
Chapter 5 Administering SQL Server 2008 Full-Text Search
SQL Server full-text search is an optional component of SQL Server 2008. It first shipped as part of beta 3 of SQL Server 7. With each release of SQL Server, full-text search becomes significantly faster and more powerful. Full-text search in SQL Server 2008 is orders of magnitude faster than it was in the previous versions.
SQL Server full-text search allows you to rapidly search for words and tokens (like MSFT, XXX, FBI, and so on) in binary, char, nchar, varchar, nvarchar, XML, image, sysname, text, and varbinary columns. It creates an index very similar to the index that you will find at the back of this book. For example, if you wanted to find rows containing the word “test” in the full-text indexed column notes in the Authors table, you would issue the following query:
Select * From Authors where contains(notes,'test')
Although you could use the LIKE predicate for such a search, full-text searches have the following advantages over using the LIKE predicate:
![]() In general, they are orders of magnitude faster than using a
In general, they are orders of magnitude faster than using a LIKE predicate.
![]() They can search binary content.
They can search binary content.
![]() They can use language features.
They can use language features.
However, searches using the LIKE predicate can
![]() Search for patterns in the middle of a word, for example:
Search for patterns in the middle of a word, for example:
select * From tableName where column like '%una%'
![]() Search for sequences. For example, ‘abc[a,b][0-9]%’ will search on content beginning with abc, then either the letter a or b, then a number, and then anything else.
Search for sequences. For example, ‘abc[a,b][0-9]%’ will search on content beginning with abc, then either the letter a or b, then a number, and then anything else.
![]() Can be faster than a full-text search if you have a nonclustered index on the column, or if you are only searching on word beginnings.
Can be faster than a full-text search if you have a nonclustered index on the column, or if you are only searching on word beginnings.
SQL full-text search is typically used to allow users to conduct searches against content (for example, a jewelry store might want to allow users to search their online store catalogs), or to satisfy relational searches.
The purpose of this chapter is to explain the features of SQL full-text search and how to implement and administer them in SQL Server 2008.
The following is a list of the new features in SQL Server 2008 full-text search.
![]() Full-text catalogs are now stored inside the database.
Full-text catalogs are now stored inside the database.
![]() SQL Server Query Optimizer now can use highly optimized execution plans against the full-text indexes stored in the catalogs.
SQL Server Query Optimizer now can use highly optimized execution plans against the full-text indexes stored in the catalogs.
![]() Noise lists (also known as stop word lists, or noise files) are now stored in the database. Microsoft now refers to there as Full-Text stoplists or more simply as stoplists. You can create any number of noise word lists, and each full-text index table or indexed view can have its own specific noise word list.
Noise lists (also known as stop word lists, or noise files) are now stored in the database. Microsoft now refers to there as Full-Text stoplists or more simply as stoplists. You can create any number of noise word lists, and each full-text index table or indexed view can have its own specific noise word list.
![]() A Dynamic Management View (DMV) is provided to troubleshoot querying.
A Dynamic Management View (DMV) is provided to troubleshoot querying.
![]() Two DMVs are provided to troubleshoot indexing.
Two DMVs are provided to troubleshoot indexing.
![]() Full-text language support has been increased.
Full-text language support has been increased.
![]() Full-text catalogs in log-shipped or mirrored databases do not need to be repopulated when you fail over. In previous versions of SQL Server, if you log-shipped or mirrored a database that was full-text indexed, you would have to repopulate the full-text indexes when you failed over to the secondary or mirror. In SQL Server 2008 this is no longer necessary—on failover the full-text indexes are immediately accessible and queryable.
Full-text catalogs in log-shipped or mirrored databases do not need to be repopulated when you fail over. In previous versions of SQL Server, if you log-shipped or mirrored a database that was full-text indexed, you would have to repopulate the full-text indexes when you failed over to the secondary or mirror. In SQL Server 2008 this is no longer necessary—on failover the full-text indexes are immediately accessible and queryable.
![]() Full-text search now works with the FILESTREAM property of varbinary(max) columns.
Full-text search now works with the FILESTREAM property of varbinary(max) columns.
![]() A new external engine does the content extraction and indexing, called FDHost (Filter Daemon Host) also known as SQL Full-Text Host.
A new external engine does the content extraction and indexing, called FDHost (Filter Daemon Host) also known as SQL Full-Text Host.
![]() Full-text search has increased language support and now supports 48 languages, up from the 23 supported in SQL Server 2005.
Full-text search has increased language support and now supports 48 languages, up from the 23 supported in SQL Server 2005.
![]() Full-text search provides the ability to define a filegroup where the full-text catalogs can be stored.
Full-text search provides the ability to define a filegroup where the full-text catalogs can be stored.
![]()
DBCC CHECKDB validates SQL full-text structures, but does not validate their contents.
![]() A considerable number of performance improvements have been added.
A considerable number of performance improvements have been added.
Of all the features described in the preceding list, the one that is going to have the most significant impact on developers is the performance improvements while querying. Tests on large tables reveal a significant increase in querying, especially when performing mixed queries. A mixed query is a query which combines relational and full-text predicates.
SQL Server Full-Text Search has two essential functions, indexing and searching. The indexing process creates the full-text index that the searching function searches to determine which rows contain columns containing the word, token, or phrase you are searching for.
The indexing engine (hosted by a process called FDHost and launched by a service called MSSQLFTLauncher) connects to your database (using a component called a protocol handler) and reads the tables. It extracts the textual data from the columns you are full-text indexing, using components called word breakers. The filters (also known as iFilters) are able to read the varchar/char, XML, and binary documents, extract the text, and then send the text to the word breakers. The filters are specific for the type of documents that are stored in the columns you are full-text indexing. By default this will be char (character) or text data. If you are storing data in columns using the char, varchar, nchar, nvarchar, or the text data types, the text filter will be used.
If you are storing XML documents in columns of the XML data type, an XML filter will be used, which has special logic that can be used to interpret and index the contents of XML documents.
Binary data requires different handling. Binary data is data stored in a format that is only understood by the application that reads and writes documents in that format. Typically, a text editor cannot read binary data. If you store binary data in SQL Server, for SQL full-text search to be able to full-text index it, it must be able to extract the textual data from it. To be able to index and search full-text data, you need to do the following:
1. Store it in its native format in the image or varbinary(max) columns.
2. Install the appropriate Filter or IFilter for the document type and for the bit version of your OS (32 bit or 64 bit). Filters extract the textual information and sometimes properties from the documents. You can see a list of the document types that SQL Server 2008 has filters for by querying:
select document_type from sys.fulltext_document_types
Table 5.1 documents the file extension with the document type.
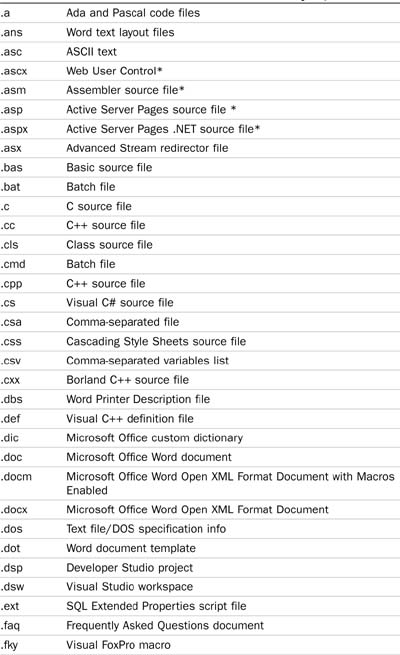
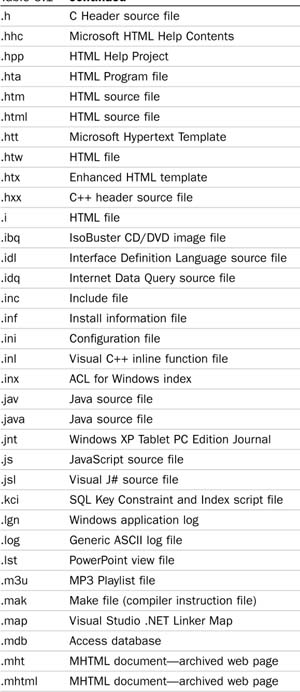
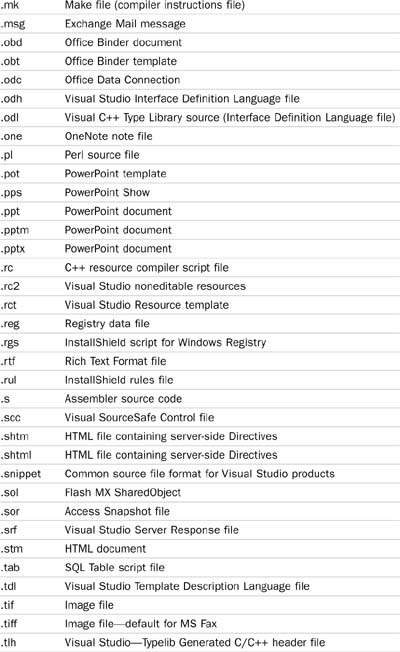
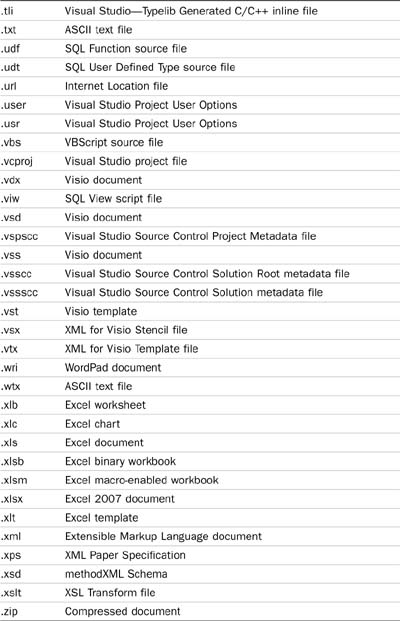
For example, SQL Server 2008 contains filters for all Office documents, HTML files, and TIFF files (it can do OCR on faxes stored in the TIFF format), but it does not contain the filter for Adobe’s Portable Document Format (PDF). You will need to search the Adobe web site to obtain this filter, download it, and install it on your system.
