatly reduces time required to copy OLAP database files—which tend to be large (greater than 50GB).
The master copy of the OLAP data is stored in the data storage location managed by cluster services. If multiple NLB configured servers are being used, the local disks on these front-end servers will store the operational versions of the OLAP data. This approach guarantees that there is a master copy of the OLAP data and instantiating any load-balanced servers with copies is relatively easy to do and easily managed. After any new copy of the OLAP data is placed on the front-end servers, an update job can easily change the location of the data folder referenced. Now keep in mind that with a master copy of the OLAP data being managed within a cluster, it is easy to add a new analysis server to the front-end NLB cluster. The analysis server is required only to copy the data and add the host to the cluster—then the server is up and running extremely rapidly. Because every analysis server contains its own data, they are not dependent on any outside resource. Performance is consistent, and there is no single point of failure anywhere in the cluster.
Data Staging— Design a high performance data staging capability that will feed your MSAS environment affectively. OLAP applications integrate data from many data sources. Make sure your data staging capability has the disk and CPU resources to handle the data and processing to continuously populate the OLAP/MSAS system.
SQL clustering— Use SQL clustering for your SQL Server portion of your system. This would include the staging data capabilities that are usually present in an OLAP processing configuration. SQL clustering offers the highest fail-over capability for SQL Server-based processing. In addition, this should be at least a two-node SQL cluster in an active/passive mode.
If you use the NLB clustered configuration you will not be able to use the writeback data capabilities of your OLAP cubes. In this one configuration case, the multi-dimensional data must be read-only.
These OLAP/MSAS focused recommendations will yield a highly available platform for your OLAP end-users. Once you get these basic elements in place, the staging of any data updates and managing database size growth will quickly take over as the bigger challenge within your OLAP/MSAS deployments.