3. Add a char or varchar column to the tables you are full-text indexing that will contain the extension the binary data would have if it were stored in the file system. This column is referred to as the document type column.
4. Construct your full-text index referencing this document type column. Please refer to the sections “Creating a Full-Text Index Using the Wizard” and “Creating a Full-Text Index Using TSQL” later in this chapter for more information on how to do this.
For example, execute this query in the AdventureWorks 2008 database and you will get the following:
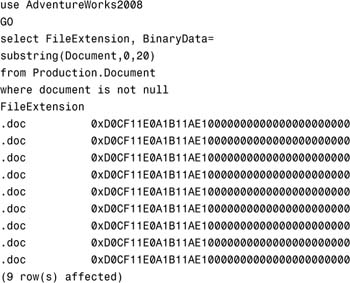
In the Production.Document table, there are nine Word documents stored in binary format in the Document column. For SQL full-text search to be able to properly index these documents, it has to know that they are Word documents, and it uses the FileExtension column to do this. If you do not give a type column or the extension you give is not recognized, the default text filter will be used.
The filters are specific for the document type; that is, the Word filters understand the file format for Word documents and the XML filters understand the file format of the XML documents, and they will emit text data from the binary documents stored in the columns you are full-text indexing. If you need to index documents for which the file type does not appear in the results of sys.full_text_document_types, you will need to install that filter on the server running SQL Server 2008, and then allow SQL Server 2008 to use them. To allow SQL Server to use these third-party filters, you will need to issue the following two commands:
sp_FullText_Service 'load_os_resources',1
sp_FullText_Service 'verify_signature',0
The first command will load all the filters installed on the OS, and the second will disable the need to verify certificates of the third-party filters. This is important if you are using an unsigned filter like Adobe’s PDF filter. If you fail to do this, your filter may not load, and all filters will take longer to load as the third-party filters certificates are checked.
You can write your own filters to extend what is shipped by default in SQL Server 2008 full-text search. Refer to the following document for more information on how to do this:
http://msdn2.microsoft.com/en-us/library/ms916793.aspx
During the indexing process, the filters will read the content you want to full-text index from the base tables and then send the stream of text data to another set of components called word breakers. The word breakers are language specific. They will apply language rules to the text stream emitted by the filters, and they break the text stream into words or tokens that are ready for indexing. The US and UK (or International English) word breakers don’t do a lot during the indexing process as the language rules applied during indexing are very simple. However, for German they will break a compound word down into its constituent words, so the word Wanderlust is broken down into Wanderlust, Wandern, and Lust—and all three words are stored in the index as such (only they are lowercased—all words are stored as Unicode and lowercased in the index). For Far Eastern languages, the word breakers have to interpret the entire word and pull it apart character by character looking for constituent characters and subcharacters—each character is stored in the index.
By default the word breaker that will be used by FTHost is the language specified in the sp_configure (unless you specify that you want the contents of the columns you are full-text indexing to be indexed in a different language).
The following T-SQL command will show you your default full-text language
sp_configure 'default full-text language'
Results:
name minimum maximum config_value run_value
-------------------------- ------- ------- ------------ ---------
default full-text language 0 2147483647 1033 1033
Here we see that we are using the Locale ID (LCID) of 1033, which corresponds to US English.
Please refer to the sections “Configuring Full-Text Indexes Using the Wizard” and “Configuring Full-Text Indexes Using TSQL.” Note that some documents have language-specific tags in them, which will launch different word breakers than the ones you specify on your server, or in your full-text index creation statement. For example, Word and XML documents have language tags embedded in them; if your Word documents are in German, but you specify in your full-text index creation statement that they are to be indexed in French, your Word document will be indexed in German, not French.
There is a lot of discussion about the differences between the UK and US word breakers. Basically they are identical except for how they handle words like realize (US spelling) and realise (UK spelling). These differences show up during query time (when you are searching, not during indexing time). So if you are searching on realize using a FreeText search, you will get rows returned where your full-text indexed cloumns contain the words realize, realizing, and realized, but not to the UK spelling of these words: realise, realising, and realised.
The word breaker will also break acronyms and tokens like C# in different ways. FBI will be indexed as FBI and F.B.I.; fbi will only be indexed as fbi. C# will be indexed as C with a placeholder indicating that a nonindexable character occurred after the C. Searching on C# will return rows where your full-text columns contain C#, C+, C++, C!, and so on. But c# will be indexed as c (if c is not in your noise word list).
When the word breaker has completed its task, it sends the list of words to be indexed to the indexer (also known as the index writer). Stop words are removed from the list of words to be indexed. Stop words are words that occur too frequently to be helpful in searching. For example, if you were to search on the word the or internet on a search engine, so many results would be returned that you would likely be unable to find what you are looking for. You need more specific search terms to narrow or refine your search. Stop words are considered to occur too frequently to be useful in searches and as such no one will search on them. Stop words are also called noise words; lists of stop words are called stoplists, stop word lists, or noise word lists.
In SQL Server 2008 full-text search, noise words are stored in system tables. Before a word or token is indexed in the full-text indexes by the indexer, it is checked to see if this word is in the stop word list. If it is a positional character, it is stored in the full-text index, noting that a stop word occurred at that position. Noise word lists were important in search engines a decade ago when disk costs were expensive. Now they are used to prevent terms from being indexed; for example, a Microsoft search engineer told me that a customer would add the word sex to his noise word list so that any searches including this term would be unable to find any documents containing the word sex. The search engine that powers the Microsoft public web sites adds words that occur infrequently (and the word Microsoft) to its stop word lists. The stop word lists that ship with SQL Server 2008 contain letters, numbers, personal pronouns (I, me, mine, yours), articles (a, at, the, of, to), and so on. Whenever you make a change to a stop word list, you must repopulate your full-text indexes for accurate results.
Here are the steps to maintain your stop word lists:
1. In SQL Server Management Studio, connect to a SQL Server instance.
2. Expand the database that contains the tables you want to full-text index.
3. Expand the Storage Folder.
4. Right-click on Full-Text Stop Lists.
5. Select New Full-Text Stoplist.
6. Give a name to your stoplist and assign an owner.
7. If you are adding stop words that you do not want to be indexed, the best approach is to create an empty stoplist. If you want to modify an existing stop list, select Create from the System Stoplist.
8. After your stop list is created, locate it in the Full Text Stoplists folder and select Properties. In the dialog you can add stop words or delete stop words for each language.
9. After you have made your changes, you will need to rebuild your full-text catalogs. Expand the Full Text Catalogs folder, right-click on each of your catalogs, and select Rebuild.
10. Click OK in the dialog that asks “Do you want to drop the full-text catalog and rebuild it?”
11. Click Close to exit this dialog.
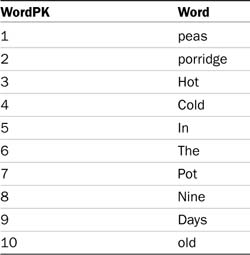
The indexer builds an inverted file index, which is basically two tables, one a table of words, and the other table showing which words occur in which rows and columns, and what position they occur in. For example, consider the phrase “Peas porridge hot, peas porridge cold, peas porridge in the pot nine days old.” The word table is illustrated in Table 5.2.
The hypothetical word position table is illustrated in Table 5.3.
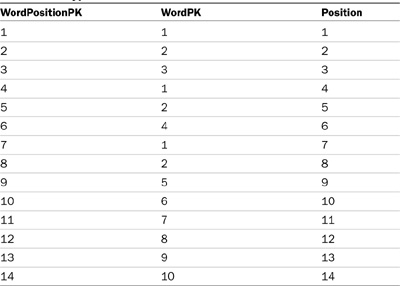
To illustrate how this works, the first word (Peas) is stored in the word table with a value of 1, the second (porridge) is stored in the word table with a value of 2, the third word (hot) is stored in the word table with a value of 3, and the fourth word (Peas) is already in the word table with a value of 1, so it is not added again. This process is continued until all the words present in the phrase are stored in the word table. Then in the word position table, the first word (Peas) is stored with a pk of 1, and the word pk value of 1 (from the word table), and it is the first word in the phrase, so its word position is 1. The second word (porridge) is stored with a pk of 2, and its word pk has a value of 2 (from the word table) and its word position is 3. The third word (hot) is stored with a pk of 3, and its word pk has a value of 3 (from the word table) and a word position of 3. The fourth word (peas again) is stored with pk of 4, its word pk is 1, and it is the fourth word in the phrase, so its word position is 4. This continues for the entire phrase.
At any one time there may be multiple inverted file indexes for a full-text indexed table. At periodic intervals while indexing is occurring, the multiple inverted file indexes are combined into a single inverted file index through a process called a master merge. You can force a master merge by doing a catalog reorganize in either of two ways:
Unlike the indexer, the search components are completely within the SQL Server query engine. When you issue your search queries using the SQL Contains or FreeText predicates (or their analogues ContainsTable or FreeTextTable), the search is conducted against the inverted file index and sometimes your base tables. Depending on the language you search in and the type of search you do, the word breakers may expand your search beyond the original search terms. For example, if you do a FreeText search on the word exercise, the search will actually be done on the following words: exercise, exercised, exercises, and exercising; and this search will return rows that contain any of the variants of the word exercise in the columns you are full-text indexing. If you are searching on a term like “University of California,” the search will be conducted on “University [any word] California” as of is a noise word. So you will get rows returned where the full-text columns contain the word University before a noise word and then the word California occurs; for example University of California, University to California, University at California, and even University Southern California where Southern is not a noise word. Key to understanding why University Southern California is returned is that the Full-Text Search engine will return rows containing University, then any single word or token, and then California. University of Southern California would not be returned as there are two words between University and California. Also, at query time the query engine can do thesaurus expansions. For example, with your thesaurus file enabled, a FreeText query on IE would return rows where the full-text indexed columns contained IE, IE5, or Internet Explorer.
Now that we understand the architecture of full-text search, let’s discuss how to create our full-text catalogs.
Full-text catalogs are essentially provided for backward compatibility with previous versions of SQL Server. In previous versions of SQL Server they would contain the full-text indexes of the tables and views you were full-text indexing. Each table you are full-text indexing can have a single full-text index on it. You can place this full-text index in only one catalog. A catalog can contain multiple full-text indexes.
The only reason you might want to have different full-text catalogs is different levels of accent sensitivity.
There are basically two steps to implementing a full-text solution. Before you create a full-text index, you must create a full-text catalog. In the wizard, full-text catalog creation can be done alongside the full-text index creation, but under the covers the catalog is always created first.
We’ll first discuss creation of the full-text catalog using the wizard, and then by using the TSQL commands.
There are two entry points to creating a full-text catalog:
![]() Using SQL Server Management Studio
Using SQL Server Management Studio
![]() Using TSQL
Using TSQL
1. In SQL Server Management Studio, connect to a SQL Server instance.
2. Expand the Database folder that contains the tables you want to full-text index.
3. Expand the Storage folder, and right-click on the Full-Text catalog folder.
4. Select and click the New Full-Text Catalog menu item, which will display the New Full-Text Catalog dialog box as illustrated in Figure 5.1.
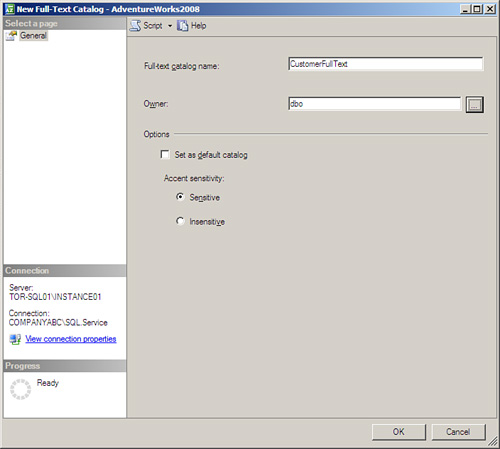
5. After you have set the options for your catalog, click on OK to close the dialog box.
There are several options here:
![]() Full-Text Catalog Name—This is the name of your full-text catalog. The name should be descriptive of the function of the catalog. The name will be used when creating full-text indexes (unless you create a default catalog).
Full-Text Catalog Name—This is the name of your full-text catalog. The name should be descriptive of the function of the catalog. The name will be used when creating full-text indexes (unless you create a default catalog).
![]() Owner—This is the owner of the full-text catalog. The owner “owns” the catalog: Anyone in the dbo_role in the database or sys_admin role on the server will be able to manage the full-text catalog, but the owner “owns” the full-text catalog, and the owner is the only one who will be able to drop it.
Owner—This is the owner of the full-text catalog. The owner “owns” the catalog: Anyone in the dbo_role in the database or sys_admin role on the server will be able to manage the full-text catalog, but the owner “owns” the full-text catalog, and the owner is the only one who will be able to drop it.
![]() Set as Default Catalog—If you select this option, you will not need to specify which catalog you want to use for your full-text indexes. By default all full-text indexes will be created in this catalog.
Set as Default Catalog—If you select this option, you will not need to specify which catalog you want to use for your full-text indexes. By default all full-text indexes will be created in this catalog.
![]() Accent Sensitivity—This option controls how accents are handled in the full-text indexing process. If you specify that your catalog is accent insensitive, all words indexed have their accents removed, so if you search on an accented version of the word, you will get hits to all possible variants of that accented word, so a search on café will give hits to café, cafe, cafè, café, cafê, and cafë! If you specified that you wanted your catalog to be accent sensitive, the words would be indexed with their accents, so a search on café would only return rows with full-text columns containing the word café.
Accent Sensitivity—This option controls how accents are handled in the full-text indexing process. If you specify that your catalog is accent insensitive, all words indexed have their accents removed, so if you search on an accented version of the word, you will get hits to all possible variants of that accented word, so a search on café will give hits to café, cafe, cafè, café, cafê, and cafë! If you specified that you wanted your catalog to be accent sensitive, the words would be indexed with their accents, so a search on café would only return rows with full-text columns containing the word café.
The TSQL commands used to create a catalog are highly symmetrical with the SQL Full-text Search Wizard options. The TSQL syntax used to create the full-text catalog is
CREATE FULLTEXT CATALOG CatalogName
ON FILEGROUP FileGroupName
WITH ACCENT_SENSITIVITY=OFF
AS DEFAULT
AUTHORIZATION dbo
These options map to the options in the Full-Text Catalog dialog box, with the exception of the IN PATH option. This is a legacy parameter that provides backward compatibility with SQL 2005, where it specified the file system directory where the full-text catalog would be created. Values specified for this parameter in SQL Server 2008 have no effect.
The only required parameter is the catalog name parameter. There can only be one default catalog per database, and by default accent sensitivity is on.
The full-text indexes are what the SQL Server references to determine which rows match your search phrase. There are three ways to create a full-text index on your table or indexed view:
![]() Using TSQL commands
Using TSQL commands
![]() Using the Full-Text Index Wizard, accessible by right-clicking on your table in SQL Server Management Studio
Using the Full-Text Index Wizard, accessible by right-clicking on your table in SQL Server Management Studio
![]() Using the Full-Text Catalog Properties dialog by selecting tables in the Tables/Views tab
Using the Full-Text Catalog Properties dialog by selecting tables in the Tables/Views tab
We will defer how to create full-text indexes on your tables or indexed views using TSQL commands until the next section. We’ll discuss how to use the Full-Text Index Wizard before we talk about using the Catalog Properties dialog.
To launch the Full-Text Index Wizard:
1. In SQL Server Management Studio, connect to a SQL Server instance.
2. Expand the database that contains the tables or indexed views you want to full-text index in SQL Server Management Studio.
3. Locate the table (you can only full-text index one table at a time) and right-click on it.
4. Click the Full-Text Index menu option, and then select Define Full-Text Index as illustrated in Figure 5.2.
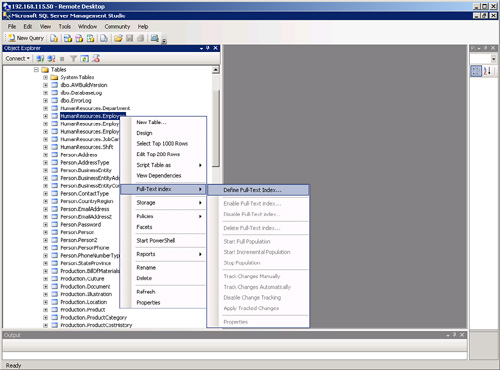
We will defer the discussion of the other menu options until we have completed the Full-Text Index Wizard. Clicking on Define Full-Text Index will launch the Full-Text Index Wizard, which is illustrated in Figure 5.3.
5. Click on Next to advance the wizard to the Select an Index dialog as illustrated in Figure 5.4.
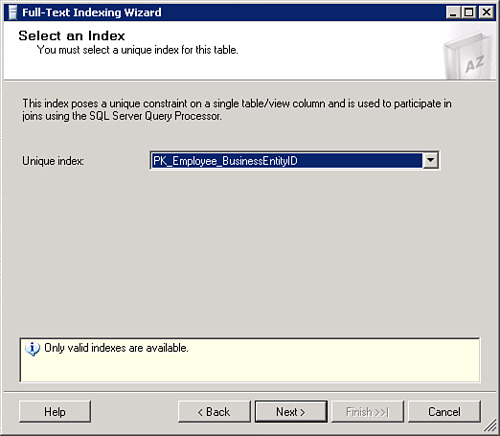
In Figure 5.4, note that the Unique Index drop-down box displays a list of all the unique indexes that are available to use as basis for full-text indexing. Full-text indexing uses a key index to be able to identify the row it is indexing and the row returned in response to full-text searches. The key index values must be unique; otherwise, full-text indexing will be unable to determine which row it has already indexed and which rows it has yet to index.
If your table does not have any unique indexes on it, this dialog will display a message in the lower half stating that a unique column must be defined on this table/view. You will also notice that if your table does not have a unique index/primary key on it that SQL full-text indexing can use, the Unique Index drop-down list box will not be enabled.
There are three other criteria for an index to be used as a basis for a full-text index table:
a. It must be a single-column index.
b. The column must be nondeterministic; that is, it cannot be a computed column.
c. It must be non-null.
4. After you have made your key index selection, click Next. This will launch the Select Table Columns dialog box, illustrated in Figure 5.5.
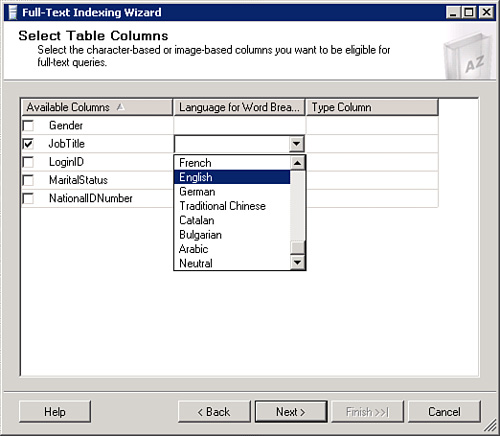
The Select Tables Columns dialog box is where you
![]() Choose which columns you want to full-text index.
Choose which columns you want to full-text index.
![]() Choose which language you want your content stored in each column to be indexed in.
Choose which language you want your content stored in each column to be indexed in.
![]() Specify which column will be used to indicate to the full-text indexing engine what type of data is stored in varbinary(max) or image data type columns.
Specify which column will be used to indicate to the full-text indexing engine what type of data is stored in varbinary(max) or image data type columns.
This table illustrates all the data type columns that you can full-text index: binary, char, image, nchar, ntext, nvarchar, sysname, text, varbinary, varchar, and XML data type columns. Select the columns you want to full-text index and then select the language in which you want your content to be full-text indexed, by clicking on the text box under the Language for Word Breaker column. As we discussed in the “Architecture” section, the word breaker is a COM component that applies language rules to the text stream emitted by the filters.
The Language for Word Breaker drop-down list box displays all the language options.
See Table 5.4 for a list of all supported full-text indexing languages. If you do not select a language, the default full-text language setting for your server will be the language used. You can set this or determine the setting by using the following command:
sp_configure 'show advanced options', 1
RECONFIGURE WITH OVERRIDE
Sp_configure 'default full-text language'
This will display the following results:
default full-text language 0 2147483647 1033 1033
What is important to note here is the run_value 1033. This is the LCID (LoCale IDentifier), which corresponds to an entry in sys.fulltext_Languages, as the following query demonstrates:
select lcid, name From sys.fulltext_languages
where lcid=1033
6. After you have selected the language to be used to index your column’s content, you may want to select a document type column that will tell the indexer what type of content is in your varbinary and image data type columns. This drop-down option will only be enabled for the varbinary and image data type columns.
7. When you have completed step 6, you can select Next or Finish. If you select Next, the Select Change Tracking dialog box (illustrated in Figure 5.6) will be displayed.
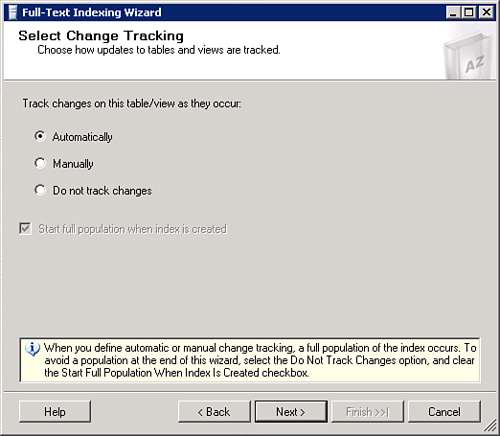
There are four options to index your content.
![]() Change Tracking—Apply Changes in Background
Change Tracking—Apply Changes in Background
![]() Change Tracking—Apply Changes Manually
Change Tracking—Apply Changes Manually
![]() Full Population
Full Population
![]() Incremental Population
Incremental Population
We will cover population types in the next section, “Population Types.”
8. After you have selected your population method, click the Next button in the Select Change Tracking dialog box. This will launch the Select Catalog, Index FileGroup, and Stoplist dialog box illustrated in Figure 5.7.
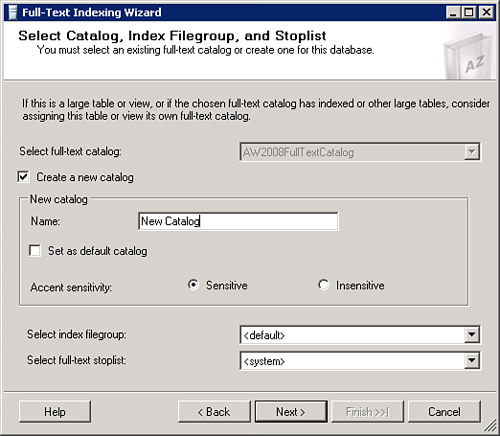
We have already discussed the options in catalog creation in the section “Creating a Full-Text Catalog Using the Wizard.” The only new option that appears here is the Select Full-Text Stoplist drop-down. By default you will be using the system stop list. If you click the drop-down box, you have the option to select other stop word lists that you have created for this database, or the <off> option. The <off> option will essentially give you an empty stop word list—in other words, full-text indexing will index all words or tokens.
9. After you have configured your catalog, select Next. The Define Population Schedules dialog box will allow you to define schedules for full or incrementation populations, as illustrated in Figure 5.8.
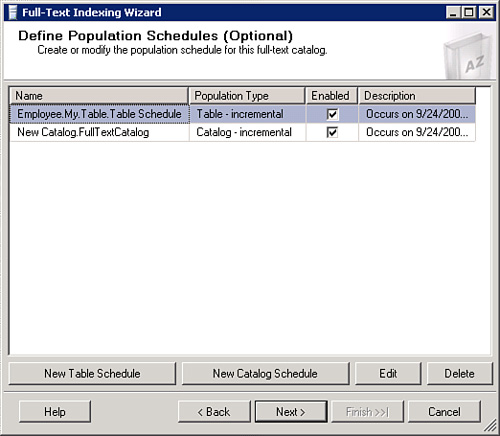
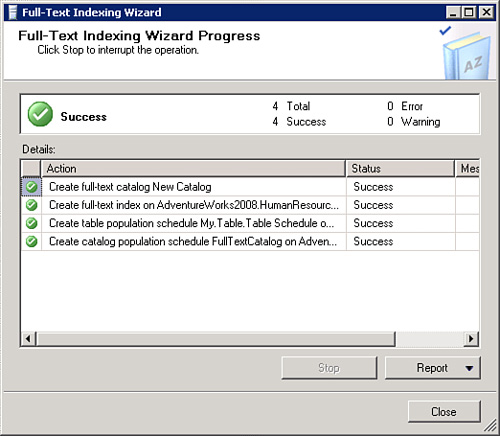
10. Clicking Next will present the Full-Text Indexing Wizard Description, which is a summary of what the full-text indexing wizard will create. You can expand any of the nodes for more information on how the Full-Text Indexing wizard will create your full-text index and/or catalog. Click Back to make changes, or Finish to create the index. A progress dialog will display the status of each creation step. Figure 5.9 illustrates the dialog displayed when the progress is complete. If you do get an error there will be a hyperlink you can click to get more information on the error.
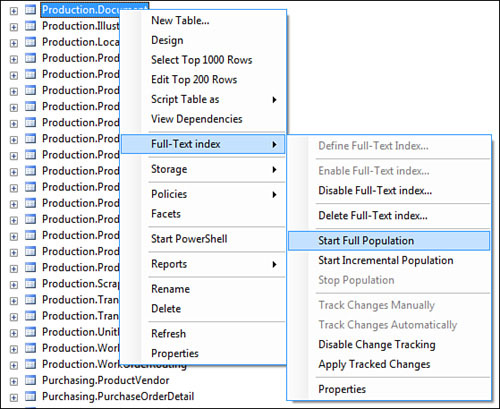
You can also create a full-text index on a table from the Catalog folder. To do this, use the following steps:
1. In SQL Server Management Studio, connect to a SQL Server instance.
2. Expand the database that contains the tables you want to full-text index.
3. Right-click on your catalog, select Properties, and click on the Tables/Views tab as illustrated in Figure 5.10.
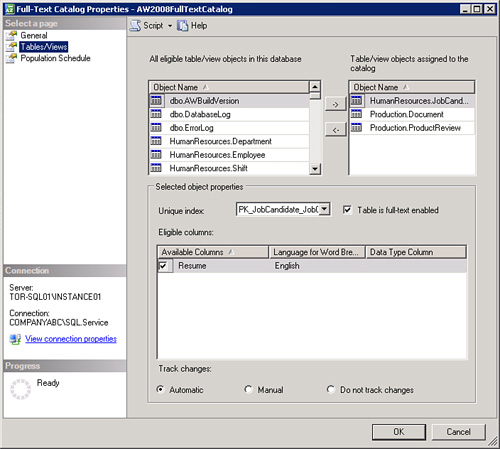
4. To add a table or view, you will need to click on the arrow tab to move tables in and out of the list box titled Tables/View Objects Assigned to the Catalog.
After a table/view is assigned to the catalog, you will note that you have an option to include columns to be full-text indexed in the Eligible Columns text box at the bottom of the dialog as well as selecting Language for Word Breaker and Data Type Column (if you are indexing image or varbinary data type columns). You also have the option to select how you want this table to be populated—change tracking with update in background, change tracking with update index manually, or no population type (the Do Not Track Changes option). If you select the option to not track changes, you will be responsible for controlling the population yourself.
SQL full-text search builds indexes by gathering the data to be indexed from the base tables. This process is called population and there are four types of populations.
The Automatic option is the Track Changes Automatically. Figure 5.11 illustrates where you can find this menu option in the full-text index menu options when you right click on a table. This option is also visible in the catalog properties dialog, illustrated in the lower half of Figure 5.10.
Change tracking is the process by which the full-text indexing process keeps track of changes that have occurred in the tables you are full-text indexing. By default when a change occurs in one of the columns in a row you are full-text indexing, change tracking will queue a list of the rows and their columns that changes. The indexing host then processes this change in near-real time.
What is important to note about change tracking is that if you update a column that you are not full-text indexing, that row will not be full-text indexed again.
In extreme load cases there may be some locking associated with change tracking, so you have the option of postponing the indexing process until a later point in time. This is the Manually option (visible in the lower half of Figure 5.10), also known as Track Changes, Manually (visible in Figure 5.11). If you right-click on a table that you have already full-text indexed and select the Full-Text Index option, you will notice the Track Changes Manually option, which corresponds to the Manually option. If data is modified in a full-text column on your full-text index table, a list of the keys corresponding to these rows will be stored in a change tracking queue until you manually apply the changes to the indexing process—you do this by a scheduleor by right-clicking on your table and selecting full-text indexing and then the Apply Tracked Changes option. For example, you can schedule all of your full-text changes to be indexed at night or another quiet period, or you could have them scheduled to be “manually” applied every 5 minutes. You also have the option of manually applying them yourself. Keep in mind that if you choose this option you will not get real-time indexing; in other words, searches done on your full-text index will only be up to date to the last time you applied the changes.
As we discussed earlier, change tracking tracks changes to the full-text indexed columns and indexes the rows that have changed. This process occurs in near-real time. Full-population is a process that extracts each row and full-text indexes the columns you are full-text indexing. There is no change tracking involved; every row is reindexed, whether it has been changed or not. Full-populations are best used when the bulk of your data changes at one time, and consequently you have no real-time requirements. For example, if a jewelry chain wants to allow their customers to search a table with item descriptions, and the items that they have for sale only change quarterly, a full-population will work best. Change tracking introduces too much overhead.
You may find that if your data changes daily at some point in time, change tracking will work better than a full-population, but it all depends on how much data you have and how frequently you want it updated. A rough rule of thumb is that if 80% or more of your data changes at any one time, you should use full-text indexing. If less than 80% changes and you want real-time index updates, use change tracking with apply changes in background. If you experience locking between DML processes and the full-text indexing process, use Change Tracking with Apply Changes Manually. In some cases, you may find that incremental populations work best when less than 80% of your data changes at one time and you do not require near-real-time indexing. We will cover this in the next topic.
To select Full-Population, select the Do Not Track Changes option, and ensure that the Start Full-Population When Index Is Created option is selected.
An incremental population is best used when a significant portion of your data changes at one time and at infrequent intervals. With an incremental population, a timestamp column is required on the table you are full-text indexing. The incremental population process records the highest timestamp value each time it runs. It compares the timestamp value from the previous run and then returns a list of rows that have higher timestamp values than the last run. This way it gets a list of all the rows that have changed since the last run. Key to understanding how an incremental population are three facts:
1. If the time stamp column does not exist, a full-population is run.
2. All rows that have a higher timestamp value than the last time recorded stamp value are reindexed, even if the data in the columns you are full-text indexing has not changed. If a change is made to an ancillary column, the row will still be full-text indexed again.
3. The timestamp column only returns a list of inserted or updated rows. The incremental population process still has to retrieve key values from the entire table to determine which rows have been deleted and remove the corresponding entries from the full-text index.
Depending on how many rows have been deleted or updated, a full-population may be faster than an incremental population. You will need to do benchmarking tests to see which population method will work best for you.
Creating full-text indexes on your tables is syntactically similar to the way you create indexes on your tables.
In its simplest form the TSQL creation statement would look like this:
CREATE FULLTEXT INDEX on [HumanResources].[Department]
(Name LANGUAGE 1033)
KEY INDEX PK_Department_DepartmentID ON (AW2008FullTextCatalog,
FILEGROUP [PRIMARY])
Where Name is the column you are full-text indexing, 1033 is the language you are indexing in (this is American English), PK_Department_DepartmentID is the primary key of the table [HumanResources].[Department] that you are full-text indexing, AW2008FullTextCatalog is the name of the catalog, and Primary is the name of the file group.
The arguments of the full-text index creation statement are as follows:
![]()
TableName— This is the name of the table or index view that you want to full-text index.
![]()
ColumnName— This is the name of the column or columns you want to full-text index. If you are indexing multiple columns, you would separate them with commas. Here is an example:
CREATE FULLTEXT INDEX on [HumanResources].[Department]
(Name LANGUAGE 1033, GroupName LANGUAGE 1036)
KEY INDEX PK_Department_DepartmentID ON
(AW2008FullTextCatalog,
FILEGROUP [PRIMARY])
Here we are full-text indexing two columns, Name, and GroupName. We are indexing Name using American English (I033) and GroupName using French (1036). The Language argument is completely optional.
![]()
Type Column— The Type Column argument is to be used when you are full-text indexing image or varbinary columns. It contains the name of a column that tells the indexer what the type of content is in the image or varbinary column for that row; for example, for one row it might contain the value doc, and for another the value pdf. Here is an example of using the Type Column option that is used in the table [Production].[Document]:
--if you entered the above full-text index creation command
--you will need to drop the existing full-text index
--use this command to do it
--DROP FULLTEXT INDEX on [Production].[Document]
CREATE FULLTEXT INDEX ON [Production].[Document](
[Document] TYPE COLUMN [FileExtension] LANGUAGE [English])
KEY INDEX [PK_Document_DocumentNode]ON
([AW2008FullTextCatalog], FILEGROUP [PRIMARY])
WITH (CHANGE_TRACKING = AUTO, STOPLIST = SYSTEM)
GO
Note that as this full-text index is already in place, you will need to drop it before you run the preceding command. Use this command to drop it:
Use AdventureWords2008
GO
DROP FULLTEXT INDEX on [Production].[Document]
The warning applies to inserts or updates made to your image or varbinary columns using WRITETEXT or UPDATETEXT operations that are not logged. If you use these operations to update the tables you are full-text indexing, these changes will not be indexed.
![]()
Language— This option is used to apply different language word breakers to your full-text indexed columns. It is optional and if you do not use this option, the default full-text language setting will determine which language word breaker will be used. To determine the LCID to be used, consult sys.fulltextlanguages. In addition, note that if you are indexing language-aware documents (like Word and XML documents), the language settings in these documents will override whatever language you have specified your columns to be indexed in.
![]()
Key Index— Key Index is the unique index that you are using as a key for full-text indexing operations. Please refer to the Type Column discussion for a sample of its usage.
![]()
Full-Text Catalog Name— This is the name of your full-text catalog. If you have a default full-text catalog set up for the database that contains your tables that you are full-text indexing, you will not need to specify a catalog. Please refer to the Type Column discussion for a sample of its usage.
![]()
FileGroup— This parameter is for backward compatibility only.
![]()
Change_Tracking— This parameter determines how your full-text index is populated. By default, Change Tracking with Update Index in Background will be done. You can also select Change Tracking with Update Index Manually, or that no population should occur after full-text index creation.
Here are some examples of these features. The following three statements are all equivalent. The = is optional, and Change Tracking with Update Index in Background is the default.
CREATE FULLTEXT INDEX ON [Production].[Document](
[Document] TYPE COLUMN [FileExtension] LANGUAGE [English])
KEY INDEX [PK_Document_DocumentNode]ON ([AW2008FullText
Catalog],
FILEGROUP [PRIMARY])
WITH CHANGE_TRACKING=AUTO
CREATE FULLTEXT INDEX ON [Production].[Document](
[Document] TYPE COLUMN [FileExtension] LANGUAGE [English])
KEY INDEX [PK_Document_DocumentNode]ON ([AW2008FullText
Catalog],
FILEGROUP [PRIMARY])
WITH CHANGE_TRACKING AUTO
CREATE FULLTEXT INDEX ON [Production].[Document](
[Document] TYPE COLUMN [FileExtension] LANGUAGE [English])
KEY INDEX [PK_Document_DocumentNode]ON ([AW2008FullText
Catalog],
FILEGROUP [PRIMARY])
For manual change tracking the following command would be used:
CREATE FULLTEXT INDEX ON [Production].[Document](
[Document] TYPE COLUMN [FileExtension] LANGUAGE [English])
KEY INDEX [PK_Document_DocumentNode]ON ([AW2008FullText
Catalog],
FILEGROUP [PRIMARY])
WITH CHANGE_TRACKING MANUAL
For no populations you would use the following command
CREATE FULLTEXT INDEX ON [Production].[Document](
[Document] TYPE COLUMN [FileExtension] LANGUAGE [English])
KEY INDEX [PK_Document_DocumentNode]ON ([AW2008FullText
Catalog],
FILEGROUP [PRIMARY])
Users may see this warning... Warning: Request to start a full-text index population on table or indexed view ‘Production.Document’ is ignored because a population is currently active for this table or indexed view.
WITH CHANGE_TRACKING=OFF,NO POPULATION
If you wanted to do a full population after the fact, you would use the ALTER FULLTEXT INDEX command as in the following example:
ALTER FULLTEXT INDEX ON [Production].[Document]
START FULL POPULATION
If you were using Change Tracking with Update Index Manually and you wanted all tracked changes updated in the index, you would use the following command:
When you have completed creating a full-text index using the wizard, you may need to control the index population on the table or catalog level.
To do this, right-click on your table and select Full-Text Indexing. This option is illustrated in Figure 5.12.
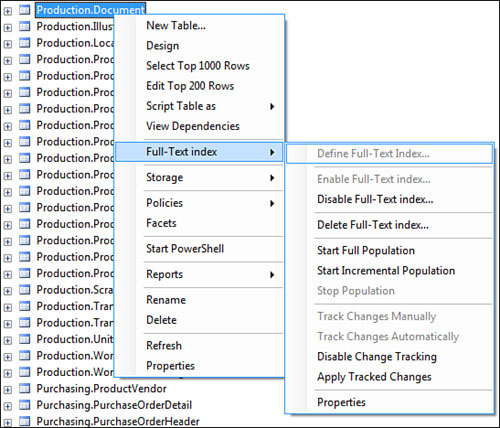
You will notice the following options:
![]() Define Full-Text Index (disabled in Figure 5.12)—Use this option to create a full-text index on your table.
Define Full-Text Index (disabled in Figure 5.12)—Use this option to create a full-text index on your table.
![]() Enable Full-Text Index (disabled in Figure 5.12)—Use this option to enable a disabled full-text index.
Enable Full-Text Index (disabled in Figure 5.12)—Use this option to enable a disabled full-text index.
![]() Disable Full-Text index—Used to disable a full-text index. The index will be searchable, but will not index any new rows or changes until it is enabled. After an index is enabled, you will need to run a full or incremental population. If change tracking is enabled, SQL Server will automatically start a full or incremental population. Incremental populations will be done if there is a timestamp column on the table and a full population has already been run. Otherwise SQL Server will automatically do the full-population.
Disable Full-Text index—Used to disable a full-text index. The index will be searchable, but will not index any new rows or changes until it is enabled. After an index is enabled, you will need to run a full or incremental population. If change tracking is enabled, SQL Server will automatically start a full or incremental population. Incremental populations will be done if there is a timestamp column on the table and a full population has already been run. Otherwise SQL Server will automatically do the full-population.
![]() Delete Full-Text Index—Used to delete a full-text index. You will no longer be able to search this index after it is deleted.
Delete Full-Text Index—Used to delete a full-text index. You will no longer be able to search this index after it is deleted.
![]() Start Full-Population—Will start a full-population. Use this if you are manually controlling your populations or have made a change to the full-text index, or the stop word list.
Start Full-Population—Will start a full-population. Use this if you are manually controlling your populations or have made a change to the full-text index, or the stop word list.
![]() Start Incremental Population—Will start an incremental population if there is a timestamp column on the table you are full-text indexing.
Start Incremental Population—Will start an incremental population if there is a timestamp column on the table you are full-text indexing.
![]() Stop Population (disabled in Figure 5.12)—Use this option if you need to stop a population for performance reasons, or if you need to do maintenance on your full-text index, for example, to change a stop word list.
Stop Population (disabled in Figure 5.12)—Use this option if you need to stop a population for performance reasons, or if you need to do maintenance on your full-text index, for example, to change a stop word list.
![]() Disable Change Tracking—This option will disable change tracking permanently. To keep your full-text index up to date, you will need to enable this option again (using the Track Changes Manually or Track Changes Automatically option, or by running a full or incremental population).
Disable Change Tracking—This option will disable change tracking permanently. To keep your full-text index up to date, you will need to enable this option again (using the Track Changes Manually or Track Changes Automatically option, or by running a full or incremental population).
![]() Apply Tracked Changes—Use this option if you have enabled Track Changes Manually. You will need to select Apply Tracked Changes to feed the latest changes that have occurred on your full-text indexed table to the indexing process.
Apply Tracked Changes—Use this option if you have enabled Track Changes Manually. You will need to select Apply Tracked Changes to feed the latest changes that have occurred on your full-text indexed table to the indexing process.
![]() Start PowerShell—This option provides a window into PowerShell to create and run PowerShell scripts.
Start PowerShell—This option provides a window into PowerShell to create and run PowerShell scripts.
![]() Properties—This option launches the Full-Text Index Properties dialog box where you can configure properties on your full-text index.
Properties—This option launches the Full-Text Index Properties dialog box where you can configure properties on your full-text index.
The options Define Full-Text Index, Enable Full-Text Index, Stop Population, Track Changes Manually, and Track Changes Automatically are not enabled in this dialog as they are mutually exclusive with an already created full-text index on a table that has change tracking enabled.
Stop lists are used when you want to hide words in searches or to prevent words from being indexed that would otherwise bloat your full-text index and might cause performance problems. Stop lists (also known as noise word lists or stop word lists) are a legacy component from decades ago when disk prices were very expensive. Back then, using stop lists could save considerable disk space. However, with disk prices being relatively cheap, the use of stop lists is no longer as critical as it once was. You can create your own stop word list using the following instructions:
1. In SQL Server Management Studio, connect to your SQL Server.
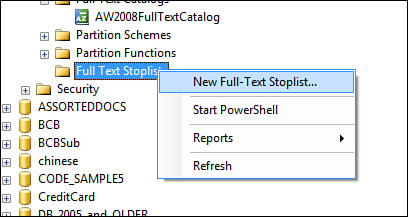
2. Expand your database in SQL Server Management Studio, and then right-click on the Full-Text Stop Lists node.
3. Select New Full-Text StopList.
You have an option of creating your own stop list, basing it on a system stop list, creating an empty one, or creating one based on another stop list in a different database. Each catalog can have its own stop list, which is a frequently demanded feature, as some search consumers want to be able to prevent some words from being indexed in one table, but want the same words indexed in a different table.
To maintain your stop word lists:
1. In SQL Server Management Studio, connect to a SQL Server instance.
2. Expand the database, the Storage folder, and the Full-Text Stop Lists folder.
3. Right-click on the stop list you need to maintain. Select Properties. Figure 5.13 illustrates this option.
The options are to add a stop word, delete a stop word, delete all stop words, and clear the stop list. After you select which option you want, you can enter a stop word, and then the language to which you want that stop word to be applied.
Keep in mind that the stop lists are applied at query time (while searching) and at index time (while indexing). Changes made to a stop list will be reflected in real time in searches, but will only be applied to newly indexed words. The stop words will still be in the catalog until you rebuild the catalog. It is a best practice to rebuild your catalog as soon as you have made changes to your stop word list. To rebuild your full-text catalog, right-click on the catalog in SQL Server Enterprise Manager and select the Rebuild option.
Frequently searchers will want their search automatically expanded to another term; for example, if you search on cars you might want also want results returned for automobiles, or if you search on the word center, you might want results coming back that include the alternative spelling centre. This type of thesaurus capability is called an expansion. Alternatively, some search administrators will want a search term replaced by another term altogether. For example, some searchers might search on Bombay, a city in India that is now called Mumbai. If all of the content in the database used the term Mumbai, search administrators will want to replace the search term Bombay with Mumbai.
SQL Server full-text search has a Thesaurus option, which allows for both expansions and replacements. At the command prompt, navigate to C:Program FilesMicrosoft SQL ServerMSSQL10.MSSQLSERVERMSSQLFTData. Note that Vista users will have to run the command prompt as an administrator or log on as an administrator to enable this feature. You will notice 48 language-specific XML thesaurus files there. Use the TSGlobal.xml thesaurus file if you want to add patterns and replacements that will be applied to all language-specific thesaurus files. Otherwise, edit the thesaurus file for your language. The thesaurus file will look something like this:
<XML ID="Microsoft Search Thesaurus">
<!-- Commented out
<thesaurus xmlns="x-schema:tsSchema.xml">
<diacritics_sensitive>0</diacritics_sensitive>
<expansion>
<sub>Internet Explorer</sub>
<sub>IE</sub>
<sub>IE5</sub>
</expansion>
<replacement>
<pat>NT5</pat>
<pat>W2K</pat>
<sub>Windows 2000</sub>
</replacement>
<expansion>
<sub>run</sub>
<sub>jog</sub>
</expansion>
</thesaurus>
-->
</XML>
What is important to note here is that before you can start to use the thesaurus options, you will need to edit your thesaurus file using a text editor (preferably Notepad as some commercial text editors will not save the thesaurus file correctly), and edit out the two comment tags. There are three options in the thesaurus file:
![]()
Diacritics_sensitive—This is analogous to the accent sensitivity settings on your catalog. With Diacritics Sensitive set to 0, accents will not be respected. So if you have a replacement of café with coffee, a search on cafe will be replaced with the search term coffee. Setting this value to 1 will replace both search terms café and cafe with coffee.
![]() Replacements—These are search terms you want to have replaced with another search term. The
Replacements—These are search terms you want to have replaced with another search term. The pat tag indicates this is a pattern you want replaced. The sub tag indicates what the replacement search word or phrase is to be. As the sample thesaurus file indicates, you can have more than one replacement. To add your own replacement, you must start and end the replacement with <replacement> and </replacement> respectively. The word or phrase you want to be replaced must be delimited by the pat tags, for example, if you want sex replaced by gender, you would need to wrap sex in the pat tags like this:
<pat>sex</pat>
Then your substitute gender would be wrapped in the sub tags like this:
<sub>gender</sub>
So your entire replacement section would look like this:
<replacement><pat>sex</pat><sub>gender</sub></replacement>
![]() Expansions—These are search terms where you want results returned to the original search word, but also to other words or phrases. The example in the thesaurus file is for Internet Explorer. The expansions are IE and IE5. So if you were searching on Internet Explorer, you would get search results to rows containing the terms Internet Explorer, rows containing IE, and rows containing IE5. The same formatting rules apply to the expansion tags as the replacement tags.
Expansions—These are search terms where you want results returned to the original search word, but also to other words or phrases. The example in the thesaurus file is for Internet Explorer. The expansions are IE and IE5. So if you were searching on Internet Explorer, you would get search results to rows containing the terms Internet Explorer, rows containing IE, and rows containing IE5. The same formatting rules apply to the expansion tags as the replacement tags.
To test the thesaurus option, create a small table that contains the pattern and substation terms on different rows and then do FreeText searches. FreeText searches do implicit thesaurus expansion and replacements.
The focus of this book is on administering SQL Server 2008, and the focus of this chapter is on administering SQL Server 2008 full-text search. Complete coverage of full-text queries is beyond the scope of this book and more appropriate for a book on SQL Server 2008 programming. However, as it is essential for the DBA to test full-text search to ensure that it is working correctly, this section will present the basics on how to search the full-text indexes.
There are two types of searches:
![]() Contains—A strict word/phrase-based search: exact matches only by default.
Contains—A strict word/phrase-based search: exact matches only by default.
![]() FreeText—A more natural way to search where the search terms are linguistically expanded so that a search is conducted on both singular and plural forms of nouns, articles, and all declensions of a verb. So a search on apple would return rows containing apple and apples, and a search on mouse would return rows containing mouse and mice. This expansion of terms is called stemming.
FreeText—A more natural way to search where the search terms are linguistically expanded so that a search is conducted on both singular and plural forms of nouns, articles, and all declensions of a verb. So a search on apple would return rows containing apple and apples, and a search on mouse would return rows containing mouse and mice. This expansion of terms is called stemming.
There are two variants of these searches:
![]() Contains/ContainsTable
Contains/ContainsTable
![]() FreeText/FreeTextTable
FreeText/FreeTextTable
Typical Contains/FreeText searches can be conducted like this:
select *
from [Production].[Document]
where CONTAINS(Document, 'arm')
select *
from [Production].[Document]
where FREETEXT(Document, 'arm')
There are several points to note here:
![]() You can search on all columns (*), or one or more columns (Col1, Col2). If you search on more than one column, you must delimit them with commas.
You can search on all columns (*), or one or more columns (Col1, Col2). If you search on more than one column, you must delimit them with commas.
![]() All searches whether they are on a word/token or a phrase must be wrapped in single quotes. If you are searching on phrases using the
All searches whether they are on a word/token or a phrase must be wrapped in single quotes. If you are searching on phrases using the Contains predicate, you must wrap the phrase in double quotes. If you wrap a phrase in double quotes in a FreeText query, the search will be the functional equivalent of a Contains query; that is, you will get no stemming.
FreeText queries by default are expanded by all expansions in the TSGlobal.xml file and the thesaurus file for your language.
Contains queries can be made more FreeText-like by using the following predicates:
![]()
FormsOf(Inflectional, “my search term”)—Where your phrase is stemmed:
SELECT Title FROM production.Document
WHERE CONTAINS (*, 'FormsOf(Inflectional, cycle)')
![]()
FormsOf(Thesaurus, “my search term”)—Where your phrase is expanded according to your thesaurus file and the global thesaurus file (TSGlobal.xml).
![]()
Near—By using NEAR or ~, for example:
Select * from [Production].[Document]
where CONTAINS(Document, '"crank" NEAR "arm"')
![]() Boolean operators—You can use AND, OR, and NOT, for example:
Boolean operators—You can use AND, OR, and NOT, for example:
Select * from [Production].[Document]
where CONTAINS(Document, '"crank" AND NOT "hand"')
![]() Weighted—You can weigh the importance of search terms:
Weighted—You can weigh the importance of search terms:
Select * from [Production].[Document]
where CONTAINS(Document, 'ISABOUT("crank", arm
WEIGHT(0.9))')
![]() * (a wildcard operator)—Using this predicate will wild-card the search term, so a search on hel* will return rows containing hell, Helen, help, and Helwig. Note that if you wild-card one term in a search phrase, all terms in the search phrase will be wild-carded. Here is a example:
* (a wildcard operator)—Using this predicate will wild-card the search term, so a search on hel* will return rows containing hell, Helen, help, and Helwig. Note that if you wild-card one term in a search phrase, all terms in the search phrase will be wild-carded. Here is a example:
SELECT Title FROM production.Document
WHERE CONTAINS (*, '"reflect*"')
The Contains Table/FreeTextTable clause returns a ranked rowset. Here is an example of its usage:
SELECT Title, RANK FROM production.Document join
CONTAINSTABLE(production.Document, *,'reflector') AS k ON
k.[Key]=production.Document.DocumentNode ORDER BY RANK DESC
ContainsTable and FreeText tables are especially valuable as they return a rank that can be used to order so that the most relevant searches are returned first. They also have a top_n_by_rank parameter, which allows you to limit the number of rows returned. Performance might be unacceptable if you were to conduct a complex query that returns several hundred thousand rows. This parameter is especially useful for such searches where you only want 100 rows returned. Here is an example of its usage:
SELECT Title, rank FROM production.Document join
CONTAINSTABLE(production.Document, *,'reflector',100) AS k ON
k.[Key]=production.Document.DocumentNode ORDER BY RANK DESC
The first question you should ask yourself when you have a problem with SQL full-text search is: Is the problem with searching or with indexing? To make this determination Microsoft has included three Dynamic Management Views (DMVs) in SQL Server 2008 to help you answer this question:
![]()
sys.dm_fts_index_keywords
![]()
sys.dm_fts_index_keywords_by_document
![]()
sys.dm_fts_parser
The first two DMVs will display the contents of your full-text index. The first DMV will return the following columns:
![]() Keyword—Each keyword in varbinary form
Keyword—Each keyword in varbinary form
![]() Display _term—The keyword as indexed; all the accents will be removed from the word.
Display _term—The keyword as indexed; all the accents will be removed from the word.
![]() Column_ID—The column ID in which the word exists
Column_ID—The column ID in which the word exists
![]() Document_Count—The number of times the word exists in that column
Document_Count—The number of times the word exists in that column
The second DMV breaks down the keywords by document. Like the first DMV it also contains the Keyword, display_term, and Column_ID columns, but in addition it contains the following two columns:
![]() Document_ID—The row in which the keyword occurred
Document_ID—The row in which the keyword occurred
![]() Occurrence_count—The number of times the word occurred in the cell (a cell is also known as a tuple; it is a row-column combination, that is, the contents of the third column in the fifth row)
Occurrence_count—The number of times the word occurred in the cell (a cell is also known as a tuple; it is a row-column combination, that is, the contents of the third column in the fifth row)
The first DMV is used primarily to determine candidate noise words and hapax legomena (words that occur once in your index and are likely typos) and can be used to diagnose indexing problems. The second DMV is used to determine what was stored in your index for a particular cell.
Here are some examples of their usage:
select * From sys.dm_fts_index_keywords(DB_ID(),
Object_iD('Production.Document'))
select * From sys.dm_fts_index_keywords_by_document(DB_ID(),
Object_iD('Production.Document'))
These two DMVs are used to determine what occurs at index time. The third DMV is used primarily to determine what happens at search time; in other words, how SQL Server full-text search interprets your search phrase. Here is an example of its usage.
select * from sys.dm_fts_parser(@queryString,
@LCID, @StopListID, @AccentSensitive)
@QueryString is your search word or phrase, @LCID is the LoCale ID for your language (determinable by querying sys.fulltext_languages), @StopListID is your stoplist file (determinable by querying sys.fulltext_stoplists), and @AccentSensitive allows you to set accent sensitivity (0 not sensitive, 1 sensitive to accents). Here is an example of how this works:
select * from sys.dm_fts_parser('café', 1033, 0, 1)
select * from sys.dm_fts_parser('café', 1033, 0, 0)
In the second example, you will notice that the display_term is cafe and not café. These queries return the following columns:
![]() Keyword—A varbinary representation of your keyword.
Keyword—A varbinary representation of your keyword.
![]() Group_id—The query parser builds a parse tree of the search phrase. If you have any Boolean searches, it will assign different Group_IDs to each part of the search term. For example, in the search phrase ‘“Hillary Clinton” OR “Barak Obama”’ Hillary and Clinton will belong to Group_ID 1 and Barak and Obama will belong to Group_ID 2.
Group_id—The query parser builds a parse tree of the search phrase. If you have any Boolean searches, it will assign different Group_IDs to each part of the search term. For example, in the search phrase ‘“Hillary Clinton” OR “Barak Obama”’ Hillary and Clinton will belong to Group_ID 1 and Barak and Obama will belong to Group_ID 2.
![]() Phrase_id—Some words are indexed in multiple forms, for example data-base is indexed as data, base, and database. In this case data and base will have the same
Phrase_id—Some words are indexed in multiple forms, for example data-base is indexed as data, base, and database. In this case data and base will have the same Phrase_id and database will have another phrase_id.
![]() Occurence_count—This is how frequently the word appears in the search string.
Occurence_count—This is how frequently the word appears in the search string.
![]() Special_term—Refers to any delimiters that the parser finds in the search phrase. Possible values are Exact Match, End of Sentence, End of Paragraph, and End of Chapter.
Special_term—Refers to any delimiters that the parser finds in the search phrase. Possible values are Exact Match, End of Sentence, End of Paragraph, and End of Chapter.
![]() Display_term—This is how the term would be stored in the index.
Display_term—This is how the term would be stored in the index.
![]() Expansion_type—The type of expansion: whether it is a thesaurus expansion (4), an inflectional expansion (2), or not expanded (0). For example, this query will show the stemmed variants of the word run:
Expansion_type—The type of expansion: whether it is a thesaurus expansion (4), an inflectional expansion (2), or not expanded (0). For example, this query will show the stemmed variants of the word run:
select * from sys.dm_fts_parser('FORMSOF( INFLECTIONAL,
run)',
1033, 0, 0)
![]() Source_Term—This is the source term as it appears in your query.
Source_Term—This is the source term as it appears in your query.
When troubleshooting indexing problems, consult the full-text error log, which can be found in C:Program FilesMicrosoft SQL ServerMSSQL10.MSSQLSERVERMSSQLLOG and will start with the prefix SQLFT followed by the database ID (padded with leading 0s), the catalog_id (query sys.fulltext_catalogs for this value), and then an extension of LOG. You may find many versions of the log each with a numerical extension, such as SQLFT0001800005.LOG.4. This is the fourth version of this log. These full-text indexing logs can be read by any text editor.
You may find entries in this log indicating that documents were retried or documents failed indexing along with error messages returned from the filters.
Here are some general best practices for improving SQL Server 2008 full-text search performance:
![]() Make your key index as narrow as possible—preferably an integer column with a nonclustered index on it. If your key index is your clustered index, place a nonclustered index on it as well and consider making this index a covering index.
Make your key index as narrow as possible—preferably an integer column with a nonclustered index on it. If your key index is your clustered index, place a nonclustered index on it as well and consider making this index a covering index.
![]() Consider partitioning very large tables into different physical tables (full-text indexing does not take advantage of partitioned tables). By doing so you can issue full-text queries in parallel and union all the results.
Consider partitioning very large tables into different physical tables (full-text indexing does not take advantage of partitioned tables). By doing so you can issue full-text queries in parallel and union all the results.
![]() Consider converting any binary data to text before storing it in the database to increase indexing performance and decrease indexing time. Note that OCR documents (TIFFs) are the most resource-intensive documents to full-text index.
Consider converting any binary data to text before storing it in the database to increase indexing performance and decrease indexing time. Note that OCR documents (TIFFs) are the most resource-intensive documents to full-text index.
![]() If you are using change tracking, reorganize your indexes periodically to improve performance and decrease fragmentation. Right-click on your catalog, select Properties, and click Optimize Catalog.
If you are using change tracking, reorganize your indexes periodically to improve performance and decrease fragmentation. Right-click on your catalog, select Properties, and click Optimize Catalog.
![]() If you are using change tracking, and experience locking while full-text indexing (especially when using the change tracking population types), use trace flag 7464, i.e.
If you are using change tracking, and experience locking while full-text indexing (especially when using the change tracking population types), use trace flag 7464, i.e.
DBCC TRACEON (7646, -1)
Microsoft has provided the following DMVs to help you monitor the indexing process:
![]()
Sys.dm_fts_outstanding_batches—This is a list of what is currently in the queue to be full-text indexed. Watch for entries in the is_retry_batch, retry_hints, retry_hints_description, and doc_failed columns. These indicate problems with locking between user activity and the indexing process as well as the filters malfunctioning or being unable to index the contents of binary object in the row.
![]()
Sys.dm_fts_fdhosts—This provides information on the index’s host process. Watch to see if the number of batches increases or remains high. This can indicate memory pressure in the OS, or insufficient resources; for example, when you index Asian-language content, you will see this value remain high as it is a CPU-intensive process.
![]()
Sys.dm_fts_memory_buffers—The indexing process is not only CPU intensive but also can be memory intensive if you are indexing large numbers of large documents.
![]()
Sys.dm_fts_index_population—Use this DMV to check the status of your indexing processes. Under resource pressure (for example, low disk space), the population process may pause. Check the status_description column for more information on your indexing progression.
![]()
Sys.dm_fts_active_catalogs—This DMV reports on the status of your full-text catalogs.
![]()
Sys.dm_fts_memory_pools—This DMV reports on memory use of the full-text indexing process. If the buffer_count is consistently high, you may need to cap the amount of memory SQL Server uses to dedicate some memory to the OS (and consequently the indexing process).
![]()
Sys.dm_fts_population_ranges—This DMV returns information about the specific ranges related to a full-text index population currently in progress.